目录
[1 网络中的五元组](#1 网络中的五元组)
[2 协议分层](#2 协议分层)
[TCP / IP五层(或四层)模型](#TCP / IP五层(或四层)模型)
[3 网络编程套接字](#3 网络编程套接字)
[4 TCP/IP协议](#4 TCP/IP协议)
[TCP 可靠传输(特别重要)](#TCP 可靠传输(特别重要))
[1 确认应答(可靠性机制)](#1 确认应答(可靠性机制))
[2 超时重传(可靠性机制)](#2 超时重传(可靠性机制))
[3 连接管理(可靠性机制)](#3 连接管理(可靠性机制))
[4 滑动窗口(效率机制)](#4 滑动窗口(效率机制))
[5 流量控制(效率机制)](#5 流量控制(效率机制))
[6 拥塞控制(可靠机制)](#6 拥塞控制(可靠机制))
[7 延迟应答(效率机制)](#7 延迟应答(效率机制))
[8 捎带应答](#8 捎带应答)
[9 面向字节流(粘包问题)](#9 面向字节流(粘包问题))
[10 异常情况](#10 异常情况)
[1 HTTP](#1 HTTP)
[2 HTTPS](#2 HTTPS)
[一、 HTTPS 的本质](#一、 HTTPS 的本质)
[二、 为什么要引入 HTTPS?(背景与威胁)](#二、 为什么要引入 HTTPS?(背景与威胁))
[三、 HTTPS 的"三把利刃":加密机制](#三、 HTTPS 的“三把利刃”:加密机制)
[四、 核心工作流程:HTTPS 握手 (Handshake)](#四、 核心工作流程:HTTPS 握手 (Handshake))
[五、 数据完整性:摘要算法 (Digest)](#五、 数据完整性:摘要算法 (Digest))
[💡 重点总结:三组密钥的配合](#💡 重点总结:三组密钥的配合)
1 网络中的五元组
-
源IP地址 --->发件人地址
-
源端口号 --->发件人电话
-
目的地址 --->收件人地址
-
目的端口号 ---> 收件人电话
-
协议 --->约定:那个快递公司,买什么东西,服务.......
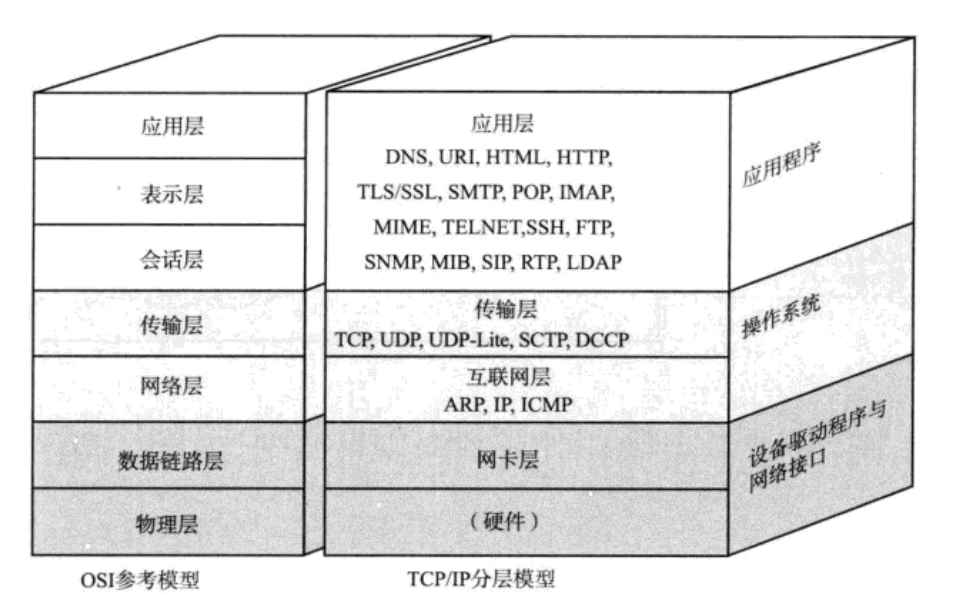
2 协议分层
OSI七层模型
物链网输会表用
TCP / IP五层(或四层)模型
四层模型不包括物理层
-
应用层(用户自定义的协议):与用户打交道,接收展示用户的数据,只关注物品本身
-
传输层(典型的TCP,UDP):完成端到端的传输的准备,确定收送主机的地址的端口号
-
网络层(IP协议):规划端到端之间的网络路径
-
数据链路层(网络接口层)(以太网协议):完成点到点之间的传输,每个网络设备之间的传输
-
物理层(以太网协议)
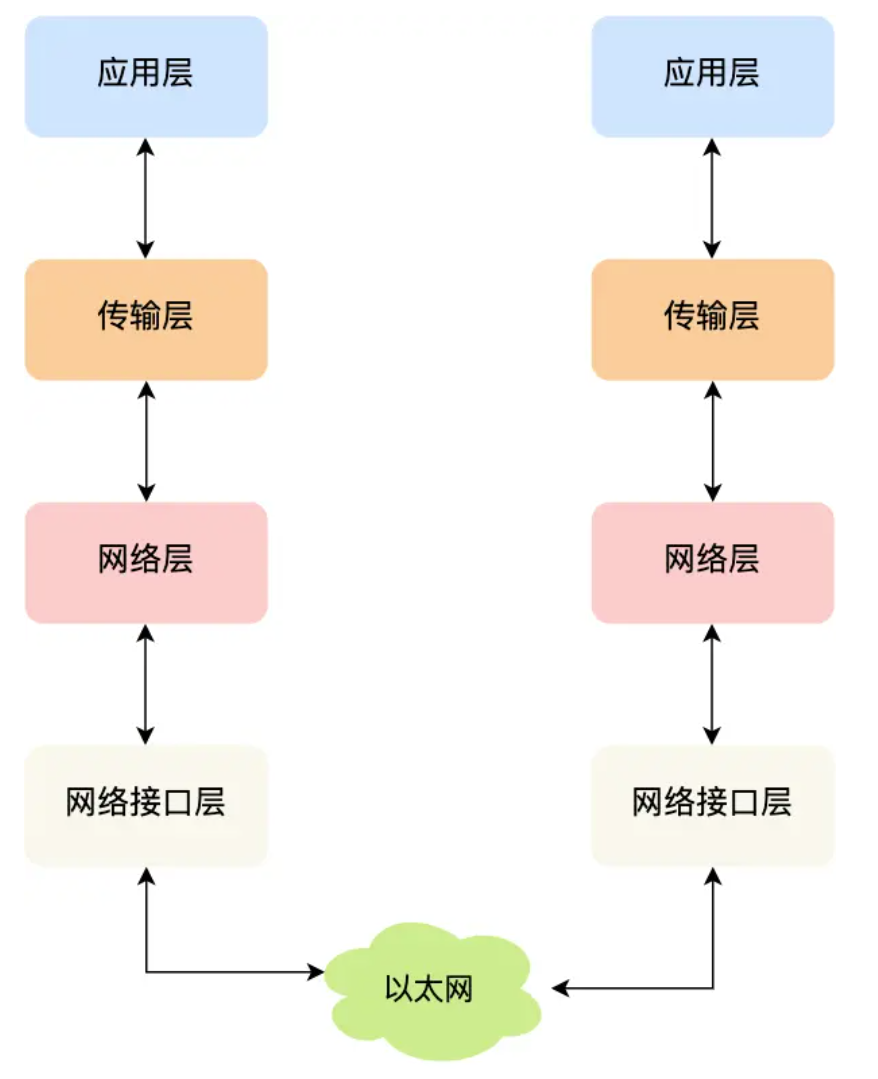
每一层的封装格式
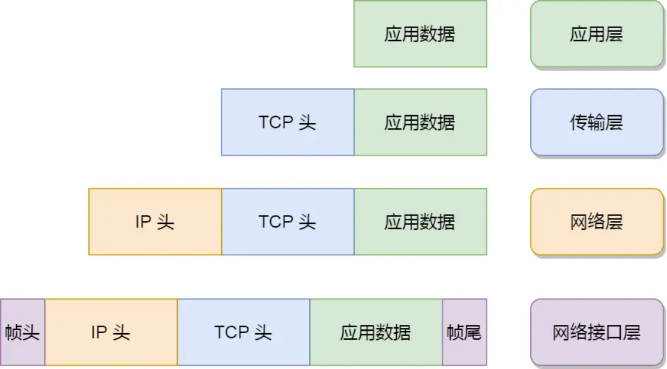
封装和分用
封装是在发送方进行的对数据的处理
分用是在接收方进行的对数据的处理
3 网络编程套接字
Socket套接字
-
流套接字:使用传输层TCP协议:一点一点的发送,和之前的文件流一样
-
数据报套接字:使用传输层UDP协议:把一个报文当做一个整体一次性发送
网络编程

TCP/UDP协议的区别
| TCP | UDP |
|---|---|
| 有连接 | 无连接 |
| 可靠传输 | 不可靠传输 |
| 面型字节流 | 面相数据宝 |
| 有接受缓冲区,也有发送缓冲区 | 有接受缓冲区,无发送缓冲区 |
| 大小不限 | 大小受限,一次最多传输64K |
| 全双工 | 全双工 |

4 TCP/IP协议
应用层
JSON
-
{}表示对象
-
\[\]表示数组
-
字符串用""包裹
-
对象的属性用字符串表示(双引号包裹)
-
属性与属性之间用逗号隔开、
-
最后一个元素没有逗号

进程的两个问题
一个进程可以绑定多个端口号
一个端口号不能被多个进程绑定
在操作系统层面:一个端口号对应一个进程,通过端口号找到对应的进程
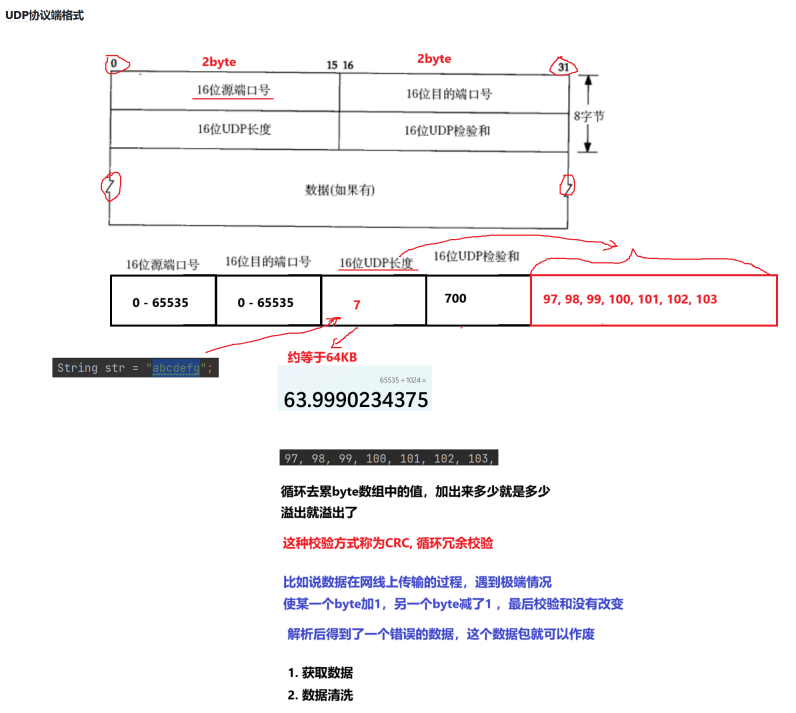
UDP协议
TCP协议
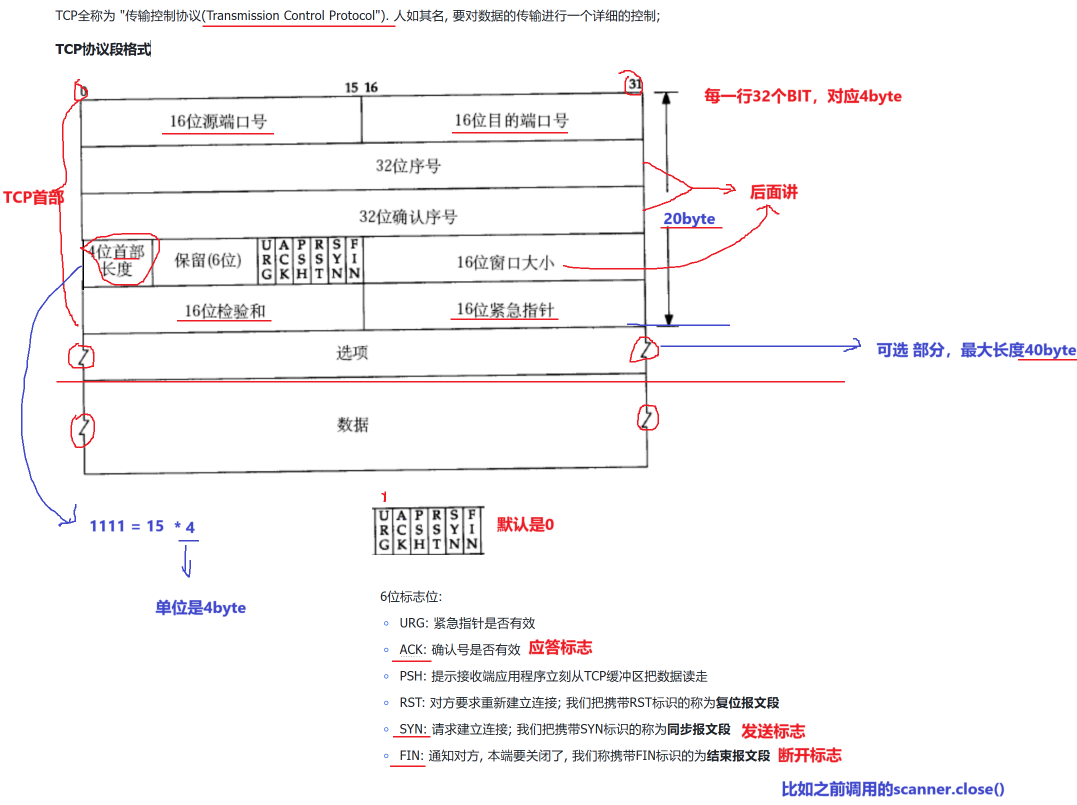
TCP 可靠传输(特别重要)
1 确认应答(可靠性机制)
应答:在传输层接收对方给发送方的一个回复,只是一个标记并没有真实的结果 响应:针对请求计算出来的响应,是真实数据
2 超时重传(可靠性机制)
-
发送超时
-
接收方收到了数据,返回应答的时候超时
3 连接管理(可靠性机制)
作用:在发送方和接收方初次建立连接的时候,确认双方的收发能力
-
初次建立时,三次握手
-
断开连接时,四次挥手
三次握手
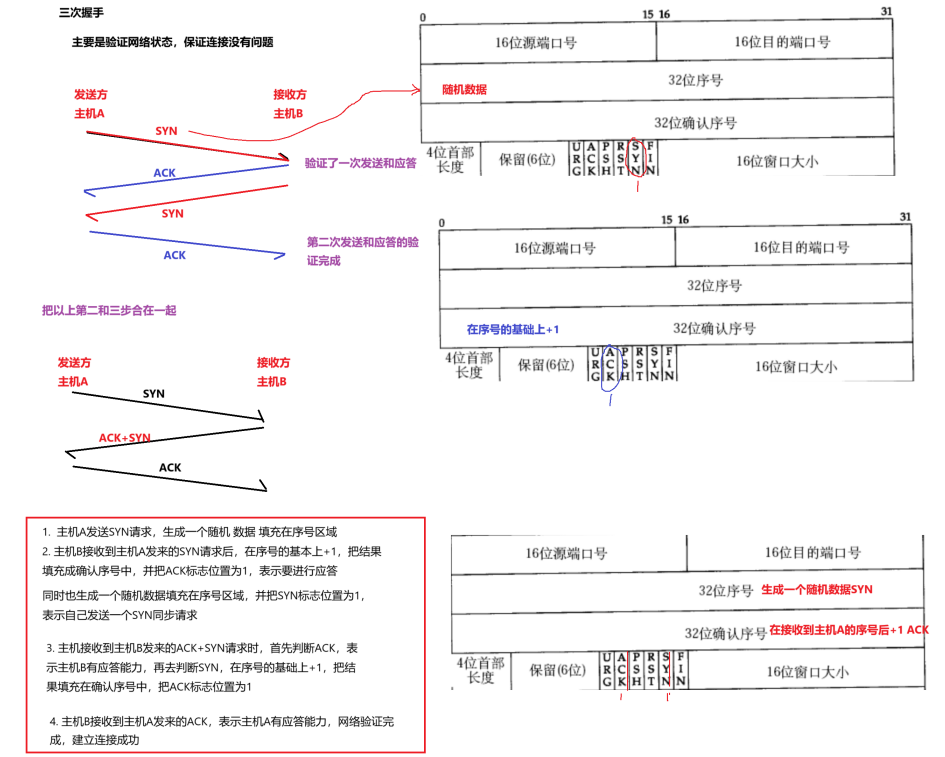
-
主机A发送SYN请求,生成一个随机数据填充在序号区域
-
主机B接收到主机A发来的SYN请求后,在序号的基本上+1,把结果填充成确认序号中,并把ACK标志位置为一,表示要进行应答,同时生成一个随机数据填充在序号区域,并把SYN标志位置为1,表示自己发送一个SYN同步请求
-
主机A接收到主机B发来的ACK+SYN请求时,首先判断ACK,表示主机B有应答能力,再去判断SYN,在序号的基础上+1,把结果填充在 确认序号中,把ACK标志位置为1
-
主机B接收到主机A发来的ACK,表示主机A有应答能力,网络验证完成,建立连接成功
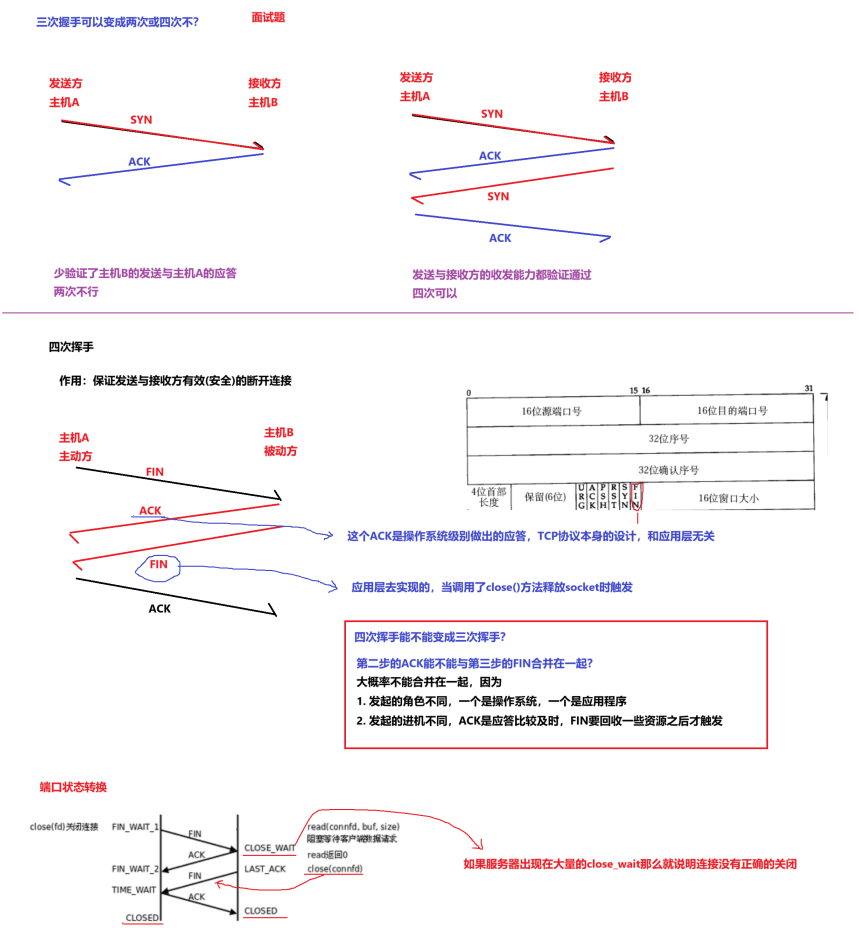
4 滑动窗口(效率机制)
异常情况一:数据包已经抵达了,但是ACK丢了
异常情况二:数据包直接丢了,数据包没有到达主机B
滑动窗口与效率
-
窗口越大网络吞吐量越高
-
窗口越大效率越高
-
窗口越小效率越低
-
如果窗口无限大,就和UDP一样了
5 流量控制(效率机制)
作用:用来控制发送方的窗口大小,通过接收方返回来的ACK进行反制
6 拥塞控制(可靠机制)
作用:通过网络的畅通程序来控制窗口的大小
7 延迟应答(效率机制)
TCP在应答时,并不是每收到一个请求应答一次,而是每隔记得应答一次
8 捎带应答
ACK是系统内核做出的应答(传输层)
发送响应是应用层面的(应用层)
9 面向字节流(粘包问题)
创建一个TCP的Socket,同时在内核中创建一个发送缓冲区(写)和一个接收缓冲区(读)
粘包问题就是:每接收到一个报文就把他放入缓冲区,在读取报文时,不能有效的区分每个数据名称
对于粘包问题解决:
-
为每个消息定义一个分隔符,或者说用一个分隔符来界边一条消息
-
在应用层协议中定义一个区域(字段),用来表示当前消息的长度
10 异常情况
-
程序崩溃
-
正常关机
-
主机掉电或断网

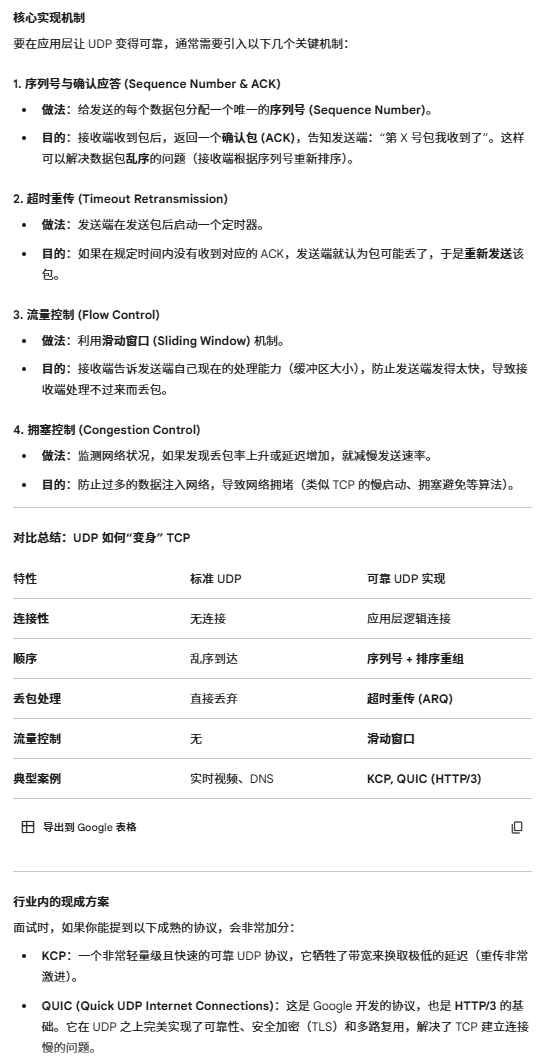
用UDP实现可靠传输(经典面试题)
网络层
IP地址
IP地址是指互联网协议地址,又译为网际协议地址
HTTP/HTTPS
1 HTTP
超文本传输协议,是一种应用广泛的应用层协议
Fiddle 抓包工具
可以捕获本机发送的所有HTTP请求,相当于客户端与服务器端的中间人
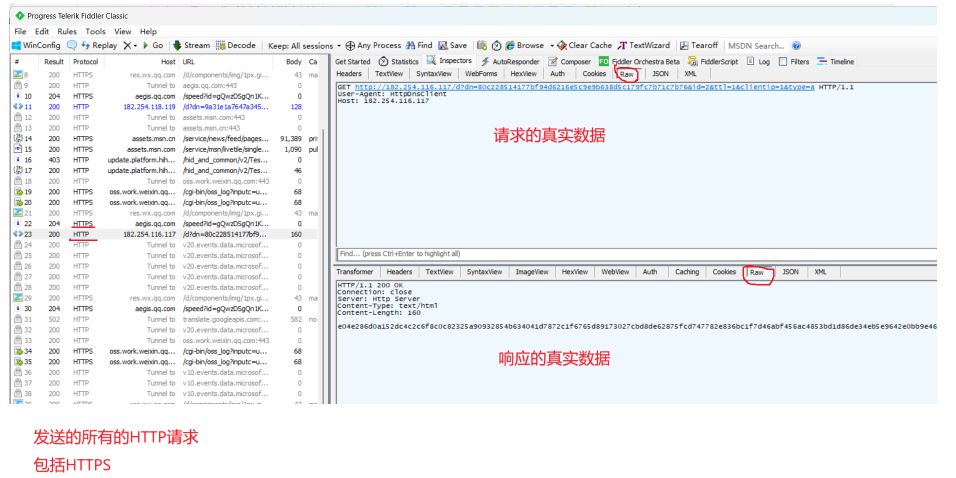
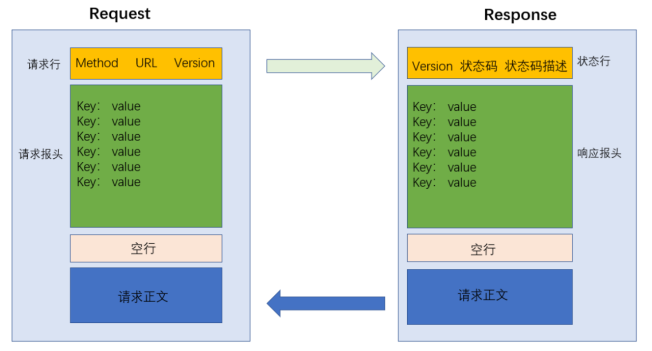
HTTP请求(Request)
URL

方法(method)
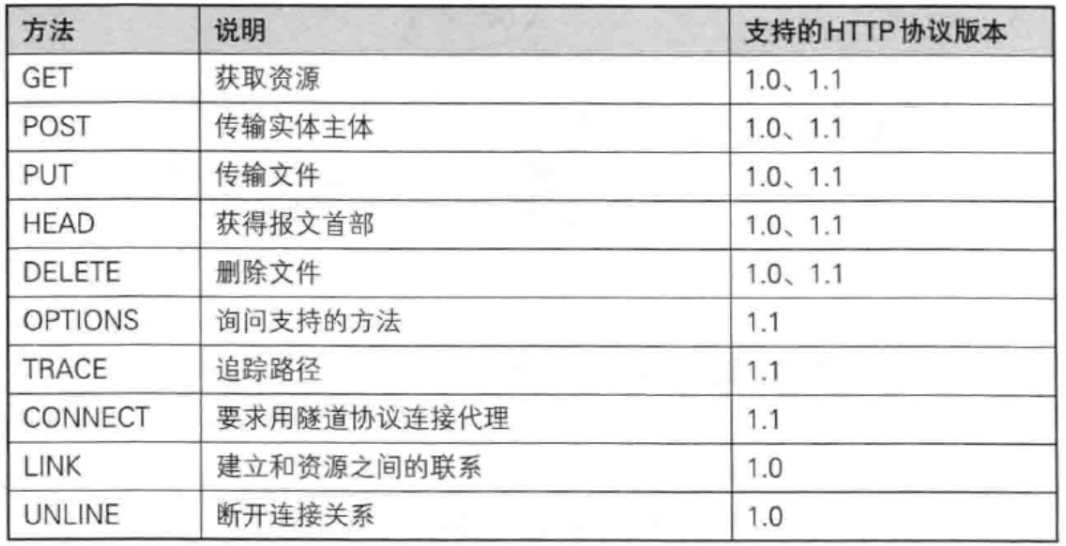
GET 和 POST 是 HTTP 协议中最基础、最常用的两种请求方法。虽然它们在底层都是通过 TCP/IP 协议传输数据,但在设计初衷和具体表现上有着本质的区别。
简单来记其核心区别:GET 通常用于"获取"数据,而 POST 通常用于"提交"数据。
以下是它们的详细对比:
- 核心区别速览表
| 特性 | GET 请求 | POST 请求 |
|---|---|---|
| 主要功能 | 从服务器获取资源(如请求一个网页、查询数据)。 | 向服务器提交数据(如提交表单、上传文件)。 |
| 数据传递位置 | 数据附加在 URL 的末尾(Query String),以 ? 分割,参数间用 & 连接。 |
数据存放在 HTTP 报文的主体(Body) 中。 |
| 数据长度限制 | 受限于浏览器和服务器对 URL 长度的限制(通常在 2KB 到 8KB 左右)。 | 理论上没有限制(实际受限于服务器配置,可传输大量数据)。 |
| 安全性 | 较低。数据直接暴露在 URL 中,会被保存在浏览器历史记录、书签和服务器日志中。 | 较高。数据不在 URL 中显示,不会被保存在浏览器历史记录中。 |
| 幂等性 (Idempotency) | 是幂等的。多次执行相同的 GET 请求,服务器状态不变,得到的结果应该是一样的。 | 非幂等。多次执行相同的 POST 请求,可能会在服务器上创建多个资源(如重复提交订单)。 |
| 缓存机制 | 请求可以被浏览器缓存,也可以被加入书签。 | 请求不会被缓存,不能被加入书签。 |
| 数据类型 | 只允许 ASCII 字符。 | 支持多种数据类型(如文本、二进制、JSON、文件等)。 |
关键差异深度解析
数据的可见性与"安全性"
-
GET 的参数就像写在明信片上,任何人只要看到 URL 就能看到数据(例如:
https://example.com/search?keyword=apple)。因此,绝对不能用 GET 请求来传输密码或敏感信息。 -
POST 的参数放在了信封里(Body 中),普通用户在地址栏看不到。但这并不意味着绝对安全。如果不使用 HTTPS 协议,网络抓包工具依然可以轻易看到 POST 请求体中的明文数据。真正的安全性依赖于 HTTPS 加密,而不是 POST 方法本身。
幂等性与副作用
-
GET 是安全的、幂等的: 这意味着你仅仅是去"看"一眼数据,无论你看一次还是看一万次,服务器上的数据都不会因此改变。这也是为什么浏览器允许你随意刷新 GET 请求的页面。
-
POST 会产生副作用: 比如在购物网站点击"付款"按钮通常是一个 POST 请求。如果你在付款成功后强行刷新页面,浏览器通常会弹出一个警告框("确认重新提交表单?"),因为再次发送 POST 请求可能会导致你被扣费两次。
底层数据包传输差异(技术细节)
在部分浏览器(如早期的 Firefox 等)和底层机制中,发送方式略有不同:
-
GET 通常产生一个 TCP 数据包:浏览器将 HTTP Header 和 Data 一并发送出去,服务器响应 200 OK 并返回数据。
-
POST 有时会产生两个 TCP 数据包:浏览器先发送 HTTP Header,服务器响应 100 Continue,浏览器再发送 Data,最后服务器响应 200 OK。这种机制的作用是先探测服务器是否愿意接收数据,避免在服务器拒绝时浪费带宽上传大量体积的数据包。
- 总结:什么时候用哪个?
-
使用 GET: 当你的操作只是为了查询、读取或过滤信息,且不需要改变服务器状态时。例如:搜索引擎查询、查看商品详情、获取新闻列表。
-
使用 POST: 当你的操作会改变服务器状态 ,或者需要传输敏感、大量的数据时。例如:用户登录注册、发布一条评论、修改个人资料、上传图片文件。

HTTP请求报头(Header)
Header的整体格式是"键值对"结构,每个键值对占一行,键和值之间使用分好分割
Host
表示服务器主机的地址和端口号
Content-Length
表示body中的数据长度
Content-Type
表示请求的body中的数据格式
User-Agent (简称 UA)
表示浏览器/操作系统的属性
Refer
cookie
理解登录过程
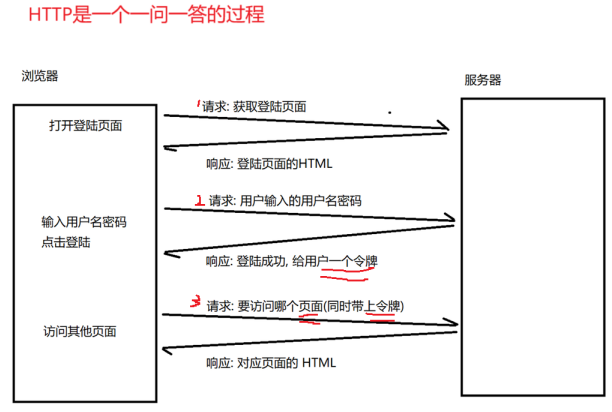
HTTP响应解释
HTTP 状态码(Status Code)是用来表示服务器对请求的处理结果的。它们被分为五大类,每一类都有特定的含义。
以下是常见的 HTTP 状态码及其含义的对照表:
HTTP 状态码分类概览
| 状态码范围 | 类别 | 描述 |
|---|---|---|
| 1xx | 信息性状态码 | 接收的请求正在处理 |
| 2xx | 成功状态码 | 请求正常处理完毕 |
| 3xx | 重定向状态码 | 需要进行附加操作以完成请求 |
| 4xx | 客户端错误状态码 | 服务器无法处理请求(客户端原因) |
| 5xx | 服务器错误状态码 | 服务器处理请求时出错 |
常用状态码详细列表
| 状态码 | 状态描述 | 语义及常见场景 |
|---|---|---|
| 200 | OK | 请求成功。表示从客户端发来的请求在服务器端被正常处理了。 |
| 204 | No Content | 请求成功,但返回的响应报文中不含实体的主体部分(无内容)。 |
| 301 | Moved Permanently | 永久性重定向。资源已被分配了新的 URL,以后应使用资源现在的 URL。 |
| 302 | Found | 临时性重定向。资源临时移动到了新的 URL,希望用户本次能访问新的 URL。 |
| 304 | Not Modified | 未修改。资源未改变,可直接使用浏览器缓存。 |
| 400 | Bad Request | 错误请求。请求报文中存在语法错误,服务器无法理解。 |
| 401 | Unauthorized | 未认证。当前请求需要用户身份认证(常用于登录校验失败)。 |
| 403 | Forbidden | 禁止访问。服务器理解请求,但拒绝执行(如没有访问权限)。 |
| 404 | Not Found | 未找到资源。服务器上无法找到请求的资源,或 URL 拼写错误。 |
| 405 | Method Not Allowed | 方法不允许。使用了服务器不支持的请求方法(如对只支持 GET 的接口发 POST)。 |
| 500 | Internal Server Error | 服务器内部错误。服务器端在执行请求时发生了错误(常为代码异常)。 |
| 502 | Bad Gateway | 网关错误。作为网关或代理的服务器从上游服务器接收到了无效响应。 |
| 504 | Gateway Timeout | 网关超时。服务器作为网关,未能及时从上游服务器接收响应。 |
重点说明
-
200 vs 204:200 会返回数据(如 JSON、HTML),204 仅告知成功而不返回任何内容。
-
401 vs 403:401 是"你是谁?我不知道,请登录",403 是"我知道你是谁,但你没权力干这事"。
-
404 vs 500:404 通常是前端路径写错了或资源被删了;500 则是后端代码写得有问题(比如触发了空指针异常)。
2 HTTPS
一、 HTTPS 的本质
HTTPS (Hypertext Transfer Protocol Secure) 并非独立协议,而是在 HTTP 协议的基础上引入了一个加密层(通常是 SSL 或 TLS)。
-
公式 :
HTTPS = HTTP + 加密 + 认证 + 完整性保护。 -
端口 :默认使用 443 端口(HTTP 默认使用 80 端口)。
二、 为什么要引入 HTTPS?(背景与威胁)
HTTP 采用明文传输,数据在互联网中经过多个节点(如路由器、运营商网关)时极其不安全。
-
运营商劫持:中间节点篡改 HTML 代码。例如:下载一个 A 软件,由于中间人修改了下载链接,最后下成了 B 软件。
-
窃听风险:用户的账号、密码、支付信息对中间人完全透明。
-
冒充风险:黑客可以伪造一个一模一样的银行网站诱导用户登录。
三、 HTTPS 的"三把利刃":加密机制
HTTPS 通过混合加密平衡了安全与性能:
- 对称加密 (Symmetric Encryption)
-
特点 :加密和解密使用同一个密钥。
-
优点:计算速度非常快。
-
缺点:无法安全地将密钥传给对方。如果明文传密钥,加密就失去了意义。
- 非对称加密 (Asymmetric Encryption)
-
特点 :有一对密钥------公钥 (Public Key) 和 私钥 (Private Key)。公钥加密的数据只能用私钥解。
-
优点:解决了密钥传输问题。
-
缺点:计算速度慢,且存在"中间人伪造公钥"的风险。
- 数字证书 (Digital Certificate) & CA 机构
-
解决问题 :为了证明"公钥确实是该网站的",引入了公正的第三方机构 CA (Certificate Authority)。
-
核心内容 :证书包含网站信息、公钥以及 CA 机构的数字签名。
四、 核心工作流程:HTTPS 握手 (Handshake)
这是面试和理解中最关键的部分,其精髓在于用非对称加密来安全地传输对称加密的密钥。
-
客户端请求:浏览器连接服务器并索要证书。
-
服务器响应 :返回包含 公钥 A 的 数字证书。
-
客户端验证:
-
浏览器通过内置的 CA 公钥解密证书签名,确保证书未被篡改。
-
校验域名、有效期等。
-
-
生成会话密钥 :浏览器本地生成一个随机对称密钥 R(用于后续正式通信)。
-
加密密钥 R :浏览器使用服务器证书里的 公钥 A 对 密钥 R 进行加密并发送。
-
服务器解密 :服务器使用只有自己才知道的 私钥 A' 解密,拿到 密钥 R。
-
加密通信开始 :从此以后,双方的所有数据传输都使用 密钥 R 进行对称加密。
五、 数据完整性:摘要算法 (Digest)
HTTPS 还利用了哈希函数(如 MD5 或 SHA系列)来确保内容未被修改。
-
特点:
-
定长:无论原文多长,哈希值长度固定。
-
分散:原文改一个字,哈希值天差地别。
-
不可逆:无法通过哈希值还原原文。
-
-
逻辑:在签名时,先计算证书内容的哈希,再加密。客户端收到后重新计算对比,一致则代表内容完整。
💡 重点总结:三组密钥的配合
| 密钥组 | 角色 | 作用 |
|---|---|---|
| CA 私钥/公钥 | 验证官 | 服务器证书的签名与验证,防止证书被冒充。 |
| 服务器 私钥/公钥 | 快递员 | 在握手阶段加密传输"会话密钥"。 |
| 对称密钥 (R) | 守护者 | 握手完成后,负责海量通信数据的快速加解密。 |