你好!我是探物 AI,多模态感知算法工程师,不定期分享自己学习的环境感知算法。
这篇文章我想和你详细聊聊UFLDv2车道线检测算法,以及如何基于检测结果搭建一个实用的车道偏离预警系统。这是我做ADAS项目时花时间最多的模块,踩了不少坑,希望这些经验能帮到你。
一、为什么选择UFLDv2?
在车道线检测领域,主流方案大致分为两类:
| 方案 | 代表方法 | 速度 | 精度 | 特点 |
|---|---|---|---|---|
| 语义分割 | SCNN, ERFNet | 慢 | 高 | 像素级分割,计算量大 |
| 行/列锚点回归 | UFLD, UFLDv2 | 快 | 较高 | 基于锚点的位置回归,极快 |
UFLDv2(Ultra Fast Lane Detection v2)的核心思想是:不逐像素分割车道线,而是将车道线检测转化为行/列锚点上的位置分类问题。这种设计让它的推理速度极快,非常适合ADAS这种对实时性要求很高的场景。
UFLDv2 vs UFLD v1 的主要区别
- v1只有行锚点(row anchor),v2同时使用行锚点和列锚点(col anchor)
- v2增加了车道线存在性判断(exist_row / exist_col),更鲁棒
- v2输出4个分支:
loc_row、loc_col、exist_row、exist_col - v2支持更多数据集:CULane、TuSimple、CurveLanes
二、UFLDv2算法原理
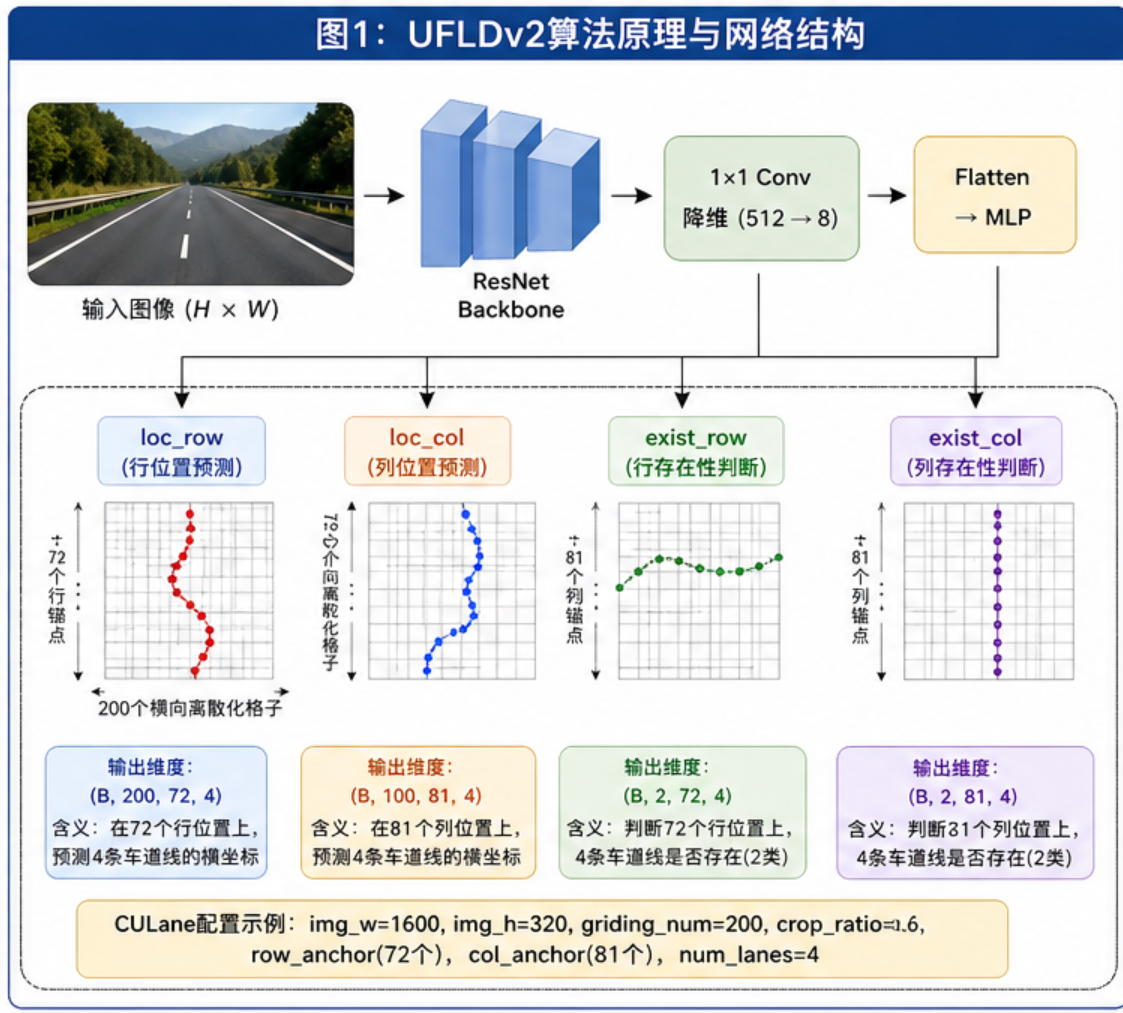
2.1 核心思想
传统语义分割方法需要输出一张与输入同尺寸的分割图,计算量巨大。UFLDv2换了个思路:
-
在图像的预设行位置 上,预测车道线的水平坐标
-
在图像的预设列位置 上,预测车道线的垂直坐标
-
将连续坐标离散化为分类问题(griding_num个类别)
输入图像 (H × W)
↓
ResNet Backbone (提取特征)
↓
1×1 Conv (降维到8通道)
↓
Flatten → MLP (全连接层)
↓
┌──────────┬──────────┬──────────┬──────────┐
│ loc_row │ loc_col │exist_row │exist_col │
│ 行位置预测 │ 列位置预测 │ 行存在性 │ 列存在性 │
└──────────┴──────────┴──────────┴──────────┘
2.2 模型配置
不同数据集的配置参数不同,项目中CULane的配置如下:
python
class ModelConfig():
def init_culane_config(self):
self.img_w = 1600 # 模型输入宽度
self.img_h = 320 # 模型输入高度
self.griding_num = 200 # 横向离散化数量
self.crop_ratio = 0.6 # 裁剪比例(只取图像下半部分)
self.row_anchor = np.linspace(0.42, 1, 72) # 72个行锚点
self.col_anchor = np.linspace(0, 1, 81) # 81个列锚点
self.num_lanes = 4 # 检测4条车道线关键参数解释:
griding_num=200:将水平方向离散化为200个格子,每个格子对应一个分类类别row_anchor:在图像纵向上均匀采样72个位置,在这些位置上预测车道线的横坐标crop_ratio=0.6:只取图像下方60%的区域(车道线主要在下半部分)
2.3 网络结构
python
class parsingNet(torch.nn.Module):
def __init__(self, backbone='18', num_grid_row=200, num_cls_row=72,
num_grid_col=100, num_cls_col=81, num_lanes=4, ...):
super().__init__()
# ResNet骨干网络
self.model = resnet(backbone, pretrained=pretrained)
# 1×1卷积降维:512→8通道(ResNet18)
self.pool = torch.nn.Conv2d(512, 8, 1)
# 全连接分类头
self.input_dim = input_height // 32 * input_width // 32 * 8 # 10×50×8=4000
mlp_mid_dim = 2048
self.cls = torch.nn.Sequential(
torch.nn.LayerNorm(self.input_dim),
torch.nn.Linear(self.input_dim, mlp_mid_dim),
torch.nn.ReLU(),
torch.nn.Linear(mlp_mid_dim, total_dim), # 4个分支的输出拼接
)
def forward(self, x):
x2, x3, fea = self.model(x) # ResNet提取特征
fea = self.pool(fea) # 1×1卷积降维
fea = fea.view(-1, self.input_dim) # 展平
out = self.cls(fea) # MLP预测
# 拆分为4个输出
pred_dict = {
'loc_row': out[:, :dim1].view(-1, num_grid_row, num_cls_row, num_lanes),
'loc_col': out[:, dim1:dim1+dim2].view(-1, num_grid_col, num_cls_col, num_lanes),
'exist_row': out[:, dim1+dim2:dim1+dim2+dim3].view(-1, 2, num_cls_row, num_lanes),
'exist_col': out[:, -dim4:].view(-1, 2, num_cls_col, num_lanes),
}
return pred_dict输出维度解析(以CULane为例):
| 输出 | 形状 | 含义 |
|---|---|---|
| loc_row | (B, 200, 72, 4) | 72个行位置上,4条车道线的横向位置(200类分类) |
| loc_col | (B, 100, 81, 4) | 81个列位置上,4条车道线的纵向位置(100类分类) |
| exist_row | (B, 2, 72, 4) | 72个行位置上,4条车道线是否存在(2类分类) |
| exist_col | (B, 2, 81, 4) | 81个列位置上,4条车道线是否存在(2类分类) |
三、模型训练
3.1 训练配置
项目中的CULane训练配置(culane_res18.py):
python
dataset = 'CULane'
epoch = 50
batch_size = 32
optimizer = 'SGD'
learning_rate = 0.05
weight_decay = 0.0001
momentum = 0.9
scheduler = 'multi'
steps = [25, 38] # 学习率衰减的epoch
gamma = 0.1 # 衰减系数
warmup = 'linear'
warmup_iters = 695
backbone = '18' # ResNet18
num_lanes = 4
griding_num = 200
num_row = 72
num_col = 81
train_width = 1600
train_height = 320
use_aux = False # 不使用辅助分割头
fc_norm = True # 全连接层前加LayerNorm3.2 训练流程
bash
# 1. 克隆UFLDv2官方仓库
git clone https://github.com/cfzd/Ultra-Fast-Lane-Detection-v2.git
# 2. 准备CULane数据集
# 下载后放到data/CULane目录
# 3. 修改配置文件
# 编辑configs/culane_res18.py,设置data_root路径
# 4. 开始训练
python train.py configs/culane_res18.py3.3 训练技巧
- Backbone选择:ResNet18足够用,速度快;需要更高精度可以换ResNet34/50
- crop_ratio:CULane用0.6,TuSimple用0.8,根据数据集调整
- use_aux:训练时可以开启辅助分割头帮助收敛,推理时关闭
- 学习率策略:SGD + MultiStepLR,在epoch 25和38处衰减
四、模型部署:PyTorch → ONNX
4.1 转换脚本
项目提供了完整的转换脚本 convertPytorchToONNX.py:
python
def convert_model(model_path, model_type=LaneModelType.UFLDV2_CULANE):
# 加载配置
cfg = LaneV2Config("./configs/" + Path(model_path).stem + ".py")
# 构建模型
net = model_tusimple.get_model(cfg)
# 加载权重(处理多GPU训练的module.前缀)
state_dict = torch.load(model_path, map_location='cpu')['model']
compatible_state_dict = {}
for k, v in state_dict.items():
if 'module.' in k:
compatible_state_dict[k[7:]] = v
else:
compatible_state_dict[k] = v
net.load_state_dict(compatible_state_dict, strict=False)
# 导出ONNX
img = torch.zeros(1, 3, cfg.train_height, cfg.train_width).to('cuda')
torch.onnx.export(net, img, onnx_file_path, verbose=True)
# 验证
model = onnx.load(onnx_file_path)
onnx.checker.check_model(model)4.2 执行转换
bash
cd TrafficLaneDetector
python convertPytorchToONNX.py转换完成后会生成 ufldv2_culane_res18_320x1600.onnx 文件。
4.3 FP16量化(可选)
如果需要进一步加速,可以做FP16量化:
bash
python onnxQuantization.py -i ./TrafficLaneDetector/models/ufldv2_culane_res18_320x1600.onnx五、车道线检测推理
5.1 输入预处理
python
def __prepare_input(self, image):
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 按crop_ratio裁剪下半部分
new_size = (self.input_width, int(self.input_height / self.cfg.crop_ratio))
img_input = cv2.resize(img, new_size).astype(np.float32)
img_input = img_input[-self.input_height:, :, :] # 取底部
# ImageNet标准化
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img_input = ((img_input / 255.0 - mean) / std)
# HWC → NCHW
img_input = img_input.transpose(2, 0, 1)[np.newaxis, :, :, :]
return img_input.astype(self.input_types)关键点 :crop_ratio=0.6 意味着只取图像下方60%送入模型,因为车道线主要出现在图像下半部分。
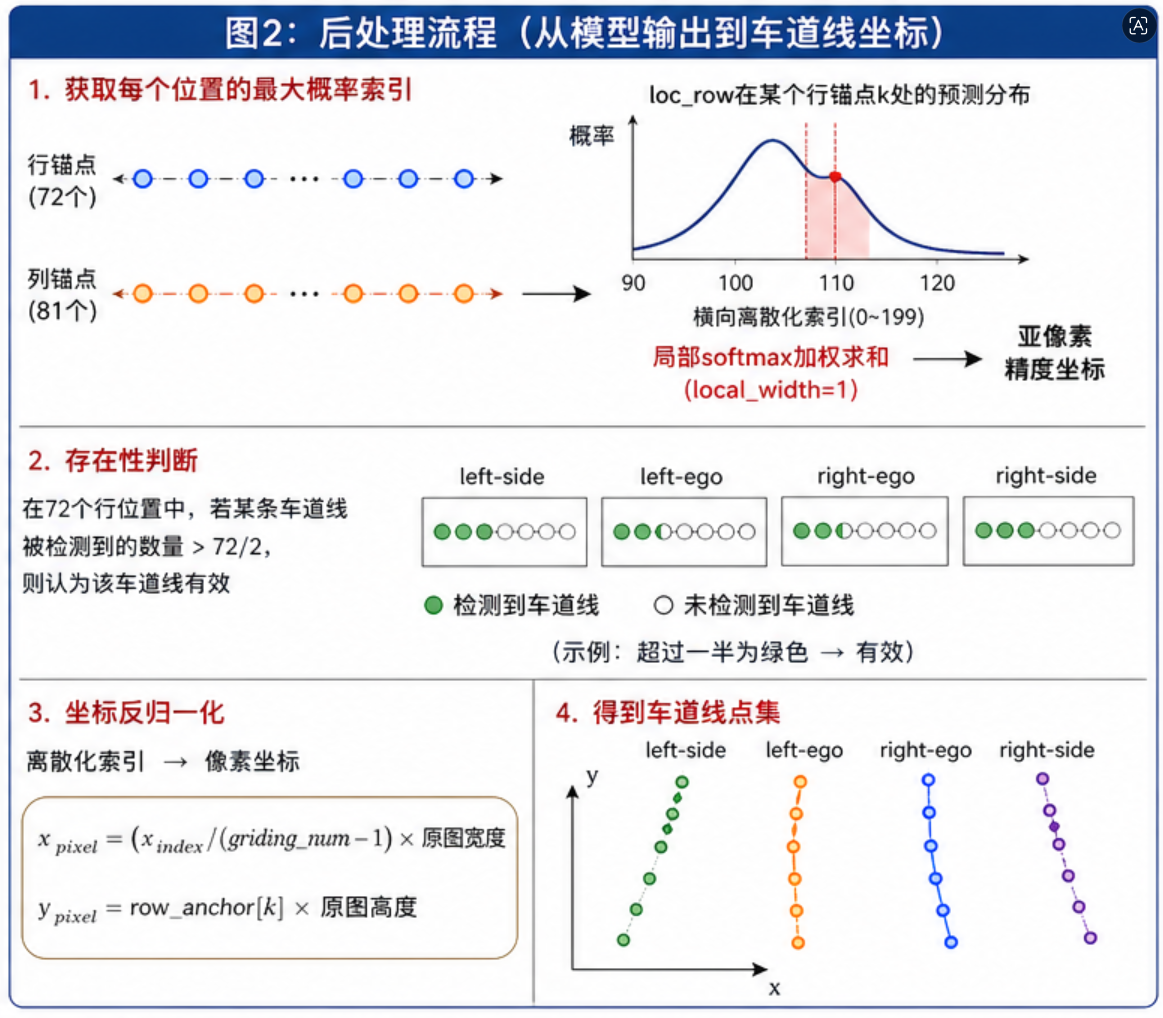
5.2 输出后处理
这是最核心的部分,如下图的解释:将模型输出转换为车道线坐标点:
python
def __process_output(self, output, cfg, local_width=1):
output = {
"loc_row": output[0], # 行位置预测
"loc_col": output[1], # 列位置预测
"exist_row": output[2], # 行存在性
"exist_col": output[3], # 列存在性
}
# 获取每个位置的最大概率索引
max_indices_row = output['loc_row'].argmax(1)
valid_row = output['exist_row'].argmax(1) # 存在性判断
max_indices_col = output['loc_col'].argmax(1)
valid_col = output['exist_col'].argmax(1)
lanes_points = {"left-side": [], "left-ego": [], "right-ego": [], "right-side": []}
lanes_detected = {"left-side": False, "left-ego": False, "right-ego": False, "right-side": False}
# 处理行锚点(检测水平车道线段)
row_lane_idx = [1, 2] # 左车道线和右车道线
for i in row_lane_idx:
tmp = []
# 存在性判断:超过一半的行位置检测到才算有效
if valid_row[0, :, i].sum() > num_cls_row / 2:
for k in range(valid_row.shape[1]):
if valid_row[0, k, i]:
# softmax + 加权求和,得到亚像素精度的坐标
all_ind = list(range(max(0, max_indices_row[0,k,i] - local_width),
min(num_grid_row-1, max_indices_row[0,k,i] + local_width) + 1))
out_tmp = (_softmax(output['loc_row'][0, all_ind, k, i]) *
list(map(float, all_ind))).sum() + 0.5
out_tmp = out_tmp / (num_grid_row - 1) * original_image_width
tmp.append((int(out_tmp), int(cfg.row_anchor[k] * original_image_height)))
if i == 1:
lanes_points["left-ego"].extend(tmp)
if len(tmp) > 2: lanes_detected["left-ego"] = True
else:
lanes_points["right-ego"].extend(tmp)
if len(tmp) > 2: lanes_detected["right-ego"] = True
# 列锚点处理类似...
return np.array(list(lanes_points.values()), dtype="object"), list(lanes_detected.values())后处理的关键技巧:
- Softmax加权求和 :不是直接取argmax,而是在最大值附近取
local_width个值做softmax加权,这样能得到亚像素精度的坐标 - 存在性判断 :
exist_row/col判断每个位置是否有车道线,超过一半位置检测到才认为该车道线有效 - 4条车道线 :
left-side、left-ego、right-ego、right-side,其中left-ego和right-ego是本车道左右线
5.3 车道区域提取
检测到车道线后,需要提取本车道的区域多边形:
python
def __update_lanes_area(self, lanes_points, img_height):
if self.lane_info._area_status:
index = len(lanes_points) // 2
left_lanes_points = lanes_points[index - 1] # left-ego
right_lanes_points = lanes_points[index] # right-ego
# 可选:多项式拟合平滑车道线
if self.adjust_lanes:
left_lanes_points, right_lanes_points = self.__adjust_lanes_points(...)
# 拼接成封闭多边形:左线点 + 右线点(翻转)
self.lane_info._area_points = np.vstack((
left_lanes_points,
np.flipud(right_lanes_points)
))多项式拟合平滑:
python
@staticmethod
def __adjust_lanes_points(left_lanes_points, right_lanes_points, image_height):
# 二次多项式拟合
leftx, lefty = list(zip(*left_lanes_points))
left_fit = np.polyfit(lefty, leftx, 2)
rightx, righty = list(zip(*right_lanes_points))
right_fit = np.polyfit(righty, rightx, 2)
# 生成拟合后的点
both_fity = np.linspace(miny, maxy, image_height)
left_fitx = left_fit[0]*both_fity**2 + left_fit[1]*both_fity + left_fit[2]
right_fitx = right_fit[0]*both_fity**2 + right_fit[1]*both_fity + right_fit[2]
return [(int(l), int(y)) for l, y in zip(left_fitx, both_fity)], \
[(int(r), int(y)) for r, y in zip(right_fitx, both_fity)]六、车道偏离预警(LDWS)设计
6.1 偏离判断原理
LDWS的核心是计算车辆在车道内的横向偏移量,流程如下:
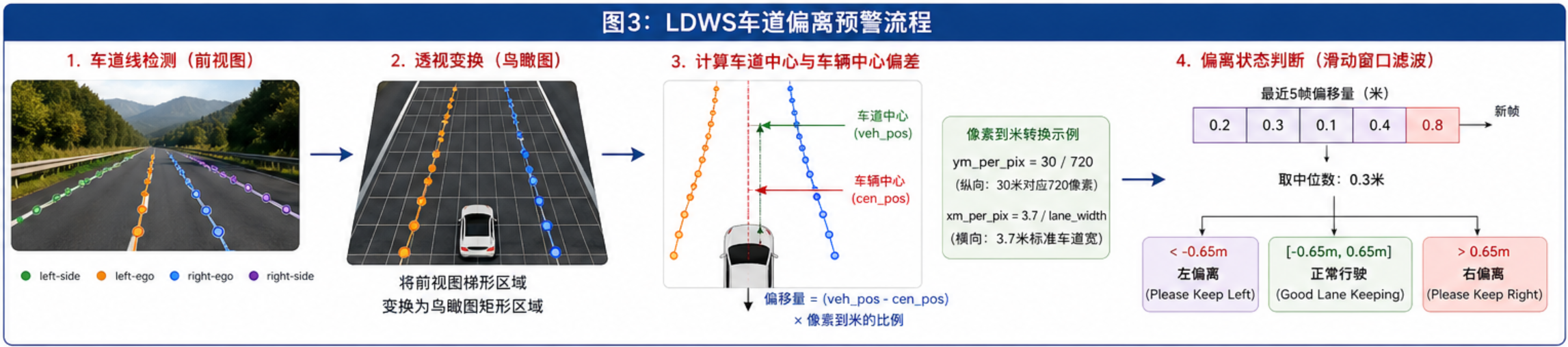
6.2 透视变换
将前视图转为鸟瞰图,才能准确计算偏移量:
python
class PerspectiveTransformation(object):
def __init__(self, img_size=(1280, 720)):
# 源点:前视图中的梯形区域
self.src = np.float32([
(img_size[0]*0.3, img_size[1]*0.7), # 左上
(img_size[0]*0.2, img_size[1]), # 左下
(img_size[0]*0.95, img_size[1]), # 右下
(img_size[0]*0.8, img_size[1]*0.7), # 右上
])
# 目标点:鸟瞰图中的矩形区域
offset_x = img_size[0] / 4
self.dst = np.float32([
(offset_x, 0),
(offset_x, img_size[1]),
(img_size[0] - offset_x, img_size[1]),
(img_size[0] - offset_x, 0),
])
# 计算变换矩阵
self.M = cv2.getPerspectiveTransform(self.src, self.dst)
self.M_inv = cv2.getPerspectiveTransform(self.dst, self.src)
def transformToBirdView(self, img):
return cv2.warpPerspective(img, self.M, self.img_size)6.3 偏移量计算
在鸟瞰图上计算偏移量:
python
def calcCurveAndOffset(self, img, left_lanes, right_lanes):
if len(left_lanes) and len(right_lanes):
# 多项式拟合
left_fit = np.polyfit(left_lanes[:, 1], left_lanes[:, 0], 2)
right_fit = np.polyfit(right_lanes[:, 1], right_lanes[:, 0], 2)
# 像素到米的转换
ym_per_pix = 30 / 720 # 纵向:30米对应720像素
xm_per_pix = 3.7 / 700 # 横向:3.7米(标准车道宽)对应700像素
# 计算车道中心
leftx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]
rightx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]
lane_width = abs(leftx[719] - rightx[719])
lane_xm_per_pix = 3.7 / lane_width
veh_pos = (leftx[719] + rightx[719]) / 2.0 # 车道中心
cen_pos = img.shape[1] / 2.0 # 车辆中心(图像中心)
# 偏移量(米),正=右偏,负=左偏
distance_from_center = (veh_pos - cen_pos) * lane_xm_per_pix
return distance_from_center6.4 偏离状态判断
python
class TaskConditions(object):
def __init__(self):
self.vehicle_offset_record = LimitedList(5) # 滑动窗口5帧
def UpdateOffsetStatus(self, vehicle_offset, offset_thres=0.65):
if vehicle_offset is not None:
self.vehicle_offset_record.append(vehicle_offset)
if self.vehicle_offset_record.full():
avg_offset = np.median(self.vehicle_offset_record)
if abs(avg_offset) > offset_thres:
if avg_offset > 0:
self.offset_msg = OffsetType.RIGHT # "Please Keep Right"
else:
self.offset_msg = OffsetType.LEFT # "Please Keep Left"
else:
self.offset_msg = OffsetType.CENTER # "Good Lane Keeping"偏离阈值说明:
offset_thres=0.65:偏移量超过0.65米触发预警- 使用中位数滤波避免抖动
- 滑动窗口5帧(30fps下约0.17秒延迟)
七、可视化效果
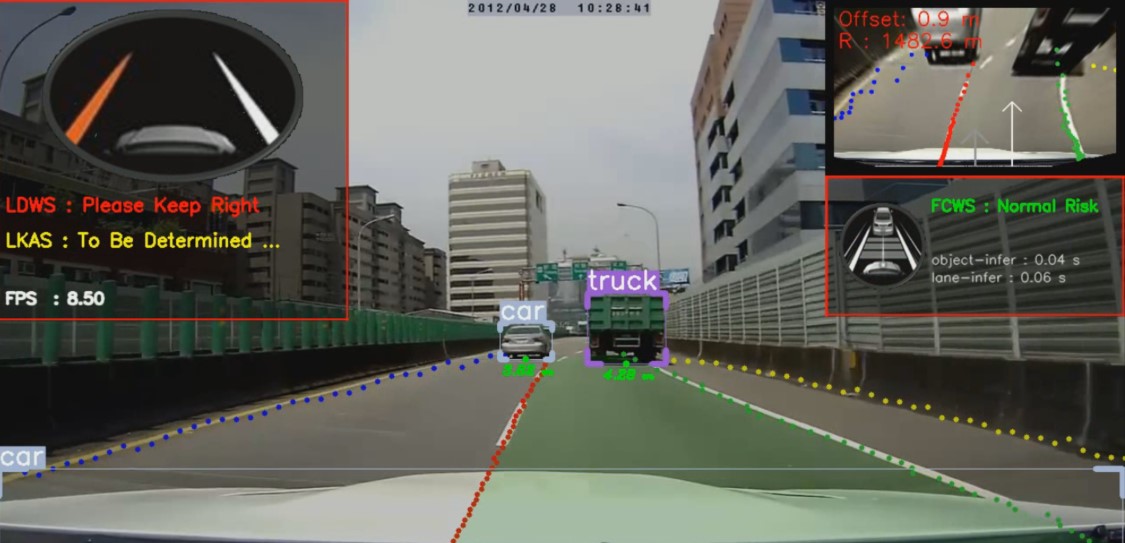
7.1 车道线绘制
python
def DrawDetectedOnFrame(self, image, type=OffsetType.UNKNOWN, alpha=0.3):
overlay = image.copy()
for lane_num, lane_points in enumerate(self.lane_info.lanes_points):
# 偏离时对应车道线变红
if lane_num == 1 and type == OffsetType.RIGHT:
color = (0, 0, 255)
elif lane_num == 2 and type == OffsetType.LEFT:
color = (0, 0, 255)
else:
color = lane_colors[lane_num]
for lane_point in lane_points:
cv2.circle(overlay, lane_point, 3, color, thickness=-1)
image[:] = cv2.addWeighted(overlay, alpha, image, 1 - alpha, 0)7.2 车道区域填充
python
def DrawAreaOnFrame(self, image, color=(255, 191, 0), alpha=0.85):
if self.lane_info.area_status:
lane_segment_img = image.copy()
cv2.fillPoly(lane_segment_img, pts=[self.lane_info.area_points], color=color)
image[:] = cv2.addWeighted(image, alpha, lane_segment_img, 1 - alpha, 0)八、性能指标与优化方向
8.1 性能参考
| 指标 | 数值 | 说明 |
|---|---|---|
| 推理速度(ONNX) | ~15ms/帧 | ResNet18 + ONNX Runtime |
| 推理速度(TensorRT FP16) | ~5ms/帧 | 需要TensorRT环境 |
| CULane F1 | ~75% | ResNet18 |
| 模型大小 | ~16MB | ONNX格式 |
8.2 优化方向
- 换更轻量的Backbone:ResNet18 → MobileNetV3,速度更快
- TensorRT部署:FP16推理可提速3倍
- 动态透视变换:根据车道线位置自适应调整变换区域(项目已实现)
- 夜间增强:加入低光照增强预处理
- 时序平滑:利用前后帧的车道线一致性做时序滤波
九、完整使用流程
python
from TrafficLaneDetector import UltrafastLaneDetectorV2
from TrafficLaneDetector.ufldDetector.perspectiveTransformation import PerspectiveTransformation
from taskConditions import TaskConditions
# 1. 初始化车道检测模型
lane_config = {
"model_path": "./TrafficLaneDetector/models/ufldv2_culane_res18_320x1600.onnx",
"model_type": LaneModelType.UFLDV2_CULANE
}
UltrafastLaneDetectorV2.set_defaults(lane_config)
laneDetector = UltrafastLaneDetectorV2(logger=LOGGER)
# 2. 初始化透视变换
transformView = PerspectiveTransformation((width, height))
# 3. 初始化状态分析
analyzeMsg = TaskConditions()
# 4. 主循环
while cap.isOpened():
ret, frame = cap.read()
if ret:
# 车道线检测
laneDetector.DetectFrame(frame)
# 透视变换
birdview_show = transformView.transformToBirdView(frame)
birdview_lanes_points = [transformView.transformToBirdViewPoints(lp)
for lp in laneDetector.lane_info.lanes_points]
# 计算偏移量
(_, _), vehicle_offset = transformView.calcCurveAndOffset(
birdview_show, *birdview_lanes_points[1:3])
# 更新偏离状态
analyzeMsg.UpdateOffsetStatus(vehicle_offset)
# 可视化
laneDetector.DrawDetectedOnFrame(frame, analyzeMsg.offset_msg)
laneDetector.DrawAreaOnFrame(frame)十、总结
UFLDv2是一个非常实用的车道线检测算法,它的行/列锚点设计让速度和精度达到了很好的平衡。基于检测结果,通过透视变换和偏移量计算,就能搭建一个实用的LDWS系统。
做这个模块时我最大的体会是:后处理和状态判断比模型本身更重要。模型给出的是每帧的原始检测结果,如何把这些结果变成稳定可靠的预警信号,才是真正考验工程能力的地方。
希望这篇文章对你有帮助!如果你在做车道线检测时遇到什么问题,欢迎交流。