哈希 ,为 Hash 的音译,意为混乱。在计算机领域,哈希是一个统称,核心分三类:哈希函数 ,哈希值 ,哈希表 。本文主要讲解的是 哈希表。
什么是哈希表
所谓哈希表 ,是通过哈希函数 将 key 映射为数组下标,以平均O (1) 效率实现增删查、并通过冲突处理保障数据存储的键值存储结构。
哈希函数 是将任意类型的关键字,换算成合法数组下标,用来实现快速映射,并尽量减少哈希冲突的函数。
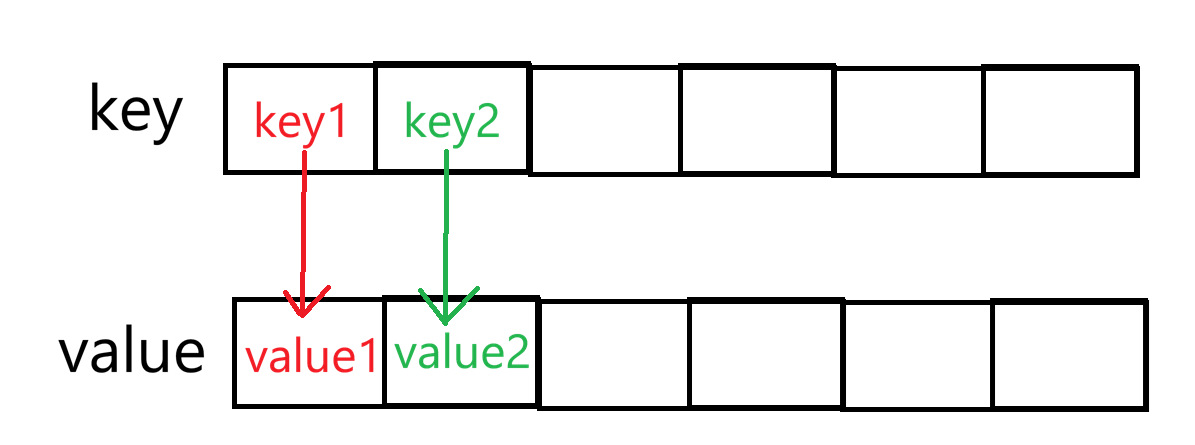
哈希表就是用 一个值 去映射 另一个值,以空间换取时间,你给它传入 key 的值,它可以直接给你返回 value 的值。
直接定址法
构建一个哈希表最简单的方法是直接定址法。直接定址法的思路和计数排序相同,就是计算 key 在结构中的位置,比如:

如果使用直接定址法,那么这里得开辟 209 个空间,且有绝大部分空间是无用的,浪费的。如果在直接定址法上使用偏移量进行优化,可以大大减少所要开辟的空间:

但是这种方法还是不行,假如有数据为 { 3,203 },这样也是需要开大量的空间的。但是办法总比困难多,这时我们可以借助特定的哈希函数来控制范围,比如:

但是呢但是(没完了是吧!!),假如有数据为 { 12, 23, 34 } ,当我们设置除数为 11,那么通过函数计算出来的值就会全部都是 1。这就是哈希冲突。
由以上可见,直接定址法难以做到尽善尽美,那有没有别的方法来构建哈希表呢?有的兄弟,有的。在基础的定址法种,除了直接定址法,我们还有开放定址法 和链定址法。
开放定址法
开放定址法 的原理是在算出下标已被占用时,按某种规则继续在表内找下一个可用位置,直到找到空位插入。
对于查找规则,有三种比较常见的,线性探测,二次探测,双重散列。
线性探测
线性探测的规则十分简单,就是固定一个步长,找到被占用位置间隔一个步长距离的位置,如果该位置也被占用,就继续找下一个,以此类推。
核心公式:
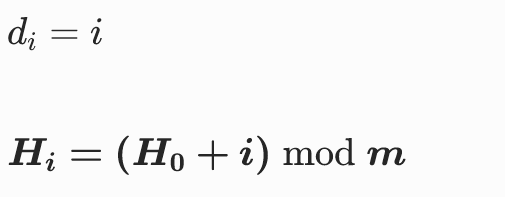
通过线性探测的规则,我们其实不难发现它的某些弊端:
假如 a,b 为相邻两个位置,有两个值经过计算后,发现都应该插入 a 中,那么根据规则,应该一个数据放在 a,一个放在 b。那在后面的数据如果算出结果应该插入 b 中时,会因为 b 已经被占用而继续向后寻找。
随着被占用位置的增多,出现这种情况的概率会不断上升,造成 " 堆积" 问题,这会严重降低哈希表效率。
二次探测
二次探测和线性探测很像,我们来看看它的核心公式就知道了:
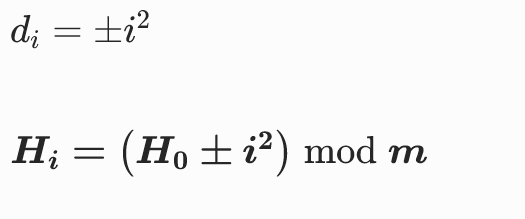
没错,二次探测只是在线性探测的基础上给它的步长设置为平方。这种 " 跳跃 " 的方法缓解了堆积问题,但是仍可能出现 " 二次堆积"。
双重散列
双重散列是**开放定址法里最优秀的一种。**它的步长设置根据 key 值的不同而变化:
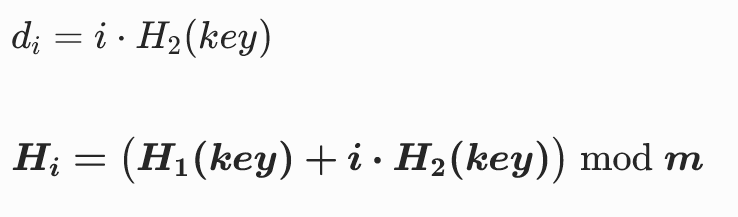
双重散列几乎无堆积,分布最均匀。
特殊问题
扩容
我们在哈希表的负载因子到 0.7 以后进行扩容。但这个扩容可不是随便扩的,我们需要保持哈希表的大小是一个质数,如果按照以前扩 2 倍的方法,扩容之后的大小就不是一个质数了。sgi版本的哈希表使用了一个近似二倍的质数表,每次取质数表中的数据作为扩容之后的大小。
key不能取模
当 key 是类似 string 这样不能取模的类型时,我们可以通过设计一个仿函数来把 key 转换为一个可以取模的整型。实现这个仿函数的要求是尽量让 key 的每一个值都参与到计算中,这样可以让转换出来的 key 不同,也不失为降低哈希冲突概率的一份力量。
链定址法
链定址法不再是往数组中直接插入值,而是挂载一条单链表。
当计算出相同的哈希值时,不需要往后占其他的位置,而是直接在该位置的链表上开位置存放,这解决了哈希冲突,也解决了堆积问题。
但是这又带来了别的问题,当你要查找的值所处的位置的链表过长,时间效率会退化到 O(n)。