文章目录
- 一、概念简述
- 二、快速上手
- 三、定义模型
- 四、工具
-
- [4.1 工具定义](#4.1 工具定义)
-
- [方法一:@tool 装饰器](#方法一:@tool 装饰器)
- 方法二:StructuredTool
- [4.2 绑定工具](#4.2 绑定工具)
- [4.3 调用工具](#4.3 调用工具)
- [4.4 工具搜索](#4.4 工具搜索)
一、概念简述
LangChain 是一个围绕大语言模型(LLM)构建的应用开发框架,核心思路是把"调用模型 "这件事拆解成一组可复用的模块,让开发者不用每次都从零开始写对话管理、提示词拼接、工具调用这些重复的东西。
要知道光有一个能聊天的模型是不够的,真实业务里还得让它查数据库、调接口、记住上下文、按特定格式输出......这些"周边工作"堆在一起非常麻烦,LangChain 就是把这套脚手架帮你搭好。
核心概念:
- Model:对各家 LLM 的统一封装,换模型不用改业务代码。
- Prompt:提示词模板管理,支持变量插入、Few-shot 示例等。
- Chain:把多个步骤串起来顺序执行,比如"先检索文档 → 再让模型回答"。
- Tool:模型可以调用的外部能力,比如搜索、计算器、数据库查询。
- Memory:跨轮次的上下文记忆,用来维持多轮对话状态。
- Agent:让模型自己决定调用哪些工具、以什么顺序执行,而不是写死流程。
目前 LangChain 生态分两个主要包:langchain-core(核心抽象)和 langchain(上层封装),另外有 langchain-openai、langchain-anthropic 这类针对具体厂商的集成包。
二、快速上手
底层框架
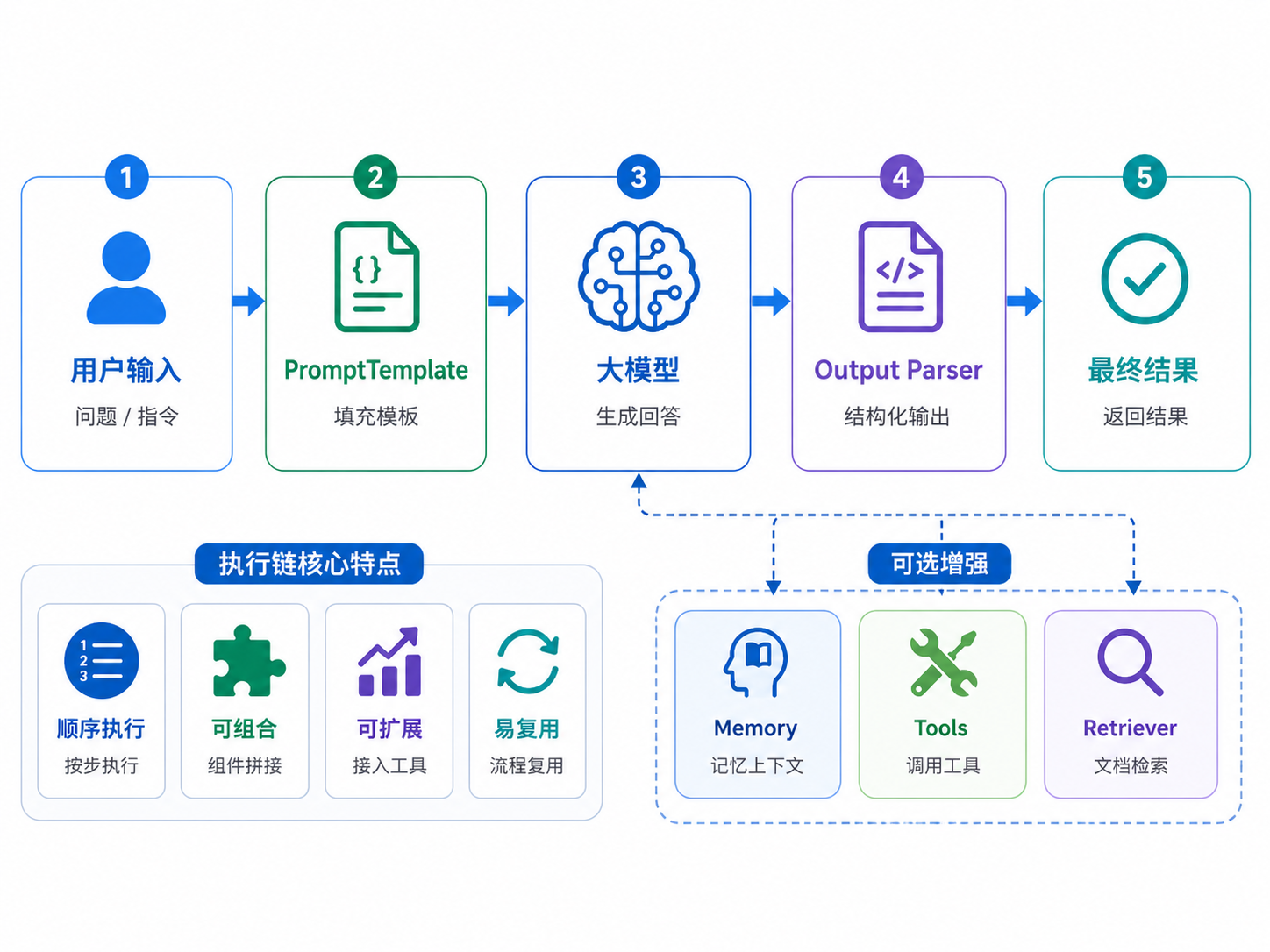
LangChain 的底层是一套基于管道操作符 | 的链式调用语法。每个组件------模型、提示词、解析器都实现了统一的 Runnable 接口,所以可以像搭积木一样随意组合。
示例:
Prompt | Model | OutputParser这一行就是一条完整的执行链,左边的输出自动成为右边的输入。每个组件只需要关心自己的输入和输出,不需要了解其他组件的实现细节,这使得整个系统非常灵活、易于扩展。
执行链
执行链(Chain)是 LangChain 里最基础的执行单元。最简单的链就是"给模型一个提示,拿回一个结果",复杂的链可以包含条件分支、并行执行、多模型协作等。
安装依赖:
bash
pip install langchain langchain-openai定义大模型
python
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="deepseek-chat") 在运行之前需要保证 api_key 正确且可用,在 ChatOpenAI 里提供了 api_key 和 base_url 参数来设置 API 密钥和请求地址,但尽量把它设置到环境变量中,不要硬编码暴露在代码里,以 Linux 系统为例:
bash
export OPENAI_API_KEY=DeepSeek的api-Key
export OPENAI_BASE_URL=https://api.deepseek.com/v1又或者使用独立的 DeepSeek 环境变量名:
bash
export DEEPSEEK_API_KEY=DeepSeek的api-Key
export DEEPSEEK_BASE_URL=https://api.deepseek.com/v1此时定义方式改为从环境变量中手动读取:
python
import os
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)推荐使用环境变量的方式管理密钥,一方面避免密钥泄露到代码仓库,另一方面方便在不同环境(开发、生产)之间切换配置。
调用大模型
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
model = ChatOpenAI(model="deepseek-chat")
# 定义消息列表
messages = [
SystemMessage(content="你是一个翻译官,任务是把用户输入的信息翻译成英语"),
HumanMessage(content="阴天你看不见我,天晴你会想起我!"),
]
# 调用并输出完整响应对象
result = model.invoke(messages)
print(result)
# 只获取文本内容
print(result.content) SystemMessage:系统提示词,用来给模型设定角色、行为规范,在整个对话中优先级最高。HumanMessage:用户提示词,模拟用户说的话,是模型主要响应的内容。
model.invoke(messages) 返回的是一个 AIMessage 对象,包含 content(文本回复)、response_metadata(token 用量、模型名等元信息)等字段。如果只需要文本,直接取 .content 即可。
输出:
You can't see me on cloudy days, but you'll think of me when the sky clears!链式调用
StrOutputParser 是 LangChain 内置的字符串输出解析器,作用是从 AIMessage 对象中提取出 .content 字符串,省去手动访问属性的步骤。在链中加上它,最终 invoke 拿到的就直接是字符串,而不是完整的消息对象。
python
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
# 用 | 把模型和解析器串成一条链
chain = model | parser
result = chain.invoke(messages)
print(result) # 直接输出字符串,无需 .content三、定义模型
方法1:ChatOpenAI
ChatOpenAI 是 LangChain 对 OpenAI 兼容接口(包括 DeepSeek、通义千问等第三方兼容接口)的封装类,上面已经介绍了基本用法,这里来看看其他常用参数。
model:决定使用哪个模型,如"deepseek-chat"、"gpt-4o"等。temperature:模型温度,控制输出的随机程度(发散程度),范围0.0 ~ 2.0:0:稳定,确定性强,适合需要精确答案的任务(如代码生成、数学计算)。0.3:偏稳定,输出较为保守。0.7:默认值,兼顾稳定与多样。1.0:稍有发散,适合创意写作。2.0:极度随机,基本失控,实际场景很少使用。
max_tokens:限制单次输出的 token 数,防止回答过长消耗过多费用。timeout:请求超时秒数,超时后直接报错放弃,避免程序卡死。max_retries:请求失败后的重试次数,网络不稳定时有用。
temperature 对比测试:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
model1 = ChatOpenAI(model="deepseek-chat", temperature=0.0)
model2 = ChatOpenAI(model="deepseek-chat", temperature=1.0)
model3 = ChatOpenAI(model="deepseek-chat", temperature=2.0)
messages = [
SystemMessage(content="给你一段话,补全故事"),
HumanMessage(content="一只小狗在__, 用15个字补全这个故事"),
]
print(model1.invoke(messages).content)
print(model2.invoke(messages).content)
print(model3.invoke(messages).content)三次运行结果对比:
一只小狗在雨中奔跑,寻找回家的路。
一只小狗在雨夜里蜷缩着哼唱。
冰冷的公园长椅下发着抖,死一般的寂静......
一只小狗在雨中奔跑,寻找回家的路。
一只小狗在雨中等主人,终于等到。
一只小狗在沙滩救了她掉下来的蟹布
一只小狗在雨中奔跑,寻找回家的路。
一只小狗在雪地里捡到一根骨头。
寻找离家几天的我,爪子磨破了也在所不惜。 可以看到,随着温度升高,模型的输出越来越"天马行空"。生产环境中 temperature=2.0 基本不可用,通常根据任务类型在 0.0 ~ 1.0 之间调整。
方法2:init_chat_model
init_chat_model 是 LangChain 提供的统一初始化函数,是对 ChatOpenAI、ChatAnthropic 等各家封装类的再次封装。它的优势在于:用同一套代码初始化任意支持的聊天模型提供商,切换模型时无需修改业务逻辑。
快速定义并调用:
python
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat")
print(model.invoke("你是谁?").content) init_chat_model 会根据 model 参数自动推断使用哪家的封装类。如果需要指定提供商,可以传入 model_provider 参数,如 model_provider="openai"、model_provider="anthropic" 等。
可配置模型
在某些场景下,我们希望在运行时动态调整模型参数(如在不同请求中使用不同的 temperature 或 max_tokens),而不是每次都重新实例化一个模型。init_chat_model 支持通过以下两个参数实现这一点:
configurable_fields:声明哪些参数允许在后期动态修改,传入参数名的元组。config_prefix:给这些动态参数添加前缀,在多个模型共存时避免命名冲突。
python
from langchain.chat_models import init_chat_model
model = init_chat_model(
model="deepseek-chat",
max_tokens=500,
temperature=2,
configurable_fields=("max_tokens", "temperature"),
config_prefix="first"
)
# 在 invoke 时通过 config 动态覆盖参数
result = model.invoke(
input="你是谁?",
config={
"configurable": {
"first_max_tokens": 10, # 覆盖 max_tokens
"first_temperature": 0.7 # 覆盖 temperature
}
}
)
print(result.content) config 中的键名格式为 {prefix}_{field_name},这里前缀是 first,所以键名是 first_max_tokens 和 first_temperature。运行时传入的值会覆盖初始化时的默认值。
输出结果:
你好!我是DeepSeek,由深度求 由于 max_tokens 被动态设置为 10,输出在第 10 个 token 处被截断,这正是可配置参数的预期效果。
四、工具
有时候大模型的能力还不足以完成我们的任务,比如它无法实时联网查天气、不能精确做数学计算、也没办法访问你的数据库。这时候可以给它绑定工具(Tool),让它根据需要调用我们预先写好的函数来补充能力。
需要注意的是:工具的选择 由大模型负责(它根据语义判断该不该调、调哪个),工具的执行由程序负责。大模型本身不直接运行代码,它只是返回"我要调用 XX 工具,参数是 YY"这样的结构化信息,程序员再根据这个信息去真正执行函数。
4.1 工具定义
工具是需要让大模型去匹配调用的,所以定义一个工具必须包含以下三点信息:
- 哪些是工具:通过装饰器或特定类声明,让 LangChain 知道这是可调用的工具。
- 这个工具是用来做什么的:通过文档字符串(docstring)描述工具功能,模型依据此来决定是否调用。
- 这个工具怎么使用:通过参数描述说明每个参数的含义和类型,模型依据此来组装调用参数。
方法一:@tool 装饰器
@tool 是最简洁的工具定义方式,直接在普通函数上加装饰器即可。
示例1:Google 风格文档字符串
python
from langchain_core.tools import tool
@tool
def add1(a: int, b: int) -> int:
"""两数相加
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b@tool:将函数声明为可被大模型调用的工具。- 函数第一行的简短描述(
两数相加):告诉模型这个工具的用途。 Args:块:描述每个参数的含义,模型依此理解如何传参。
文档字符串的格式不强制要求是 Google 风格,但推荐使用------它可读性强,且 LangChain 能正确解析参数描述生成 tool schema。如果缺少文档字符串,工具 schema 校验会失败,模型将无法正确调用。
示例2:使用 Pydantic 模型定义参数 schema
python
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class AddInput(BaseModel):
"""两数相加"""
a: int = Field(..., description="第一个整数")
b: int = Field(..., description="第二个整数")
@tool(args_schema=AddInput)
def add2(a: int, b: int) -> int:
return a + b 通过 args_schema 传入 Pydantic 模型,可以对参数进行更严格的类型校验和更丰富的描述。Field(..., description=...) 中的 ... 表示该参数为必填项。这种方式在参数复杂、需要校验时更为推荐。
示例3:使用 Annotated 内联描述参数
python
from typing import Annotated
from langchain_core.tools import tool
@tool
def add3(
a: Annotated[int, "第一个整数"],
b: Annotated[int, "第二个整数"],
) -> int:
"""两数相加"""
return a + b Annotated[类型, 描述] 是一种更紧凑的写法,把参数描述直接内联到类型注解里,无需单独写 Args: 块,适合参数较少时使用。
方法二:StructuredTool
StructuredTool 适合需要更灵活控制工具元信息(如工具名、描述)的场景,或者需要给已有函数包装成工具而不想修改原函数的情况。
示例1:直接从函数创建
python
from langchain_core.tools import StructuredTool
def add1(a: int, b: int) -> int:
"""两数相加"""
return a + b
add_tool = StructuredTool.from_function(func=add1) from_function 会自动从函数签名和文档字符串中提取名称、描述、参数信息,效果与 @tool 装饰器基本一致。
示例2:自定义工具名和描述
python
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
class AddInput(BaseModel):
a: int = Field(..., description="第一个整数")
b: int = Field(..., description="第二个整数")
def add2(a: int, b: int) -> int:
return a + b
add2_tool = StructuredTool.from_function(
func=add2,
name="Add", # 重新给工具起名
description="两数相加", # 工具功能描述
args_schema=AddInput, # 工具参数 schema
)当你需要给工具起一个更语义化的名字、或者函数本身没有文档字符串时,可以通过这几个参数手动指定。
输出测试:
python
print(add_tool.invoke({"a": 2, "b": 5})) # 7
print(add_tool.name) # add1
print(add_tool.description) # 两数相加
print(add_tool.args) # {'a': {'type': 'integer', ...}, 'b': {...}}结果:
5
add1
两数相加
Args:
a: 第一个整数
b: 第二个整数
{'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}返回调用结果与调用过程(content_and_artifact)
有时我们希望工具在返回结果的同时,也返回中间数据(比如用于 debug 的调用过程、用于论文引用的数据来源)。LangChain 通过 response_format="content_and_artifact" 支持这一模式:函数返回一个二元组 (content, artifact),其中 content 是喂给大模型的文本结果,artifact 是给程序员或下游组件分析用的原始数据。
python
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
class Add3Input(BaseModel):
a: int = Field(..., description="第一个整数")
b: int = Field(..., description="第二个整数")
def add3(a: int, b: int):
nums = [a, b]
content = f"{nums}相加的结果是{a + b}" # 给模型看的文字结果
artifact = nums # 给程序/开发者的原始数据
return content, artifact
add3_tool = StructuredTool.from_function(
func=add3,
name="Add3",
description="两数相加",
args_schema=Add3Input,
response_format="content_and_artifact" # 声明返回两部分
) 使用 response_format="content_and_artifact" 时,需要模拟大模型的调用姿势(传入 type="tool_call" 的字典),这样 LangChain 才能正确分离 content 和 artifact:
python
result = add3_tool.invoke({
"name": "add3",
"args": {"a": 3, "b": 4},
"type": "tool_call", # 声明这是一次工具调用
"id": "call_001", # 并发场景下用于匹配调用与结果
})
print(result.content) # "[3, 4]相加的结果是7" ← 给模型看的
print(result.artifact) # [3, 4] ← 给程序看的 id 字段在并发调用多个工具时非常重要,用于让模型将工具调用请求和返回结果一一对应起来,避免混淆。
4.2 绑定工具
定义好工具之后,需要把工具绑定 到模型上,让模型知道有哪些工具可以使用。通过 model.bind_tools() 实现:
python
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from typing import Annotated
@tool
def add(a: int, b: int) -> int:
"""两数相加
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b
@tool
def multiply(
a: Annotated[int, "第一个整数"],
b: Annotated[int, "第二个整数"],
) -> int:
"""两数相乘"""
return a * b
model = ChatOpenAI(model="deepseek-chat")
# 将工具列表绑定到模型
tools = [add, multiply]
model_with_tools = model.bind_tools(tools=tools) bind_tools 会把工具的 schema(名称、描述、参数结构)以特定格式注入到每次请求的 system 信息中,让模型在生成回复时"知道"自己有这些工具可用。
4.3 调用工具
第一步:让模型选择工具
python
from langchain_core.messages import HumanMessage
ai_msg = model_with_tools.invoke("45乘2等于多少")
print(ai_msg.tool_calls)输出:
python
[{'name': 'multiply', 'args': {'a': 45, 'b': 2},
'id': 'call_00_kYzR2NlD4MN9uVTjSx9NAd4O', 'type': 'tool_call'}] 注意:这一步模型只是根据语义匹配出了"应该调用 multiply,参数是 a=45, b=2",并没有真正执行函数 。ai_msg.tool_calls 是一个列表,包含了模型认为需要调用的所有工具及其参数。
默认情况下,模型会根据问题相关性自行决定是否调用工具。如果需要强制模型必须调用工具 ,可以设置 tool_choice="any"(从绑定的工具中任选其一调用)或 tool_choice="工具名" (强制调用指定工具):
python
model_with_tools = model.bind_tools(tools=tools, tool_choice="any")第二步:执行工具
python
result = multiply.invoke(ai_msg.tool_calls[0])
print(result.content) # 90 把 tool_calls[0](一个包含 name、args、id 的字典)传给对应工具的 .invoke(),工具会执行函数并返回 ToolMessage。
完整多工具调用流程
实际场景中,用户可能在一句话里触发多个工具调用。我们需要把所有工具的调用结果收集起来,连同原始消息一起再次喂给模型,让模型把结果整合成自然语言返回给用户。消息组织规则如下:
HumanMessage:用户的原始提问AIMessage:模型返回的工具调用信息(即ai_msg)ToolMessage:每个工具的执行结果
python
from langchain_core.messages import HumanMessage
messages = [
HumanMessage("50加4等于多少?7乘11等于多少?")
]
# Step 1: 让模型决定调用哪些工具
ai_msg = model_with_tools.invoke(messages)
messages.append(ai_msg) # 把模型的工具调用信息加入消息历史
# Step 2: 逐一执行工具,将结果加入消息历史
tool_map = {"add": add, "multiply": multiply}
for tool_call in ai_msg.tool_calls:
selected_tool = tool_map[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call) # 执行工具
messages.append(tool_msg) # 将工具结果加入消息列表
# Step 3: 把完整消息历史再次喂给模型,生成自然语言回复
print(model.invoke(messages).content) 整个流程的数据流是:用户提问 → 模型选工具 → 程序执行工具 → 结果喂回模型 → 模型组织语言回答用户。这种设计把"推理"(模型做)和"执行"(程序做)清晰地分离开来,既保留了模型的语义理解能力,又保证了工具执行的安全性和可控性。
4.4 工具搜索
并非所有工具都需要自己编写,LangChain 生态提供了大量现成的第三方工具集成。其中 Tavily 是一个专为 AI 场景优化的搜索引擎,支持返回结构化搜索结果,非常适合作为大模型的联网搜索工具。
使用前需要先注册账号并获取 API Key,然后设置到环境变量中:
bash
export TAVILY_API_KEY=你的TavilyApiKey安装依赖:
bash
pip install langchain-tavily定义并绑定工具:
python
import os
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langchain_core.messages import HumanMessage
model = ChatOpenAI(model="deepseek-chat")
# 定义搜索工具,max_results 限制返回的最大搜索结果数
tool = TavilySearch(max_results=4)
# 将搜索工具绑定到模型
model_with_tools = model.bind_tools([tool])完整调用流程:
python
messages = [HumanMessage("2024年诺贝尔物理学奖得主是谁?")]
# Step 1: 模型决定是否调用搜索工具
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
# Step 2: 执行搜索工具,获取真实搜索结果
for tool_call in ai_message.tool_calls:
tool_message = tool.invoke(tool_call)
messages.append(tool_message)
# Step 3: 将搜索结果喂给模型,生成最终回答
print(model.invoke(messages).content)Tavily 本质上是一个搜索引擎接口,不局限于特定类型的查询,可以搜索新闻、百科、技术文档等任何公开网页内容。模型会根据搜索结果中的信息来组织自然语言回答,而不是凭训练数据中的知识作答,因此能有效解决大模型知识过时的问题。
max_results 参数控制搜索返回的结果条数,数量越多,模型参考的信息越丰富,但同时也会消耗更多 token。建议根据问题复杂度在 2~5 之间调整。
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!🎉