声明:
- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
目录
[Dense Block](#Dense Block)
[Transition Layer](#Transition Layer)
我的环境:
Python版本:3.10.19
PyTorch版本:2.9.1+cu130
Torchvision版本:0.24.1+cu130
CUDA版本:13.0
GPU设备:NVIDIA GeForce RTX 5060
一、网络介绍:
1.WHY
2016年,康奈尔大学、清华大学与Facebook FAIR的研究团队合作提出了DenseNet(Densely Connected Convolutional Networks),论文一举斩获CVPR 2017最佳论文奖。
要理解DenseNet的动机,需要先回到我们上一节介绍的ResNet的成功与局限。何恺明在提出ResNet时做了一个关键假设:如果对某一网络中增添一些可以学到恒等映射的层,那么最差的结果也是新网络的这些层在训练后成为恒等映射而不影响原网络性能。基于这一假设,ResNet通过identity shortcut让信号绕过非线性变换,成功训练了超过100层的网络。
然而问题也随之而来。ResNet虽然通过skip connection保留了信息流,但其合并方式------element-wise summation ------在每个shortcut交汇处将原始信号与变换后的信号直接相加。这种做法可能破坏已学习到的特征信息 ,导致网络不得不重新学习冗余特征。DenseNet的作者团队从另一个工作中获得关键启发:随机深度网络(Stochastic Depth)的实验表明,ResNet中很多层可以被随机丢弃而不显著影响预测结果,这意味着ResNet的每一层只提取了非常少的特征,存在明显的冗余性。
正是基于这两点观察------求和会破坏信息流 和层间存在大量冗余 ------DenseNet提出了一个截然不同的假设:特征复用。与其让每一层重复学习冗余的特征,不如让早期层提取的特征图被所有后续层直接访问和使用。换言之,如果某个特征图在早期就有用,那么它应该在网络的任何阶段都无需重新计算即可被使用。
DenseNet的核心创新在于改变了跨层连接的信息合并方式:用 concatenation(按通道拼接)取代了 summation(按元素相加)。这一改变确保了原始特征图不会被破坏,每一层都能访问到"集体知识"中的所有历史信息
2.WHAT
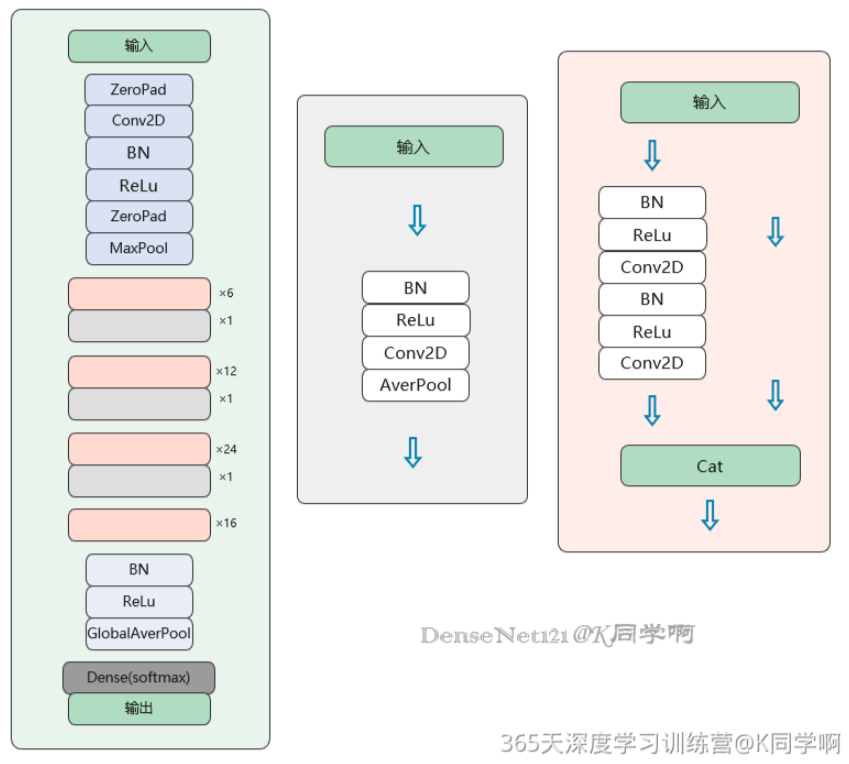
DenseNet的整体架构由两个核心模块交替堆叠而成:Dense Block(密集块) 和 Transition Layer(过渡层)
Dense Block
Dense Block是DenseNet的核心组件。在一个Dense Block内部,每一层的输入都是前面所有层输出的拼接,且该层输出的特征图也会被后续所有层所使用。
在Dense Block内部,特征图的空间尺寸保持不变 ,因此不同层的输出可以在Channel维度上顺利拼接。并且DenseNet中有一个核心超参数------Growth Rate(增长率) ,通常记为 k。
它的含义很简单:在Dense Block内部,每一层产生的新增特征图数量就是 k。
DenseNet的一个关键设计理念是让每一层非常"窄"------k通常很小(如12, 24, 32),远小于ResNet单层输出的几百个Channel。这样做有两个好处:
-
参数极省:每一层只需学习少量新特征,大量的特征通过Concat从前面层复用而来。
-
信息精炼:每一层只需要学习"增量知识",添加到网络的"集体知识库"中,而不需要重复存储已有特征。
Transition Layer
Dense Block内部不改变特征图尺寸,因此下采样操作交给了Transition Layer 。Transition Layer位于两个相邻Dense Block之间,由1×1卷积 + 2×2平均池化组成:
-
1×1卷积:将前一个Dense Block输出的通道数压缩到 θ×mθ×m(其中m是输入通道数,θ称为压缩因子)
-
平均池化:将特征图空间尺寸减半(H→H/2, W→W/2)
当压缩因子 θ < 1 时,Transition Layer会主动压缩特征图的通道数。论文中取 θ = 0.5 ,即每次将通道数减半,带有这种压缩机制的DenseNet被称为DenseNet-C。
二、运行结果
DenseNet
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self, in_channels, growth_rate):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, growth_rate * 4, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(growth_rate * 4)
self.conv2 = nn.Conv2d(growth_rate * 4, growth_rate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat([x, out], 1)
return out
class DenseBlock(nn.Module):
def __init__(self, in_channels, num_layers, growth_rate):
super(DenseBlock, self).__init__()
self.layers = nn.ModuleList([Bottleneck(in_channels + i*growth_rate, growth_rate) for i in range(num_layers)])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
class Transition(nn.Module):
def __init__(self, in_channels, out_channels):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(in_channels)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
def forward(self, x):
out = self.conv(F.relu(self.bn(x)))
out = self.avg_pool(out)
return out
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_classes=4):
super(DenseNet, self).__init__()
num_init_features = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
num_features = num_init_features
self.blocks = nn.ModuleList()
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_features, num_layers, growth_rate)
self.blocks.append(block)
num_features += num_layers * growth_rate
if i != len(block_config) - 1:
transition = Transition(num_features, num_features // 2)
self.blocks.append(transition)
num_features //= 2
self.bn_final = nn.BatchNorm2d(num_features)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(num_features, num_classes)
def forward(self, x):
out = self.conv1(x)
for block in self.blocks:
out = block(out)
out = F.relu(self.bn_final(out))
out = self.avg_pool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
model = DenseNet().to(device)
model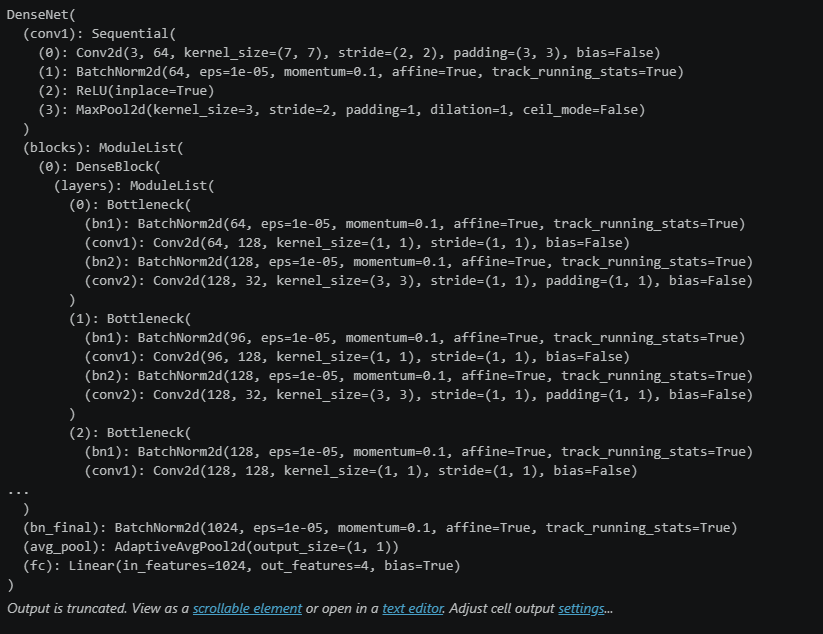
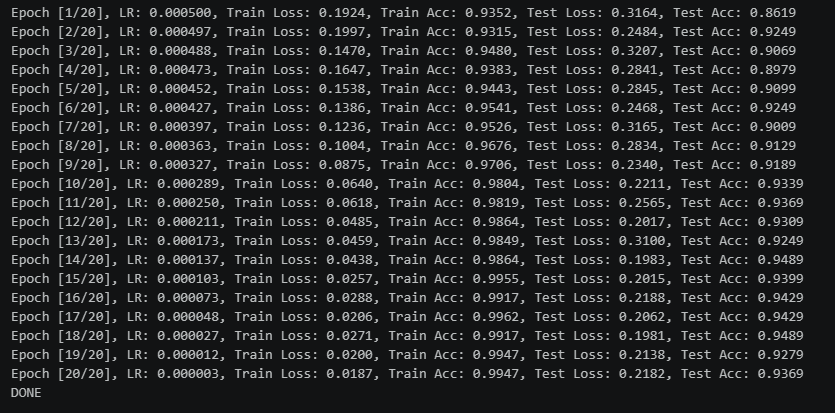
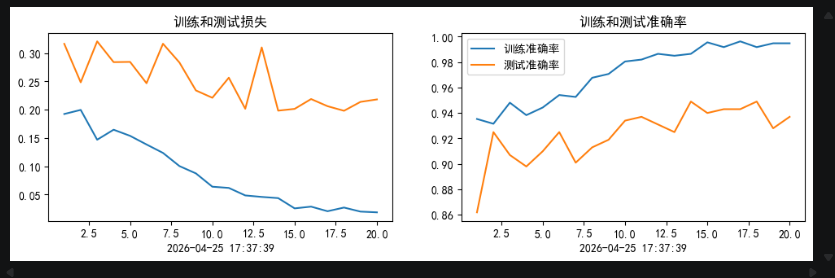
50次余弦退火训练结果
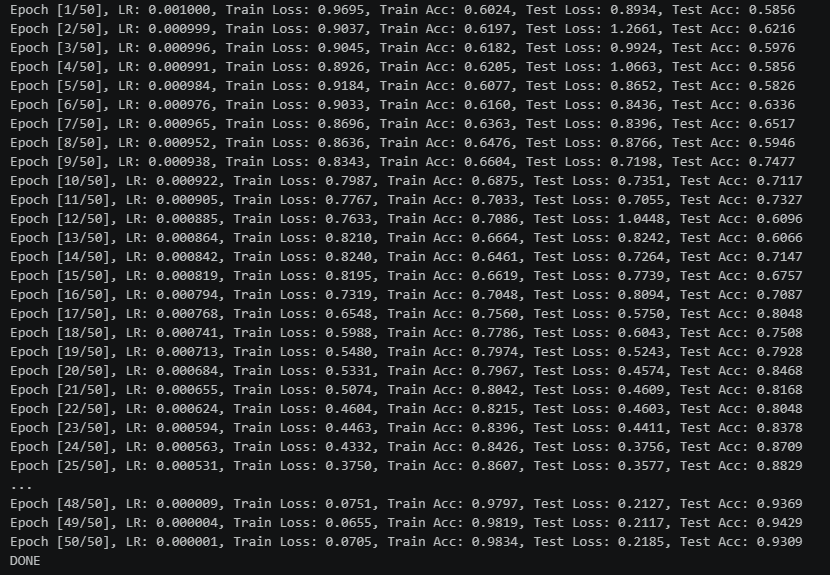
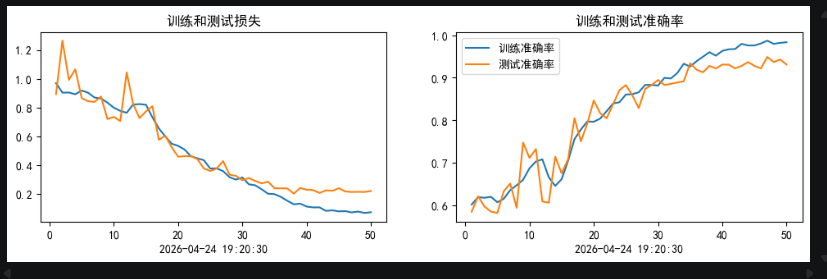
再加20次初始值减半的余弦退火训练结果
三、总结:
本次我们在以前的数据集上,学习并训练了一个新的模型结构DenseNet,了解了它的起源结构特点以及优缺点。经过自己动手实操,自己搭建模型,大幅度增加了我对DenseNet网络的认知。
DenseNet的提出为深度学习架构设计开辟了一条新的道路:不再靠"更深"或"更宽"赢取性能,而是通过极致的连接密度和特征复用,实现参数效率的最大化。其"加法不做、拼接收好"的设计哲学,与ResNet代表了解决深层网络梯度传播问题的两种互补思路。