前言:大模型越来越强,也越来越难部署。
在云端,问题通常围绕吞吐、延迟、GPU 利用率展开。但到了端侧、本地设备、小显存推理场景,另一个问题会迅速变成硬门槛:模型权重到底能不能放进内存?
MIT 这篇《Hyperloop Transformers》研究的正是这个问题。论文提出了一种参数更省的 Transformer 架构,目标是在相近计算路径下,用更少参数获得接近甚至更好的语言建模效果。论文作者来自 MIT。

正文:在内存受限场景下的新范式
理解这篇论文,可以先从一个直觉开始。
普通 Transformer 像一条固定流水线。输入 token 从第 1 层走到第 N 层,每一层都有自己独立的一套参数。模型越深,流水线越长,参数越多,权重占用也越大。
Looped Transformer 换了一个思路:既然很多层都在做相似的表示变换,能不能让一部分层被重复使用?也就是让输入经过同一组 Transformer block 多次。这样模型拥有更深的"有效深度",参数量却不会随着深度线性增长。
这个想法很节省参数,但也有明显副作用。反复经过同一组层,模型表达容易变得僵硬。每一轮循环都使用同样的参数,表示变化空间会受限制。论文也指出,普通 looped Transformer 在 depth-matched 对比下,perplexity 往往落后于普通 Transformer。
Hyperloop Transformer 的核心改动,就在这:
它把整个模型分成三段:begin block、middle block、end block。begin block 负责把输入表示带入模型,middle block 负责主要计算,end block 负责输出前的收尾。真正被循环执行的,只有中间的 middle block。论文称这种方式为 middle cycle 策略。
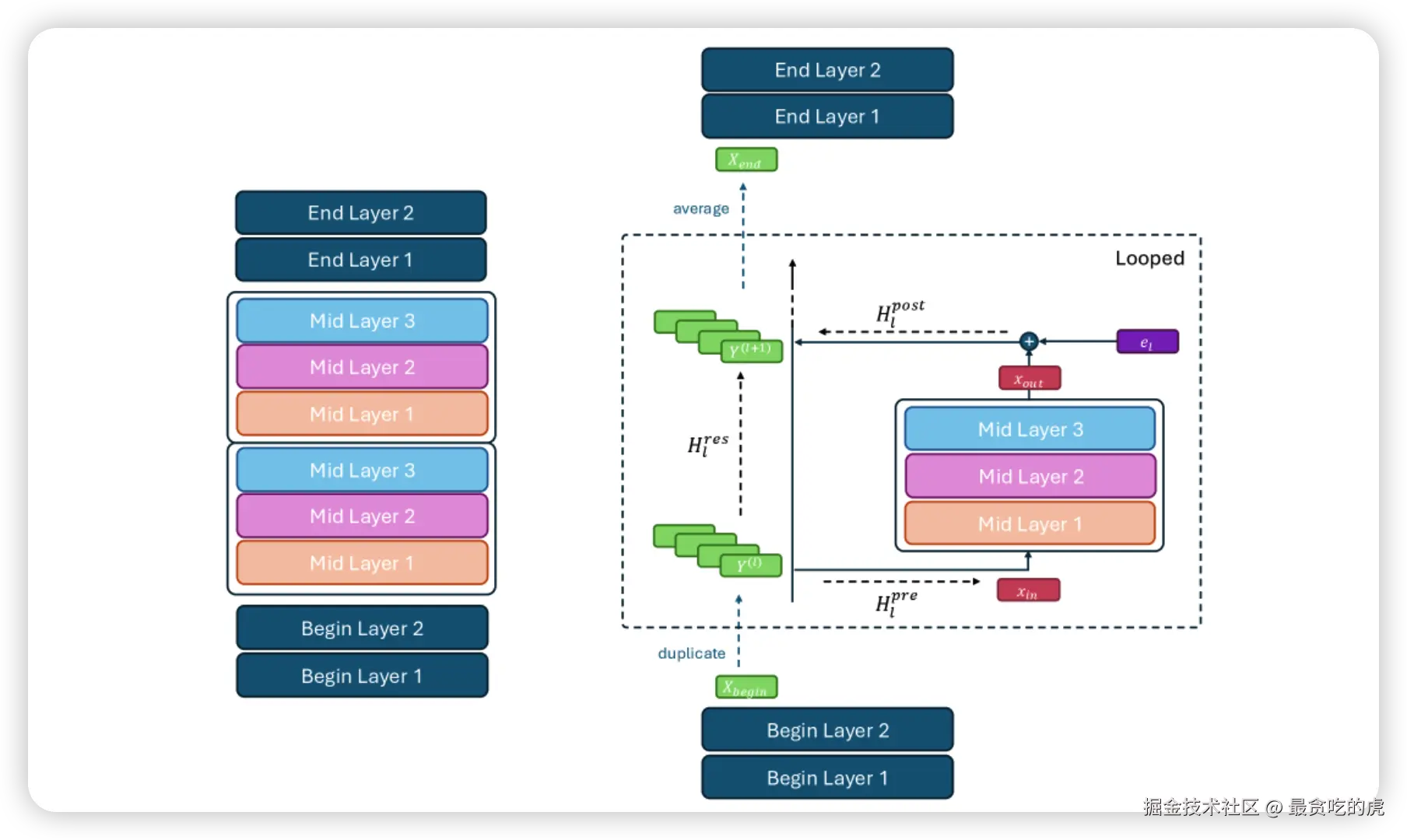
这还只是第一步。
第二步是加入 hyper-connections。普通 Transformer 通常维护一条 residual stream,可以理解成模型在每一层之间传递的主信息通道。Hyperloop 把这条通道扩展成多条并行的 residual streams,让信息可以在多个残差流之间读写和混合。论文里采用的是更轻量的 hyper-connection 变体,并且只在每次 loop 之后应用,而不是每个 attention 或 MLP 子层之后都应用。这样可以给循环层更多表达自由,同时控制额外参数和计算开销。
用一个更直观的类比:
普通 looped Transformer 像让一个人反复用同一种方法修改文章;Hyperloop 则给这个人准备了几份并行草稿,每一轮修改后可以在草稿之间交换信息。这样仍然复用同一个核心编辑能力,但每一轮的状态不再被单一路径锁死。
论文最后实验结果:
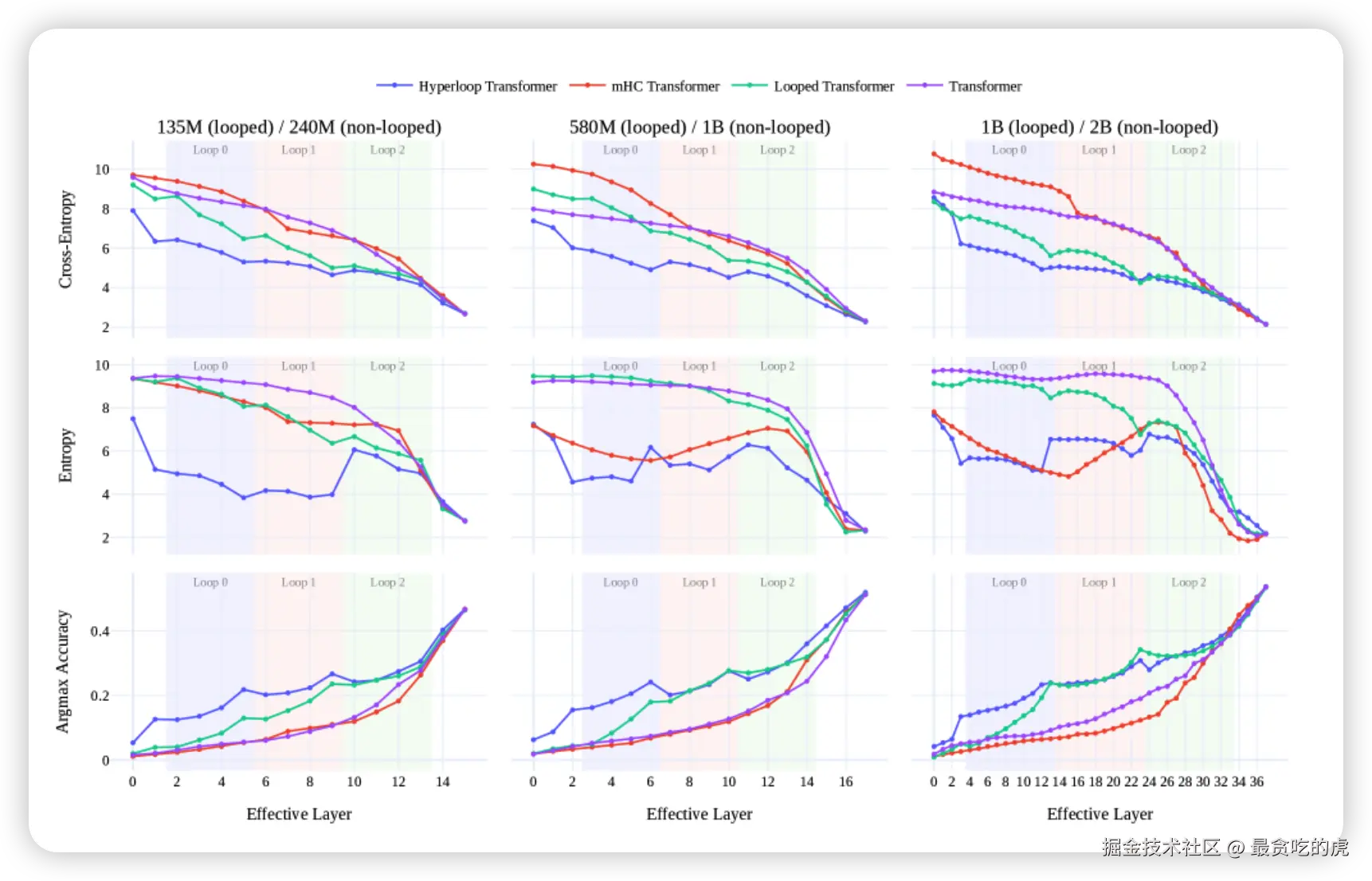
第一排是 Cross-Entropy。可以粗略理解成"模型预测下一个 token 的错误程度"。
第二排是 Entropy。可以理解成"模型有多不确定"。越高表示模型还很犹豫,给很多 token 都分了一些概率;越低表示它更确信某些答案。
第三排是 Argmax Accuracy。意思是:如果只看这一层当前最想选的 token,它选对的比例是多少。越高越好。
更值得注意的是量化结果。
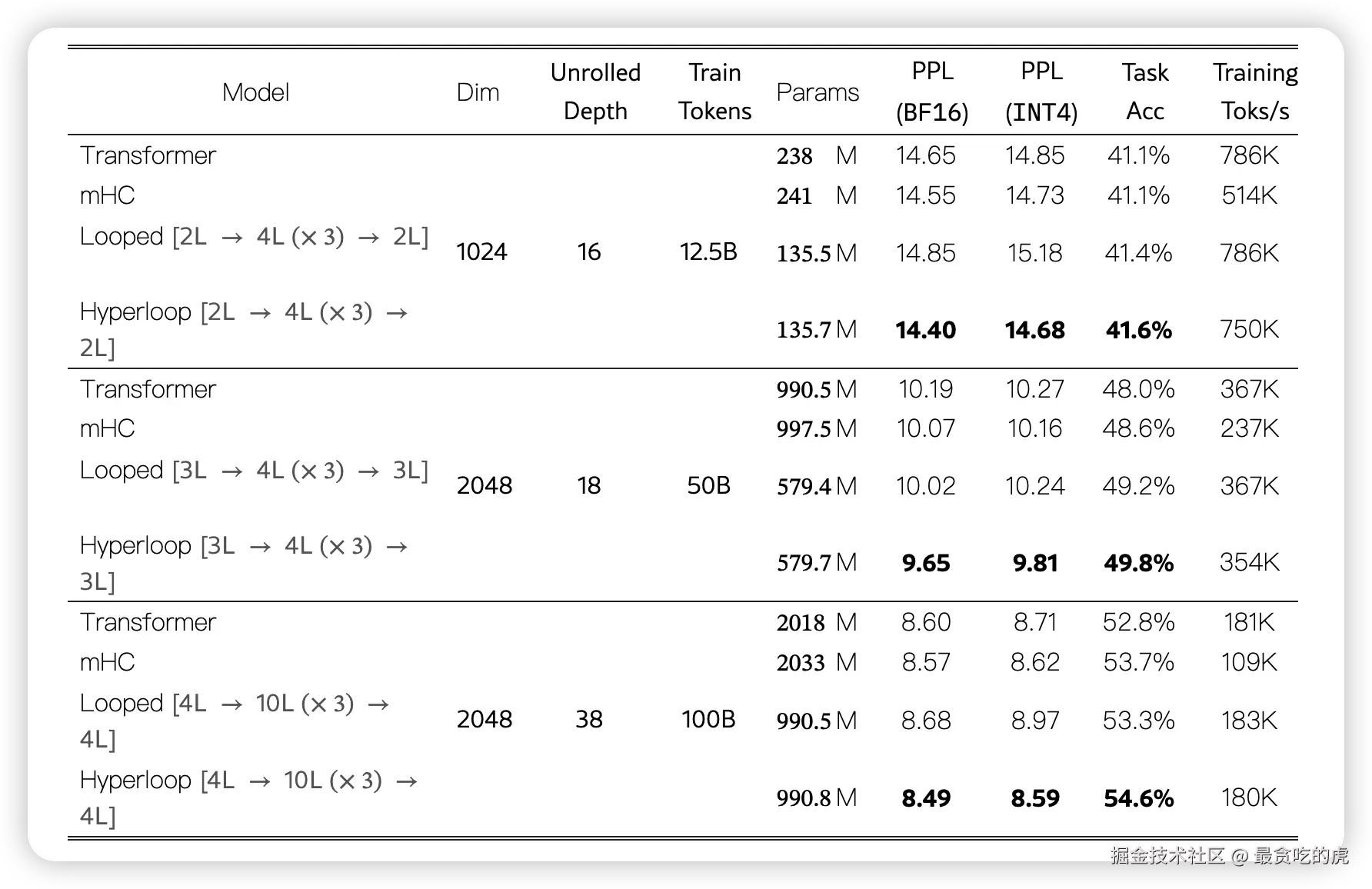
Hyperloop Transformer 用更少参数,效果反而比普通 Transformer、Looped Transformer、mHC Transformer 更好。
表里每一组是在同一个训练设置下比较几种模型。它分成三个规模:
第一组:小模型,隐藏维度 1024,训练 12.5B tokens。
第二组:中等模型,隐藏维度 2048,训练 50B tokens。
第三组:更大模型,隐藏维度 2048,训练 100B tokens。
表头的几个指标可以这样理解:
Params 是参数量,越少越省内存。
PPL (BF16) 是正常精度下的困惑度,越低越好。
PPL (INT4) 是 4-bit 量化后的困惑度,越低越好。
Task Acc 是下游任务平均准确率,越高越好。
Training Toks/s 是训练速度,每秒处理多少 token,越高越快。
论文还做了训练效率分析。由于 hyper-connections 只加在 loop 级别,并且采用更简单的结构,PyTorch 直接实现下,Hyperloop 相比普通 Transformer 和普通 Looped Transformer 只有较小吞吐下降;相比之下,朴素 mHC Transformer 实现会有更明显的 slowdown。
所以这篇论文真正有意思的地方,在于它把 Transformer 的扩展方式从"堆更多独立层"引向"复用核心层 + 改造信息流"。
对于大模型架构来说,参数量、计算量、性能之间一直存在拉扯。传统思路通常会用更多层、更宽 hidden size、更大 MLP 来提升能力。Hyperloop 走的是另一条路径:保留有效深度,压缩独立参数数量,再通过更灵活的残差信息流弥补循环复用带来的表达限制。
这对本地 LLM、手机端模型、低显存 GPU 推理都有现实意义。很多用户关心模型每秒能生成多少 token,但在更底层的问题上,模型首先要能被加载。一个 8GB 或 16GB 内存设备,真正可用于模型权重和 KV cache 的空间很有限。参数效率提升,会直接影响模型能否落地。
当然,Hyperloop 目前还不能被解读成最终答案。在论文中,主要限制是实验规模。论文实验覆盖的是学术算力可承担的模型规模,至于"少约一半参数仍然匹配普通 Transformer"的收益能否延伸到更大 frontier model,还需要进一步验证。
未来的小模型和端侧 LLM 架构,可能会更重视"参数复用"的设计。模型可以通过循环层获得更深的计算过程,通过 hyper-connections 保持信息流动的灵活性,通过量化进一步压低内存占用。
Hyperloop Transformer 让同一组 Transformer 层多走几圈,再用更丰富的残差连接打破循环层的表达僵化。它关心的核心问题很现实:当内存成为瓶颈,LLM 架构该怎样用更少权重做出更强表示。