一、RAG 存在的问题
1. RAG 流程
RAG(Retrieval-Augmented Generation)将检索与生成结合,基本流程分为两个阶段:
索引阶段(Index Process)
-
加载文件:读取原始文档(PDF、Word、HTML、Markdown、TXT、CSV 等)
-
读取文本:提取文档中的文字内容,处理表格、图片等非结构化数据
-
文本分割:将长文本切分成更小的"块"(chunks)
-
文本向量化:使用嵌入模型将每个文本块转换为向量表示
-
存入数据库:将向量与原始文本关联存储到向量数据库(如 FAISS、Chroma、Pinecone)
查询阶段(Query Process)
-
用户提问:输入自然语言问题
-
问句向量化:用同一嵌入模型将问题转换为向量
-
相似度检索:在向量库中匹配最相似的 top k 个文本块
-
构建 prompt:将检索到的文本块作为上下文,与问题一起填入预定义的 prompt 模板
-
LLM 生成:提交给大语言模型,生成最终答案
2. RAG 痛点分析
索引阶段的故障点
-
内容缺失(Missing Content)
知识库中根本没有回答问题所需的信息。此时 RAG 容易"编造"答案,产生幻觉。
例子:知识库只包含产品说明书,用户问"售后服务电话是多少",库中无此信息,模型可能随便编一个号码。 -
文档加载准确性和效率
PDF、图片型扫描件、复杂表格等格式解析困难。
例子:PDF 中的文字可能是图片的一部分,或表格结构在提取后变成纯文本,丢失行列关系。 -
文档切分的粒度(Chunking Granularity)
块太大:包含无关信息,干扰答案,且浪费 token。
块太小:关键信息可能被切散,答案不完整。
例子:一个问题的答案需要跨越两个相邻段落,如果切分将它们分开,检索可能只拿到其中一段。
查询阶段的故障点
-
错过排名靠前的文档(Missed Top Ranked)
正确答案在知识库中,但其向量相似度排名不高(比如排在第 6 位,而只取 top 5),导致未被召回。
-
上下文与答案无关(Not in Context)
检索到的文本块虽然相似,但实际不包含答案,这是前两个问题的直接后果。
-
格式错误(Wrong Format)
LLM 没有按要求的格式输出。
例子:要求返回 JSON{"answer": "..."},模型却返回普通字符串"答案是 42"。 -
答案不完整(Incomplete)
答案只回答了问题的一部分,遗漏其他要点。
例子:问"A 和 B 的区别是什么",只回答了 A 的特点,未提 B。 -
未提取到答案(Not Extracted)
检索到的上下文中明明有正确答案,但 LLM 未能从中提取出来。
原因:上下文过长、信息分散、模型注意力不足等。 -
答案粒度不当(Incorrect Specificity)
答案过于具体或过于笼统。
例子:问"如何修复网络连接问题",答"检查网线"(太具体)或"尝试一些方法"(太笼统)
二、RAG 优化方法
1. 内容缺失
-
扩充知识库:识别缺失的知识领域,主动添加相关文档或数据源。
-
数据清洗与增强:去除噪声、统一格式、消除矛盾。例如,使用正则表达式清理特殊符号,或用大模型对冲突信息进行消歧。
-
Prompt 引导拒答:在 prompt 中加入指令:"如果你无法从给定的上下文中找到确切答案,请回答'根据现有知识库,无法回答该问题'。" 这能有效减少胡乱编造。
2. 文档加载准确性和效率
-
专用文档解析器:
-
PDF:使用
pdfplumber或PyMuPDF提取文字,对扫描件配合 OCR(如 Tesseract)。 -
HTML:使用
BeautifulSoup或 LangChain 的WebBaseLoader去除标签、保留正文。 -
表格:使用
pandas保留结构,或将每行转为句子描述。
-
-
数据预处理流水线:建立统一的清洗流程(去空白、规范化、去除非内容标记等)。
3. 文档切分的粒度
选择合适的策略比固定一种分割方式更重要:
-
固定长度分块:最简单,直接按 token 数或字符数切分,适合通用场景。
-
内容重叠分块:相邻块保留重叠部分(如重叠 10%~20%),避免信息被切散到边界。
-
基于结构的分块 :利用 Markdown 标题、HTML 章节、段落标记,保持逻辑单元完整。例如按
##分割。 -
递归分块 :LangChain 的
RecursiveCharacterTextSplitter先尝试按段落\n\n切分,若块过大则按\n再切,再大则按空格、字符依次细分。 -
分块大小选择因素:
-
嵌入模型偏好:OpenAI
text-embedding-ada-002在 512 tokens 左右效果较好;开源模型可能更短。 -
文档类型:长文档(书籍、论文)用较大块(800-1200 tokens);短消息、FAQ 用小块(200-300 tokens)。
-
查询特征:短查询配合小块;长查询、复杂问题配合大块或使用多级检索。
-
4. 错过排名靠前的文档
-
过召回 + 重排序(Reranking):
-
设置较大的初始召回数量(如 topK=20)。
-
使用更精细的重排模型(如 Cohere Rerank、BGE-reranker)对 20 个结果重新计算相关性分数。
-
取重排后的前 3~5 个作为最终上下文。
优点:兼顾效率和精度,避免简单增大 K 带来的噪声。
-
-
多路检索:同时使用关键词检索(BM25)和向量检索,合并结果后再重排。
5. 提取上下文与答案无关
该问题通常是"内容缺失"或"错过排名靠前文档"的直接体现,因此优化应回归到:
-
确保知识库覆盖足够广且质量高。
-
使用重排序提高召回的准确率。
-
可增加 查询重写 步骤:将原始问题改写为更精准的多个子查询,分别检索后合并。
6. 格式错误
-
Prompt 工程 :明确要求格式并给出示例(Few-shot)。
示例:text
请严格以 JSON 格式返回,例如:{"answer": "云计算的英文是 Cloud Computing"} -
结构化输出解析器 :使用 LangChain 的
PydanticOutputParser:-
定义 Pydantic 数据模型(如
class Answer(BaseModel): answer: str)。 -
解析器自动验证 LLM 输出,若不匹配则尝试修复或重试。
-
-
输出后处理:对常见错误(如忘记闭合括号、多了额外文本)用正则或简单逻辑修复。
7. 答案不完整
-
问题分解:
-
引导用户将复杂问题拆解为多个简单问题。
-
或自动使用 LLM 将原问题分解成若干子问题,依次检索并收集答案,最后再汇总生成最终回答。
-
-
多跳检索(Multi-hop Retrieval):对于需要多个事实才能回答的问题,先检索第一个证据,再用它生成下一个查询,迭代获取完整信息。
8. 未提取到答案
-
提示压缩技术 :当检索到的上下文很长时,使用 上下文压缩 方法:
-
先用一个轻量级模型(或 LLM 自身)提取与问题最相关的句子。
-
或者使用
LLMChainExtractor(LangChain 提供),它会自动识别并保留只有相关内容的压缩文档。 -
压缩后的 prompt 更短,模型更容易定位答案,同时节省 token。
-
-
优化指令:在 prompt 中强调"请基于下面上下文中的原文来回答,不要自己编造"。
9. 答案太具体或太笼统(与幻觉高度相关)
-
暂无彻底解决方案,这是大模型固有的"幻觉"问题的一种表现形式。
-
可尝试的缓解措施:
-
使用更大的模型(如 GPT-4 比 GPT-3.5 更稳定)。
-
增加检索上下文的多样性和冗余度(多个来源支持同一答案)。
-
加入置信度评分:要求模型同时输出对答案的确信程度。
-
使用反馈循环:让另一个模型实例评估答案的粒度是否合适,并修正。
-
三、Advanced RAG
在基础 RAG 基础上,Advanced RAG 通过预检索策略 和后检索策略提升检索质量,从而更好地解决内容缺失、排名靠后、答案不完整等痛点。
一、预检索策略
1. 优化索引(提高被检索内容的质量)
-
增强数据颗粒度:合理切分文档,保留完整语义单元。
-
优化索引结构:如使用层级索引、摘要索引等。
-
添加元数据:为每个文本块附加时间、来源、标题等信息,便于过滤。
-
对齐优化:使文本块与常见查询类型更匹配。
-
混合检索:结合向量检索与关键词检索(如 BM25),兼顾语义与精确匹配。
2. 查询优化(让原始问题更适合检索)
查询重写(Query Rewriting)
-
目标:不改变意图,仅优化表述清晰度与完整性。
-
常用技术 :使用 LLM 重写查询。
示例 Prompt :
"请将以下用户查询改写成更清晰、更完整的句子,同时保持原意不变。用户查询:{query}"
查询转换(Query Transformation)
-
目标:改变查询形式,使其更易检索。
-
常用技术:
-
关键词提取:只保留名词、动词等核心词。
-
步退提示(Step-back Prompting):将复杂问题抽象成更高级的背景问题,先检索背景知识,再结合原问题检索。
-
子问题分解:将复杂问题拆解为多个简单子问题,分别检索后合并答案(通常需多步检索)。
-
查询扩展(Query Expansion)
-
目标:增加相关术语或上下文,丰富查询信息。
-
常用技术:
-
LLM 扩展:让模型生成与原始查询相关的扩展词或短语。
-
多查询扩展:生成多个不同表述的查询变体,分别检索后合并结果。
-
二、后检索策略(优化检索结果的集成方式)
1. 重排序(Reranking)
-
目标:对检索到的文档列表重新排序,将更相关、更准确的文档排在前面。
-
实现方式:使用专用重排模型(如 Cohere Rerank、BGE-reranker)计算查询与文档之间的相关性得分,按得分排序。
-
典型流程:先过召回(如 top 20),再重排取前几名(如 top 3)。
2. 摘要(Summary)
-
目标:生成检索结果的简短摘要,帮助用户快速把握主要内容。
-
两种方法:
-
抽取式摘要:直接选取原文中的关键句子或短语。
-
生成式摘要:使用 LLM 重新生成简明的摘要文本。
-
3. 融合(Fusion)------ 以 RAG-Fusion 为代表
-
目标:从原始查询生成多个相似但不完全相同的查询变体,覆盖用户意图的多个方面,提升检索结果的全面性与相关性。
-
典型步骤:
-
基于原始查询生成多个查询变体。
-
对每个变体分别检索。
-
融合所有检索结果(如使用倒数排名融合 RRF 或重排合并)。
-
四、RAG实战
1.背景与痛点
RAG(检索增强生成)是目前大语言模型落地问答系统的标配架构。但朴素 RAG 常常面临一些"翻车"场景:
-
用户问了一个知识库里没有的问题,模型却自信地胡编乱造;
-
检索到的文档压根不相关,模型仍然强行生成答案;
-
一些通用问题(如"今天天气如何")本应联网搜索,却走内部向量库,得到"未找到答案"的尴尬回复。
为此设计了一个具备自适应路由 + 自我纠错 + 网络回退的增强型 RAG 系统。它能像一位经验丰富的客服经理一样:先判断问题归属,再从合适的来源找资料,还能自我评估检索质量,必要时重写查询甚至更换搜索渠道。
基于 LangChain + LangGraph + Chroma + 智谱大模型,完整实现这一系统。
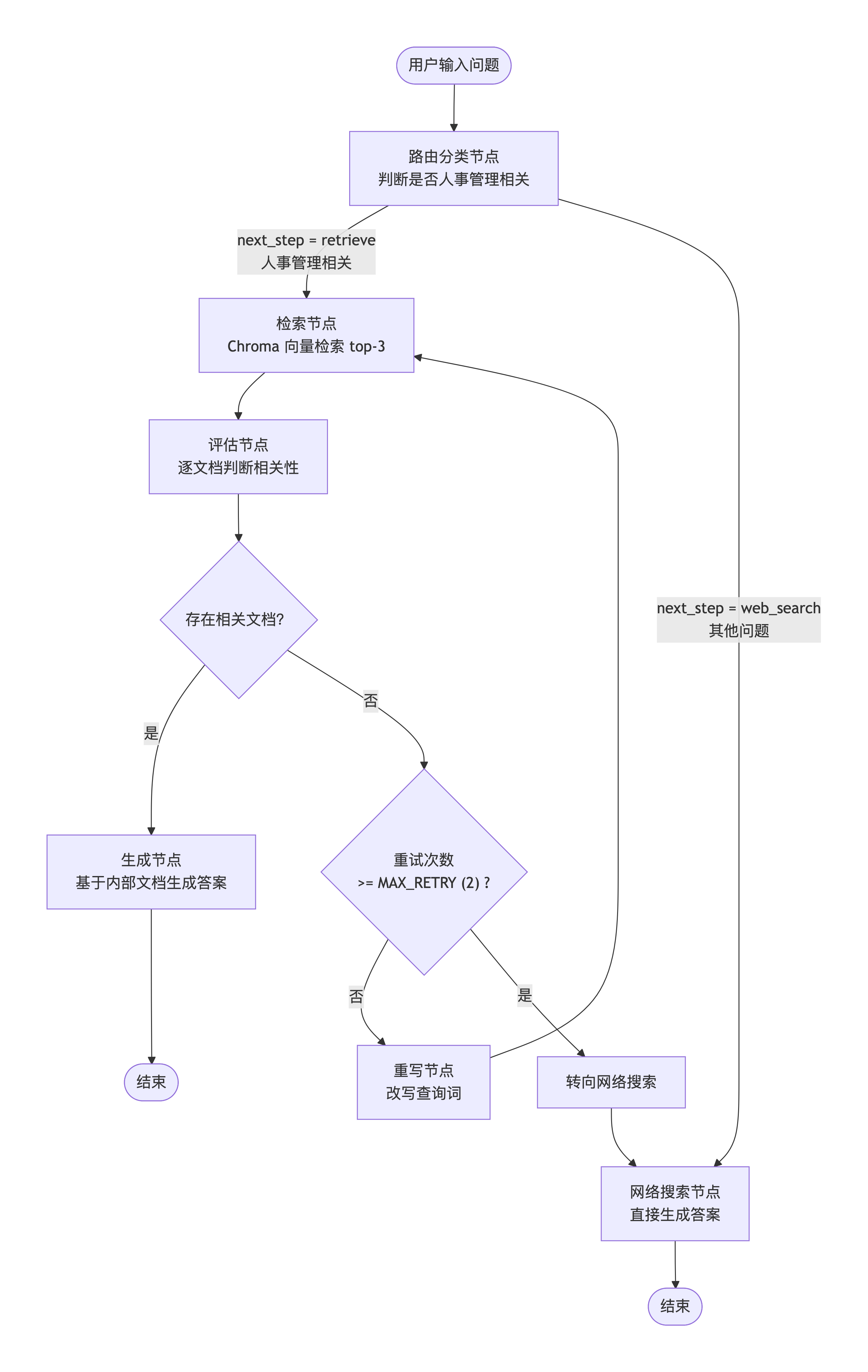
2. 总体架构
系统整体流程图
-
顶层路由器:使用 LLM 判断问题属于"人事管理"(内部知识库)还是"通用问题"(网络搜索)。
-
内部检索闭环:检索 → 评估 → 不合格则重写查询 → 重试,最多 2 次。
-
网络回退:内部检索失败或通用问题直接调用智谱搜索引擎,确保高覆盖率。
-
自我纠错:评估节点用 LLM 判定文档相关性,避免"垃圾进垃圾出"。
3.完整代码
3.1定义状态和常量
from typing import TypedDict, List
from langchain.agents import create_agent
from langchain_community.document_loaders import WebBaseLoader, UnstructuredWordDocumentLoader
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import tool
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.constants import END
from langgraph.graph import StateGraph
from agent.my_llm import llm, zhipuai_client
#最大重试次数
MAX_RETRY = 2
#自定义状态类
class GraphState(TypedDict):
question: str #问题
generation: str #最总答案
documents: List[Document] #搜索到的文档
retry_count: int #重试次数
next_step: str #下一步节点3.2构建知识库
-
Word 文档 :
人事管理流程.docx,包含请假、考勤、薪酬等内容#加载文档
web_loader = WebBaseLoader(
web_paths=('https://news.pku.edu.cn/mtbdnew/12ade13c2ed542fda4ab268ca3bc4524.htm',),
)
web_documents = web_loader.load()
#加载文档
doc_loader = UnstructuredWordDocumentLoader("./人事管理流程.docx")
doc_documents = doc_loader.load()#切分文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(doc_documents)
3.3 向量存储
采用 Chroma(轻量级本地向量库),配合智谱的 embedding-2 模型。
#embedding 模型
# 智谱 Embedding 配置
embeddings = ZhipuAIEmbeddings(
api_key="XXX",
model="embedding-2", # 智谱的 embedding 模型名
)
vector_store = Chroma.from_documents(
documents=docs, # 这里使用您加载并分割后的文档列表
embedding=embeddings, # 使用您的智谱嵌入模型
persist_directory="./chroma_db", # 本地持久化目录
collection_name="demo_rag"
)3.4核心节点
3.4.1检索节点
#检索节点
def retrieve(state: GraphState):
print("----------进入检索节点----------")
question = state['question']
documents = vector_store.similarity_search(question, k=3)
print(f"----------检索到{len(documents)}个文档----------")
return {"documents": documents, "retry_count": state.get("retry_count", 0) + 1}3.4.2评估节点
grade_prompt = """
您是一个评估检索到的文档与用户问题相关性的评分员。
这个测试不需要非常严格,目标是过滤掉明显错误的检索结果。
如果文档包含与用户问题相关的关键词或语义信息,就判定为相关。
相关则回答'yes' 否则回答'no'
严格输出'yes'或者'no'不要输出其它内容
"""
prompt_template = ChatPromptTemplate.from_messages(
[
("system", grade_prompt),
("human", "检索到的文档: \n\n {document} \n\n 用户问题: {question}")
]
)
chain = prompt_template | llm | StrOutputParser()
#评估节点
def grade_documents(state: GraphState) -> dict:
print("----------进入评估节点----------")
question = state["question"]
documents = state["documents"]
filtered_docs = []
for doc in documents:
score = chain.invoke(
{"question": question, "document": doc.page_content}
)
if score == 'yes':
filtered_docs.append(doc)
print(f"----------评估合格文档数:{len(filtered_docs)}----------")
return {"documents": filtered_docs}3.4.3生成节点
#生成节点
def generate(state: GraphState) -> dict:
print("----------进入生成节点----------")
"""节点:基于评估合格的文档生成最终答案"""
print("---生成节点---")
question = state["question"]
documents = state["documents"]
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个乐于助人的助手。请严格基于提供的上下文来回答问题。如果无法从上下文中找到答案,请如实告知。"),
("human", "上下文: {context}\n\n问题: {question}"),
]
)
rag_chain = prompt | llm | StrOutputParser()
generation = rag_chain.invoke({"question": question, "context": format_docs(documents)})
return {"generation": generation}3.4.4重写节点
#重写节点
def rewrite_query(state: GraphState):
print("----------进入重写节点----------")
question = state["question"]
rewrite_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个查询重写助手。你的任务是将用户的问题改写成更适合进行语义检索的版本。"),
("human", "原始问题: {question}")
]
)
rewrite_chain = rewrite_prompt | llm | StrOutputParser()
better_question = rewrite_chain.invoke({"question": question})
return {"question": better_question}3.4.5网络搜索节点
@tool
def search_tool(query:str) -> str:
"""网络搜索工具"""
try:
response = zhipuai_client.web_search.web_search(search_engine="search_pro", search_query=query)
if response.search_result:
return "\n\n".join([result.content for result in response.search_result])
return "没有搜素到任何内容"
except Exception as e:
print(e)
return "搜索出现错了"
#网络搜索节点
def web_search(state: GraphState) -> dict:
question = state['question']
agent = create_agent(
llm,
tools=[search_tool],
system_prompt="你是一个智能助手可以的调用工具回答用户的问题"
)
resp = agent.invoke({"messages": [HumanMessage(content=question)]})
return {"generation": resp['messages'][-1].content}3.4.6路由分类节点
def route_classifier(state: GraphState) -> dict:
question = state['question']
classification_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个分类器。请判断用户问题是否与"人事管理流程"相关。
人事管理流程包括:请假、考勤、招聘、入职、离职、培训、绩效考核、薪资福利等人力资源管理相关事务。
如果问题涉及上述内容,请回答 'hr';否则回答 'general'。
只输出 'hr' 或 'general',不要输出其他内容。"""),
("human", "问题:{question}")
])
classifier_chain = classification_prompt | llm | StrOutputParser()
decision = classifier_chain.invoke({"question": question}).strip().lower()
print(f"---路由决策:问题 '{question}' 被分类为 '{decision}'---")
if decision == "hr":
return {"next_step": "retrieve"} # 走内部向量检索流程
else:
return {"next_step": "web_search"} # 走网络检索节点3.5工作流组装
#条件边
def decide_to_generate(state: GraphState):
filtered_documents = state["documents"]
retry_count = state.get("retry_count", 0)
if not filtered_documents:
# 没有相关文档
if retry_count >= MAX_RETRY:
print(f"---已达到最大重试次数 ({MAX_RETRY}),无法找到答案,转向网路搜素---")
return "web_search" # 转向特殊处理节点
else:
print(f"---无相关文档,当前重试次数 {retry_count},将进行查询重写---")
return "rewrite_query"
else:
return "generate"
# 4. 构建工作流
workflow = StateGraph(GraphState)
# 添加节点
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("rewrite_query", rewrite_query)
workflow.add_node("generate", generate)
workflow.add_node("web_search", web_search)
workflow.add_node("route_classifier", route_classifier)
# 设置入口点
workflow.set_entry_point("route_classifier")
# 分类器的条件边
workflow.add_conditional_edges(
"route_classifier",
lambda state: state.get("next_step", "retrieve"), # 实际从分类器返回值决定(我们需要用一个临时变量)
{
"retrieve": "retrieve",
"web_search": "web_search",
}
)
# 添加边
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"rewrite_query": "rewrite_query",
"generate": "generate",
"web_search": "web_search", # 新增分支
},
)
workflow.add_edge("rewrite_query", "retrieve") # 重写后需重新检索
workflow.add_edge("generate", END)
workflow.add_edge("web_search", END)
# 编译应用
app = workflow.compile()3.6测试
# 假设你的提问是:
final_state = app.invoke({"question": "薪酬组成结构?", "retry_count": 0})
# 观察终端输出,看看系统是否会在第一次检索失败后,重写查询词并再次尝试。
print("最终答案:", final_state["generation"])
# 假设你的提问是:
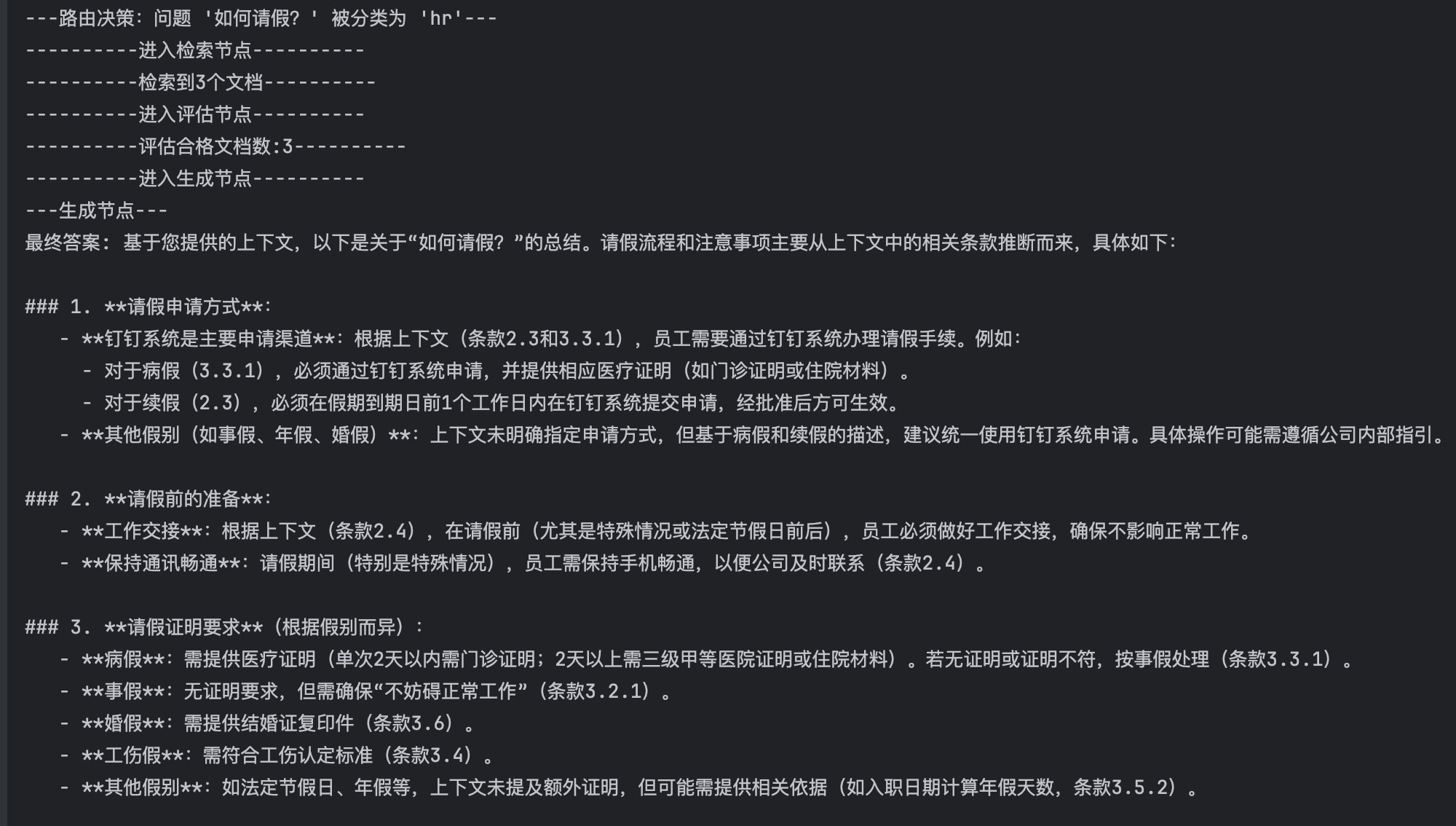
final_state = app.invoke({"question": "如何请假?", "retry_count": 0})
# 观察终端输出,看看系统是否会在第一次检索失败后,重写查询词并再次尝试。
print("最终答案:", final_state["generation"])