Python
这是一篇基于菜鸟教程提炼的 Python 核心知识点笔记。如果你有 C 或 Java 基础,这篇笔记能帮你快速跨越语法差异,直击 Python 的精髓。
内容涵盖了从基础语法(如缩进、数据类型)到高阶特性(如装饰器、生成器、上下文管理器),重点解析了命名空间、作用域及多继承等核心概念。
希望这篇总结能为你提供一份清晰的"避坑指南"和速查手册,助你高效掌握 Python
更详细的教程可以看Python3 教程 | 菜鸟教程
文章目录
- Python
-
-
-
- 代码块
- 多行语句
- 基本数据类型
- 复数
- 字符串
- 元组
- Set(集合)
- Dictionary(字典)
- [bytes 类型](#bytes 类型)
- Docstring文档字符串
- :=
- [Python 字符串格式化](#Python 字符串格式化)
- f-string
- for...else
- 推导式
- 迭代器
- 生成器
- with
- 函数
- 装饰器
- 模块
- import
- [from ... import 语句](#from … import 语句)
- [name 属性](#name 属性)
- [dir() 函数](#dir() 函数)
- 输入输出
- [pickle 模块](#pickle 模块)
- OS
- 异常
- 面向对象
- 类型注解
- python标准库
-
-
代码块
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数
多行语句
可以使用反斜杠 \ 来实现多行语句
在 \[\], {}, 或 () 中的多行语句,不需要使用反斜杠 \
python中数字有四种类型:整数、布尔型、浮点数和复数
r可以让\不发生转义
- 字符串可以用 + 运算符连接在一起,用 ***** 运算符重复
- 字符串切片
str[start:end],其中 start(包含)是切片开始的索引,end(不包含)是切片结束的索引。 - 字符串的切片可以加上步长参数 step,语法格式如下:
str[start:end:step]
同一行显示多条代码用;分隔
基本数据类型
Python3 中有 6 种标准数据类型,以及 bool 布尔类型(bool 是 int 的子类,有时单独列出):
- Number(数字)
- String(字符串)
- bool(布尔类型)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
按是否可变,可以分为以下两类:
- 不可变数据(4 个):Number(数字)、String(字符串)、bool(布尔)、Tuple(元组)
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
此外还有一些高级的数据类型,如字节数组类型 bytes。
判断变量类型:
isinstance 和 type 的区别在于:
-
type()不会认为子类是一种父类类型。 -
isinstance()会认为子类是一种父类类型。 -
数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数(向下取整)。
-
在混合计算时,Python 会把整型自动转换为浮点数。
复数
Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj 或者 complex(a, b) 表示,复数的实部 a 和虚部 b 都是浮点型
字符串
Python 没有单独的字符类型,一个字符就是长度为 1 的字符串
Python 字符串不能被改变。向一个索引位置赋值,比如 word[0] = 'm' 会导致错误
在 Python 中,所有非零的数字和非空的字符串、列表、元组等数据类型都被视为 True,只有 0、空字符串、空列表、空元组等被视为 False
元组
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开
| 特性 | 列表 (List) | 元组 (Tuple) |
|---|---|---|
| 可变性 | 可变 (Mutable) | 不可变 (Immutable) |
| 语法符号 | 方括号 [] |
圆括号 () |
| 性能速度 | 相对较慢 | 更快,内存占用更小 |
| 作为字典键 | 不可以 | 可以 (如果内部元素也都是可哈希的) |
Set(集合)
Python 中的集合(Set)是一种无序、可变的数据类型,用于存储唯一的元素。集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
在 Python 中,集合使用大括号 {} 表示,元素之间用逗号 , 分隔。也可以使用 set() 函数创建集合。
注意:创建一个空集合必须用 set() 而不是 {} ,因为 {} 创建的是一个空字典。
Dictionary(字典)
字典(dictionary)是 Python 中另一个非常有用的内置数据类型。
字典是一种映射类型,用 {} 标识,它是一个 键(key) : 值(value) 的集合。键(key) 必须使用不可变类型,且在同一个字典中键必须是唯一的。
注意:Python 3.7 起,字典会保持元素的插入顺序 ,不再是无序的。如果需要有序字典的特性,直接使用普通
dict即可。
bytes 类型
在 Python3 中,bytes 类型表示的是不可变的二进制序列(byte sequence)。与字符串类型不同的是,bytes 类型中的元素是整数值(0 到 255 之间的整数),而不是 Unicode 字符。
创建 bytes 对象最常见的方式是使用 b 前缀
也可以使用 bytes() 函数将其他类型的对象转换为 bytes 类型,第二个参数指定编码方式
| 函数 | 描述 |
|---|---|
| int(x ,base) | 将 x 转换为一个整数 |
| float(x) | 将 x 转换为一个浮点数 |
| complex(real ,imag) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 计算字符串中的有效 Python 表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value) 元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为对应的字符 |
| ord(x) | 将一个字符转换为它的整数值(Unicode 码点) |
| hex(x) | 将一个整数转换为十六进制字符串 |
| oct(x) | 将一个整数转换为八进制字符串 |
Docstring文档字符串
Docstring 可以通过 __doc__ 属性直接访问,也可以使用 help() 函数查看
| 特性 | 文档字符串 (Docstring) | 普通注释 (Comment) |
|---|---|---|
| 写法 | 用 三引号 (""" ... """) 包裹 |
用 井号 (# ...) 开头 |
| 位置 | 必须放在函数、类或模块的第一行 | 可以放在代码的任何地方 |
| 存储 | 会被 Python 保存在内存中 (__doc__) |
会被 Python 忽略,运行时直接丢弃 |
| 访问 | 可以通过 __doc__ 或 help() 查看 |
无法通过代码访问 |
:=
(3.8引入新运算符)
在 Python 的海象运算符 := 中,逻辑顺序是:先赋值,后判断。
虽然它写在一行里,但计算机内部执行时是有严格先后顺序的。
执行流程解析
当你写下 if (x := 10) > 5: 时,Python 内部发生了以下步骤:
- 先计算右侧 :计算
10。 - 立即赋值 :把
10这个值赋给变量x(此时内存里x已经是 10 了)。 - 返回数值 :这个表达式
(x := 10)的结果就是刚才赋的值(即10)。 - 最后判断 :用返回的
10去和5进行比较(10 > 5)
Python 字符串格式化
Python 支持格式化字符串的输出。基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
之前我们习惯用百分号 (%):
python
\>>> name = 'Runoob'
\>>> 'Hello %s' % name
'Hello Runoob'f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,实例如下:
python
>>> name = 'Runoob'
>>> f'Hello {name}' # 替换变量
'Hello Runoob'
>>> f'{1+2}' # 使用表达式
'3'
>>> w = {'name': 'Runoob', 'url': 'www.runoob.com'}
>>> f'{w["name"]}: {w["url"]}'
'Runoob: www.runoob.com'for...else
在 Python 中,for...else 语句用于在循环结束后执行一段代码。
语法格式如下:
python
for item in iterable:
# 循环主体
else:
# 循环结束后执行的代码当循环执行完毕(即遍历完 iterable 中的所有元素)后,会执行 else 子句中的代码,如果在循环过程中遇到了 break 语句,则会中断循环,此时不会执行 else 子句。
推导式
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体
-
列表
python[表达式 for 变量 in 列表] [out_exp_res for out_exp in input_list] 或者 [表达式 for 变量 in 列表 if 条件] [out_exp_res for out_exp in input_list if condition]-
out_exp_res:列表生成元素表达式,可以是有返回值的函数
-
for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中
-
if condition:条件语句,可以过滤列表中不符合条件的值
-
-
字典
python{ key_expr: value_expr for value in collection } 或 { key_expr: value_expr for value in collection if condition } -
集合
python{ expression for item in Sequence } 或 { expression for item in Sequence if conditional } -
元组
python(expression for item in Sequence ) 或 (expression for item in Sequence if conditional )
迭代器
迭代器只能往前不会后退
迭代器有两个基本的方法:iter() 和 next()
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回
with
with 关键字为我们提供了一种优雅的方式来处理文件操作、数据库连接等需要明确释放资源的场景
python
with expression [as variable]:
# 代码块expression返回一个支持上下文管理协议的对象as variable是可选的,用于将表达式结果赋值给变量- 代码块执行完毕后,自动调用清理方法
with 的优势
with 语句通过上下文管理协议(Context Management Protocol)解决了这些问题:
- 自动资源释放:确保资源在使用后被正确关闭
- 代码简洁:减少样板代码
- 异常安全:即使在代码块中发生异常,资源也会被正确释放
- 可读性强:明确标识资源的作用域
with底层就是先执行了with后面类的enter方法然后执行with里面的代码块最后执行exit方法
自定义上下文管理器
通过实现 __enter__ 和 __exit__ 方法创建自定义的上下文管理器:
python
class Timer:
def __enter__(self):
import time
self.start = time.time()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
import time
self.end = time.time()
print(f"耗时: {self.end - self.start:.2f}秒")
return False
# 使用示例
with Timer() as t:
# 执行一些耗时操作
sum(range(1000000))Python 的 contextlib 模块提供了更简单的方式来创建上下文管理器:
python
from contextlib import contextmanager
@contextmanager
def tag(name):
print(f"<{name}>")
yield
print(f"</{name}>")
# 使用示例
with tag("h1"):
print("这是一个标题")函数
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串---用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return 表达式 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
默认参数
如果调用函数时没传这个参数,就用默认值;传了就优先用新值
python
# age 是默认参数,默认 18 岁
def register(name, age=18):
print(f"{name} 今年 {age} 岁")
register("Alice") # 没传 age,自动用 18 -> 输出:Alice 今年 18 岁
register("Bob", 20) # 传了 20,覆盖默认值 -> 输出:Bob 今年 20 岁不定长参数
*args(打包位置参数)
-
作用: * 接收所有没有名字的多余参数(按位置传的)。
-
结果: 这些参数会被打包成一个元组。
-
记忆法:
*像是一个袋子,把散落的参数装进去。
**kwargs(打包关键字参数)
-
作用: 接收所有带名字 的多余参数(
key=value形式)。 -
结果: 这些参数会被打包成一个字典。
-
记忆法:
**像是把键值对整理进字典里。
python
def my_func(a, *args, **kwargs):
print(f"必传参数: {a}")
print(f"多余位置参数(元组): {args}")
print(f"多余关键字参数(字典): {kwargs}")
my_func(1, 2, 3, x=10, y=20)
# 输出:
# 必传参数: 1
# 多余位置参数(元组): (2, 3)
# 多余关键字参数(字典): {'x': 10, 'y': 20}匿名函数
Python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数
- lambda 只是一个表达式,函数体比 def 简单很多
- lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数
python
lambda 参数1,参数2:表达式eg:
python
x = lambda a : a + 10
print(x(5))创建多个匿名函数
可以将匿名函数封装在一个函数内,这样可以使用同样的代码来创建多个匿名函数
python
def myfunc(n):
return lambda a : a * n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11))
print(mytripler(11))参数位置强制
为函数的参数设定了"交通规则",明确了哪些参数必须"按顺序排队"(位置传递),哪些参数必须"出示证件"(关键字传递)
| 特性 | 符号 | 作用 | 典型场景 |
|---|---|---|---|
| 强制位置参数 | / |
符号左侧的参数只能通过位置传递 | 核心参数、保留改名灵活性 |
| 强制关键字参数 | * |
符号右侧的参数只能通过关键字传递 | 配置选项、避免参数混淆 |
关键字传递 就是通过
参数名=值的方式来调用函数。它牺牲了一点点打字的长度,换来了顺序的自由 和代码的清晰度
装饰器
方法的装饰器
用于在不修改原函数代码的前提下,动态扩展函数或类的功能
本质上,装饰器是一个函数:它接收一个函数作为参数,并返回一个新的函数(通常是对原函数的增强版本)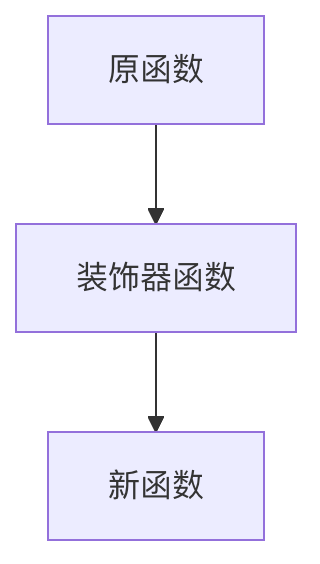
python
def my_decorator(func):
def wrapper():
print("函数执行前")
func()
print("函数执行后")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()装饰器就是一个功能外壳 ,通过
@语法,在函数定义时,将原函数替换为一个增强了功能的新函数
如果原函数有参数,需要在 wrapper 中使用 *args, **kwargs:
python
def my_decorator(func):
def wrapper(*args, **kwargs):
print("执行前")
func(*args, **kwargs)
print("执行后")
return wrapper
@my_decorator
def greet(name):
print(f"Hello, {name}!")
greet("Alice")进阶带参数的装饰器
python
def repeat(num_times):
def decorator(func):
def wrapper(*args, **kwargs):
for _ in range(num_times):
func(*args, **kwargs)
return wrapper
return decorator
@repeat(3)
def say_hello():
print("Hello!")
say_hello()类的装饰器
python
def log_class(cls):
class Wrapper:
def __init__(self, *args, **kwargs):
self.wrapped = cls(*args, **kwargs)
def __getattr__(self, name):
return getattr(self.wrapped, name)
def display(self):
print("调用前")
self.wrapped.display()
print("调用后")
return Wrapper
@log_class
class MyClass:
def display(self):
print("原方法")
obj = MyClass()
obj.display()
__init__:接管控制权它是装饰器的初始化入口 。当你执行
obj = MyClass()时,实际上是在创建装饰器定义的Wrapper类。
- 核心作用 :捕获并保存原对象。
- 具体行为:
- 拦截原本要创建原类实例的操作。
- 在内部手动创建原类的实例(
self.wrapped = cls(...))。- 把这个原对象藏在装饰器内部,作为"内核"。
- 如果没有它:装饰器只是个空壳,原对象根本没被创建,后续所有功能都无法运行。
__getattr__:透明代理它是装饰器的透明通道 。当你调用
obj.some_method()时,如果装饰器自己没有这个方法,就会触发它。
- 核心作用 :转发未知的调用。
- 具体行为:
- 监听所有对"不存在属性/方法"的访问。
- 自动把请求转发给藏在内部的
self.wrapped原对象。- 让外部调用者感觉不到装饰器的存在,仿佛还在直接操作原对象。
- 如果没有它 :装饰器是"瞎子"。你只能调用装饰器里显式写出的方法(如
display),原对象的其他所有功能(如save,delete)都会报错找不到。可以类比为java类中的构造方法和GetterSetter方法
角色 Java 概念 Python 方法 目的 入口 构造方法 __init__确保对象被正确创建并持有原对象引用。 通道 Getter/Setter __getattr__确保外部能访问到内部对象的属性和能力。
常用内置装饰器:
@staticmethod:定义静态方法@classmethod:定义类方法@property:将方法变为属性
核心总结
装饰器 = 函数包装函数 + 不修改原代码扩展功能
- @ 语法本质是函数替换
- wrapper 才是真正执行的函数
- 推荐使用 *args, **kwargs 提高通用性
- 支持函数、类、甚至带参数的装饰器
模块
模块就是一个.py文件
模块的作用
- 代码复用:将常用的功能封装到模块中,可以在多个程序中重复使用。
- 命名空间管理:模块可以避免命名冲突,不同模块中的同名函数或变量不会互相干扰。
- 代码组织:将代码按功能划分到不同的模块中,使程序结构更清晰。
import
想使用 Python 源文件,只需在另一个源文件里执行 import 语句
一个模块只会被导入一次,不管你执行了多少次 import。这样可以防止导入模块被一遍又一遍地执行
Java的import 仅简化包名,Python的import 会执行模块代码
Python 的
import是一个可执行语句。当程序运行到
import my_module时,Python 会做三件事:
- 找文件 :在硬盘上找
my_module.py。- 执行代码 :从上到下运行这个文件里的所有代码 (定义函数、定义类、赋值变量,甚至执行
- 给结果:把执行结果打包成一个模块对象给你用。
import 的本质就是**"执行并实例化",它把一个 .py 文件变成了一个活的对象**供你调用。先执行模块内的代码 然后打包成一个对象,让程序可以使用模块里的方法
模块的搜索路径
当导入一个模块时,Python 会按照以下顺序查找模块:
- 当前目录。
- 环境变量
PYTHONPATH指定的目录。 - Python 标准库目录。
.pth文件中指定的目录。
from ... import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中
from ... import依然会运行整个模块的代码,它的核心作用是为了**"不用写前缀"**(即调用模块里的函数时不用模块名.函数名),还可以:
-
起别名解决命名冲突:
from ... import ... as ... -
提升代码可读性
-
可以局部导入:写在函数内部而非文件开头
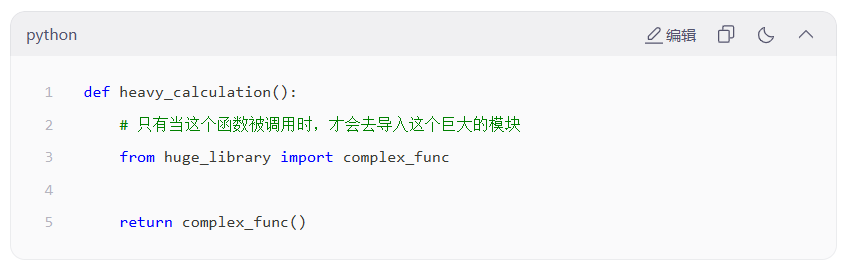
实现加速启动
- 无论你用
import ...还是from ... import ...,只要你把它们写在文件的最开头 (全局作用域),Python 在程序启动的第一秒,就会立刻去执行那个模块的所有代码 - 写在函数里面:需要用时再导入,加速了启动程序
- 无论你用
name 属性
一个模块被另一个程序第一次引入时,其主程序将运行。
如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用 name 属性来使该程序块仅在该模块自身运行时执行。
python
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')每个模块都有一个 name 属性。
- 如果模块是被直接运行,
__name__的值为__main__。- 如果模块是被导入的,
__name__的值为模块名
dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回
输入输出
键盘输入用input()
python
#!/usr/bin/python3
str = input("请输入:");
print ("你输入的内容是: ", str)输出用print()
pickle 模块
python的pickle模块实现了基本的数据序列和反序列化
- 序列化:把对象转换成二进制字节流
- 反序列化:把二进制字节流转换为对象
| 函数对 | 功能 | 使用场景 |
|---|---|---|
dump() / load() |
将对象序列化到文件 / 从文件加载对象 | 数据化持久 |
dumps() / loads() |
将对象序列化到内存(bytes) / 从内存(bytes)加载对象 | 网络传输 |
与JSON对比
| 特性 | Pickle | JSON |
|---|---|---|
| 支持类型 | 几乎所有 Python 对象(自定义类、函数等) | 仅限基本数据类型(dict, list, str, int...) |
| 格式 | 二进制,人类不可读 | 文本,人类可读 |
| 性能 | 快,文件体积小 | 相对较慢,文件体积大 |
| 安全性 | 高风险 | 安全 |
| 跨语言 | 不支持 (Python 专用) | 支持 (通用数据格式) |
OS
os 模块是 Python 标准库中的一个重要模块,它提供了与操作系统交互的功能。
通过 os 模块,你可以执行文件操作、目录操作、环境变量管理、进程管理等任务。
os 模块是跨平台的,这意味着你可以在不同的操作系统(如 Windows、Linux、macOS)上使用相同的代码。
在使用 os 模块之前,你需要先导入它。导入 os 模块的代码如下:
python
import osos.getcwd(): 获取当前工作目录。os.chdir(path): 切换当前工作目录。os.listdir(path): 列出指定目录下的所有文件和子目录。os.mkdir(path): 创建单层目录。os.makedirs(path): 递归创建多层目录。os.rmdir(path): 删除空目录。os.removedirs(path): 递归删除空目录。os.rename(src, dst): 重命名文件或目录。os.remove(path): 删除指定文件。os.walk(top): 递归遍历目录树,生成目录路径、子目录列表和文件列表。
异常

python
try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')抛出异常
python
raise [Exception [, args [, traceback]]]面向对象
类
- 定义类 :使用
class关键字。 __init__方法:构造方法,在创建对象时自动调用,用于初始化对象的属性。self参数 :代表对象自身 。在类的方法中,第一个参数必须是self,通过它来访问对象的属性和方法。
python
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('runoob',10,30)
p.speak()私有属性:用
__作为前缀定义的
继承
python
class 子类名(父类名):
...
python
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()多继承
Python同样有限的支持多继承形式。多继承的类定义形如下例:
python
class DerivedClassName(Base1, Base2, Base3): ...需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法,实例如下:
python
#!/usr/bin/python3
class Parent: # 定义父类
def myMethod(self):
print ('调用父类方法')
class Child(Parent): # 定义子类
def myMethod(self):
print ('调用子类方法')
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
super(Child,c).myMethod() #用子类对象调用父类已被覆盖的方法
super()是用于调用父类(超类)的一个方法
类型注解
- 提高代码可读性:让他人(以及未来的你)一眼就能看懂代码的意图
- 便于静态检查:在运行代码前,通过工具发现潜在的类型错误
- 增强IDE支持:让代码编辑器提供更准确的自动补全和提示
python
# 没有类型注解
def greet(name):
return f"Hello, {name}"
# 有类型注解
def greet(name: str) -> str:
return f"Hello, {name}"
python
# 没有类型注解的代码
name = "Alice"
age = 30
is_student = False
scores = [95, 88, 91]
# 有类型注解的代码
name: str = "Alice" # 注解为字符串 (str)
age: int = 30 # 注解为整数 (int)
is_student: bool = False # 注解为布尔值 (bool)
scores: list = [95, 88, 91] # 注解为列表 (list)-
谁来审查?
-
工具 :主要是 mypy (最流行的静态类型检查器)、pyright(VS Code 内置的检查引擎)。
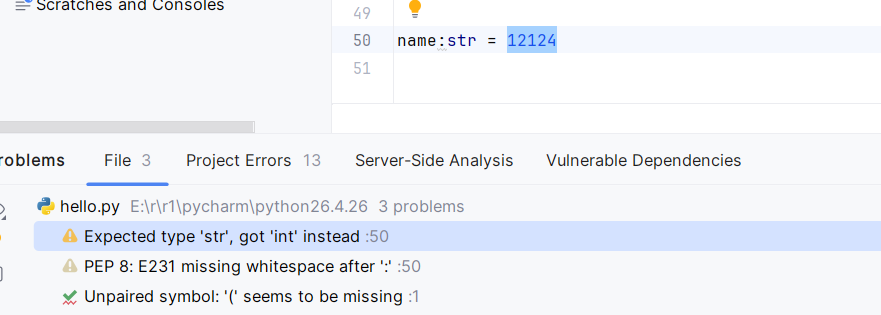
PyCharm 在你写代码的时候,就在后台悄悄地帮你运行了一个轻量级的"代码审查"(类似于 mypy 的简化版)
-
人:开发者。
-
-
审查的是什么?
- 工具会扫描你的代码,不运行它,而是像做数学题一样推导逻辑。
- 它会对比:"你承诺的(注解)" vs "你实际给的(代码逻辑)"。
python标准库
| 功能分类 | 核心模块 | 作用简介 | 典型应用场景 |
|---|---|---|---|
| 系统与文件 | os |
操作系统接口(文件/目录操作、环境变量) | 自动化运维脚本、路径处理 |
pathlib |
面向对象的路径处理(比 os 更现代) |
跨平台文件路径拼接与操作 | |
shutil |
高级文件操作(复制、移动、删除) | 批量文件备份、压缩/解压 | |
sys |
解释器交互(命令行参数、退出程序) | 获取运行参数、控制程序流程 | |
| 数据与格式 | json |
JSON 数据的编码与解码 | 处理 API 接口数据、配置文件 |
csv |
CSV 文件读写 | 处理 Excel 导出的表格数据 | |
pickle |
Python 对象序列化(二进制) | 保存模型参数、缓存复杂对象 | |
| 时间与日期 | datetime |
日期和时间处理的核心 | 计算时间差、格式化时间戳 |
time |
底层时间访问与暂停 | 程序延时 (sleep)、性能测试 |
|
| 文本与正则 | re |
正则表达式引擎 | 复杂的字符串匹配、数据清洗 |
string |
字符串常量与工具 | 获取字母表、数字字符集 | |
| 网络与通信 | urllib |
URL 处理与 HTTP 请求 | 简单的网页抓取、发送网络请求 |
http |
HTTP 协议支持 | 搭建简易测试服务器 | |
socket |
底层网络接口 | 开发聊天室、TCP/UDP 通信 | |
| 数据结构 | collections |
高级容器(Counter, deque, defaultdict) | 统计词频、高效队列操作 |
itertools |
高效迭代工具 | 排列组合、无限循环生成器 | |
| 数学与随机 | math |
基础数学函数(三角、对数、幂) | 科学计算、几何运算 |
random |
生成随机数 | 抽奖程序、打乱列表顺序 | |
| 并发编程 | threading |
多线程编程 | IO 密集型任务(如下载) |
multiprocessing |
多进程编程(绕过 GIL 锁) | CPU 密集型任务(如计算) | |
asyncio |
异步 I/O 编程 | 高并发网络服务 | |
| 其他工具 | logging |
日志记录 | 记录程序运行状态、排查错误 |
sqlite3 |
轻量级数据库 | 本地数据存储、小型应用后端 | |
hashlib |
哈希与加密(MD5, SHA256) | 密码加密、文件完整性校验 |