一句话总结openclaw记忆:类人认知的分层蒸馏记忆架构
OpenClaw 是一款面向单用户或小团队的自托管 Agent 平台,其记忆系统的核心设计哲学是完全的可解释性与渐进式知识沉淀------ 它不依赖任何黑盒化的向量数据库或隐式索引,而是通过类人认知的分层蒸馏逻辑,让记忆的生命周期完全透明、可干预。
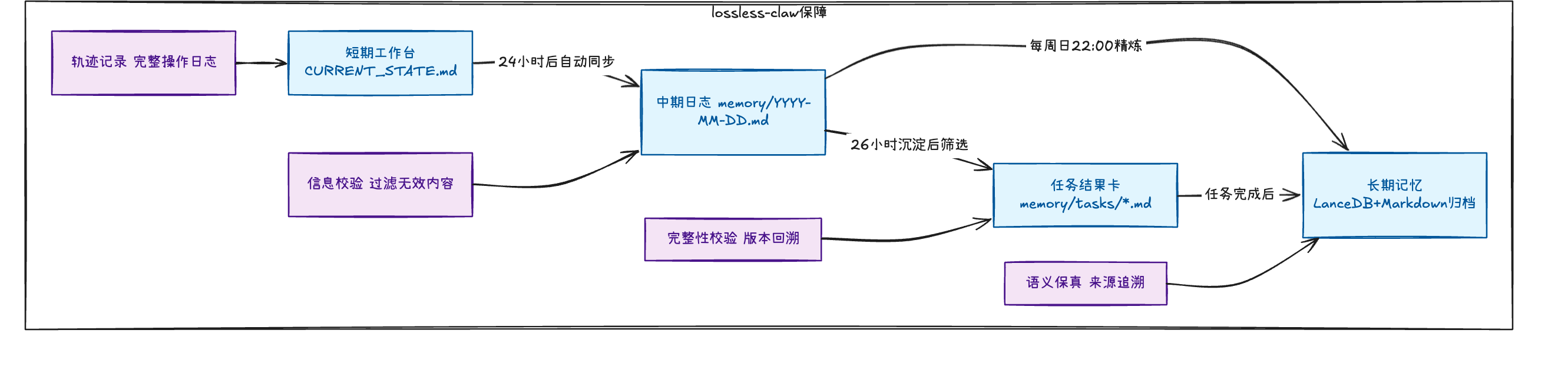
OpenClaw 的记忆系统遵循 "原始输入→短期缓存→中期整理→长期归档" 的类人认知流程,将记忆明确划分为四个核心层级,每个层级对应不同的存储介质、生命周期与访问规则。这种分层设计的本质,是对 "原始信息 - 有用信息 - 持久知识" 的价值过滤,每一层都承担着 "提炼高价值信息" 的功能。
记忆层级结构
OpenClaw 的记忆层级并非简单的 "时间分层",而是 "价值分层"------ 每一层的信息密度、持久化优先级与访问成本都有明确差异,层级之间通过自动化流程完成信息流转:
|--------|--------------------------------------------|---------------|-----------------------------------------------------------------------------------------------------------------|
| 记忆层级 | 存储介质 | 生命周期 | 核心功能 |
| 短期工作台 | CURRENT_STATE.md | 单次会话 / 24 小时 | 缓存当前会话的所有上下文,包括用户提问、工具调用结果、子 Agent 的中间输出,是 Agent 实时思考的 "工作区" |
| 中期日志 | 按日期命名的 Markdown 文件(如memory/2026-03-18.md) | 26 小时 | 每日 23:00 自动同步最近 26 小时的有效会话 ------ 同步前会过滤掉重复提问、错误工具调用等无效信息,仅保留有价值的交互记录 |
| 任务结果卡 | memory/tasks/*.md | 与任务周期绑定 | 子 Agent 的任务输出会以结构化格式沉淀于此,包含任务 ID、执行时间、核心结论与关联资源,是跨会话任务交接的标准化载体 |
| 长期记忆 | LanceDB 向量数据库 + Markdown 归档 | 永久(需手动清理) | 每周日 22:00 由系统自动精炼,提取中期日志与任务结果卡中的 "非时间敏感事实"------ 比如项目的技术栈选型、用户的长期偏好、反复验证的经验规则,最终以 Markdown 文件归档,并同步向量索引以支持快速检索 |
值得注意的是,OpenClaw 的记忆层级之间并非单向流转:比如当用户在新会话中调用某一历史任务的结果时,系统会自动将任务结果卡从长期记忆临时加载到短期工作台,待会话结束后再根据新的交互信息更新该结果卡,确保记忆的动态性。
核心机制解析
OpenClaw 的记忆系统通过三大核心机制,解决了传统记忆系统的 "遗忘" 与 "冗余" 问题:
(1)蒸馏式记忆流转:从 "原始记录" 到 "持久知识" 的价值过滤
OpenClaw 的记忆流转不是简单的 "复制粘贴",而是通过 "日增量同步 + 周度精炼" 的自动化流程完成价值提纯,每一轮流转都会降低记忆的冗余度、提升信息密度。具体而言:
- 日增量同步:每日 23:00 触发,仅处理最近 26 小时的会话数据 ------ 这个时间窗口既覆盖了当天的所有有效交互,又避免了跨天的冗余数据。同步时会过滤掉 "重复提问""工具调用错误日志""无意义的闲聊" 等无效信息,仅将用户的明确需求、Agent 的有效回答、工具调用的成功结果追加到当日的中期日志文件中。
- 周度精炼:每周日 22:00 触发,系统会遍历过去 7 天的中期日志与任务结果卡,通过 LLM 提取 "持久事实"------ 比如 "用户要求所有接口返回格式必须是 JSON:API 规范""支付模块的超时阈值经过测试,30 秒是最优值" 这类非时间敏感、可长期复用的信息。提取完成后,系统会将这些事实写入长期记忆的 Markdown 文件,同时清理过期的中期日志(保留最近 30 天的日志作为备份)。
- 幂等性保障:在每日同步与周度精炼流程中,系统会基于消息指纹(Message Fingerprint)对数据进行去重 ------ 即使同一信息被多次写入,也只会保留最新的版本,从根源上避免了记忆冗余。
这种设计的核心逻辑是:记忆的价值与冗余度成反比------ 只有通过持续蒸馏,才能让有限的存储资源承载高价值的长期知识,同时避免冗余信息干扰检索效率。
(2)QMD 混合检索:精准度与效率的平衡
OpenClaw 的检索系统以 QMD(Queryable Markdown)为核心,这是一种将 Markdown 的可读性与结构化检索能力结合的格式 ------ 每个 Markdown 文件都包含标准化的元数据(如创建时间、记忆类型、关联标签),既支持人类直接编辑,也支持机器的精确查询。其检索流程严格遵循 "任务优先、语义兜底" 的顺序,从高价值、高精准度的记忆开始匹配,逐步降级到泛化的语义检索,确保在有限的检索成本内获取最优结果:
- 任务结果卡检索:优先查询memory/tasks/目录下的结构化文件,根据任务 ID、执行时间或标签精准匹配 ------ 比如用户问 "上周的支付模块测试结果如何",系统会直接定位到对应日期的任务结果卡,无需遍历所有记忆。
- 语义检索:若任务结果卡无匹配项,则调用 LanceDB 向量索引,对长期记忆的 Markdown 文件进行语义匹配 ------ 向量索引基于 Gemini-embedding-2-preview 模型构建,支持多模态内容(如截图、音频转写文本)的检索。
- 全文检索:若语义检索仍无结果,最后会使用 SQLite FTS5 对所有 Markdown 文件进行全文匹配 ------ 这是兜底方案,但由于前期的蒸馏流程已经过滤了冗余信息,全文检索的效率依然能得到保障。
此外,QMD 检索还支持 "候选重排序":系统会先获取 4 倍于需求的候选结果,再通过本地 Qwen3 reranker 模型对结果按 "相关性""时效性""权威性" 三个维度重排序,进一步提升检索精准度。
(3)会话裁剪与缓存淘汰:有限上下文窗口的高效利用
为了避免上下文窗口溢出,OpenClaw 设计了 "软修剪 + 硬保留" 的双层机制,在保证关键信息不丢失的前提下,将上下文规模控制在模型可承受的范围内:
- 软修剪:当会话 Token 数量接近 4000 的软阈值时,系统会自动裁剪 "非关键历史"------ 具体规则是保留最后 N 条 Agent 回复(N 由keepLastAssistants参数配置,默认是 5 条),并对中间的大体积工具结果(如超过 1000Token 的 API 响应)进行摘要压缩,压缩后会在上下文中标注 "已压缩,原始内容见工具结果日志",方便后续追溯。
- 硬保留:所有工具调用的核心结果(如任务完成状态、关键数据返回值)、用户的明确指令(如 "必须使用 Python 3.11 版本")会被强制保留,不会因 Token 阈值被裁剪。
- TTL 缓存淘汰:对于超过 5 分钟未活跃的会话,系统会触发自动修剪 ------ 仅保留最近 3 条 Agent 回复与用户的核心需求,释放的内存用于新会话的缓存。
这种机制的核心权衡是:牺牲部分非关键历史的完整性,换取关键信息的可及性与系统的稳定性------ 比如在代码调试场景中,用户的前 10 轮尝试可能被压缩,但最后一次成功的调试参数会被完整保留。