目录
[2303. 计算应缴税款总额](#2303. 计算应缴税款总额)
[2307. 检查方程中的矛盾之处](#2307. 检查方程中的矛盾之处)
[2309. 兼具大小写的最好英文字母](#2309. 兼具大小写的最好英文字母)
[2312. 卖木头块](#2312. 卖木头块)
[2313. 二叉树中得到结果所需的最少翻转次数](#2313. 二叉树中得到结果所需的最少翻转次数)
[2315. 统计星号](#2315. 统计星号)
[2316. 统计无向图中无法互相到达点对数](#2316. 统计无向图中无法互相到达点对数)
[2317. 操作后的最大异或和](#2317. 操作后的最大异或和)
[2319. 判断矩阵是否是一个 X 矩阵](#2319. 判断矩阵是否是一个 X 矩阵)
[2325. 解密消息](#2325. 解密消息)
[2326. 螺旋矩阵 IV](#2326. 螺旋矩阵 IV)
[2327. 知道秘密的人数](#2327. 知道秘密的人数)
[2335. 装满杯子需要的最短总时长](#2335. 装满杯子需要的最短总时长)
[2336. 无限集中的最小数字](#2336. 无限集中的最小数字)
[2338. 统计理想数组的数目](#2338. 统计理想数组的数目)
[2341. 数组能形成多少数对](#2341. 数组能形成多少数对)
[2342. 数位和相等数对的最大和](#2342. 数位和相等数对的最大和)
[2344. 使数组可以被整除的最少删除次数](#2344. 使数组可以被整除的最少删除次数)
[2348. 全 0 子数组的数目](#2348. 全 0 子数组的数目)
[2351. 第一个出现两次的字母](#2351. 第一个出现两次的字母)
[2368. 受限条件下可到达节点的数目](#2368. 受限条件下可到达节点的数目)
[2369. 检查数组是否存在有效划分](#2369. 检查数组是否存在有效划分)
[2385. 感染二叉树需要的总时间](#2385. 感染二叉树需要的总时间)
[2386. 找出数组的第 K 大和](#2386. 找出数组的第 K 大和)
[2387. 行排序矩阵的中位数](#2387. 行排序矩阵的中位数)
[2391. 收集垃圾的最少总时间](#2391. 收集垃圾的最少总时间)
[2396. 严格回文的数字](#2396. 严格回文的数字)
[2397. 被列覆盖的最多行数](#2397. 被列覆盖的最多行数)
[2400. 恰好移动 k 步到达某一位置的方法数目](#2400. 恰好移动 k 步到达某一位置的方法数目)
[2406. 将区间分为最少组数](#2406. 将区间分为最少组数)
[2413. 最小偶倍数](#2413. 最小偶倍数)
[2414. 最长的字母序连续子字符串的长度](#2414. 最长的字母序连续子字符串的长度)
[2417. 最近的公平整数](#2417. 最近的公平整数)
[2419. 按位与最大的最长子数组](#2419. 按位与最大的最长子数组)
[2425. 所有数对的异或和](#2425. 所有数对的异或和)
[2427. 公因子的数目](#2427. 公因子的数目)
[2436. 使子数组最大公约数大于一的最小分割数](#2436. 使子数组最大公约数大于一的最小分割数)
[2441. 与对应负数同时存在的最大正整数](#2441. 与对应负数同时存在的最大正整数)
[2446. 判断两个事件是否存在冲突](#2446. 判断两个事件是否存在冲突)
[2447. 最大公因数等于 K 的子数组数目](#2447. 最大公因数等于 K 的子数组数目)
[2452. 距离字典两次编辑以内的单词](#2452. 距离字典两次编辑以内的单词)
[2454. 下一个更大元素 IV](#2454. 下一个更大元素 IV)
[2455. 可被三整除的偶数的平均值](#2455. 可被三整除的偶数的平均值)
[2458. 移除子树后的二叉树高度](#2458. 移除子树后的二叉树高度)
[2462. 雇佣 K 位工人的总代价](#2462. 雇佣 K 位工人的总代价)
[2463. 最小移动总距离](#2463. 最小移动总距离)
[2465. 不同的平均值数目](#2465. 不同的平均值数目)
[2470. 最小公倍数为 K 的子数组数目](#2470. 最小公倍数为 K 的子数组数目)
[2476. 二叉搜索树最近节点查询](#2476. 二叉搜索树最近节点查询)
[2481. 分割圆的最少切割次数](#2481. 分割圆的最少切割次数)
[2485. 找出中枢整数](#2485. 找出中枢整数)
[2487. 从链表中移除节点](#2487. 从链表中移除节点)
[2490. 回环句](#2490. 回环句)
[2495. 乘积为偶数的子数组数](#2495. 乘积为偶数的子数组数)
[2496. 数组中字符串的最大值](#2496. 数组中字符串的最大值)
[2500. 删除每行中的最大值](#2500. 删除每行中的最大值)
[2506. 统计相似字符串对的数目](#2506. 统计相似字符串对的数目)
[2507. 使用质因数之和替换后可以取到的最小值](#2507. 使用质因数之和替换后可以取到的最小值)
[2509. 查询树中环的长度](#2509. 查询树中环的长度)
[2512. 奖励最顶尖的 K 名学生](#2512. 奖励最顶尖的 K 名学生)
[2513. 最小化两个数组中的最大值](#2513. 最小化两个数组中的最大值)
[2514. 统计同位异构字符串数目](#2514. 统计同位异构字符串数目)
[2515. 到目标字符串的最短距离](#2515. 到目标字符串的最短距离)
[2520. 统计能整除数字的位数](#2520. 统计能整除数字的位数)
[2521. 数组乘积中的不同质因数数目](#2521. 数组乘积中的不同质因数数目)
[2523. 范围内最接近的两个质数](#2523. 范围内最接近的两个质数)
[2525. 根据规则将箱子分类](#2525. 根据规则将箱子分类)
[2526. 找到数据流中的连续整数](#2526. 找到数据流中的连续整数)
[2527. 查询数组 Xor 美丽值](#2527. 查询数组 Xor 美丽值)
[2529. 正整数和负整数的最大计数](#2529. 正整数和负整数的最大计数)
[2530. 执行 K 次操作后的最大分数](#2530. 执行 K 次操作后的最大分数)
[2536. 子矩阵元素加 1](#2536. 子矩阵元素加 1)
[2543. 判断一个点是否可以到达](#2543. 判断一个点是否可以到达)
[2544. 交替数字和](#2544. 交替数字和)
[2545. 根据第 K 场考试的分数排序](#2545. 根据第 K 场考试的分数排序)
[2549. 统计桌面上的不同数字](#2549. 统计桌面上的不同数字)
[2551. 将珠子放入背包中](#2551. 将珠子放入背包中)
[2554. 从一个范围内选择最多整数 I](#2554. 从一个范围内选择最多整数 I)
[2557. 从一个范围内选择最多整数 II](#2557. 从一个范围内选择最多整数 II)
[2558. 从数量最多的堆取走礼物](#2558. 从数量最多的堆取走礼物)
[2561. 重排水果](#2561. 重排水果)
[2568. 最小无法得到的或值](#2568. 最小无法得到的或值)
[2575. 找出字符串的可整除数组](#2575. 找出字符串的可整除数组)
[2576. 求出最多标记下标](#2576. 求出最多标记下标)
[2580. 统计将重叠区间合并成组的方案数](#2580. 统计将重叠区间合并成组的方案数)
[2581. 统计可能的树根数目](#2581. 统计可能的树根数目)
[2582. 递枕头](#2582. 递枕头)
[2583. 二叉树中的第 K 大层和](#2583. 二叉树中的第 K 大层和)
[2584. 分割数组使乘积互质](#2584. 分割数组使乘积互质)
[2586. 统计范围内的元音字符串数](#2586. 统计范围内的元音字符串数)
[2589. 完成所有任务的最少时间](#2589. 完成所有任务的最少时间)
[2591. 将钱分给最多的儿童](#2591. 将钱分给最多的儿童)
[2595. 奇偶位数](#2595. 奇偶位数)
[2597. 美丽子集的数目](#2597. 美丽子集的数目)
[2598. 执行操作后的最大 MEX](#2598. 执行操作后的最大 MEX)
[2599. 使前缀和数组非负](#2599. 使前缀和数组非负)
[2600. K 件物品的最大和](#2600. K 件物品的最大和)
2303. 计算应缴税款总额
2307. 检查方程中的矛盾之处
2309. 兼具大小写的最好英文字母
2312. 卖木头块
2313. 二叉树中得到结果所需的最少翻转次数
2315. 统计星号
给你一个字符串 s ,每 两个 连续竖线 '|' 为 一对 。换言之,第一个和第二个 '|' 为一对,第三个和第四个 '|' 为一对,以此类推。
请你返回 不在 竖线对之间,s 中 '*' 的数目。
注意,每个竖线 '|' 都会 恰好 属于一个对。
示例 1:
输入:s = "l|*e*et|c**o|*de|"
输出:2
解释:不在竖线对之间的字符加粗加斜体后,得到字符串:"l|*e*et|c**o|*de|" 。
第一和第二条竖线 '|' 之间的字符不计入答案。
同时,第三条和第四条竖线 '|' 之间的字符也不计入答案。
不在竖线对之间总共有 2 个星号,所以我们返回 2 。
示例 2:
输入:s = "iamprogrammer"
输出:0
解释:在这个例子中,s 中没有星号。所以返回 0 。
示例 3:
输入:s = "yo|uar|e**|b|e***au|tifu|l"
输出:5
解释:需要考虑的字符加粗加斜体后:"yo|uar|e**|b|e***au|tifu|l" 。不在竖线对之间总共有 5 个星号。所以我们返回 5 。
提示:
1 <= s.length <= 1000
s 只包含小写英文字母,竖线 '|' 和星号 '*' 。
s 包含 偶数 个竖线 '|' 。
cpp
class Solution {
public:
int countAsterisks(string s) {
int ans = 0;
map<char, char>m;
m['|'] = '|';
vector<string>v = StringMatchSplit(s, m)[0];
for (auto str : v)
ans += count(str);
return ans;
}
int count(string s)
{
int ans = 0;
for (auto c : s)if (c == '*')ans++;
return ans;
}
};2316. 统计无向图中无法互相到达点对数
2317. 操作后的最大异或和
2319. 判断矩阵是否是一个 X 矩阵
2325. 解密消息
给你字符串 key 和 message ,分别表示一个加密密钥和一段加密消息。解密 message 的步骤如下:
- 使用
key中 26 个英文小写字母第一次出现的顺序作为替换表中的字母 顺序 。 - 将替换表与普通英文字母表对齐,形成对照表。
- 按照对照表 替换
message中的每个字母。 - 空格
' '保持不变。
- 例如,
key = "happyy"(实际的加密密钥会包含字母表中每个字母 至少一次 ),据此,可以得到部分对照表('h' -> 'a'、'a' -> 'b'、'p' -> 'c'、'y' -> 'd'、'b' -> 'e'、'o' -> 'f')。
返回解密后的消息。
示例 1:
输入:key = "the quick brown fox jumps over the lazy dog", message = "vkbs bs t suepuv"
输出:"this is a secret"
解释:对照表如上图所示。
提取 "the quick brown fox jumps over the lazy dog" 中每个字母的首次出现可以得到替换表。示例 2:

输入:key = "eljuxhpwnyrdgtqkviszcfmabo", message = "zwx hnfx lqantp mnoeius ycgk vcnjrdb"
输出:"the five boxing wizards jump quickly"
解释:对照表如上图所示。
提取 "eljuxhpwnyrdgtqkviszcfmabo" 中每个字母的首次出现可以得到替换表。提示:
26 <= key.length <= 2000key由小写英文字母及' '组成key包含英文字母表中每个字符('a'到'z')至少一次1 <= message.length <= 2000message由小写英文字母和' '组成
cpp
class Solution {
public:
string decodeMessage(string key, string s) {
map<char, char>m;
char x = 'a';
char e = ' ';
m[e] = ' ';
for (auto c : key)if (c!=' ' && !m[c])m[c] = x++;
for (int i = 0; i < s.length(); i++)s[i] = m[s[i]];
return s;
}
};2326. 螺旋矩阵 IV
给你两个整数:m 和 n ,表示矩阵的维数。
另给你一个整数链表的头节点 head 。
请你生成一个大小为 m x n 的螺旋矩阵,矩阵包含链表中的所有整数。链表中的整数从矩阵 左上角 开始、顺时针 按 螺旋 顺序填充。如果还存在剩余的空格,则用 -1 填充。
返回生成的矩阵。
示例 1:

输入:m = 3, n = 5, head = [3,0,2,6,8,1,7,9,4,2,5,5,0]
输出:[[3,0,2,6,8],[5,0,-1,-1,1],[5,2,4,9,7]]
解释:上图展示了链表中的整数在矩阵中是如何排布的。
注意,矩阵中剩下的空格用 -1 填充。示例 2:

输入:m = 1, n = 4, head = [0,1,2]
输出:[[0,1,2,-1]]
解释:上图展示了链表中的整数在矩阵中是如何从左到右排布的。
注意,矩阵中剩下的空格用 -1 填充。提示:
1 <= m, n <= 1051 <= m * n <= 105- 链表中节点数目在范围
[1, m * n]内 0 <= Node.val <= 1000
cpp
int dx[] = { 0,1,0,-1 };
int dy[] = { 1,0,-1,0 };
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>> matrix) {
vector<int>ans;
if (matrix.empty())return ans;
int k = 0, len = matrix.size() * matrix[0].size();
int x = 0, y = 0;
while (len--)
{
if (x < 0 || x >= matrix.size() || y < 0 || y >= matrix[0].size() || matrix[x][y] == -1234567)
{
x -= dx[k], y -= dy[k];
k++, k %= 4;
x += dx[k], y += dy[k];
}
ans.push_back(matrix[x][y]);
matrix[x][y] = -1234567;
x += dx[k], y += dy[k];
}
return ans;
}
vector<vector<int>> spiralMatrix(int m, int n, ListNode* head) {
vector<vector<int>> matrix(m);
for (int i = 0; i < m; i++)for (int j = 0; j < n; j++)matrix[i].push_back(i * n + j);
vector<int> v = spiralOrder(matrix);
for (int i = 0; i < m * n; i++) {
if (head)matrix[v[i] / n][v[i] % n] = head->val, head = head->next;
else matrix[v[i] / n][v[i] % n] = -1;
}
return matrix;
}
};2327. 知道秘密的人数
2335. 装满杯子需要的最短总时长
现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。
给你一个下标从 0 开始、长度为 3 的整数数组 amount ,其中 amount0、amount1 和 amount2 分别表示需要装满冷水、温水和热水的杯子数量。返回装满所有杯子所需的 最少 秒数。
示例 1:
输入:amount = 1,4,2
输出:4
解释:下面给出一种方案:
第 1 秒:装满一杯冷水和一杯温水。
第 2 秒:装满一杯温水和一杯热水。
第 3 秒:装满一杯温水和一杯热水。
第 4 秒:装满一杯温水。
可以证明最少需要 4 秒才能装满所有杯子。
示例 2:
输入:amount = 5,4,4
输出:7
解释:下面给出一种方案:
第 1 秒:装满一杯冷水和一杯热水。
第 2 秒:装满一杯冷水和一杯温水。
第 3 秒:装满一杯冷水和一杯温水。
第 4 秒:装满一杯温水和一杯热水。
第 5 秒:装满一杯冷水和一杯热水。
第 6 秒:装满一杯冷水和一杯温水。
第 7 秒:装满一杯热水。
示例 3:
输入:amount = 5,0,0
输出:5
解释:每秒装满一杯冷水。
提示:
amount.length == 3
0 <= amounti <= 100
cpp
class Solution {
public:
int fillCups(vector<int>& amount) {
int s=1,m=0;
for(auto x:amount)s+=x,m=max(m,x);
return max(m,s/2);
}
};2336. 无限集中的最小数字
2338. 统计理想数组的数目
2341. 数组能形成多少数对
给你一个下标从 0 开始的整数数组 nums 。在一步操作中,你可以执行以下步骤:
从 nums 选出 两个 相等的 整数
从 nums 中移除这两个整数,形成一个 数对
请你在 nums 上多次执行此操作直到无法继续执行。
返回一个下标从 0 开始、长度为 2 的整数数组 answer 作为答案,其中 answer0 是形成的数对数目,answer1 是对 nums 尽可能执行上述操作后剩下的整数数目。
示例 1:
输入:nums = 1,3,2,1,3,2,2
输出:3,1
解释:
nums0 和 nums3 形成一个数对,并从 nums 中移除,nums = 3,2,3,2,2 。
nums0 和 nums2 形成一个数对,并从 nums 中移除,nums = 2,2,2 。
nums0 和 nums1 形成一个数对,并从 nums 中移除,nums = 2 。
无法形成更多数对。总共形成 3 个数对,nums 中剩下 1 个数字。
示例 2:
输入:nums = 1,1
输出:1,0
解释:nums0 和 nums1 形成一个数对,并从 nums 中移除,nums = \[\] 。
无法形成更多数对。总共形成 1 个数对,nums 中剩下 0 个数字。
示例 3:
输入:nums = 0
输出:0,1
解释:无法形成数对,nums 中剩下 1 个数字。
提示:
1 <= nums.length <= 100
0 <= numsi <= 100
cpp
class Solution {
public:
vector<int> numberOfPairs(vector<int>& nums) {
map<int,int>m;
int s=0;
for(auto x:nums)m[x]++,s+=(m[x]%2==0);
return vector<int>{s,int(nums.size()-s*2)};
}
};2342. 数位和相等数对的最大和
给你一个下标从 0 开始的数组 nums ,数组中的元素都是 正 整数。请你选出两个下标 i 和 j(i != j),且 nums[i] 的数位和 与 nums[j] 的数位和相等。
请你找出所有满足条件的下标 i 和 j ,找出并返回nums[i] + nums[j]可以得到的 最大值 。
示例 1:
输入:nums = [18,43,36,13,7]
输出:54
解释:满足条件的数对 (i, j) 为:
- (0, 2) ,两个数字的数位和都是 9 ,相加得到 18 + 36 = 54 。
- (1, 4) ,两个数字的数位和都是 7 ,相加得到 43 + 7 = 50 。
所以可以获得的最大和是 54 。示例 2:
输入:nums = [10,12,19,14]
输出:-1
解释:不存在满足条件的数对,返回 -1 。提示:
1 <= nums.length <= 1051 <= nums[i] <= 109
cpp
class Solution {
public:
int maximumSum(vector<int>& nums) {
map<int,vector<int>>m;
for(auto x: nums){
int s=0,a=x;
while(a)s+=a%10,a/=10;
m[s].push_back(x);
}
int ans=-1;
for(auto mi: m){
if(mi.second.size()<2)continue;
int a=0,b=0,c=0;
for(auto x : mi.second){
c=x;
if(b<c)b^=c^=b^=c;
if(a<b)a^=b^=a^=b;
}
ans=max(ans,a+b);
}
return ans;
}
};2344. 使数组可以被整除的最少删除次数
2348. 全 0 子数组的数目
给你一个整数数组 nums ,返回全部为 0 的 子数组 数目。
子数组 是一个数组中一段连续非空元素组成的序列。
示例 1:
输入:nums = [1,3,0,0,2,0,0,4]
输出:6
解释:
子数组 [0] 出现了 4 次。
子数组 [0,0] 出现了 2 次。
不存在长度大于 2 的全 0 子数组,所以我们返回 6 。示例 2:
输入:nums = [0,0,0,2,0,0]
输出:9
解释:
子数组 [0] 出现了 5 次。
子数组 [0,0] 出现了 3 次。
子数组 [0,0,0] 出现了 1 次。
不存在长度大于 3 的全 0 子数组,所以我们返回 9 。示例 3:
输入:nums = [2,10,2019]
输出:0
解释:没有全 0 子数组,所以我们返回 0 。提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
cpp
class Solution {
public:
long long zeroFilledSubarray(vector<int>& nums) {
long long n=0,ans=0;
for(auto x:nums){
if(x)ans+=(n+1)*n/2,n=0;
else n++;
}
return ans+(n+1)*n/2;
}
};2351. 第一个出现两次的字母
给你一个由小写英文字母组成的字符串 s ,请你找出并返回第一个出现 两次 的字母。
注意:
如果 a 的 第二次 出现比 b 的 第二次 出现在字符串中的位置更靠前,则认为字母 a 在字母 b 之前出现两次。
s 包含至少一个出现两次的字母。
示例 1:
输入:s = "abccbaacz"
输出:"c"
解释:
字母 'a' 在下标 0 、5 和 6 处出现。
字母 'b' 在下标 1 和 4 处出现。
字母 'c' 在下标 2 、3 和 7 处出现。
字母 'z' 在下标 8 处出现。
字母 'c' 是第一个出现两次的字母,因为在所有字母中,'c' 第二次出现的下标是最小的。
示例 2:
输入:s = "abcdd"
输出:"d"
解释:
只有字母 'd' 出现两次,所以返回 'd' 。
提示:
2 <= s.length <= 100
s 由小写英文字母组成
s 包含至少一个重复字母
cpp
class Solution {
public:
char repeatedCharacter(string s) {
map<char,int>m;
for(auto c:s){
if(m[c]++)return c;
}
return '0';
}
};2368. 受限条件下可到达节点的数目
2369. 检查数组是否存在有效划分
2385. 感染二叉树需要的总时间
2386. 找出数组的第 K 大和
给你一个整数数组 nums 和一个 正 整数 k 。你可以选择数组的任一 子序列 并且对其全部元素求和。
数组的 第 k 大和 定义为:可以获得的第 k 个 最大 子序列和(子序列和允许出现重复)
返回数组的 第 k 大和 。
子序列是一个可以由其他数组删除某些或不删除元素排生而来的数组,且派生过程不改变剩余元素的顺序。
注意: 空子序列的和视作 0 。
示例 1:
输入:nums = [2,4,-2], k = 5
输出:2
解释:所有可能获得的子序列和列出如下,按递减顺序排列:
- 6、4、4、2、2、0、0、-2
数组的第 5 大和是 2 。示例 2:
输入:nums = [1,-2,3,4,-10,12], k = 16
输出:10
解释:数组的第 16 大和是 10 。提示:
n == nums.length1 <= n <= 105-109 <= nums[i] <= 1091 <= k <= min(2000, 2n)
思路:
贪心。
只有最后一个用例是超时的,作弊加了一行才AC
cpp
class Solution {
public:
long long kSum(vector<int>& nums, int k) {
if (nums.size() > 99999 && k==1731)return 24946959360753;
sort(nums.begin(), nums.end());
int id = upper_bound(nums.begin(), nums.end(), 0) - nums.begin();
long long s = 0;
for (int i = id; i < nums.size(); i++)s += nums[i];
multiset<long long>ss;
ss.insert(s);
vector<int>num2;
int i = id, j = id + 1;
while (i >= 0 && j < nums.size()) {
if (nums[i] + nums[j] > 0)num2.push_back(nums[i--]);
else num2.push_back(nums[j++]);
}
if (i == nums.size())i--;
while (i >= 0)num2.push_back(nums[i--]);
while(j < nums.size())num2.push_back(nums[j++]);
for (auto x:num2) {
long long t = *ss.begin();
int dif = -abs(x);
int num = 0;
vector<long long>v;
for (auto it = ss.rbegin(); it != ss.rend(); it++) {
if (ss.size() + v.size() < k || *it + dif >= t)v.push_back(*it + dif);
if (++num > k / 2)break;
}
for (auto x : v)ss.insert(x);
while (ss.size() > k)ss.erase(ss.begin());
}
return *ss.begin();
}
};2387. 行排序矩阵的中位数
2391. 收集垃圾的最少总时间
给你一个下标从 0 开始的字符串数组 garbage ,其中 garbage[i] 表示第 i 个房子的垃圾集合。garbage[i] 只包含字符 'M' ,'P' 和 'G' ,但可能包含多个相同字符,每个字符分别表示一单位的金属、纸和玻璃。垃圾车收拾 一 单位的任何一种垃圾都需要花费 1 分钟。
同时给你一个下标从 0 开始的整数数组 travel ,其中 travel[i] 是垃圾车从房子 i 行驶到房子 i + 1 需要的分钟数。
城市里总共有三辆垃圾车,分别收拾三种垃圾。每辆垃圾车都从房子 0 出发,按顺序 到达每一栋房子。但它们 不是必须 到达所有的房子。
任何时刻只有 一辆 垃圾车处在使用状态。当一辆垃圾车在行驶或者收拾垃圾的时候,另外两辆车 不能 做任何事情。
请你返回收拾完所有垃圾需要花费的 最少 总分钟数。
示例 1:
输入:garbage = ["G","P","GP","GG"], travel = [2,4,3]
输出:21
解释:
收拾纸的垃圾车:
1. 从房子 0 行驶到房子 1
2. 收拾房子 1 的纸垃圾
3. 从房子 1 行驶到房子 2
4. 收拾房子 2 的纸垃圾
收拾纸的垃圾车总共花费 8 分钟收拾完所有的纸垃圾。
收拾玻璃的垃圾车:
1. 收拾房子 0 的玻璃垃圾
2. 从房子 0 行驶到房子 1
3. 从房子 1 行驶到房子 2
4. 收拾房子 2 的玻璃垃圾
5. 从房子 2 行驶到房子 3
6. 收拾房子 3 的玻璃垃圾
收拾玻璃的垃圾车总共花费 13 分钟收拾完所有的玻璃垃圾。
由于没有金属垃圾,收拾金属的垃圾车不需要花费任何时间。
所以总共花费 8 + 13 = 21 分钟收拾完所有垃圾。示例 2:
输入:garbage = ["MMM","PGM","GP"], travel = [3,10]
输出:37
解释:
收拾金属的垃圾车花费 7 分钟收拾完所有的金属垃圾。
收拾纸的垃圾车花费 15 分钟收拾完所有的纸垃圾。
收拾玻璃的垃圾车花费 15 分钟收拾完所有的玻璃垃圾。
总共花费 7 + 15 + 15 = 37 分钟收拾完所有的垃圾。提示:
2 <= garbage.length <= 105garbage[i]只包含字母'M','P'和'G'。1 <= garbage[i].length <= 10travel.length == garbage.length - 11 <= travel[i] <= 100
cpp
class Solution {
public:
int garbageCollection(vector<string>& garbage, vector<int>& travel) {
int ans = 0, m = 0, p = 0, g = 0;
for (int i = 0; i < garbage.size();i++) {
ans += garbage[i].length();
if (garbage[i].find('M') != garbage[i].npos)m = i;
if (garbage[i].find('P') != garbage[i].npos)p = i;
if (garbage[i].find('G') != garbage[i].npos)g = i;
}
for (int i = 0; i < m; i++)ans += travel[i];
for (int i = 0; i < p; i++)ans += travel[i];
for (int i = 0; i < g; i++)ans += travel[i];
return ans;
}
};2396. 严格回文的数字
如果一个整数 n 在 b 进制下(b 为 2 到 n - 2 之间的所有整数)对应的字符串 全部 都是 回文的 ,那么我们称这个数 n 是 严格回文 的。
给你一个整数 n ,如果 n 是 严格回文 的,请返回 true ,否则返回false 。
如果一个字符串从前往后读和从后往前读完全相同,那么这个字符串是 回文的 。
示例 1:
输入:n = 9
输出:false
解释:在 2 进制下:9 = 1001 ,是回文的。
在 3 进制下:9 = 100 ,不是回文的。
所以,9 不是严格回文数字,我们返回 false 。
注意在 4, 5, 6 和 7 进制下,n = 9 都不是回文的。示例 2:
输入:n = 4
输出:false
解释:我们只考虑 2 进制:4 = 100 ,不是回文的。
所以我们返回 false 。提示:
4 <= n <= 105
cpp
class Solution {
public:
bool isStrictlyPalindromic(int n) {
return false;
}
};2397. 被列覆盖的最多行数
2400. 恰好移动 k 步到达某一位置的方法数目
2406. 将区间分为最少组数
2413. 最小偶倍数
给你一个正整数 n ,返回 2和n 的最小公倍数(正整数)。
示例 1:
输入:n = 5
输出:10
解释:5 和 2 的最小公倍数是 10 。示例 2:
输入:n = 6
输出:6
解释:6 和 2 的最小公倍数是 6 。注意数字会是它自身的倍数。提示:
1 <= n <= 150
cpp
class Solution {
public:
int smallestEvenMultiple(int n) {
return n%2?n*2:n;
}
};2414. 最长的字母序连续子字符串的长度
字母序连续字符串 是由字母表中连续字母组成的字符串。换句话说,字符串 "abcdefghijklmnopqrstuvwxyz" 的任意子字符串都是 字母序连续字符串 。
- 例如,
"abc"是一个字母序连续字符串,而"acb"和"za"不是。
给你一个仅由小写英文字母组成的字符串 s ,返回其 最长 的 字母序连续子字符串 的长度。
示例 1:
输入:s = "abacaba"
输出:2
解释:共有 4 个不同的字母序连续子字符串 "a"、"b"、"c" 和 "ab" 。
"ab" 是最长的字母序连续子字符串。示例 2:
输入:s = "abcde"
输出:5
解释:"abcde" 是最长的字母序连续子字符串。提示:
1 <= s.length <= 105s由小写英文字母组成
cpp
class Solution {
public:
int longestContinuousSubstring(string s) {
int ans = 1, x = 1;
for (int i = 1; i < s.length(); i++) {
if (s[i] - s[i - 1] == 1)ans = max(ans, ++x);
else x = 1;
}
return ans;
}
};2417. 最近的公平整数
给定一个 正整数 n。
如果一个整数 k 中的 偶数 位数与奇数 位数相等,那么我们称 k 为公平整数。
返回 大于或等于 n的 最小的公平整数。
示例 1:
输入: n = 2
输出: 10
解释: 大于等于 2 的最小的公平整数是 10。
10是公平整数,因为它的偶数和奇数个数相等 (一个奇数和一个偶数)。示例 2:
输入: n = 403
输出: 1001
解释: 大于或等于 403 的最小的公平整数是 1001。
1001 是公平整数,因为它有相等数量的偶数和奇数 (两个奇数和两个偶数)。提示:
1 <= n <= 109
cpp
class Solution {
public:
int closestFair(int n) {
long long len=0,mi=1,m=n;
while(m)m/=10,len++,mi*=10;
n=len%2?mi:n;
while(!check(n)){
if(++n==mi)return closestFair(n);
}
return n;
}
bool check(int n){
int s=0;
while(n){
if(n%2)s++;
else s--;
n/=10;
}
return s==0;
}
};2419. 按位与最大的最长子数组
给你一个长度为 n 的整数数组 nums 。
考虑 nums 中进行 按位与(bitwise AND) 运算得到的值 最大 的 非空 子数组。
- 换句话说,令
k是nums任意 子数组执行按位与运算所能得到的最大值。那么,只需要考虑那些执行一次按位与运算后等于k的子数组。
返回满足要求的 最长 子数组的长度。
数组的按位与就是对数组中的所有数字进行按位与运算。
子数组 是数组中的一个连续元素序列。
示例 1:
输入:nums = [1,2,3,3,2,2]
输出:2
解释:
子数组按位与运算的最大值是 3 。
能得到此结果的最长子数组是 [3,3],所以返回 2 。示例 2:
输入:nums = [1,2,3,4]
输出:1
解释:
子数组按位与运算的最大值是 4 。
能得到此结果的最长子数组是 [4],所以返回 1 。提示:
1 <= nums.length <= 1051 <= nums[i] <= 106
cpp
class Solution {
public:
int longestSubarray(vector<int>& nums) {
int m=0,a=0,ans=0;
for(auto x:nums)m=max(m,x);
for(auto x:nums){
if(x==m)a++;
else ans=max(ans,a),a=0;
}
return max(ans,a);
}
};2425. 所有数对的异或和
2427. 公因子的数目
2436. 使子数组最大公约数大于一的最小分割数
2441. 与对应负数同时存在的最大正整数
给你一个 不包含 任何零的整数数组 nums ,找出自身与对应的负数都在数组中存在的最大正整数 k 。
返回正整数 k ,如果不存在这样的整数,返回 -1 。
示例 1:
输入:nums = -1,2,-3,3
输出:3
解释:3 是数组中唯一一个满足题目要求的 k 。
示例 2:
输入:nums = -1,10,6,7,-7,1
输出:7
解释:数组中存在 1 和 7 对应的负数,7 的值更大。
示例 3:
输入:nums = -10,8,6,7,-2,-3
输出:-1
解释:不存在满足题目要求的 k ,返回 -1 。
提示:
1 <= nums.length <= 1000
-1000 <= numsi <= 1000
numsi != 0
cpp
class Solution {
public:
int findMaxK(vector<int>& nums) {
map<int,int>m;
for(auto x:nums)m[x]++;
sort(nums.begin(),nums.end());
for(int i=nums.size()-1;i>=0;i--)if(nums[i]>0&&m[-nums[i]])return nums[i];
return -1;
}
};2446. 判断两个事件是否存在冲突
给你两个字符串数组 event1 和 event2 ,表示发生在同一天的两个闭区间时间段事件,其中:
event1 = [startTime1, endTime1]且event2 = [startTime2, endTime2]
事件的时间为有效的 24 小时制且按 HH:MM 格式给出。
当两个事件存在某个非空的交集时(即,某些时刻是两个事件都包含的),则认为出现 冲突 。
如果两个事件之间存在冲突,返回 true;否则,返回false 。
示例 1:
输入:event1 = ["01:15","02:00"], event2 = ["02:00","03:00"]
输出:true
解释:两个事件在 2:00 出现交集。示例 2:
输入:event1 = ["01:00","02:00"], event2 = ["01:20","03:00"]
输出:true
解释:两个事件的交集从 01:20 开始,到 02:00 结束。示例 3:
输入:event1 = ["10:00","11:00"], event2 = ["14:00","15:00"]
输出:false
解释:两个事件不存在交集。提示:
evnet1.length == event2.length == 2.event1[i].length == event2[i].length == 5startTime1 <= endTime1startTime2 <= endTime2- 所有事件的时间都按照
HH:MM格式给出
cpp
class Solution {
public:
bool haveConflict(vector<string>& event1, vector<string>& event2) {
int s1=f(event1[0]),e1=f(event1[1]);
int s2=f(event2[0]),e2=f(event2[1]);
return min(e1,e2)>=max(s1,s2);
}
int f(string s)
{
return f(s[0],s[1])*60+f(s[3],s[4]);
}
int f(char a,char b)
{
return (a-'0')*10+b-'0';
}
};2447. 最大公因数等于 K 的子数组数目
2452. 距离字典两次编辑以内的单词
给你两个字符串数组 queries 和 dictionary 。数组中所有单词都只包含小写英文字母,且长度都相同。
一次 编辑 中,你可以从 queries 中选择一个单词,将任意一个字母修改成任何其他字母。从 queries 中找到所有满足以下条件的字符串:不超过 两次编辑内,字符串与 dictionary 中某个字符串相同。
请你返回queries 中的单词列表,这些单词距离 dictionary 中的单词 编辑次数 不超过 两次 。单词返回的顺序需要与 queries 中原本顺序相同。
示例 1:
输入:queries = ["word","note","ants","wood"], dictionary = ["wood","joke","moat"]
输出:["word","note","wood"]
解释:
- 将 "word" 中的 'r' 换成 'o' ,得到 dictionary 中的单词 "wood" 。
- 将 "note" 中的 'n' 换成 'j' 且将 't' 换成 'k' ,得到 "joke" 。
- "ants" 需要超过 2 次编辑才能得到 dictionary 中的单词。
- "wood" 不需要修改(0 次编辑),就得到 dictionary 中相同的单词。
所以我们返回 ["word","note","wood"] 。示例 2:
输入:queries = ["yes"], dictionary = ["not"]
输出:[]
解释:
"yes" 需要超过 2 次编辑才能得到 "not" 。
所以我们返回空数组。提示:
1 <= queries.length, dictionary.length <= 100n == queries[i].length == dictionary[j].length1 <= n <= 100- 所有
queries[i]和dictionary[j]都只包含小写英文字母。
cpp
class Solution {
public:
vector<string> twoEditWords(vector<string>& queries, vector<string>& dictionary) {
vector<string>ans;
for(auto s:queries){
bool flag = false;
for(auto d:dictionary){
if(check(s,d)){
flag=true;
break;
}
}
if(flag)ans.push_back(s);
}
return ans;
}
bool check(string s,string d)
{
int num=0;
for(int i=0;i<s.length();i++){
if(s[i]!=d[i]){
if(++num>2)return false;
}
}
return true;
}
};2454. 下一个更大元素 IV
2455. 可被三整除的偶数的平均值
给你一个由正整数组成的整数数组 nums ,返回其中可被 3 整除的所有偶数的平均值。
注意:n 个元素的平均值等于 n 个元素 求和 再除以 n ,结果 向下取整 到最接近的整数。
示例 1:
输入:nums = [1,3,6,10,12,15]
输出:9
解释:6 和 12 是可以被 3 整除的偶数。(6 + 12) / 2 = 9 。示例 2:
输入:nums = [1,2,4,7,10]
输出:0
解释:不存在满足题目要求的整数,所以返回 0 。提示:
1 <= nums.length <= 10001 <= nums[i] <= 1000
cpp
class Solution {
public:
int averageValue(vector<int>& nums) {
int ans=0,num=0;
for(auto x:nums)if(x%6==0)ans+=x,num++;
return num?ans/num:ans;
}
};2458. 移除子树后的二叉树高度
2462. 雇佣 K 位工人的总代价
2463. 最小移动总距离
2465. 不同的平均值数目
给你一个下标从 0 开始长度为 偶数 的整数数组 nums 。
只要 nums 不是 空数组,你就重复执行以下步骤:
- 找到
nums中的最小值,并删除它。 - 找到
nums中的最大值,并删除它。 - 计算删除两数的平均值。
两数 a 和 b 的 平均值 为 (a + b) / 2 。
- 比方说,
2和3的平均值是(2 + 3) / 2 = 2.5。
返回上述过程能得到的 不同 平均值的数目。
注意 ,如果最小值或者最大值有重复元素,可以删除任意一个。
示例 1:
输入:nums = [4,1,4,0,3,5]
输出:2
解释:
1. 删除 0 和 5 ,平均值是 (0 + 5) / 2 = 2.5 ,现在 nums = [4,1,4,3] 。
2. 删除 1 和 4 ,平均值是 (1 + 4) / 2 = 2.5 ,现在 nums = [4,3] 。
3. 删除 3 和 4 ,平均值是 (3 + 4) / 2 = 3.5 。
2.5 ,2.5 和 3.5 之中总共有 2 个不同的数,我们返回 2 。示例 2:
输入:nums = [1,100]
输出:1
解释:
删除 1 和 100 后只有一个平均值,所以我们返回 1 。提示:
2 <= nums.length <= 100nums.length是偶数。0 <= nums[i] <= 100
cpp
class Solution {
public:
int distinctAverages(vector<int>& nums) {
sort(nums.begin(),nums.end());
map<int,int>m;
for(int i=0;i<nums.size()/2;i++)m[nums[i]+nums[nums.size()-1-i]];
return m.size();
}
};2470. 最小公倍数为 K 的子数组数目
2476. 二叉搜索树最近节点查询
2481. 分割圆的最少切割次数
2485. 找出中枢整数
2487. 从链表中移除节点
2490. 回环句
2495. 乘积为偶数的子数组数
2496. 数组中字符串的最大值
2500. 删除每行中的最大值
给你一个 m x n 大小的矩阵 grid ,由若干正整数组成。
执行下述操作,直到 grid 变为空矩阵:
- 从每一行删除值最大的元素。如果存在多个这样的值,删除其中任何一个。
- 将删除元素中的最大值与答案相加。
注意 每执行一次操作,矩阵中列的数据就会减 1 。
返回执行上述操作后的答案。
示例 1:

输入:grid = [[1,2,4],[3,3,1]]
输出:8
解释:上图展示在每一步中需要移除的值。
- 在第一步操作中,从第一行删除 4 ,从第二行删除 3(注意,有两个单元格中的值为 3 ,我们可以删除任一)。在答案上加 4 。
- 在第二步操作中,从第一行删除 2 ,从第二行删除 3 。在答案上加 3 。
- 在第三步操作中,从第一行删除 1 ,从第二行删除 1 。在答案上加 1 。
最终,答案 = 4 + 3 + 1 = 8 。示例 2:

输入:grid = [[10]]
输出:10
解释:上图展示在每一步中需要移除的值。
- 在第一步操作中,从第一行删除 10 。在答案上加 10 。
最终,答案 = 10 。提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 501 <= grid[i][j] <= 100
cpp
class Solution {
public:
int deleteGreatestValue(vector<vector<int>>& grid) {
for(auto &gi:grid)sort(gi.begin(),gi.end());
auto ans=grid[0];
for(auto gi:grid){
for(int i=0;i<ans.size();i++)ans[i]=max(ans[i],gi[i]);
}
int s=0;
for(auto x:ans)s+=x;
return s;
}
};2506. 统计相似字符串对的数目
给你一个下标从 0 开始的字符串数组 words 。
如果两个字符串由相同的字符组成,则认为这两个字符串 相似 。
- 例如,
"abca"和"cba"相似,因为它们都由字符'a'、'b'、'c'组成。 - 然而,
"abacba"和"bcfd"不相似,因为它们不是相同字符组成的。
请你找出满足字符串 words[i]和words[j] 相似的下标对(i, j),并返回下标对的数目,其中 0 <= i < j <= words.length - 1 。
示例 1:
输入:words = ["aba","aabb","abcd","bac","aabc"]
输出:2
解释:共有 2 对满足条件:
- i = 0 且 j = 1 :words[0] 和 words[1] 只由字符 'a' 和 'b' 组成。
- i = 3 且 j = 4 :words[3] 和 words[4] 只由字符 'a'、'b' 和 'c' 。 示例 2:
输入:words = ["aabb","ab","ba"]
输出:3
解释:共有 3 对满足条件:
- i = 0 且 j = 1 :words[0] 和 words[1] 只由字符 'a' 和 'b' 组成。
- i = 0 且 j = 2 :words[0] 和 words[2] 只由字符 'a' 和 'b' 组成。
- i = 1 且 j = 2 :words[1] 和 words[2] 只由字符 'a' 和 'b' 组成。 示例 3:
输入:words = ["nba","cba","dba"]
输出:0
解释:不存在满足条件的下标对,返回 0 。提示:
1 <= words.length <= 1001 <= words[i].length <= 100words[i]仅由小写英文字母组成
cpp
class Solution {
public:
int hash(string s)
{
int x = 0;
char a = 'a';
for (auto c : s)x |= 1 << (c - a);
return x;
}
int similarPairs(vector<string>& words) {
map<int, int>m;
for (auto str : words)m[hash(str)]++;
int ans = 0;
for (auto mi : m) {
ans += mi.second*(mi.second - 1) / 2;
}
return ans;
}
};2507. 使用质因数之和替换后可以取到的最小值
2509. 查询树中环的长度
2512. 奖励最顶尖的 K 名学生
2513. 最小化两个数组中的最大值
2514. 统计同位异构字符串数目
2515. 到目标字符串的最短距离
给你一个下标从 0 开始的 环形 字符串数组 words 和一个字符串 target 。环形数组 意味着数组首尾相连。
- 形式上,
words[i]的下一个元素是words[(i + 1) % n],而words[i]的前一个元素是words[(i - 1 + n) % n],其中n是words的长度。
从 startIndex 开始,你一次可以用 1 步移动到下一个或者前一个单词。
返回到达目标字符串 target 所需的最短距离。如果 words 中不存在字符串 target ,返回 -1 。
示例 1:
输入:words = ["hello","i","am","leetcode","hello"], target = "hello", startIndex = 1
输出:1
解释:从下标 1 开始,可以经由以下步骤到达 "hello" :
- 向右移动 3 个单位,到达下标 4 。
- 向左移动 2 个单位,到达下标 4 。
- 向右移动 4 个单位,到达下标 0 。
- 向左移动 1 个单位,到达下标 0 。
到达 "hello" 的最短距离是 1 。示例 2:
输入:words = ["a","b","leetcode"], target = "leetcode", startIndex = 0
输出:1
解释:从下标 0 开始,可以经由以下步骤到达 "leetcode" :
- 向右移动 2 个单位,到达下标 2 。
- 向左移动 1 个单位,到达下标 2 。
到达 "leetcode" 的最短距离是 1 。示例 3:
输入:words = ["i","eat","leetcode"], target = "ate", startIndex = 0
输出:-1
解释:因为 words 中不存在字符串 "ate" ,所以返回 -1 。提示:
1 <= words.length <= 1001 <= words[i].length <= 100words[i]和target仅由小写英文字母组成0 <= startIndex < words.length
cpp
class Solution {
public:
int closestTarget(vector<string>& words, string target, int startIndex) {
if (words[startIndex] == target)return 0;
int i = startIndex, j = startIndex, n = words.size();
while (true)
{
i = (i + n - 1) % n;
if (i == j)break;
if (words[i] == target)return getLen(n, startIndex, i);
j = (j + 1) % n;
if (i == j)break;
if (words[j] == target)return getLen(n, startIndex, j);
}
return -1;
}
int getLen(int n, int startIndex, int id)
{
if (id <= startIndex)return min(startIndex - id, id + n - startIndex);
return getLen(n, id, startIndex);
}
};2520. 统计能整除数字的位数
给你一个整数 num ,返回 num 中能整除 num 的数位的数目。
如果满足 nums % val == 0 ,则认为整数 val 可以整除 nums 。
示例 1:
输入:num = 7
输出:1
解释:7 被自己整除,因此答案是 1 。示例 2:
输入:num = 121
输出:2
解释:121 可以被 1 整除,但无法被 2 整除。由于 1 出现两次,所以返回 2 。示例 3:
输入:num = 1248
输出:4
解释:1248 可以被它每一位上的数字整除,因此答案是 4 。提示:
1 <= num <= 109num的数位中不含0
cpp
class Solution {
public:
int countDigits(int num) {
int ans = 0, d = num;
while (d) {
if (num % (d % 10) == 0)ans++;
d /= 10;
}
return ans;
}
};2521. 数组乘积中的不同质因数数目
2523. 范围内最接近的两个质数
2525. 根据规则将箱子分类
2526. 找到数据流中的连续整数
2527. 查询数组 Xor 美丽值
2529. 正整数和负整数的最大计数
2530. 执行 K 次操作后的最大分数
给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。你的 起始分数 为 0 。
在一步 操作 中:
- 选出一个满足
0 <= i < nums.length的下标i, - 将你的 分数 增加
nums[i],并且 - 将
nums[i]替换为ceil(nums[i] / 3)。
返回在 恰好 执行 k 次操作后,你可能获得的最大分数。
向上取整函数 ceil(val) 的结果是大于或等于 val 的最小整数。
示例 1:
输入:nums = [10,10,10,10,10], k = 5
输出:50
解释:对数组中每个元素执行一次操作。最后分数是 10 + 10 + 10 + 10 + 10 = 50 。示例 2:
输入:nums = [1,10,3,3,3], k = 3
输出:17
解释:可以执行下述操作:
第 1 步操作:选中 i = 1 ,nums 变为 [1,4,3,3,3] 。分数增加 10 。
第 2 步操作:选中 i = 1 ,nums 变为 [1,2,3,3,3] 。分数增加 4 。
第 3 步操作:选中 i = 2 ,nums 变为 [1,1,1,3,3] 。分数增加 3 。
最后分数是 10 + 4 + 3 = 17 。提示:
1 <= nums.length, k <= 1051 <= nums[i] <= 109
cpp
class Solution {
public:
long long maxKelements(vector<int>& nums, int k) {
priority_queue<int>q;
for (auto x : nums)q.push(x);
long long ans = 0;
while (k--) {
int x = q.top();
ans += x;
q.pop();
q.push((x + 2) / 3);
}
return ans;
}
};2536. 子矩阵元素加 1
2543. 判断一个点是否可以到达
2544. 交替数字和
2545. 根据第 K 场考试的分数排序
班里有 m 位学生,共计划组织 n 场考试。给你一个下标从 0 开始、大小为 m x n 的整数矩阵 score ,其中每一行对应一位学生,而 score[i][j] 表示第 i 位学生在第 j 场考试取得的分数。矩阵 score 包含的整数 互不相同 。
另给你一个整数 k 。请你按第 k 场考试分数从高到低完成对这些学生(矩阵中的行)的排序。
返回排序后的矩阵。
示例 1:
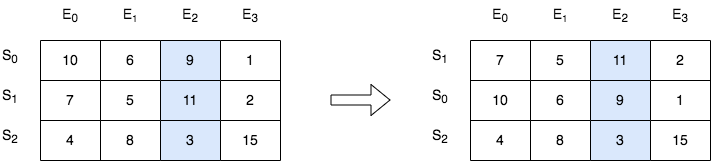
输入:score = [[10,6,9,1],[7,5,11,2],[4,8,3,15]], k = 2
输出:[[7,5,11,2],[10,6,9,1],[4,8,3,15]]
解释:在上图中,S 表示学生,E 表示考试。
- 下标为 1 的学生在第 2 场考试取得的分数为 11 ,这是考试的最高分,所以 TA 需要排在第一。
- 下标为 0 的学生在第 2 场考试取得的分数为 9 ,这是考试的第二高分,所以 TA 需要排在第二。
- 下标为 2 的学生在第 2 场考试取得的分数为 3 ,这是考试的最低分,所以 TA 需要排在第三。示例 2:
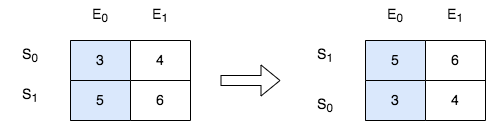
输入:score = [[3,4],[5,6]], k = 0
输出:[[5,6],[3,4]]
解释:在上图中,S 表示学生,E 表示考试。
- 下标为 1 的学生在第 0 场考试取得的分数为 5 ,这是考试的最高分,所以 TA 需要排在第一。
- 下标为 0 的学生在第 0 场考试取得的分数为 3 ,这是考试的最低分,所以 TA 需要排在第二。提示:
m == score.lengthn == score[i].length1 <= m, n <= 2501 <= score[i][j] <= 105score由 不同 的整数组成0 <= k < n
cpp
#define Frev SingleVectorOpt::frev//翻转vector、翻转二维vector的每一行
#define SortId VectorOpt::sortId//排序后数组中的每个数的原ID,输入8 5 6 7,输出1 2 3 0
class Solution {
public:
vector<vector<int>> sortTheStudents(vector<vector<int>>& score, int k) {
vector<int>v;
for (auto &vi : score)v.push_back(vi[k]);
auto ids = SortId(v);
vector<vector<int>>ans;
for(auto id:ids)ans.push_back(score[id]);
return Frev<vector<int>>(ans);
}
};2549. 统计桌面上的不同数字
给你一个正整数 n ,开始时,它放在桌面上。在 109 天内,每天都要执行下述步骤:
- 对于出现在桌面上的每个数字
x,找出符合1 <= i <= n且满足x % i == 1的所有数字i。 - 然后,将这些数字放在桌面上。
返回在 109 天之后,出现在桌面上的 不同 整数的数目。
注意:
- 一旦数字放在桌面上,则会一直保留直到结束。
%表示取余运算。例如,14 % 3等于2。
示例 1:
输入:n = 5
输出:4
解释:最开始,5 在桌面上。
第二天,2 和 4 也出现在桌面上,因为 5 % 2 == 1 且 5 % 4 == 1 。
再过一天 3 也出现在桌面上,因为 4 % 3 == 1 。
在十亿天结束时,桌面上的不同数字有 2 、3 、4 、5 。示例 2:
输入:n = 3
输出:2
解释:
因为 3 % 2 == 1 ,2 也出现在桌面上。
在十亿天结束时,桌面上的不同数字只有两个:2 和 3 。 提示:
1 <= n <= 100
cpp
class Solution {
public:
int distinctIntegers(int n) {
if(n==1)return 1;
return n-1;
}
};2551. 将珠子放入背包中
你有 k 个背包。给你一个下标从 0 开始的整数数组 weights ,其中 weights[i] 是第 i 个珠子的重量。同时给你整数 k 。
请你按照如下规则将所有的珠子放进 k 个背包。
- 没有背包是空的。
- 如果第
i个珠子和第j个珠子在同一个背包里,那么下标在i到j之间的所有珠子都必须在这同一个背包中。 - 如果一个背包有下标从
i到j的所有珠子,那么这个背包的价格是weights[i] + weights[j]。
一个珠子分配方案的 分数 是所有 k 个背包的价格之和。
请你返回所有分配方案中,最大分数 与 最小分数 的 差值 为多少。
示例 1:
输入:weights = [1,3,5,1], k = 2
输出:4
解释:
分配方案 [1],[3,5,1] 得到最小得分 (1+1) + (3+1) = 6 。
分配方案 [1,3],[5,1] 得到最大得分 (1+3) + (5+1) = 10 。
所以差值为 10 - 6 = 4 。示例 2:
输入:weights = [1, 3], k = 2
输出:0
解释:唯一的分配方案为 [1],[3] 。
最大最小得分相等,所以返回 0 。提示:
1 <= k <= weights.length <= 1051 <= weights[i] <= 109
cpp
class Solution {
public:
long long putMarbles(vector<int>& weights, int k) {
for (int i = weights.size() - 1; i; i--)weights[i] += weights[i - 1];
sort(weights.begin() + 1, weights.end());
long long ans = 0;
for (int i = 1; i <= k - 1; i++)ans -= weights[i];
for (int i = weights.size() - k + 1; i < weights.size(); i++)ans += weights[i];
return ans;
}
};2554. 从一个范围内选择最多整数 I
给你一个整数数组 banned 和两个整数 n 和 maxSum 。你需要按照以下规则选择一些整数:
- 被选择整数的范围是
[1, n]。 - 每个整数 至多 选择 一次 。
- 被选择整数不能在数组
banned中。 - 被选择整数的和不超过
maxSum。
请你返回按照上述规则 最多 可以选择的整数数目。
示例 1:
输入:banned = [1,6,5], n = 5, maxSum = 6
输出:2
解释:你可以选择整数 2 和 4 。
2 和 4 在范围 [1, 5] 内,且它们都不在 banned 中,它们的和是 6 ,没有超过 maxSum 。示例 2:
输入:banned = [1,2,3,4,5,6,7], n = 8, maxSum = 1
输出:0
解释:按照上述规则无法选择任何整数。示例 3:
输入:banned = [11], n = 7, maxSum = 50
输出:7
解释:你可以选择整数 1, 2, 3, 4, 5, 6 和 7 。
它们都在范围 [1, 7] 中,且都没出现在 banned 中,它们的和是 28 ,没有超过 maxSum 。提示:
1 <= banned.length <= 1041 <= banned[i], n <= 1041 <= maxSum <= 109
cpp
class Solution {
public:
int maxCount(vector<int>& banned, int n, int maxSum) {
map<int,int>m;
for(auto x:banned)m[x]=1;
int ans=0;
for(int i=1;i<=n;i++){
if(m[i])continue;
maxSum-=i;
if(maxSum>=0)ans++;
else break;
}
return ans;
}
};2557. 从一个范围内选择最多整数 II
2558. 从数量最多的堆取走礼物
给你一个整数数组 gifts ,表示各堆礼物的数量。每一秒,你需要执行以下操作:
- 选择礼物数量最多的那一堆。
- 如果不止一堆都符合礼物数量最多,从中选择任一堆即可。
- 选中的那一堆留下平方根数量的礼物(向下取整),取走其他的礼物。
返回在 k 秒后剩下的礼物数量*。*
示例 1:
输入:gifts = [25,64,9,4,100], k = 4
输出:29
解释:
按下述方式取走礼物:
- 在第一秒,选中最后一堆,剩下 10 个礼物。
- 接着第二秒选中第二堆礼物,剩下 8 个礼物。
- 然后选中第一堆礼物,剩下 5 个礼物。
- 最后,再次选中最后一堆礼物,剩下 3 个礼物。
最后剩下的礼物数量分别是 [5,8,9,4,3] ,所以,剩下礼物的总数量是 29 。示例 2:
输入:gifts = [1,1,1,1], k = 4
输出:4
解释:
在本例中,不管选中哪一堆礼物,都必须剩下 1 个礼物。
也就是说,你无法获取任一堆中的礼物。
所以,剩下礼物的总数量是 4 。提示:
1 <= gifts.length <= 1031 <= gifts[i] <= 1091 <= k <= 103
cpp
class Solution {
public:
long long pickGifts(vector<int>& gifts, int k) {
priority_queue<int>q;
long long ans=0;
for(auto x:gifts)q.push(x),ans+=x;
while(k--){
int x=q.top();
int y=int(sqrt(x*1.0));
ans-=x-y;
q.pop();
q.push(y);
}
return ans;
}
};2561. 重排水果
2568. 最小无法得到的或值
2575. 找出字符串的可整除数组
给你一个下标从 0 开始的字符串 word ,长度为 n ,由从 0 到 9 的数字组成。另给你一个正整数 m 。
word 的 可整除数组 div 是一个长度为 n 的整数数组,并满足:
- 如果
word[0,...,i]所表示的 数值 能被m整除,div[i] = 1 - 否则,
div[i] = 0
返回word 的可整除数组。
示例 1:
输入:word = "998244353", m = 3
输出:[1,1,0,0,0,1,1,0,0]
解释:仅有 4 个前缀可以被 3 整除:"9"、"99"、"998244" 和 "9982443" 。示例 2:
输入:word = "1010", m = 10
输出:[0,1,0,1]
解释:仅有 2 个前缀可以被 10 整除:"10" 和 "1010" 。提示:
1 <= n <= 105word.length == nword由数字0到9组成1 <= m <= 109
cpp
class Solution {
public:
vector<int> divisibilityArray(string word, int m) {
vector<int>ans;
long long s=0;
for(auto c:word){
s=(s*10+c-'0')%m;
ans.push_back(s==0);
}
return ans;
}
};2576. 求出最多标记下标
给你一个下标从 0 开始的整数数组 nums 。
一开始,所有下标都没有被标记。你可以执行以下操作任意次:
- 选择两个 互不相同且未标记 的下标
i和j,满足2 * nums[i] <= nums[j],标记下标i和j。
请你执行上述操作任意次,返回nums 中最多可以标记的下标数目。
示例 1:
输入:nums = [3,5,2,4]
输出:2
解释:第一次操作中,选择 i = 2 和 j = 1 ,操作可以执行的原因是 2 * nums[2] <= nums[1] ,标记下标 2 和 1 。
没有其他更多可执行的操作,所以答案为 2 。示例 2:
输入:nums = [9,2,5,4]
输出:4
解释:第一次操作中,选择 i = 3 和 j = 0 ,操作可以执行的原因是 2 * nums[3] <= nums[0] ,标记下标 3 和 0 。
第二次操作中,选择 i = 1 和 j = 2 ,操作可以执行的原因是 2 * nums[1] <= nums[2] ,标记下标 1 和 2 。
没有其他更多可执行的操作,所以答案为 4 。示例 3:
输入:nums = [7,6,8]
输出:0
解释:没有任何可以执行的操作,所以答案为 0 。提示:
1 <= nums.length <= 1051 <= nums[i] <= 109
cpp
class Solution {
public:
int maxNumOfMarkedIndices(vector<int>& nums) {
sort(nums.begin(), nums.end());
int ans = 0;
for (int i = 0, j = nums.size() / 2; i < nums.size() / 2;i++,j++) {
while (j < nums.size() && nums[j] < nums[i] * 2)j++;
if (j == nums.size())return ans;
ans += 2;
}
return ans;
}
};2580. 统计将重叠区间合并成组的方案数
2581. 统计可能的树根数目
2582. 递枕头
2583. 二叉树中的第 K 大层和
2584. 分割数组使乘积互质
2586. 统计范围内的元音字符串数
2589. 完成所有任务的最少时间
2591. 将钱分给最多的儿童
给你一个整数 money ,表示你总共有的钱数(单位为美元)和另一个整数 children ,表示你要将钱分配给多少个儿童。
你需要按照如下规则分配:
- 所有的钱都必须被分配。
- 每个儿童至少获得
1美元。 - 没有人获得
4美元。
请你按照上述规则分配金钱,并返回 最多 有多少个儿童获得 恰好 8 美元。如果没有任何分配方案,返回 -1 。
示例 1:
输入:money = 20, children = 3
输出:1
解释:
最多获得 8 美元的儿童数为 1 。一种分配方案为:
- 给第一个儿童分配 8 美元。
- 给第二个儿童分配 9 美元。
- 给第三个儿童分配 3 美元。
没有分配方案能让获得 8 美元的儿童数超过 1 。示例 2:
输入:money = 16, children = 2
输出:2
解释:每个儿童都可以获得 8 美元。提示:
1 <= money <= 2002 <= children <= 30
cpp
class Solution {
public:
int distMoney(int money, int children) {
if(money<children)return -1;
if(money>children*8)return children-1;
int ans=(money-children)/7;
if(children*8-4==money && ans>0)ans--;
return ans;
}
};2595. 奇偶位数
给你一个 正 整数 n 。
用 even 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的偶数下标的个数。
用 odd 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的奇数下标的个数。
请注意,在数字的二进制表示中,位下标的顺序 从右到左。
返回整数数组answer,其中answer = [even, odd] 。
示例 1:
**输入:**n = 50
输出:1,2
解释:
50 的二进制表示是 110010。
在下标 1,4,5 对应的值为 1。
示例 2:
**输入:**n = 2
输出:0,1
解释:
2 的二进制表示是 10。
只有下标 1 对应的值为 1。
提示:
1 <= n <= 1000
cpp
class Solution {
public:
vector<int> evenOddBit(int n) {
int even=0,odd=0;
while(n){
if(n&1)even++;
n>>=1;
if(n&1)odd++;
n>>=1;
}
return vector<int>{even,odd};
}
};2597. 美丽子集的数目
2598. 执行操作后的最大 MEX
2599. 使前缀和数组非负
给定一个 下标从0开始 的整数数组 nums 。你可以任意多次执行以下操作:
- 从
nums中选择任意一个元素,并将其放到nums的末尾。
nums 的前缀和数组是一个与 nums 长度相同的数组 prefix ,其中 prefix[i] 是所有整数 nums[j](其中 j 在包括区间 [0,i] 内)的总和。
返回使前缀和数组不包含负整数的最小操作次数。测试用例的生成方式保证始终可以使前缀和数组非负。
示例 1 :
输入:nums = [2,3,-5,4]
输出:0
解释:我们不需要执行任何操作。
给定数组为 [2, 3, -5, 4],它的前缀和数组是 [2, 5, 0, 4]。示例 2 :
输入:nums = [3,-5,-2,6]
输出:1
解释:我们可以对索引为1的元素执行一次操作。
操作后的数组为 [3, -2, 6, -5],它的前缀和数组是 [3, 1, 7, 2]。提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
cpp
class Solution {
public:
int makePrefSumNonNegative(vector<int>& v) {
priority_queue<int,vector<int>, greater<int>>q;
long long ans = 0, s = 0;
for (auto x:v) {
s += x;
q.push(x);
if (s<0) {
ans++;
s -= q.top();
q.pop();
}
}
return ans;
}
};