一、查找的基本概念
| 术语 | 定义 |
|---|---|
| 查找 | 在数据集合中寻找满足某种条件的数据元素的过程 |
| 查找表 | 用于查找的数据集合 |
| 静态查找表 | 仅涉及查找操作,无须动态修改(顺序查找、折半查找) |
| 动态查找表 | 需要支持插入或删除操作(二叉排序树查找) |
| 关键字 | 数据元素中唯一标识该元素的数据项 |
| 平均查找长度(ASL) | ASL = Σ Pᵢ·Cᵢ,衡量查找算法效率的核心指标 |
二、顺序查找和折半查找
2.1 顺序查找(线性查找)
适用于顺序表和链表,可用于无序表和有序表。
哨兵技巧:将ST.elem[0]设为哨兵,从后往前查找,避免循环中反复判断数组下标是否越界。
| 场景 | 成功ASL | 失败ASL |
|---|---|---|
| 无序表(等概率) | (n+1)/2 |
n+1 |
| 有序表(等概率) | (n+1)/2 |
n/2 + n/(n+1)(优于无序表) |
优化技巧:若已知各记录查找概率,应将记录按查找概率由大到小排列,使高频元素靠近查找起点。
2.2 折半查找(二分查找)
仅适用于关键字有序的顺序表(不支持链式存储)。
int BinarySearch(SSTable L, ElemType key) {
int low = 0, high = L.TableLen - 1, mid;
while (low <= high) {
mid = (low + high) / 2;
if (L.elem[mid] == key) return mid;
else if (L.elem[mid] > key) high = mid - 1;
else low = mid + 1;
}
return -1;
}判定树:平衡二叉树,树高h = ⌈log₂(n+1)⌉
| 指标 | 值 |
|---|---|
| 成功ASL | ≈ log₂(n+1) - 1 |
| 时间复杂度 | O(log₂n) |
注意:折半查找仅适用于顺序存储结构,且要求表中元素按关键字有序排列。
2.3 分块查找(索引顺序查找)
基本思想:将查找表划分为若干子块,块内可无序,块间有序(前一块的最大关键字 < 后一块的所有关键字)。建立索引表(最大关键字 + 起始地址)。
查找过程:
-
在索引表中确定待查记录所在的块(顺序查找或折半查找)
-
在目标块内进行顺序查找
ASL = 索引查找长度 + 块内查找长度
当均匀分块(n(总记录数)=b(块数)×s(每块大小)),索引表和块内均采用顺序查找时:
-
ASL = (b+1)/2 + (s+1)/2 = (s²+2s+n)/(2s) -
最优块大小
s = √n时,ASL_min = √n + 1
三、树形查找
3.1 二叉排序树(BST)
定义:左子树所有结点 < 根结点 < 右子树所有结点,左右子树也分别为BST。中序遍历得到递增序列。
基本操作:
| 操作 | 实现要点 |
|---|---|
| 查找 | 从根开始,逐层向下比较,选择左/右子树 |
| 插入 | 查找失败的位置即为插入位置,新结点必为叶结点 |
| 构造 | 从空树开始,依次插入元素(重复关键字被忽略) |
| 删除 | ①叶结点直接删;②仅有一棵子树,子树上移;③有两棵子树,用中序后继(或前驱)替代,转化为①或② |
查找效率:
-
平均:
O(log₂n) -
最坏:输入序列有序 → 单支树 →
O(n)
与二分查找对比:二分查找的判定树唯一,BST的形态取决于插入顺序。动态查找(频繁插入/删除)宜用BST,静态查找宜用二分查找。
3.2 平衡二叉树(AVL树)
定义:任意结点的左右子树高度差的绝对值 ≤ 1。平衡因子 = 左高 - 右高,取值 -1、0、1。
插入后的四种调整:
| 情况 | 描述 | 调整操作 |
|---|---|---|
| LL | 在A的左孩子的左子树插入 | 右单旋转 |
| RR | 在A的右孩子的右子树插入 | 左单旋转 |
| LR | 在A的左孩子的右子树插入 | 先左旋后右旋 |
| RL | 在A的右孩子的左子树插入 | 先右旋后左旋 |
性质:
-
查找时间复杂度:
O(log₂n) -
删除可能需要多次调整(向上回溯)
-
含n个结点的AVL树最大深度为
O(log₂n)
3.3 红黑树
红黑性质:
① 每个结点红或黑;② 根黑;③ 叶结点(NULL)黑;④ 无两个相邻红结点;⑤ 每个结点到任意叶结点的路径上黑结点数相同。
结论:
-
从根到叶的最长路径 ≤ 2 × 最短路径
-
有n个内部结点的红黑树高度
h ≤ 2log₂(n+1)
插入:新结点初始着为红色。根据叔结点颜色分三种情形调整。
与AVL对比:
| 场景 | 推荐 |
|---|---|
| 查找操作远多于插入/删除 | AVL树 |
| 插入/删除频繁 | 红黑树 |
实际应用:C++的
map/set、Java的TreeMap/TreeSet均基于红黑树实现。
四、B树和B+树
4.1 B树(多路平衡查找树)
m阶B树:每个结点至多m棵子树,所有叶结点在同一层次。
性质(根结点特殊):
| 结点类型 | 子树范围 | 关键字范围 |
|---|---|---|
| 根结点(非叶) | 2 ~ m | 1 ~ m-1 |
| 其他非叶结点 | ⌈m/2⌉ ~ m |
⌈m/2⌉-1 ~ m-1 |
| 叶结点 | 无子树 | 不存储数据 |
B树的高度(n个关键字):
-
最小高度:
h ≥ log_m(n+1) -
最大高度:
h ≤ log_{⌈m/2⌉}((n+1)/2) + 1
插入:结点关键字数达m时分裂 --- 中间关键字提升至父结点,左右分裂为两个结点。
删除:需保证结点关键字数 ≥ ⌈m/2⌉-1,否则需借位或合并。
4.2 B+树
m阶B+树:所有关键字和记录指针存储在叶结点中,叶结点通过指针按关键字顺序链接。
B树 vs B+树:
| 对比项 | B树 | B+树 |
|---|---|---|
| 关键字与子树关系 | n个关键字 → n+1棵子树 | n个关键字 → n棵子树 |
| 关键字范围 | ⌈m/2⌉-1 ~ m-1 |
⌈m/2⌉ ~ m |
| 关键字存储 | 所有结点 | 仅叶结点 |
| 非叶结点功能 | 存储关键字 | 仅索引(存储子结点最大值) |
| 支持顺序查找 | ❌ | ✅(叶结点链表) |
B+树常用于数据库索引,支持两种查找:顺序查找(从头指针)和多路查找(从根结点)。
五、散列表(Hash表)
5.1 基本概念
散列函数:
Hash(key) = Addr,将关键字映射到存储地址。
冲突:不同关键字映射到同一地址,这些关键字称为同义词。
5.2 散列函数的构造方法
| 方法 | 公式 | 特点 |
|---|---|---|
| 直接定址法 | H(key)=key 或 a·key+b |
无冲突,适用于关键字连续分布 |
| 除留余数法 | H(key)=key % p |
最常用,p为不超过m且接近m的质数 |
| 数字分析法 | 选取分布均匀的数位 | 适用于已知且固定的关键字集合 |
| 平方取中法 | 取关键字平方的中间几位 | 分布均匀,适用于位数较少的情形 |
5.3 处理冲突的方法
1. 开放定址法
Hᵢ = (H(key) + dᵢ) % m
| 方法 | 增量序列 | 特点 |
|---|---|---|
| 线性探测 | dᵢ = 1,2,...,m-1 |
易产生聚集(堆积) |
| 平方探测 | dᵢ = 1²,-1²,2²,-2²,... |
避免堆积,m需为4k+3的素数 |
| 双散列 | dᵢ = i·H₂(key) |
需两个散列函数 |
| 伪随机序列 | dᵢ = 第i个伪随机数 |
--- |
重要:开放定址法不能直接物理删除元素,否则会截断其他同义词的查找路径。应设置删除标记实现逻辑删除。
2. 拉链法(链地址法)
将散列到同一地址的所有同义词组织成一个链表。适用于频繁插入/删除的场景。
5.4 散列查找性能
装填因子:
α = 表中记录数 / 散列表长度,α越大,冲突概率越高。
影响ASL的三个因素:
-
散列函数
-
冲突处理方法
-
装填因子α
六、查找算法具体例子与图示
1、顺序查找
例子:在无序表中查找关键字 7
数据:[5, 3, 8, 1, 9, 2, 7, 4, 6](共9个元素)
查找过程:
索引: 0 1 2 3 4 5 6 7 8
值: 5 3 8 1 9 2 7 4 6
↑
第1次比较: 5≠7,继续
5\] \[3\] \[8\] \[1\] \[9\] \[2\] \[7\] \[4\] \[6
↑
第2次比较: 3≠7,继续
5\] \[3\] \[8\] \[1\] \[9\] \[2\] \[7\] \[4\] \[6
↑
第3次比较: 8≠7,继续
... 跳过中间 ...
5\] \[3\] \[8\] \[1\] \[9\] \[2\] \[7\] \[4\] \[6
↑
第6次比较: 2≠7,继续
5\] \[3\] \[8\] \[1\] \[9\] \[2\] \[7\] \[4\] \[6
↑
第7次比较: 7=7 查找成功,位置6
图示:
顺序查找过程(查找7):
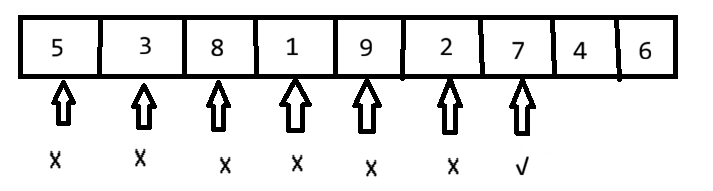
查找成功ASL = (1+2+...+9)/9 = 5
查找失败ASL = 10(需比较所有9个元素+哨兵)
2、折半查找
例子:在有序表中查找关键字 33
数据:[7, 10, 13, 16, 19, 29, 32, 33, 37, 41, 43](11个元素)
查找过程:
初始: low = 0, high = 10
7, 10, 13, 16, 19, 29, 32, 33, 37, 41, 43
↑ ↑
low high
第1次: mid = (0+10)/2 = 5 → 29
7, 10, 13, 16, 19, 29, 32, 33, 37, 41, 43
↑
mid
33 > 29 → 在右半部分,low = mid+1 = 6
第2次: low=6, high=10, mid = (6+10)/2 = 8 → 37
7, 10, 13, 16, 19, 29, 32, 33, 37, 41, 43
↑ ↑ ↑
low mid high
33 < 37 → 在左半部分,high = mid-1 = 7
第3次: low=6, high=7, mid = (6+7)/2 = 6 → 32
7, 10, 13, 16, 19, 29, 32, 33, 37, 41, 43
↑ ↑
(low) mid high
33 > 32 → 在右半部分,low = mid+1 = 7
第4次: low=7, high=7, mid = (7+7)/2 = 7 → 33
7, 10, 13, 16, 19, 29, 32, 33, 37, 41, 43
↑
(low) mid (high)
33 = 33 → 查找成功,位置7
图示(判定树):
折半查找判定树(n=11):
29
/ \
13 37
/ \ / \
7 16 32 41
\ \ \ \
10 19 33 43
(此处省略失败结点)
查找33的路径: 29 → 37 → 32 → 33(共4次比较)
ASL成功 = (1×1 + 2×2 + 3×4 + 4×4)/11 = 3
ASL失败 = (3×4 + 4×8)/12 ≈ 3.67
3、分块查找
例子:查找关键字 62
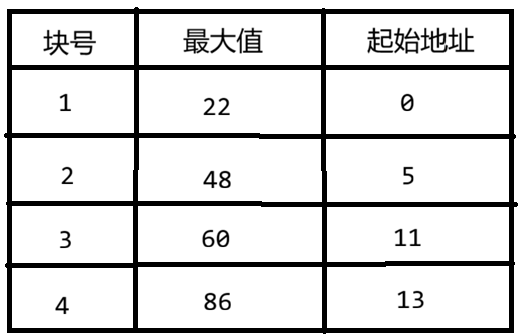
数据:[22, 12, 13, 9, 8, 33, 42, 44, 38, 24, 48, 60, 58, 74, 49, 86, 53]
分块规则:按值域分为4块
-
第1块:最大值 22(22,12,13,9,8)
-
第2块:最大值 48(33,42,44,38,24,48)
-
第3块:最大值 60(60,58)
-
第4块:最大值 86(74,49,86,53)
索引表:
查找过程:
第1步:在索引表中确定块
索引表: 22, 48, 60, 86
↑ ↑
22<62 ? 48<62 ? 60<62 ? 86>62
62 > 60,62 < 86 → 在第4块
第2步:在第4块内顺序查找
块4: 74, 49, 86, 53
↑ ↑ ↑ ↑
1 2 3 4
74≠62, 49≠62, 86≠62, 53≠62 → 查找失败
图示:
分块查找结构:
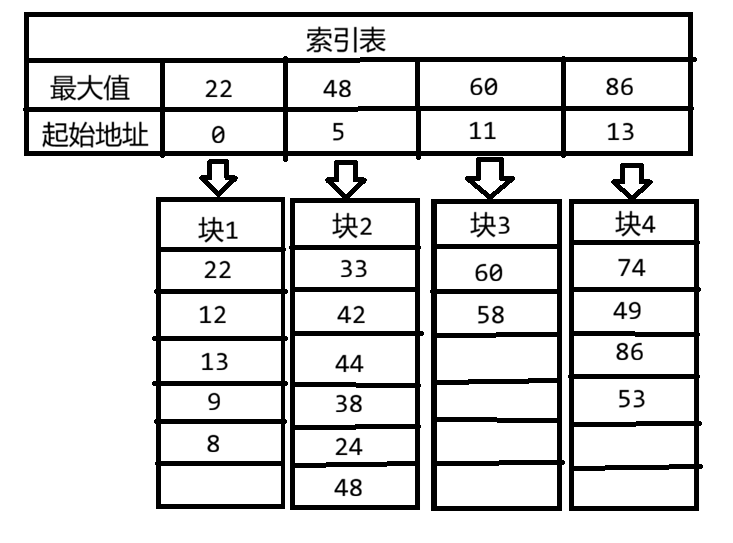
查找62: 索引表找到块4 → 块内顺序查找 → 未找到
4、二叉排序树(BST)
例子:构造BST并查找关键字 50
插入序列:[50, 30, 80, 20, 40, 70, 90, 35, 85]
构造过程:
(1) 插入50 (2) 插入30
50 50
/ \ / \
30
(3) 插入80 (4) 插入20
50 50
/ \ / \
30 80 30 80
/
20
(5) 插入40 (6) 插入70
50 50
/ \ / \
30 80 30 80
/ \ / \ /
20 40 20 40 70
(7) 插入90 (8) 插入35
50 50
/ \ / \
30 80 30 80
/ \ / \ / \ / \
20 40 70 90 20 40 70 90
/
35
(9) 插入85
50
/ \
30 80
/ \ / \
20 40 70 90
/ /
35 85
查找50的过程:
查找50:
50 ← 第1次比较: 50=50 查找成功
/ \
30 80
/ \ / \
20 40 70 90
/ /
35 85
比较次数: 1
查找35的过程:
查找35:
50 ← 第1次比较: 35<50,向左
/ \
30 80 ← 第2次比较: 35>30,向右
/ \ / \
20 40 70 90 ← 第3次比较: 35<40,向左
/ /
35 85 ← 第4次比较: 35=35
5、平衡二叉树(AVL)
例子:构造AVL树并演示LL旋转
插入序列:[30, 20, 10]
构造过程:
(1) 插入30 (2) 插入20
30 30
/ \ / \
20
平衡因子: 30:0 平衡因子: 30:1, 20:0
(3) 插入10
3
/ \
20
/
10
此时平衡因子: 30:2 不平衡!
插入位置: 30的左孩子的左子树 → LL型
LL旋转(右单旋):
旋转前: 旋转后:
30 20
/ \ / \
20 X 10 30
/ \ / \
10 Y Y X
其中X、Y为可能存在的子树
具体旋转:
旋转前: 旋转后:
30 20
/ / \
20 10 30
/
10
平衡因子: 30:2, 20:1, 10:0 → 20:0, 30:0, 10:0
6、B树
例子:3阶B树(每个结点最多2个关键字,最少1个)
插入序列:[50, 30, 80, 20, 40, 70, 90]
构造过程:
(1) 插入50 (2) 插入30
50\] \[30,50
(3) 插入80
30,50,80 → 结点满(3个关键字),分裂
中间关键字50提升为根
50
/ \
30\] \[80
(4) 插入20
50
/ \
20,30\] \[80
(5) 插入40
50
/ \
20,30,40 80 → 左孩子满,分裂
中间关键字30提升,插入父结点
30,50
/ | \
20\] \[40\] \[80
(6) 插入70
30,50
/ | \
20\] \[40\] \[70,80
(7) 插入90
30,50
/ | \
20 40 70,80,90 → 右孩子满,分裂
中间关键字80提升
30,50,80
/ | | \
20\] \[40\] \[70\] \[90
B树图示(最终形态):
30,50,80
/ | \ \
20\] \[40\] \[70\] \[90
(叶结点) (叶) (叶) (叶) (叶)
查找70: 根节点30<50<70<80 → 第3棵子树 → 找到70
7、散列表
例子:拉链法
关键字序列:[19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79]
散列函数:H(key) = key % 13
散列表结构:
索引 0: 1 → 14 → 27 → 79 → 53
索引 1: (空)
索引 2: 2 → 15 → 28 → 41 → 54
索引 3: 3 → 16 → 29 → 42 → 55
索引 4: 4 → 17 → 30 → 43 → 56
索引 5: 5 → 18 → 31 → 44 → 57
索引 6: 6 → 19 → 32 → 45 → 58
索引 7: 7 → 20 → 33 → 46 → 59
索引 8: 8 → 21 → 34 → 47 → 60
索引 9: 9 → 22 → 35 → 48 → 61
索引 10: 10 → 23 → 36 → 49 → 62
索引 11: 11 → 24 → 37 → 50 → 63
索引 12: 12 → 25 → 38 → 51 → 64
查找84的过程:
H(84) = 84 % 13 = 6
索引6的链表: 6 → 19 → 32 → 45 → 58 → 71 → 84
比较: 6≠84, 19≠84, 32≠84, 45≠84, 58≠84, 71≠84, 84=84
比较次数: 7次
例子:线性探测法
同一关键字序列,散列表长度16
构造过程:
H(19)=6: L6=19
H(14)=1: L1=14
H(23)=10: L10=23
H(1)=1: 冲突 → L2=1
H(68)=3: L3=68
H(20)=7: L7=20
H(84)=6: 冲突 → L8=84
H(27)=1: 冲突 → L4=27
H(55)=3: 冲突 → L5=55
H(11)=11: L11=11
H(10)=10: 冲突 → L12=10
H(79)=1: 冲突 → L9=79
最终散列表:
索引: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
值: 14 1 68 27 55 19 20 84 79 23 11 10
查找84:
H(84)=6: L6=19≠84
H₁=(6+1)=7: L7=20≠84
H₂=(6+2)=8: L8=84 查找成功,比较3次
各算法ASL总结表
| 算法 | 数据结构 | 成功ASL | 失败ASL | 时间复杂度 |
|---|---|---|---|---|
| 顺序查找 | 无序表 | (n+1)/2 | n+1 | O(n) |
| 折半查找 | 有序顺序表 | ≈log₂(n+1)-1 | ≈log₂(n+1) | O(log₂n) |
| 分块查找 | 分块表 | √n+1 | --- | O(√n) |
| BST(平衡) | 二叉树 | O(log₂n) | O(log₂n) | O(log₂n) |
| AVL | 二叉树 | O(log₂n) | O(log₂n) | O(log₂n) |
| 散列表(拉链) | 散列表 | 1+α/2 | α+e⁻ᵅ | O(1)~O(n) |
| 散列表(线性探测) | 散列表 | (1+1/(1-α))/2 | --- | O(1)~O(n) |
α为装填因子,通常取0.5~0.85
七、思考
- 折半查找 ≈ 猜数字游戏
每次猜中间的数,根据提示往左或往右缩小区间。这就是折半(二分)查找。
2. 二叉排序树 ≈ 查字典从中间翻开,比当前页小就往左翻,大就往右翻。BST就是这种"二分思维"的树形表达。
3. 平衡二叉树 ≈ 整理书架书架歪了就要调整,让左右两边高度差不多,这样才能保持查找效率。
4. 红黑树 ≈ 地铁线路图不是每条线路都完全对称(不像AVL那么严格),但整体平衡,保证从起点到任何站点的路径不会太长。
5. B树 ≈ 图书馆索书系统图书馆有很多书架(分支),每个书架有多层(关键字),根据索书号快速定位到书架和层,而不是一本一本找。
6. 散列表 ≈ 超市存包柜你的取件码(Hash值)直接告诉你柜子编号(地址),直接去开柜,不需要翻找。
注:以上内容参考 2027年数据结构考研复习指导 王道论坛 组编,其中有一些个人想法,如有任何错误或不妥,欢迎各位大佬指出,如果各位有一些有意思的想法,也可以和我交流一下~感谢!
八、明日计划
排序算法(上)