1. 一元线性回归 -- 正规方程法求解
(一元线性回归先对 k求偏导,再对b求偏导,将得到的两个式子进行计算,得到二元一次方程的解。不需要像前面的案例,对b进行假设(假设b=100))

2. 多元线性回归 -- 正规方程法求解

(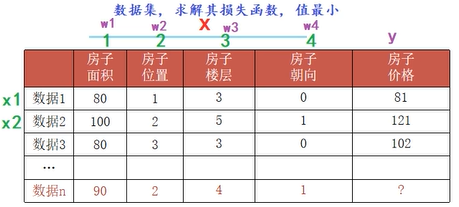 1️⃣ 图示:特征为x即横着,竖着的1234分别为x的几个特征列,横着的x1、x2...分别为数据1、数据2等第几条数据,每一列都有自己的系数w1、w2...:即w1是第1列的权重、w2是第二列的权重...;
1️⃣ 图示:特征为x即横着,竖着的1234分别为x的几个特征列,横着的x1、x2...分别为数据1、数据2等第几条数据,每一列都有自己的系数w1、w2...:即w1是第1列的权重、w2是第二列的权重...;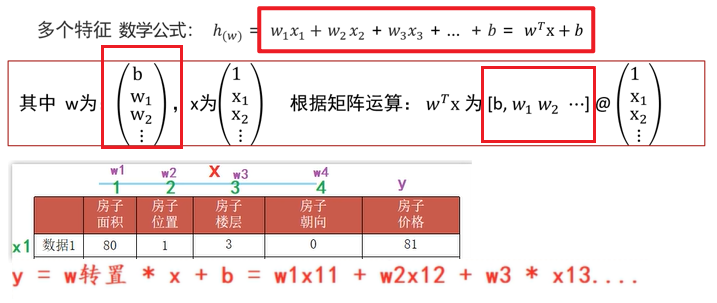
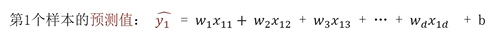 2️⃣ 第1个样本预测值: (即x1这行)数据的预测值(如图文字公式): y = w的转置 * x + b = w1乘以x1这一行的第一列即w1乘以11 + w2乘以x1这一行的第二列即w2乘以12 + w3 乘以 x1这一行的第三列即w3乘以13 + ...即可算出第一行(第1个样本)即x1这行数据的预测值;
2️⃣ 第1个样本预测值: (即x1这行)数据的预测值(如图文字公式): y = w的转置 * x + b = w1乘以x1这一行的第一列即w1乘以11 + w2乘以x1这一行的第二列即w2乘以12 + w3 乘以 x1这一行的第三列即w3乘以13 + ...即可算出第一行(第1个样本)即x1这行数据的预测值;

损失函数(如图公式)
3️⃣ 第1个样本的损失: (如图文字公式)符号:伊普西龙。等号前:(预测值 - 真实值)即误差,算平方;等号后:w1x11+w2x12+w3x13...,这是第一个样本的损失;(第二个样本的损失:w1x21+w2x22+w3x23+...wdx2d+b-y1再平方);式子变形:()括号内是预测值 减去 真实值y1,j表示当前样本的每一列特征: 从1开始,j=1时是第一列,j=2是第二列;d表示一共有d列特征;当前算出的是第一个样本的损失;第二个样本的损失:如图,1的位置换成2;第三个样本的对应位置换成3...多个,前面用∑,d代表一共有d列特征,j代表当前样本的每一列特征,i从1开始,到m结束,m代表一共有m个样本,此为多原线性回归的损失函数;
想让损失函数的值最小 即要对损失公式进行求导;"只要让多元线性回归损失函数取最小值,此时的权重W(w就是一个向量)就是最优解!" 为什么w就是一个向量?:假如有(w1, w2, w3, w4)4列特征,这4列可看作是Pandas中的Series对象,那么它充当的角色就是向量;)
2.1 损失函数普通方式转成矩阵方式

(可将损失函数的普通方式转为矩阵方式:损失J(w) = 第一个样本的预测h(x1) - 真实值y1)+ 第二个样本的预测h(x2) - 真实值y2 + ...+ 第m
个样本的预测h(xm) - 真实值ym == i从1开始到m个,()括号里面是(预测值-真实值)误差;等价于上面的公式:里面是wx的转置加上b;
铺垫知识:X的转置成语x = x范数的平方;证明:
①举例:L2范数:有一个元素坐标是(1, 2),求其向量模:x轴坐标为1,y轴坐标为2,模长为1的平方+2的平方,再开平方;即为2范数。假设元素坐标为(1, 2, -3),模长为1方+2方+3方,再开平方根;即为2范数。
如不开平方根,则为2范数的平方;②举例 X的转置 * X:例如有一个x(1, 2, -3), x的转置乘以x:对应11 + 2 2 + (-3)* (-3)。
(x的转置)可写成X乘以w减去y。求公式的最小值即针对w进行求导,因为x代表特征、y代表标签,将公式看作一个复杂函数求导(先对外求导,再对内求导):得到第(1)步,在第(2)步:两边都乘以x的转置---(3)假设逆存在,两边都乘以(x的转置x)的逆(矩阵乘以矩阵的逆矩阵得到单位矩阵,单位矩阵就是1)---(4)消掉2
---(6)两边都乘以x的转置---(7)再乘以(x的转置x)的逆...)
2.2 解释为啥转换时是Xw?
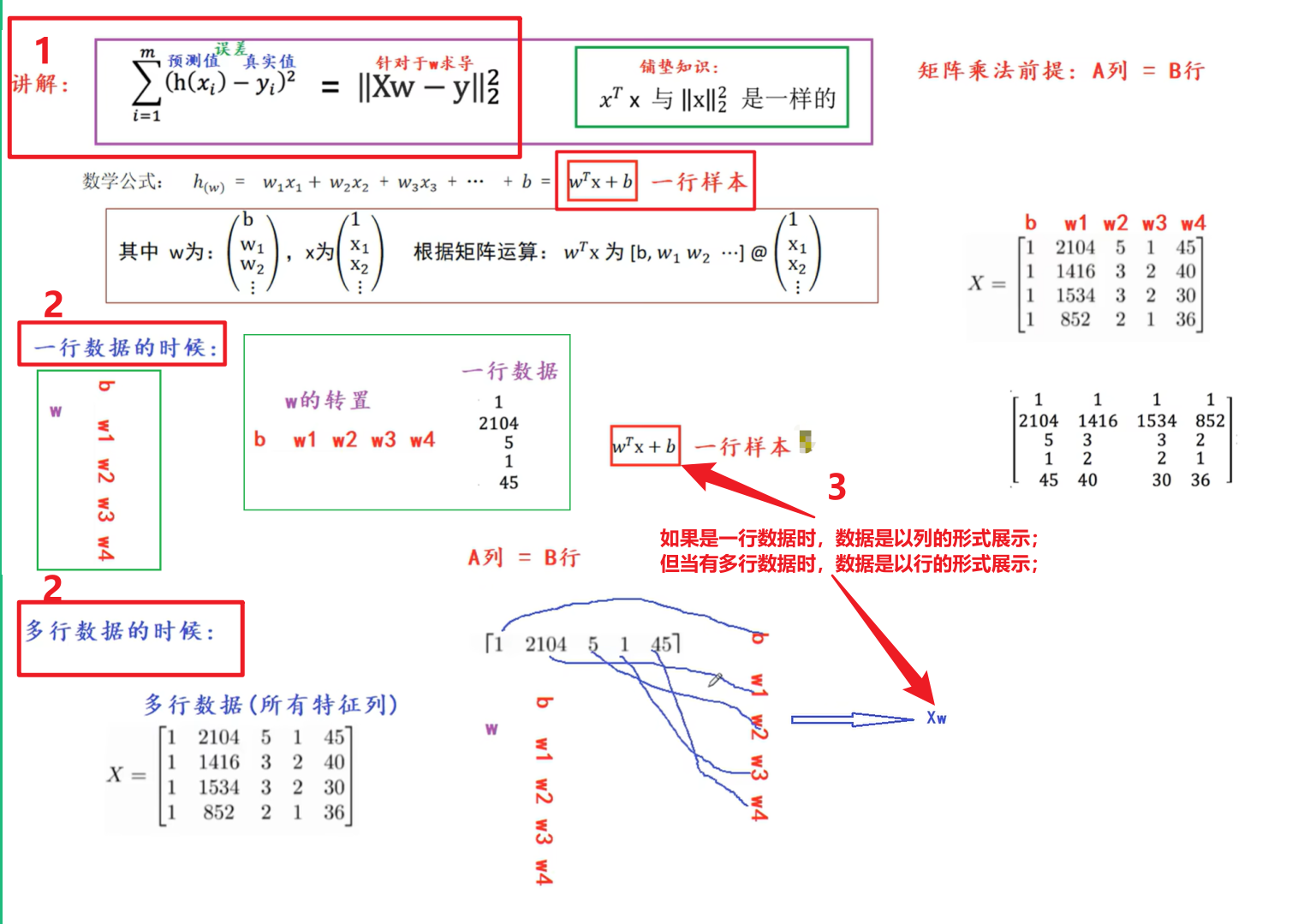
(在python中没有行的概念,一行数据是以列的形式来展示的;如图正常每列都有数据从x(1)~x(4)(正常没有x(0)是为了y=wx+b的b保留的),每一列都有对应的系数w1 ~ w4,前面补了一列x0、列值都是1。
图中的数学公式w的转置*x+b算的是一行数据,不是多行数据;对于多行数据:之前pandas的Series、DataFrame中一行样本展示时是以列的形式展示的。因此w系数这一行、以及x数据行都是以列的形式展示的(都是列竖着),两者无法进行相乘(因为矩阵乘法的前提是:A列=B行,这种情况才能相乘),因为有1列多行所以无法相乘;所以如果是一行数据的情况下,数据是以列的形式展示 ,将 系数w转置 * 1列数据 满足A列=B行,可以相乘;但当有多行数据时,数据是以行的形式展示:w还是1列展示,但是x有多行数据,此时不满足A列=B行,无法进行相乘;此时可将X放左边,w放右边,满足A列=B行即5列=5行,此时可以相乘:X的每一行去乘以w的列、即多列特征*w系数 可写成 Xw)
2.3 损失函数普通方式转成矩阵方式 带入参数计算:
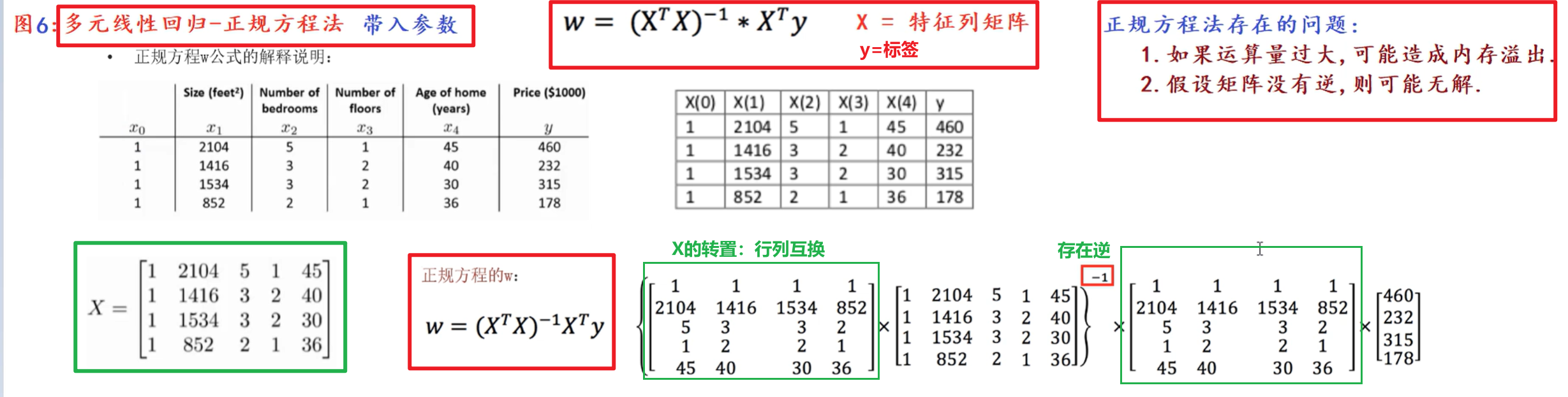
3. 总结:
3.1 用正规方程求解时:
① 对于一元函数 ,有两个一元线性回归公式计算结果;
② 对于多元函数 :推到过程中逆一定得是存在的,如果逆不存在,式子无法推导出;
所以正规方程这种方式有弊端。此时有另一种方式:梯度下降。
3.2 正规方程和梯度下降两种方式的目的:
都是为了让损失函数的值最小,意味着误差和最小,意味着算法的效率越高。