Agent 的最小执行链,到底长什么样?
想了想,最好的办法就是手搓一个。
先不管 ReAct、MCP、Function Calling、Memory、Harness 这些词。先不讲"自主规划、自主执行、自主反思"。
就写一个最小 Agent。
它只做四件事:
-
读用户任务;
-
让模型选择下一步;
-
按模型要求调用工具;
-
把工具结果喂回去,继续循环。
如果 30 分钟只能写这么一个小东西,它当然不是 Claude Code,也不是 OpenClaw。
但我觉得它很适合当一堂解剖课。
写出来的是一个小玩具,看清的是 Agent 工程的骨架。
等这个最小闭环跑起来,再回头看 Claude Code、OpenClaw、Harness,就会顺很多:它们没有把 loop 写得多玄,更多是在 loop 外面一层层补上工具边界、上下文边界、记忆边界、权限边界和验证边界。
这次只做一个最小 Coding Agent。
它有三类输入:
-
用户任务;
-
当前对话历史;
-
工具列表。
它只有三个工具:
-
list_files(path):列目录; -
read_file(path):读文件; -
run_command(command):运行一条白名单命令。
先不给写文件工具。
这个选择有点保守,但更接近我自己的使用习惯:新系统第一版先让模型"看环境",再让它做少量可控动作。写权限、删除权限、网络权限、凭证访问这些东西,后面单独加。
这就是实战里很容易被忽略的第一层边界:
Agent 的能力不是越大越好。能力要跟验证和回滚一起长。
最小闭环:20 行左右就能看懂
先看核心循环。
下面这段不是完整生产代码,只是把 Agent Loop 的骨架压出来:
python
async function runAgent(task: string) {
const messages = [
{ role: "user", content: task },
];
for (let step = 0; step < 8; step++) {
const response = await model.create({
messages,
tools,
});
messages.push({
role: "assistant",
content: response.content,
});
if (!response.toolCall) {
return response.text;
}
const observation = await runTool(response.toolCall);
messages.push({
role: "tool",
content: observation,
});
}
return "Stopped: step limit reached.";
}它做的事很少:
-
把任务和历史交给模型;
-
模型返回回答,或者返回工具调用;
-
程序执行工具;
-
工具结果作为观察写回上下文;
-
下一轮继续。
图 1:最小 Agent Loop
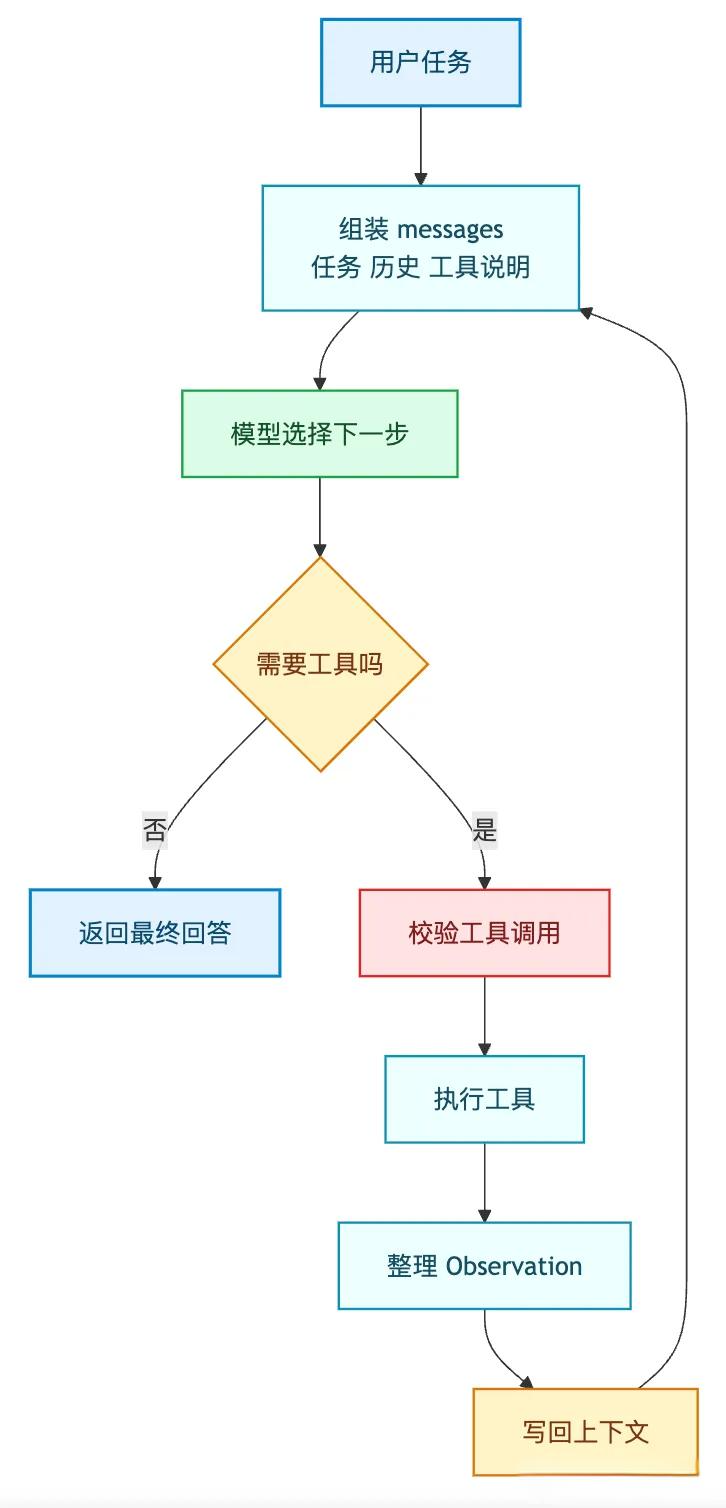
很多文章会把这里讲得很神秘。
但把代码摆出来以后,会发现就是一个循环。
如果你觉得这个骨架太简化了,也没关系。生产级 Agent 的实现通常会更长:它们会加上流式响应、事件系统、工具串行/并行调度、工具前后钩子等机制。
但主干没有变,仍然是"调模型 → 判断是否调用工具 → 执行 → 回写上下文 → 继续下一轮"。
我们之前也分析过:《OpenClaw 背后的秘密武器:极简智能体框架 Pi》。
当前 agent-loop.ts 是 639 行,主干仍然是同一类结构:外层 while(true) 循环,每轮调模型、检查有没有 toolCall、执行工具、把结果写回上下文、继续。区别在于它多了流式响应、事件系统、工具串行/并行调度、beforeToolCall/afterToolCall 钩子这些生产级的东西。但骨架没变。
问题也从这里开始。
这个 loop 能跑,不代表它能用。它没有处理权限,没有限制命令,没有裁剪输出,没有记忆策略,也没有验证完成标准。
也就是说,30 分钟能跑通 Agent。
接下来所有工程问题,都是在回答同一句话:
这个 loop 放进真实世界以后,怎么不乱跑。
工具不是函数列表
最小版本里,我们很容易这样写:
python
const tools = [
listFiles,
readFile,
runCommand,
];这只能说明程序里有三个函数。
对 Agent 来说,还不够。
模型需要知道每个工具能做什么、参数是什么、什么时候该用、失败时会返回什么。程序还要决定参数能不能信,路径能不能读,命令能不能跑,输出要不要裁剪。
所以实际更接近这样:
python
const tools = [{
name: "read_file",
description: "Read a text file inside the current workspace.",
inputSchema: {
type: "object",
properties: {
path: { type: "string" },
},
required: ["path"],
},
}];这就是 Function Calling 或 Tools API 解决的问题:让模型用结构化方式表达"我要调用哪个工具、带什么参数"。
现在各家模型的工具接口细节不同,但方向相近:工具名、描述、参数 schema、调用结果,都尽量结构化。
不过这里要补一个很重要的边界。
Function Calling 解决的是"怎么表达工具调用"。
它不会替我们解决这些问题:
-
path是否越过工作区; -
command是否危险; -
工具返回 2MB 日志时要不要全塞回模型;
-
命令失败后是重试、降级、问人,还是停止;
-
模型连续调用 8 次还没完成时,系统要不要切断。
Pi 的 coding tools 默认也很克制:Read、Bash、Edit、Write 四个核心工具。
第一次看到的时候觉得也太少了。但仔细想想,写软件大多逃不开一条主路径:读代码 → 改代码 → 跑一下看结果。这四个工具刚好覆盖了这条主路径。工具少,系统提示词就短,模型误用工具的概率就低,出了问题也更容易追溯。需要新能力的时候,Pi 更倾向把扩展能力留在系统侧,而不是一开始就把工具列表铺得很大。
说白了就一件事:
工具调用不是把函数暴露给模型,而是把真实世界切成一组可控入口。入口越少,每个入口的边界越容易守住。
图 2:一次工具调用要经过的链路
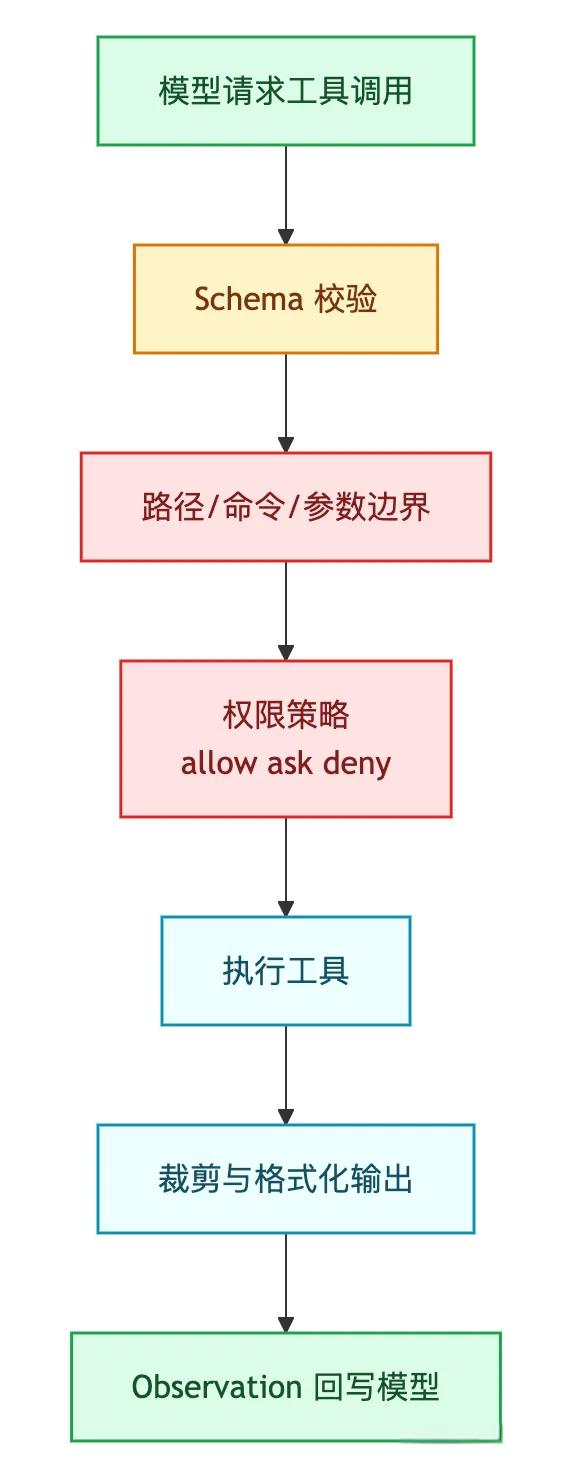
这也是回头看 Claude Code 时最容易接上的地方。
Claude Code 不是只有"模型 + Bash"。它还围绕 Bash、Read、Edit、WebFetch 等工具做了权限、确认、环境和输出处理。Anthropic 的 Bash tool 文档里也明确提醒:Bash 是直接系统访问能力,需要隔离环境、命令过滤、资源限制和日志。
手搓版用一个 run_command 就能演示概念。
一旦做成可用工具,边界就要补上。
从提示词解析到 Function Calling:一个容易被跳过的进化
很多教程讲 Agent 时会直接从 Function Calling 开始,好像它天经地义就在那里。
其实第一代"让模型调工具"的做法更原始:在系统提示词里把工具名、参数格式、返回约定全写进去,然后要求模型以 JSON 格式输出调用意图,程序再自己解析 JSON、分发到对应函数。
这套方案能跑,很多早期 demo 都这么做:在系统提示词里写清工具名和参数格式,让模型输出一段约定好的结构化结果,再由程序手动解析、手动分发。
但写过就知道,这里有几个很现实的痛点:
-
提示词越来越长,工具一多就难维护;
-
模型输出格式全靠提示词约束,偶尔会跑偏;
-
解析逻辑要自己写,边界情况不少。
所以 2022 年 ReAct 论文提出了一个关键思路:模型不应该只在文本里猜,它可以通过动作向环境拿新观察(Thought → Action → Observation)。这个范式影响了后面所有 Agent 框架的走向。
2023 年 6 月 13 日,OpenAI 把 Function Calling 放进 Chat Completions API,这条路开始进入主流开发接口:工具名、描述、参数 schema 由 API 层承载,模型用结构化方式表达"我要调什么、带什么参数",开发者不用再手写 JSON 解析。后来 Anthropic、Google、DeepSeek 都跟进了,接口细节不同,方向一致。
回头看,这个进化过程本身就很能说明一件事:
Agent 工程很少一次设计到位,更常见的是跑起来以后发现边界不够,再一层层补。
提示词解析不稳,就补 Function Calling。工具调用没有边界,就补 schema 校验和权限。模型老是停不下来,就补步数限制和超时。每一层都是从"先能跑"到"跑稳"的过程。
这也是接下来要聊的事。
Loop 会失控,所以要有 Harness
最小循环里,我故意写了一个 step < 8。
这是一个很土的限制,但很有用。
没有步数限制的 Agent,最容易出现几类问题:
-
一直调用工具,停不下来;
-
工具失败了,还假装成功继续往下走;
-
读了太多文件,把上下文塞脏;
-
提前回答,结果还没验证;
-
把中间日志当成最终结论。
这些问题和模型强不强有关,但不全是模型问题。
它们更多发生在运行时。
这也是这半年一直写 Harness 时,我反复想表达的那件事:
Harness 不是给 Agent 套的一层壳。它是把 loop 放进真实工程环境以后,补出来的运行系统。
一个最小 Harness 至少要管这些东西:
-
最大循环轮数;
-
最大工具调用次数;
-
单次工具超时;
-
token 和成本预算;
-
工具输出裁剪;
-
错误分类和恢复;
-
关键动作确认;
-
日志和回放;
-
任务完成标准。
Pi 的做法可以拿来参考。它在 agent-loop 里提供了两个钩子:beforeToolCall 和 afterToolCall。前者在工具执行前拦截,可以校验参数、检查权限、直接 block 掉不安全的调用;后者在执行后介入,可以修改返回内容、标记错误、做输出裁剪。这两个钩子不复杂,但把"工具执行前后的控制权"从模型手里拿了回来,交给了工程侧。
图 3:从能跑到可用,中间差的是运行时边界
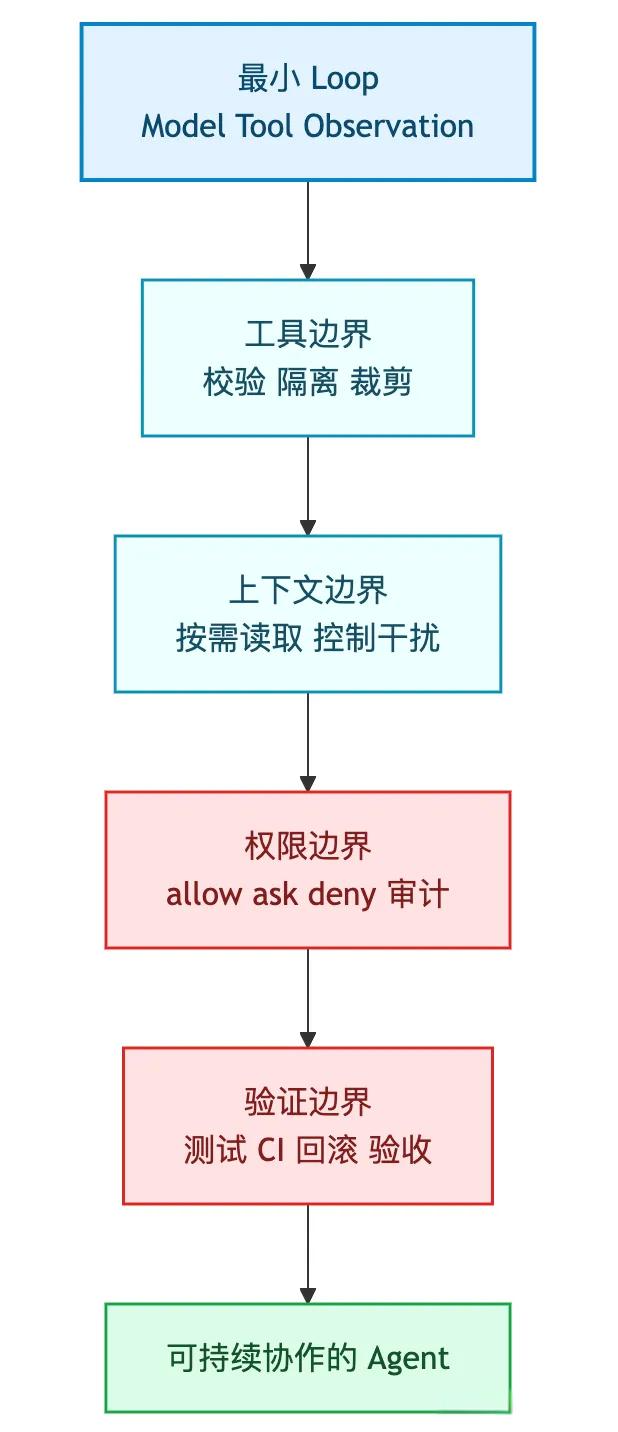
如果把 Claude Code、Codex、OpenClaw 放到这张图里看,会比单看功能表更清楚。
Claude Code 更偏 Coding Agent:仓库上下文、文件工具、Bash、Todo、Subagent、Compact、权限和验证。
Pi 选了一条很克制的路线:coding tools 默认只有四个核心工具,旁边再放 read-only tools 和扩展系统。这样做的好处是工具面不大,上下文更干净,也更容易审计。
OpenClaw 更偏长期通用 Agent:消息入口、会话、工作区、记忆、插件、网关、安全边界。它底层跑的就是 Pi 的引擎。
三条路线不一样,但拆开看,最小 loop 是共同的。差距发生在 loop 外面:各自补的边界不同,适合的场景也不同。
记忆不是聊天记录越多越好
手搓版第一轮最简单:
python
messages.push(userMessage);
messages.push(assistantMessage);
messages.push(toolObservation);这就是上下文记忆。
短任务够用。
但只要任务稍微长一点,就会遇到几个很现实的问题:
-
• 工具输出越来越多;
-
• 旧错误路径一直留在上下文里;
-
• 对话越长越贵;
-
• 模型开始被无关历史干扰;
-
• 会话一重启,什么都没了。
所以 Memory 不能只理解成"把聊天记录留下来"。
我更愿意把它拆成三层:
| 层次 | 保存什么 | 适合放哪里 |
|---|---|---|
| 当前上下文 | 当前任务需要的消息、工具结果、文件片段 | messages / context window |
| 持久事实 | 项目约定、用户偏好、长期背景 | Markdown / DB / profile |
| 过程经验 | 某类任务以后怎么做、踩坑路径、工作流 | Skills / playbooks / procedures |
这也是 OpenClaw、Hermes、Clawdbot 这些系统值得拆的地方。
OpenClaw/Clawdbot 走过一条很工程化的路线:把记忆放进工作区文件,让它可读、可改、可审计、可迁移。比如 memory/YYYY-MM-DD.md 记录流水,MEMORY.md 保存更长期的事实;检索时返回片段、路径和行号,而不是把整本记忆塞回去。
Hermes 则把 procedural memory 这层讲得更重:事实和偏好进 memory,任务经验可以沉淀成 skill。它更关心"这类事情以后怎么做"。
这两条路指向同一件事:
记忆系统的目标不是让 Agent 什么都记住,而是让它在合适的时候想起对当前任务有用的东西。
手搓版如果要加记忆,我会先做一个很小的版本:
const memory = {
projectRules: readMarkdown("AGENTS.md"),
recentSummary: readMarkdown("memory/session-summary.md"),
};
const messages = [
{ role: "system", content: memory.projectRules },
{ role: "system", content: memory.recentSummary },
{ role: "user", content: task },
];先用 Markdown。
先让人看得懂。
等内容量、召回需求、跨项目复用真的上来,再谈向量库、全文检索、重排和自动整理。
很多系统的问题不在于没有记忆,反倒在于太早把记忆做成黑盒。
我自己的倾向也很明确:先不要把记忆做成黑盒。先用 Markdown、摘要和关键词 检索把最小版本跑通。等记忆量真的上来、简单检索明显不够用时,再加向量化、重 排和自动整理。每一层都应该有明确的痛点驱动。
Agent 工程里很多东西都是这个节奏:先跑通最小版本,碰到瓶颈再加层。
权限决定它能不能长期跑
记忆解决了"Agent 知道什么"的问题。接下来是另一个更敏感的问题:"Agent 能做什么"。
最小 Agent 里最危险的工具,一般是 run_command。
一旦把 Bash 给模型,能力一下子变大。
它可以列目录、读文件、跑测试、调用 CLI。
也可能误删文件、泄露环境变量、访问外部网络、跑长时间命令。
所以我很少把"给模型一个 Bash"理解成酷炫能力。
它更像一把很锋利的刀。
好用,但要有刀鞘。
Claude Code 的权限系统就是这个方向:哪些工具调用直接允许,哪些要询问,哪些禁止。Anthropic 后来写 Claude Code auto mode 时也讲过一个很实际的矛盾:每次写文件和跑命令都问用户,安全,但会带来 approval fatigue;完全不问,又容易放大风险。
他们没有简单走向"以后都不问",而是用分类器在动作执行前识别哪些可以放行、哪些需要拦截。文章里也给了边界:在真实 overeager actions 数据集上,完整 pipeline 仍有 17% 的 false-negative rate。
这个数字很有价值。
也就是说,自动化权限系统可以减少打扰,但不能把高风险动作的人类确认完全拿掉。
OpenClaw 的经验也类似。通用 Agent 一旦接入聊天入口、插件、工作区和本地工具,网关和权限边界就不再是"安全附录",而是主路径的一部分。
所以手搓版到了权限层,我会先切四档:
| 权限层 | 例子 | 默认策略 |
|---|---|---|
| 只读 | list_files 、read_file |
可直接执行 |
| 安全执行 | npm test 、pytest、go test |
白名单 |
| 写操作 | write_file 、apply_patch |
需要确认 |
| 高风险动作 | 删除、网络、凭证、系统目录 | 默认禁止 |
这张表不复杂。
但它决定了 Agent 是一个可控工具,还是一个事故放大器。
验证比"完成了"更重要
权限管住了 Agent 能做什么。但还有一个问题:Agent 说"做完了",你怎么知道它真的做完了?
Agent 最容易让人误判的地方,就是它很会写"完成了"。
但工程里,完成不是语气,是证据。
手搓版如果只是最后返回:
任务完成。这个回答没有太大价值。
至少要能回答:
-
读了哪些文件;
-
调了哪些工具;
-
改了什么;
-
跑了什么测试;
-
哪些检查通过;
-
哪些风险还没处理。
对 Coding Agent 来说,最小验证通常包括:
-
相关测试通过;
-
类型检查通过;
-
lint 或格式化通过;
-
diff 能对应用户任务;
-
失败时有错误摘要和下一步建议;
-
高风险改动有人确认。
这也是我看 Claude Code、Codex、OpenClaw 这些系统时最在意的部分。
模型越来越强以后,"能写出一段代码"不再稀奇。
更稀缺的是,它能不能把上下文、工具、权限、测试、日志和恢复接成一个闭环。
没有验证,Agent 只是很会解释。
有了验证,它才开始接近一个能协作的工程工具。
这也是我自己踩过坑以后的一个体会。传统 CI/CD 跑失败了,你看日志就知道哪行报错。Agent 跑"成功"了,你反而要更警惕,因为模型太擅长用自信的语气说"搞定了",但它说的"搞定"和工程意义上的"搞定"经常不是一回事。
回头看 Claude Code:它把最小循环做厚了
到这里,回头看 Claude Code 就会顺很多。
之前拆 Pi 源码的时候就有这个感受:它的 agent-loop.ts 虽然已经是 600 多行的生产代码,但主干和我们手搓版很接近。Claude Code 也是如此,核心 loop 没有什么神秘的新机制。
最小手搓版是:
Model -> Tool -> Observation -> LoopClaude Code 更像是:
Model
-> Repo Context
-> Tool System
-> Permission
-> Bash / Read / Edit
-> Todo / Subagent
-> Compact / Memory
-> Validation
-> Loop它没有把 Agent Loop 变成玄学。
它做的是把一个朴素的 loop 放进真实软件工程环境里。
这也是为什么同一个模型,在聊天框和在 Claude Code 里的体感完全不同。
聊天框里,模型主要在生成文本。你问它"帮我改个 bug",它只能说"你可以试试这样改"。
Claude Code 里,模型进入了一个工作台:它能看仓库,能读文件,能跑命令,能记录 Todo,能把支线任务交给 subagent,能在上下文变重时 compact,也能在权限系统下行动。它不是在"说"怎么改 bug,而是真的在改。
这背后对应的就是 Harness,也就是模型外面的运行系统。
把前面的内容压成一句话:
30 分钟手搓 Agent,看见的是 loop;Pi、Claude Code、OpenClaw 补上的,是 loop 在真实世界里工作所需要的边界。