论文总结
开发了一个面向人类衰老和健康的生成式深度学习框架 AURORA(AI Unification and Reconstruction of Omics Reassembly Atlas),利用单一的常规体检数据或面部图像,即可跨模态生成涵盖转录组、代谢组、微生物组等7种模态的全景虚拟图谱。经部分配对的少量数据训练和在超42万人的真实世界多队列中验证,AURORA不仅构建了高精度的多模态衰老时钟与疾病预测模型,更实现了个性化药物与生活方式的"数基扰动",为精准医疗和抗衰老干预提供了革命性的"数字孪生"方案。
摘要
理解衰老和复杂疾病需要多样化的数据,涵盖从分子画像到影像和常规临床检测。然而,大多数多组学数据集仅测量部分模态,且被批次效应所干扰。本文介绍AURORA(组学重组图谱的AI统一与重建),这是一个生成式深度学习平台,整合了七种模态(包括转录组学、代谢组学、微生物组、3D和热面部成像以及临床实验室检测),涵盖425,258个个体的581,763个样本。AURORA协调批次效应,重建不同模态缺失数据,实现高精度的多模态衰老时钟和疾病风险预测器。它还支持个性化的计算机模拟扰动分析,预测干预和药物反应,并通过纵向队列验证。作为概念验证,我们提供了一个原型AI代理,将单输入模态转换为用户和研究人员的多模态报告。AURORA共同将非侵入性输入与全面的衰老生物标志物和治疗发现相结合。
引言
衰老和复杂疾病通过相互关联的生物过程表现出来。大规模研究建立了多组衰老时钟和复合生物标志物面板,捕捉了生物衰老的多方面,为评估长寿干预和疾病风险提供了定量终点。1,2 与此同时,机器学习方法越来越多地应用于药物定位和衰老干预发现,使得从大量生物医学数据集和分子特征中识别候选化合物成为可能。3 尽管人群层面已有许多健康指南,但对于个体而言,"N = 1"的健康轨迹和干预措施可能与指南不同。为了全面评估个性化衰老和疾病轨迹并设计个性化干预和治疗,涵盖分子特征、微生物特征、生理特征11和表型特征12至14的多维画像1,2,4--6具有巨大潜力。然而,这些多模态数据成本高昂,且有时用于常规监测和个性化治疗时具有侵入性。一个实际目标是从稀疏的测量(如常规血液检查或非侵入性面部图像)推断出丰富多维的健康特征,并利用该特征支持个别化的风险评估和干预测试。实现这一目标将使公众能够获得易于获取的健康摘要,使研究人员能够将表型与分子通路连接起来,并帮助药物开发者模拟个性化化合物效应(见图1A)。这一直是多维数据生成的长期承诺,但尽管拥有大量可用数据,但由于大多数多模态数据碎片化:不同模态配对不完全,1,3--7,15 受缺失的模态及平台和批次效应影响影响,且难以跨人群推广。因此,如何将碎片化的多维数据统一为通用表示,并在计算机模拟中生成完整的模态轮廓,用于个体化风险评估及利用计算机扰动发现个性化管理策略或药物反应,仍是一个悬而未决的挑战16(见图1A)。本文介绍AURORA(组学重组图谱的AI统一与重建),这是一个基于7种生物和表型模态训练的生成框架,来自超过425,000名个体。AURORA 实现了高精度的跨模态统一与生成;构建个性化数字孪生,精炼衰老、健康和疾病的轨迹;并预测候选干预的反应(见图1B)。计算机扰动中的 AURORA 使得大型人类队列中药物反应的分层成为可能。更广泛地说,AURORA 建立了将零散生物医学观察转化为可扩展的生物学景观的范式,带来个性化洞见,应用范围涵盖生物标志物发现、治疗开发和临床精准医疗。
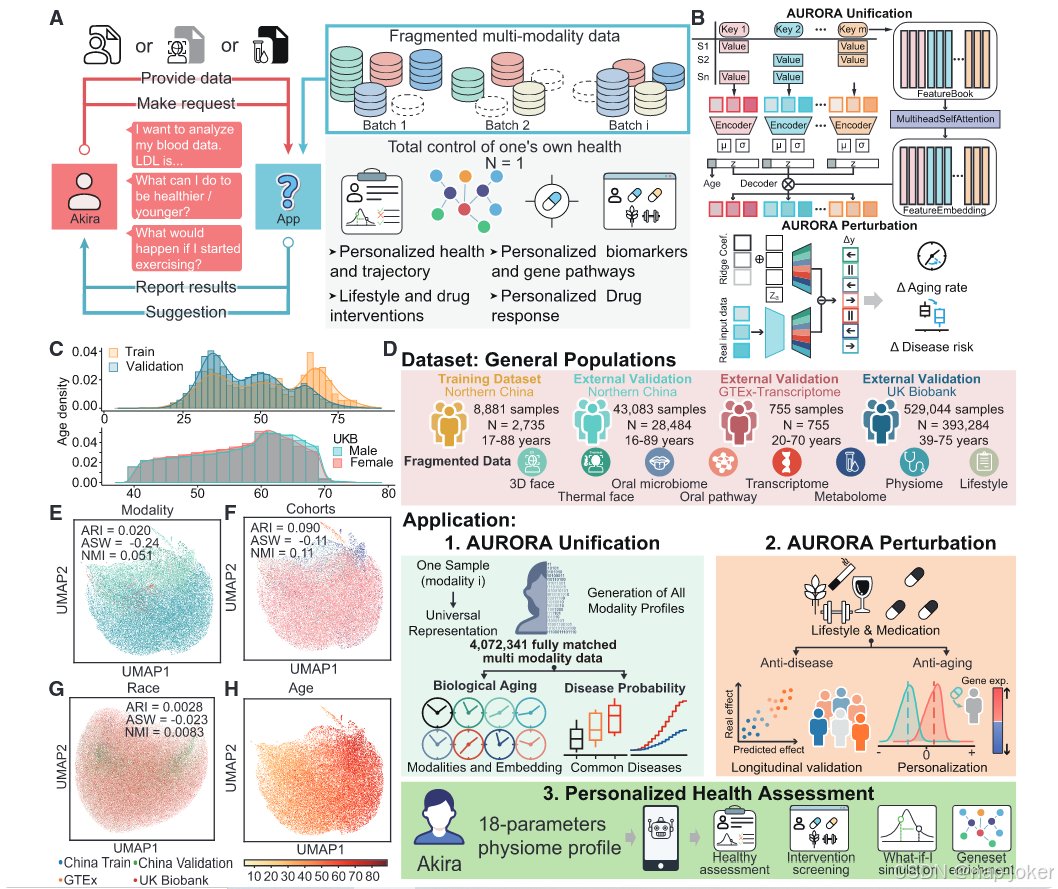
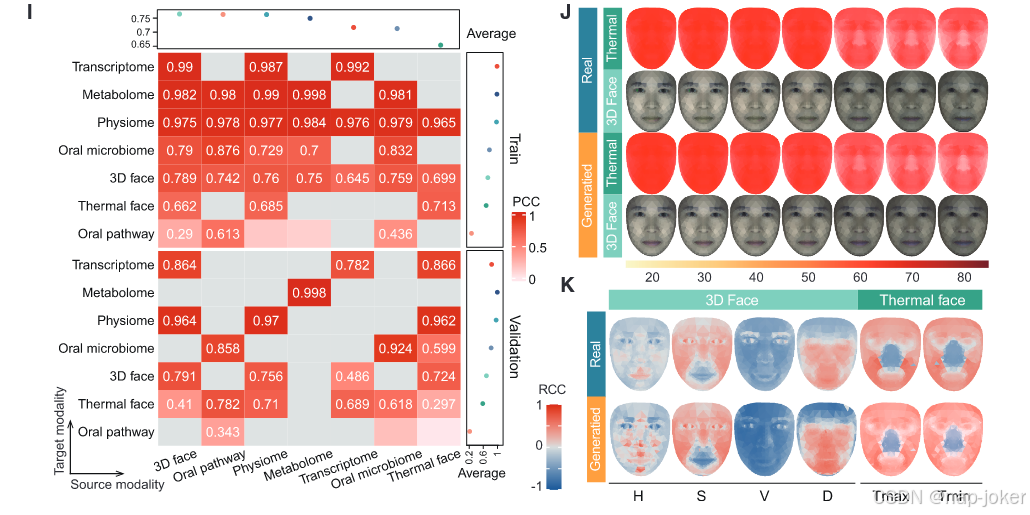
图1。AURORA 通过生成式深度学习实现了个性化多模态数据统一(A)长期以来对多维数据用于个性化衰老和疾病风险评估及干预的承诺,以及研究人员、生物技术和制药公司对分子机制、治疗靶点发现和药物定位的期待,仍因数据碎片化和批次效应而难以实现,导致多模态数据缺乏个性化的普遍表示。(B) AURORA 统一架构,旨在协调批次效应并统一碎片化数据。输入的多模态数据被分为两部分,分别是离散特征项和连续值。模型首先为每个特征建立初始化嵌入,并通过多头自我注意力模块学习最终嵌入,其中一个维度专注于年龄。该值部分由模型模态特定变分编码器处理,以获得低维样本嵌入。然后,样本和特征嵌入的内积作为解码模块的第一层,用于重建训练和验证集中的每个模态数据。AURORA 扰动架构通过扰动输入配置文件或潜空间来模拟模态、生活方式和药物变化的影响。键、特征或令牌;Sn,样本n;每个潜在维度的均值和标准差μ和σ 1维;年龄,第一维;z,其余48个维度;Pert,扰动;系数,系数。(C) 密度图显示训练和验证数据集中的年龄分布,除UKB(上层)和UKB数据集(底部)外。(D) AURORA 训练流程及统一与扰动算法的应用,用于模拟个性化干预效果,以及分子机制、治疗靶点发现和药物重新定位。(E--H)UMAP 样本嵌入可视化,按来源模态(E)、队列(F)、种族(G)和年龄(H)着色。ASW、ARI 和 NMI 均有标记。(I) 每个来源模态对的生成数据与真实数据之间的整体 PCC。平均 PCC 显示在顶部和右侧面板。(J) 连续年龄组生成的及真实三维人脸和热面孔。生成的人脸分别来源于非三维(平均,n = 5,231)或非热成像(平均,n = 7,100)多模态剖面。(K) 面部图像年龄与面部特征之间的 RCC。H,色相;S,饱和度;V,值;Tmax,Z分数尺度最高温度;Tmin,Z分数尺度最低温度
结果
AURORA框架------AURORA统一与AURORA扰动
AURORA 包含两个模块:AURORA 统一和 AURORA 扰动。我们设计了 AURORA Unification,这是一个生成式深度学习框架,用于处理不同模态的离散签名条目和数值。该模型为每个特征初始化一个"特征书",将特征文本视为非顺序标记(区别于计算机视觉和自然语言处理)。标记通过多元自注意层相互作用,学习最终的特征嵌入。特定的编码器处理每个模态,将数据点建模为低维嵌入。模态分类器随后通过对抗学习对齐不同模态的样本嵌入,其中一个维度解开以表示年龄,其他维度调整以捕捉混杂因素。解码器利用统一样本嵌入和特征嵌入的内积作为第一层,通过多层感知器(MLP)连接,生成类似输入数据的模拟数据(见图1B)。随后,利用生成模型的力量,我们设计了AURORA Perturbation,在多模态尺度上模拟不同因素对AURORA数字个体表示的影响。我们首先通过利用条件特征对潜在嵌入的脊系数作为效应量来推断其干预效应。然后,我们将这些因素加入参考潜在嵌入中,生成计算机模拟中的扰动剖面,以与未扰动剖面进行比较(图1B;STAR方法)。
跨多模态人类数据集对AURORA模型的训练与验证
自2012年以来,我们一直在收集来自总体健康人群中不同年龄队列的多样化生物和表型数据,包括3D面部图像、8、17张热面部图像、12张外周血单核细胞(PBMC)转录组、13、14以及生理组数据(如血液生物化学、血压和BMI),这些数据在开发衰老时钟方面发挥了关键作用。由于口腔微生物组与衰老相关疾病,包括阿尔茨海默病、心血管疾病和癌症,且易于获取,我们也从2018年开始收集舌包微生物组用于宏基因组测序。此外,我们利用核磁共振(NMR)分析了这些个体的血浆代谢组,以考察其对宿主代谢的影响。总计共计31,372名个体,共计51,964个多模态数据点(见表S1)。随后,我们还纳入了来自GTEx血液转录组(n=755)和英国的外部验证队列生物样本库(UKB)血液代谢组(n = 290,937)和生理组(n = 238,107)。我们共创建了一份涵盖425,258名参与者的广义多模态衰老图谱,年龄范围(图1C)和性别分布均衡(见图1C;表S1)。约10%的个体拥有三种或以上模态数据,使我们能够进行稳健的多模态分析。每个队列的全面人口统计和基线特征见表S1。我们使用了10,960个部分配对多模态特征,包括3,588个三维面部特征、1,794个热面部特征、220个口腔微生物组分类单元、415条口腔代谢通路、4,580个转录本、345个代谢物和18个体检参数,来自中国队列的8,881个样本,共2,735名个体,用于训练AURORA Unification。随后,我们使用来自43,083个样本(28,084名中国队列个体)、755个GTEx转录组和290,937个UKB代谢组,以及238,107个生理组(见图1D)作为外部验证数据,以确保AURORA能够生成跨不同族群和测序平台的模态特异性数据,具有显著的批次效应和缺失值。
AURORA统一实现了跨模态统一,揭示了衰老轨迹
一个成功的跨模态生成模型必须将不同模态的数据对齐到一个一致的潜在空间。AURORA 在这项任务中表现出色,成功地将所有数据映射到不同来源模态、不同批次、不同族裔、平台和性别的共享低维生物状态空间(图 1E--1G 和 S1A--S1C)。此外,定量积分指标进一步支持了跨模态、批次和种族的有效混合,包括平均轮廓宽度(ASW)、调整兰特指数(ARI)和归一化互信息(NMI)(图 1E--1G 和 S1C),这些指标基于高维 AURORA 潜在嵌入计算,而非统一流形近似和投影(UMAPs)。然而,我们观察到2012年队列与其他队列之间3D面部图像数据整合不完美,差异很可能是由于2012年影像系统分辨率低10倍所致。值得注意的是,潜空间捕捉到了明显的老化轨迹(见图1H和S1D)。对生成数据进行降维也出现了类似的模式(图S1E和S1G)。为评估AURORA的生成性能,我们计算了所有模态中所有个体合成数据生成与真实数据之间的皮尔逊相关系数(PCC)和均方误差(MSE)。在所有七个模态生成任务中,AURORA都表现出持续的高准确率(图S2A)。我们还进一步通过比较自生成和跨生成任务中95%置信区间的PCC,测试源模态是否影响其他模态的生成(图1I;表S2)。自重建的准确性可能反映数据维度和噪声。例如,三维人脸数据具有更高的维度和复杂度(空间、纹理和深度特征),使得完美的自我重建比简单的表格分子数据更难实现。对于口腔通路,注意通路丰度数据稀疏且噪声较大(零很多),即使在自我重建中也降低了相关性。AURORA 在个体层面相关性(图 S2B 和 S2C)中表现出稳健表现,而由于真实世界数据包含大量批次和平台效应,且在生成数据中基本被修正,特征级相关性略有下降(见图 S2D 和 S2E)。我们的结果显示,3D面部图像在生成其他模态时表现最佳,表明3D面部成像比其他单一模态包含更丰富、更整合的衰老和健康状态生物学信息。这很可能是因为面部是一个复杂的器官,反映了系统性生理、炎症、激素状态和心血管健康。鉴于面部特征包含更丰富的生物信息,且是训练样本中第二大(比生理样本小14.5%),我们进行了三次消融实验,以验证AURORA的性能不受面部模态的限制。具体来说,我们在移除3D人脸数据、热面部数据,随后又从训练数据集中移除3D人脸和热成像数据后,重新训练了ORORA模型。重新训练的AURORA模型在批量和源模态、年龄表示和跨模态生成方面表现出一致的能力(图S3A--S3D)。完整AURORA和消融AURORA(不含3D人脸数据)、无热面数据及无3D和热感人脸数据的跨模态平均PCC(不含模态内预测)分别为训练集的0.762、0.772、0.767和0.759,验证集的0.654、0.617、0.646和0.502(见图1I和S3D)。包括AURORA在内的神经网络模型对训练集大小非常敏感。为测试小数据集是否会影响AURORA的性能,我们使用子抽样数据集进行模拟评估。值得注意的是,即使训练集样本量占40%,AURORA仍保持稳健性能(图S3E)。此外,我们采用单细胞多组学预测和积分方法对模型进行了基准测试,计算了AURORA生成与真实数据之间的平均PCC和相关矩阵距离(CMD)。在不同的生成任务中,我们观察到样本级数据的相关性持续较高(训练和验证分别为PCC = 0.70和0.50,CMD = 0.36和0.22),表明在捕捉个体变异方面具有可靠性。然而,特征间的相关性较低(训练和验证分别为PCC = 0.23和0.24,CMD = 0.29和0.43),这是由于不同模态中存在扩展或独立特征,且这些特征与其他模态不完全对齐(见图S3F--S3I)。为了直观展示真实数据与生成数据之间的相似性,我们模拟了其他模态连续年龄组的平均3D和热面面部图像。生成的图像成功地重新捕捉了衰老特征(图1J)。此外,大多数生成和真实特征也表现出与年龄相似的Spearman秩相关系数(RCC),进一步验证了AURORA的性能(见图1K;表S3)。这些发现表明AURORA准确地将所有数据映射到一个共享的、具有生物学意义的潜在空间,揭示了清晰的衰老连续体。定量指标确认各队列间模态高度对齐,缺失模态的生成稳健,批次效应被消除。即使训练数据减少,模型仍保持高性能,展示了其稳定性和可扩展性。
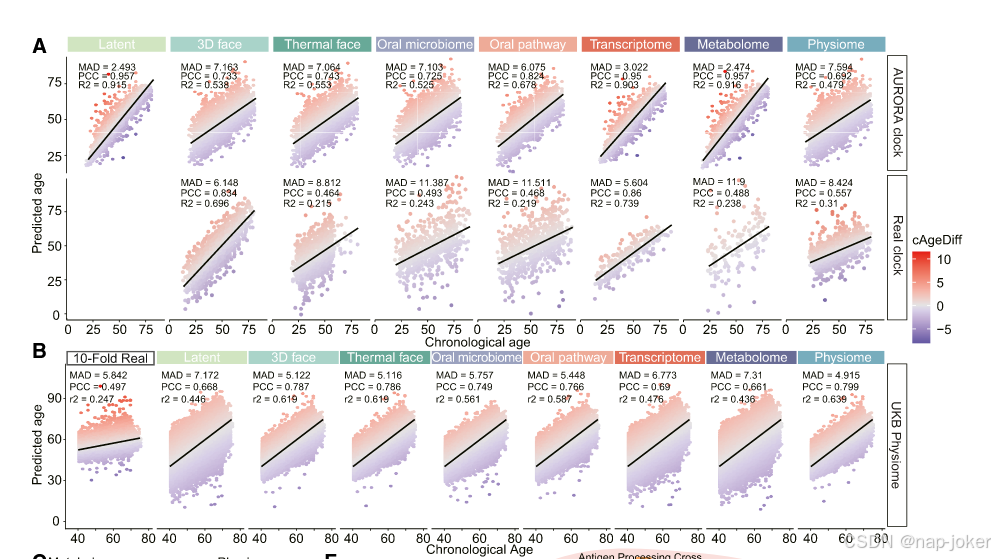
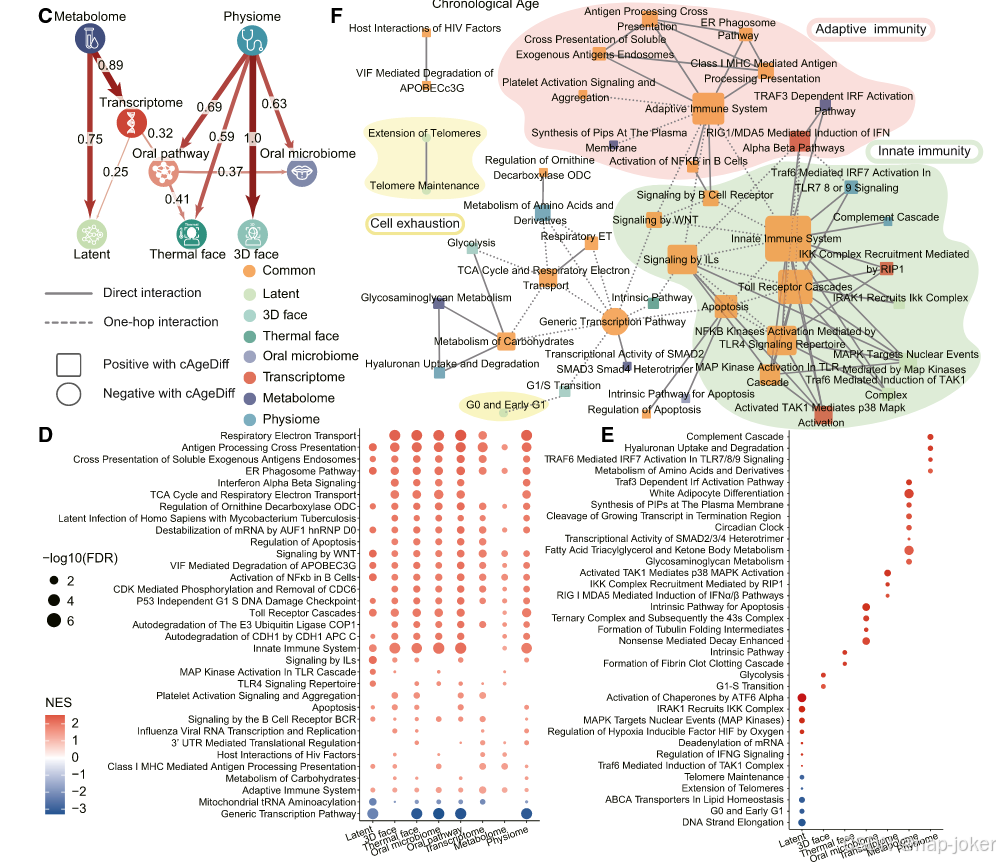
图2。AURORA 统一使得构建和界定准确的多模态老化时钟成为可能。(A) AURORA 生成的数据型特定老化时钟和潜在嵌入老化时钟包含更多训练样本(缺少 AURORA 生成的模态),且其准确性高于训练集中的基于真实数据的时钟,除三维面钟外。在独立验证集见图S3A。每个面板上标注了MAD、PCC和R2。每个点代表每个样本,并按缩放的cAgeDiff进行着色。基于AURORA的衰老时钟N为8,725,真实数据集的N如表S1中每个模态所示。(B)模态特异的衰老时钟和潜在嵌入衰老时钟(A)以及基于真实数据的脊回归衰老时钟,并对UKB数据进行了10折交叉验证,显示生成的物理组数据性能优于基于真实物理组/代谢组数据的时钟,此外还能推断多维时钟。每个面板上标记了MAD、PCC和R2。每个模态的N与表S1中每个模态的表现相同。(C) 由8种不同模态模型(包括潜在嵌入)生成的cAgeDiff之间的贝叶斯网络。链接是通过贝叶斯推断和SEM推断出的重要影响。边的颜色和宽度以及边上的数量代表SEM的估计值。(D和E)基因集富集分析(GSEA)基于生成基因表达水平与每个时钟cAgeDiff之间的RCC确定了富集GO项。不同时钟的共享(D)项和唯一(E)项通过|NES|> 1和FDR < 0.01进行了筛选。(F) 基于Reactome数据库的cAgeDiff正负相关通路网络。节点大小表示节点的度数。
AURORA Unification 使多模态衰老时钟得以实现,并揭示隐藏的分子相关性。AURORA 生成的衰老时钟在预测准确性上超越了真实数据库时钟
借助AURORA强大的跨模态数据生成能力,我们能够为每个样本填补缺失的模态。这意味着基于每个测量模态,我们从碎片化的剖面中生成了所有七种模态的数据,包括其自身模态。利用AURORA生成的数据,我们为每个模态构建了一个衰老时钟和潜在嵌入,将衰老速率量化为cAgeDiff(也称为年龄差距或ΔAge)。cAgeDiff反映了个体的生物年龄相对于同龄同龄人的群体规范,6,7表示衰老是加速(cAgeDiff > 0)还是减速(cAgeDiff < 0)。为了训练和验证时钟,我们使用了与AURORA相同的训练和验证集。我们基于三个参数:平均绝对差(MAD)、PCC和R平方(R²)对八个常见回归模型(包括线性模型、基于树的模型和神经网络)进行了基准测试。脊回归在验证队列中表现最佳,因此被选用于后续分析(表S4)。在各种老化时钟中,基于潜在嵌入的时钟在预测时间年龄方面最为准确,训练集和验证集的PCC分别为0.957和0.713,MAD为2.493和7.363,R2为0.915和0.509(见图2A和S4A)。其他模态时钟也表现出较高的准确性,训练集的PCC范围为0.7至0.9,验证集为0.6至0.7(见图2A和S4A)。值得注意的是,不同队列或性别之间没有显著偏差(图S4B--S4D;表S4)。相比之下,基于真实数据的模态时钟在较小的训练数据集或显著的批次效应下表现不佳,凸显了AURORA缓解这些问题的能力。例如,基于真实转录组的衰老时钟未能在GTEx数据集中预测年龄,而基于数据的基于数据的衰老时钟表现异常出色(见图S4A和S4C),展示了AURORA自动消除批次效应的能力。仅基于UKB生理组数据,利用这一优势,所有其他模态数据和时钟均可生成,使得比原始UKB生理组数据时钟更优的时钟,PCC从0.497提升至0.799,平均年龄变化从5.842年提升至4.915年(见图2B和S4E),证明了AURORA生成的时钟具有强的普遍性。通过根据同龄群体的总体规范调整预测年龄,我们得出了cAgeDiff(校正年龄差异),表示与年龄无关的生物衰老速率(图2A和S4B)。以往研究表明,来自不同模态或组织的cAgeDiff往往无法完美对齐,尤其是在模型误差范围内。4,6,7 除了明确解开的年龄维度外,其余47个潜在维度在不同模态间存在对抗性比对。这种比对确保了仅由这47个维度导出的年龄混杂嵌入能够生成保留丰富且时间独立的生物学信息的数据,包括疾病相关的变异和与年龄本身不同的个体化衰老轨迹。Pearson对每个模态数据的年龄调整残差(真实与生成)之间的相关性表明相关性依然显著(尽管降低),证实了超越时间年龄的生物衰老方差的捕捉(见图S4F)。这表明 AURORA 的模态对齐和生成过程强化了跨模态的信息,使时钟能够准确预测自身的 cAgeDiff,同时解释其他模态的变化。这些结果展示了基于 AURORA 生成数据训练的老化时钟的高准确性,超过了基于真实数据训练的时钟。这一改进凸显了 AURORA 精炼预测和增强衰老分析的能力,具有强大的普适性。
基于AURORA的模态特异性和潜在嵌入老化时钟揭示了共享、独特且隐藏的衰老机制
随后,我们利用cAgeDiff平均的2-SD截止点,识别出加速或减缓衰老的个体(快老龄和慢老龄化者),并比较了不同年龄钟的差异。在某一模态中被认定为快老或慢老者的人,在其他模态中可能被归类为相似的类型,而非被归类为相反类型(见图S4G和S4H)。尤其是三维面部时钟,识别出其他模态中最快和缓慢老化者数量最多(见图S4G和S4H)。为了进一步研究不同模态特征间的相互作用模式并构建多系统衰老网络,我们采用贝叶斯网络进行因果推断,并采用结构方程建模(SEM)估算cAgeDiff的参数。我们的分析显示,cAgeDiff的生理组和代谢组对其他时钟的cAgeDiff影响最为显著(图2B)。有趣的是,热面部衰老似乎受不同年龄钟的影响更广泛,而三维面部衰老则更为显著(见图2B)。接下来,我们考察了哪些多模式特征和生活方式因素与衰老加速和减缓相关(见图S4I)。基于PBMC转录组,我们发现许多通路通常与大多数模态的cAgeDiff正相关,包括抗原加工、适应性和先天免疫系统、干扰素信号传导、白细胞介素信号传导、凋亡和Toll样受体信号传导。相比之下,通用转录和tRNA氨基酰化与大多数cAgeDiff呈负相关(见图2D)。此外,若干通路具有特定模态性。这些通路包括生理组的氨基酸代谢、脂肪酸代谢和白脂肪细胞相关代谢的代谢组、IFNα/β转录组的通路、三维面部的糖酵解作用和G1/S转变,以及热面部的纤维蛋白凝固级联反应。有趣的是,AURORA 潜嵌入时钟包含了最具模式特异性的通路,包括与其 cAgeDiff 正相关的 ATF6、IKK、MAPK 和 HIF 通路,以及脂质稳态、DNA 链延长和端粒维持通路中的 ABCA 转运蛋白,这些通路与其 cAgeDiff 呈负相关(见图2E),表明其能够捕捉隐藏的基本衰老过程。一贯地,模态-共同通路主要位于 Reactome 数据库构建的通路连接网络中先天免疫和适应性免疫的中心群(STAR 方法)中,而模态特异性通路主要位于主网络的边缘或孤立子网络(图2F)。总体而言,利用 AURORA 生成的数据,我们构建了模态特异性和潜空间老化时钟。基于嵌入的时钟实现了最高精度(PCC = 0.957;MAD = 2.5年训练,7.4年验证),并有效推广至GTEx和UKB数据。它还揭示了潜伏轨迹与端粒遗失之间的联系,从而统一了不同模态的分子和表型衰老过程。
疾病预测与纵向验证 AURORA生成的数据比中国队列中的真实数据模型更能准确预测疾病
我们还评估了cAgeDiffs反映生物健康和疾病状态的能力。我们测试了cAgeDiff是否与年龄相关慢性疾病相关,包括脂肪肝、肝囊肿、高血压、高血脂、2型糖尿病(T2D)和心血管疾病(CVD)。我们训练了六个MLP分类器,利用AURORA生成的数据或年龄混杂嵌入(排除年龄作为特征)预测这些疾病,以防止预测偏差。值得注意的是,训练于年龄混杂嵌入的分类器表现最佳,其次是热成像面部图像,训练集的曲线下面积(AUC)分别为0.79至0.88和0.64至0.82(见图3A和S5A)。与老化时钟的结果类似,基于真实数据的疾病分类器表现不如使用样本嵌入的分类器,并存在过拟合和普遍性有限的问题(见图S5B)。
AURORA 衰老混杂嵌入预测中国队列中的疾病严重程度、未来风险及分子生物标志物
AURORA嵌入预测的疾病概率不仅显著高于对照组,且与带有州标签肝病的严重程度有强相关性(见图3B和3C)。如预期,疾病概率之间的相关模式与参与者的共病相符,表明AURORA衍生的疾病预测反映了真实的共病状况(见图S5E)。此外,预测的疾病概率与既定诊断标准一致(例如,高血压患者的收缩压和舒张压SBP和DBP,高脂血症的葡萄糖和甘油三酯,脂肪肝患者的谷氨酸草酰乙酸和丙氨酸转氨酶GOT和ALT;图S5F),显示了模型的临床相关性。我们还发现预测的疾病概率与这些疾病在3年内未来风险显著相关(见图3D和S5G)。这些结果表明预测概率能够代表这些慢性疾病的进展和风险。值得注意的是,由于这些预测涵盖了当前疾病状态和纵向风险轨迹,模型本质上捕捉了亚临床和预后信号,如尿素(见图S5F),这些信号与早期病理(包括高血压、代谢综合征、胰岛素抵抗、血脂异常、T2D和心血管事件)有显著关联。17 这些结果表明基于AURORA的疾病预测器在预防性干预策略中的优势。我们还观察到疾病概率与cAgeDiff之间存在强烈相关性,表明cAgeDiff可以有效代表健康状况和慢性病风险(图3E)。此外,Kaplan-Meier(KM)曲线显示,在未来2--3年随访期间,累计事件发生率明显上升,且3D时钟cAgeDiff的上升,表明面部衰老加快与未来疾病风险升高相关(见图3F)。此外,我们发现疾病特征与cAgeDiff之间存在众多交叉点。根据其PCCs对cAgeDiff、6种慢性病风险和生活方式因素,将所有特征聚类为六个组,发现这些参数在不同模态间均匀分布,而非按模态分开(见图3G)。这表明不同健康状态导致不同模态的协同变化。第2和第6簇代表负向衰老和疾病特征,富含参与细胞增殖、细胞因子和WNT家族的蛋白-蛋白相互作用(PPI)网络(见图3H)。
这些结果表明,基于ORORA生成的多模态数据训练的疾病预测器,特别是关于年龄混杂AURORA潜在嵌入的数据,不仅能够精确预测六种慢性疾病、其共病情况及与衰老速率的关联,还展现了纵向预测能力。此外,年龄混杂潜在嵌入的更好表现表明,衰老相关疾病的发展轨迹偏离正常健康衰老。
AURORA生成的数据比UKB队列中的真实数据模型更能准确预测疾病
受到这些发现鼓舞,我们接着考察了基于AURORA的嵌入是否也能提升UKB队列中的疾病预测准确性,UKB队列是一个具有更广泛疾病注释的独立人群队列。我们将AURORA框架应用于UKB队列的疾病预测任务。基于AURORA的疾病预测器持续优于基于UKB的生理组或代谢组数据模型,在多种疾病中实现显著更高的AUCs(见图3F)。在比较基于真实生理数据的预测变量与使用ORORA生成的物理组数据嵌入预测变量时,心力衰竭/肺水肿的AUC从0.67升至0.84,短暂性脑缺血发作(TIA)的AUC从0.70升至0.83,中风从0.74升至0.84,心脏病/心肌梗死从0.84升至0.92,肾癌从0.77升至0.85,肝癌从0.74升至0.82(见图4A、4B、S6A和S6B)。根据真实生理数据,绝大多数非癌症疾病(362种中333种)和癌症(40种中37种)是不可预测的(AUC < 0.7);相比之下,AURORA 实现了准确预测,并将可预测性疾病总数(AUC > 0.7)从29%增加到96个(占所有非癌症疾病的26.52%),癌症从3个增加到17个(占所有癌症的42.50%)(见图4A和4B)。表S5。为进一步评估在无影像数据下的 AURORA 预测能力,我们比较了两对疾病的疾病预测表现:使用原始 UKB 数据与无面貌图像的 AURORA 统一多模态嵌入,以及带无面部图像数据训练的 AURORA 嵌入。结果显示,即使 AURORA 本身训练时没有任何面部图像,基于 AURORA 嵌入训练的分类器仍显著优于基于原始 UKB 数据训练的分类器。具体来说,38、37 和 37 个非癌症疾病模型以及 3、3 和 5 个预测模型的 AUC > 0。 分别有75个使用年龄混杂嵌入的AURORA训练时未使用3D面部图像、无热面部图像,且未使用3D和热成像面部图像,而使用真实数据的非癌症疾病模型仅有19个,癌症模型仅1个(见图S6C)。与之前的实相关系结果一致,AURORA在所有七种模态上训练提供了额外的预测提升,45个非癌症模型和6个癌症模型达到AUC>0.75(图S6C)。此外,基于AURORA嵌入的模型与真实代谢组数据比较时也观察到类似的提升(图S6A--S6C;表S5)。这表明AURORA通过模型中嵌入的丰富信息补充了原始数据,且仅凭18参数常规血液检测数据即可轻松应用于临床环境。
AURORA衍生的多模态衰老时钟预测UKB队列中的未来疾病风险和生物标志物
基于UKB中生理组和代谢组组合产生的八个AURORA生成时钟,我们用Cox比例风险模型(调整年龄和性别)测试,发现热面cAgeDiff的增加与多种疾病(包括全因性痴呆、脑血管疾病、慢性肾病、中风和心力衰竭)中最高的风险比(HRs)和一致性指数(C指数)相关(见图4C和S6D),其次是基于生理的cAgeDiff。这些发现表明cAgeDiff是未来疾病风险的强且模态一致的预测指标,热面部特征捕捉了特别显著的早期生理衰退标志。我们对基线无疾病且整体cAgeDiff(8个AURORA生成时钟的平均值)中前10%(快速年龄增长者)和后10%(慢老化者)的个体进行了生存分析。KM曲线显示,随访期间累计事件发生率明显上升,cAgeDiff增加表明生物衰老加快与未来疾病风险升高相关(见图4D)。这些结果进一步证实了所有8个衰老时钟,尤其是热面衰老时钟(UKB数据中缺失,但由AURORA生成)与AURORA改进的生理衰老时钟的加速,与独立UKB队列中多种慢性病风险的更高有关。总体而言,训练中AUC为0.79--0.88,验证为0.64--0.82,优于基于真实单模数据的模型。预测概率与未来疾病发生相关,支持预防性风险评估。在英国研究委员会的数据中,AURORA 将标准血液检测可可靠预测的疾病数量从少于 32 种增加到超过 113 种,凸显了其转化潜力。
AURORA扰动实现生活方式和药理学模拟,预测生活方式干预对衰老和疾病风险的影响
利用极光扰动(图5A),我们研究了生活方式因素对衰老的影响。极光生活方式扰动重现了吸烟、软饮、过度饮酒、暴饮暴食和加工肉类对健康带来的众所周知的不利影响,通过增加各种疾病风险(包括心血管疾病和代谢疾病)和加速衰老(图5B),这为扰动结果提供了概念性的验证。在多种习惯中,植物性饮食通常能减少cAgeDiff并改善健康结果,而动物性饮食则相反(见图5B)。与中国队列一致,UKB队列中的极光扰动发现酒精、加工肉类和谷物摄入、吸烟及熬夜与持续的有害和加速衰老效应相关,而植物性饮食(包括水果和蔬菜摄入)和体力劳动则观察到保护性和减缓衰老的效果(见图S6E)。这些发现凸显了饮食干预在调节衰老速率方面的潜力,并展示了极光扰动的力量识别不同群体和族群间的此类效应。
个体化药物效应的纵向验证和生物标志物发现
接着,我们评估了AURORA在利用UKB队列纵向用药记录模拟药理干扰的准确性(图5C)。模拟药物对四种慢性病的影响显示,模拟在靶向适应症下还原了预期的治疗概率降低(见图S6F)。随后,我们识别出一组在基线(第一次就诊)确诊但对药物未接触,并在第二次就诊前开始相关药物方案的参与者(每药N≥10次)。预测的疾病概率变化(Δ P_predicted)显示出中位数相关性为0.45,临床变化显著(Δ P_observed = 第二次就诊一次)(图5D),验证了AURORA在建模个体层面药物干预反应方面的可靠性(见图5E和S6G)。作为案例研究,我们将AURORA扰动应用于UKB队列中T2D患者,重点关注二甲双胍和胰岛素治疗的预测效果。个体根据预测治疗对疾病严重程度的影响,分为反应组(ΔT2D概率<--0.4)和无反应组(ΔT2D概率>0.4)。值得注意的是,非二甲双胍组的BMI显著高于反应组(p = 0.0411),而胰岛素反应组间未观察到显著BMI差异。相反,胰岛素治疗无反应者ALP水平显著升高(p = 8.81e 3),二甲双胍组未观察到差异(见图5E)。这些发现表明AURORA扰动揭示了与特定抗糖尿病药物治疗反应性相关的不同生物标志物。总体而言,AURORA成功重现了生活方式因素(如吸烟危害和植物性饮食益处)在各人群中的已知影响。药物扰动分析进一步显示,预测的分子转变与现实世界的纵向用药效应相关(中位PCC = 0.454)。模型还预测了对二甲双胍和胰岛素的差异反应,识别出区分反应者的生物标志物,从而实现个性化的治疗分层。
极光扰动使得重新定位和个性化干预成为可能
接着,我们通过极光扰动模拟药物对cAgeDiff的影响,探讨了药物重新定位以减缓衰老的可能性。我们观察到,二甲双胍、阿司匹林、叶黄素、各种维生素(B1和D)及微量矿物质(钙)以及天然泻药(如fybogel、乳果糖和芦荟制品)几乎所有方式的cAgeDiff都降低了,而其他一些药物,如多西环素(一种抗生素)和周塞米(一种强效利尿剂),则通常会增加cAgeDiff(见图5F)。此外,各种雌激素疗法被推断能降低cAgeDiff,而各种孕酮片和注射则显著增加了大多数cAgeDiff(见图5F)。尽管AURORA Perturbation推断二甲双胍是大多数人(84.92%)的顶级抗衰老药物之一,但有15.08%的个体被推断表现出相反的衰老加速效应。相比之下,72.41%和27.59%的个体分别被推断为多西环素具有促进和抗衰老的效果(见图5G)。为进一步探讨二甲双胍的个性化抗衰老潜力,我们研究了AURORA-Unification生成的转录组图谱与预测二甲双胍治疗后cAgeDiff极端变化相关的特征。cAgeDiff减少中前10%的个体(即预测抗衰老反应最强者)表现出高表达的胰岛素/IGF信号分子IGFBP3、压力诱导高血压促进钙调节因子TRPC3、成熟的衰老标志物CDKN2B以及神经退行性疾病相关应激颗粒蛋白FUS。相比之下,cAgeDiff增加前10%的个体(即二甲双胍后预测衰老加速者)表现出极低的基因表达(见图5H)。这些表达模式在UKB队列中不存在,且纯由AURORA生成,揭示了二甲双胍治疗和抗衰老效果的最佳目标个体的新特征。综合这些发现表明,AURORA 能够识别具有减缓时钟潜力的化合物,并展示了该框架能够完全基于多模态特征在计算机中预测个性化治疗效果的能力,为精准干预设计提供了可扩展的方法。
AURORA Agent:人工智能与生物学的交互整合
如图1A和1B所设想,作为概念验证,我们将AURORA的应用扩展到实验室研究之外,开发了一个交互式AI代理,结合了AURORA的生物跨模态生成能力与现代大型语言模型(LLM)的高级语言推理和视觉理解能力(见图6)。该系统提供实时、个性化评估,并允许与公众用户、生物医学研究人员和制药开发者无缝互动。该代理可通过网页门户或命令行接受任何简单模式,如面部图像或18参数血液生物化学画像。LLM能够解释自然语言请求并自动调用相应的AURORA模块,从而有效地将稀疏输入转化为多模态健康肖像。面向公众,它提供简明的健康评估,包括生物年龄和常见疾病风险,并筛查对生活方式或药物干预的反应,并预测特定干预可能引起的变化。对于研究人员,它生成高精度的跨模态谱,并从极少的部分数据中实现基因通路或分子机制分析,而药物研发公司则可模拟化合物效应并探索个性化的靶点网络。为了将AURORA的能力转化为实践,AURORA Agent将AURORA的生物建模与大型语言理解。通过网页和命令行访问,代理用自然语言解释用户查询,接受任意模态输入,并自主调用AURORA模块以提供个性化分析。面向公众,它提供简明的健康摘要、生理年龄估计和风险评估。对研究人员而言,它支持跨模态数据生成和分子机制分析。对于制药开发者,它模拟化合物效应并绘制药物靶向网络。通过将推理与生物生成相结合,AURORA 代理将碎片化的观察转化为功能性数字孪生,从而实现生成生物学的普及化。
讨论
AURORA 代表了生物医学的变革框架,将多模态数据统一为既能解释又能操控生物状态的生成表征。与以往大多数研究将健康结果与表观遗传学、蛋白质组学或微生物组等单一模态相关,AURORA 则将七种异质数据类型整合到一个共享的潜在空间中。这使得构建个性化的虚拟人类表征成为可能,捕捉系统范围的生物学,弥合了碎片化数据集留下的空白。这一发现表明,非侵入性、低成本的测量可以作为研究和临床试验中昂贵组学检测的有效代理。通过重建缺失数据,AURORA 揭示了面部成像常被低估的单一模态,可能是其捕捉系统衰老线索的能力。我们还观察到预测准确度的明显差异:从面部特征生成分子数据的准确率高于相反方向。这种方向差异在生物学上是合理的。面部整合了遗传、代谢和环境因素的累积信号,作为系统衰老的综合总结。相比之下,单个组学模态通常只捕捉这一复杂生物过程的特定片段。这一方向优势还得到了我们的模态信息量分析支持,该分析将3D面部成像识别为跨模态补值中最具信息量的单一模态。这些模式在独立验证队列间的一致性反驳了简单记忆训练数据的反对。从实际角度看,常规血液检测通过我们的模型解读时,可能携带足够信息,比标准单模态预测变量更广泛地标记风险。关键是,AURORA 使得基于机制的干预发现成为可能。在更广泛的范围内,AURORA 支持可扩展的治疗性筛查,预测如个性化二甲双胍和胰岛素对糖尿病的影响,这些与英国糖尿病的纵向结果相符,以及用于个性化二甲双胍衰老减缓效应的转录组生物标志物。这些能力为临床测试的化合物优先排序提供了一种具有成本效益的策略,降低了精准药物开发的障碍。虽然以衰老为例,但该框架已推广至健康与疾病领域。通过从有限、零碎的测量转向对潜在生物本质的全面数字模拟,AURORA 将生物医学研究提升至超越单纯观察。其构建人口尺度虚拟人类图谱和模拟个性化反应的能力,为推进生物标志物开发、临床风险预测、分子机制、治疗靶点发现和药物再利用奠定了基础,开辟了从被动观察到主动模拟的路径。
研究的局限性
虽然我们的模型展示了跨模态推断的可行性,但仅从有限的单模态数据生成完美、高保真度的分子剖面仍是一个理想目标,而非当前的现实。因此,全面的分子测量和配对多组学数据集仍然是提供训练稳健模型和准确捕捉生物细微差别所需基础信息的关键。需要前瞻性研究以评估不同人群的精度,并验证AURORA发现的实验性新治疗策略。随着更多平衡的多模态数据集的出现,AURORA可以无缝整合它们,精炼生物学洞见。然而,通过统一不同生物医学数据并支持机制模拟,AURORA定位为学术发现和生物技术创新的平台,实现了长期以来的数据驱动、个性化且临床可操作医学的承诺。目前,AURORA Agent仍处于概念验证阶段,尚未为实际应用优化。展望未来,将此类框架扩展为人口规模的虚拟人类图谱,有望改变生物医学研究和医疗,实现数字化实验和精准干预,涵盖人类生物学的全方位领域。
数据和代码的可用性
根据我们的参与者同意协议,三维和热成像面部图像及其他对个人身份敏感的元数据不得公开或共享。2012年队列的映射RNA-seq读段可在NODE OEP001041库公开获取;GTEx数据可在 https://www.gtexportal.org/home/ 下载处公开获取。本研究中的所有微生物组数据均公开于OMIX014936。本研究中的所有代谢组数据均公开于OMIX014937。
• 所有分析均使用免费的Python和R软件包进行。AURORA框架可在GitHub获取:https:// github.com/JackieHanLab/Aurora。
• 用于创建论文图表的数值可在Data S1中获取。如需重新分析本文数据所需的额外信息,可向主联系人索取。