最近逆向分析了 Claude Design(内部代号 Omelette)的前端编译产物,发现了一个让人意外的事实:完整的 Agent 智能逻辑全在前端 。后端只做两件事------中转 Claude API 和项目数据 CRUD。也就是说,prompt 构建、工具定义、工具调度、agent 循环、上下文管理,全跑在浏览器里。代码:github.com/lizuncong/s...
这篇文章我们用最少的代码,在浏览器里复刻一个能跑的 mini 版 Claude Design harness。接入智谱 AI(GLM)大模型,实现真实的 LLM 调用和 tool-use 循环。
最近在跟睿博学习agent开发,有兴趣可以关注:github.com/Dr-Corgi/Op...
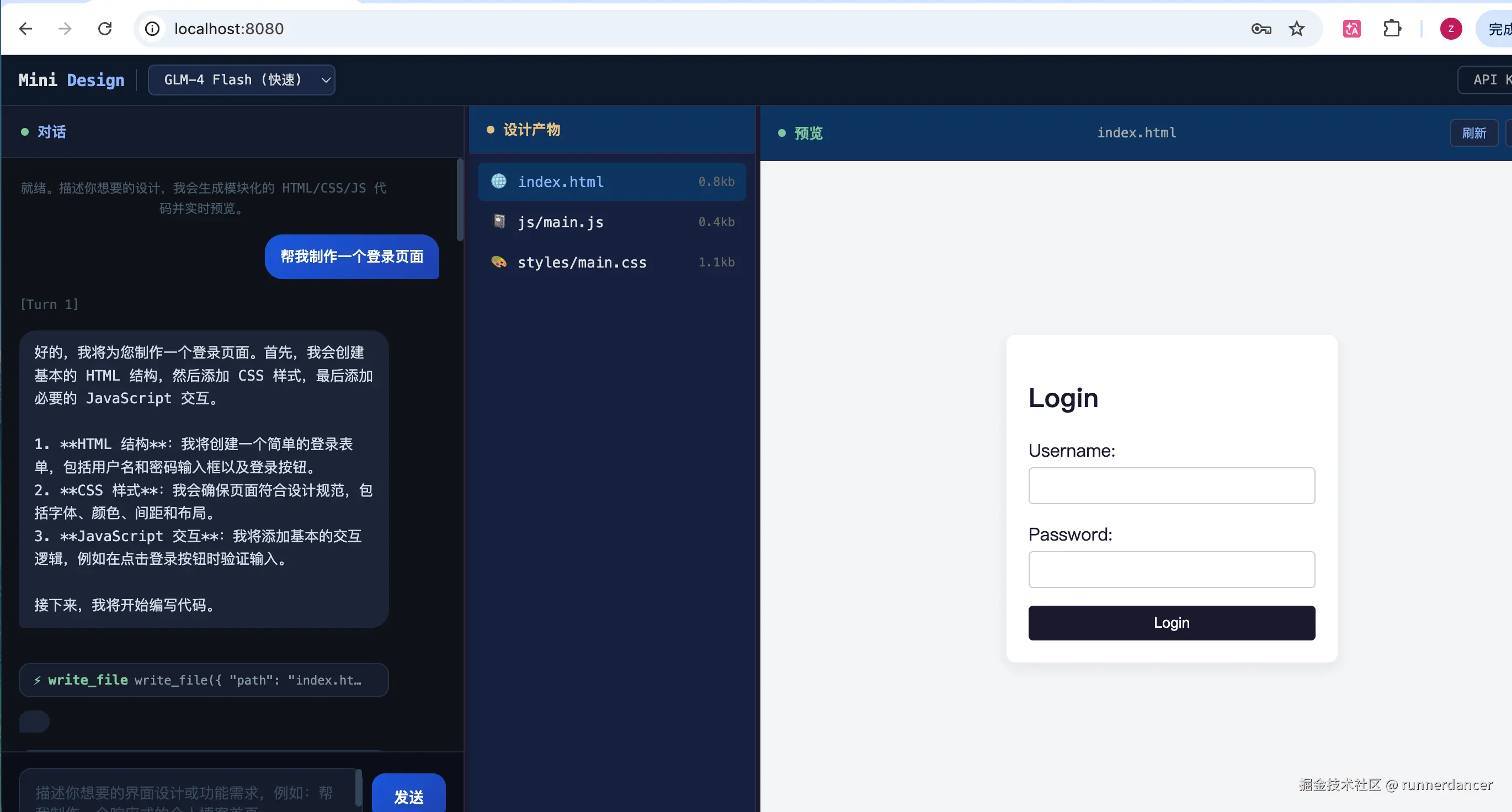
最终效果
在浏览器打开一个 HTML 文件,输入智谱 AI API Key,然后输入"帮我创建一个按钮组件",agent 会自动:
- 调用
write_file写入按钮代码 - 调用
read_file确认文件内容 - 输出完成消息
首次使用需在弹窗中输入智谱 AI API Key(前往 open.bigmodel.cn 注册获取)。
效果预览:
一、为什么 Agent 的智能在前端?
你可能习惯了后端跑 agent、前端只负责渲染的模式。LangChain、Vercel AI SDK 基本都是这么干的。但 Claude Design 选择了完全不同的路线。
看一眼它的架构就明白了:
bash
┌─────────────────────────────────────────┐
│ 浏览器(前端 harness) │
│ ├─ System Prompt 构建 │
│ ├─ 工具注册表 + 调度器 │
│ ├─ Agent Loop(while 循环) │
│ ├─ 上下文管理(Snip 裁剪) │
│ └─ 流式 UI 渲染 │
└──────────────┬──────────────────────────┘
│ gRPC 转发
▼
┌─────────────────────────────────────────┐
│ 后端服务 │
│ ├─ /design/v1/design/ → Claude API │
│ └─ 项目数据 CRUD │
└─────────────────────────────────────────┘为什么要这么做?
- 低延迟。工具执行在前端,比如读文件、展示预览,不需要绕一圈服务器
- 流式交互。模型一边生成代码,前端一边渲染预览,体验上接近"实时编程"
- 离线可用。即使后端挂了,工具系统还能工作
代价就是前端要承担更多逻辑。但这些逻辑并不复杂------核心就是一个 while 循环。
二、消息格式 --- OpenAI Function Calling 协议
在动手之前,得先搞清楚 OpenAI 兼容 API 的消息格式。这是整个 harness 的基础。
智谱 AI 提供 OpenAI 兼容接口,我们直接使用 OpenAI 的 function calling 协议:
javascript
// 1. 发给 API 的消息列表
const messages = [
{
role: 'user',
content: '帮我创建一个按钮组件'
},
{
role: 'assistant',
content: '好的,我来帮你创建。',
tool_calls: [
{
id: 'call_01ABC',
type: 'function',
function: {
name: 'write_file',
arguments: '{"path":"Button.html","content":"<button>Click</button>"}'
}
}
]
},
{
role: 'tool',
tool_call_id: 'call_01ABC',
content: 'Written Button.html (24 chars)'
}
];
// 2. API 返回的响应
const response = {
choices: [{
message: {
role: 'assistant',
content: '文件已创建。',
tool_calls: null
},
finish_reason: 'stop' // 或 'tool_calls'
}],
usage: { prompt_tokens: 100, completion_tokens: 50 }
};关键点:
- assistant 消息可以同时包含 content 和 tool_calls。模型说"我来帮你创建"的同时调用工具
- tool 结果使用 role: 'tool' 发送 。必须包含
tool_call_id来匹配对应的调用 - finish_reason 决定循环走向 :
tool_calls→ 继续循环,stop→ 结束
这个消息格式就是我们整个 agent loop 的骨架。
三、工具系统 --- 注册表 + 调度器
在 Claude Design 的源码里,工具系统用一个全局 Map 管理所有工具:
javascript
// 源码中的工具注册
const iN = [...S4, ...k8, ...R8, ...t6, ...s6, ...w6, ...F6, ...L6];
const Lu = new Map(iN.map(e => [e.name, e]));我们的 mini 版本也照这个模式来。
3.1 工具注册表
javascript
// tools/index.js
export const toolRegistry = new Map();
export function registerTool(def) {
toolRegistry.set(def.name, def);
}
export function getToolDefinitions() {
return [...toolRegistry.values()]
.filter(t => !t.enabled || t.enabled())
.map(t => ({
name: t.name,
description: t.description,
input_schema: t.input_schema,
}));
}
export async function dispatchTool(toolName, input, ctx) {
const tool = toolRegistry.get(toolName);
if (!tool?.execute) {
return `Unknown tool: ${toolName}`;
}
return await tool.execute(input, ctx);
}三个函数:
registerTool--- 注册工具到 MapgetToolDefinitions--- 返回给 API 的工具列表(过滤掉被禁用的)dispatchTool--- 根据名字执行工具
3.2 工具定义
每个工具长这样:
javascript
// tools/filesystem.js
const fileStore = new Map(); // 内存文件系统
const fsTools = {
write_file: {
name: 'write_file',
description: 'Write content to a file in the project...',
input_schema: {
type: 'object',
properties: {
path: { type: 'string', description: 'File path' },
content: { type: 'string', description: 'The file content' },
},
required: ['path', 'content'],
},
async execute({ path, content }) {
fileStore.set(path, content);
return `Written ${path} (${content.length} chars)`;
},
},
// read_file, list_files 同理...
};对应 Claude Design 源码中的结构:
typescript
type ToolDef = {
name: string;
description: string;
input_schema: { type; properties; required };
enabled?: () => boolean;
execute?: (input, ctx) => string;
executeMidstream?: (partialJson, ctx) => void;
};我们的 mini 版只保留 name、description、input_schema、execute,其他的先不实现。
3.3 注册工具
在 agent.js 里统一注册:
javascript
import fsTools from './tools/filesystem.js';
import { registerTool } from './tools/index.js';
import snipTool from './tools/snip.js';
for (const tool of Object.values(fsTools)) {
registerTool(tool);
}
registerTool(snipTool);Claude Design 在初始化时会注册十几个工具组(文件操作、视图控制、质量保证、Figma 集成...),我们的 mini 版只有 4 个:write_file、read_file、list_files、snip。
四、真实 LLM 调用 --- 接入智谱 AI (GLM)
我们使用智谱 AI 的 OpenAI 兼容接口来实现真实的 LLM 调用。API 端点:https://open.bigmodel.cn/api/paas/v4/chat/completions。
由于智谱 AI 提供 OpenAI 兼容接口,我们可以直接使用 OpenAI 的 function calling 格式,无需任何格式转换。
4.1 API Key 管理
API Key 通过 localStorage 持久化:
javascript
export function getApiKey() {
return localStorage.getItem('zhipu_api_key') || '';
}
export function setApiKey(key) {
localStorage.setItem('zhipu_api_key', key);
}
export function hasApiKey() {
return !!getApiKey();
}4.2 非流式调用
javascript
export async function callZhipuAPI(messages, tools, systemPrompt, options = {}) {
const apiKey = getApiKey();
if (!apiKey) {
throw new Error('未设置智谱 AI API Key,请先在页面顶部设置');
}
const body = {
model: 'glm-4-flash',
messages: [
{ role: 'system', content: systemPrompt },
...messages,
],
max_tokens: options.maxTokens || 64000,
temperature: options.temperature ?? 0.7,
};
if (tools && tools.length > 0) {
body.tools = tools;
body.tool_choice = 'auto';
}
const resp = await fetch('https://open.bigmodel.cn/api/paas/v4/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`,
},
body: JSON.stringify(body),
});
if (!resp.ok) {
const errorBody = await resp.text();
let errorMsg = `API 请求失败 (${resp.status})`;
try {
const errJson = JSON.parse(errorBody);
errorMsg = errJson.error?.message || errJson.message || errorMsg;
} catch {}
throw new Error(errorMsg);
}
return await resp.json();
}4.3 流式调用(SSE)
流式输出让用户能实时看到模型的回复,体验更流畅:
javascript
export async function callZhipuStream(messages, tools, systemPrompt, callbacks = {}, options = {}) {
const apiKey = getApiKey();
if (!apiKey) {
throw new Error('未设置智谱 AI API Key,请先在页面顶部设置');
}
const body = {
model: 'glm-4-flash',
messages: [
{ role: 'system', content: systemPrompt },
...messages,
],
max_tokens: options.maxTokens || 64000,
temperature: options.temperature ?? 0.7,
stream: true,
stream_options: { include_usage: true },
};
if (tools && tools.length > 0) {
body.tools = tools;
body.tool_choice = 'auto';
}
const resp = await fetch('https://open.bigmodel.cn/api/paas/v4/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`,
},
body: JSON.stringify(body),
});
const reader = resp.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
const accumulated = {
content: '',
tool_calls: [],
usage: { prompt_tokens: 0, completion_tokens: 0 },
finish_reason: null,
};
while (true) {
const { done, value } = await reader.read();
if (done) {
break;
}
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split('\n');
buffer = lines.pop() || '';
for (const line of lines) {
const trimmed = line.trim();
if (!trimmed || trimmed === 'data: [DONE]' || !trimmed.startsWith('data: ')) {
continue;
}
try {
const chunk = JSON.parse(trimmed.slice(6));
const delta = chunk.choices?.[0]?.delta || {};
// 文本增量
if (delta.content) {
accumulated.content += delta.content;
if (callbacks.onTextChunk) {
callbacks.onTextChunk(delta.content);
}
}
// 工具调用增量
if (delta.tool_calls) {
for (const tc of delta.tool_calls) {
const idx = tc.index ?? 0;
if (!accumulated.tool_calls[idx]) {
accumulated.tool_calls[idx] = { id: '', type: 'function', function: { name: '', arguments: '' } };
}
if (tc.id) {
accumulated.tool_calls[idx].id = tc.id;
}
if (tc.function?.name) {
accumulated.tool_calls[idx].function.name += tc.function.name;
}
if (tc.function?.arguments) {
accumulated.tool_calls[idx].function.arguments += tc.function.arguments;
}
}
}
if (chunk.choices?.[0]?.finish_reason) {
accumulated.finish_reason = chunk.choices[0].finish_reason;
}
if (chunk.usage) {
accumulated.usage = chunk.usage;
}
} catch {}
}
}
return {
choices: [{
message: {
role: 'assistant',
content: accumulated.content || null,
tool_calls: accumulated.tool_calls.filter(tc => tc.id),
},
finish_reason: accumulated.finish_reason || 'stop',
}],
usage: accumulated.usage,
};
}流式调用的关键点:
- 增量累积 :
delta.content和delta.tool_calls都是增量,需要累积 - tool_calls 的 index :多个工具调用通过
index区分,需要按索引累积 - 回调通知 :每收到一个文本 chunk 就调用
onTextChunk,实现实时渲染
五、Agent Loop --- 整个系统的核心
这里是重头戏。Claude Design 的 agent loop 对应源码中的 _te() 函数,大约 400 行压缩代码。我们用不到 100 行实现一个最小版本。
核心逻辑就是一个 while 循环:
arduino
┌──────────────────────────────────────┐
│ while (turnCount < MAX_TURNS) { │
│ 1. 组装消息 + token 预算检查 │
│ 2. 调用 LLM(流式) │
│ 3. 检查 finish_reason │
│ 4. 有 tool_calls → 执行 → 追加结果│
│ 5. stop → 返回 │
│ } │
└──────────────────────────────────────┘5.1 完整实现
javascript
// agent.js
export async function runAgent(userInput, {
onText,
onStreamText,
onToolCall,
onToolResult,
onDone,
onSnip
} = {}, existingMessages = []) {
const messages = existingMessages.length > 0 ? [...existingMessages] : [];
const { getToolDefinitions } = await import('./tools/index.js');
const rawTools = getToolDefinitions();
// 转换为 OpenAI 工具格式
const tools = rawTools.map(t => ({
type: 'function',
function: {
name: t.name,
description: t.description,
parameters: t.input_schema,
},
}));
let turnCount = 0;
const MAX_TURNS = 10;
while (turnCount < MAX_TURNS) {
turnCount++;
// 1. 追加 user 消息(带 [id:mNNNN] 标签)
if (userInput) {
const taggedContent = tagUserMessage(userInput);
messages.push({ role: 'user', content: taggedContent });
}
// 2. Token 预算检查
const estimated = estimateTokens(messages, SYSTEM_PROMPT);
if (estimated > MAX_TOKENS * 0.8) {
const idsToRemove = executeSnips(messages);
if (idsToRemove.size > 0) {
const before = messages.length;
const trimmed = trimMessages([...messages], idsToRemove);
messages.length = 0;
messages.push(...trimmed);
onSnip(before, messages.length);
}
}
onText(`\n[Turn ${turnCount}] `);
// 3. 流式调用 LLM
let fullContent = '';
const apiResp = await callZhipuStream(messages, tools, SYSTEM_PROMPT, {
onTextChunk(chunk) {
fullContent += chunk;
onStreamText(chunk);
},
});
const choice = apiResp.choices[0];
const msg = choice.message;
const usage = apiResp.usage || { prompt_tokens: 0, completion_tokens: 0 };
const finishReason = choice.finish_reason;
// 4. 追加 assistant 消息
const assistantMsg = { role: 'assistant', content: msg.content || '' };
if (msg.tool_calls) {
assistantMsg.tool_calls = msg.tool_calls;
}
messages.push(assistantMsg);
if (fullContent) {
onText('\n');
}
// 5. 根据 finish_reason 决定下一步
if (finishReason !== 'tool_calls' || !msg.tool_calls || msg.tool_calls.length === 0) {
onDone(usage);
return messages;
}
// 6. 执行工具,追加 tool 结果
for (const tc of msg.tool_calls) {
const fn = tc.function;
const input = typeof fn.arguments === 'string' ? JSON.parse(fn.arguments) : fn.arguments;
onToolCall(fn.name, input);
const { dispatchTool } = await import('./tools/index.js');
try {
const result = await dispatchTool(fn.name, input, {});
onToolResult(fn.name, result);
messages.push({
role: 'tool',
tool_call_id: tc.id,
content: typeof result === 'string' ? result : JSON.stringify(result),
});
} catch (err) {
const errContent = `Error: ${err.message}`;
onToolResult(fn.name, errContent);
messages.push({
role: 'tool',
tool_call_id: tc.id,
content: errContent,
});
}
}
// 7. 后续轮次不再追加新 user 消息
userInput = '';
}
onText('\n[Agent] 达到最大轮次限制\n');
return messages;
}5.2 关键改进
相比之前的版本,教学版做了以下改进:
- 流式输出 :使用
callZhipuStream实现实时文本渲染 - OpenAI 原生格式 :无需格式转换,直接使用
tool_calls和toolrole - 对话持久化 :支持传入
existingMessages,实现多轮对话
5.3 和 Claude Design 源码的对应关系
| 我们的代码 | Claude Design 源码 | 说明 |
|---|---|---|
while (turnCount < MAX_TURNS) |
for(;;) + turn break |
主循环 |
callZhipuStream() |
dQ() |
流式 LLM 调用 |
dispatchTool() |
Rx() |
工具调度器 |
estimateTokens() |
fj() |
Token 估算 |
executeSnips() |
vj() |
Snip 批量执行 |
tagUserMessage() |
消息 ID 系统 | [id:mNNNN] 标签 |
finish_reason 分支 |
_te() 内的条件判断 |
tool_calls / stop |
Claude Design 的 _te() 还有很多我们没有实现的逻辑:AbortController 中断处理、follow-up 消息注入、prompt caching、消息清洗管线...但这些不影响理解核心骨架。
六、上下文管理 --- Snip 延迟裁剪
长对话的问题是:消息会越来越多,最终超出模型的 context window。怎么处理?
最简单的方案是"从尾部截断"。但这样做很粗暴------可能把正在进行的任务中间结果给删了。
Claude Design 的方案精妙得多:让模型自己决定丢什么。
6.1 消息 ID 系统
每条 user 消息自动附加一个 ID 标签:
javascript
export function tagUserMessage(content) {
const id = `m${String(++msgIdCounter).padStart(4, '0')}`;
return `${content}\n[id:${id}]`;
}
// 输出: "帮我创建一个按钮\n[id:m0001]"这样每条消息就有了唯一的寻址标识。
6.2 Snip 的注册-执行分离
Snip 工具是整个机制的核心。模型调用 snip 时,系统只做标记,不立刻删除:
javascript
const snipTool = {
name: 'snip',
description: 'Mark a range of conversation history for deferred removal...',
input_schema: {
properties: {
from_id: { type: 'string' },
to_id: { type: 'string' },
reason: { type: 'string' },
},
required: ['from_id', 'to_id'],
},
async execute({ from_id, to_id, reason }) {
registeredSnips.push({ from_id, to_id, reason });
return `Snip registered (${registeredSnips.length} queued).`;
},
};注意:execute 只是把 snip 请求加到队列里,返回一个确认消息。消息并没有被删除。
6.3 什么时候真正执行?
在 agent loop 每轮推理前,检查 token 预算:
javascript
const estimated = estimateTokens(messages, SYSTEM_PROMPT);
if (estimated > MAX_TOKENS * 0.8) {
// Token 快满了,执行所有已注册的 snip
const idsToRemove = executeSnips(messages);
if (idsToRemove.size > 0) {
const trimmed = trimMessages([...messages], idsToRemove);
// 用 trimmed 替换 messages
}
}executeSnips() 遍历所有注册的 snip 请求,找出要删除的消息 ID 集合。trimMessages() 执行实际的删除,并在头部插入一个占位符:
javascript
{
role: 'user',
content: '<dropped_messages count="5">The preceding 5 message(s) were removed...</dropped_messages>'
}6.4 为什么要"延迟执行"?
这是一个很巧妙的设计:
- 模型可以放心注册。snip 是非破坏性的------注册了不等于立刻生效,模型可以随时继续引用之前的对话
- 只有真正需要空间时才裁剪。短对话根本不会触发裁剪
- 模型主导决策。系统不知道哪些消息重要,但模型知道。让模型通过 snip 告诉系统"这些已经不需要了"
对应 Claude Design 源码中的完整流程:
markdown
token 超阈值?
├─ 有已注册 snip → 执行 snip,继续
└─ 没有 snip → 注入 nudge 提醒模型注册 snip
→ 如果模型还是不注册 → 系统强制从尾部裁剪(fallback)这就是所谓的"先礼后兵"------先给模型自主权,不合作才系统强制。
七、跑起来
所有代码都在 docs/教学版/ 目录下。因为使用了 ES Module(<script type="module">),需要一个本地服务器来运行。
7.1 前置条件
- 前往 open.bigmodel.cn 注册账号并获取 API Key
- 默认使用
glm-4-flash模型(免费额度可用)
7.2 启动
bash
cd docs/教学版
npx serve .
# 或
python -m http.server 3000然后在浏览器打开 http://localhost:3000。首次打开会弹出 API Key 输入框,粘贴你的 Key 即可。Key 保存在浏览器 localStorage 中,后续无需重复输入。
7.3 运行效果
输入"帮我创建一个按钮组件"后,会看到:
css
> 帮我创建一个按钮组件
[Turn 1]
好的,我来帮你创建这个文件。
⚡ write_file({"path":"components/Button.html","content":"<button style=\"padding"...})
✅ write_file → Written components/Button.html (86 chars)
[Turn 2]
让我确认一下文件内容是否正确。
⚡ read_file({"path":"components/Button.html"})
✅ read_file → <button style="padding: 8px 16px; ...
[Turn 3]
文件内容确认无误,已经创建好了。
📊 tokens: xxx
--- 可以继续调整 ---三次 LLM 调用,两次工具执行,一轮完整的 tool-use 循环。流式输出让你能实时看到模型的回复,体验更流畅。
7.4 换一个试试
输入任何自然语言描述,大模型会理解你的意图并调用合适的工具。比如:
- "帮我创建一个登录页面" → 写入完整 HTML + CSS + JS
- "把按钮改成红色" → 读取现有文件后修改
- "列出所有文件" → 调用 list_files
八、和真实 Claude Design 的差距
这个 mini 版只实现了最核心的骨架。下面列一下没有覆盖的部分,方便有兴趣的同学继续扩展:
| 模块 | Claude Design 实现 | Mini 版状态 |
|---|---|---|
| Agent Loop | 400 行,含中断/重试/follow-up | 90 行,基础循环 |
| 工具系统 | 20+ 工具组,MCP/CC Bridge | 4 个基础工具 |
| 流式渲染 | SSE + 逐字输出 + UI 更新 | ✅ 已实现流式输出 |
| 上下文管理 | 三层防线(cache/snip/sanitize) | 只有 snip |
| System Prompt | 静态+动态,2000+ 行 | 完整设计规范 |
| Skill 系统 | 按需加载 <skill-md> |
未实现 |
| 消息清洗 | 4 步管线(aq→lq→dq→gq) | 未实现 |
| Prompt Caching | cache_control: ephemeral |
未实现 |
| 中断处理 | AbortController + midstream interrupt | 未实现 |
| LLM 后端 | Claude API (gRPC) | 智谱 AI (GLM) OpenAI 兼容接口 |
但核心骨架------消息格式、工具注册、tool-use 循环、snip 裁剪------已经完整可跑了。这些是所有 agent harness 的共同模式,不管你用的是 Claude、GPT 还是智谱 GLM 等开源模型。
九、代码仓库
完整代码在本文的配套仓库中:
vbnet
docs/教学版/
├── index.html ← 浏览器打开,首次需输入 API Key
├── agent.js ← Agent Loop(流式输出)
├── llm.js ← 智谱 AI 流式调用
└── tools/
├── index.js ← 注册表 + 调度器
├── filesystem.js ← 文件系统工具
└── snip.js ← 上下文裁剪零依赖,浏览器直接跑。建议一边看代码一边对照本文的讲解,会有更深的理解。
写在最后
逆向 Claude Design 的过程让我意识到:所谓的 "AI agent" 并不神秘。剥开各种框架和抽象,核心就是一个 while 循环 + 消息列表 + 工具调度。Claude Design 证明了这件事可以在浏览器里做到生产级别------而这背后的工程决策(胖客户端、延迟裁剪、流式渲染)才是真正值得学习的部分。
如果你对 Claude Design 的完整架构感兴趣,可以看我的另一篇 HARNESS_ARCHITECTURE.md 架构文档。
本文的代码是对 Claude Design 内部架构的学习复刻,仅供技术研究用途。