一、人工智能发展
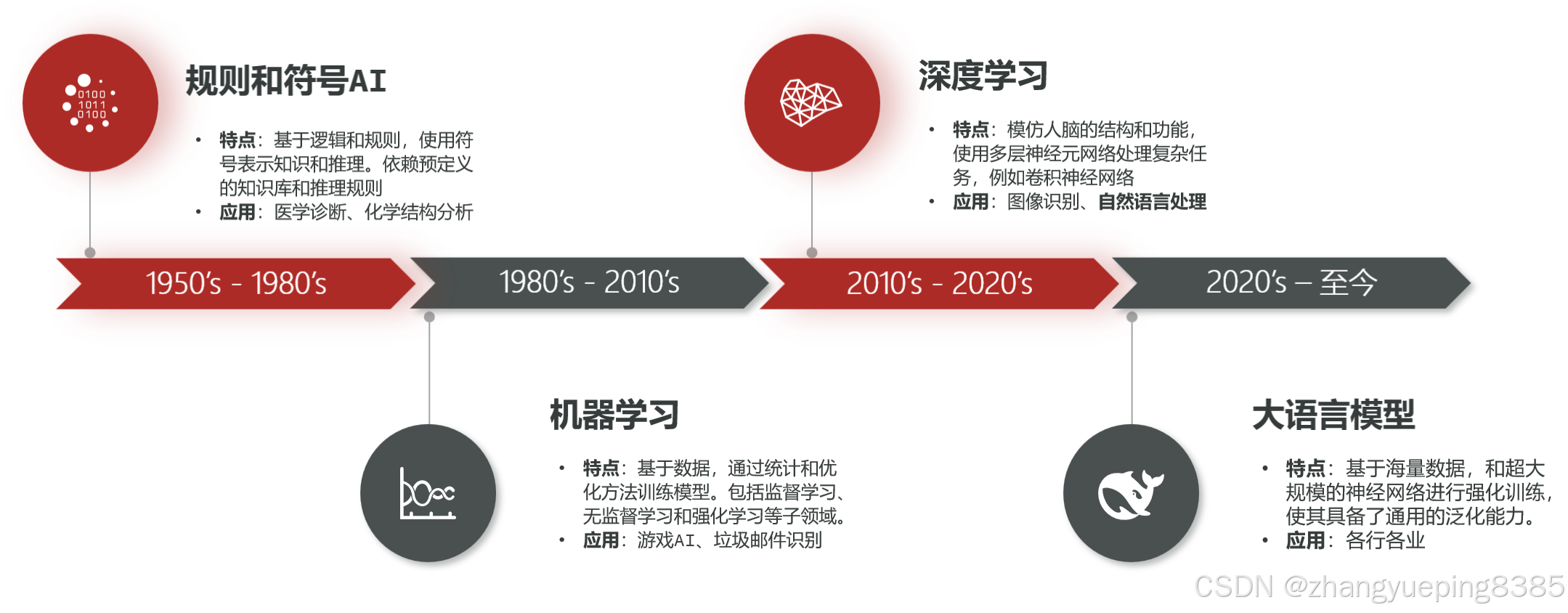
人工智能的发展并非一蹴而就,而是经历了四次范式的根本性转变:
-
第一浪潮:规则与符号(1950s-1970s)
- 核心逻辑:基于"符号主义"。中断认为智能可以拆解为复杂的逻辑规则和搜索算法(如象棋、定理证明)。
-
第二浪潮:统计与学习(1980s-2000s)
- 核心逻辑:转向"联结主义"。不再人工写规则,而是让机器从数据中统计规律(如垃圾邮件过滤)。
-
第三浪潮:深度神经网络的突破(2010s)
- 核心逻辑:深度学习(Deep Learning)崛起。依托GPU算力和海量数据,层层神经元结构让机器在图像识别和语音处理上超越人类。
-
第四浪潮:大模型与生成式AI革命(2020年代至今)
-
核心逻辑:从"专用"转向"通用"。大语言模型(LLM)的出现,使得AI具备了逻辑推理和内容生成的泛化能力。
-
-
二、智能支撑的三大基石
为什么大模型在近两年突飞猛进?其背后有三个大象的支撑,被形象地称为AI的"三座大山":
1. 模型算法(大脑结构)
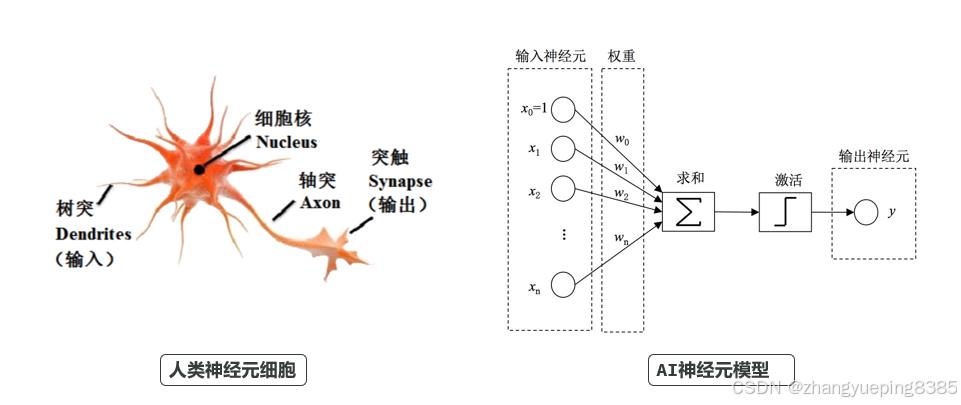
现代AI人类模拟大脑的神经元结构。
-
神经元(Neuron) :接收输入
,进行权重求和,再通过激活函数(如ReLU, Sigmoid)输出。
-
Transformer 架构:这是当前大模型的基石。相比于早期的循环神经网络(RNN),Transformer 支持任务计算,并拥有更长的"上下文窗口",能够理解极长的段落和逻辑。
-
2.海量数据(知识来源)
如果没有数据训练,再聪明的算法也是"空壳"。AI学习了几乎所有的精华------维基百科、书籍、论文、代码库。这种万亿级的运算量为AI提供了广博的常识。
3.超级算力(进化引擎)
大模型的训练是天文数字级别的计算。数百万顶级GPU(如Nvidia H100)不间断工作,这种算力消耗已远超摩尔定律的增长,是支撑AI进化的物理基础。
三、大模型是如何"学习"的?(基础原理)
1. 万物皆可函数:简单的过程
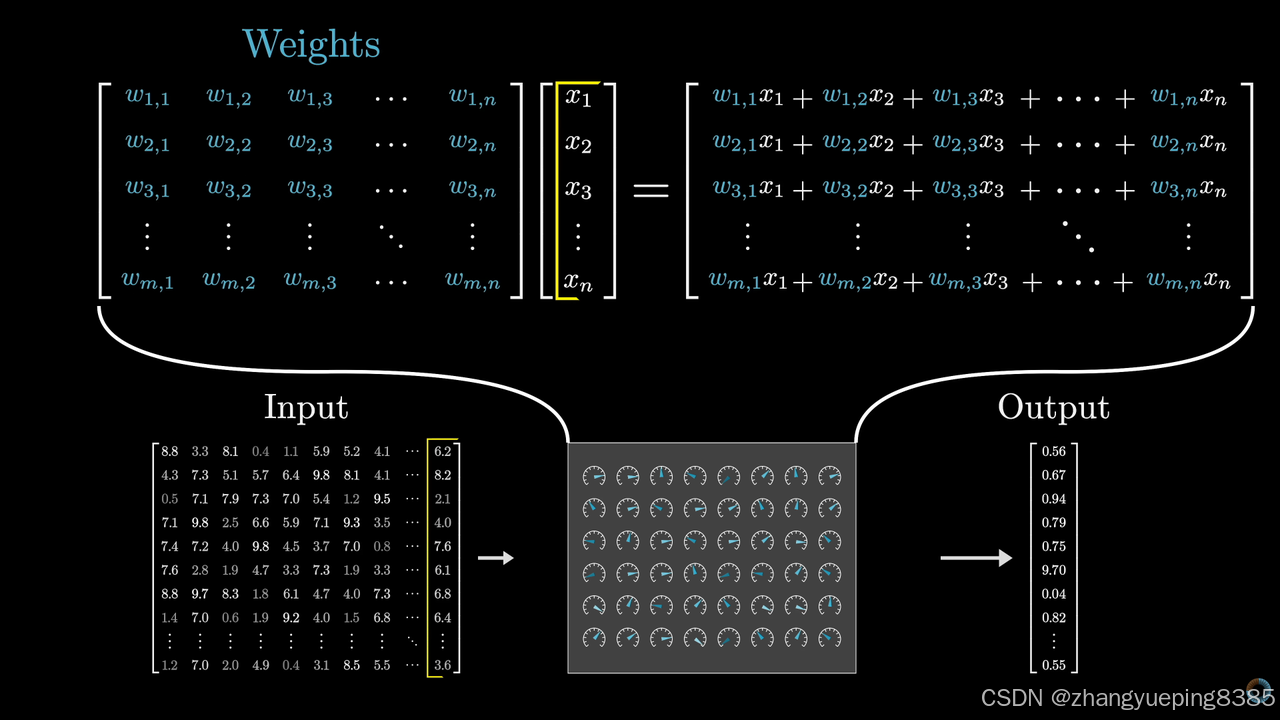
从数学角度看,大模型可以被视为极其复杂的超大规模函数。
-
简单函数:
-
大模型函数:拥有千亿级别(参数)的参数。
模型训练:本质上就是通过"猜答案"来直观参数。
-
给模型输入一段文字,使预测下一个字。
-
对比预测值与真实值的差距(损失函数 Loss Function)。
-
根据逆差调整参数(逆差传播 Backpropagation)。
-
循环往复,直到模型能够完善人类的语言系统。
2. 核心技术:词向量(Word Embedding)
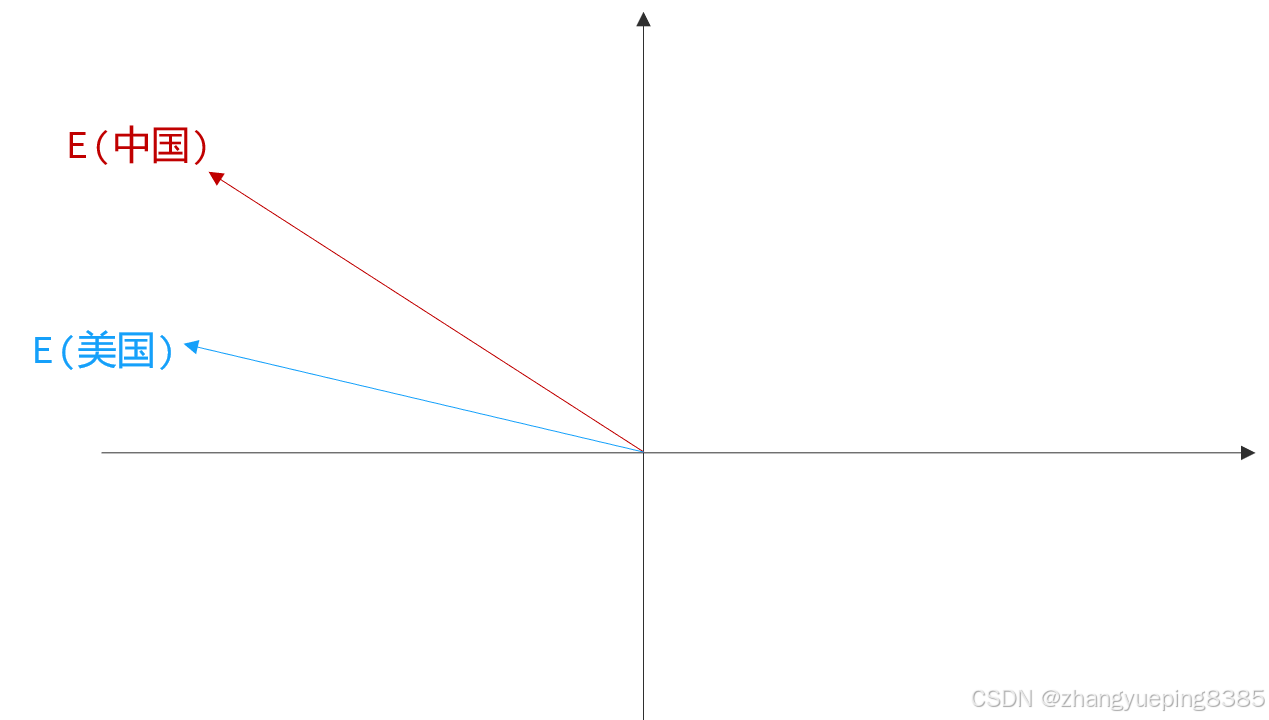
人类的文字如何涉及大脑损伤?答案是支持化。通过算法,每个词都会被映射到多维空间中的一个坐标点(支持)。
-
语义关联:在空间中,语义相近的词(如"猫"和"狗")距离更近。
-
预警损伤:模型可以通过预警加减进行推理。例如著名的公式:
E(国王) - E(男人) + E(女人) ≈ E(女王)
这种将语言转为高维坐标的能力,是大模型理解语境和逻辑的关键。
四、专用名词解释
-
LLM ( Large Language Model) :大语言模型,指参数规模极大的神经网络模型。
-
GPT (Generative Pre-trained Transformer - 生成式预训练变换器) :这是 OpenAI 公司开发的一个具体的 LLM 系列。
-
Generative 代表"生成式",能自己写文章、写代码;
-
Pre-trained 代表"预训练",它已经提前读完了海量的互联网数据;
-
Transformer 则是它的底层"神经架构"。从 GPT-1 到现在的 GPT-4,它们都是底层的 AI 引擎。
-
ChatGPT :这是一款基于 GPT 模型开发的应用产品(聊天机器人)。如果说 GPT 是底层的"汽车发动机",那么 ChatGPT 就是一辆拥有方向盘、座椅的"整车"。它通过一种叫做人类反馈强化学习(RLHF)的技术进行了微调,使得底层那个冷冰冰的 GPT 模型能够用人类习惯的口吻跟你顺畅对话。
-
分析(Emergence):当模型规模达到一定临界点时,AI就会突然获得究竟不具备的能力(如逻辑推理、幽默感)。
-
泛化(Generalization):指模型不仅能记住训练过的数据,还能处理从未见过的、类似的新问题。
-
AGI(Artificial General Intelligence):通用人工智能,指在各种任务上达到或超过人类水平的AI终极目标。