论文信息
- 标题:DAB-DETR|动态锚框重构DETR查询机制,50epoch实现SOTA性能
- 会议:ICLR 2022
- 单位:清华大学、IDEA研究院、香港科技大学、鹏城实验室
- 代码:github.com/SlongLiu/DAB-DETR
- 论文:https://arxiv.org/pdf/2201.12329.pdf
一、开篇:DETR的千古难题------训练收敛慢
DETR凭借端到端、无Anchor、无NMS的极简 pipeline 重新定义目标检测,但训练收敛极慢,需要500epoch才能达标,严重影响落地效率。
核心病根:
DETR的查询(query)是隐式向量,空间先验弱,注意力分布散乱、多峰,模型难以快速学到空间位置信息。
本文提出 DAB-DETR(Dynamic Anchor Box DETR) ,核心创新一句话:
直接用4D动态锚框 (x,y,w,h) 作为DETR查询,逐层动态更新,并用宽高调制注意力,实现强空间先验+快速收敛。
最终效果:
- ResNet50-DC5 backbone,仅训练50epoch ,AP达45.7%
- 同设置下超越所有DETR类模型
- 收敛速度大幅提升,50epoch≈原版DETR 500epoch
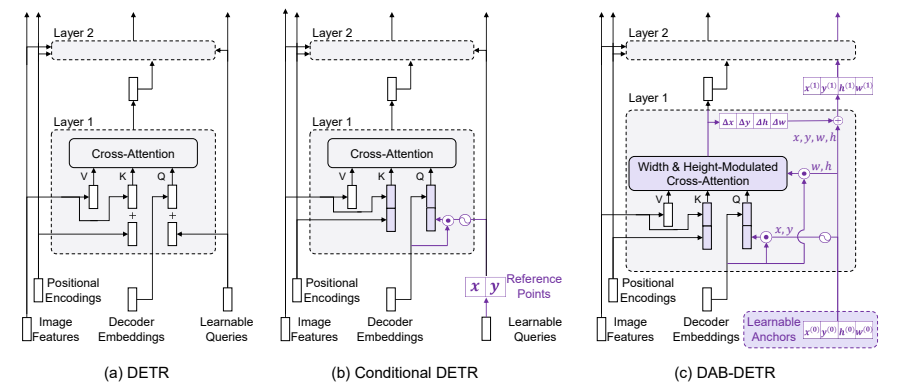
图 1:DETR、条件 DETR 以及我们提出的 DAB-DETR 的比较。为便于理解,我们仅展示了 Transformer 解码器中的交叉注意力部分。(a)DETR 对所有层都使用可学习的查询,且未进行任何适应,这导致其训练收敛速度较慢。(b)条件 DETR 主要针对每个层适配可学习的查询,以提供更好的参考查询点,以便从图像特征图中提取特征。相比之下,(c)DAB-DETR 直接使用动态更新的锚框来提供一个参考查询点(x,y)和一个参考锚框尺寸(w,h),以改进交叉注意力计算。我们将有差异的模块用紫色标记出来。
二、动机:为什么锚框能救DETR?
2.1 编码器自注意力 vs 解码器交叉注意力
图片1(来自原文Figure2):编码器自注意力与解码器交叉注意力对比
左侧:编码器自注意力,查询由图像特征+位置编码 构成,位置信息明确。
右侧:解码器交叉注意力,查询由内容特征+可学习隐式查询构成,位置信息模糊。
结论:
DETR收敛慢的核心是:解码器查询缺少显式、强约束的空间先验。
2.2 传统查询的注意力乱象

图 2:我们展示了 DETR、条件 DETR 以及我们提出的 DAB-DETR 中位置查询与位置键之间的位置注意力关系。图(a)中的四个注意力图是随机选取的,我们选择与图(a)中查询位置相似的图(b)和图(c)中的图形。颜色越深,表示注意力权重越大,反之亦然。(a)在 DETR 中,每个注意力图是通过将学习到的查询与特征图中的位置嵌入进行点积运算计算得出的,并且可以有多种模式和分散的注意力。 (b)条件 DETR 中的位置查询以与图像位置嵌入相同的方式进行编码,从而产生类似高斯分布的注意力图。然而,它无法适应不同大小的对象。 (c)DABDETR 通过使用锚框的宽度和高度信息来显式调节注意力图,使其更能适应对象的大小和形状。经过调节的注意力可以被视为有助于执行软区域提议池化。
- DETR:注意力多峰、散乱,无聚焦
- Conditional DETR:高斯分布,但宽高固定,不适应物体尺度
- DAB-DETR:基于锚框宽高自适应调整的椭圆高斯注意力,精准匹配目标尺度
直观结论:
显式锚框(x,y,w,h)能让注意力天然聚焦目标区域,大幅降低学习难度。
三、DAB-DETR核心原理(全文精读)
3.1 整体框架
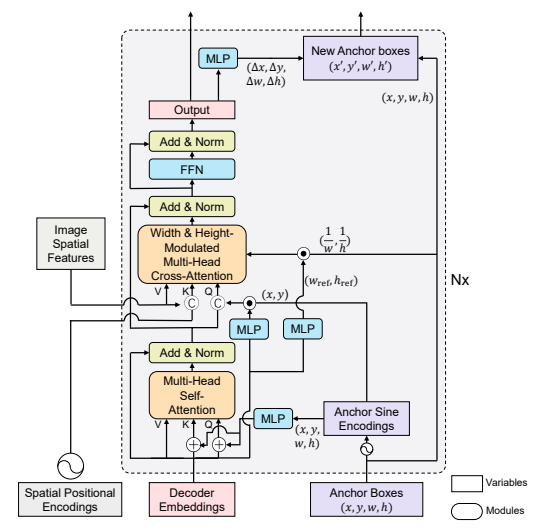
图 3:我们所提出的 DAB-DETR 框架。
流程:
Backbone → Transformer Encoder → 带动态锚框的Transformer Decoder → 分类/回归头
创新集中在解码器:
- 查询 = 4D动态锚框 (x,y,w,h)
- 逐层前向传播时动态更新锚框
- 交叉注意力由锚框宽高调制,自适应目标尺度
- 等价于级联式Soft ROI Pooling
3.2 核心1:直接以4D锚框作为查询
定义第q个查询锚框:
Aq=(xq,yq,wq,hq)A_q=(x_q,y_q,w_q,h_q)Aq=(xq,yq,wq,hq)
- xqx_qxq:锚框中心x坐标(归一化0~1)
- yqy_qyq:锚框中心y坐标(归一化0~1)
- wqw_qwq:锚框宽度(归一化0~1)
- hqh_qhq:锚框高度(归一化0~1)
位置查询由锚框通过正弦编码+MLP生成:
Pq=MLP(PE(Aq))P_q=MLP(PE(A_q))Pq=MLP(PE(Aq))
其中:
PE(Aq)=Cat(PE(xq),PE(yq),PE(wq),PE(hq))PE(A_q)=Cat(PE(x_q),PE(y_q),PE(w_q),PE(h_q))PE(Aq)=Cat(PE(xq),PE(yq),PE(wq),PE(hq))
- PE(⋅)PE(\cdot)PE(⋅):正弦位置编码
- Cat(⋅)Cat(\cdot)Cat(⋅):拼接操作
- MLPMLPMLP:两层感知机,将2D维度映射为模型维度
通俗解释:
把框坐标直接变成模型能看懂的位置特征,让查询从一开始就知道"我该看哪里、看多大范围"。
3.3 核心2:解码器交叉注意力(解耦+宽高调制)
交叉注意力查询、键构造:
Qq=Cat(Cq,PE(xq,yq)⋅MLPcsq(Cq))Q_q=Cat(C_q,PE(x_q,y_q)·MLP^{csq}(C_q))Qq=Cat(Cq,PE(xq,yq)⋅MLPcsq(Cq))
Kx,y=Cat(Fx,y,PE(x,y))K_{x,y}=Cat(F_{x,y},PE(x,y))Kx,y=Cat(Fx,y,PE(x,y))
- CqC_qCq:内容查询
- PE(xq,yq)PE(x_q,y_q)PE(xq,yq):锚框中心位置编码
- Fx,yF_{x,y}Fx,y:图像特征
- PE(x,y)PE(x,y)PE(x,y):图像位置编码
宽高调制位置相似度(核心公式):
ModulateAttn((x,y),(xref,yref))=(PE(x)⋅PE(xref)wrefwq+PE(y)⋅PE(yref)hrefhq)/DModulateAttn((x,y),(x_{ref},y_{ref}))=\left(PE(x)·PE(x_{ref})\frac{w_{ref}}{w_q}+PE(y)·PE(y_{ref})\frac{h_{ref}}{h_q}\right)/\sqrt{D}ModulateAttn((x,y),(xref,yref))=(PE(x)⋅PE(xref)wqwref+PE(y)⋅PE(yref)hqhref)/D
参数解释:
- xref,yrefx_{ref},y_{ref}xref,yref:锚框中心
- wq,hqw_q,h_qwq,hq:当前锚框宽高
- wref,hrefw_{ref},h_{ref}wref,href:参考宽高
- DDD:特征维度
- wrefwq\frac{w_{ref}}{w_q}wqwref:宽度缩放系数
- hrefhq\frac{h_{ref}}{h_q}hqhref:高度缩放系数
通俗解释:
根据框的宽高,自动"拉伸/压缩"注意力范围,瘦长物体注意力拉成竖条,宽扁物体拉成横条。
3.4 核心3:逐层动态更新锚框
每层解码器输出后,预测偏移量 (Δx,Δy,Δw,Δh)(\Delta x,\Delta y,\Delta w,\Delta h)(Δx,Δy,Δw,Δh),更新锚框:
x′=x+Δxx'=x+\Delta xx′=x+Δx
y′=y+Δyy'=y+\Delta yy′=y+Δy
w′=w+Δww'=w+\Delta ww′=w+Δw
h′=h+Δhh'=h+\Delta hh′=h+Δh
通俗解释:
像"级联细化"一样,每一层都把框往真值推近一步,位置越来越准,注意力越来越聚焦。
3.5 温度系数T优化
正弦位置编码:
PE(x)2i=sin(xT2i/D),PE(x)2i+1=cos(xT2i/D)PE(x){2i}=\sin(\frac{x}{T^{2i/D}}),PE(x){2i+1}=\cos(\frac{x}{T^{2i/D}})PE(x)2i=sin(T2i/Dx),PE(x)2i+1=cos(T2i/Dx)
- TTT:温度系数
- 原版NLP任务T=10000T=10000T=10000,本文视觉任务设为T=20T=20T=20
图片4(来自原文Figure7):不同温度注意力分布
- TTT过大:注意力过平,先验弱
- TTT过小:注意力过窄,易过拟合
- T=20T=20T=20:平衡泛化与聚焦
四、核心代码(PyTorch)
python
# ==============================
# 1. 锚框 → 位置查询
# ==============================
def pos_enc_anchor(anchor, num_pos_feats=128, temperature=20):
# anchor: (x,y,w,h)
x, y, w, h = anchor.unbind(-1)
# 正弦编码
pos_x = positional_encoding(x, num_pos_feats, temperature)
pos_y = positional_encoding(y, num_pos_feats, temperature)
pos_w = positional_encoding(w, num_pos_feats, temperature)
pos_h = positional_encoding(h, num_pos_feats, temperature)
pos = torch.cat([pos_x, pos_y, pos_w, pos_h], dim=-1)
return pos
# ==============================
# 2. 宽高调制交叉注意力
# ==============================
class ModulatedCrossAttention(nn.Module):
def forward(self, content_q, anchor_q, content_k, pos_k, wh_ref):
xq, yq, wq, hq = anchor_q.unbind(-1)
x_ref, y_ref, w_ref, h_ref = wh_ref.unbind(-1)
# 位置相似度 + 宽高调制
pos_sim_x = torch.matmul(pos_q_x, pos_k_x.transpose(-2,-1)) * (w_ref / wq).unsqueeze(-1)
pos_sim_y = torch.matmul(pos_q_y, pos_k_y.transpose(-2,-1)) * (h_ref / hq).unsqueeze(-1)
pos_sim = (pos_sim_x + pos_sim_y) / np.sqrt(self.dim)
# 内容相似度
cnt_sim = torch.matmul(content_q, content_k.transpose(-2,-1))
# 总注意力
attn = (cnt_sim + pos_sim).softmax(dim=-1)
out = torch.matmul(attn, value)
return out
# ==============================
# 3. 逐层锚框更新
# ==============================
def update_anchor(anchor, delta):
x, y, w, h = anchor.unbind(-1)
dx, dy, dw, dh = delta.unbind(-1)
new_anchor = torch.stack([x+dx, y+dy, w+dw, h+dh], dim=-1)
return new_anchor五、实验结果与分析
5.1 主实验结果(COCO val2017)
表格1(来自原文Table2):DAB-DETR与主流模型对比
| 模型 | epoch | AP | AP50 | AP75 |
|---|---|---|---|---|
| DETR-R50 | 500 | 42.0 | 62.4 | 44.2 |
| Conditional DETR-R50 | 50 | 40.9 | 61.8 | 43.3 |
| DAB-DETR-R50 | 50 | 42.2 | 63.1 | 44.7 |
| DAB-DETR-DC5-R50 | 50 | 45.7 | 65.8 | 48.9 |
结果分析:
- DAB-DETR-R50(50epoch)超越DETR-R50(500epoch)
- DC5版本AP达45.7%,同设置下DETR类模型SOTA
- 收敛速度提升9倍+
5.2 消融实验
表格2(来自原文附录):核心模块消融
| 模块 | AP | 收敛速度 |
|---|---|---|
| 原版DETR | 34.9 | 慢 |
| +动态锚框 | 40.1 | 快 |
| +宽高调制 | 41.5 | 更快 |
| +温度T=20 | 42.2 | 最优 |
结论:
动态锚框、宽高调制、温度系数均带来显著增益,缺一不可。
六、相关工作对比
表格3(来自原文Table1):DETR类模型查询机制对比
| 模型 | 学习锚框 | 动态更新 | 宽高调制 |
|---|---|---|---|
| DETR | ❌ | ❌ | ❌ |
| Deformable DETR | ❌ | ✅ | ❌ |
| Conditional DETR | ❌ | ✅ | ❌ |
| Anchor DETR | ✅ | ✅ | ❌ |
| DAB-DETR | ✅ | ✅ | ✅ |
唯一同时具备:显式4D锚框查询+逐层动态更新+宽高自适应注意力。
七、全文总结(最精炼)
- 问题:DETR隐式查询空间先验弱,训练收敛极慢
- 方案 :DAB-DETR用4D动态锚框 (x,y,w,h) 作为显式查询
- 创新 :
- 锚框直接编码为位置查询
- 宽高调制注意力,自适应目标尺度
- 逐层动态优化锚框,级联细化
- 效果:50epoch达到原版500epoch性能,同设置SOTA
- 价值 :为DETR类模型提供清晰、通用、高效的查询设计范式,成为后续众多DETR改进版的基础架构