YOLOv3 是单阶段目标检测史上承上启下的里程碑模型,它在 YOLOv2 的基础上,通过引入多尺度检测、残差网络、特征金字塔等经典设计,大幅提升了对小目标、多尺度目标的检测能力,同时保持了 YOLO 系列一贯的实时性优势。本文将结合技术细节,带你全面拆解 YOLOv3 的核心改进与底层逻辑。
一、性能总览:速度与精度的双重突破
先通过 COCO 数据集上的性能对比,直观感受 YOLOv3 的实力:
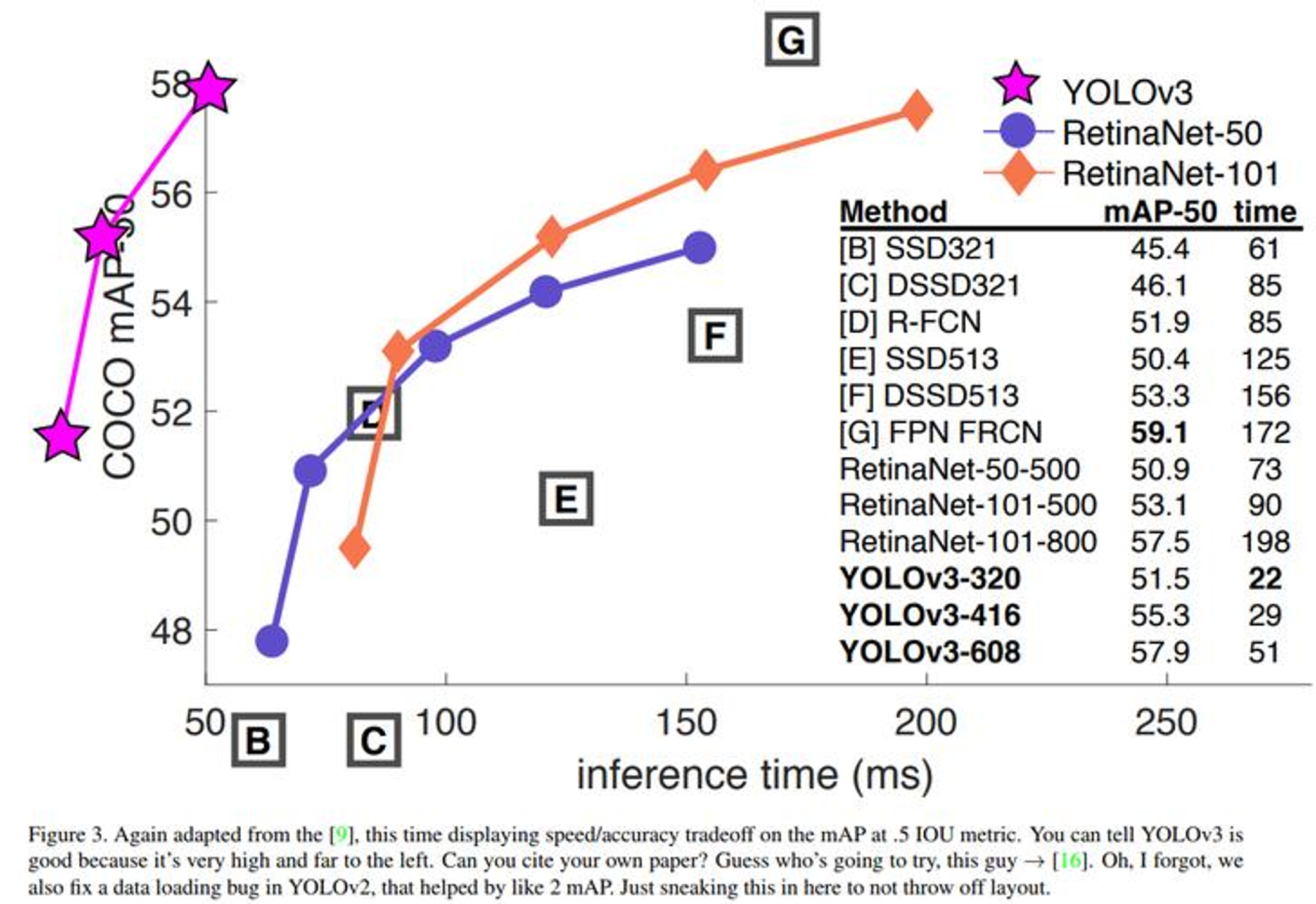
从图中可以清晰看到:
- YOLOv3-320:输入尺寸 320×320,mAP@0.5 达到 51.5%,推理时间仅 22ms,远超同精度的 SSD 系列模型。
- YOLOv3-608:输入尺寸 608×608,mAP@0.5 提升至 57.9%,推理时间 51ms,依然保持实时检测水平。相比 RetinaNet、Faster R-CNN 等两阶段模型,YOLOv3 在精度接近的同时,推理速度快了数倍,完美诠释了 "实时检测" 的优势。
二、核心改进:从 V2 到 V3 的全方位升级
1. 骨干网络:Darknet-53 + 残差连接
YOLOv3 抛弃了 YOLOv2 的 Darknet-19,改用 Darknet-53 作为骨干网络,核心改进是引入了 ResNet 的残差连接思想:
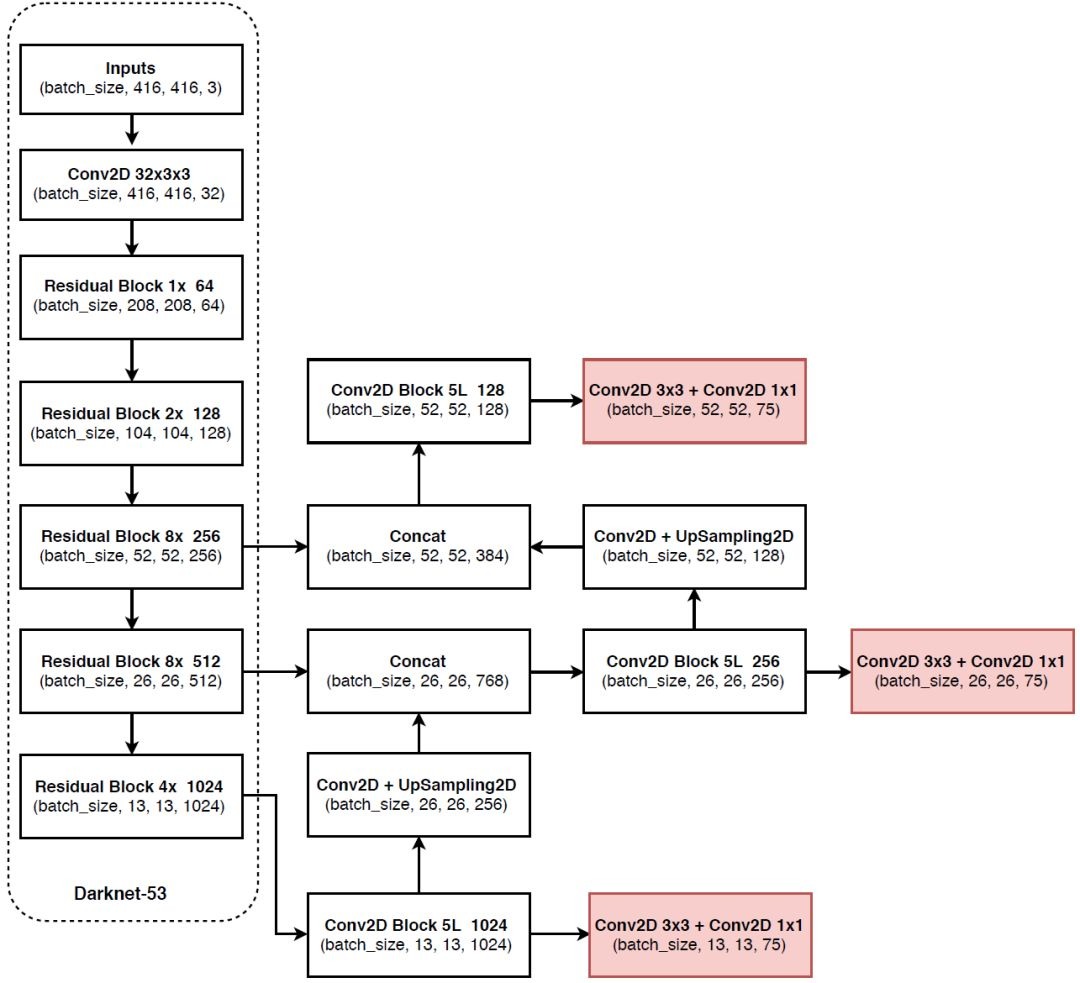
- 结构特点:
- 全卷积无池化 :没有池化层和全连接层,下采样全部通过
stride=2的卷积实现,避免池化带来的信息丢失。 - 残差模块堆叠:包含 53 个卷积层,由 5 组残差块(Residual Block)组成,解决了深层网络训练时的梯度消失 / 爆炸问题,让模型可以学习更复杂的特征。
- 多尺度特征输出:在 13×13、26×26、52×52 三个不同尺度的特征图上输出检测结果,为后续多尺度检测打下基础。
- 全卷积无池化 :没有池化层和全连接层,下采样全部通过
2. 多尺度检测:专为小目标优化的检测头
YOLOv2 仅在 13×13 的特征图上进行预测,对小目标的检测能力较弱。YOLOv3 借鉴了特征金字塔(FPN)的思想,设计了 3 个不同尺度的检测头:
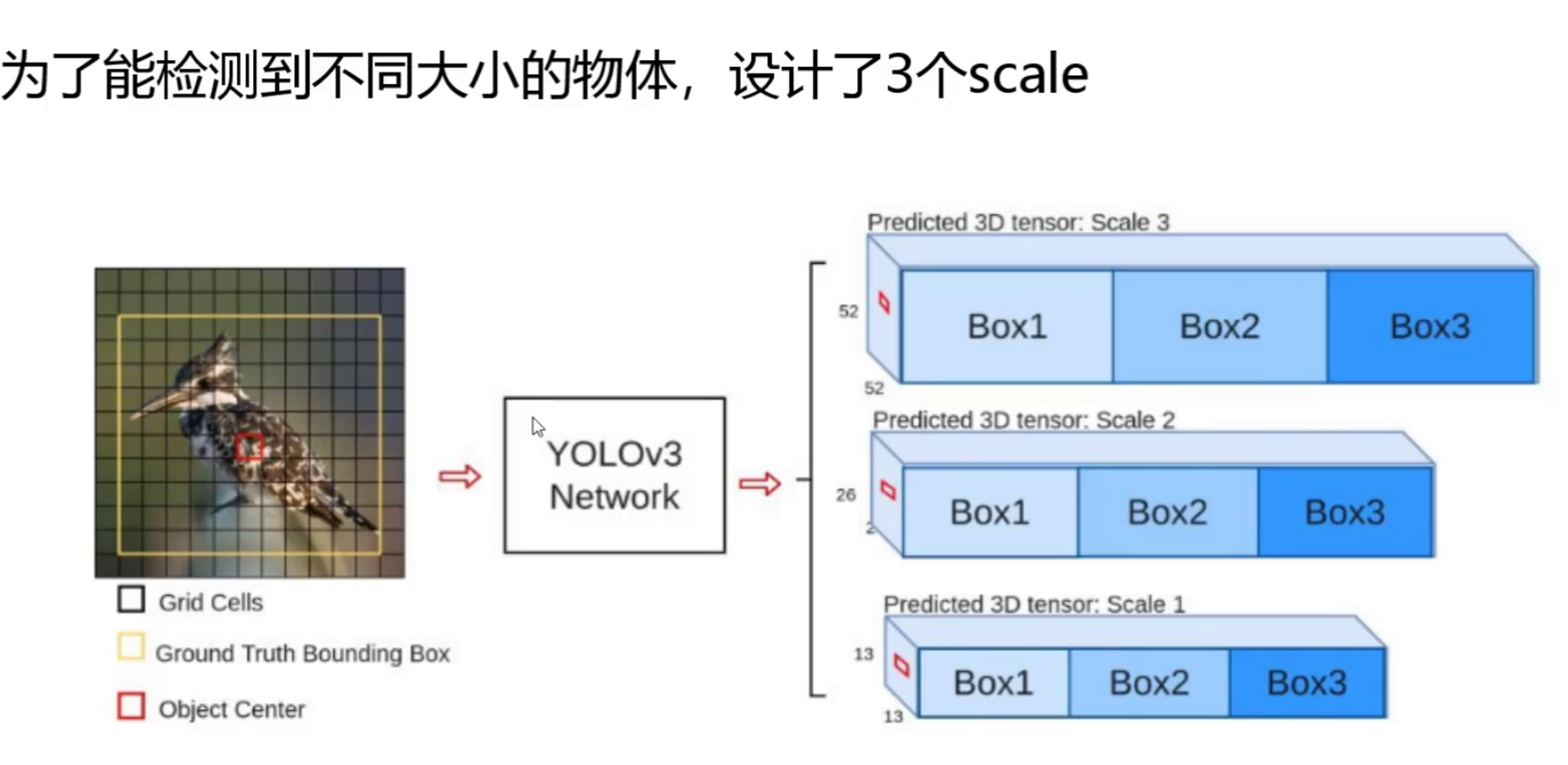
- 原理:
- 大尺度特征图(52×52):感受野最小,细节信息最丰富,用于检测小目标。
- 中等尺度特征图(26×26):感受野中等,用于检测中等大小的目标。
- 小尺度特征图(13×13):感受野最大,语义信息最丰富,用于检测大目标。
- 实现方式:通过上采样(Upsampling)和跨层连接(Concat),将深层语义信息与浅层细节信息融合,让每个尺度的特征图都同时具备细节与语义信息。
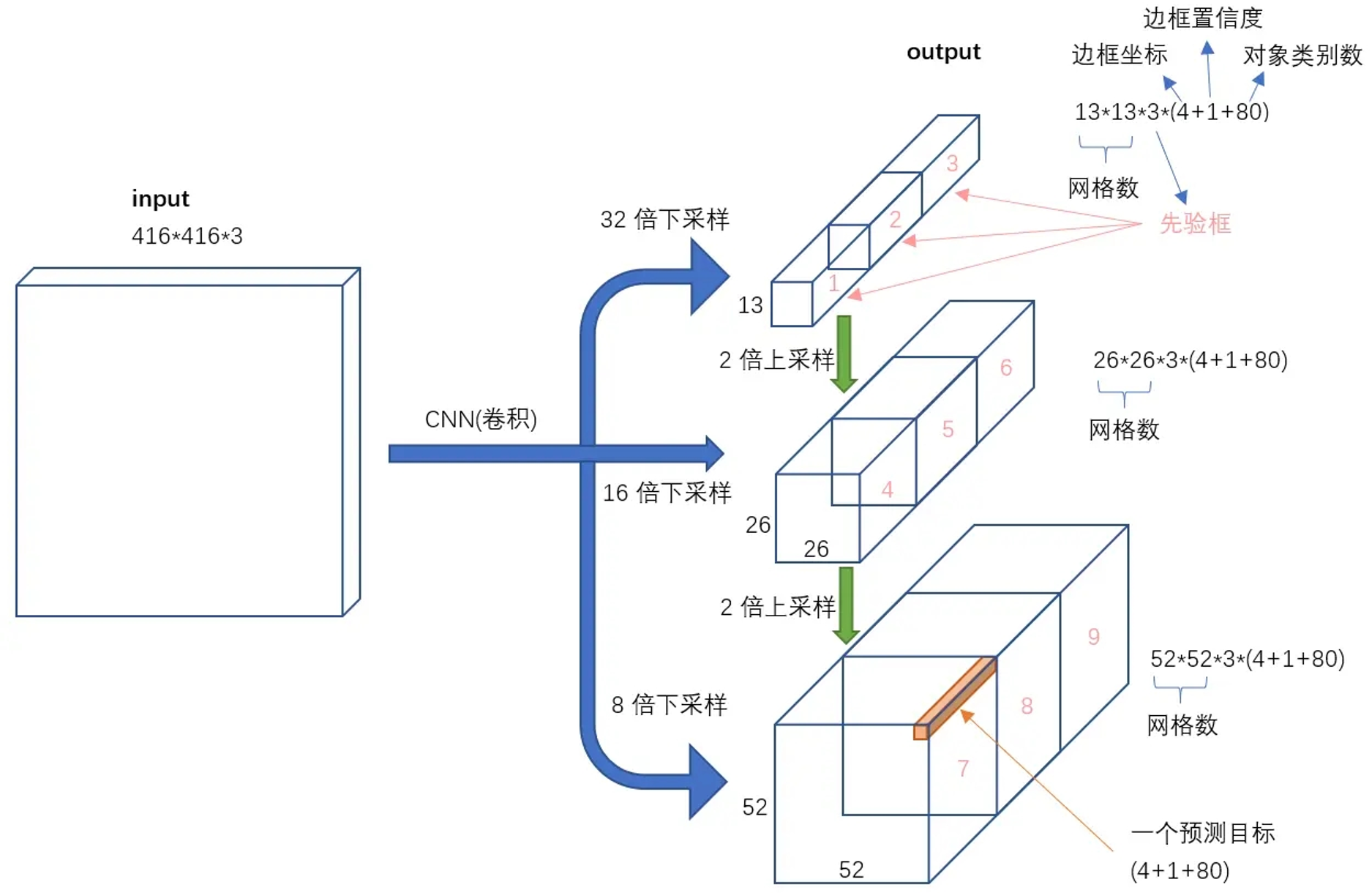
这种设计相比传统的图像金字塔,无需多次输入图像,只需要一次前向传播即可得到多尺度检测结果,在不影响速度的前提下,大幅提升了小目标检测能力。
3. 先验框升级:9 种尺度适配不同目标
YOLOv2 仅使用 5 个 K-means 聚类生成的先验框,YOLOv3 进一步扩展为 9 个先验框,并按尺度分配到 3 个检测头:
-
分配逻辑(以 COCO 数据集为例): 表格
特征图尺寸 感受野 先验框尺寸(宽 × 高) 适配目标 13×13 最大 (116×90), (156×198), (373×326) 大目标 26×26 中等 (30×61), (62×45), (59×119) 中等目标 52×52 最小 (10×13), (16×30), (33×23) 小目标
每个网格单元会预测 3 个先验框,输出维度为 3 × (4 + 1 + 80),其中:
- 4:边界框的坐标偏移量
- 1:目标置信度(是否包含目标)
- 80:COCO 数据集的类别数
4. 分类器改进:Softmax 替换为 Logistic 分类器
YOLOv3 用多个独立的 Logistic 分类器 替代了传统的 Softmax 分类器,解决了多标签分类的问题:
- 核心差异:
- Softmax:强制所有类别的概率和为 1,每个样本只能属于一个类别,无法处理 "一个物体同时属于多个类别" 的场景(比如一个物体既是 "人" 也是 "行人")。
- Logistic 分类器:每个类别独立预测,用 Sigmoid 函数将输出映射到 (0,1) 区间,每个类别的概率相互独立,支持多标签分类。
这一改进让 YOLOv3 能更好地适配复杂场景,比如 COCO 数据集中的多类别标注问题。
三、YOLOv3 与 V2 的核心差异对比
表格
| 维度 | YOLOv2 | YOLOv3 | 核心优势 |
|---|---|---|---|
| 骨干网络 | Darknet-19 | Darknet-53(含残差连接) | 更深的网络,更强的特征提取能力,训练更稳定 |
| 检测尺度 | 单尺度(13×13) | 三尺度(13×13/26×26/52×52) | 小目标检测能力大幅提升 |
| 先验框 | 5 个 | 9 个(按尺度分配) | 对不同大小目标的适配性更强 |
| 分类器 | Softmax | Logistic 分类器 | 支持多标签分类,适配复杂场景 |
| 特征融合 | Passthrough 层 | 特征金字塔(FPN)结构 | 高低层特征融合更充分,细节与语义信息兼顾 |
四、拓展知识点:YOLOv3 为何能成为 "经典中的经典"?
- 兼容并蓄的设计思想:YOLOv3 没有追求颠覆性创新,而是把当时目标检测领域的经典技巧(残差网络、特征金字塔、多尺度训练、Anchor 聚类)全部融入到单阶段检测框架中,实现了 "精度、速度、易用性" 的完美平衡。
- 工程友好性极强:模型结构清晰、训练稳定、部署成本低,无需复杂的后处理,在嵌入式设备、边缘端都能轻松实现实时检测,因此被广泛应用于工业检测、自动驾驶、安防监控等场景。
- 极强的扩展性:后续的 YOLOv4、YOLOv5、YOLOv7 等版本,都是在 YOLOv3 的基础上,对骨干网络、特征融合模块、损失函数等进行优化,核心框架依然延续了 YOLOv3 的设计思路。
五、总结
YOLOv3 是单阶段目标检测发展史上的 "集大成者",它没有盲目追求精度,而是在保持 YOLO 系列实时性优势的前提下,通过一系列成熟的技术改进,补齐了 YOLOv2 在小目标检测、多尺度目标适配、多标签分类上的短板,成为了当时工业界最受欢迎的目标检测模型之一。