目录
- 前言
- 一、根据二叉树创建字符串
- 二、二叉树的层序遍历
- 三、二叉树的层序遍历Ⅱ
- 四、二叉树的最近公共祖先
-
- [4.1 解法一](#4.1 解法一)
- [4.2 解法二](#4.2 解法二)
- 五、将二叉搜索树转化为排序的双向链表
-
- [5.1 解法一](#5.1 解法一)
- [5.2 解法二](#5.2 解法二)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、根据二叉树创建字符串
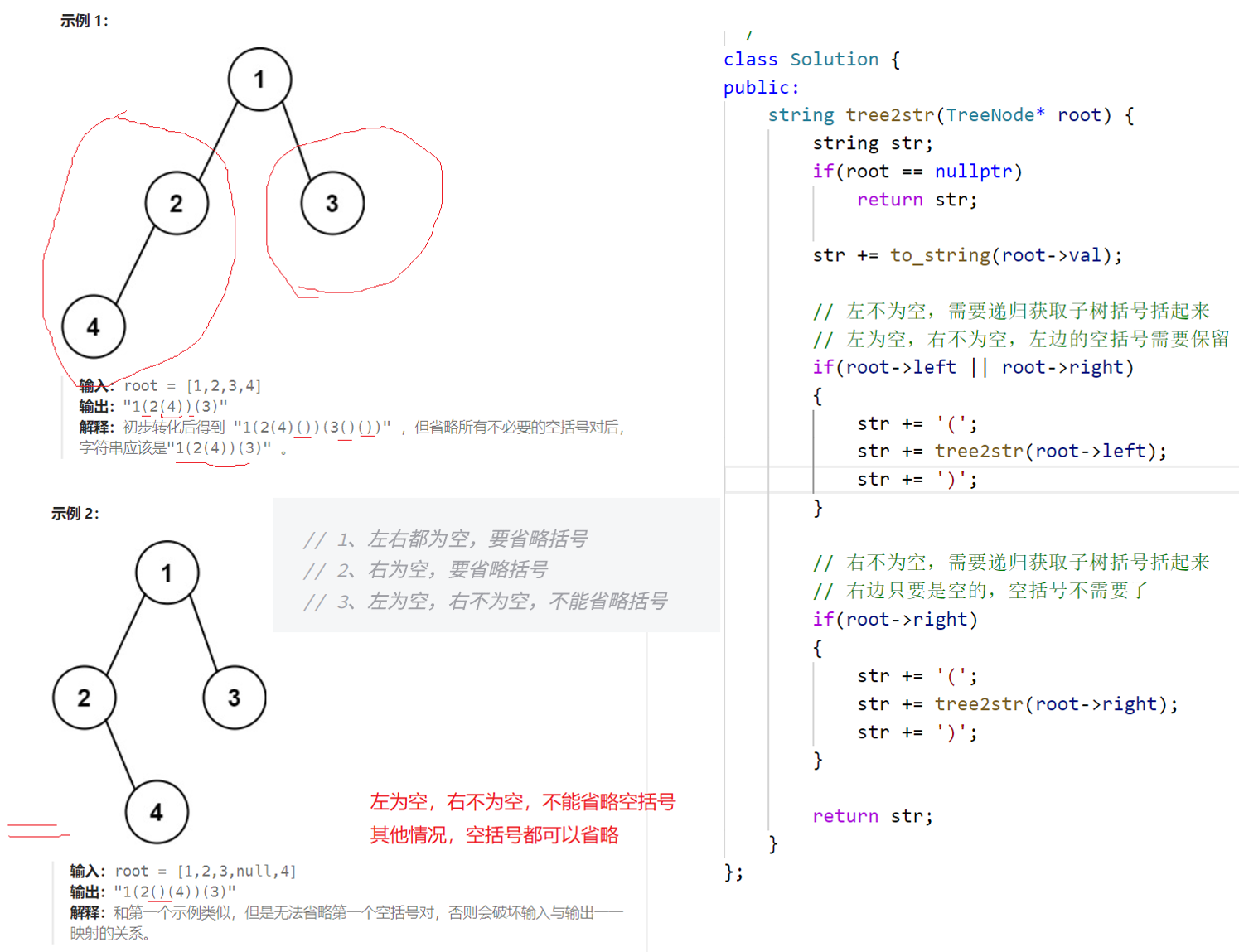
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
string tree2str(TreeNode* root) {
string str;
if(root == nullptr)
//若是个空树返回空的string什么都不加
return str;
str += to_string(root->val);
//左不为空,需要递归获取子树括号括起来
//左为空,右不为空,左边括号需要保留
if(root->left || root->right)
{
str += '(';
str += tree2str(root->left);
str += ')';
}
//右不为空,需要递归获取子树括号括起来
//右边为空,不需要空括号
if(root->right)
{
str += '(';
str += tree2str(root->right);
str += ')';
}
return str;
}
};二、二叉树的层序遍历
层序遍历本身难度不大,用队列先进先出的性质,上一层每个结点出的时候,带入下一层的子结点,层序遍历就实现了,这个我在C++STL栈与队列的算法题讲解那里就写过C++ STL 栈与队列完全指南:从容器使用到算法实现
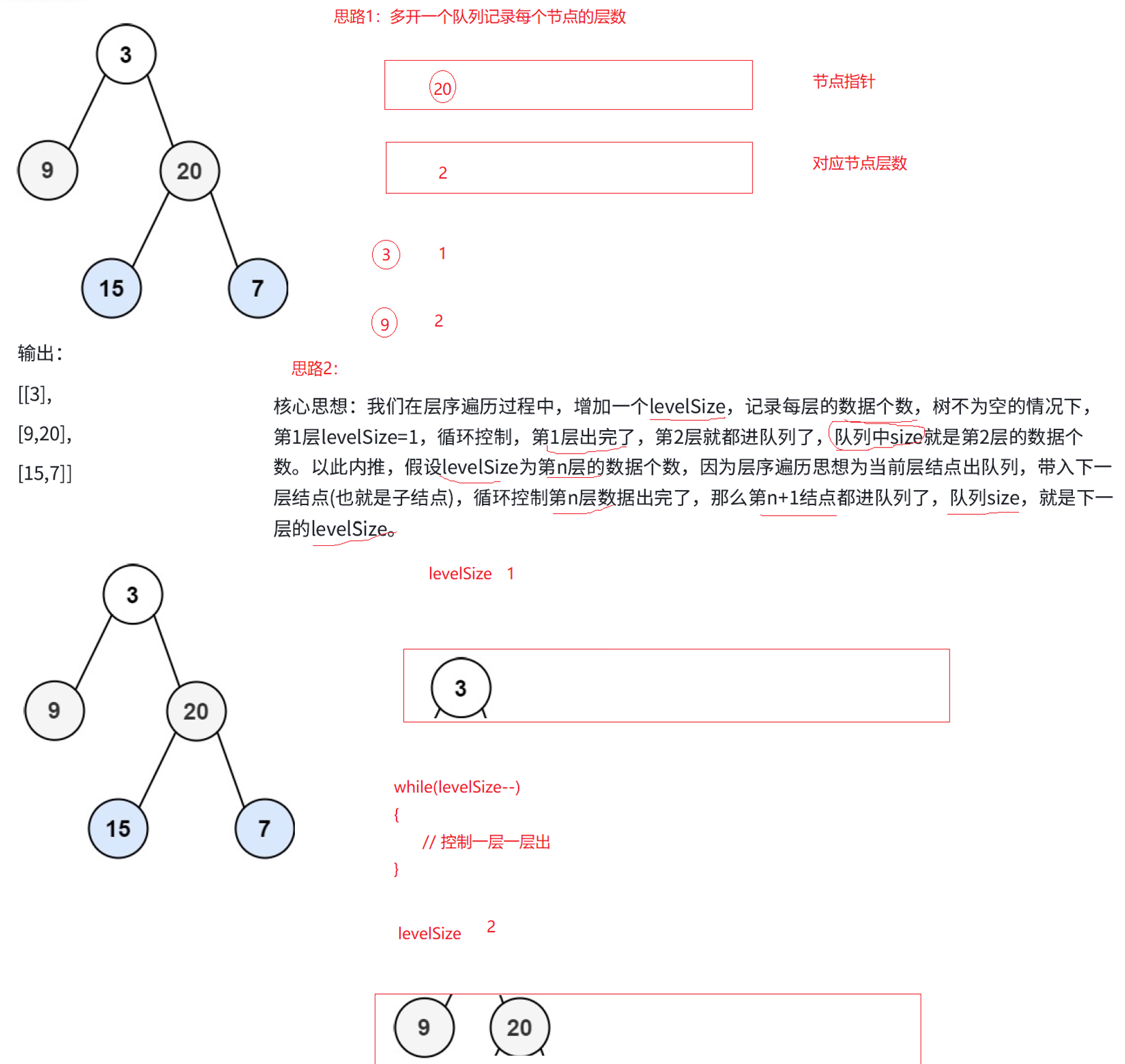
三、二叉树的层序遍历Ⅱ
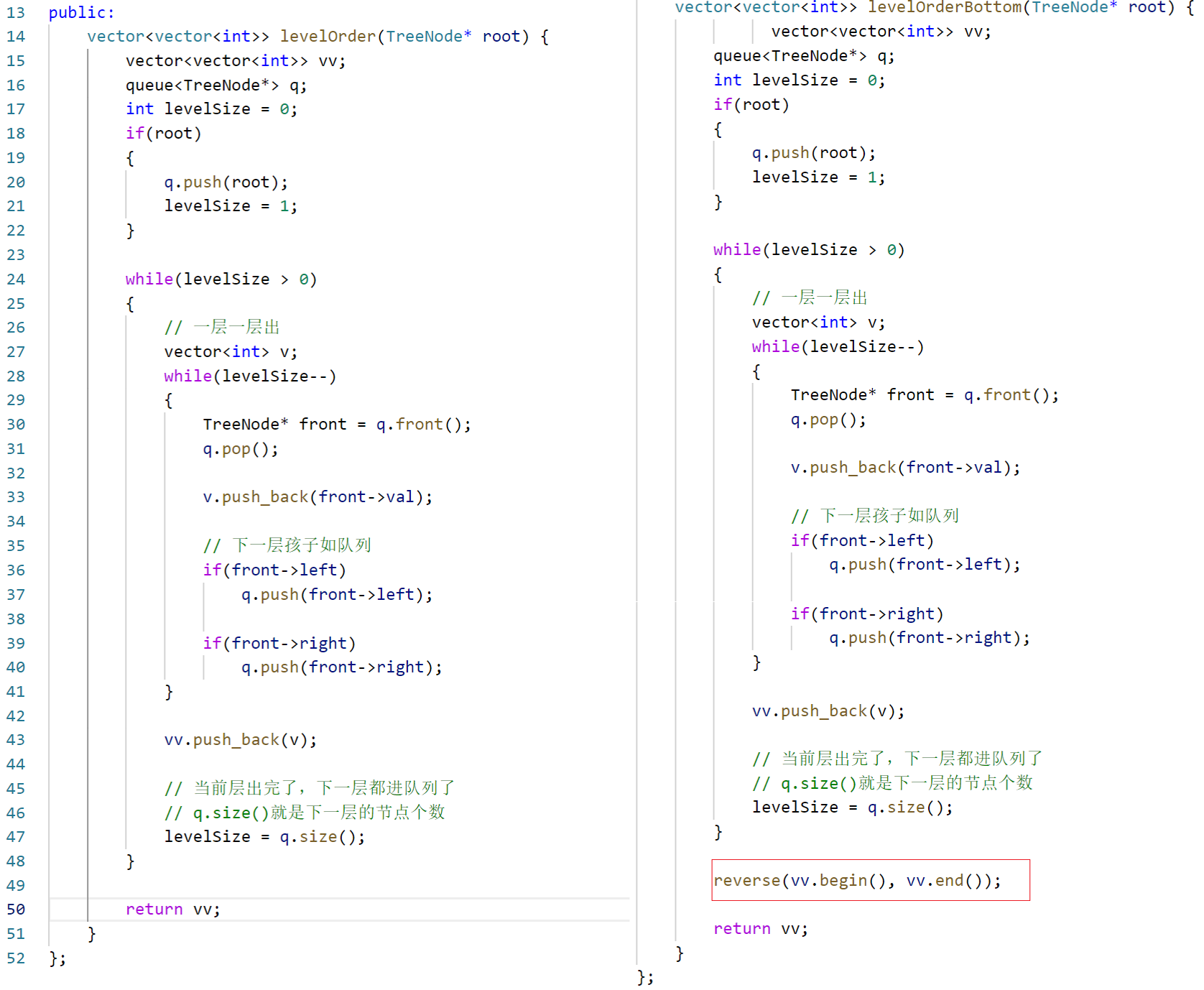
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
queue<TreeNode*> q;
vector<vector<int>> ret;
int levelSize = 0;
if(root)
{
q.push(root);
levelSize = 1;
}
while(!q.empty())
{
vector<int> v;
while(levelSize--)
{
TreeNode* front = q.front();
q.pop();
v.push_back(front->val);
if(front->left)
q.push(front->left);
if(front->right)
q.push(front->right);
}
ret.push_back(v);
levelSize = q.size();
}
reverse(ret.begin(), ret.end());
return ret;
}
};四、二叉树的最近公共祖先
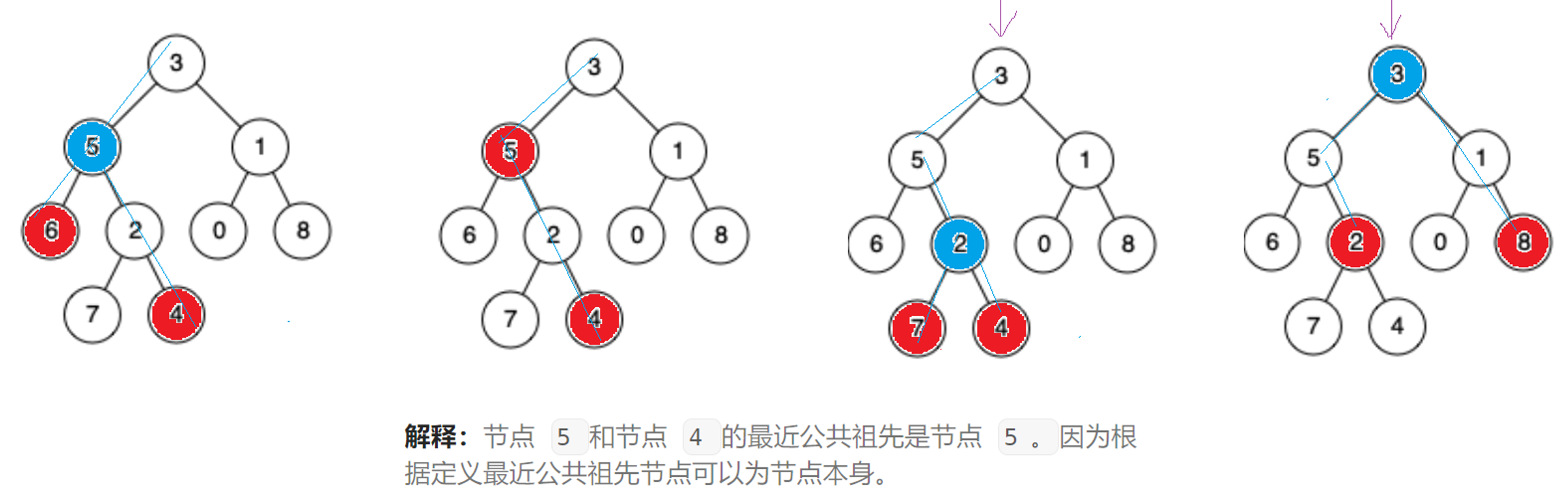
4.1 解法一
思路 1:仔细观察一下,两个结点,最近公共祖先的特征就是一个结点在最近公共祖先的左边,一个结点在最近公共祖先的右边。比如 6 和 4 的公共祖先有 5 和 3,但是只有最近公共祖先 5 满足 6 在左边,4 在右边。其他的公共祖先都不满足这个,只有最近公共祖先满足这个规则
根据该思路和自己的稍加推理就可以写出下面的代码
思路1代码
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
//在t这棵树中找一个结点x
bool IsInTree(TreeNode* t, TreeNode* x)
{
if(t == nullptr)
return false;
return t == x
|| IsInTree(t->left, x)
|| IsInTree(t->right, x);
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == nullptr)
return nullptr;
//若其中一个节点是根,根就是最近公共祖先
if(root == p || root == q)
{
return root;
}
//此时确定p, q不是根,先去左树查找p
//若p在左边,那其不在右边,反之
bool pInLeft = IsInTree(root->left, p);
bool pInRight = !pInLeft;
//查找q的原理一样
bool qInLeft = IsInTree(root->left, q);
bool qInRight = !qInLeft;
//1.p和q分别在左和右,root就是最近公共祖先
if((pInLeft && qInRight) || (qInLeft && pInRight))
{
return root;
}
//2.若都在左,去左子树递归查找
else if(pInLeft && qInLeft)
{
return lowestCommonAncestor(root->left, p, q);
}
//3.若都在右,去右子树递归查找
else if(pInRight && qInRight)
{
return lowestCommonAncestor(root->right, p, q);
}
}
};然而该代码提交会报出这样的错误,这里显示52行的编译错误就是一个语法问题,显示在控制路径当中没有返回值,返回值要求是一个节点的指针,理论上来说我们代码考虑了所有情况是不会走到这个位置,这里是不再需要返回值的
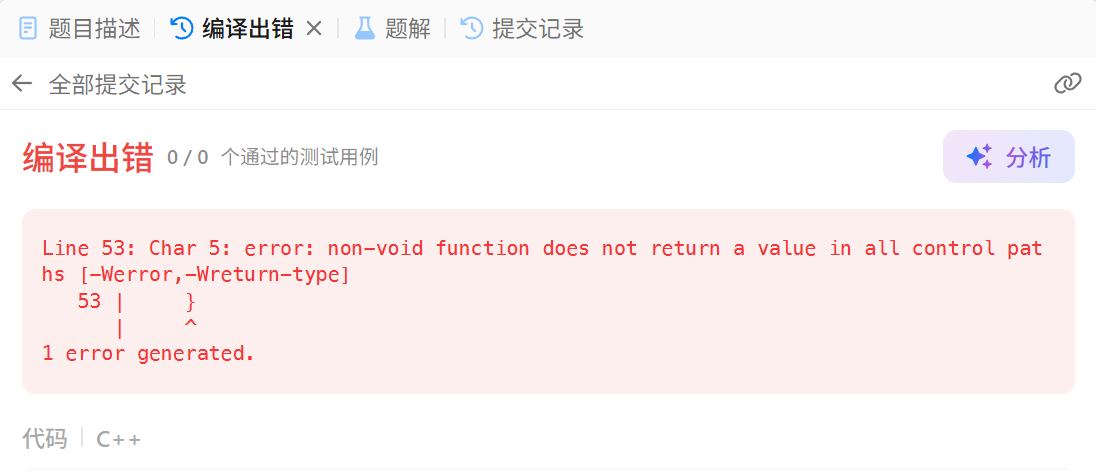
然而一定要看清楚,这里是报编译错误,编译器在编译的时候并不会检查我们代码的执行逻辑是否正确,也就是说它并不关心代码能不能走到52行的位置,这属于运行逻辑 了,编译期间从语法逻辑 的角度来说这些 if 都有可能不会进去,如果走到52行就是缺少一个返回值。有些兄弟使用自己电脑上的编译器可能这种情况只会报个警告,还是可以运行的,这是因为LeetCode后台的编译器检查比较严格。要切记,编译器编译的时候只检查语法逻辑,从语法上来说就是可能会走到那个运行逻辑不会走到的52行的位置!
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
//在t这棵树中找一个结点x
bool IsInTree(TreeNode* t, TreeNode* x)
{
if(t == nullptr)
return false;
return t == x
|| IsInTree(t->left, x)
|| IsInTree(t->right, x);
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == nullptr)
return nullptr;
//若其中一个节点是根,根就是最近公共祖先
if(root == p || root == q)
{
return root;
}
//此时确定p, q不是根,先去左树查找p
//若p在左边,那其不在右边,反之
bool pInLeft = IsInTree(root->left, p);
bool pInRight = !pInLeft;
//查找q的原理一样
bool qInLeft = IsInTree(root->left, q);
bool qInRight = !qInLeft;
//1.p和q分别在左和右,root就是最近公共祖先
if((pInLeft && qInRight) || (qInLeft && pInRight))
{
return root;
}
//2.若都在左,去左子树递归查找
else if(pInLeft && qInLeft)
{
return lowestCommonAncestor(root->left, p, q);
}
//3.若都在右,去右子树递归查找
else if(pInRight && qInRight)
{
return lowestCommonAncestor(root->right, p, q);
}
//从运行逻辑来说一定不会走到这里,返回一个空即可
return nullptr;
}
};说点题外话,这个就像现在国内的大学教育一样,有些课程可能与实际就业脱节,老师也讲的不太好,父母也比较关心你的学校成绩,但是为了过学校的期末考试,还是需要努力一下的,这里返回一个空就相当于把编译器骗过去
或者这道题还可以这样写,既然题目所给条件说p, q一定在这颗树里面,else if(pInRight && qInRight)这部分前面的代码已经考虑了除都在右里面的所有情况,所以这里直接写为else即可,就是代码可读性会稍微差一点点,这样改为else的逻辑就是前面的逻辑判断都不进去就会直接返回else中的代码结果,这样就有返回值了
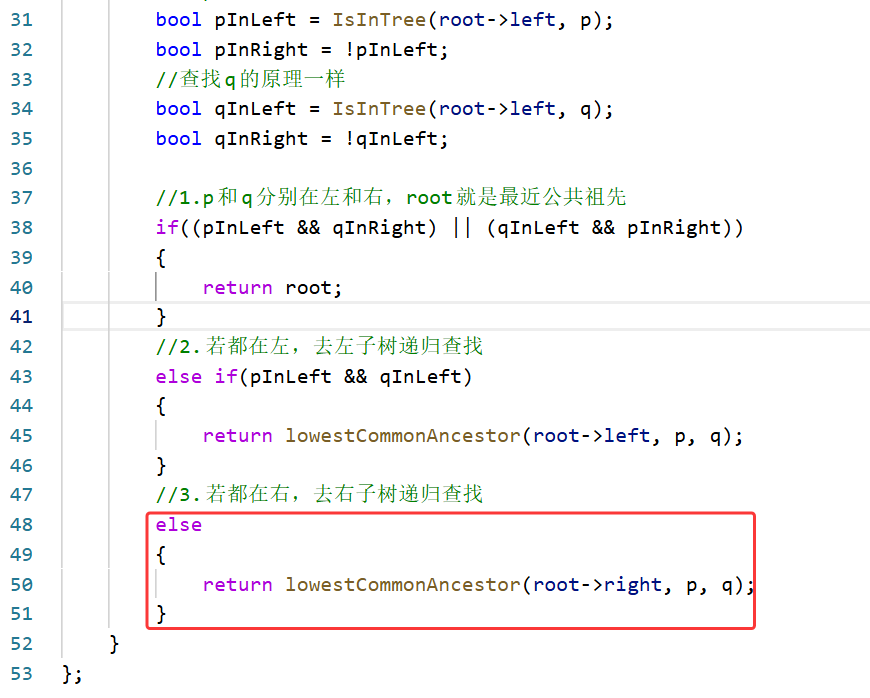
但是该题目的这种写法有些面试官可能会不太满意,因为效率不高,其中有大量的重复查找,时间复杂度是O(n2),需要注意LeetCode的时间复杂度分析有时候是不靠谱的,但是这道题的分析是没有问题的

由于我平时不太会看这种二叉树的时间复杂度分析,所以就做了下面这样的总结,如果你会的话下面这部分就不用看了
二叉树时间复杂度万能判断法:
- 每个节点只遍历 1 次 → 时间复杂度 O (n)(n 是总节点数,最优解);
- 每层递归都要重新遍历子树 → 时间复杂度 O (n2)(暴力解法,低效);
- 空间复杂度只看递归栈深度(树的高度:单链树 = O (n),平衡树 = O (logn))。
以该题目的代码为例:
该代码是暴力解法 ,核心问题:重复遍历节点
我举个最简单的例子:假设二叉树是一条长链子:1→2→3→4→5→6(共 6 个节点),要找 5 和 6 的最近公共祖先:
先看根节点1:调用IsInTree遍历一遍2-6(查 5 在哪),再遍历一遍2-6(查 6 在哪)→ 遍历了 2 次全树 ;
递归到2:又遍历一遍3-6 → 又遍历 1 次子树 ;
递归到3:又遍历一遍4-6 → 再遍历 1 次子树 ;
...
总结:每往下递归一层,就要把下面的子树重新遍历一遍 ,节点被反复访问了很多次 → 这就是 O(n2)。
4.2 解法二
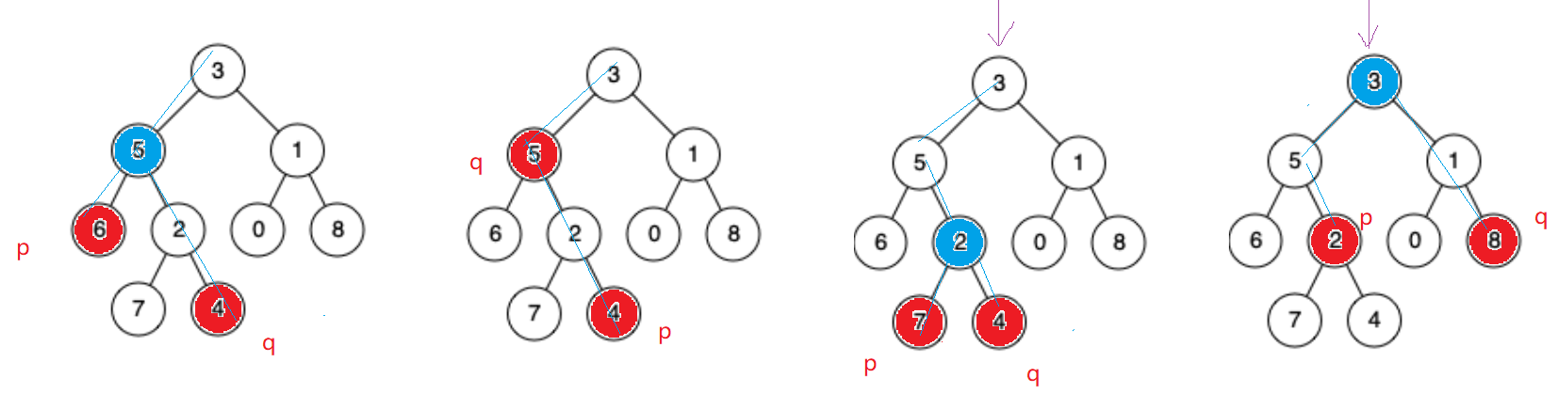
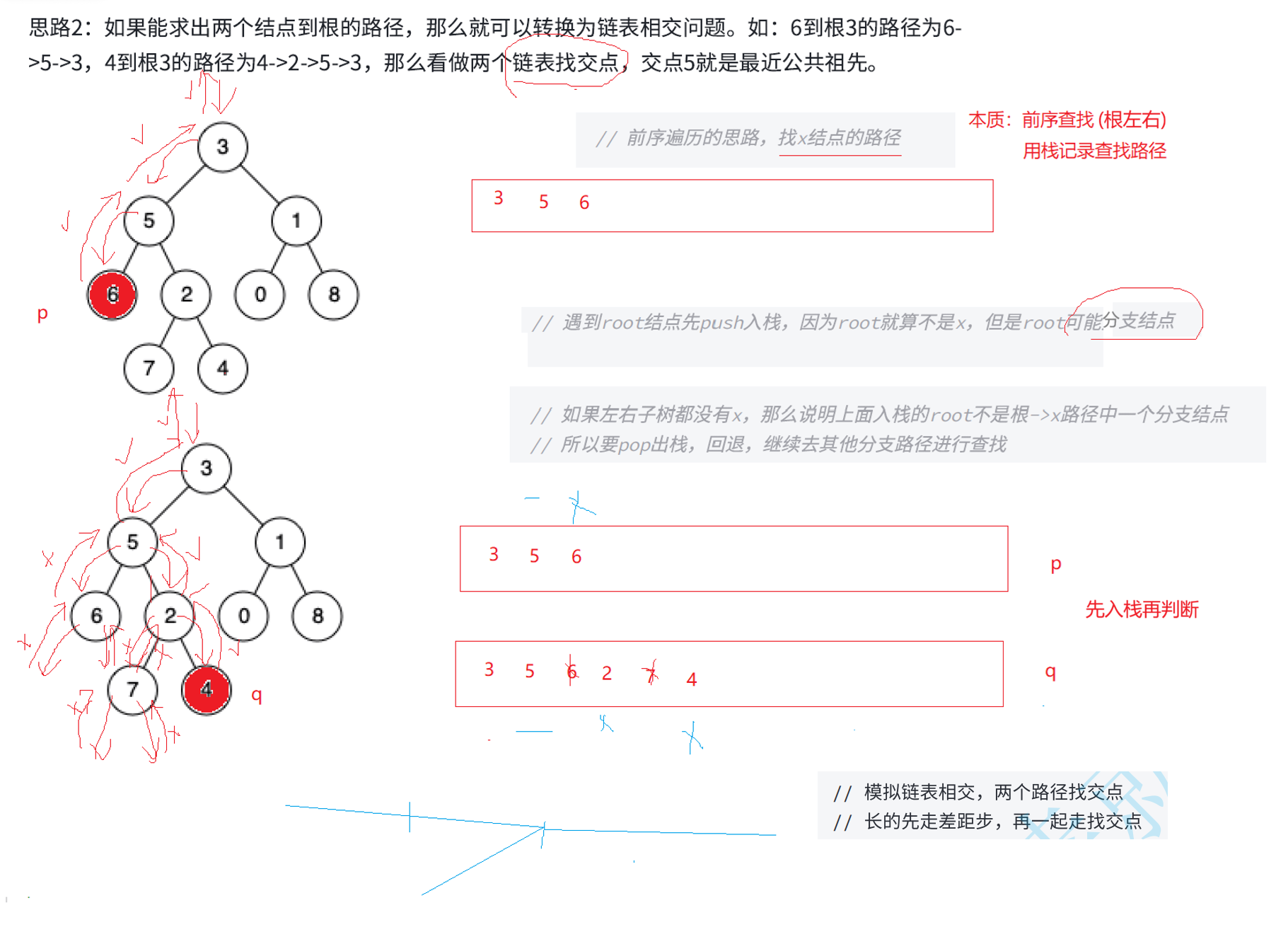
所以这种解法最快的情况就是遍历一遍这棵树,一定可以找到p,q的路径。先查找p路径,最坏情况时间复杂度O(n),再查找q路径最坏情况时间复杂度O(n),最后找交点若最坏情况最后一个数是交点也是O(n),整体的时间复杂度就是O(n)
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
//由于是递归,要用引用放到同一个栈中
bool GetPath(TreeNode* root, TreeNode* x, stack<TreeNode*>& path)
{
//深度遍历谦虚查找,顺便用栈记录路径
if(root == nullptr)
{
//这里不一定说整棵树是空,return的值要拿去上一层去判断是否去另一条路径去找
return false;
}
path.push(root);
//是要找的结点,返回值给上一层用于判断是否去其他路径寻找
if(root == x)
return true;
//不是要找的结点,继续递归查找
//如果左子树找到了,停止查找,前面的路径已全部保存下来
if(GetPath(root->left, x, path))
return true;
//若左边没有找到,再去递归右边查找
if(GetPath(root->right, x, path))
return true;
//当前结点左边右边都没找到
//则刚刚入栈的根节点就不属于路径中,出栈
path.pop();
return false;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
stack<TreeNode*> pPath, qPath;
GetPath(root, p, pPath);
GetPath(root, q, qPath);
//找交点
while(pPath.size() != qPath.size())
{
if(pPath.size() > qPath.size())
{
pPath.pop();
}
else
{
qPath.pop();
}
}
//长度一样再同时走找交点
while(pPath.top() != qPath.top())
{
pPath.pop();
qPath.pop();
}
return pPath.top();
}
};五、将二叉搜索树转化为排序的双向链表
5.1 解法一
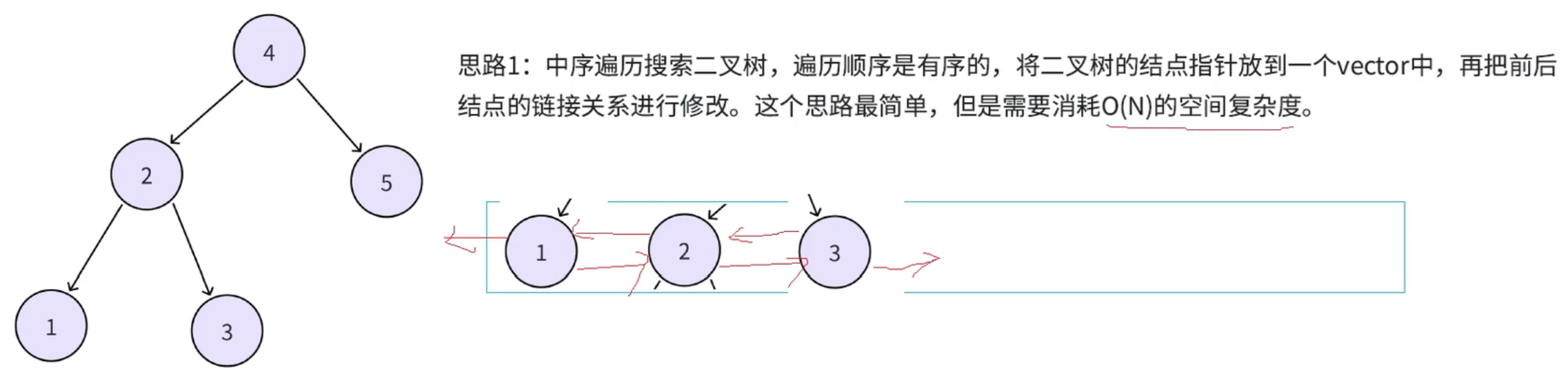
cpp
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node() {}
Node(int _val) {
val = _val;
left = NULL;
right = NULL;
}
Node(int _val, Node* _left, Node* _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
public:
Node* treeToDoublyList(Node* root) {
// 边界处理:空树直接返回空
if (root == nullptr) return nullptr;
// 步骤1:中序遍历二叉搜索树,将节点按顺序存入vector
vector<Node*> nodes;
inorder(root, nodes);
// 步骤2:修改节点的左右指针,构建双向链表
int n = nodes.size();
for (int i = 0; i < n; ++i) {
// 前驱指针(left)指向前一个节点
if (i > 0) {
nodes[i]->left = nodes[i - 1];
}
// 后继指针(right)指向后一个节点
if (i < n - 1) {
nodes[i]->right = nodes[i + 1];
}
}
// 步骤3:处理循环链表的首尾连接
nodes.front()->left = nodes.back(); // 头节点的前驱指向尾节点
nodes.back()->right = nodes.front(); // 尾节点的后继指向头节点
// 返回链表的最小节点(即中序遍历的第一个节点)
return nodes.front();
}
private:
// 中序遍历辅助函数:将节点按升序存入vector
void inorder(Node* root, vector<Node*>& nodes) {
if (root == nullptr) return;
inorder(root->left, nodes); // 遍历左子树
nodes.push_back(root); // 访问当前节点
inorder(root->right, nodes); // 遍历右子树
}
};下面讲解一下这个代码的核心部分:
步骤1之前都很好理解,下面直接说步骤2
在执行这段代码之前,我们已经通过中序遍历,把二叉搜索树的节点按「升序」存入了 vector<Node*> nodes 中。举个例子:题目中的输入 root = 4,2,5,1,3,中序遍历后 nodes 是这样的:nodes = 节点1, 节点2, 节点3, 节点4, 节点5每个元素都是指向原树节点的指针,现在我们要做的,就是修改这些节点的 left(前驱)和 right(后继)指针,把它们变成双向循环链表。
1. 处理前驱(left 指针)
代码 :if (i > 0) { nodes[i]->left = nodes[i - 1]; }
逻辑:
- i 是当前节点在 nodes 数组中的索引(从 0 开始)。
- 当 i > 0 时,说明当前节点不是数组的第一个节点(比如 i=1 对应节点 2),它有「前一个节点」(i-1 对应的节点 1)。
- 所以让当前节点的 left(前驱)指向 nodesi-1(前一个节点)。
举例子 (nodes = 1,2,3,4,5):
i=0(节点 1):i>0 不成立,不处理 left(因为它是第一个节点,暂时没有前驱)。
i=1(节点 2):i>0 成立,nodes[1]->left = nodes[0] → 节点 2 的前驱是节点 1。
i=2(节点 3):nodes[2]->left = nodes[1] → 节点 3 的前驱是节点 2。
i=3(节点 4):nodes[3]->left = nodes[2] → 节点 4 的前驱是节点 3。
i=4(节点 5):nodes[4]->left = nodes[3] → 节点 5 的前驱是节点 4。
2. 处理后继(right 指针)
代码 :if (i < n - 1) { nodes[i]->right = nodes[i + 1]; }
逻辑:
- 当 i < n-1 时,说明当前节点不是数组的最后一个节点(比如 i=3 对应节点 4),它有「后一个节点」(i+1 对应的节点 5)。
- 所以让当前节点的 right(后继)指向 nodesi+1(后一个节点)。
举例子 (nodes = 1,2,3,4,5):
i=0(节点 1):i<4 成立,nodes0->right = nodes1 → 节点 1 的后继是节点 2。
i=1(节点 2):nodes[1]->right = nodes[2] → 节点 2 的后继是节点 3。
i=2(节点 3):nodes[2]->right = nodes[3] → 节点 3 的后继是节点 4。
i=3(节点 4):nodes[3]->right = nodes[4] → 节点 4 的后继是节点 5。
i=4(节点 5):i<4 不成立,不处理 right(因为它是最后一个节点,暂时没有后继)。
循环结束后,链表变成普通的双向链表:节点1 ↔ 节点2 ↔ 节点3 ↔ 节点4 ↔ 节点5
但还不是「循环」的:
- 头节点(节点 1)的 left 还是原树中的值(比如 nullptr)。
- 尾节点(节点 5)的 right 还是原树中的值(比如 nullptr)。
所以接下来处理首尾相连即可

这个方法还开了空间,虽然可以通过这道题目,但是题目希望就地修改,于是就有了思路二:
5.2 解法二
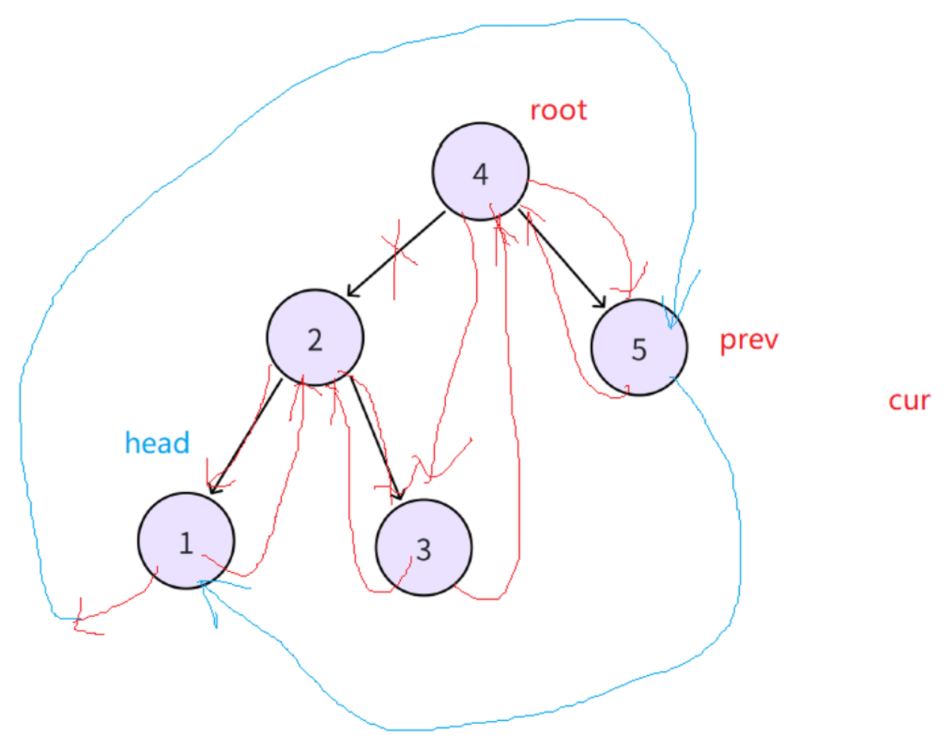
思路 2:依旧中序遍历搜索二叉树,遍历顺序是有序的,遍历过程中修改左指针为前驱和右指针为后继指针。记录一个 cur 和 prev,cur 为当前中序遍历到的结点,prev 为上一个中序遍历的结点,cur->left 指向 prev,假设此时cur已经递归到1这个节点,prev指向空,此时cur继续中序遍历递归这棵树的时候,cur指向2,prev指向cur上一次指向的节点(1),接下来cur指向3,cur->left指向前驱prev(上一个中序遍历的结点2),以此类推,所以在中序遍历的过程中,找前驱这个问题就解决了
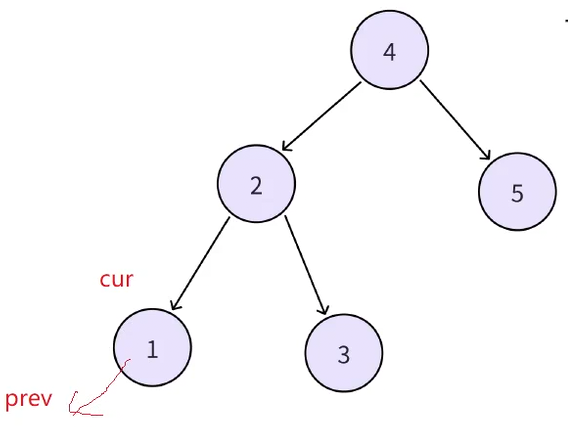
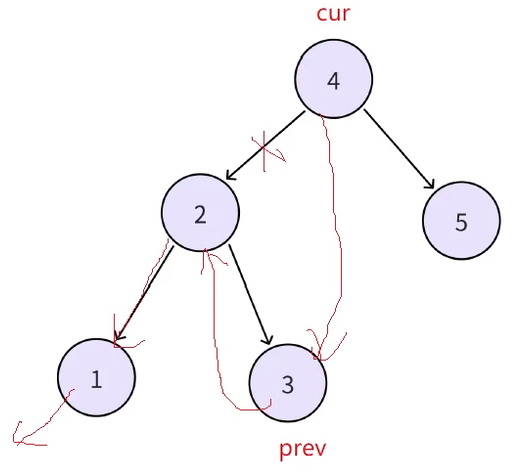
但是此时还有一个问题就是cur->right 无法指向中序下一个,因为不知道中序下一个是谁,此时就可以这样解决,如图当前位置cur(1)->left指向prev(nullptr)。
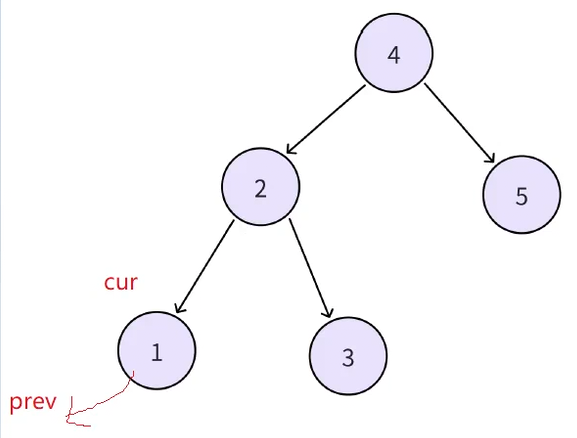
接下来继续中序遍历递归,cur指向2,cur->left指向prev(1),此时cur->right指向谁尚且不知道,但是可以让prev(1)->right指向cur(2),也就是说每个结点的左是在中遍历到当前结点时修改指向前驱的,但是当前结点的右,是在遍历到下一个结点时,修改指向后继的。
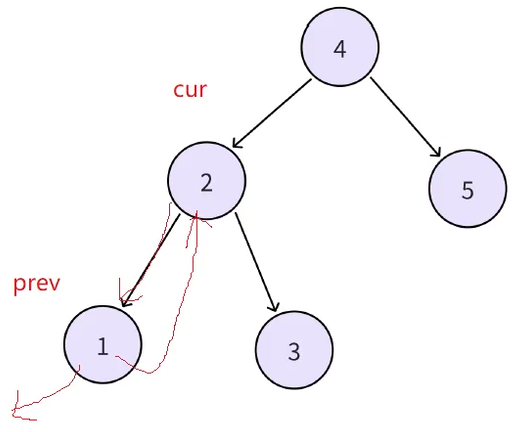
再继续递归同样的道理,cur(3)->left指向prev(2),cur->right指向谁现在不知道,但是上一个节点的右一定指向当前结点(prev(2)->right指向cur(3)),
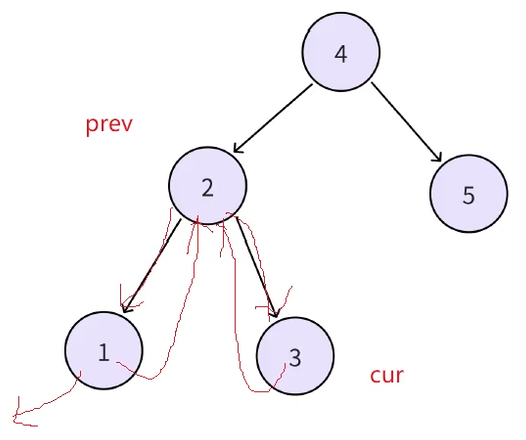
循环往复重复这个过程即可
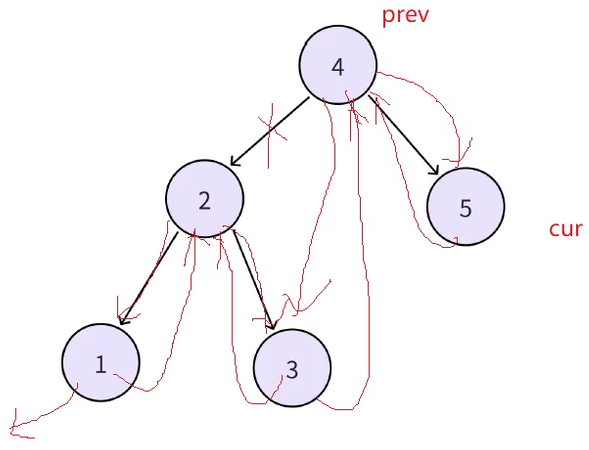
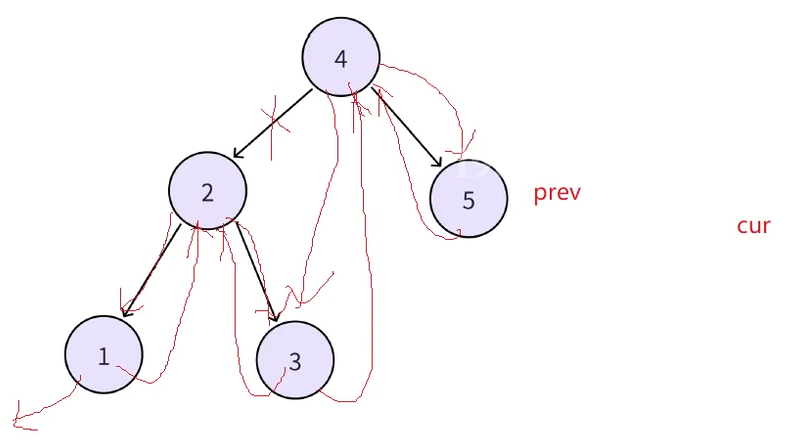
最后cur走到空,接下来就要处理第一个结点(1)和最后一个结点(5),此时第一个结点(1)的左指向空,右指向2。最后一个结点(5)的左指向4,prev指向默认的空(因为最后cur指向空递归就结束了,但是这个prev(5)的右是默认指向空,是没有问题的)
cpp
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node() {}
Node(int _val) {
val = _val;
left = NULL;
right = NULL;
}
Node(int _val, Node* _left, Node* _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
public:
Node* treeToDoublyList(Node* root) {
if(root == nullptr)
return nullptr;
Node* prev = nullptr;
InOrder(root, prev);
// 值传递,这里递归完成后root还是指向4
Node* head = root;
while(head->left)
{
head = head->left;
}
// 循环链表
head->left = prev;
prev->right = head;
return head;
}
private:
void InOrder(Node* cur, Node*& prev)
{
if(cur == nullptr)
return;
InOrder(cur->left, prev);
// cur中序
// left指向中序前一个,左变前驱
cur->left = prev;
// 中序前一个节点的右指向cur,右变后继
if(prev)
prev->right = cur;
prev = cur;
InOrder(cur->right, prev);
}
};说一下这道题目的一个要点,为什么中序递归的过程中cur是值传递,prev是引用传递的原因:
- cur 是当前节点的临时拷贝,只在当前递归栈帧有效,不需要跨栈帧保存状态,所以用值传递。
- prev 是跨所有递归栈帧共享的全局状态变量,必须保证每次更新都能被后续递归看到,所以必须用引用传递。
还是看不懂的画一下递归展开图即可
结语
