数据库运维管理正从"被动响应式"转向"主动平台化"。一款成熟的DB运维平台,不仅需要集中展示实例健康度,还需要提供实时干预、历史审计与自动化调度能力。本文基于实际产品截图中展现的功能模块,从技术专家视角拆解其设计逻辑、关键指标构成以及隐含的工程权衡。该平台覆盖了仪表板、实例管理、会话管理、告警中心、错误日志、巡检报告、SQL审计及自动化运维八大核心领域,基本形成了企业级数据库管控的闭环。
经过历时两周时间的打磨(中间多次与产品同事的讨论与沟通、与DB同事的不断探讨、加上多次DeBug...),DB运维平台v1.0版本终于可以上线了,第一阶段围绕着MySQL内核和PostgreSQL内核的数据库作为对象来进行实践。以下功能的解析(因脱敏需要,本案例的截图数据均为测试样本数据仅供平台功能解析说明使用)。欢迎关注wechat公众号-"墨者阳"了解后续。
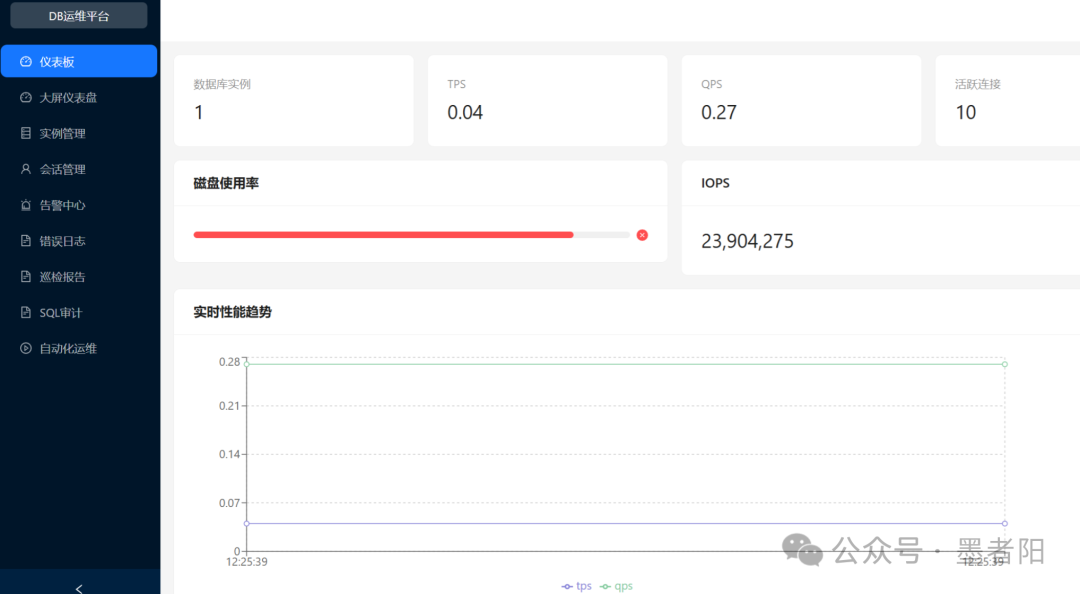
📊截图-仪表板总览:顶部展示TPS=0.04、QPS=0.27、活跃连接=10,磁盘使用率、IOPS及错误日志总条数(23,904,275)并列。右侧实时性能趋势曲线在时间轴12:25:39附近呈现小幅波动。该布局将吞吐量、连接负载与存储层指标融合,便于快速识别资源瓶颈。
从仪表板设计看,平台没有堆砌数十个指标,而是选择了四个核心KPI:TPS/QPS表征业务压力,活跃连接数反映并发竞争,磁盘使用率与IOPS则直接关联存储瓶颈。值得一提,总量接近两千四百万的错误日志计数暗示该系统可能长期记录了大量INFO级别探活日志或异常堆栈,这提示运维团队需要调整日志采样策略。多数情况下,过度记录反而会掩盖真正的错误风暴。
实例管理与资源画像:健康评分与TOP榜单的决策价值
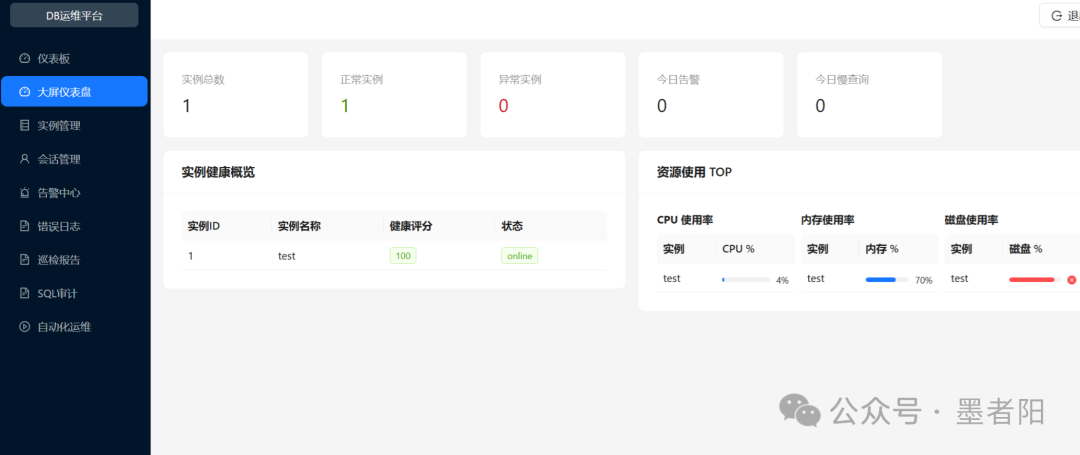
🗂️ 实例管理界面:实例列表中展示"test"(MySQL,端口3306,状态online),并提供删除操作。健康概览卡片显示实例总数1、正常实例1、异常实例0、今日告警0、今日慢查询0。资源使用TOP表分别列出CPU%、内存%、磁盘%最高的实例(均为test,CPU 4%,内存70%,磁盘占用未定量但后续告警揭示磁盘使用率达87.1%)。
实例管理模块不止于增删查改。它引入"健康评分"和"资源使用TOP"两个聚合视图,本质上对多实例场景进行降维排序。例如内存使用率70%虽然未达到警戒线,但若业务持续增长,可能面临swap或OOM风险。TOP榜单尤其适合混合部署环境,能快速定位资源争抢的"吵闹邻居"。不过,当前健康评分算法较简单(100分制且仅基于基础运行状态),若能将慢查询频率、复制延迟、死锁频率纳入评分模型,会更贴现实。
操作层面支持删除实例属于高危动作。平台应增加二次确认或软删除机制,但从界面看仅有一处"删除"按钮,设计上更偏向于实验或测试环境。在生产实践中,建议额外增加实例保护锁,避免误操作。
会话管理:实时连接可视化与主动干预
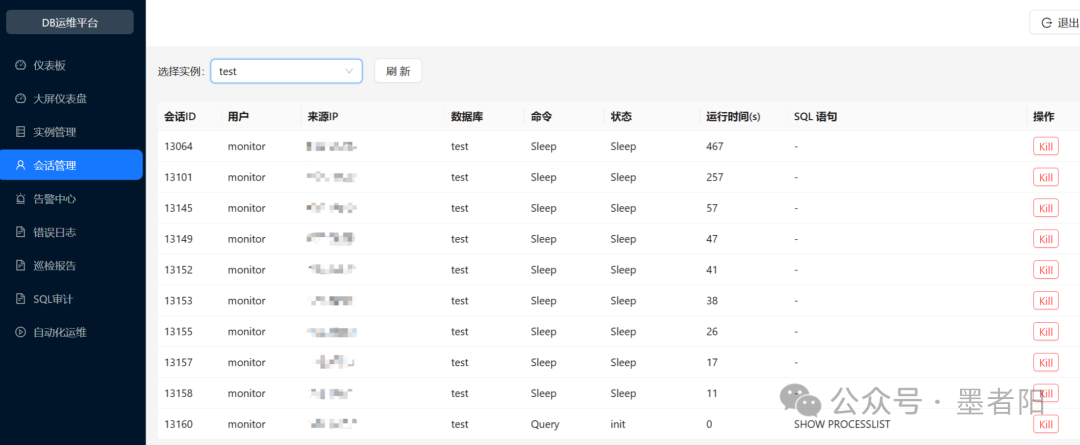
💬 会话管理:选定test实例后,展示会话ID、用户(monitor)、来源IP、数据库(test)、命令(Sleep/Query)、运行时间(最长467秒)及当前SQL。每个会话尾部提供"Kill"操作。列表底部有一条Query状态的会话执行"SHOW PROCESSLIST"。
会话管理直面数据库并发连接的真实状态。从截图中可见大量monitor用户的Sleep连接,运行时间从数十秒到数百秒不等,这通常表明应用侧连接池未正确回收连接或监控工具采用了长轮询方式。运维人员可以依据运行时间排序,批量kill空闲过长的会话。一个容易被忽视的细节是:平台本身用于拉取会话的SQL(SHOW PROCESSLIST)也出现在会话列表中。这属于"自观测"现象,无伤大雅,但说明该平台使用普通数据库账号进行监控,未采用系统表 bypass 方式。在连接数极高的场景下,频繁查询performance_schema可能会有一定开销,此处的实现需权衡。
技术上更合理的做法是提供"终止查询"和"终止连接"两种粒度的操作,目前仅支持Kill connection。对于复杂的事务回滚场景,单纯kill连接可能导致大量回滚操作,影响IO。平台没有显式提示这一风险,建议后续版本增加二次确认弹窗,告知用户可能的回滚时长。
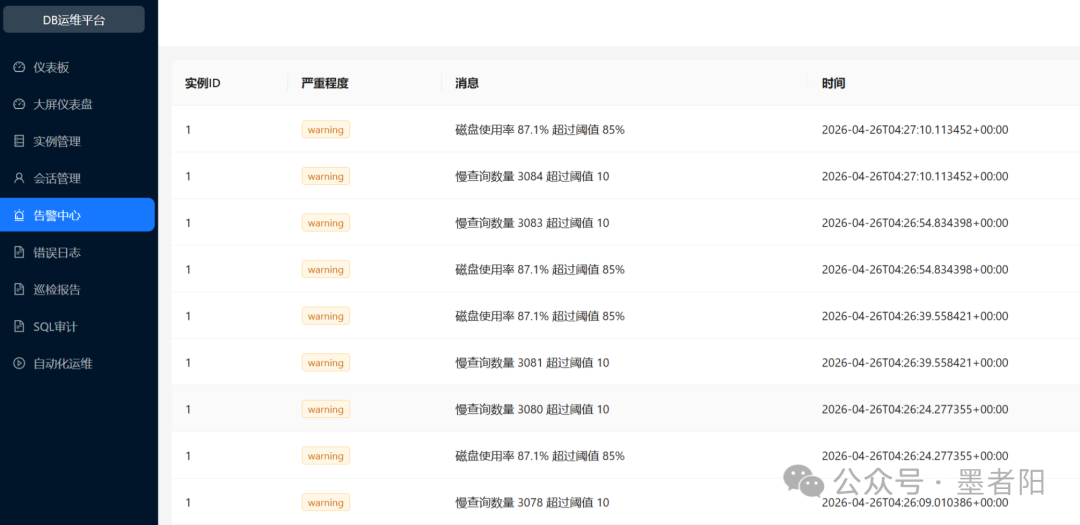
告警中心:基于阈值的主动预警与事件风暴抑制
⚠️ 告警中心:连续告警记录显示磁盘使用率87.1% > 阈值85%,慢查询数量3084 > 阈值10,时间戳从04:26:09至04:27:10,同类型告警密集出现。每条告警标注严重程度(warning)、消息内容和精确时间。
告警中心的规则引擎设计较为直观:阈值比较+时间戳序列。然而从数据来看,同一个实例在短短一分钟内触发了超过八次重复告警,显然缺乏告警聚合与静默机制。这种做法虽然保证了事件不丢失,但会造成告警风暴,让运维人员产生"狼来了"的疲惫感。更成熟的方案应当引入告警分组、抑制窗口和升级策略。例如磁盘使用率持续超过85%每10分钟仅发送一次,直到恢复或升级为critical。
另一方面,慢查询阈值设为10是否合理?从拥有3084个慢查询的实例来看,该阈值可能过于敏感,或者系统中存在未使用索引的全表扫描。平台应该允许动态阈值,根据历史基线自动调整,而不是固定值。目前许多AIOps方案已引入动态告警,但该平台仍以静态阈值为主,适合初期部署,定制化尚有提升空间。
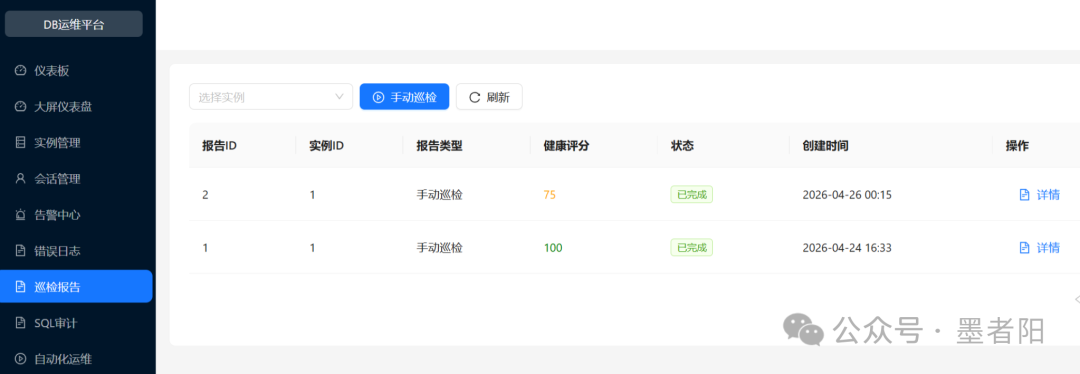
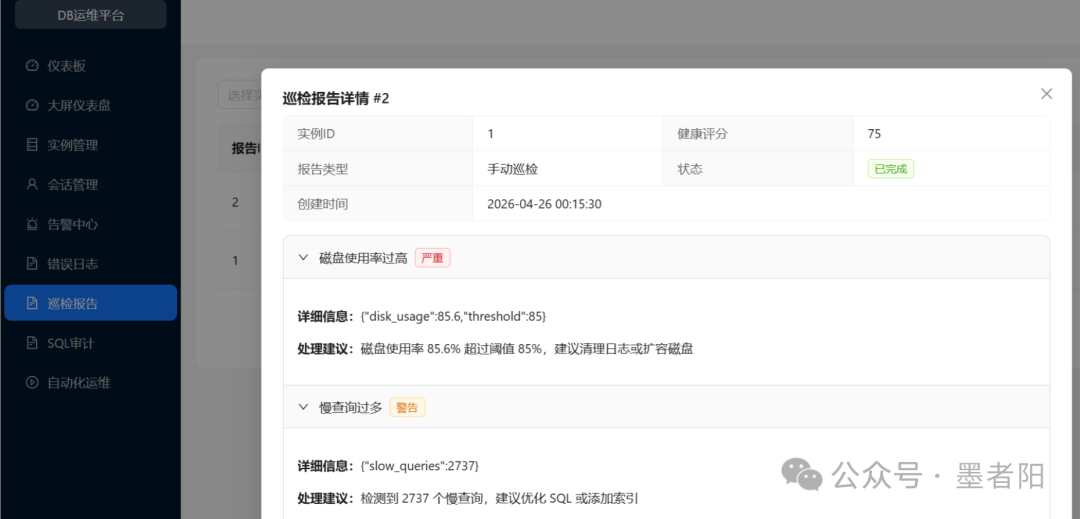
巡检报告与错误日志:深度诊断的"专业系统"雏形
📄 巡检报告详情:报告ID 2,实例ID 1,健康评分75,类型手动巡检。详情中包含"磁盘使用率过高严重"和"慢查询过多警告",并提供处理建议(清理日志/扩容磁盘,优化SQL/添加索引)。错误日志界面显示针对test实例的检索结果为"MySQL运行正常,未检测到近期严重错误"。
巡检报告不仅仅是数据采集器,它内置了规则化的诊断建议。例如检测到磁盘使用率85.6%(阈值85%),建议清理或扩容;检测到2737个慢查询,建议添加索引。这表明平台已经将一部分DBA的经验固化为判断逻辑,形成了可复用的"运维知识库"。不过,建议的颗粒度尚显粗放------未指明具体哪个表或哪个慢查询模式,也难以自动生成索引语句。若能与SQL审计模块联动,提取top 10慢查询模板并给出索引建议,则更接近自治运维。
错误日志虽然显示"未检测到严重错误",但结合告警中心频繁的warning,实际上系统处于亚健康状态。日志模块的级别过滤(INFO/WARNING/ERROR)较为基础,缺少上下文关联能力。从技术视角看,错误日志应该与巡检报告双向链接,比如点击巡检发现的"磁盘使用率过高",自动跳转到相应时间段的系统日志或操作系统磁盘空间指标,目前界面并未呈现这种跨模块联动。
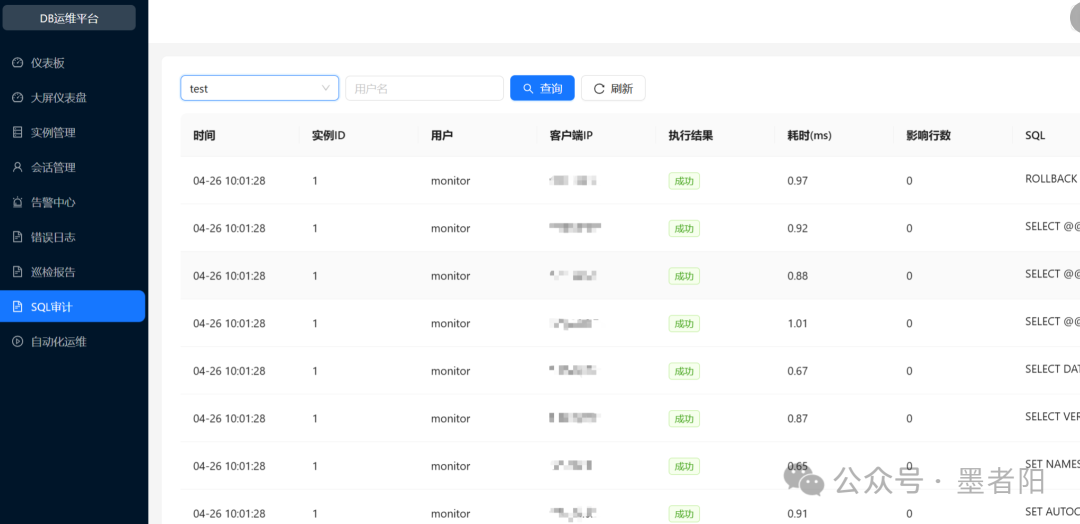
SQL审计:全量操作溯源与性能分析基础
📝 截图-SQL审计:记录时间2026-04-26 10:01:28,实例ID 1,用户monitor,执行结果成功,耗时0.65ms~1.01ms,影响行数0。SQL包括ROLLBACK、SELECT VERSION()、SET NAMES utf8mb4、SELECT DATABASE()等探活语句。
SQL审计是安全合规和故障回溯的关键组件。该平台捕获了每条SQL及其执行耗时、影响行数与客户端IP,粒度满足等保三级要求。从采样数据看,monitor用户产生了大量连接探活语句(如ROLLBACK、SET AUTOCOMMIT等),虽然单条耗时极短,但频繁执行也会给数据库带来CPU syscall开销。如果实例规模扩大至上百个,审计日志的存储量会爆炸式增长。因此,实际部署中通常只对特定用户或特定操作类型(如DDL、DML with rows>1000)进行详细审计。
目前界面中未提供基于耗时阈值的过滤(例如只显示大于100ms的慢SQL)。若能在审计模块嵌⼊耗时排序和聚合分析,则对性能优化更友好。不过作为起点,完整的审计留存已经是坚实一步。
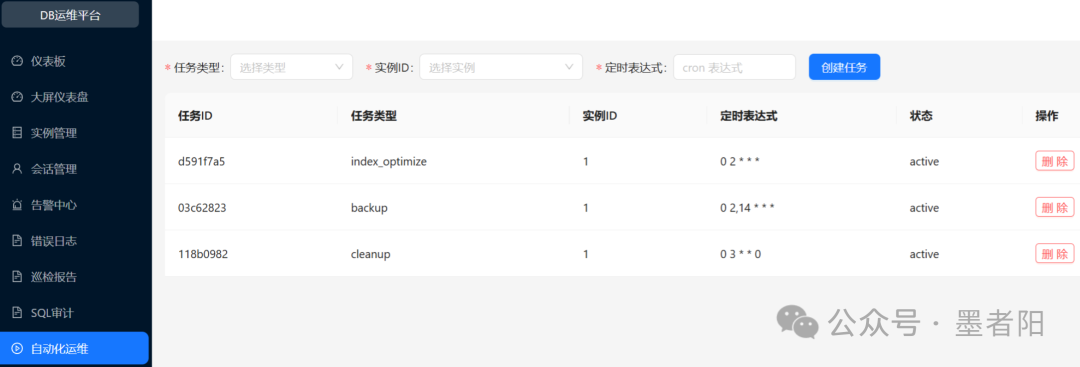
自动化运维:定时任务与Cron驱动的无人值守操作
🤖 自动化运维:支持创建任务(任务类型包括index_optimize, backup, cleanup),实例ID选择及Cron表达式输入。任务列表展示三个活动任务:index_optimize (0 2 * * *),backup (0 2,14 * * *),cleanup (0 3 * * 0)。每个任务可删除。
自动化运维模块将周期性、重复性操作从人工转为定时调度。这里使用的Cron表达式是一种标准且灵活的描述方式,支持每天凌晨2点索引优化、每天2和14点备份、每周日凌晨3点清理。一个值得讨论的设计点是任务类型中的"index_optimize"------该操作通常需要谨慎锁表,在生产环境建议使用online DDL或pt-online-schema-change工具封装。当前平台并未展示任务的具体实现细节,可能只发送优化指令,也可能调用第三方工具。若缺少锁表风险管理,可能引发业务抖动。考虑到可靠运维,应提供"并发控制"、"任务超时回滚"等配置。
任务列表只展示了active状态,无法查看历史执行记录或失败重试次数。成熟的企业级需求还应包括执行日志、执行结果的回调通知。总体来看,该模块奠定了自动化基座,后续可向"编排引擎"演化,构建数据库运维的标准化作业平台(Ops as Code)。
这套DB运维平台目前更侧重于"可见即所得",对于智能推荐、根因分析、自愈闭环等能力涉及较少。例如告警中心缺乏动态基线,可能会产生噪音;巡检报告提供建议但不支持自动执行(如自动清理日志)。设计团队显然优先保证了基础功能的稳定性和易用性,而不是一步到位追求全自动驾驶。这种取舍在多数企业内部场景中是合理的------先解决80%的显性痛点,再逐步迭代。而且,保留一定的人工决策节点,反而可以避免完全自动化带来的意外风险。
总体而言,该平台体现了"可观测性+可干预性+可重复性"的现代运维理念,是走向数据库自治的重要中间形态。后续再根据实践需求和'用户'需求再进行迭代。