目录
[1.1 研究背景](#1.1 研究背景)
[1.2 现有方法局限](#1.2 现有方法局限)
[1.3 核心贡献](#1.3 核心贡献)
[1.4 摘要](#1.4 摘要)
[2.1 智能体与环境交互的一般设置](#2.1 智能体与环境交互的一般设置)
[2.2 动作空间扩展与生成流程](#2.2 动作空间扩展与生成流程)
[2.3 独特特征](#2.3 独特特征)
[3.1 知识密集型推理任务](#3.1 知识密集型推理任务)
[3.2 决策任务](#3.2 决策任务)
1、论文概述
在开始分享这篇论文之前,我们需要来搞清楚一个定义,什么是Agent?就从最近比较火的openclaw说起,它就是一个 Agent,Agent是一种能够感知环境进行自主理解,进行决策和执行动作的智能体。Agent具备通过独立思考、调用工具逐步完成给定目标的能力,主要分为感知,决策和行动板块。
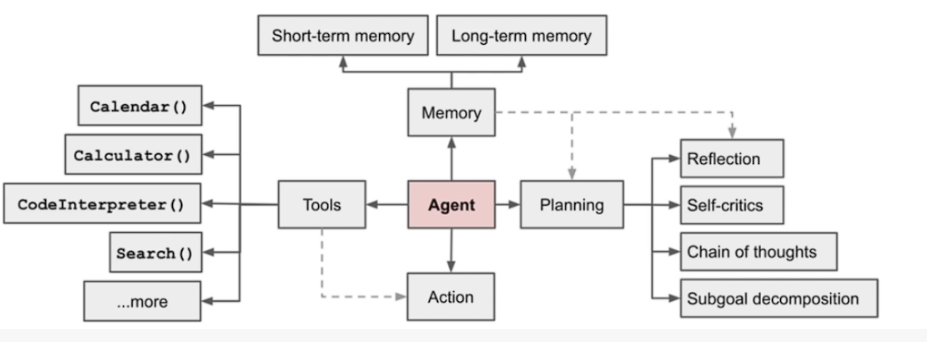
如上图所示,一个基于大模型的Agent系统可以拆分LLM(大模型)、记忆(Memory)、任务规划(Planning)以及工具使用(Tool)的集合。我们可以从右边这块Planing模块,包括反思、自我批判、链式思考等,这就是属于agent的决策板块。左边的tool板块,就是当决策板块完成后会给大模型发出指令,让它去选择调用存在的一些工具去完成任务,比如计算任务,代码检测任务,联网搜索任务等等。
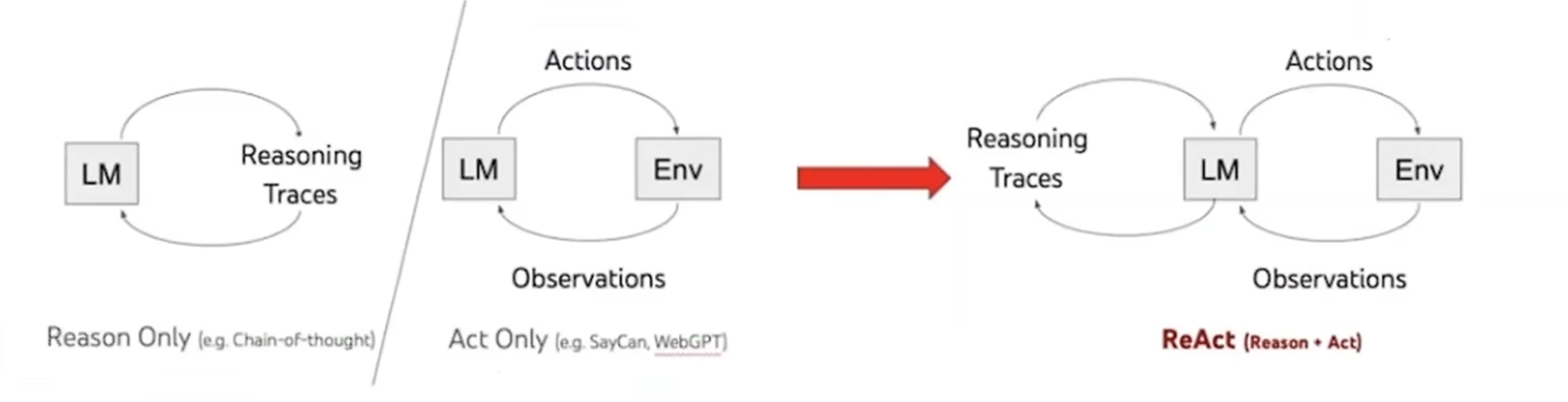
现在我们再回到这篇论文本身,这篇论文是23年的工作,当时23年是个什么情况呢,当时是gpt刚火,大家更多的去研究怎么让模型更智能,但是那个时候的模型要只会生成答案,要么只会一步步推理,那会很多模型都是自己在那算,然后直接给结果,你完全不知道他是怎么想的,推理过程完全是黑箱,而且有的时候为了推理出一个合理的答案,它还会胡编乱造,也就是大模型幻觉问题,然后作者就想能不能让模型把他的思考过程说出来,就像我们人解决问题一样,先想第一步,在想第二步,边想边说,这样不仅能减少幻觉,还能让我们知道它是如何思考的。而且作者还想到光自己想是不够的,也需要跟外面信息结合起来,比如问一些实时新闻,它的训练数据里面是没有的,就需要去外面搜索,那会很多模型都是基于静态数据进行训练的,接触不到最新信息,所以作者就将这两个事情结合起来,一个就是reasioning推理思考,一个就是acting就是行动,比如说搜索调用工具什么的,这就是ReAct。
作者信息:Shunyu Yao*,1; Jeffrey Zhao,2,;Dian Yu2, Nan Du,2; Izhak Shafran,2;Karthik Narasimhan,1; Yuan Cao,2
1、Department of Computer Science, Princeton University (普林斯顿大学计算机科学系)
2、Google Research, Brain team
项目地址:https://react-lm.github.io/.
以下将从研究背景、核心贡献、摘要、方法、实验等几个部分来进行介绍!
1.1 研究背景
大语言模型(LLM)虽然在语言理解和交互式决策任务上展现出惊人的能力,但长期以来,推理(Reasoning)与行动(Acting)一直被作为两个独立的研究方向来探讨,导致两者之间未能形成有效的协同机制。
本文指出人类智慧的一个独特特征是能够将面向任务的行动与语言推理无缝结合。在现实场景中,人类也会通过实际行动来支持推理,例如在厨房做饭时,打开食谱、打开冰箱检查食材,从而回答"现在我能做什么菜?"这样的问题。这种"行动"与"推理"之间的紧密协同作用使人类能够快速学习新任务,并在之前未见过的环境或面对信息不确定的情况下做出稳健的决策或推理。
尽管 LLM 已展现出强大的涌现能力,但当前Agent主流方法在推理与行动的结合上存在明显缺陷。如纯推理范式和纯行动范式,目前还没有研究系统性地探索如何以协同的方式将推理和行动结合起来,用于通用任务求解。更重要的是,尚未有工作验证这种协同是否能比单独的推理或单独的行动带来系统性的性能提升。
1.2 现有方法局限
1、纯推理范式(Chain-of-Thought, CoT): 通过生成多步"思考步骤"来解决复杂语言问题。仅依赖模型内部知识,不与外部环境交互,CoT虽然在算术、常识和符号推理任务上展现了多步推理能力,但本质上是静态的黑箱,它完全依赖模型自身的预训练知识,无法与外部真实世界进行交互,因此无法实时更新信息或根据新观察进行反应式调整。在需要外部事实或最新知识的任务中,这类方法极易产生事实幻觉,即模型编造出不存在的信息;同时,错误会在推理链条中逐步传播,导致最终结果不可靠。
2、纯行动类范式(Act-only): 即模型直接生成具体操作指令,然后由控制器执行的方法。这类方法的主要优势是能与外部环境产生交互,但它完全缺少高层抽象推理和工作记忆的支持,无法对整体目标进行策略性规划,也难以跟踪子目标的完成情况或处理突发异常。在长时序、稀疏奖励的环境中,模型很容易迷失方向,重复生成无效或幻觉式的行动。在问答任务中,尽管能访问外部知识源,但由于缺少推理指导,它在合成最终答案时表现较弱。
1.3 核心贡献
论文的核心贡献在于提出了一种全新的提示范式------ReAct,它首次将大语言模型中的推理与行动以交替生成的方式有机融合,形成了一个通用、可扩展且易于实现的协同框架。这一框架从根本上突破了以往方法将推理和行动割裂处理的局限,实现了两者之间的动态闭环协同。
1、框架设计层面: ReAct 将智能体的动作空间进行了系统性扩展。传统方法中,动作空间仅包含具体环境操作(如搜索、点击、移动等)。ReAct 则将动作空间扩展为外部动作与语言思考的并集,其中语言思考(即模型生成的自由形式文本推理)被视为一种不影响外部环境的特殊动作。这种思考动作的主要作用是更新当前的上下文信息,帮助模型进行高层规划、跟踪进度、注入常识知识、提取关键观察信息、处理异常情况以及调整后续计划。
•思考指导行动(Reason-to-Act):思考帮助模型制定高层计划、分解子目标、决定下一步最优操作;
•行动更新思考(Act-to-Reason):行动带来的外部观察被直接注入思考过程,使推理不再是静态的内部过程,而是动态接地到真实环境。
2、实现机制层面: ReAct在实现上极其简洁且易于复现,完全依赖提示工程(prompting)而无需修改模型参数或进行大规模训练。使用两种思考密度模式:在知识密集型任务中,采用密集思考模式,几乎每一步动作前都插入一个思考,用于分解问题、提取信息、进行常识或算术推理、重新表述搜索查询以及合成最终答案。在交互决策任务中,采用稀疏思考模式,模型自主决定何时插入思考,只在最关键的位置进行高层推理,从而避免不必要的思考开销。
1.4 摘要
虽然大型语言模型(LLMs)在语言理解和交互式决策等任务中表现出色,但它们在推理和行动方面的能力主要作为独立主题进行过研究。在本文中探索了使用LLMs以交错方式生成推理步骤和特定任务行动的方法,从而实现两者之间的更大协同:推理步骤帮助模型诱导、跟踪和更新行动计划以及处理异常,而行动则允许它与外部来源(如知识库或环境)进行交互并收集更多信息。本文将名为ReAct的方法应用于一系列语言和决策任务,并证明其在最先进基线之外的有效性,以及改进的人类可解释性和可信度。具体来说,在问答(HotpotQA)和事实验证(Fever)上,ReAct通过与简单的维基百科API交互,并生成比没有推理步骤的基线更具可解释性的任务解决,克服了思维链推理中常见的幻觉和错误传播问题。
此外,在两个交互式决策基准(ALFWorld和WebShop)上,ReAct分别比模仿学习和强化学习方法在绝对成功率上高出34%和10% ,而只需一个或两个上下文示例提示。

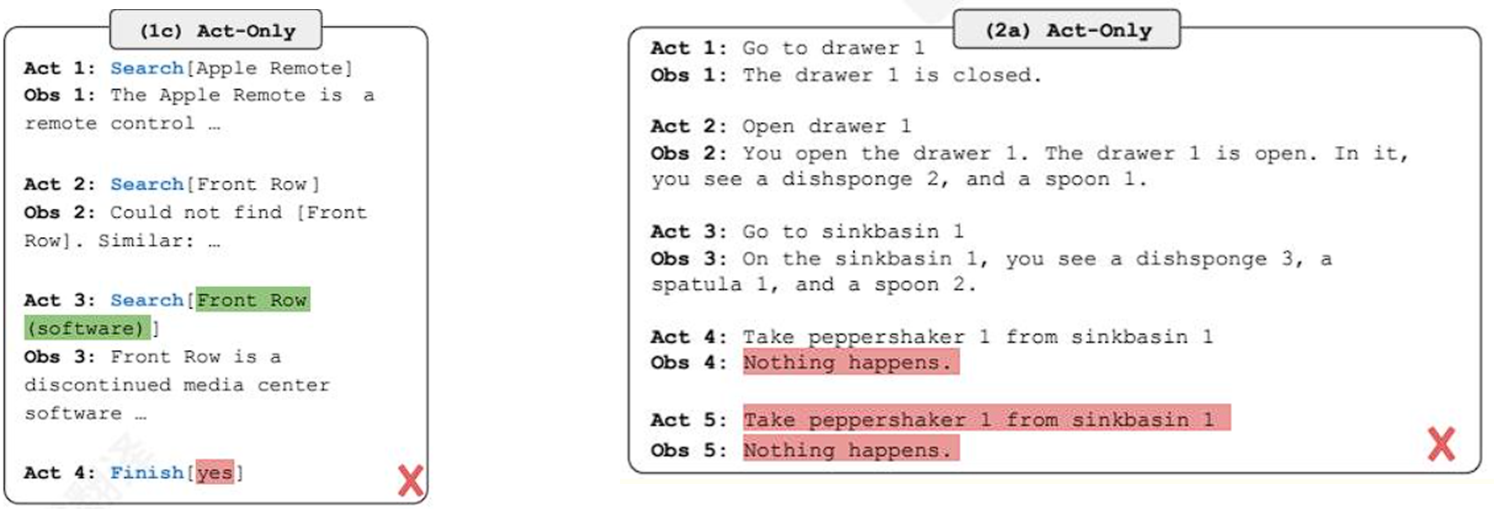
首先我们来看第一个任务,HotPotQA(多跳问答),问题示例:除了Apple Remote,还有哪种设备可以控制 Apple Remote 原本设计要交互的software?
1a)Standard:
只给模型问题,没有推理过程和外部查询。
模型回答 iPod → 错误(❌)
分析:模型直接用内部知识猜测,缺乏逻辑推理和事实验证。
1b)CoT / Reason Only
模型生成详细推理轨迹(Thought),没有行动(Action)
思考:让我们一步一步思考。Apple Remote 最初被设计用来与 Apple TV 交互。Apple TV 可以由 iPhone、iPad 和 iPod Touch 控制。因此答案是 iPhone、iPad 和 iPod Touch,错误(❌)
分析:内部推理轨迹丰富,但信息是"静态的",无法动态查证事实 → 幻觉。
1c)Act-Only(纯行动)
行动 1:搜索Apple Remote
观察 1:Apple Remote 是一个控制器......
行动 2:搜索Front Row
观察 2:无法找到 Front Row。相似结果:......
行动 3:搜索Front Row (software)
观察 3:Front Row 是一个已停产的媒体中心软件......
行动 4:完成yes(❌)
分析:模型虽然能与外部环境交互,但缺乏综合推理能力,导致于难以正确整合信息,得到一个可靠的结果。
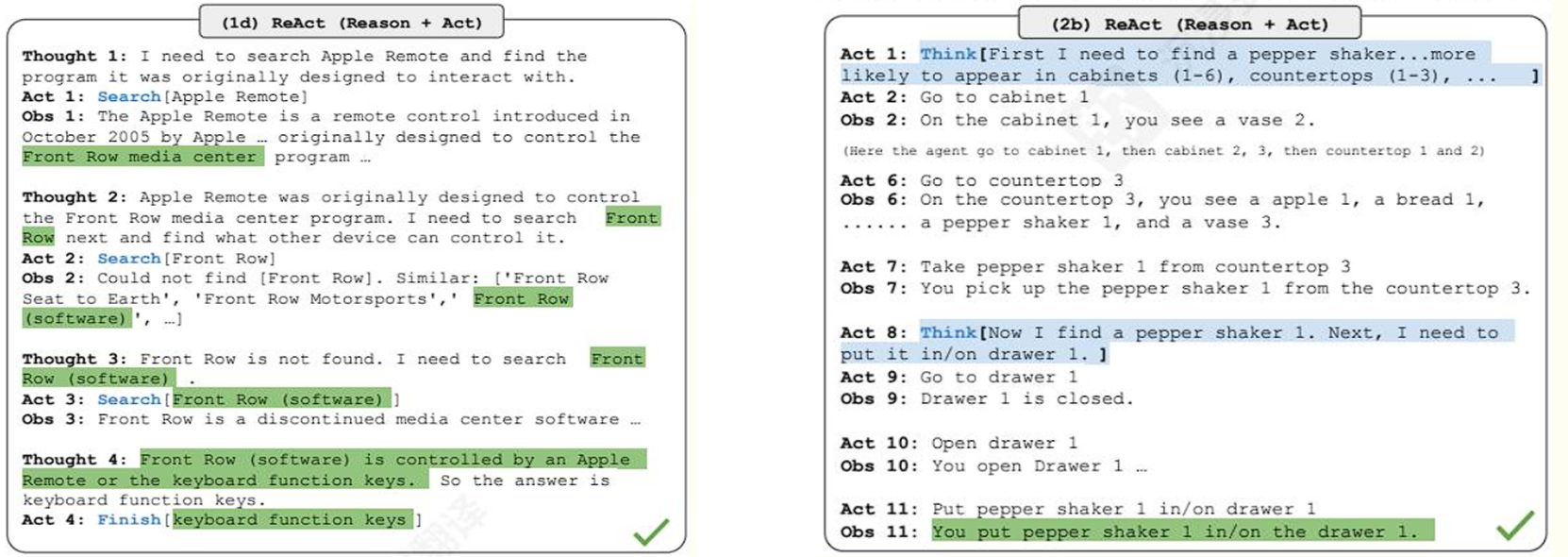
1d)ReAct(Reason + Act,思考 + 行动)
思考 1:我需要搜索Apple Remote,并找到它最初被设计用来交互的程序。
行动 1:搜索Apple Remote
观察 1:Apple Remote 是 Apple 于 2005 年 10 月推出的控制器......最初被设计用来控制 Front Row 媒体中心程序......
思考 2:Apple Remote 最初被设计用来控制Front Row媒体中心程序。我需要接下来搜索Front Row,并找到其他什么设备可以控制它。
行动 2:搜索Front Row
观察 2:无法找到 Front Row。相似结果:'Front Row Seat to Earth'、'Front Row Motorsports'、'Front Row (software)'、......
思考 3:Front Row没有找到。我需要搜索Front Row (software)。
行动 3:搜索Front Row (software)
观察 3:Front Row是一个已停产的媒体中心软件......
思考 4:Front Row (software) 是由Apple Remote或键盘功能键控制的。因此答案是键盘功能键。
行动 4:完成keyboard function keys (✔)
接着我们来看第饿二个任务,ALFWorld 文本家务游戏;任务:你站在房间中央。快速环顾四周,你看到柜子 6、柜子 1、咖啡机 1、柜台 3、炉灶 1 和烤面包机 1。你的任务是:把某个胡椒罐放到抽屉上。
2a)Act-Only(纯行动)
行动 1:去抽屉 1
观察 1:抽屉 1 是关闭的。
行动 2:打开抽屉 1
观察 2:你打开了抽屉 1。抽屉 1 已打开。在里面,你看到海绵 2 和勺子 1。
行动 3:去水池1
观察 3:在水池1 上,你看到海绵3、刮刀1 和勺子2。
行动 4:从水池1 拿起胡椒罐 1
观察 4:什么都没有发生。
行动 5:从水池 1 拿起胡椒罐 1
观察 5:什么都没有发生。(❌)
分析:模型没有推理,无法理解"胡椒罐应该放到抽屉里",只机械执行动作。
2b)ReAct(Reason + Act,思考 + 行动)
行动 1:思考首先我需要找到一个胡椒罐......它更可能出现在柜子(1-6)、柜台(1-3)......
行动 2:去柜子 1
观察 2:在柜子 1 上,你看到花瓶 2。
(此处智能体依次去了柜子 1、柜子 2、柜子 3,然后是柜台 1 和柜台 2)
行动 6:去柜台 3
观察 6:在柜台 3 上,你看到苹果 1、面包 1、......、胡椒罐 1 和花瓶 3。
行动 7:从柜台 3 拿起胡椒罐 1
观察 7:你从柜台 3 拿起了胡椒罐 1。
行动 8:思考现在我找到了胡椒罐 1。接下来,我需要把它放到抽屉 1 上。
行动 9:去抽屉 1
观察 9:抽屉 1 是关闭的。
行动 10:打开抽屉 1
观察 10:你打开了抽屉 1......
行动 11:把胡椒罐 1 放到抽屉 1 上
观察 11:你把胡椒罐 1 放到了抽屉 1 上。(✔)
分析:思考步骤帮助模型规划动作顺序,通过行动提供环境反馈,模型根据反馈调整策略,最终成功完成任务。
通过我们对以上任务的解读和对比:
CoT:思考结构好,但事实不与外部交互,自己在那跟自己玩 → 结果不可信。
Act-Only:能行动,但缺少高层思考,没办法去总结和纠错 → 盲目、重复的工作、最终失败。
ReAct:思考+行动交替,边想边做,既能制定计划、实时纠错,又能利用外部观察,最终在两个完全不同类型的任务上都取得成功。
2、ReAct方法
2.1 智能体与环境交互的一般设置

2.2 动作空间扩展与生成流程

𝒜 ̂=𝒜∪ℒ:模型现在能做的所有事情(动作空间)被扩大了,A:原来的动作空间,就是真正会影响环境的外部动作(例如:搜索 Wikipedia、去柜子 1、点击购买等)。L:新增的语言空间,也就是模型可以输出的一段文字思考。总结:以后模型既可以"动手",也可以"动嘴(思考)"
𝑎 ̂_𝑡∈ℒ:在第 t 步,模型输出的这个动作 at 是属于语言空间的。作者给它起了两个名字:思考(Thought)或 推理轨迹(reasoning trace)。
也就是说它不会真的去操作环境,所以环境不会给它任何新的观察反馈(不会产生 Obs)。它只是在模型的"脑子里"想事情。
𝑐_(𝑡+1):也就是说思考的唯一作用就是更新模型的记忆。c_t :当前上下文(模型到目前为止看到的所有历史记录,包括之前的观察和动作)。a_t:刚刚生成的这段思考文字。c_{t+1}:新的上下文 = 旧上下文 + 这段思考。简单说:思考就像在模型的笔记本上写了一条笔记,下一步行动时,模型就能带着这条笔记一起看,从而决定下一步该做什么。
2.3 独特特征
A)直观且易于设计:设计 ReAct 提示非常简单,标注者只需在自己采取的行动之上用语言写下他们的思考即可。本文没有使用任何特别的格式选择、思考设计或示例挑选。在后续章节中详细说明了每个任务的提示设计。
B) 通用且灵活:由于思考空间的灵活性和思考-动作发生格式的灵活性,ReAct 可用于具有不同动作空间和推理需求的多样的任务,包括但不限于问答、事实验证、网页导航等。
C) 高效且鲁棒:ReAct在仅从1到6个上下文示例中学习的情况下,对新任务实例展现出强大的泛化能力,在不同领域持续超越仅进行推理或仅进行行动的基线方法。
D) 与人类对齐且可控:ReAct提供了一个可解释的顺序决策和推理过程,人类可以轻松检查推理和事实正确性。此外,人类还可以通过编辑思考来实时控制或纠正智能体的行为,如下图所示。

ReAct在AlfWorld中的人机交互行为校正示例。(a)由于产生幻觉的思考(行为17),ReAct轨迹失败。(b)通过人类简单编辑两个思考(行为17、23),ReAct轨迹产生理想的推理轨迹和动作并成功。
(a)Act 17、23、25 都是 Think(思考):
ob16:发现第一个钥匙链在抽屉4中。
Act 17: "我找到第一个钥匙链,需要拿它。我可以稍后在抽屉 4 找第二个钥匙链。"
Act 23: "我把第一个钥匙链放入保险箱。接下来,我需要找到第二个钥匙链,我可以直接去抽屉 4。"
Act 25: "我找到第二个钥匙链,需要拿它。"
Act 26: 拿第二个钥匙链 → 失败(Nothing happens)
分析:虽然模型有完整思考轨迹,但存在规划错误:第一个钥匙链放进保险箱后,模型错误地认为第二个钥匙链仍在抽屉 4
实际第二个钥匙链在其他家具(如 dresser 1) → 拿取失败。也就是说ReAct在复杂任务中仍可能出现推理错误,尤其是空间记忆或物品位置判断错误。
(b)这里他直接将Act 17中的错误思考人为的删掉了,那么当agent将第一个钥匙扣放好之后,他就会去思考:我需要找到第二个钥匙链,它更可能出现在梳妆台(1)、垃圾桶(1)、保险箱(1)、边桌(1)、沙发(1)、架子(1-12)。而不是直接认定第二个钥匙链在抽屉 4中了。
也就是说在人为的删除错误思考方向,并在Thought 中加入对第二个钥匙链可能位置的推理,考虑环境中所有可能位置,而非只关注之前的抽屉
结果:模型成功完成任务,避免了"Nothing happens"的失败。ReAct 不仅让模型"边想边做",还让人类能通过编辑思考像修改笔记一样实时纠正模型行为,只需极小的干预就能把失败轨迹变成成功轨迹,这体现了 ReAct 在可解释性和可控性上的巨大优势。
3、实验
3.1 知识密集型推理任务
首先从知识密集型推理任务入手,例如问答和事实验证,ReAct 能够获取信息来支持推理,同时利用推理来确定下一步应该检索什么内容,从而展现出推理与行动的协同效应。
实验设置:
领域:本文选择了两个在知识检索和推理方面具有挑战性的数据集:(1)HotpotQA,这是一个横跨多领域的问答基准,需要对两个或更多Wikipedia段落进行推理;(2)FEVER,这是一个事实验证基准,每条声明都被标注为SUPPORTS(支持)、REFUTES(反驳)或NOT ENOUGH INFO(信息不足)。在本工作中,对两个任务都采用仅提供问题/声明的设置,即模型仅接收问题或声明作为输入,无法直接访问支持段落,必须依赖自身内部知识,或者通过与外部环境交互来检索知识,从而支持推理过程。
动作空间:
实验设计了一个简单的Wikipedia网页API,包含三种动作来支持交互式信息检索:(1)searchentity,如果对应实体页面存在,则返回该页面前 5 句话;如果不存在,则从Wikipedia搜索引擎返回最相似的5个实体;(2)lookupstring,返回页面中包含指定字符串的下一句话,模拟浏览器中的 Ctrl+F 查找功能;(3)finishanswer,以指定答案结束当前任务。需要说明的是,这个动作空间主要只能根据精确的页面名称检索到段落的一小部分,其检索能力明显弱于当前最先进的词典式或神经网络检索器。本文的目的是模拟人类与 Wikipedia的交互方式,并迫使模型通过语言中的显式推理来进行检索。
React Prompting:
对于 HotpotQA 和 FEVER,本文分别从训练集中随机选取 6 个和 3 个案例,手动编写ReAct格式的轨迹,作为少样本示例放入提示词中。每个轨迹都包含多个思考-动作-观察步骤(即密集思考模式),其中自由形式的思考用于多种任务。具体而言,本文使用的思考组合包括:分解问题("我需要搜索 x,找到 y,然后找到 z")、从Wikipedia观察中提取信息("x 始于 1844 年""这段话没有提到 x")、进行常识推理("x 不是 y,因此 z 必须是......")或算术推理("1844 < 1989")、指导搜索重写("也许我可以改成搜索/查找 x"),以及综合得出最终答案("......所以答案是 x")。
Baselines:
本文系统性地对ReAct轨迹进行消融处理,从而构建多种基线方法的提示:
(a)标准提示(Standard):移除 ReAct 轨迹中所有的思考、动作和观察。
(b)思维链提示(CoT):移除动作和观察,仅保留推理过程,作为纯推理基线。
(c)纯行动提示(Act):移除 ReAct 轨迹中的思考,大致类似于WebGPT通过与互联网交互来回答问题的方式,不过它使用不同的任务和动作空间,并且采用模仿学习和强化学习而非提示方式。
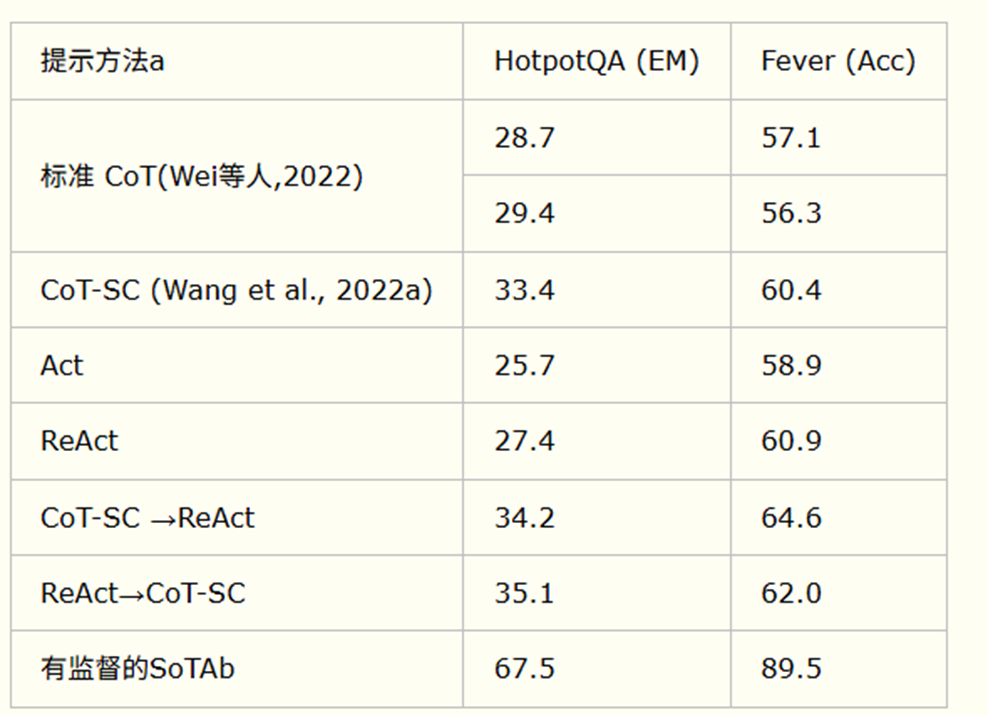
**结果:**下表展示了以 PaLM-540B 为基础模型、在不同prompt方法下 HotpotQA 和 FEVER 的结果。注意到,在两个任务上ReAct均优于Act,这表明推理对于指导行动具有重要价值,尤其是在综合得出最终答案时。
3.2 决策任务
本文还测试了ReAct在两个基于语言的交互式决策任务ALFWorld和WebShop上的表现,这两个任务都涉及复杂的环境,需要智能体在长时序、稀疏奖励的条件下进行行动,因此特别需要推理来有效规划和探索。
ALFWorld是一个合成文本游戏,旨在与具身 ALFRED 基准对齐。它包含 6 种类型的任务,智能体需要通过在模拟的家庭环境中导航和交互(例如"go to coffeetable 1""take paper 2""use desklamp 1"),来实现一个高层目标(例如"examine paper under desklamp")。一个任务实例可能包含超过 50 个位置,并且专家策略可能需要50多步才能完成,因此对智能体的规划、子目标跟踪以及系统性探索能力提出了挑战(例如逐一检查所有桌子以找到台灯)。ALFWorld特别内置了一个挑战,即需要判断常见家用物品的可能位置(例如台灯最可能出现在桌子、架子或梳妆台上),这使得该环境非常适合大语言模型利用其预训练的常识知识。
为了提示ReAct,本文为每种任务类型从训练集中随机标注了3条轨迹,每条轨迹包含稀疏的思考,这些思考用于:(1)分解目标,(2)跟踪子目标完成情况,(3)确定下一个子目标,以及(4)通过常识推理判断物品可能在哪里以及该如何处理它。
本文研究了 WebShop这是一个最近提出的在线购物网站环境,包含118万个真实世界商品和1.2万条人类指令。与 ALFWorld不同,WebShop包含高度多样化的结构化和非结构化文本(例如从 Amazon 抓取的商品标题、描述和选项),并且要求智能体根据用户指令(例如"我想要一个带抽屉的床头柜,它应该有镍色表面,价格低于140美元")通过网页交互(例如搜索"nightstand drawers"、选择按钮如"color: modern-nickel-white"或"back to search")来购买商品。该任务通过平均得分(所选商品覆盖用户所需属性的百分比,在所有 episode上取平均)和成功率(满足所有要求的 episode 占比)在500条测试指令上进行评估。
实验为Act提示设计了搜索、选择商品、选择选项和购买等动作,而ReAct提示则额外加入了推理,用于决定探索什么、何时购买以及哪些商品选项与指令相关。
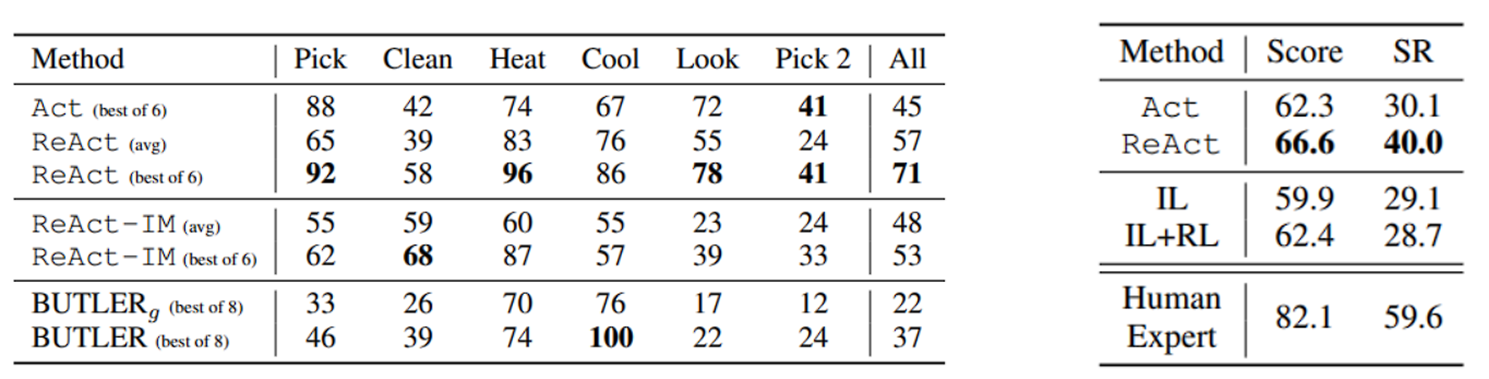
**结果:**ReAct在ALFWorld(下表左)和 WebShop(下表右)两个任务上均优于Act。在ALFWorld上,最优的 ReAct试验达到了平均成功率71%,显著超越了Act的最优试验(45%)和BUTLER(37%)。事实上,即使最差的ReAct试验(48%)也超过了两种基线方法的最优试验。此外,ReAct相对于Act的优势在6个受控试验中保持一致,相对性能提升范围为33%至90%,平均提升62%。从定性角度看,完全没有思考的Act无法正确地将目标分解为更小的子目标,或者无法跟踪环境的当前状态。
在WebShop上,仅使用 1-shot 的 Act 提示就已经与 IL 和 IL+RL 方法表现相当。加入稀疏推理后,ReAct 取得了显著更好的性能,成功率比之前的最佳结果绝对提升了 10%。
4、结论
本文提出了ReAct------一种简单而有效的方法,用于在大型语言模型中实现推理与行动的协同。通过在多轮问答、事实验证以及交互式决策任务上进行的一系列多样化实验,本文展示了ReAct能够带来更优的性能,同时生成可解释的决策轨迹。尽管本文的方法非常简洁,但对于动作空间较大的复杂任务,仍需要更多示范示例才能学习得很好,而这很容易超出上下文学习的输入长度限制。本文在HotpotQA上探索了微调方法,取得了初步令人鼓舞的结果,但要进一步提升性能,仍需从更多高质量的人类标注数据中学习。将ReAct通过多任务训练进行扩展,并与强化学习等互补范式相结合,有望构建出更强大的智能体,从而进一步释放大型语言模型在更多应用场景中的潜力。