工作流程
大语言模型 重排序器 Milvus Elasticsearch 应用程序 用户 大语言模型 重排序器 Milvus Elasticsearch 应用程序 用户 1. 数据索引阶段 2. 用户查询与检索阶段 par 并行检索 3. 融合与重排序 4. 生成回答 文档切块(Chunking) 调用 Embedding 模型 存储文本块与嵌入向量 存储文本块与嵌入向量 输入问题(Query) 调用 Embedding 模型 关键词检索 返回相关文本块 (BM25) 向量检索 返回相关文本块 (语义) 融合结果 (RRF/加权) 调用 Reranker 模型 返回重排序后的Top-K结果 构建提示词(Prompt) + 上下文 生成最终回答 返回回答
ollam+llm
[安装参考](https://blog.csdn.net/wenwang3000/article/details/145705858)这里需要2种类型的

milvus安装
参考:https://milvus.io/docs/zh 线上环境采用集群版本,这里只做演示配 配置轻量版本 Milvus Lite
shell
#安装 pymilvus 客户端
pip install pymilvus
#安装 milvus 服务端包
pip install milvus
#启动 Milvus 本地服务
milvus-server --data D:\logs\milvus_data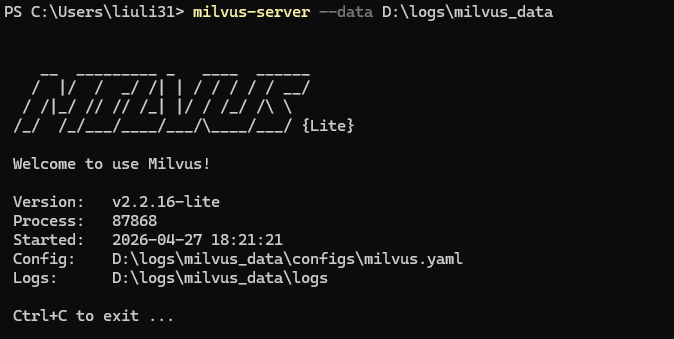
milvus客户端工具
参考:https://github.com/zilliztech/attu/blob/main/README_CN.md
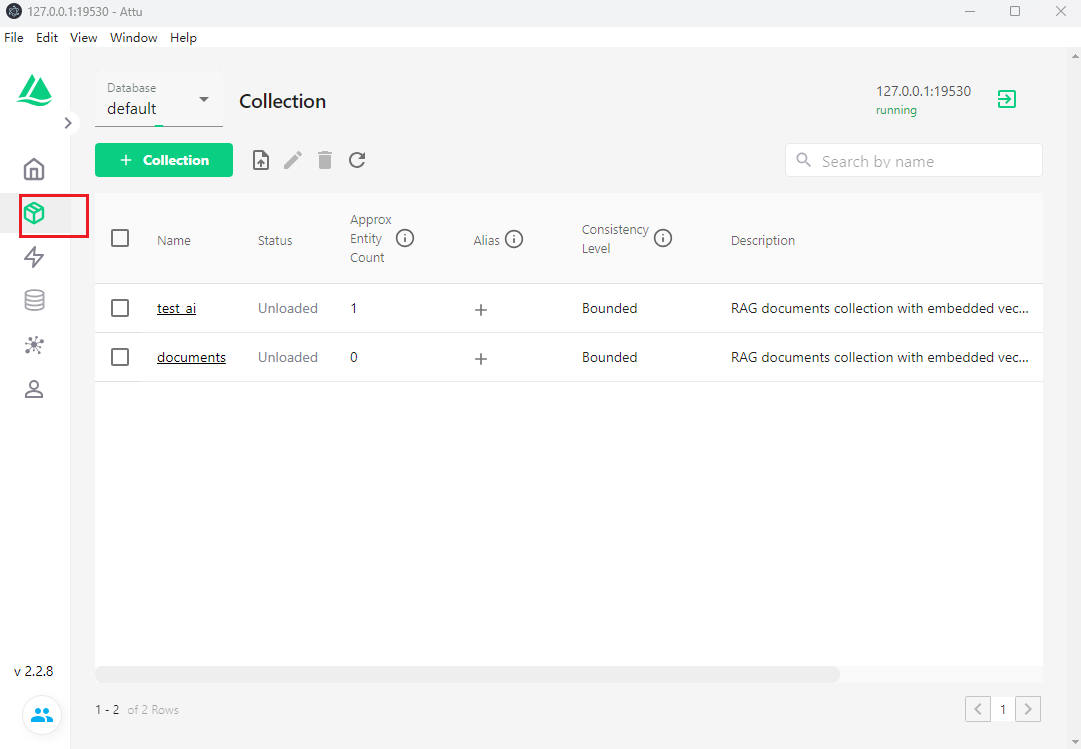
collection
elasticsearch安装
[集群配置参考](https://blog.csdn.net/wenwang3000/article/details/99820920),这里受环境限制配置单节点
配置
shell
# 配置项
cluster.name: es8
node.name: node1
path.data: D:\DataBase\elasticsearch-8.19.14\data
path.logs: D:\DataBase\elasticsearch-8.19.14\logs
network.host: 127.0.0.1
http.port: 9200
discovery.type: single-node
xpack.security.enabled: false
http.cors.enabled: true
http.cors.allow-origin: "*"ik分词器
java
#安装 ik分词器 插件
cd D:\DataBase\elasticsearch-8.19.14\plugins
.\elasticsearch-plugin install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-8.19.14.zip
启动服务
java
# 启动服务 不带任何参数) 打开浏览器,访问 http://localhost:9200
elasticsearch.bat(不带任何参数)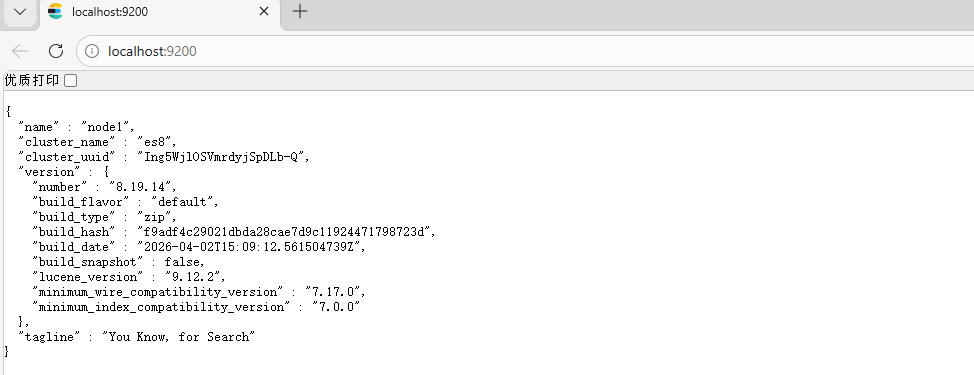
elasticsearch客户端工具
轻量、现代化的Web UI;可作为浏览器插件一键安装,极客风,支持REST API调试 https://github.com/cars10/elasticvue
浏览器插件版本:
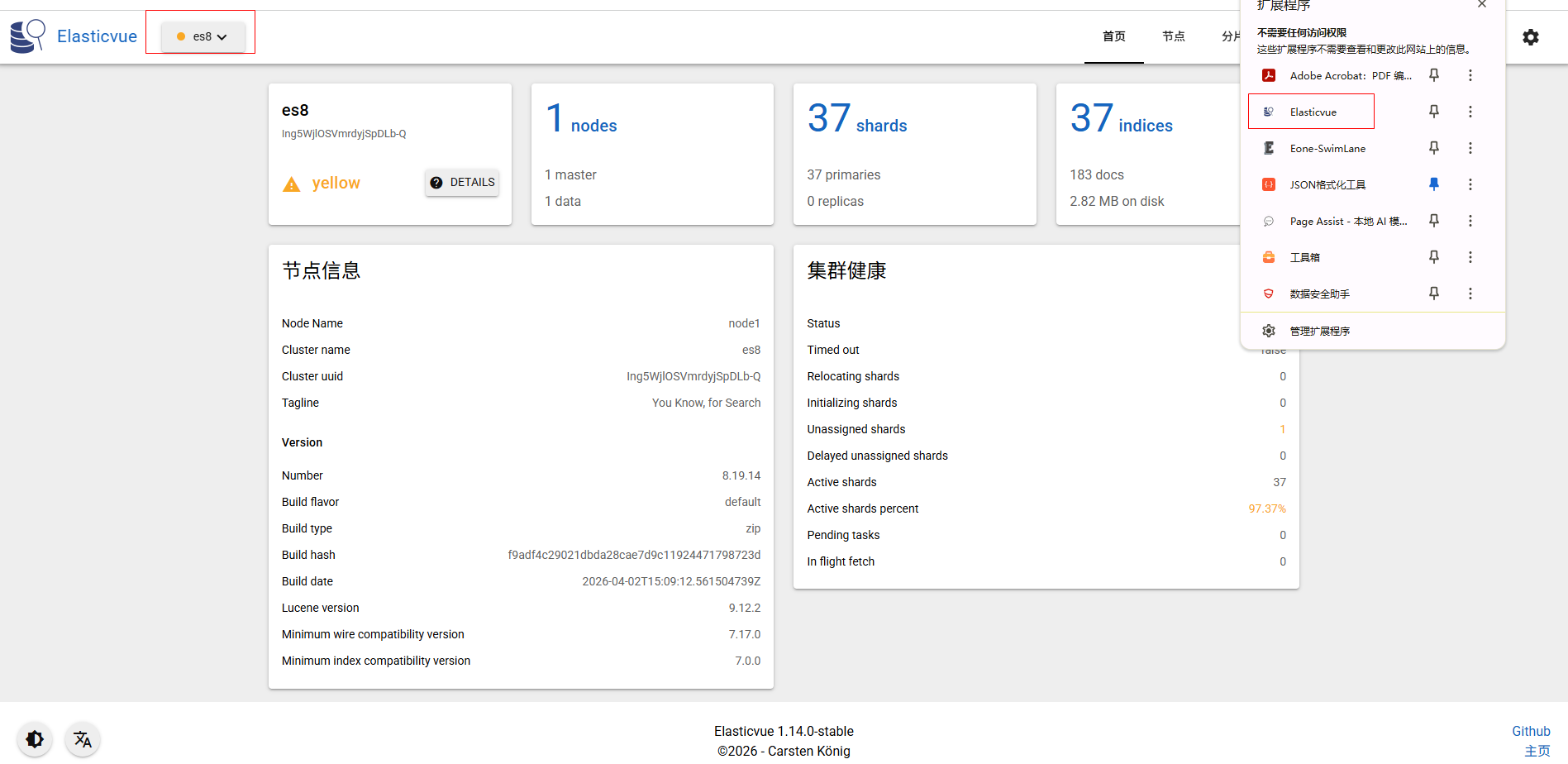
展示效果
核心代码(java版本)
jar依赖
java
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.9</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.spring.cloud.admin</groupId>
<artifactId>com-spring-ai</artifactId>
<version>1.0</version>
<name>com-spring-ai</name>
<description>admin</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>17</java.version>
<spring-ai.version>1.0.0</spring-ai.version>
<elasticsearch-java.version>8.12.0</elasticsearch-java.version>
<milvus-sdk-java.version>2.6.18</milvus-sdk-java.version>
<commons-lang3.version>3.7</commons-lang3.version>
<alibaba-fastjson.version>1.2.58</alibaba-fastjson.version>
<org-projectlombok.version>1.18.44</org-projectlombok.version>
<jackson.version>2.15.3</jackson.version>
<langchain4j.version>1.13.1</langchain4j.version>
</properties>
<dependencies>
<!-- LangChain4j core + OpenAI -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- LangChain4j Ollama 集成 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- 文档解析器(支持 PDF/Word/HTML 等) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Apache Commons Compress - 修复 Tika ZIP 处理问题 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.26.0</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<!-- Spring AI -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!--<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>-->
<!-- Elasticsearch Java Client -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>${elasticsearch-java.version}</version>
</dependency>
<!-- Milvus Java SDK -->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>${milvus-sdk-java.version}</version>
</dependency>
<!-- Jackson for JSON -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<!--common-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons-lang3.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${alibaba-fastjson.version}</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
<version>${org-projectlombok.version}</version>
</dependency>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>yml配置
java
server:
port: 8080
servlet:
# 项目contextPath
context-path: /
spring:
application:
name: ai
#ai
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: qwen3.5:2b
temperature: 0.7
embedding:
options:
model: qwen3-embedding:0.6b
autoconfigure:
exclude:
- org.springframework.boot.autoconfigure.data.elasticsearch.ElasticsearchDataAutoConfiguration
- org.springframework.boot.autoconfigure.data.elasticsearch.ElasticsearchRepositoriesAutoConfiguration
# Elasticsearch Configuration
elasticsearch:
host: localhost
port: 9200
scheme: http
username:
password:
index:
name: documents
# Milvus Configuration
milvus:
host: localhost
port: 19530
db-name: test
collection:
name: test_ai
index:
type: IVF_FLAT
metric-type: IP
embedding-dimension: 1024
search.top: 2
logging:
level:
com.example: DEBUG服务入口
java
package com.controller;
import com.ai.rag.bean.AskRequest;
import com.ai.rag.bean.DocumentChunk;
import com.ai.rag.bean.FIleInfo;
import com.ai.rag.service.DocumentChunkService;
import com.ai.rag.service.RagQueryService;
import com.alibaba.fastjson.JSONObject;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.*;
/**
┌─────────────────────────────────────────────────────────────────────┐
│ Spring Boot Application │
├─────────────────────────────────────────────────────────────────────┤
│ API Layer │
├─────────────────────────────────────────────────────────────────────┤
│ DocumentService │
│ (双写入库核心调度层) │
├─────────────────────────────────────────────────────────────────────┤
│ EmbeddingService │
│ (Ollama Chunk + 向量转换) │
├───────────────────────────────────┬─────────────────────────────────┤
│ ElasticsearchService │ MilvusService │
│ (全文检索 + 文本存储) │ (向量检索 + 向量存储) │
├───────────────────────────────────┴─────────────────────────────────┤
│ VectorStore │
│ (双写入库事务/补偿机制) │
└─────────────────────────────────────────────────────────────────────┘
*/
@Slf4j
@RestController
@RequestMapping("/api/rag")
public class RagController {
private final DocumentChunkService documentChunkService;
private final RagQueryService ragQueryService;
public RagController(DocumentChunkService documentChunkService,
RagQueryService ragQueryService) {
this.documentChunkService = documentChunkService;
this.ragQueryService = ragQueryService;
}
/**
* 全文检索接口
*/
@GetMapping("/search/text")
public ResponseEntity<List<DocumentChunk>> textSearch(@RequestParam String query,
@RequestParam(defaultValue = "10") int limit) {
return ResponseEntity.ok(ragQueryService.getSearchResults(query, limit));
}
/**
* 混合检索接口
*/
@GetMapping("/search/hybrid/{topK}")
public ResponseEntity<List<DocumentChunk>> hybridSearch(
@RequestParam String query,
@PathVariable(required = false) Integer topK) {
int finalTopK = (topK != null) ? topK : 10;
return ResponseEntity.ok(ragQueryService.hybridSearch(query, topK));
}
/**
* RAG 问答接口
*/
@PostMapping("/ask")
public ResponseEntity<Map<String, String>> askQuestion(@RequestBody AskRequest request) {
log.info("askQuestion-入参{}", JSONObject.toJSONString(request));
String answer = ragQueryService.askQuestion(request.getQuestion());
Map<String, String> response = new HashMap<>();
response.put("question", request.getQuestion());
response.put("answer", answer);
return ResponseEntity.ok(response);
}
@RequestMapping("/tikaDocument")
public String tikaDocument(@RequestBody FIleInfo fIleInfo) {
log.info("tikaDocument-入参{}", JSONObject.toJSONString(fIleInfo));
/**
* 基于Apache Tika 技术实现,支持自动检测和解析超过 1000 种文件格式。
*可处理 PDF、DOC/DOCX、PPT/PPTX、XLS/XLSX、HTML、EPUB、ZIP(内含文档)等主流办公与结构化文档格式
* 统一文本提取:将异构文档转换为标准化的纯文本,便于后续 AI 处理(如 RAG、知识库构建、文档分类等)
* 元数据保留:自动提取作者、创建日期、MIME 类型等结构化信息
*Spring 生态集成:作为 DocumentReader 接口的实现,可无缝接入 Spring AI 的文档处理流水线
*/
TikaDocumentReader reader = new TikaDocumentReader(fIleInfo.getUrl());
/**
* * PagePdfDocumentReader - 按页面读取PDF文档,适合需要分页处理的场景
* * ParagraphPdfDocumentReader - 按段落读取PDF文档,保持文档的逻辑结构
*/
//PagePdfDocumentReader reader = new PagePdfDocumentReader(fIleInfo.getUrl());
/**
* Spring AI 提供的按 Token 精确切分长文本的工具,核心用于 RAG 场景,把超长文档切分成符合大模型上下文限制的小块,同时保证语义连贯
* 精确按 Token 计数,底层集成专业分词器,安全适配模型要求
* int defaultChunkSize = 800, // 每块最大 Token 数
* int chunkOverlap = 160, // 块间重叠 Token 数(默认 20%)
* int minChunkSizeChars = 350, // 每块最小字符数
* int minChunkLengthToEmbed = 5, // 可嵌入的最小长度
* int maxNumChunks = 10000, // 最大分块数
* boolean keepSeparator = true // 保留分隔符(换行/句号)
*/
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> documents = splitter.apply(reader.read());
log.info("tikaDocument-分割结果:{}", documents.size());
List<DocumentChunk> chunks = new ArrayList<>();
for (int i = 0; i < documents.size(); i++) {
DocumentChunk chunk = DocumentChunk.builder()
.id(documents.get(i).getId())
.documentId(fIleInfo.getDocumentId())
.content(documents.get(i).getText())
.title(fIleInfo.getTitle())
.author(fIleInfo.getAuthor())
.category(fIleInfo.getCategory())
.chunkIndex(i)
.createdAt(new Date())
.updatedAt(new Date())
.totalChunks(documents.size())
.build();
chunks.add(chunk);
}
if (chunks.size() >0){
documentChunkService.batchDualWriteDocumentChunks(chunks);
}
return "ok";
}
}基础服务
milvus服务
java
package com.ai.rag.service;
import com.ai.rag.bean.DocumentChunk;
import com.ai.rag.constant.FiledEnums;
import io.milvus.client.MilvusServiceClient;
import io.milvus.grpc.DataType;
import io.milvus.grpc.MutationResult;
import io.milvus.grpc.SearchResults;
import io.milvus.param.*;
import io.milvus.param.collection.*;
import io.milvus.param.dml.DeleteParam;
import io.milvus.param.dml.InsertParam;
import io.milvus.param.dml.SearchParam;
import io.milvus.param.index.CreateIndexParam;
import io.milvus.response.QueryResultsWrapper;
import io.milvus.response.SearchResultsWrapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import jakarta.annotation.PostConstruct;
import java.util.*;
import java.util.stream.Collectors;
@Slf4j
@Service
public class MilvusService {
@Value("${milvus.host}")
private String milvusHost;
@Value("${milvus.port}")
private int milvusPort;
@Value("${milvus.db-name}")
private String dbName;
@Value("${milvus.collection.name}")
private String collectionName;
@Value("${milvus.index.type}")
private String indexType;
@Value("${milvus.index.metric-type}")
private String metricType;
@Value("${milvus.index.embedding-dimension}")
private Integer embeddingDim;
private MilvusServiceClient milvusClient;
@PostConstruct
public void init() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(milvusHost)
.withPort(milvusPort)
.withDatabaseName(dbName)
.build();
milvusClient = new MilvusServiceClient(connectParam);
log.info("Connected to Milvus at {}:{}", milvusHost, milvusPort);
// 创建集合(如果不存在)
createCollectionIfNotExists();
}
private void createCollectionIfNotExists() {
// 检查集合是否存在
R<Boolean> hasCollectionRes = milvusClient.hasCollection(
HasCollectionParam.newBuilder()
.withCollectionName(collectionName)
.build()
);
if (hasCollectionRes.getData()) {
log.info("Milvus collection already exists: {}", collectionName);
return;
}
// 定义字段结构
List<FieldType> fieldTypes = Arrays.asList(
FieldType.newBuilder()
.withName(FiledEnums.id.getCode())
.withDataType(DataType.VarChar)
.withMaxLength(255)
.withPrimaryKey(true)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.documentId.getCode())
.withDataType(DataType.VarChar)
.withMaxLength(255)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.content.getCode())
.withDataType(DataType.VarChar)
.withMaxLength(65535)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.title.getCode())
.withDataType(DataType.VarChar)
.withMaxLength(255)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.author.getCode())
.withDataType(DataType.VarChar)
.withMaxLength(255)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.category.getCode())
.withDataType(DataType.VarChar)
.withMaxLength(255)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.chunkIndex.getCode())
.withDataType(DataType.Int32)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.totalChunks.getCode())
.withDataType(DataType.Int32)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.createdAt.getCode())
.withDataType(DataType.Int64)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.updatedAt.getCode())
.withDataType(DataType.Int64)
.build(),
// 2.6+版本才支持
/* FieldType.newBuilder()
.withName(FiledEnums.createdAt.getCode())
.withDataType(DataType.Timestamptz)
.build(),
FieldType.newBuilder()
.withName(FiledEnums.updatedAt.getCode())
.withDataType(DataType.Timestamptz)
.build(),*/
FieldType.newBuilder()
.withName(FiledEnums.embedding.getCode())
.withDataType(DataType.FloatVector)
.withDimension(embeddingDim)
.build()
);
CreateCollectionParam createParam = CreateCollectionParam.newBuilder()
.withCollectionName(collectionName)
.withDescription("测试db双写")
.withFieldTypes(fieldTypes)
.build();
R<RpcStatus> res = milvusClient.createCollection(createParam);
if (res.getStatus() == R.Status.Success.getCode()) {
log.info("Created Milvus collection: {}", collectionName);
createIndex();
} else {
log.error("Failed to create Milvus collection: {}", res.getMessage());
}
}
/**
* 使用 IVF_FLAT 索引类型时,必须在 extraParam 中提供 nlist 参数,该参数控制了向量空间划分的簇数量。
*/
private void createIndex() {
// 定义索引参数
CreateIndexParam indexParam = CreateIndexParam.newBuilder()
.withCollectionName(collectionName)
.withFieldName(FiledEnums.embedding.getCode())
.withIndexType(IndexType.valueOf(indexType))
.withMetricType(MetricType.valueOf(metricType))
.withExtraParam("{\"nlist\":" + embeddingDim + "}")
.build();
R<RpcStatus> res = milvusClient.createIndex(indexParam);
if (res.getStatus() == R.Status.Success.getCode()) {
log.info("Created index on collection: {} with type {}", collectionName, indexType);
// 加载集合到内存
LoadCollectionParam loadParam = LoadCollectionParam.newBuilder()
.withCollectionName(collectionName)
.build();
milvusClient.loadCollection(loadParam);
log.info("Loaded collection: {} into memory", collectionName);
} else {
log.error("Failed to create index: {}", res.getMessage());
}
}
/**
* 批量插入文档块
*/
public boolean batchInsertDocumentChunks(List<DocumentChunk> chunks) {
if (chunks.isEmpty()) return true;
try {
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field(FiledEnums.id.getCode(), chunks.stream().map(DocumentChunk::getId)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.documentId.getCode(), chunks.stream().map(DocumentChunk::getDocumentId)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.content.getCode(), chunks.stream().map(DocumentChunk::getContent)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.category.getCode(), chunks.stream().map(DocumentChunk::getCategory)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.title.getCode(), chunks.stream().map(DocumentChunk::getTitle)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.author.getCode(), chunks.stream().map(DocumentChunk::getAuthor)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.chunkIndex.getCode(), chunks.stream().map(DocumentChunk::getChunkIndex)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.totalChunks.getCode(), chunks.stream().map(DocumentChunk::getTotalChunks)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.embedding.getCode(), chunks.stream().map(DocumentChunk::getEmbedding)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.createdAt.getCode(), chunks.stream()
.map(chunk -> chunk.getCreatedAt() != null ? chunk.getCreatedAt().getTime() : System.currentTimeMillis())
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.updatedAt.getCode(), chunks.stream()
.map(chunk -> chunk.getUpdatedAt() != null ? chunk.getUpdatedAt().getTime() : System.currentTimeMillis())
.collect(Collectors.toList())));
// 2.6+版本才支持
/* fields.add(new InsertParam.Field(FiledEnums.createdAt.getCode(), chunks.stream().map(DocumentChunk::getCreatedAt)
.collect(Collectors.toList())));
fields.add(new InsertParam.Field(FiledEnums.updatedAt.getCode(), chunks.stream().map(DocumentChunk::getUpdatedAt)
.collect(Collectors.toList())));*/
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(collectionName)
.withFields(fields)
.build();
R<MutationResult> res = milvusClient.insert(insertParam);
if (res.getStatus() == R.Status.Success.getCode()) {
log.info("Batch inserted {} chunks to Milvus", chunks.size());
return true;
} else {
log.error("Failed to batch insert to Milvus: {}", res.getMessage());
return false;
}
} catch (Exception e) {
log.error("Exception during Milvus batch insert", e);
return false;
}
}
/**
* 根据ID删除文档块
*/
public boolean deleteDocumentChunk(String id) {
try {
String expr = String.format("id == \"%s\"", id);
DeleteParam deleteParam = DeleteParam.newBuilder()
.withCollectionName(collectionName)
.withExpr(expr)
.build();
R<MutationResult> res = milvusClient.delete(deleteParam);
if (res.getStatus() == R.Status.Success.getCode()) {
log.debug("Document deleted from Milvus: {}", id);
return true;
} else {
log.error("Failed to delete from Milvus: {}", res.getMessage());
return false;
}
} catch (Exception e) {
log.error("Exception during Milvus delete", e);
return false;
}
}
/**
* 向量相似度搜索
*/
public List<DocumentChunk> searchByVector(List<Float> queryVector, int topK) {
try {
List<String> outputFields = Arrays.asList("id", "documentId", "content",
"title", "category", "chunkIndex");
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(collectionName)
.withVectorFieldName(FiledEnums.embedding.getCode())
.withVectors(Arrays.asList(queryVector))
.withTopK(topK)
.withMetricType(MetricType.valueOf(metricType))
// nlist = 1024(索引时划分的簇数) nprobe = 10(搜索时检查的簇数) 比例 = 10/1024 ≈ 1%
// 只搜索约 1% 的向量空间 如果发现搜索结果不够准确,可以适当增加 nprobe:
.withParams("{\"nprobe\":10}")
/** 做权限过滤 .withExpr("")
* // 1. 等于
* "author == \"admin\""
* // 2. 不等于
* "author != \"guest\""
* // 3. 大于/小于(数值类型)
* "createdAt > 1700000000000"
* // 4. IN 操作
* "category in [\"tech\", \"science\"]"
* // 5. NOT IN
* "category not in [\"private\", \"confidential\"]"
* // 6. AND/OR 组合
* "(author == \"admin\" || category == \"public\") && createdAt > 1700000000000"
* // 7. LIKE 模糊匹配(VarChar 字段)
* "title like \"AI%\""
* // 8. 范围查询
* "createdAt >= 1700000000000 && createdAt <= 1710000000000"
*/
.withOutFields(outputFields)
.build();
R<SearchResults> res = milvusClient.search(searchParam);
if (res.getStatus() == R.Status.Success.getCode()) {
SearchResultsWrapper wrapper = new SearchResultsWrapper(res.getData().getResults());
List<DocumentChunk> results = new ArrayList<>();
for (QueryResultsWrapper.RowRecord record : wrapper.getRowRecords()) {
DocumentChunk chunk = DocumentChunk.builder()
.id((String)record.get("id"))
.documentId((String) record.get("documentId"))
.content((String) record.get("content"))
.title((String) record.get("title"))
.category((String) record.get("category"))
.chunkIndex((Integer) record.get("chunkIndex"))
.build();
results.add(chunk);
}
return results;
} else {
log.error("Failed to search in Milvus: {}", res.getMessage());
return new ArrayList<>();
}
} catch (Exception e) {
log.error("Exception during Milvus search", e);
return new ArrayList<>();
}
}
}es服务
java
package com.ai.rag.service;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch._types.mapping.Property;
import co.elastic.clients.elasticsearch.core.*;
import co.elastic.clients.elasticsearch.core.search.Hit;
import co.elastic.clients.elasticsearch.indices.CreateIndexRequest;
import co.elastic.clients.elasticsearch.indices.ExistsRequest;
import co.elastic.clients.elasticsearch.indices.IndexSettings;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.ai.rag.bean.DocumentChunk;
import com.ai.rag.constant.FiledEnums;
import jakarta.annotation.PostConstruct;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@Service
public class ElasticsearchService {
@Value("${elasticsearch.host}")
private String esHost;
@Value("${elasticsearch.port}")
private int esPort;
@Value("${elasticsearch.scheme}")
private String esScheme;
@Value("${elasticsearch.username}")
private String esUsername;
@Value("${elasticsearch.password}")
private String esPassword;
@Value("${elasticsearch.index.name}")
private String indexName;
private ElasticsearchClient esClient;
@Value("${milvus.index.embedding-dimension}")
private Integer embeddingDim;
@PostConstruct
public void init() throws IOException {
RestClient restClient = buildRestClient();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper()
);
this.esClient = new ElasticsearchClient(transport);
// 创建索引(如果不存在)
createIndexIfNotExists();
}
private RestClient buildRestClient() {
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
if (esUsername != null && !esUsername.isEmpty()) {
credentialsProvider.setCredentials(
AuthScope.ANY,
new UsernamePasswordCredentials(esUsername, esPassword)
);
}
return RestClient.builder(
new HttpHost(esHost, esPort, esScheme)
).setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
).build();
}
/**
* Mapping 理解为索引的"蓝图"或"表结构",它定义了每个字段的数据类型、是否被索引、如何被分析等关键属性
* @throws IOException
*/
private void createIndexIfNotExists() throws IOException {
ExistsRequest existsRequest = ExistsRequest.of(e -> e.index(indexName));
boolean exists = esClient.indices().exists(existsRequest).value();
if (!exists) {
CreateIndexRequest createIndexRequest = CreateIndexRequest.of(i -> i
.index(indexName)
.settings(IndexSettings.of(s -> s
.numberOfShards("1")
.numberOfReplicas("1")
))
.mappings(m -> m
.properties(FiledEnums.id.getCode(), Property.of(p -> p.keyword(k -> k)))
.properties(FiledEnums.documentId.getCode(), Property.of(p -> p.keyword(k -> k)))
.properties(FiledEnums.content.getCode(), Property.of(p -> p.text(t -> t
.analyzer("ik_max_word") //最细粒度分词(索引时使用)
.searchAnalyzer("ik_smart") //智能分词(搜索时使用)
)))
.properties(FiledEnums.title.getCode(), Property.of(p -> p.text(t -> t
.analyzer("ik_max_word") //最细粒度分词(索引时使用)
.searchAnalyzer("ik_smart") //智能分词(搜索时使用)
)))
.properties(FiledEnums.author.getCode(), Property.of(p -> p.text(t -> t
.analyzer("ik_max_word") //最细粒度分词(索引时使用)
.searchAnalyzer("ik_smart") //智能分词(搜索时使用)
)))
.properties(FiledEnums.category.getCode(), Property.of(p -> p.text(t -> t)))
.properties(FiledEnums.embedding.getCode(), Property.of(p -> p.denseVector(t -> t.dims(embeddingDim))))
.properties(FiledEnums.chunkIndex.getCode(), Property.of(p -> p.integer(t -> t)))
.properties(FiledEnums.totalChunks.getCode(), Property.of(p -> p.integer(t -> t)))
.properties(FiledEnums.createdAt.getCode(), Property.of(p -> p.date(t -> t)))
.properties(FiledEnums.updatedAt.getCode(), Property.of(p -> p.date(t -> t)))
)
);
esClient.indices().create(createIndexRequest);
log.info("Created Elasticsearch index: {}", indexName);
}
}
/**
* 批量插入文档块
*/
public boolean batchInsertDocumentChunks(List<DocumentChunk> chunks) {
try {
var bulkRequest = BulkRequest.of(b -> {
b.index(indexName);
for (DocumentChunk chunk : chunks) {
b.operations(op -> op
.index(idx -> idx
.id(chunk.getId())
.document(chunk)
)
);
}
return b;
});
BulkResponse response = esClient.bulk(bulkRequest);
if (response.errors()) {
log.error("Bulk insert to ES had errors");
return false;
}
log.info("Batch inserted {} chunks to Elasticsearch", chunks.size());
return true;
} catch (IOException e) {
log.error("Failed to batch insert document chunks to Elasticsearch", e);
return false;
}
}
/**
* 全文搜索
*/
public List<DocumentChunk> search(String query, int limit) {
try {
SearchResponse<DocumentChunk> response = esClient.search(s -> s
.index(indexName)
.query(q -> q
.match(m -> m
.field("content")
.query(query)
)
)
.size(limit),
DocumentChunk.class
);
List<DocumentChunk> results = new ArrayList<>();
for (Hit<DocumentChunk> hit : response.hits().hits()) {
if (hit.source() != null) {
results.add(hit.source());
}
}
return results;
} catch (IOException e) {
log.error("Failed to search in Elasticsearch", e);
return new ArrayList<>();
}
}
}向量化服务
java
package com.ai.rag.service;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@Service
public class OllamaEmbeddingService {
@Value("${spring.ai.ollama.base-url}")
private String ollamaBaseUrl;
@Value("${spring.ai.ollama.embedding.options.model}")
private String embeddingModel;
private final HttpClient httpClient;
private final ObjectMapper objectMapper;
public OllamaEmbeddingService() {
this.httpClient = HttpClient.newHttpClient();
this.objectMapper = new ObjectMapper();
}
/**
* 生成单个文本的 Embedding 向量
*/
public List<Float> generateEmbedding(String text) {
try {
String requestBody = String.format(
"{\"model\":\"%s\",\"input\":\"%s\"}",
embeddingModel,
escapeJson(text)
);
// log.info("Ollama embedding request: {}", requestBody);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(ollamaBaseUrl + "/api/embed"))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(requestBody))
.build();
HttpResponse<String> response = httpClient.send(request,
HttpResponse.BodyHandlers.ofString());
// log.info("Ollama embedding response: {}", response.body());
if (response.statusCode() == 200) {
JsonNode jsonNode = objectMapper.readTree(response.body());
JsonNode embeddings = jsonNode.get("embeddings");
if (embeddings != null && embeddings.isArray() && embeddings.size() > 0) {
List<Float> embedding = new ArrayList<>();
for (JsonNode value : embeddings.get(0)) {
embedding.add(value.floatValue());
}
return embedding;
}
} else {
log.error("Ollama embedding failed with status: {}", response.statusCode());
}
} catch (IOException | InterruptedException e) {
log.error("Failed to generate embedding", e);
Thread.currentThread().interrupt();
}
return null;
}
/**
* 批量生成 Embedding 向量
*/
public List<List<Float>> generateEmbeddingsBatch(List<String> texts) {
List<List<Float>> embeddings = new ArrayList<>();
for (String text : texts) {
List<Float> embedding = generateEmbedding(text);
if (embedding != null) {
embeddings.add(embedding);
} else {
log.error("Failed to generate embedding for text: {}", text.substring(0,
Math.min(50, text.length())));
}
}
return embeddings;
}
private String escapeJson(String text) {
return text.replace("\\", "\\\\")
.replace("\"", "\\\"")
.replace("\n", "\\n")
.replace("\r", "\\r");
}
}数据双写
java
package com.ai.rag.service;
import com.ai.rag.bean.DocumentChunk;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
@Slf4j
@Service
public class DocumentChunkService {
private final ElasticsearchService elasticsearchService;
private final MilvusService milvusService;
private final OllamaEmbeddingService ollamaEmbeddingService;
private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
public DocumentChunkService(ElasticsearchService elasticsearchService,
MilvusService milvusService,
OllamaEmbeddingService ollamaEmbeddingService) {
this.elasticsearchService = elasticsearchService;
this.milvusService = milvusService;
this.ollamaEmbeddingService = ollamaEmbeddingService;
}
/**
* 批量文档块双写入库
*/
public boolean batchDualWriteDocumentChunks(List<DocumentChunk> chunks) {
if (chunks == null || chunks.isEmpty()) {
return true;
}
// Step 1: 批量生成 Embedding(优化性能)
List<String> texts = chunks.stream().map(DocumentChunk::getContent)
.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);
List<List<Float>> embeddings = ollamaEmbeddingService.generateEmbeddingsBatch(texts);
if (embeddings.size() != chunks.size()) {
log.error("批量生成Embedding失败, expected {} but got {}", chunks.size(), embeddings.size());
return false;
}
for (int i = 0; i < chunks.size(); i++) {
chunks.get(i).setEmbedding(embeddings.get(i));
}
// Step 2: 批量写入 Elasticsearch
boolean esSuccess = elasticsearchService.batchInsertDocumentChunks(chunks);
if (!esSuccess) {
log.error("写入es失败 需完善补偿机制");
// TODO
return false;
}
// Step 3: 批量写入 Milvus
boolean milvusSuccess = milvusService.batchInsertDocumentChunks(chunks);
if (!milvusSuccess) {
log.error("写入milvus失败 需完善补偿机制");
// TODO
return false;
}
return true;
}
}查询服务
java
package com.ai.rag.service;
import com.ai.rag.bean.DocumentChunk;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.*;
@Slf4j
@Service
public class RagQueryService {
private final ElasticsearchService elasticsearchService;
private final MilvusService milvusService;
private final OllamaEmbeddingService ollamaEmbeddingService;
@Value("${spring.ai.ollama.base-url}")
private String ollamaBaseUrl;
@Value("${spring.ai.ollama.chat.options.model}")
private String chatModel;
@Value("${spring.ai.ollama.chat.options.temperature}")
private String temperature;
@Value("${search.top}")
private Integer searchTop;
private final HttpClient httpClient;
// 请在 RagQueryService 中添加以下方法
public List<DocumentChunk> getSearchResults(String query, int limit) {
return elasticsearchService.search(query, limit);
}
public RagQueryService(ElasticsearchService elasticsearchService,
MilvusService milvusService,
OllamaEmbeddingService ollamaEmbeddingService) {
this.elasticsearchService = elasticsearchService;
this.milvusService = milvusService;
this.ollamaEmbeddingService = ollamaEmbeddingService;
this.httpClient = HttpClient.newHttpClient();
}
/**
* 混合检索:向量检索 + 全文检索,并进行结果融合
*/
public List<DocumentChunk> hybridSearch(String query, int topK) {
// Step 1: 向量检索 - 将查询转为向量后检索
List<Float> queryVector = ollamaEmbeddingService.generateEmbedding(query);
log.info("hybridSearch-将查询转为向量:{}", JSONObject.toJSONString(queryVector));
// log.info("hybridSearch-将查询转为向量后检索:{}", JSONObject.toJSONString(queryVector));
List<DocumentChunk> vectorResults = new ArrayList<>();
if (queryVector != null) {
log.info("hybridSearch-从向量库检索开始......");
vectorResults = milvusService.searchByVector(queryVector, topK);
log.info("hybridSearch-从向量库检索返回 {} 条", vectorResults.size());
}
// Step 2: 全文检索
log.info("hybridSearch-从es检索开始......");
List<DocumentChunk> textResults = elasticsearchService.search(query, topK);
log.info("hybridSearch-从es检索返回 {} 条", textResults.size());
// Step 3: 结果融合(RRF 算法去重融合)
return fusionResults(vectorResults, textResults, topK);
}
/**
* 基于 RRF(Reciprocal Rank Fusion)的结果融合
*/
private List<DocumentChunk> fusionResults(List<DocumentChunk> vectorResults,
List<DocumentChunk> textResults, int topK) {
Map<String, Double> scoreMap = new HashMap<>();
Map<String, DocumentChunk> chunkMap = new HashMap<>();
// 计算向量检索的 RRF 分数
for (int i = 0; i < vectorResults.size(); i++) {
DocumentChunk chunk = vectorResults.get(i);
String id = chunk.getId();
double rrfScore = 1.0 / (i + 60); // RRF with k=60
scoreMap.put(id, scoreMap.getOrDefault(id, 0.0) + rrfScore);
chunkMap.putIfAbsent(id, chunk);
}
// 计算文本检索的 RRF 分数
for (int i = 0; i < textResults.size(); i++) {
DocumentChunk chunk = textResults.get(i);
String id = chunk.getId();
double rrfScore = 1.0 / (i + 60);
scoreMap.put(id, scoreMap.getOrDefault(id, 0.0) + rrfScore);
chunkMap.putIfAbsent(id, chunk);
}
// 按 RRF 分数排序并取 topK
List<Map.Entry<String, Double>> sorted = new ArrayList<>(scoreMap.entrySet());
sorted.sort((a, b) -> b.getValue().compareTo(a.getValue()));
List<DocumentChunk> results = new ArrayList<>();
for (int i = 0; i < Math.min(topK, sorted.size()); i++) {
results.add(chunkMap.get(sorted.get(i).getKey()));
}
//log.info("fusionResults-结果融合结果 {}", JSONObject.toJSONString(results));
log.info("hybridSearch-RRF计计算后返回总条数: {}", results.size());
return results;
}
/**
* 完整的 RAG 问答
*/
public String askQuestion(String question) {
// Step 1: 混合检索获取相关文档块
List<DocumentChunk> relevantChunks = hybridSearch(question, searchTop);
if (relevantChunks.isEmpty()) {
return generateFallbackAnswer(question);
}
// Step 2: 构建 Prompt
String context = buildContextFromChunks(relevantChunks);
String prompt = buildPrompt(question, context);
// Step 3: 调用 Ollama 生成回答
return generateAnswer(prompt);
}
private String buildContextFromChunks(List<DocumentChunk> chunks) {
StringBuilder sb = new StringBuilder();
int rank = 1;
for (DocumentChunk chunk : chunks) {
sb.append("【参考文档").append(rank++).append("】\n");
sb.append(chunk.getContent()).append("\n\n");
}
return sb.toString();
}
private String buildPrompt(String question, String context) {
return String.format(
"你是一个专业的智能问答助手。请基于以下提供的参考资料内容,回答用户的问题。\n\n" +
"注意事项:\n" +
"1. 仅使用参考资料中的信息进行回答,不要编造或添加参考资料中不包含的内容\n" +
"2. 如果参考资料中不包含相关信息,请直接告知用户\"根据现有资料无法回答此问题\"\n" +
"3. 回答应当准确、简洁、有条理\n" +
"4. 确保回答与用户的问题相关\n\n" +
"=== 参考资料 ===\n%s\n" +
"=== 用户问题 ===\n%s\n\n" +
"=== 回答 ===\n",
context, question
);
}
private String generateAnswer(String prompt) {
try {
String requestBody = String.format(
"{\"model\":\"%s\",\"prompt\":\"%s\",\"stream\":false,\"temperature\":"+temperature+"}",
chatModel, escapeJson(prompt)
);
log.info("请求大模型开始:{}");
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(ollamaBaseUrl + "/api/generate"))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(requestBody))
.build();
HttpResponse<String> response = httpClient.send(request,
HttpResponse.BodyHandlers.ofString());
log.info("请求大模型响应: {}", response.body());
if (response.statusCode() == 200) {
JSONObject jsonResponse = JSONObject.parseObject(response.body());
String responseBody = jsonResponse.getString("response");
log.info("请求大模型检索结果:{}", responseBody);
return responseBody;
} else {
log.error("请求大模型失败: {}", response.statusCode());
return "对不起,生成回答时出现了错误。";
}
} catch (IOException | InterruptedException e) {
log.error("请求大模型异常", e);
Thread.currentThread().interrupt();
return "对不起,生成回答时出现了错误。";
}
}
private String generateFallbackAnswer(String question) {
String prompt = String.format(
"用户提出了问题:\"%s\"\n" +
"但当前知识库中未检索到相关的资料。请友好地告知用户当前无法回答该问题," +
"并建议用户提供更多信息或尝试其他问题。\n\n" +
"请以自然、有帮助的态度进行回复。",
question
);
return generateAnswer(prompt);
}
private String escapeJson(String text) {
return text.replace("\\", "\\\\")
.replace("\"", "\\\"")
.replace("\n", "\\n")
.replace("\r", "\\r");
}
}