摘要
承接上篇《Flink 实时计算四大基石》,本文进入实时计算核心工程化场景 ------ 多数据源关联。结合实时数仓分层架构,深度拆解 Union、Connect、Interval Join、Lookup Join 四大关联方案,从架构定位、核心定义、生产场景、代码实现到避坑要点,清晰界定各方案选型边界,提供可直接落地的实战技巧,助力开发者吃透多流关联核心,适配生产落地与面试需求。
一、多流关联架构总览(实时数仓分层视角)
在企业级实时数仓体系中,多流关联并非随意使用,而是严格对应分层架构 ,承担不同阶段的数据处理职能:
|-----------|----------------|-----------------------------|----------|
| 架构分层 | 核心职责 | 适用关联方案 | 设计目标 |
| ODS 层 | 原始数据接入 | 无 | 数据同步 |
| DWD 层 | 数据清洗、标准化、补全维度 | Union + Lookup Join | 构建统一明细宽表 |
| DWS 层 | 业务关联、指标聚合、宽表输出 | Connect + Interval Join | 支撑核心业务指标 |
| ADS 层 | 报表输出、业务应用 | 无 | 提供最终数据服务 |
架构设计原则:简单合并放 DWD,业务关联放 DWS,维表补全贯穿全流程
二、方案一:Union 多流合并
2.1 架构定位
DWD 层核心算子 → 多源同构数据统一入口,实现物理分散、逻辑统一的数据整合
2.2 核心定义
Union 是 Flink 提供的无状态多流合并算子 ,将多条数据结构、字段类型完全一致 的数据流,在内存中进行逻辑合并,不产生数据冗余、不涉及状态存储、不改变数据结构 。
2.3 核心特性对比
|--------|---------------------|-------------------|
| 特性 | 说明 | 生产注意事项 |
| 数据类型要求 | 必须完全一致(POJO / 基本类型) | 字段顺序、类型需严格统一 |
| 性能 | 极高,纯内存操作,无 IO 开销 | 高吞吐场景优先选择 |
| 状态使用 | 无状态 | 不会出现状态膨胀问题 |
| 并行度 | 多流并行度可不同 | 建议保持一致提升效率 |
| 数据顺序 | 不保证时序 | 依赖后续 Watermark 对齐 |
2.4 场景
全端用户行为日志统一归集
- 数据源:APP、小程序、H5、第三方平台 4 个 Kafka Topic
- 数据结构:完全一致,物理隔离、权限隔离
- 需求:统一 UV/PV 统计、统一清洗、统一写入 ClickHouse
- 不可替代性:Connect 仅支持 2 条流;Interval Join 需要关联匹配;Kafka 转发产生数据冗余
2.5 代码实现
java
// 1. 定义多源Kafka数据源
KafkaSource<UserBehavior> appSource = KafkaSource.<UserBehavior>builder()
.setTopics("topic_app_log")
.setDeserializer(new UserBehaviorDeSerializer())
.build();
KafkaSource<UserBehavior> miniSource = ...; // 小程序源
KafkaSource<UserBehavior> h5Source = ...; // H5源
// 2. 多流读取
DataStream<UserBehavior> appStream = env.fromSource(appSource, ...);
DataStream<UserBehavior> miniStream = env.fromSource(miniSource, ...);
DataStream<UserBehavior> h5Stream = env.fromSource(h5Source, ...);
// 3. Union合并(核心算子)
DataStream<UserBehavior> unionStream = appStream.union(miniStream, h5Stream);
// 4. 统一清洗处理
DataStream<UserBehavior> cleanedStream = unionStream
.filter(bean -> StringUtils.isNotBlank(bean.getUserId()))
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)));
// 5. 统一输出
cleanedStream.sinkTo(clickHouseSink);2.6 最终生产效果
✅ 多源数据统一口径,避免重复开发
✅ 纯内存合并,无额外存储成本
✅ 支持动态增删数据源,无需修改链路
✅ 统一监控、统一告警、统一运维
三、方案二:Connect 双流连接
3.1 架构定位
DWS 层动态计算算子 → 业务数据流 + 控制规则流协同处理,实现动态配置、实时风控
3.2 核心定义
Connect 支持两条不同数据类型 的数据流连接,通过CoProcessFunction分别处理两条流数据,共享算子状态 ,实现流与流之间的实时协同、动态交互。
3.3 核心原理时序图
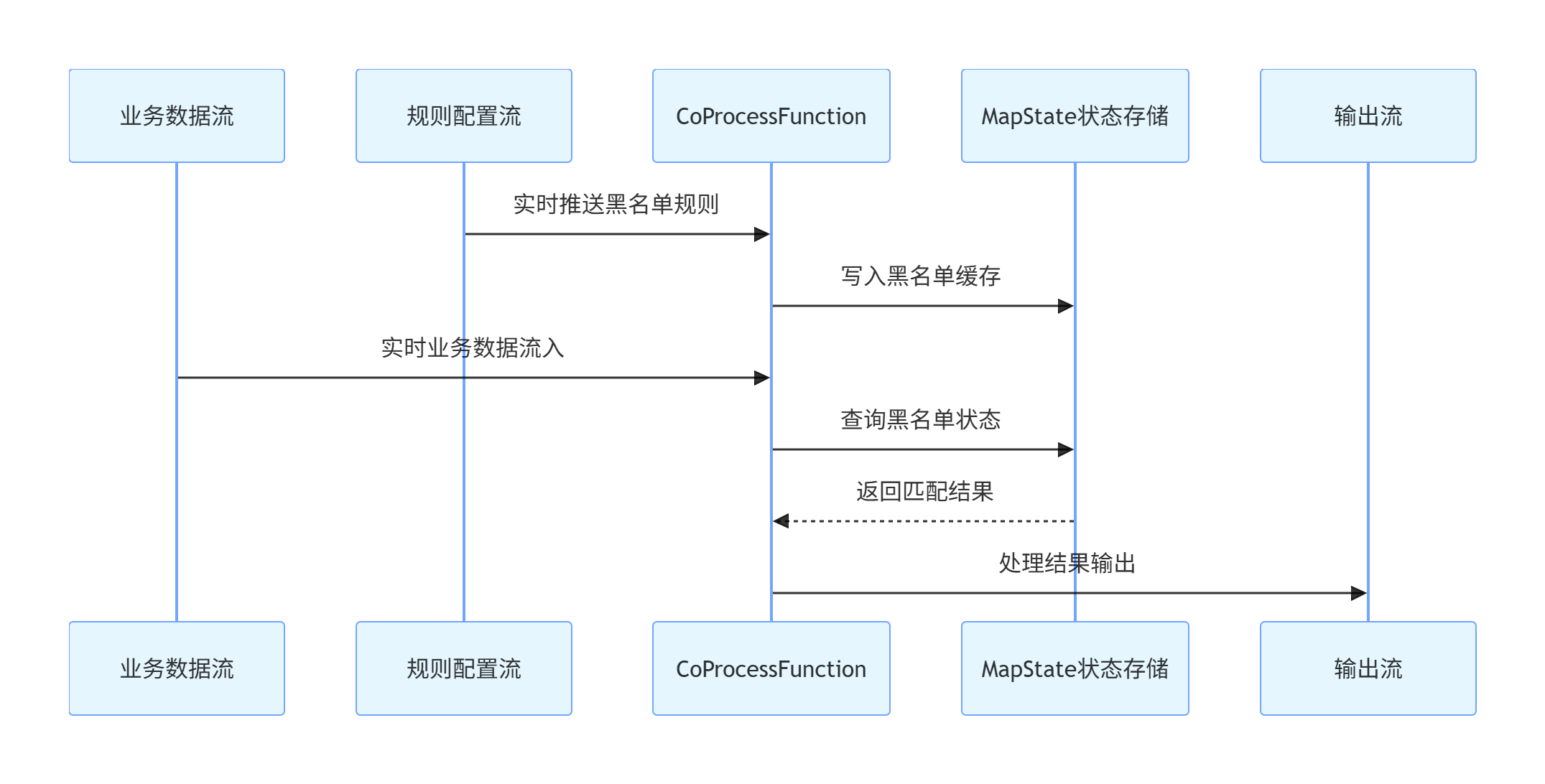
3.4 场景
支付流 + 动态黑名单实时风控
- 主流:用户支付实时流
- 控制流:后台配置的黑名单 / 白名单 / 风控规则
- 需求:规则实时生效、低延迟校验、无外部依赖
- 不可替代性:Union 类型不匹配;Interval Join 无时间关联;Lookup Join 有查询延迟
3.5 代码实现
java
// 1. 定义两条流
DataStream<PayOrder> payStream = env.fromSource(payKafkaSource, ...);
DataStream<BlackListRule> ruleStream = env.fromSource(ruleKafkaSource, ...);
// 2. Connect连接
ConnectedStreams<PayOrder, BlackListRule> connectedStream = payStream.connect(ruleStream);
// 3. 协同处理(共享状态)
connectedStream.process(new CoProcessFunction<PayOrder, BlackListRule, RiskResult>() {
// 黑名单状态(共享)
private MapState<String, Boolean> blackListState;
@Override
public void open(Configuration parameters) {
MapStateDescriptor<String, Boolean> descriptor = new MapStateDescriptor<>(
"blackListState", String.class, Boolean.class
);
blackListState = getRuntimeContext().getMapState(descriptor);
}
// 处理业务数据
@Override
public void processElement1(PayOrder order, Context ctx, Collector<RiskResult> out) throws Exception {
boolean isBlock = blackListState.get(order.getUserId()) == Boolean.TRUE;
out.collect(new RiskResult(order.getOrderId(), isBlock ? "REJECT" : "ACCEPT"));
}
// 处理规则数据
@Override
public void processElement2(BlackListRule rule, Context ctx, Collector<RiskResult> out) throws Exception {
blackListState.put(rule.getUserId(), rule.getIsBlock());
}
});3.6 最终生产效果
✅ 规则实时生效,无需重启任务
✅ 纯内存计算,无外部查询延迟
✅ 状态共享,数据一致性保证
✅ 动态风控、动态阈值场景标准方案
四、方案三:Interval Join 流流时间关联
4.1 架构定位
DWS 层核心业务算子 → 双业务流按 Key + 时间精准匹配,构建核心业务宽表
4.2 核心定义
基于EventTime + Watermark + KeyGroup 的双流关联算子,仅当相同 Key + 事件时间在指定时间区间 内时触发匹配,完美支持乱序数据,是生产中最核心、最常用 的双流关联方案。
4.3 核心参数对比
|--------|----------------|-----------------------|
| 参数 | 作用 | 生产配置建议 |
| 关联 Key | 业务关联主键 | orderId、userId、itemId |
| 时间下界 | 允许数据提前时间 | -10s(订单前支付) |
| 时间上界 | 允许数据延迟时间 | +10s(支付滞后订单) |
| 时间语义 | 必须使用 EventTime | 保证业务时间精准 |
| 状态清理 | 区间过期自动清理 | 避免状态膨胀 |
4.4 场景
订单流 ↔ 支付流 实时关联计算支付成功率
- 流 1:订单创建流(orderId、orderTime、amount)
- 流 2:支付完成流(orderId、payTime、payAmount)
- 需求:10 秒内匹配、计算实时成功率、支持乱序
- 不可替代性:Union 仅合并不匹配;Connect 无时间关联;Lookup Join 不支持流匹配
4.5 代码实现
java
// 1. 两条业务流(已设置EventTime + Watermark)
DataStream<Order> orderStream = env.fromSource(orderSource, ...);
DataStream<Pay> payStream = env.fromSource(paySource, ...);
// 2. Interval Join核心实现
orderStream
.keyBy(Order::getOrderId)
.intervalJoin(payStream.keyBy(Pay::getOrderId))
.between(Time.seconds(-10), Time.seconds(10)) // 时间窗口
.process(new ProcessJoinFunction<Order, Pay, OrderPayWide>() {
@Override
public void processElement(Order order, Pay pay, Context ctx, Collector<OrderPayWide> out) {
OrderPayWide wide = new OrderPayWide();
wide.setOrderId(order.getOrderId());
wide.setOrderTime(order.getOrderTime());
wide.setPayTime(pay.getPayTime());
wide.setPaySuccess(pay.getStatus() == 1);
out.collect(wide);
}
});4.6 最终生产效果
✅ 订单 - 支付精准匹配,支持乱序补偿
✅ 实时计算支付成功率、超时未支付率
✅ 状态自动清理,无状态膨胀风险
✅ DWS 层业务宽表标准构建方案
五、方案四:Lookup Join 流与维表关联
5.1 架构定位
全层通用补全算子 → 实时流补全外部维表信息,构建宽表字段
5.2 核心定义
Lookup Join 是实时数据流异步查询外部维表 (MySQL/Redis/HBase)的关联方式,通过AsyncIO 异步非阻塞 + 本地缓存 提升性能,是实时数仓中字段补全最通用方案 。
5.3 生产优化对比
|---------|---------|-----------------------|---------------|
| 优化项 | 未优化 | 优化后 | 性能提升 |
| 查询方式 | 同步阻塞 | AsyncIO 异步非阻塞 | 降低 80% 线程阻塞 |
| 缓存策略 | 无缓存 | LRU 本地缓存 + Redis 二级缓存 | 减少 90% 外部查询 |
| 超时控制 | 无超时 | 1s 超时熔断 | 避免拖慢 Flink 任务 |
| 并发控制 | 串行查询 | 异步多路复用 | 提升 5-10 倍吞吐量 |
5.4 场景
用户点击流补全商品维表信息
- 实时流:用户点击流(仅含 itemId)
- 维表:MySQL 商品表(itemId、name、category、price、shopId)
- 需求:实时补全、低延迟、不修改上游数据
- 不可替代性:其他方案均为流 - 流关联,无法查询外部静态数据
5.5 代码实现
java
// 异步查询Redis维表
AsyncDataStream.unorderedWait(
clickStream,
new AsyncFunction<UserClick, UserClickWide>() {
// 本地缓存(LRU)
private final LoadingCache<String, ItemInfo> cache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(key -> itemRedisClient.get(key));
@Override
public void asyncInvoke(UserClick click, ResultFuture<UserClickWide> result) {
String itemId = click.getItemId();
// 先查本地缓存
ItemInfo itemInfo = cache.getIfPresent(itemId);
if (itemInfo != null) {
result.complete(Collections.singleton(new UserClickWide(click, itemInfo)));
return;
}
// 异步查Redis
itemRedisClient.hgetAll("item:" + itemId, callback -> {
ItemInfo info = JSON.parseObject(callback, ItemInfo.class);
cache.put(itemId, info);
result.complete(Collections.singleton(new UserClickWide(click, info)));
});
}
},
1000, TimeUnit.MILLISECONDS // 超时控制
);5.6 最终生产效果
✅ 实时流字段补全,构建完整宽表
✅ 异步 + 缓存,性能满足高并发
✅ 不侵入上游业务,架构解耦
✅ 实时数仓标准化维表补全方案
六、架构师视角:四大方案选型决策树
6.1 技术选型决策
|-------------------|---------------|-----------|
| 决策条件 | 首选方案 | 架构分层 |
| 多条同构流需要统一处理 | Union | DWD 层 |
| 业务流 + 动态规则 / 配置流 | Connect | DWS 层 |
| 两条业务流按 Key + 时间匹配 | Interval Join | DWS 层 |
| 实时流需要补全外部维表 | Lookup Join | DWD/DWS 层 |
6.2 核心设计原则
- 分层原则 :DWD 负责合并与补全,DWS 负责业务关联
- 性能原则 :无状态优先(Union)→ 有状态轻量(Connect)→ 状态计算(Interval Join)→ 外部查询(Lookup Join)
- 运维原则 :优先使用内置算子,避免自定义复杂状态
- 扩展原则 :支持动态增删数据源、规则、维表字段
七 、核心复习要点
融合架构选型、关键特性与生产避坑,精简复盘核心考点,适配开发自查与面试复习。
1.架构分层边界
- DWD 层:依靠 Union 做多源同构流合并、Lookup Join 完成维表补全;
- DWS 层:依靠 Connect 实现动态规则协同、Interval Join 完成业务流时间关联。
2.四大关联核心区别
- Union:无状态同构流合并,仅做数据归集,无关联匹配逻辑;
- Connect:支持双异构流,依托共享状态,实现数据流与配置控制流联动;
- Interval Join:基于事件时间 + 水印 + 分组 Key,完成双流时间区间精准匹配,适配乱序场景;
- Lookup Join:异步查询外部维表,用于实时宽表字段补全,属于流与外部存储联动。
3.生产避坑精简要点
- Union 需保证多流数据结构完全一致,避免序列化报错;
- Connect 规则流配置状态 TTL,防止状态持续膨胀;
- Interval Join 合理限制时间区间,搭配状态 TTL,控制存储开销;
- Lookup Join 强制使用异步 + 缓存,禁止同步查库,避免任务阻塞。
4.选型核心原则
多源合并选 Union、动态规则选 Connect、业务双流关联选 Interval Join、维度补全选 Lookup Join,四大场景互不兼容、不可相互替代。
📚 我的技术博客导航:点击进入一站式查看所有干货