背景知识:
我们在写完C/C++代码的时候会经历四个大阶段:
-
预处理(在代码中将预处理(#)的内容进行展开)。
-
编译(将对应的c/c++代码转换成会汇编语言)。
-
汇编(将汇编语言转换成对应的二进制)。
4.链接(将二进制进行链接起来形成一个表, 运行你编写的程序,生成可执行程序)。
初识gcc/g++:
gcc一般是进行c语言编译的, 而g++时进行c/c++编译的。
用法/语法:
gcc/g++ 选项 文件名 要进行编译的文件名使用:
这是我写的一个c 语言的程序,我们只是进行写了代码我们现在要运行他该如何做呢???
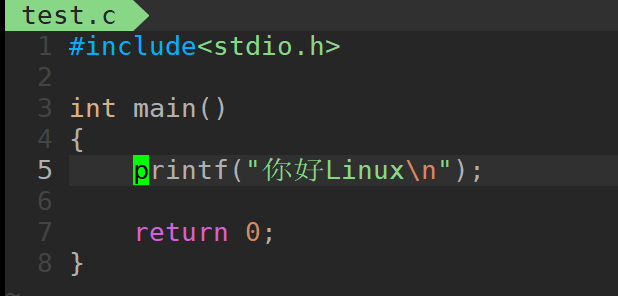
这里我们能看到我们使用了gcc 进行编译后形成了可执行的程序,我们使用相对路径进行运行后我们写的程序就可以跑起来了。
所以这里我们还可以知道"-o"选项是生成对应的可执行文件的。 并且"-o"后面跟上对应的文件名, 就会编译为对应的文件了。
四大阶段:
我们知道了代码会经历四个阶段, 现在就让我们来深度的了解这四个阶段:
阶段一: 预处理(.i)
预处理阶段是将我们的头文件和#define定义的常量和宏进行展开。
这是我写的一个代码那我们就来看一下这个预处理阶段的代码会成什么样子吧。
gcc -E test.c //默认打印在显示器里
gcc -E test.c -o test.i//生成一个.i文件进行储存那我们生成了一个.i文件我们现在把他打开看看吧。

进去之后发现行数非常的多, 原因是我们的头文件的内容多, 他将头文件的内容展开了(GG跳转到最后一行)
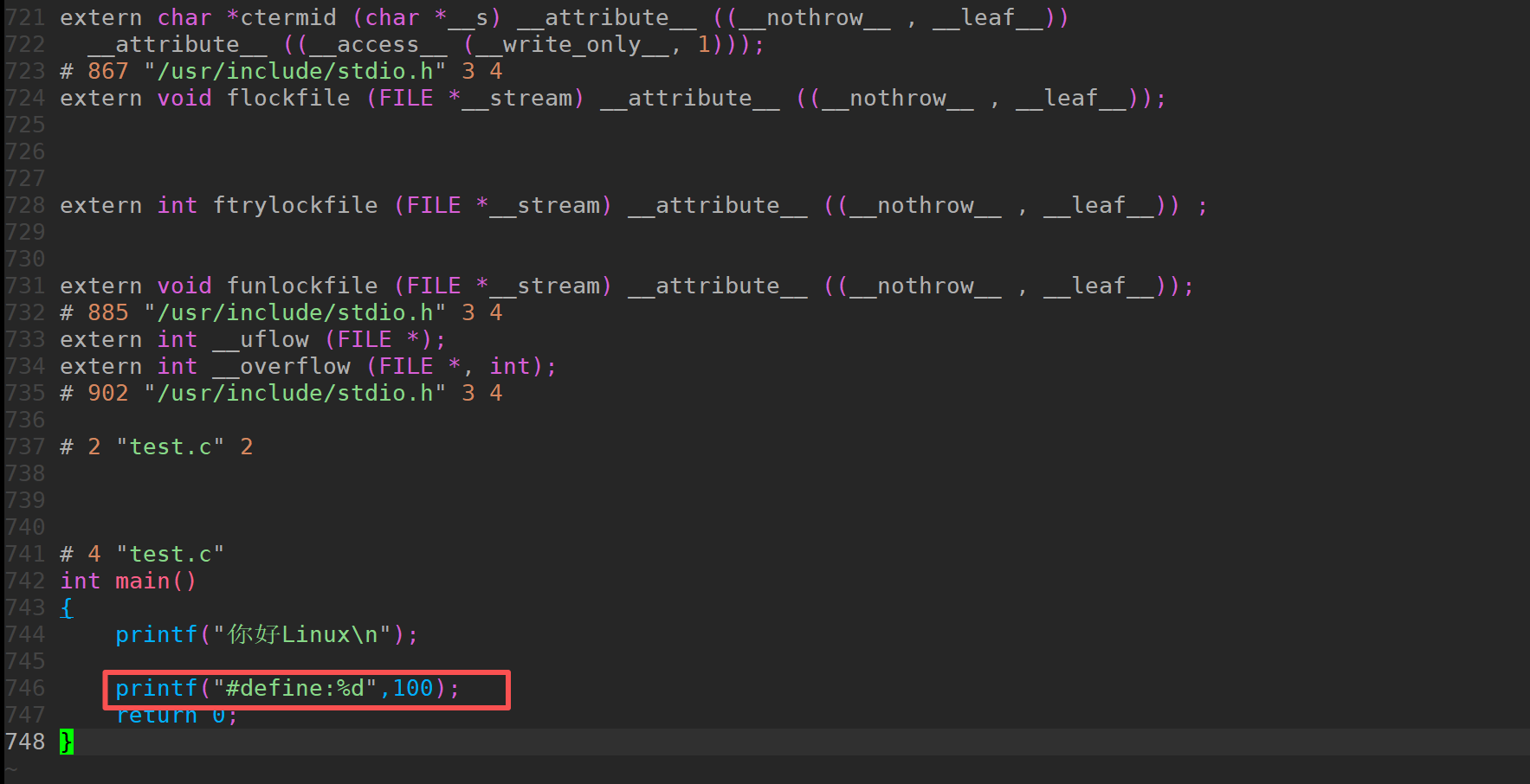
我们定义的LL被替换了100这是在预处理阶段的替换操作。
阶段二:编译(.s)
编译是将我们写的c 语言的代码转换为对应的汇编语言。那我们肯定也能像预处理一样通过gcc 来进行对应文件的观察了。 那我们还是那个代码我们该怎么操作呢???
下面我们就来进行演示一下吧:
gcc -S test.c // 默认打印在显示器
gcc -S test.c -o test.s// 生成一个.s文件来进行对应的储存这样我们就生成了对应的.s文件

我们直接进入
vim test.s我们可以看到一些列的汇编代码
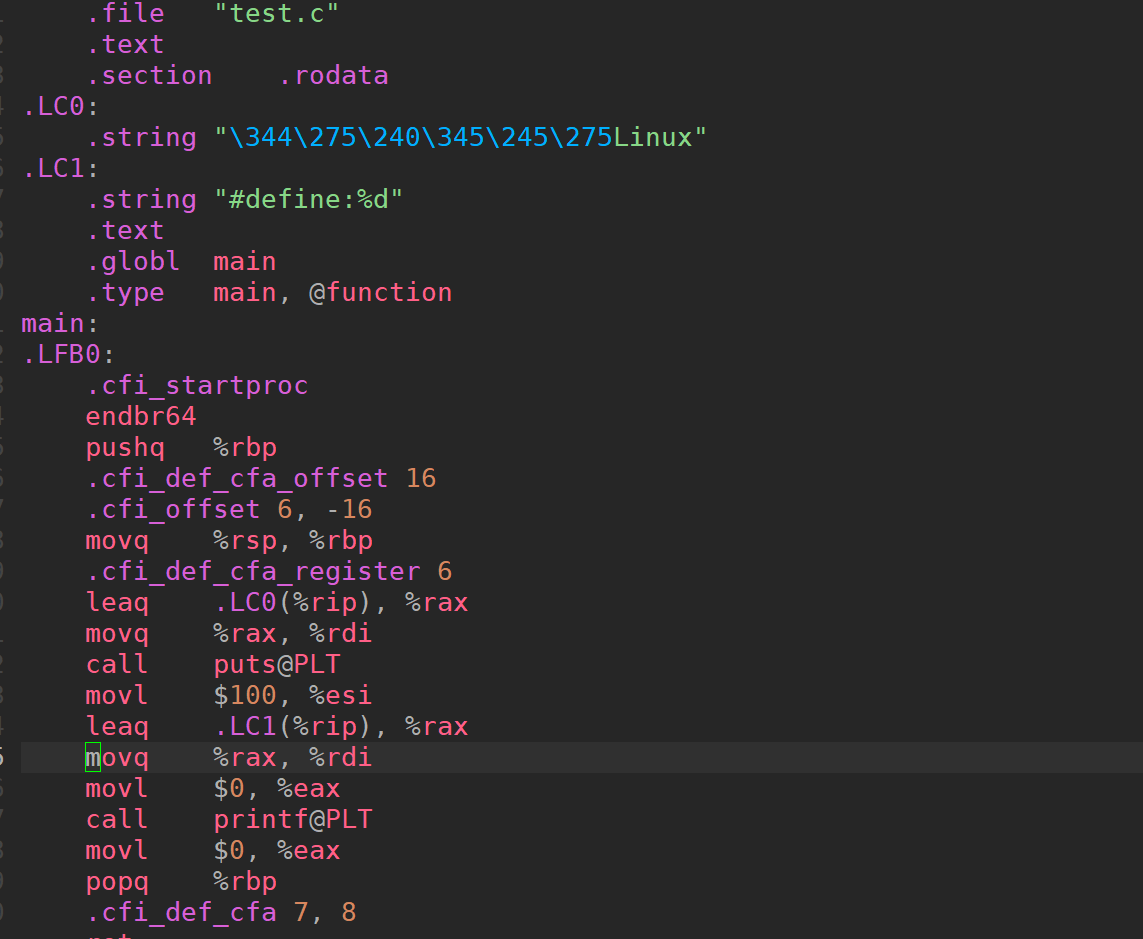
这就是我们编译阶段的核心要点。
阶段三:汇编(.obj)
这个阶段我们就是将汇编代码转换为对应的二进制文件那我们继续使用上面的代码就可以了。
gcc -c test.c //默认打印在显示器上
gcc -c test.c -o test.obj //生成一个.obj的文件 我们打开他:
我们打开他:
vim test.obj发现是一堆的二进制的乱码。

阶段四: 链接(.exe)
当然链接不是这么的简单的我们先进性简单的了解在进行细致的了解
生成对应的可执行文件
gcc test.obj //通过目标文件进行生成
gcc -o test test.c //直接生成可执行
综上所述:
我们知道了四个阶段同时也了解了四个阶段的选项:
.E 预处理阶段
. S 编译阶段
.c 链接阶段
记忆我们的左上角的(Esc)也就是这个顺序。
深度理解链接:
我们要进行多文件的编译创建
我们在一个的目录创建了这几个文件来进行我们的test

源文件的内容, 我们要把他们编译成.o文件来进行链接。
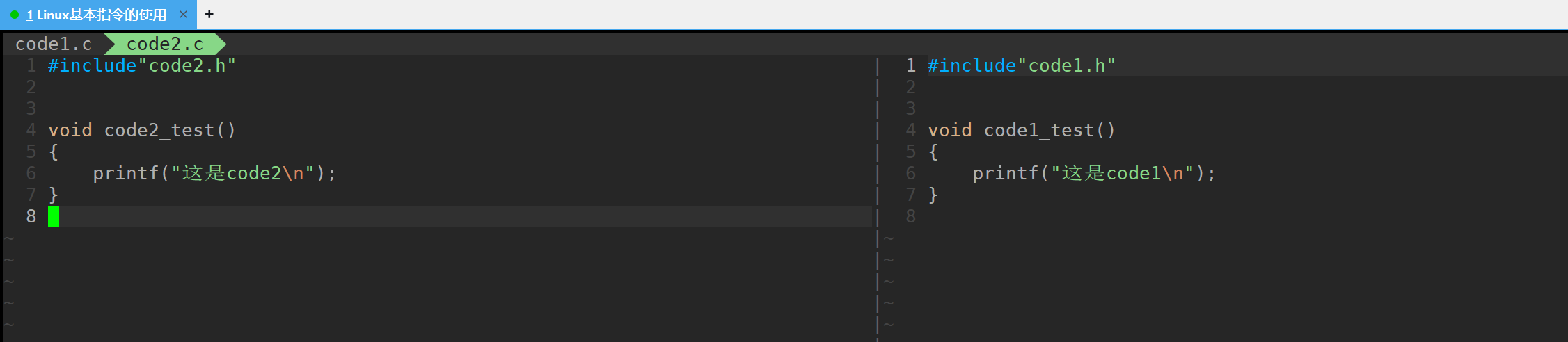
我们就生成了对应的文件,都是二进制的我们没必要进行查看(看不懂的)我们不想要把源码给别人卡就可以采用这样的方法。

我们上一个文件有调用这两个函数的那我们(mv)进行移动的话。 来进行上一级的使用
mv *.h *.o ..
好的这样我们就移动到上一级了。 我们要把他们都给链接起来。
test文件的内容:
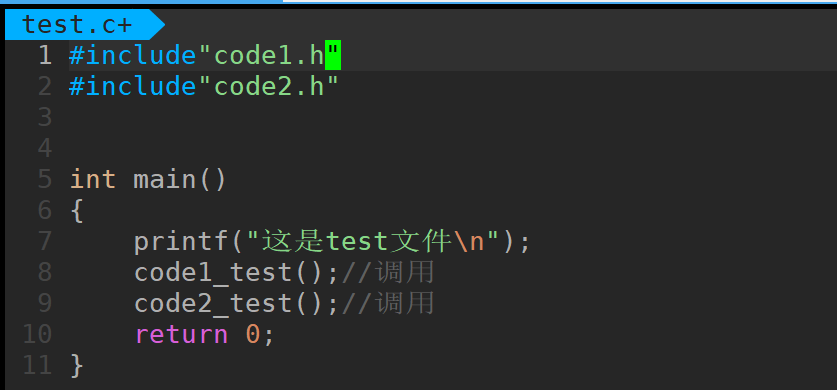
把他编译为对应的.o文件

下面我们开始进行链接:
我们把当前文件的所有.o文件进行链接。 然后运行。
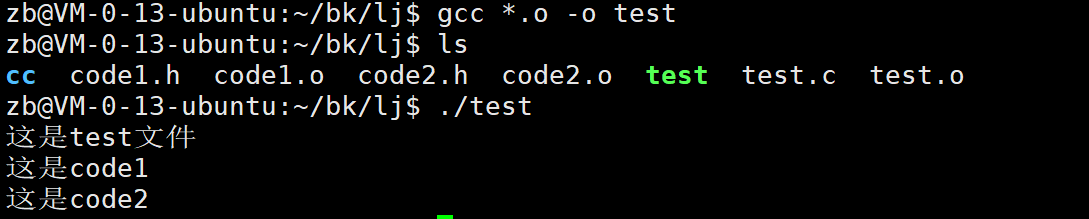
如果我们的源代码可以让别人知道的话我们也可以直接的进行源文件生成
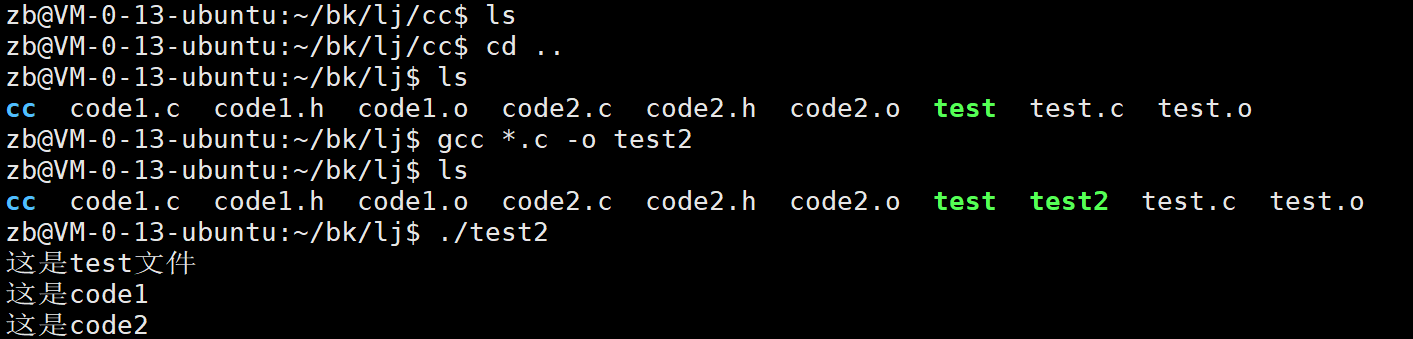
这样也是可以的。
浅谈动静态库的相关知识
动静态库的链接
在实际开发中,我们不会把所有代码写在一个源文件里,而是拆分成多个 .c源文件,文件之间会存在依赖关系(比如 A 文件调用 B 文件定义的函数)。
C 语言的编译规则是:每个源文件独立编译 ,一个 .c 文件生成一个对应的 .o 目标文件。这些独立的目标文件之间并不知道彼此的存在,为了让它们能互相调用、形成一个完整的可执行程序,就需要把所有目标文件打包合并到一起 ,这个合并过程就是静态链接。
静态链接的缺点:
-
内存浪费 / 空间浪费 静态链接会把所有用到的库代码、函数代码,完整复制一份到最终的可执行程序里。如果多个程序都使用同一个静态库,每个程序都会单独拷贝一份库代码,极大占用磁盘空间和运行内存。
-
更新维护极其麻烦 一旦静态库中的代码有 bug、需要升级,所有使用这个库的可执行程序,都必须重新编译、重新链接,无法单独更新库文件,扩展性极差。
-
可执行程序体积巨大因为把所有依赖都打包进程序里,最终生成的文件会比动态链接大得多
动态链接解决了这些问题,他的工作大概就是将我们的动态库的地址加载到内存中如果我们需要的话我们可以通过底层的某些指令来进行查找这样一个地址的内存也就是(4/8字节)能很好的进行解决内存大量被占用的情况。
库的区分:
在linux操作系统中: 动态库(XXX.so),静态库(XXX.a)
在windows操作系统中: 动态库(XXX.dll), 静态库(XXX.lib)
当然我们在linux系统下也能进行查看对应的库的情况:
语法: ldd 可执行文件的文件名我们下面的图片看一下对应的是依赖动态库的。
我们在之前学习语言的时候就知道了一个概念那就是库
像我们C语言的printf scanf...都依赖了一个库那就是吧stdio这个库。
我们在我们的操作系统中也是可以了解的一些系统的动静态库的

当然这里还有一个file指令能查看库的具体的内容,我们可以看到一句话(dynamically linked, interpreter)默认是动态链接的。当然我们也能够得到结论gcc编译的二进制文件默认是动态链接的。


在unbutu静态库的安装方法:
sudo apt install libssl-dev总结:
静态库调用的时候我们是将静态库的代码拷贝到程序中,而动态库我们是通过指针指令的形式进行的调动, 这样两者进行比较时我们能发现动态库的代价是更小的。这里我们只是浅谈动静态库详细的后续期待与诸位一起讨论。
自动化构建-make/makefile
首先在说明make和makefile之前我们先一句话说一下这两个是什么
make 是一个指令。
makefile是一个文件。
那这两者有什么关系呢???
他们的关系就像我们的vim和.vimrc一样我们配置vimrc,是为了让我们的vim更好的被使用。 同理我们配置makefile是为了让我们的make能更好的进行工作。
我们在写完代码的时候我们总是要gcc...的进行编译, 编译一次还行但是多次以后就会有些麻烦了,那我们是不是每次编译的时候都要写这么长的命令, 我们不想这样此时make带着makefile来了。
make/makefile的的用法:
创建makefile文件
方法一:
vim makefile
方法二:
vim Makefile此时我们目录下有以下的文件

makefile的文件我们写入:
1 test:test.c
2 gcc -o test test.c现我们wq使用make试一下会有什么效果
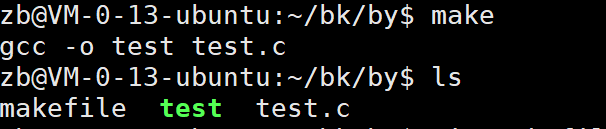
我们make一下它出现的就是我们makefile的条件所以编译的时候我们直接进行make就能将文件进行编译了。
深度理解makefile的代码:
1 test:test.c
2 gcc -o test test.c首先上面的
test:test.c我们叫做依赖关系。理解: 我们要是想要生成test要依赖文件test.c。
而我们的目录下没有test但是又test.c。 我们可以使用test.c搭配方法来进行生成test
而方法就是下面的那一行我们要进行这个方法进行生成test。
注意:在我们写对应的方法是要以Tab键开头这是语法规定。
所以所以: 有了这些方法我们是不是可以生成对应我们上面所说的.i.s.o文件了?
那现在我们试一试:
当前目录下我们拥有的文件:

1 test:test.o
2 gcc test.o -o test
3 test.o:test.s
4 gcc -c test.s -o test.o
5 test.s:test.i
6 gcc -S test.i -o test.s
7 test.i:test.c
8 gcc -E test.c -o test.i代码解读:
我们要生成test要依赖test. o但是我们没有test.o那继续我们想要test.o 我们就必须要有test.s
但是我们也没有test.s 我们就要依赖test.i同理我们也没有。那么向下我们发现我们有test.c他能生成test.i进而生成test.s ... 最后生成test。那我们make一下试试把:
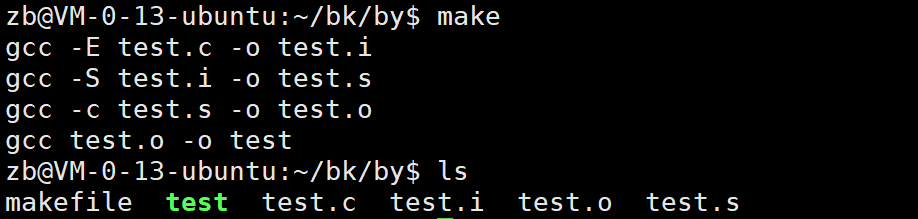
果然我们make一下都生成了。
但是我们不想要这些生成的文件了我们难道要rm一个个删吗这样太长了有简单的方法吗???
像我们的make一样:
答: 肯定是有的那我们该怎么的操作呢?
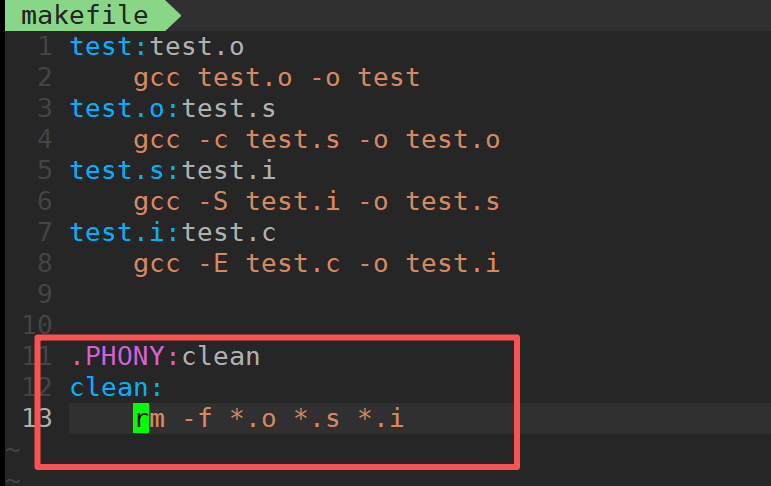
代码的解读:
.PHONY是什么意思呢???
他后面的clean又是什么意思呢???
答: 他是设置一个伪目标, 它的作用是让我们多次的执行对应的指令。(后面演示)
与上面的方法一样以Tab进行开头。那我们执行一下看一下效果把:
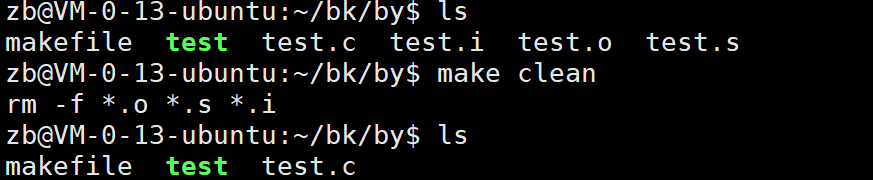
果然文件都被删除了。
深度理解伪目标:
像我们在执行make的时候就没有对应的.PHONY那我们多次执行的结果是什么样子的呢???
我们可以试试:
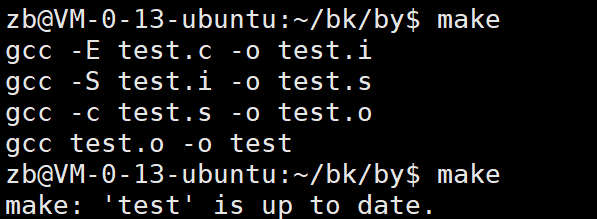
第一次让我进行使用而我们的代码并没有进行改变所以我们看看有伪目标的:

两次都能进行使用
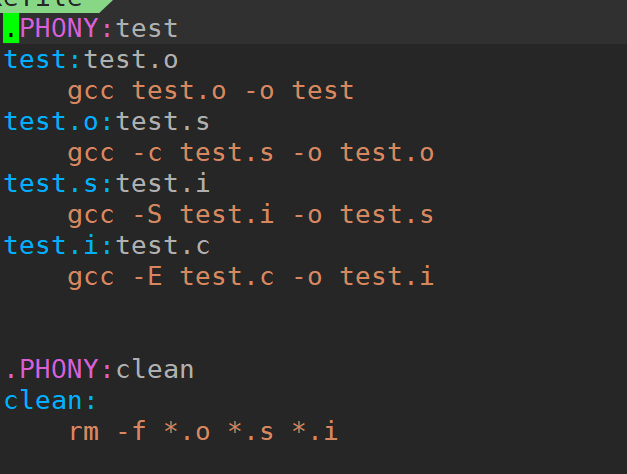
我们加上了对应的伪目标了:

我们可以进行多次的编译了, 但是我们编译对应的代码没有进行改变我们编译多次也没有用。
但是我们的多次清除能更加完美的进行文件的删除。
还有有大家应该注意到我们这里为什么只运行了第一个下面的为啥不运行了。我们的make后不带任何的指令默认是执行第一句话的。
但是我们将指令的显示出来有点不好看我们想要进行隐藏,那该怎么办呢?
在前面加上@
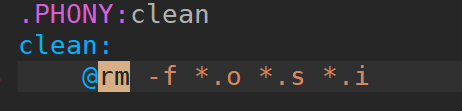
果然隐藏了

make/makefile的进阶用法:
1 DEST=test
2 SRC=test.c
3 cc=gcc
4 RM=rm -f
5 FLA = -o
6
7 $(DEST):$(SRC)
8 @$(cc) $(FLA) $(DEST) $(SRC)
9 @echo "编译成功"
10
11 .PHONY:clean
12 clean:
13 $(RM) $(DEST)我们的DEST SRC可以理解文宏的替换将他们进行替换而$我们可以理解为解引用,而我们用@吧信息隐藏了我们想要查看信息的话我们可以用echo来进行打印信息。
我们现在来认识几个有关的操作符:
@ ^
直接看使用:
这里的@=(DEST) \^=(SRC)
1 DEST=test
2 SRC=test.c
3 cc=gcc
4 RM=rm -f
5 FLA = -o
6
7 $(DEST):$(SRC)
8 @$(cc) $(FLA) $@ $^
9 @echo "编译成功"
10
11 .PHONY:clean
12 clean:
13 $(RM) $(DEST)
1 SRC=$(shell ls *.c)//把该目录下的.c全部拿出来
2 OBJ=$(SRC:.c=.o)// 将SRC文件的所有文件的.o换成.c
3 cc=gcc
4 RM=rm -f
5 FLA = -o
6 F= -c
7 DEST=test
8
9 $(DEST):$(OBJ)
10 $(cc) $(FLA) $@ $^
11 %.o:%.c
12 @$(cc) $(F) $<
13 @echo "编译成功"
20 .PHONY:clean
21 clean:
22 $(RM) $(DEST) $(OBJ)
23 %.o : %.c的意思是将所有的改目录下的(.c)文件全部编译成.o文件。
$<是将所有的.c文件进行展开。
