中级软考(软件工程师)算法特辑------常考的六大基础排序算法
- 一、六大排序算法逻辑
-
- [1.1 直接插入排序](#1.1 直接插入排序)
- [1.2 冒泡排序](#1.2 冒泡排序)
- [1.3 简单选择排序](#1.3 简单选择排序)
- [1.4 堆排序](#1.4 堆排序)
-
-
- [1. 思路分析:内存与时间的博弈](#1. 思路分析:内存与时间的博弈)
- [2. 答案:Top K 的具体操作逻辑](#2. 答案:Top K 的具体操作逻辑)
-
- [1.5 快速排序](#1.5 快速排序)
- [1.6 归并排序](#1.6 归并排序)
- 二、排序算法总结和比较
- 三、总结
一、六大排序算法逻辑
1.1 直接插入排序
📝 算法定义: 将待处理的元素逐个插入到已经排好序的有序子表中,从而不断扩大有序区的规模。

- 执行步骤图解 (示例:5, 2, 4, 6):
- 初始状态:5 视为有序区,待插入序列为 {2, 4, 6}。
- 插入 2:2 与 5 比较,2 较小,插入 5 之前。结果:2, 5, 4, 6。
- 插入 4:4 与有序区 2, 5 比较,插入 2 和 5 之间。结果:2, 4, 5, 6。
- 最终状态:插入 6,6 最大,位置不变。结果:2, 4, 5, 6。
- 核心操作点 : 寻找
插入位置与元素的后移。 - 性能分析 : 时间复杂度
O(n^2),空间复杂度O(1),稳定。 - 应用场景 : 数据量较小或数据已"基本有序"时效率极高(常作为混合算法的底层实现)。
直接插入排序展现了"稳扎稳打"的逻辑美感,虽然在大规模无序数据前效率较低,但在微观有序场景下性能卓越。
1.2 冒泡排序
📝 算法定义: 重复走访序列,通过相邻元素的比较与交换,让极大元素像气泡一样逐渐"沉"到序列末尾。

-
执行步骤图解 (示例:5, 2, 4, 1):
- 第一趟执行:
- 比较 5 与 2,交换 -> 2, 5, 4, 1
- 比较 5 与 4,交换 -> 2, 4, 5, 1
- 比较 5 与 1,交换 -> 2, 4, 1, 5
- 第一趟结果:5 已固定在最终位置。
- 最终状态:重复上述逻辑处理 2, 4, 1。
-
核心操作点 :
相邻交换。 -
性能分析 : 时间复杂度
O(n^2),空间复杂度O(1),稳定。 -
应用场景: 主要用于教学演示,或对稳定性有严格要求且数据量极小的场景。
冒泡排序逻辑最为直观,但其频繁的交换操作(Swap)导致其在工程实践中往往被性能更好的算法替代。
1.3 简单选择排序
📝 算法定义: 每一趟从待排序列中选出最小的一个元素,直接与待排区的第一个元素交换。

- 执行步骤图解 (示例:5, 2, 4, 1):
- 第一趟执行:扫描全表 5, 2, 4, 1,锁定最小值 1。
- 第一趟结果:将 1 与首位元素 5 交换 -> 1, 2, 4, 5。此时 1 已固定。
- 最终状态:在后续 2, 4, 5 中继续选最小,以此类推。
- 核心操作点 : 选出
极值下标后进行一次性交换。 - 性能分析 : 时间复杂度
O(n^2),空间复杂度O(1),不稳定。 - 注:其不稳定性源于交换过程。例如 5, 5, 2,第一趟 2 与第一个 5 交换,破坏了两个 5 的原始相对顺序。
- 应用场景: 当单个记录占用空间巨大(移动成本高)但记录总数较少时。
简单选择排序以"少动多看"为策略,通过最小化移动次数来应对笨重的数据记录。
1.4 堆排序
📝 算法定义 : 利用大顶堆(或小顶堆)的树形结构特性,通过不断将堆顶元素与堆末尾元素交换并重新调整堆来实现排序。
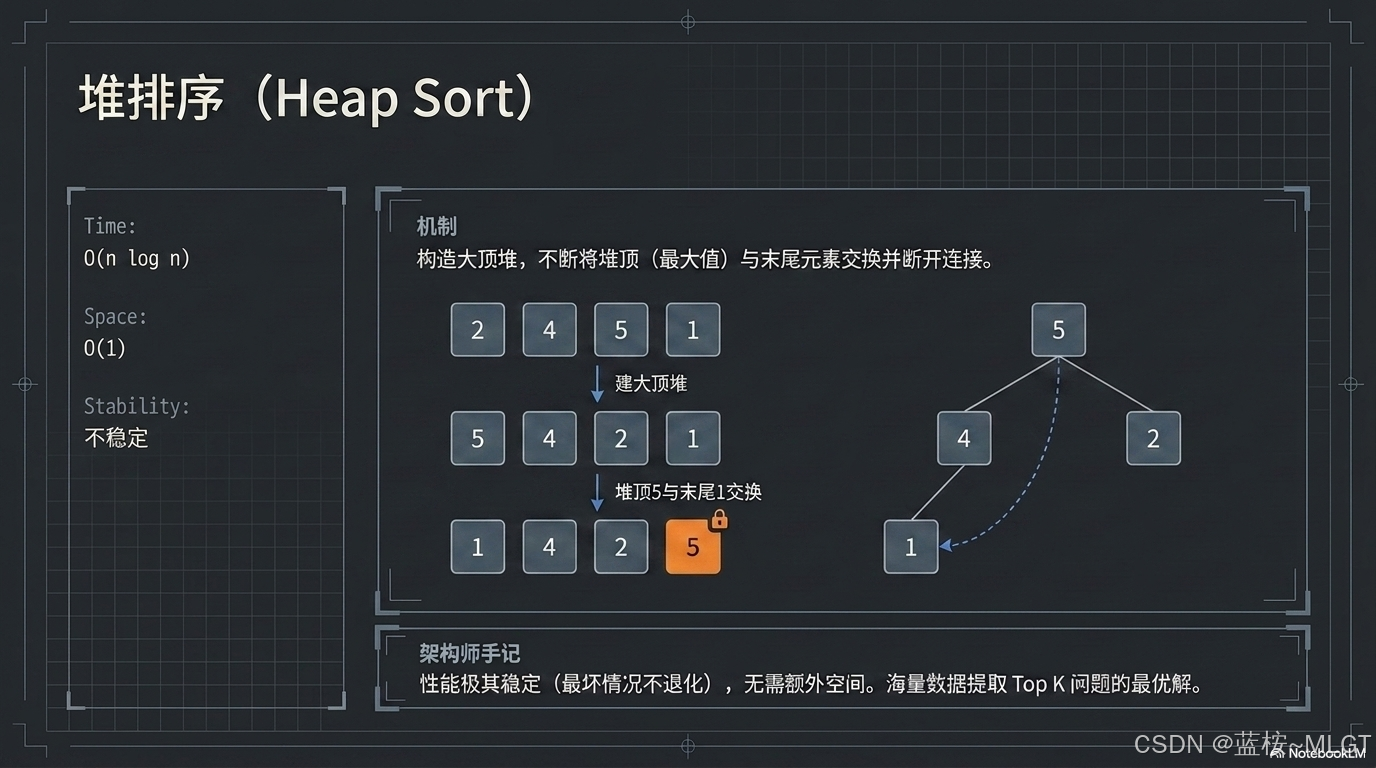
- 执行步骤图解 (示例:2, 4, 5, 1):
- 建堆阶段:将初始序列构造为大顶堆。结果:5, 4, 2, 1(5 为堆顶)。
- 第一趟交换:将堆顶 5 与末尾元素 1 交换。
- 第一趟结果:1, 4, 2, \| 5。此时 5 已固定在数组末尾。
- 调整阶段:对剩余元素 1, 4, 2 重新调整为堆,再次交换堆顶。
- 核心操作点 : 堆顶与末尾交换后的"
下沉"调整。 - 性能分析 : 时间复杂度
O(n \log n)空间复杂度O(1),不稳定。 - 应用场景: 典型的海量数据 Top K 问题(例如从 10 亿个数中提取最小的 100 个)。
事实上在最开始看堆排序的时候,例子中构建的大顶推已经有序了,为什么还需要排序?为什么在海量数据中很稳定?
- 堆的定义:仅仅保证"父节点大于(或小于)左右子节点"。
- 事实:它不保证左子节点和右子节点之间的大小关系,也不保证不同分支之间的节点顺序。
- 示例 :
序列[90, 80, 70, 60, 40]是一个大顶堆(完全有序)。
序列[90, 70, 80, 60, 50]也是一个大顶堆。看,70 在 80 的左边,但 70 比 80 小。在数组存储中,它依然是无序的。
为什么要交换?
我们排序的目标通常是得到一个从小到大的递增序列。
- 第一步:建堆。 我们的唯一收获是:确定了当前序列的最大值在堆顶(索引 0)。
- 第二步:交换。 我们把这个"最大值"换到数组的"最后一位"。此时,最后一位就"归位"了(它是最终有序序列的一部分)。
- 第三步:调整。 换上来的那个数通常很小,破坏了堆的性质。我们缩小堆的范围(排除最后一位),对剩下的元素重新进行"下沉"调整,再次选出剩下的最大值。
总结: 交换的目的是为了 "固定位置" 。堆排序本质上是一种 "高效率的选择排序" 。简单选择排序是遍历整个数组找最大,而堆排序是利用堆这种结构,在 O ( log n ) O(\log n) O(logn) 的时间内快速"弹"出一个最大值。
为什么海量数据 Top K 选堆排序最"稳"?
这里的"稳"指的不是算法稳定性(堆排序本身是不稳定的),而是指性能的稳定性 和内存利用的极致优化。
1. 思路分析:内存与时间的博弈
假设我们要从 10亿个 整数中找到 最大的 100个 (K=100)。
-
方案 A:全排序(快排/归并)
- 你需要把 10亿个数全部读入内存。
- 10亿个 int 约占 4GB 内存。如果内存只有 1GB,程序直接崩溃。
- 时间复杂度: O ( N log N ) O(N \log N) O(NlogN)。
-
方案 B:堆排序(小顶堆法)
- 你只需要在内存中维护一个大小仅为 100 的小顶堆。
- 占用的内存微乎其微。
2. 答案:Top K 的具体操作逻辑
- 先取前 100 个数,构建一个小顶堆 。此时,堆顶是这 100 个数里最小的那个。
- 从第 101 个数开始,每一个数都跟堆顶比较:
- 如果这个数比堆顶还小,那它肯定不是前 100 大,直接扔掉。
- 如果这个数比堆顶大,说明它有资格进入前 100,用它替换堆顶,然后向下调整堆。
- 遍历完 10亿个数后,堆里的 100 个数就是我们要的结果。
为什么它更高效?
- 时间复杂度 :从 O ( N log N ) O(N \log N) O(NlogN) 降到了 O ( N log K ) O(N \log K) O(NlogK) 。因为 K K K 极小, log K \log K logK 几乎可以看作常数。
- 空间复杂度 :从 O ( N ) O(N) O(N) 降到了 O ( K ) O(K) O(K)。
- 稳定性(性能表现) :无论这 10亿个数是乱序的、准有序的,还是完全倒序的,堆排序的处理时间几乎是恒定的(每个数仅需一次比较和可能的一次 log K \log K logK 调整)。
1.5 快速排序
📝 算法定义 : 采用分治策略,通过一趟排序将序列分割成独立的两部分,基准值左侧均小于它,右侧均大于它,随后递归排序两部分。
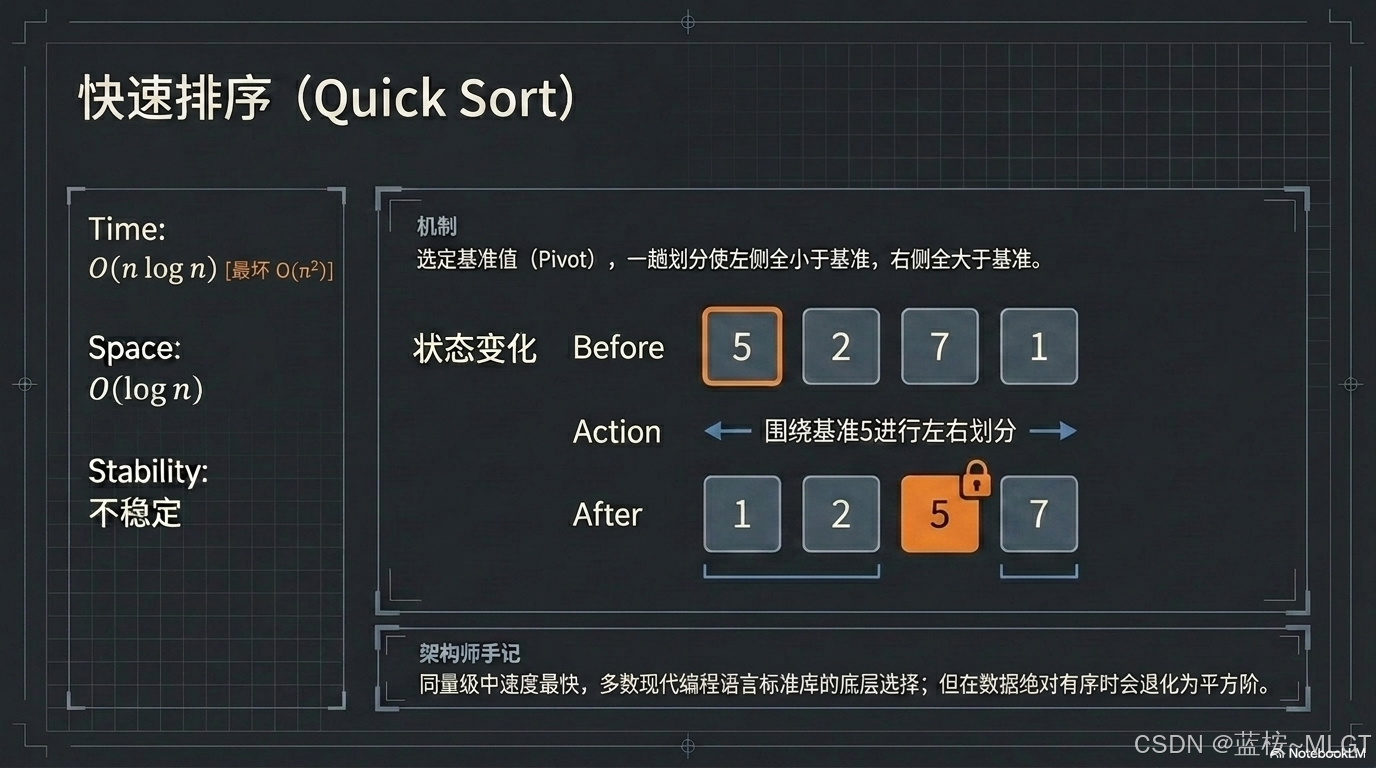
- 执行步骤图解 (示例:5, 2, 7, 1,基准 Pivot 取 5):
- 分区操作:设定指针移动,使得 5 左侧填充比它小的元素,右侧填充比它大的元素。
- 第一趟结果:1, 2, 5, 7。此时基准值 5 已固定在其最终位置。
- 递归阶段:分别对左侧 {1, 2} 和右侧 {7} 进行快排。
- 核心操作点: 基准分割(Partition)。
- 性能分析 : 平均时间复杂度
O(n \log n),最坏O(n^2),空间复杂度O(\log n)(源于递归调用的系统栈深度)。不稳定。 - 应用场景: 绝大多数编程语言标准库的默认首选算法。
快速排序以卓越的平均速度称霸,虽然存在极端退化的可能,但依然是现代软件工程中应用最广的排序基石。
1.6 归并排序
📝 算法定义: 采用分治法,将有序的子序列逐步合并,最终得到完整的有序序列。

-
执行步骤图解 (示例:处理 5, 2, 1, 4):
- 分解与预处理:将序列拆分为 5, 2 和 1, 4。
- 局部排序:在合并前,子序列必须有序。变为 2, 5 和 1, 4。
- 合并(Merge):
- 比较 2 与 1,取 1;
- 比较 2 与 4,取 2;
- 比较 5 与 4,取 4;
- 最后放入 5。
- 合并结果:1, 2, 4, 5。
-
核心操作点 : 双指针
有序序列合并。 -
性能分析 : 时间复杂度
O(n \log n),空间复杂度O(n)(需额外辅助数组),稳定。 -
应用场景: 外部排序(当数据量大到无法全部放入内存,需借助磁盘处理时)。
归并排序的逻辑极其整洁,其对稳定性的坚守和对大数据的友好使其在大型分布式计算中无可替代。
二、排序算法总结和比较

三、总结
排序是软考中占比比较大的,而且通常有时候比较难,因为各种排序混合在一起很容易混淆,所以专门提出来一章进行说明。