论文信息
- 标题:Anchor DETR: Query Design for Transformer-Based Object Detection
- 会议:AAAI 2022
- 单位:MEGVII Technology(旷视科技)
- 代码:github.com/megvii-research/AnchorDETR
- 论文:https://arxiv.org/pdf/2109.07107.pdf
一、引言:DETR的查询黑盒之谜
DETR开创了Transformer端到端检测的极简范式,无Anchor、无NMS ,美得不像话。
但它有两个老大难问题:
- 查询不可解释:object query 是纯可学习向量,不知道它"负责看哪里"。
- 收敛极慢:要训 500 epoch,工业落地根本等不起。
根本原因:
每个查询没有明确的空间责任范围,全局乱看,优化难度极大。
于是旷视这篇 Anchor DETR 直接拍板:
让每个查询绑定一个锚点(anchor point),有明确的"地盘",学得又快又好!
效果直接拉满:
- 训练轮数从 500 → 50 epoch(提速 10 倍)
- R50-DC5 单尺度特征,AP 44.2%
- 速度 19 FPS,超过 DETR、Deformable DETR、Conditional DETR
- 还提出 RCDA 行列解耦注意力,省显存、无随机内存访问、硬件友好拉满
二、核心动机:让查询"有址可寻"
2.1 DETR 查询的乱象
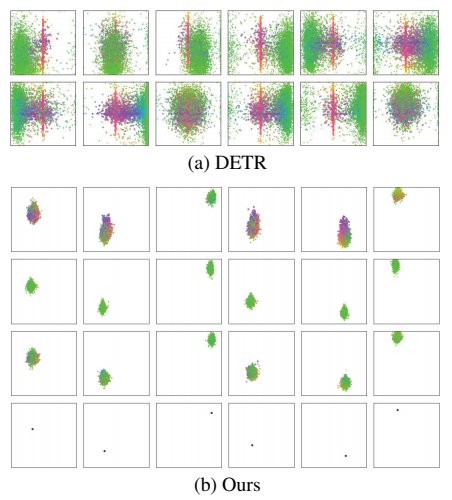
图 1:预测区域的可视化展示。请注意,子图(a)源自 DETR 图(Carion 等人,2020 年)。每个预测区域包含了查询值集上的所有框预测。每个有颜色的点代表一个预测的标准化中心位置。这些点通过颜色编码来区分,绿色代表小框,红色代表大水平框,蓝色代表大垂直框。子图(b)最后一行中的黑色点表示锚点。我们所提出的预测区域与特定位置的关系比 DETR 更紧密。
(a) DETR:每个查询的预测框散布全图,没有明确聚焦区域。
(b) Anchor DETR:每个查询的预测都紧紧围绕自己的锚点,职责清晰。
这就是位置模糊性:查询不知道自己该管哪儿,自然难训练。
2.2 解决方案:Anchor Point + Multi-Pattern
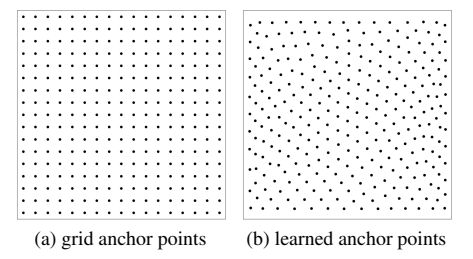
图 2:锚点分布的可视化展示。每个点都代表了一个锚点的标准化位置。
Anchor DETR 做了两件最关键的事:
- 查询 = 锚点编码:每个查询明确"我守这个点"。
- 一点多检测:一个锚点配多个 pattern,解决"同位置多物体"问题。
三、方法详解:全文精读无省略
3.1 总体架构
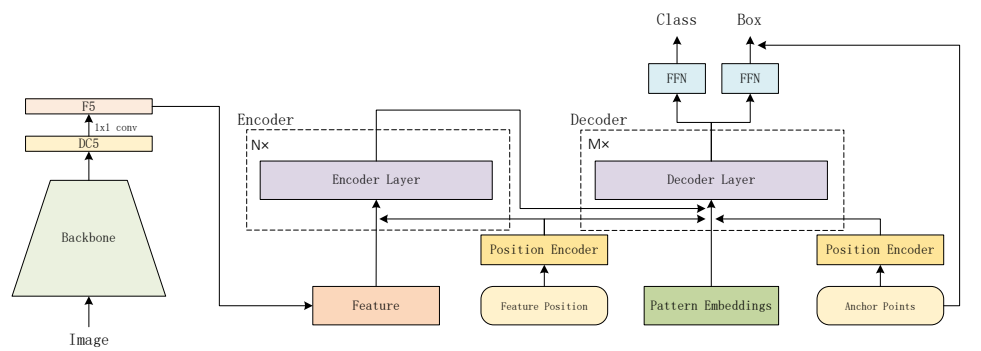
图 3:所提出探测器的流程图。请注意,编码器层和解码器层的结构与 DETR1 相同,只是我们在编码器层中替换掉了自注意力机制,在解码器层中替换掉了交叉注意力机制,改用了我们提出的"行列解耦注意力"机制。
流程:
Backbone → Encoder(带RCDA)→ Decoder(带Anchor查询+RCDA)→ FFN分类回归
创新点只有两个,但贯穿全文:
- 基于锚点+模式的查询设计
- 行列解耦注意力 RCDA
3.2 锚点与查询编码
(1)锚点定义
锚点就是图像上的坐标点:
Posq∈RNA×2Pos_q \in \mathbb{R}^{N_A \times 2}Posq∈RNA×2
- NAN_ANA:锚点数量
- 每个点存储 (x,y)(x,y)(x,y),归一化 0~1
支持两种锚点:
- 网格锚点:均匀铺在图上
- 可学习锚点:随机初始化,跟着训练一起学
(2)锚点 → 物体查询
把锚点坐标编码成查询位置嵌入:
Qp=Encode(Posq)Q_p = Encode(Pos_q)Qp=Encode(Posq)
最直接的方式就是和key共用编码函数:
Qp=g(Posq),Kp=g(Posk)Q_p = g(Pos_q),\quad K_p = g(Pos_k)Qp=g(Posq),Kp=g(Posk)
文章直接用 两层MLP 做编码,适配性更强。
3.3 Multi-Pattern:一點多檢測
一个位置可能叠多个物体(比如人抱小孩)。
于是给每个锚点配 Np 个模式向量,让一个点能出多个框。
最终查询数量:
Nq=Np×NAN_q = N_p \times N_ANq=Np×NA
- NpN_pNp:模式数(默认3)
- NAN_ANA:锚点数(默认300)
所有锚点共享同一组模式向量,保证平移不变性。
图片3(来自原文 Figure 4)
三个模式分别负责不同宽高比的物体,分工明确。
3.4 注意力公式回顾
DETR 标准注意力:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dk QKT)V
Q=Qf+Qp,K=Kf+KpQ=Q_f+Q_p,\quad K=K_f+K_pQ=Qf+Qp,K=Kf+Kp
- QfQ_fQf:查询内容特征
- QpQ_pQp:查询位置(本文=锚点编码)
- KfK_fKf:键内容
- KpK_pKp:键位置
3.5 RCDA:行列解耦注意力(超级硬核)
这是本文第二个大创新:把2D注意力拆成行注意力 + 列注意力。
为什么要拆?
标准注意力的内存消耗:
Nq×H×W×MN_q \times H \times W \times MNq×H×W×M
太高!
RCDA 先对 K 做全局池化,拆成:
- 行特征 Kf,x∈RW×CK_{f,x} \in \mathbb{R}^{W \times C}Kf,x∈RW×C
- 列特征 Kf,y∈RH×CK_{f,y} \in \mathbb{R}^{H \times C}Kf,y∈RH×C
然后先做行注意力 ,再做列注意力。
最终内存消耗从 O(HW)O(HW)O(HW) 降到 O(H+W)O(H+W)O(H+W),省显存、速度快、硬件友好,且不会引入随机内存访问。
四、核心公式与符号解释
4.1 锚点查询
Qp=Encode(Posq)Q_p = Encode(Pos_q)Qp=Encode(Posq)
- QpQ_pQp:物体查询(位置部分)
- PosqPos_qPosq:锚点坐标 (x,y)(x,y)(x,y)
- EncodeEncodeEncode:正弦编码 + MLP
4.2 多模式查询
QfinitQ_f^{init}Qfinit 由模式向量广播得到
- Nq=Np×NAN_q = N_p × N_ANq=Np×NA
- NpN_pNp:每个锚点的检测头数(模式数)
- NAN_ANA:锚点数量
4.3 RCDA 内存节省比
StandardRCDA=W×MC\frac{Standard}{RCDA} = \frac{W×M}{C}RCDAStandard=CW×M
- WWW:特征图宽
- MMM:头数
- CCC:通道数(默认256)
默认设置下可省2~4倍显存。
五、核心代码(PyTorch 风格)
python
# ==============================
# 1. 锚点编码 → 查询
# ==============================
def encode_anchor_points(anchor_points, out_dim=256):
# anchor_points: [B, N, 2] (x,y)
x, y = anchor_points.unbind(-1)
pos_x = positional_encoding(x, out_dim//2)
pos_y = positional_encoding(y, out_dim//2)
pos = torch.cat([pos_x, pos_y], dim=-1)
# MLP 编码
pos = mlp(pos)
return pos
# ==============================
# 2. 多模式 pattern 扩展
# ==============================
def multiply_pattern(anchor_embedding, pattern_embedding):
# anchor_embedding: [B, NA, C]
# pattern_embedding: [NP, C]
NA = anchor_embedding.shape[1]
NP = pattern_embedding.shape[0]
# 每个锚点复制 NP 个模式
q_pos = anchor_embedding.unsqueeze(2).repeat(1,1,NP,1)
q_feat = pattern_embedding.unsqueeze(0).repeat(1,NA,1,1)
# 合并成 [B, NA*NP, C]
q_pos = q_pos.flatten(1,2)
q_feat = q_feat.flatten(1,2)
return q_feat, q_pos
# ==============================
# 3. 行列解耦注意力 RCDA
# ==============================
class RowColumnDecoupledAttention(nn.Module):
def forward(self, q, k, v, q_pos=None, k_pos=None):
# 解耦行、列特征
k_row = k.mean(1) # [B, W, C]
k_col = k.mean(2) # [B, H, C]
# 行注意力
attn_row = torch.matmul(q, k_row.transpose(-2,-1))
out_row = torch.matmul(attn_row.softmax(-1), v)
# 列注意力
attn_col = torch.matmul(q, k_col.transpose(-2,-1))
out_col = torch.matmul(attn_col.softmax(-1), v)
# 融合
return out_row + out_col六、实验结果与深度分析
6.1 与Transformer检测模型对比
表格1(来自原文 Table 1)
| 模型 | 特征 | AP | FPS |
|---|---|---|---|
| DETR | DC5 | 43.3 | 12 |
| SMCA | multi | 43.7 | 10 |
| Deformable DETR | multi | 43.8 | 15 |
| Conditional DETR | DC5 | 43.8 | 10 |
| Anchor DETR | DC5 | 44.2 | 19 |
结论:
- 单尺度特征吊打多尺度
- 速度第一
- 50epoch 超过 DETR 500epoch
6.2 与主流检测器对比
表格2(来自原文 Table 2)
| 模型 | Epoch | AP |
|---|---|---|
| DETR-DC5 | 500 | 43.3 |
| Anchor DETR-DC5 | 50 | 44.2 |
真正意义上 速度、精度、收敛、成本全维度超越。
6.3 消融实验
表格3(来自原文 Table 3)
| RCDA | anchor | pattern | AP |
|---|---|---|---|
| 39.3 | |||
| ✅ | 42.6 | ||
| ✅ | 40.3 | ||
| ✅ | 40.3 | ||
| ✅ | ✅ | ✅ | 44.2 |
三个组件缺一不可,共同提升 4.9 AP!
七、全文总结(最精髓5句话)
- DETR慢的根源:查询无明确空间责任,注意力散乱难优化。
- Anchor DETR 解法 :查询=锚点编码,责任明确,收敛狂快。
- Multi-Pattern:一个锚点多模式,解决同位置多物体。
- RCDA 行列解耦注意力 :省显存、速度快、硬件友好。
- 最终效果:50epoch、单尺度、无NMS、无Anchor、AP 44.2%、FPS 19。
这篇是工业落地极其友好的一篇 DETR 改进,结构干净、速度快、收敛快、可解释强。