Leetcode链表-day9
记录自己刷力扣备战秋招的刷题笔记❤️
------wosz
前面被其他事件耽搁了几天,现在刷题继续
链表
链表就是由数据和指针构成的一种数据结构,它的数据存储不一定是连续的,而是通过 next 指针来进行连接链表。
链表分类:
-
单链表
单链表指的就是单相指向的链表,主要指
next只有一个指向方向就是指向后节点。 -
双向链表
双向链表就是指的不止指向后节点还指向前节点,通过
next和pre进行指向,可以查找到前向也可以查找到后向。 -
循环链表
就是单相链表。只不过最后一个节点的
next不指向nullptr,而是指回头节点。
只需要知道链表里面分为数据域 和指针域。
相交链表
给两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
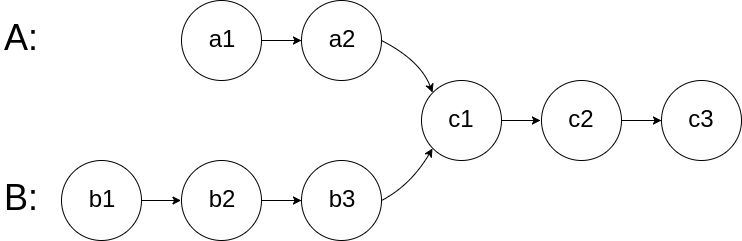
我的题解
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode*tempa=headA;
while(tempa!=NULL)
{
ListNode*tempb=headB;
while(tempb!=NULL)
{
if(tempa==tempb)
{
return tempa;
}
tempb=tempb->next;
}
tempa=tempa->next;
}
return NULL;
}
};我就暴力,直接两层遍历即可进行查找。
官方题解
cpp
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == nullptr ? headB : pA->next;
pB = pB == nullptr ? headA : pB->next;
}
return pA;
}
};官方使用的是双指针解法,这个双指针的移动方法是当我们一个链表走到链尾部了,就从另一条链表进行继续查找。
原理:
核心思路就是:让两个指针走过的总路程一样。
pa一开始比pb多走了 A 的独有部分apb一开始比pa多走了 B 的独有部分b
当它们交换链表后:
pa会去补走 B 前面的那段bpb会去补走 A 前面的那段a
这就导致二者的总路程一样。
反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
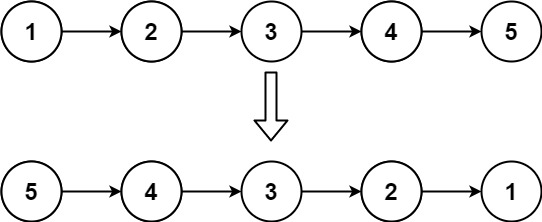
我的题解
cpp
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* pre=nullptr;
ListNode* cur=head;
while(cur!=nullptr)
{
ListNode*temp=cur->next; //保存后节点
cur->next=pre; //指向前节点
pre=cur; //保存前节点
cur=temp; //链表前移
}
return pre;
}
};这道题就是很经典的,主要就是三个点:
- 保存后节点为
temp - 改变指针指向
cur-next=pre - 保存前节点为当前节点
pre=cur - 链表移动
cur=temp
这种题主要就是防止链表找不到下一个遍历的点,因此要先进行一次保存。
官方题解也是一样的方法这里就不进行列举了。
回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。

输入 :head = 1,2,2,1
输出:true
我的题解
cpp
class Solution {
public:
bool isPalindrome(ListNode* head) {
ListNode*cur=head;
vector<int>v;
while(cur!=nullptr)
{
v.push_back(cur->val);
cur=cur->next;
}
vector<int>temp=v;
reverse(temp.begin(),temp.end());
if(v==temp)
return true;
else
return false;
}
};这个题我想了一下,感觉遍历这个也不想数组一样好遍历,所以我会把它转成数组 的形式,然后直接 reverse 判断即可知道是不是回文链表了。有点蠢哈,但是能做出来就行😂

官方的题解
cpp
class Solution {
public:
bool isPalindrome(ListNode* head) {
if (head == nullptr) {
return true;
}
// 找到前半部分链表的尾节点并反转后半部分链表
ListNode* firstHalfEnd = endOfFirstHalf(head);
ListNode* secondHalfStart = reverseList(firstHalfEnd->next);
// 判断是否回文
ListNode* p1 = head;
ListNode* p2 = secondHalfStart;
bool result = true;
while (result && p2 != nullptr) {
if (p1->val != p2->val) {
result = false;
}
p1 = p1->next;
p2 = p2->next;
}
// 还原链表并返回结果
firstHalfEnd->next = reverseList(secondHalfStart);
return result;
}
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr != nullptr) {
ListNode* nextTemp = curr->next;
curr->next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
ListNode* endOfFirstHalf(ListNode* head) {
ListNode* fast = head;
ListNode* slow = head;
while (fast->next != nullptr && fast->next->next != nullptr) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
};这道题本质是学习快慢指针加反转后半链表,学习一下官方的思路,核心步骤就三步:
- 快慢指针找链表中点
- 反转后半段链表
- 两段比较
这道题核心还是快慢指针找链表中点 ,原理就是当快指针走到终点时,慢指针刚好走到中间。需要注意的是奇、偶情况→终止条件。
环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
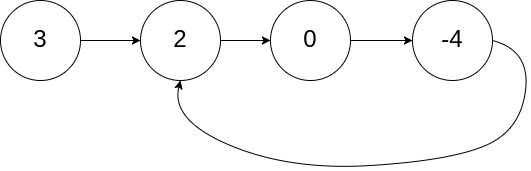
我的题解
cpp
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode*fast=head;
ListNode*slow=head;
while(fast != NULL && fast->next != NULL)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
{
return true;
}
}
return false;
}
};这道题以前看视频看到过解法就是快慢双指针 ,需要注意的就是遍历的条件要考虑到终止的条件 fast != NULL && fast->next != NULL 。
快慢双指针判断环形链表的原理就是:如果是环的话,我们的快指针肯定会追上慢指针。
官方的解法也是通过快慢双指针,就省略了官方的解题了。
环形链表II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
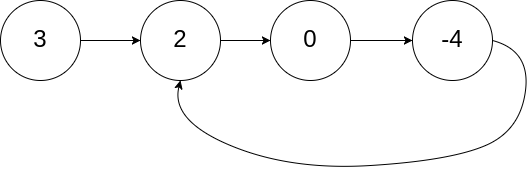
我的题解
cpp
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode*fast=head;
ListNode*slow=head;
while(fast != NULL && fast->next != NULL)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
{
ListNode*temp=head;
while(temp!=slow)
{
temp=temp->next;
slow=slow->next;
}
return slow;
}
}
return NULL;
}
};这道题也是一样的就是快慢双指针加上逻辑推理 ,就是在上一题的基础上相遇了此时我们新开一个慢指针,然后让慢指针和新开的慢指针相遇,这个节点就是入环点。
原理:
假设:
head到 入环点 的距离是a- 入环点 到 第一次相遇点 的距离是
b - 从 相遇点 再走到 入环点 的距离是
c
环的长度:b+c 慢指针走的长度:a+b 快指针走的长度:a+b+n(b+c) (绕圈圈)
快指针式慢指针的两倍
cpp
2(a + b) = a + b + n(b + c)得出头节点到入环点的距离a
cpp
a = (n - 1)(b + c) + c这个式子就表示从头节点到入环点的距离 a 就等于从相遇点到入环点的距离 c 。(n - 1)(b + c) 这个本质上就是绕环绕圈圈,直接就可以看成是从相遇点进行绕圈圈,所以 a 就等于 c 。
官方的解法也是通过快慢双指针,依旧省略了官方的解题了。
合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
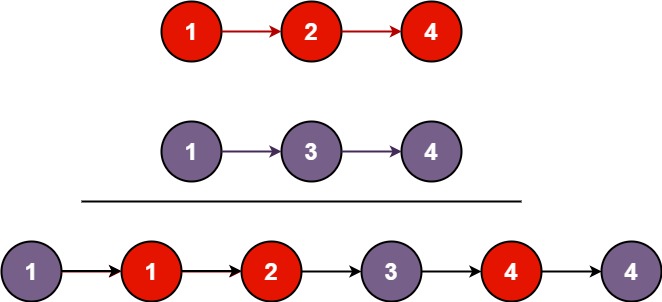
输入 :l1 = 1,2,4, l2 = 1,3,4
输出:1,1,2,3,4,4
我的题解
cpp
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode* dummy = new ListNode;
ListNode* cur = dummy;
while (list1 != nullptr || list2 != nullptr)
{
ListNode* temp = new ListNode;
temp->next = nullptr;
if (list1 != nullptr && list2 == nullptr)
{
temp->val = list1->val;
cur->next = temp;
cur = cur->next;
list1 = list1->next;
}
else if (list1 == nullptr && list2 != nullptr)
{
temp->val = list2->val;
cur->next = temp;
cur = cur->next;
list2 = list2->next;
}
else
{
if (list1->val > list2->val)
{
temp->val = list2->val;
cur->next = temp;
cur = cur->next;
list2 = list2->next;
}
else
{
temp->val = list1->val;
cur->next = temp;
cur = cur->next;
list1 = list1->next;
}
}
}
return dummy->next;
}
};这道题就是创建一个新链表进行比较放入链表中即可,属于基础题。就是只需要注意一下边界条件判断即可。
当然我是创建的新链表其实可以直接改变指向即可,不用新建链表
cpp
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode* dummy = new ListNode();
ListNode* cur = dummy;
while (list1 != nullptr && list2 != nullptr) {
if (list1->val < list2->val) {
cur->next = list1;
list1 = list1->next;
} else {
cur->next = list2;
list2 = list2->next;
}
cur = cur->next;
}
if (list1 != nullptr) {
cur->next = list1;
} else {
cur->next = list2;
}
return dummy->next;
}
};官方也是这种写法,此处省略。
两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
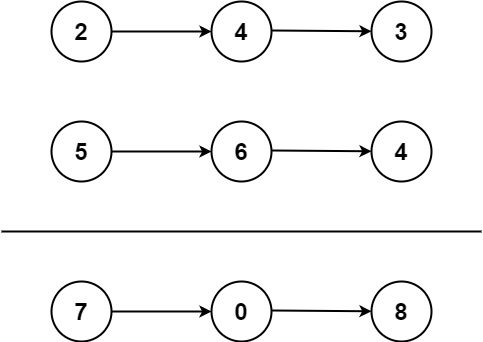
输入 :l1 = 2,4,3, l2 = 5,6,4
输出 :7,0,8
解释:342 + 465 = 807
我的题解
cpp
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* dummy = new ListNode();
ListNode* cur = dummy;
int flag = 0;
while (l1 != nullptr || l2 != nullptr) {
int x = (l1 != nullptr) ? l1->val : 0;
int y = (l2 != nullptr) ? l2->val : 0;
int sum = x + y + flag;
flag = sum / 10;
cur->next = new ListNode(sum % 10);
cur = cur->next;
if (l1 != nullptr) l1 = l1->next;
if (l2 != nullptr) l2 = l2->next;
}
if (flag) {
cur->next = new ListNode(flag);
}
return dummy->next;
}
};这道题我感觉就像加法一样来进行加法进位即可。
官方思路差不多这里就略过了。
删除链表的倒数第N个节点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
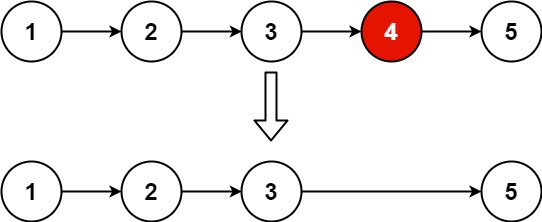
输入 :head = 1,2,3,4,5, n = 2
输出:1,2,3,5
我的题解
cpp
ListNode* list_reverse(ListNode*head)
{
ListNode*prenode=nullptr;
ListNode*cur=head;
while(cur!=nullptr)
{
ListNode*temp=cur->next;
cur->next=prenode;
prenode=cur;
cur=temp;
}
return prenode;
}
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode*myhead=new ListNode;
ListNode*reverse_node=list_reverse(head);
myhead->next=reverse_node;
int count=1;
ListNode*pre=myhead;
while(reverse_node!=nullptr) //找n节点
{
if(n==count)
{
ListNode*temp=reverse_node->next;
pre->next=temp;
break;
}
pre=reverse_node;
reverse_node=reverse_node->next;
count++;
}
ListNode*tag=list_reverse(myhead->next);
return tag;
}
};我的想法就比较直接了,直接反转链表从头开始好计数,然后删除了之后,再次反转回去即可。
官方题解
cpp
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummy = new ListNode(0, head);
ListNode* first = head;
ListNode* second = dummy;
for (int i = 0; i < n; ++i) { //移动第一个指针
first = first->next;
}
while (first) {
first = first->next;
second = second->next;
}
second->next = second->next->next;
ListNode* ans = dummy->next;
delete dummy;
return ans;
}
};这道题我们应该学习的就是快慢双指针,让我们的快指针本身就领先于慢指针。
我们可以使用两个指针 first 和 second 同时对链表进行遍历,并且 first 比 second 超前 n 个节点。当 first 遍历到链表的末尾时,second 就恰好处于倒数第 n 个节点。
两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
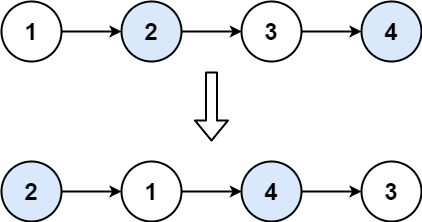
输入 :head = 1,2,3,4
输出:2,1,4,3
我的题解
cpp
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* myhead = new ListNode;
myhead->next = head;
ListNode* pre = myhead;
while (pre->next != nullptr && pre->next->next != nullptr)
{
ListNode* second = pre->next; // 第一个节点
ListNode* first = pre->next->next; // 第二个节点
ListNode* temp = first->next; // 保存下一组开头
second->next = temp;
first->next = second;
pre->next = first;
pre = second; // pre移动到这一组交换后的尾巴
}
return myhead->next;
}
};我的想法是利用双指针 ,每次直接跳两个,然后进行交换即可。这个最需要注意的就是使用哪个当成我们的循环条件,采用 pre 来进行判断更加合理。
官方采用的迭代思路也是这个,此处就省略了。
K个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
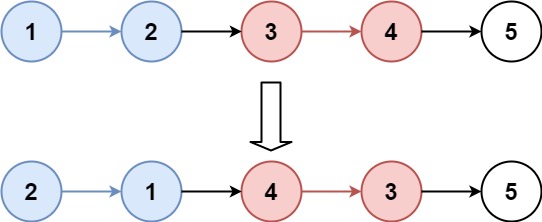
输入 :head = 1,2,3,4,5, k = 3
输出:3,2,1,4,5
我的题解
cpp
ListNode* reverse_node(ListNode* head, ListNode* tail)
{
ListNode* stop = tail->next; // 下一组的开头
ListNode* cur = head;
ListNode* pre = stop;
while (cur != stop)
{
ListNode* temp = cur->next;
cur->next = pre;
pre = cur;
cur = temp;
}
return pre; // 反转后的新头,也就是原来的 tail
}
class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode* myhead = new ListNode;
myhead->next = head;
ListNode* slow = head; // 当前这一组的头
ListNode* fast = myhead; // 用来找当前这一组的尾
ListNode* pre = myhead; // 当前这一组前面的节点
while (true)
{
// 找到当前这一组的第 k 个节点
for (int i = 0; i < k; i++)
{
fast = fast->next;
if (fast == nullptr)
return myhead->next;
}
ListNode* latter = fast->next; // 下一组开头
ListNode* newHead = reverse_node(slow, fast); // 反转当前组
pre->next = newHead; // 前面接上反转后的头
pre = slow; // slow 反转后变成这一组的尾
slow = latter; // slow 指向下一组开头
fast = pre; // fast 从当前组尾巴重新开始找下一组
}
return myhead->next;
}
};这道题我思路就是快慢双指针 ,就是默认我们的这个快指针比慢指针多k步开始走即可。大致的思路总结就是:k 个一组找到尾节点 -> 反转这一组 -> 接回原链表 -> 继续下一组
需要非常注意一下这个翻转之后的逻辑很容易乱。
官方的题解也是这个思路,此处依旧省略。
随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝 。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
输入 :head = \[7,null,13,0,11,4,10,2,1,0]
输出:\[7,null,13,0,11,4,10,2,1,0]
我的题解
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == NULL) {
return NULL;
}
Node* oldHead = head; // 保存原链表头
Node* myhead = new Node(0); // 虚拟头节点
Node* pre = myhead;
// 1. 先复制普通 next 链表
while (head != NULL)
{
Node* temp = new Node(head->val);
pre->next = temp;
pre = pre->next;
head = head->next;
}
// 2. 再处理 random 指针
Node* cur = oldHead;
Node* new_cur = myhead->next;
while (cur != NULL)
{
if (cur->random == NULL)
{
new_cur->random = NULL;
}
else
{
Node* old = oldHead;
Node* new_node = myhead->next;
while (old != NULL)
{
if (cur->random == old)
{
new_cur->random = new_node;
break;
}
old = old->next;
new_node = new_node->next;
}
}
cur = cur->next;
new_cur = new_cur->next;
}
return myhead->next;
}
};我目前的思路感觉有点笨,就是先对链表进行复制一次保留随机指针为空 ,然后再通过双指针,依次对两条链表进行遍历判断即可,可能时间确实有点复杂了。
官方题解
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == NULL) return NULL;
unordered_map<Node*, Node*> mp;
Node* cur = head;
// 第一次遍历:复制所有节点,建立 原节点 -> 新节点 的映射
while (cur != NULL) {
mp[cur] = new Node(cur->val);
cur = cur->next;
}
// 第二次遍历:连接 next 和 random
cur = head;
while (cur != NULL) {
mp[cur]->next = mp[cur->next];
mp[cur]->random = mp[cur->random];
cur = cur->next;
}
return mp[head];
}
};这道题原本可能是让我们学习哈希表映射法,这里学习一下GPT说的哈希映射的方法。
random 指针难找对应关系,所以用 unordered_map 建立 old 到 copy 的映射。直呼太妙了!!
排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
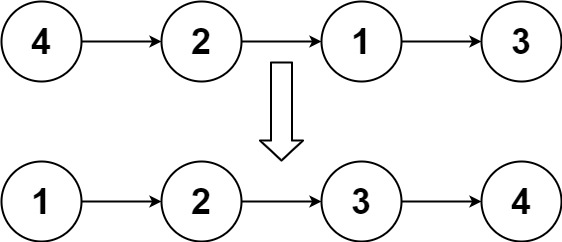
输入 :head = 4,2,1,3
输出:1,2,3,4
这道题,我脑子里只有o(n^2)的方法或者就是复制到容器进行重组,肯定不太行,直接学习官方的方法吧。
官方题解
cpp
// 合并两个有序链表
ListNode* merge_node(ListNode* l1, ListNode* l2)
{
ListNode* myhead = new ListNode;
ListNode* cur = myhead;
while (l1 != nullptr && l2 != nullptr)
{
if (l1->val < l2->val)
{
cur->next = l1;
l1 = l1->next;
}
else
{
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if (l1 != nullptr) //直接就等于剩下的即可
cur->next = l1;
else
cur->next = l2;
return myhead->next;
}
// 递归归并排序
ListNode* sort_node(ListNode* head)
{
if (head == nullptr || head->next == nullptr)
{
return head;
}
// 1. 快慢指针找中点
ListNode* slow = head;
ListNode* fast = head;
ListNode* pre = nullptr;
while (fast != nullptr && fast->next != nullptr)
{
pre = slow;
slow = slow->next;
fast = fast->next->next;
}
// 2. 断开链表
pre->next = nullptr;
// 3. 递归排序左右两边
ListNode* left = sort_node(head);
ListNode* right = sort_node(slow);
// 4. 合并两个有序链表
return merge_node(left, right);
}
class Solution {
public:
ListNode* sortList(ListNode* head) {
return sort_node(head);
}
};这道题最应该学习的方法是归并排序 加快慢双指针。(排序以前学过的都有点搞忘了,链表学了之后再补一下吧)
归并排序就是先把大问题不断拆成小问题,再把小问题按顺序合并起来。
- 分:把数组/链表拆成两半
- 治:分别把左右两半排好序
- 合:把两个有序部分合并成一个有序整体
核心就是:拆分 -> 排序 -> 合并
就是不断递归然后进行合并。步骤:
- 快慢指针找中点
- 断开链表
- 递归左边和右边
- 返回合并有序链表
合并K个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
输入 :lists = \[1,4,5,1,3,4,2,6]
输出 :1,1,2,3,4,4,5,6
解释:链表数组如下:
1-\>4-\>5, 1-\>3-\>4, 2-\>6
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
我的题解
cpp
ListNode* merge_node(ListNode* l1, ListNode* l2)
{
ListNode* myhead = new ListNode;
ListNode* cur = myhead;
while (l1 != nullptr && l2 != nullptr)
{
if (l1->val < l2->val)
{
cur->next = l1;
l1 = l1->next;
}
else
{
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if (l1 != nullptr) //直接就等于剩下的即可
cur->next = l1;
else
cur->next = l2;
return myhead->next;
}
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int list_num=lists.size();
if(list_num==0) return nullptr;
ListNode*myhead=lists[0];
for(int i=1;i<list_num;i++)
{
myhead=merge_node(myhead,lists[i]);
}
return myhead;
}
};我想到的就是只想到了遍历 加有序两两结合 实现合并。我的就是顺序合并。
官方题解
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
ListNode* merge_node(ListNode* l1, ListNode* l2)
{
ListNode* myhead = new ListNode;
ListNode* cur = myhead;
while (l1 != nullptr && l2 != nullptr)
{
if (l1->val < l2->val)
{
cur->next = l1;
l1 = l1->next;
}
else
{
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if (l1 != nullptr)
cur->next = l1;
else
cur->next = l2;
return myhead->next;
}
// 分治合并 lists[left...right]
ListNode* merge_range(vector<ListNode*>& lists, int left, int right)
{
if (left > right)
return nullptr;
if (left == right)
return lists[left];
int mid = left + (right - left) / 2;
ListNode* l1 = merge_range(lists, left, mid);
ListNode* l2 = merge_range(lists, mid + 1, right);
return merge_node(l1, l2);
}
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int list_num = lists.size();
if (list_num == 0)
return nullptr;
return merge_range(lists, 0, list_num - 1);
}
};这道题最应该学习的时分治合并:
一开始就已经有 K 个有序链表,我们只需要不断两两合并。
这个相对我们的顺序合并时间复杂度更小,顺序合并时间复杂度是:O(Nk) ,分治合并的时间复杂度是:O(N log k)
LRU缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
txt
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4LRU知识点补充:
LRU缓存时一种缓存淘汰机制 ,每访问或使用一个元素就标记为最近使用 ,当缓存满了时,就淘汰最久没有使用的元素。
就拿链表说人话:A→B→C→D(容量为4)
- 比如取用C时,就从链表中取出C放到链表头的位置 C→A→B→D(容量为4)
- 当来一个元素 E 时,此时就淘汰掉 D 成为 E→C→A→B(容量为4)
官方题解
cpp
class LRUCache {
public:
struct Node {
int key;
int value;
Node* prev;
Node* next;
Node(int k, int v) {
key = k;
value = v;
prev = nullptr;
next = nullptr;
}
};
int cap;
unordered_map<int, Node*> mp; //哈希表
Node* head; //头
Node* tail; //尾
LRUCache(int capacity) {
cap = capacity; //初始化容量
head = new Node(0, 0); // 虚拟头节点
tail = new Node(0, 0); // 虚拟尾节点
head->next = tail;
tail->prev = head;
}
// 删除某个节点
void removeNode(Node* node) {
Node* pre = node->prev;
Node* nxt = node->next;
pre->next = nxt;
nxt->prev = pre;
}
// 把节点插入到头部,表示最近使用
void addToHead(Node* node) {
node->next = head->next;
node->prev = head;
head->next->prev = node; //更换原本的节点
head->next = node;
}
// 把某个节点移动到头部
void moveToHead(Node* node) {
removeNode(node);
addToHead(node);
}
// 删除尾部节点,也就是最久未使用节点
Node* removeTail() {
Node* node = tail->prev;
removeNode(node);
return node;
}
int get(int key) {
if (mp.find(key) == mp.end()) {
return -1;
}
Node* node = mp[key];
// 访问过这个节点,所以它变成最近使用
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (mp.find(key) != mp.end()) {
// key 已经存在,更新 value
Node* node = mp[key];
node->value = value;
// 更新后也算最近使用
moveToHead(node);
} else {
// key 不存在,新建节点
Node* node = new Node(key, value);
mp[key] = node;
addToHead(node);
// 如果超过容量,删除最久未使用的节点
if (mp.size() > cap) {
Node* old = removeTail();
mp.erase(old->key);
delete old;
}
}
}
};我的想法就是使用链表进行构造LRU ,然后哈希表快速查找 。看了一下官方的思路用的是双向链表,还是直接学习一下官方的写法和思路吧。其实我的C++还没有怎么学习过类,先简单学习一下类。
结构体和类知识补充
C++结构体比C的结构体更加方便,引入了构造函数 和普通函数。
- 构造函数:构造函数就相当于是一个初始化,名字和结构体和类的函数名字一样。
- 普通函数:普通函数则作为我们创建的对象或者类的一个方法进行调用。
在C语言中,我们定义结构体会定义成为:
c
typedef struct node{
int val;
struct node*next;
}node_t;在C++中定义的结构体则可以如下:
cpp
struct Node {
int key;
int value;
Node(int k, int v) { //构造函数
key = k;
value = v;
}
~Node() { //析构函数
cout << "析构函数" << endl;
}
void print() {
cout << value << endl;
}
};其中 Node 作为构造函数在我们创建结构体时就会默认进行调用,相当于进行初始化,print 则是作为方法,使用.print()进行调用。
目的就是更加方便的初始化节点以及数据,减少繁琐。然后在创建指针时,我们有两种方法进行分配空间 new 和 malloc ,new 是C++新增加的,下面争对二者进行一个区分说明:
new会分配一个内存空间,同时调用构造函数。- 删除使用
delete,会调用解析函数。 - 申请出现异常
std::bad_alloc,程序终止运行。
- 删除使用
malloc只会分配一个内存空间。- 删除使用
free,不会调用解析函数。 - 申请失败返回
NULL,需要判断是否成功分配。
- 删除使用
cpp
Node*myhead=new Node(3,1);
/*---------------------------------*/
Node*myhead=(Node*)malloc(sizeof(Node));
myhead->key=3;
myhead->val=1;类就是可以理解成一种数据 以及操作这些数据的函数,基本的结构如下:
cpp
class 类名 {
public:
// 外部可以访问的成员
private:
// 外部不能直接访问的成员
};public说的是外部可以访问的就是提供给外部进行创建然后可以进行调用的。private则只能是在类内部进行调用,就可以理解成只能在class中进行使用。
基本的结构如下:
- 成员变量
- 成员函数
- 构造函数
- 析构函数
使用
-
定义类
cppclass Student { public: string name; int age; Student(string n, int a) { name = n; age = a; } void show() { cout << name << " " << age << endl; } }; -
创建对象
Student s("张三", 20); -
调用成员
s.show(); cout << s.name << endl; cout << s.age << endl;