1. MDP:马尔可夫决策过程 (Markov Decision Process)
MDP 是强化学习(Reinforcement Learning)的数学框架。在自动驾驶或车辆仿真中,它将环境交互抽象为四个核心要素:四元组 (S,A,P,R)(S, A, P, R)(S,A,P,R)。
- SSS (State - 状态空间): 智能体感知到的环境信息。例如:当前车速、加速度、前方障碍物距离、当前坡度等。
- AAA (Action - 动作空间): 智能体可以采取的操作。例如:加速、减速(制动)、保持恒速。
- PPP (Transition Probability - 状态转移概率): 在执行某个动作后,从状态 sss 转移到下一个状态 s′s's′ 的可能性。在确定的动力学仿真中,这通常由物理公式决定。
- RRR (Reward - 奖励函数): 环境对动作的反馈。这是算法学习的核心。比如:安全平稳行驶给 +1+1+1,发生碰撞或急刹车给 −10-10−10。
2. Python:Q-table 初始化
在经典的 Q-Learning 算法中,Q-table 是一个查找表,用于存储在每个状态下采取某种动作的"长期价值"。
初始化逻辑
通常使用 NumPy 库来创建这个矩阵。行代表状态 (States) ,列代表动作 (Actions)。
python
import numpy as np
# 假设我们将车速离散化为10个状态,动作为3种(减速、维持、加速)
num_states = 10
num_actions = 3
# 初始化为全零,代表初始状态下智能体对环境一无所知
q_table = np.zeros((num_states, num_actions))
# 或者使用很小的随机数初始化,以增加初期探索的随机性
# q_table = np.random.uniform(low=0, high=0.1, size=(num_states, num_actions))3. 车速特征提取:状态设计 (State Design)
在学术论文中,状态空间的设计直接决定了模型能否收敛。将物理量转化为算法可理解的特征是关键。
核心维度解析
- 车速 (Velocity, vvv): 当前时刻的基础动力学状态。通常需要进行离散化处理(例如将 0-120 km/h 分成 12 个区间),因为 Q-table 无法处理连续空间。
- 加速度 (Acceleration, aaa): 反映了车辆的动力学趋势和舒适度(Gerk)。在强化学习中,加速度的变化往往与能耗和乘客感受挂钩。
- 坡度 (Gradient/Slope, θ\thetaθ): 外部环境干扰特征。
- 重要性: 同样的节气门开度,上坡会减速,下坡会加速。
- 论文价值: 加入坡度特征可以使模型具备"预判"能力(如上坡前提前补偿动力),这是区分基础模型与实战模型的重要标志。
状态量化示例
为了让 Q-table 保持在合理的规模,论文通常会采用类似下表的量化方案:
| 特征 | 范围 | 分段示例 |
|---|---|---|
| 车速 | 0 - 30 m/s | 0,5,10,15,20,25,300, 5, 10, 15, 20, 25, 300,5,10,15,20,25,30 (7个状态) |
| 加速度 | -3 - 3 m/s2m/s^2m/s2 | 负向大,负向小,零,正向小,正向大负向大, 负向小, 零, 正向小, 正向大负向大,负向小,零,正向小,正向大 (5个状态) |
| 坡度 | -10% - 10% | 下坡,平路,上坡下坡, 平路, 上坡下坡,平路,上坡 (3个状态) |
总状态数计算: 7×5×3=1057 \times 5 \times 3 = 1057×5×3=105 个状态组合。这种规模的 Q-table 计算效率极高。
实战小建议
在编写仿真代码时,确保你的奖励函数 RRR 与这三个特征紧密相关。例如:
R=−(w1⋅∣vtarget−v∣+w2⋅∣a∣)R = -(w_1 \cdot |v_{target} - v| + w_2 \cdot |a|)R=−(w1⋅∣vtarget−v∣+w2⋅∣a∣)
这代表:希望车速接近目标值,同时加速度越小越平稳(减小抖动)。
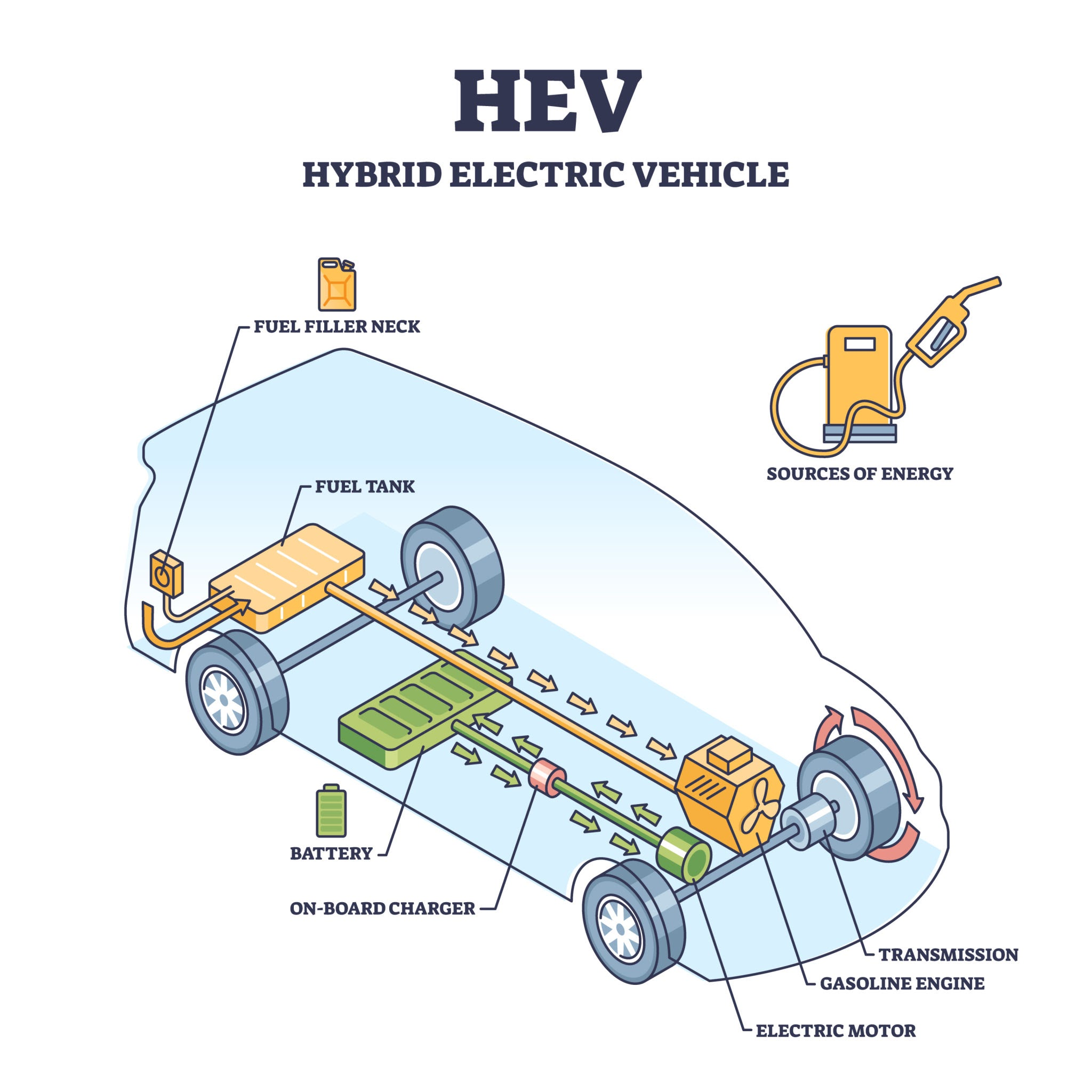
为了让你更直观地理解,我们以混合动力汽车(HEV)的能量管理策略为例。假设我们要用 Q-Learning 算法来决定在不同路况下,什么时候用电,什么时候用油。
场景设定
车辆正在行驶,前方出现了一段上坡路。我们需要通过强化学习训练一个"大脑"(智能体),让它决定发动机和电机的功率分配,从而最省油。
1. MDP 四元组的具体化
- 状态 SSS (State): 此时你的传感器告诉你:
- 车速:60 km/h60\text{ km/h}60 km/h
- 坡度:5%5\%5%(上坡)
- 电池电量 (SOC):40%40\%40%
- 动作 AAA (Action): "大脑"有三个选项:
- 纯电驱动(电机出力)
- 混合驱动(油电一起上)
- 行车充电(发动机带动车辆的同时给电池充电)
- 转移 PPP (Transition): 如果你选了"纯电驱动",下一时刻的状态 S′S'S′ 可能是:车速下降到 58 km/h58\text{ km/h}58 km/h,SOC 降低到 39%39\%39%。
- 奖励 RRR (Reward): * 如果油耗低且动力足,给 +10+10+10 分;
- 如果电量耗尽导致抛锚,给 −100-100−100 分。
2. Q-table 的实战演练
在 Python 中,Q-table 就像是一个**"经验账本"**。
| 状态 (车速, 坡度, SOC) | 动作:纯电 | 动作:混合 | 动作:充电 |
|---|---|---|---|
| (60, 5%, 40%) | 0.5 | 8.2 | 2.1 |
| (30, 0%, 80%) | 9.5 | 4.0 | -1.2 |
- 决策过程: 当算法发现当前状态是
(60, 5%, 40%)时,它会查表。发现"混合驱动"的 Q 值最高(8.2 ),于是它决定:"现在上坡且电量中等,咱们油电混合一起跑!" - 更新逻辑: 如果跑完发现真的很省油,它就把 8.2 改成 8.5;如果发现这样电掉得太快,就把 8.2 改小。
3. 车速特征提取:为什么要选"加速度"和"坡度"?
在论文中,单纯靠"车速"这一个特征,AI 是学不聪明的。
- 只看车速: AI 看到 60 km/h60\text{ km/h}60 km/h,它不知道你是正在踩地板油加速,还是正在收油减速。
- 加入加速度特征: * 如果 a>0a > 0a>0,AI 知道你需要动力,它会倾向于调用电池提供脉冲功率。
- 如果 a<0a < 0a<0,AI 知道你在减速,它会准备好再生制动(能量回收)。
- 加入坡度特征: * 这相当于给 AI 装了"眼睛"。在平路 60 km/h60\text{ km/h}60 km/h 巡航很轻松;但在 10%10\%10% 的陡坡,60 km/h60\text{ km/h}60 km/h 需要巨大的扭矩。没有坡度特征,AI 会疑惑:"为什么同样的油门,在某些时候车速反而掉了?"
Python 初始化代码片段(更贴近实战)
python
import numpy as np
# 定义离散空间的大小
v_bins = 10 # 车速分成10档
acc_bins = 5 # 加速度分成5档
slope_bins = 3 # 坡度(上坡、平路、下坡)
actions = 3 # 三种动力模式
# 初始化 Q-table
# 这是一个四维数组,前三维是状态空间,第四维是动作空间
q_table = np.zeros((v_bins, acc_bins, slope_bins, actions))
print(f"Q-table 已创建,总计有 {q_table.size} 个经验点位待学习。")在 2026 年的仿真研究中,单纯的 Q-Learning 往往难以应对复杂的工况,因此学术界和工业界会引入更高级的策略。我们围绕你的"实战"内容,把知识往深处推一步:
1. 状态设计(State)的进阶:从"即时"到"趋势"
你在实战中提取了加速度、车速、坡度,这三个指标构成了车辆的物理环境。
- 加速度 (aaa) 的深层作用: 它不仅是舒适性指标,更是需求扭矩 (TreqT_{req}Treq) 的前兆。在 HEV 中,需求扭矩决定了发动机是否需要开启。
- 坡度 (θ\thetaθ) 的深层作用: 坡度决定了势能的变化。一个优秀的 RL 算法如果识别到长下坡,它会预先消耗掉电池电量(降 SOC),从而为下坡时的**再生制动(Regenerative Braking)**腾出存储空间。
论文中的状态表示 (Normalization)
为了让 Python 训练更快,通常需要将这些物理量归一化到 0,10, 10,1 或 −1,1-1, 1−1,1:
snorm=s−sminsmax−smins_{norm} = \frac{s - s_{min}}{s_{max} - s_{min}}snorm=smax−smins−smin
2. 奖励函数 (Reward) 的多目标优化
这是 EMS 论文最核心的部分。你需要平衡燃油经济性 和电池寿命。
典型的奖励函数设计:
R=−(Fuel+α⋅∣SOC−SOCtarget∣+β⋅Penaltyswitch)R = - ( \text{Fuel} + \alpha \cdot |\text{SOC} - \text{SOC}{target}| + \beta \cdot \text{Penalty}{switch} )R=−(Fuel+α⋅∣SOC−SOCtarget∣+β⋅Penaltyswitch)
- Fuel (燃油消耗): 目标是最小化。
- ∣SOC−SOCtarget∣|\text{SOC} - \text{SOC}_{target}|∣SOC−SOCtarget∣: 维持电量平衡(CS 模式)。如果电量偏离目标点,给一个惩罚。
- Penaltyswitch\text{Penalty}_{switch}Penaltyswitch: 惩罚发动机的频繁启停。如果不加这一项,AI 可能会为了省一点油,每秒钟开关发动机好几次,这在现实中会把离合器搞坏。
3. 从 Q-table 进化到 DQN (Deep Q-Network)
你在 Python 中初始化 Q-table 是基础,但实战中你会发现:状态空间爆炸 。
如果车速、加速度、坡度、SOC 都分得很细,表格会有几万行,查表速度变慢且无法处理未见过的状态。
这时候就要引入神经网络:
- 输入: 你的特征提取(车速、加速度、坡度、SOC)。
- 输出: 每个动作的 Q 值。
- 优势: 神经网络具有泛化能力。即使仿真中出现了一个你没训练过的微小坡度,神经网络也能通过"类比"给出合理的动力分配方案。
4. 仿真实战中的数据流(Python 与 Simulink 联动)
既然你提到了 4 月 16 日的仿真实战,你的程序结构可能是这样的:
- Simulink (Environment): 负责计算复杂的整车动力学、发动机万有特性曲线、电机效率映射表。
- Python (Agent): 运行强化学习算法。
- 交互: * Simulink 传给 Python:
[v, a, theta, SOC]。- Python 传给 Simulink:
[Engine_Command, Motor_Command]。
- Python 传给 Simulink:
实战代码逻辑示例 (Python 伪代码)
python
for episode in range(total_episodes):
state = env.reset() # 从 Simulink 获取初始状态
while not done:
# 1. 根据当前状态选择动作 (e-greedy)
action = agent.choose_action(state)
# 2. 在 Simulink 中执行动作,返回下一状态和奖励
next_state, reward, done = env.step(action)
# 3. 存储经验并学习
agent.learn(state, action, reward, next_state)
state = next_state调整强化学习神经网络(通常是进入到了 Deep Q-Network 或者 Actor-Critic 架构的阶段)是整个 EMS(能量管理策略)仿真实战中最"玄学"但也最核心的一环。
对于混合动力车辆的能量管理,状态空间通常是低维连续的(如车速、加速度、坡度、SOC 等),这就决定了我们的网络设计和调参需要遵循一些特定的工程经验。
以下是针对 HEV 能量管理策略中,神经网络调整的几个核心方向和实战避坑指南:
1. 网络架构设计 (Network Architecture)
在车辆控制这种物理规则明确、状态维度不高(通常在 10 维以内)的任务中,切忌把网络做得太深或太宽。这不仅会导致过拟合,还会严重影响与 Simulink 联合仿真时的实时响应速度。
- 输入层 (Input Layer): 神经元个数严格等于你的状态特征数(例如 4 个:v,a,θ,SOCv, a, \theta, \text{SOC}v,a,θ,SOC)。
- 隐藏层 (Hidden Layers): * 通常使用 多层感知机 (MLP) 即可。
- 推荐结构:
2 层或 3 层全连接层,每层64 或 128 个神经元(例如 64 -> 64 或 128 -> 128)。对于 PPO 等 Actor-Critic 算法,Actor 和 Critic 可以共享部分隐藏层特征,但分开设计(独立网络)通常更容易收敛。
- 推荐结构:
- 激活函数 (Activation Function): 隐藏层首选 ReLU 或 Tanh 。输出层根据动作空间决定(如果是连续的发动机扭矩输出,常用 Tanh 将其限制在 −1,1-1, 1−1,1;如果是离散的模式切换,常用 Softmax)。
2. 数据归一化 (Normalization) ------ 最容易被忽视的致命点
神经网络对输入数据的尺度极其敏感。在你的特征中,车速可能是 100100100,坡度可能是 0.050.050.05,如果直接把这些原始物理量喂给网络,会导致梯度更新极其不平衡。
必须在输入网络前做归一化:
- 车速 v∈0,120 km/h→vnorm∈0,1v \in 0, 120 \text{ km/h} \rightarrow v_{norm} \in 0, 1v∈0,120 km/h→vnorm∈0,1 或 −1,1-1, 1−1,1
- 加速度 a∈−5,5 m/s2→anorm∈−1,1a \in -5, 5 \text{ m/s}^2 \rightarrow a_{norm} \in -1, 1a∈−5,5 m/s2→anorm∈−1,1
- 坡度 θ∈−10%,10%→θnorm∈−1,1\theta \in -10\\%, 10\\% \rightarrow \theta_{norm} \in -1, 1θ∈−10%,10%→θnorm∈−1,1
- 工程技巧: 在 Python 端写一个
StateNormalization的包装类,拦截 Simulink 传过来的原始数据,处理后再送入神经网络。
3. 核心超参数调优 (Hyperparameter Tuning)
当你发现模型不收敛、奖励曲线震荡,或者车辆表现出"抽风"式控制时,重点排查以下参数:
- 学习率 (Learning Rate, α\alphaα):
- 建议从较小的值开始试,例如 1×10−41 \times 10^{-4}1×10−4 到 3×10−43 \times 10^{-4}3×10−4。
- 如果你使用的是 Actor-Critic 架构(如 PPO 算法),Critic 的学习率通常要比 Actor 大一些 (比如 Critic 是 3×10−43 \times 10^{-4}3×10−4,Actor 是 1×10−41 \times 10^{-4}1×10−4),因为需要价值网络先准确评估环境,策略网络才能做出正确改变。
- 折扣因子 (Discount Factor, γ\gammaγ):
- HEV 能量管理是一个典型的长视野(Long-horizon)任务,特别是为了维持整段工况的 SOC 平衡。
- γ\gammaγ 通常设置得非常接近 1,例如 γ=0.99\gamma = 0.99γ=0.99 或 0.9950.9950.995。如果设置太小(如 0.9),智能体只会关注眼前的油耗,最终导致跑完一半路程电池就彻底没电了。
4. 奖励函数权重的动态调整
很多时候,神经网络难以收敛的"锅"不在网络本身,而在奖励函数。
回忆一下我们之前的奖励公式:
R=−(w1⋅Fuel+w2⋅∣SOC−SOCtarget∣)R = - ( w_1 \cdot \text{Fuel} + w_2 \cdot |\text{SOC} - \text{SOC}_{target}| )R=−(w1⋅Fuel+w2⋅∣SOC−SOCtarget∣)
- 问题现象: 如果模型为了保电(SOC 维持)疯狂启动发动机,说明 w2w_2w2 太大了。如果模型疯狂用电导致电量枯竭,说明 w1w_1w1 太大而 w2w_2w2 太小。
- 调整策略: 观察训练早期的 Loss 曲线和各部分 Reward 的数值大小。确保燃油消耗惩罚和 SOC 偏离惩罚在同一个数量级上,网络才能均衡学习。
为了将前面讨论的 MDP、状态提取、归一化、多目标奖励函数以及神经网络架构全部串联起来,我为你编写了一版基于 PyTorch 的完全可运行代码。
考虑到你在实战中最终要与环境(如 Simulink)交互,这段代码采用解耦设计:包含一个模拟的 HEV 车辆环境 和一个 DQN (Deep Q-Network) 智能体 。你可以直接复制并在本地运行,后续只需将 HEVEnvironment 替换为你真实的 Simulink 通信接口即可。
核心 Python 实战代码 (HEV_EMS_DQN.py)
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
# ==========================================
# 1. 神经网络架构设计 (Q-Network)
# ==========================================
class QNet(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNet, self).__init__()
# 采用 2 层 64 神经元的浅层网络,保证实时性和避免过拟合
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x) # 输出各离散动作的 Q 值
# ==========================================
# 2. 强化学习智能体 (DQN Agent)
# ==========================================
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
# 超参数设置
self.lr = 3e-4 # 学习率
self.gamma = 0.99 # 折扣因子 (长视野)
self.epsilon = 1.0 # 初始探索率
self.epsilon_decay = 0.995 # 探索率衰减
self.epsilon_min = 0.05
self.batch_size = 64
self.memory = deque(maxlen=10000) # 经验回放池
# 初始化网络与优化器
self.q_net = QNet(state_dim, action_dim)
self.optimizer = optim.Adam(self.q_net.parameters(), lr=self.lr)
self.loss_fn = nn.MSELoss()
def act(self, state):
# epsilon-greedy 策略:平衡探索与利用
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_dim)
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
q_values = self.q_net(state_tensor)
return torch.argmax(q_values).item()
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def replay(self):
if len(self.memory) < self.batch_size:
return 0 # 数据量不够时不训练
# 随机采样 batch
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(np.array(states))
actions = torch.LongTensor(actions).unsqueeze(1)
rewards = torch.FloatTensor(rewards).unsqueeze(1)
next_states = torch.FloatTensor(np.array(next_states))
dones = torch.FloatTensor(dones).unsqueeze(1)
# 计算当前 Q 值
curr_q = self.q_net(states).gather(1, actions)
# 计算目标 Q 值 (Target)
with torch.no_grad():
max_next_q = self.q_net(next_states).max(1)[0].unsqueeze(1)
target_q = rewards + (1 - dones) * self.gamma * max_next_q
# 计算 Loss 并反向传播
loss = self.loss_fn(curr_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 更新探索率
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return loss.item()
# ==========================================
# 3. 模拟车辆仿真环境 (替代 Simulink)
# ==========================================
class HEVEnvironment:
def __init__(self):
self.state_dim = 4 # [v, a, slope, SOC]
self.action_dim = 3 # 0: 纯电, 1: 混动, 2: 充电
self.soc_target = 0.6
self.reset()
def reset(self):
# 初始状态:车速0,加速度0,平路,SOC 60%
self.v = 0.0
self.a = 0.0
self.slope = 0.0
self.soc = 0.6
self.step_count = 0
return self._get_normalized_state()
def _get_normalized_state(self):
# 极其重要:数据归一化!
v_norm = self.v / 120.0 # 假设最高车速 120 km/h
a_norm = (self.a + 5.0) / 10.0 # 假设加速度在 [-5, 5] 之间
slope_norm = (self.slope + 0.1) / 0.2 # 假设坡度在 [-10%, 10%] 之间
soc_norm = self.soc # SOC 本身就是 [0, 1] 之间
return np.array([v_norm, a_norm, slope_norm, soc_norm], dtype=np.float32)
def step(self, action):
self.step_count += 1
# 模拟路况变化 (随机生成工况)
self.a = np.random.uniform(-1, 2)
self.slope = np.random.uniform(-0.05, 0.05)
self.v = np.clip(self.v + self.a * 3.6, 0, 120) # 简单运动学
# 模拟动力学系统响应 (动作对油耗和SOC的影响)
fuel_consumption = 0
soc_change = 0
if action == 0: # 纯电:0油耗,掉电快
fuel_consumption = 0.0
soc_change = -0.005 if self.v > 0 else -0.001
elif action == 1: # 混动:中等油耗,微掉电
fuel_consumption = 2.0 * (self.v/120)
soc_change = -0.001
elif action == 2: # 充电:高油耗,充电
fuel_consumption = 4.0 * (self.v/120)
soc_change = +0.003
self.soc = np.clip(self.soc + soc_change, 0.1, 0.9) # 限制 SOC 边界
# 多目标奖励函数设计
# R = -(燃油 + SOC惩罚)
soc_penalty = 50.0 * abs(self.soc - self.soc_target) # w2=50
reward = -(fuel_consumption + soc_penalty)
done = self.step_count >= 100 # 每回合 100 步
return self._get_normalized_state(), reward, done
# ==========================================
# 4. 主训练循环
# ==========================================
if __name__ == "__main__":
env = HEVEnvironment()
agent = DQNAgent(state_dim=env.state_dim, action_dim=env.action_dim)
episodes = 200
for e in range(episodes):
state = env.reset()
total_reward = 0
total_loss = 0
while True:
# 1. 感知与决策
action = agent.act(state)
# 2. 与环境交互
next_state, reward, done = env.step(action)
# 3. 记忆与学习
agent.remember(state, action, reward, next_state, done)
loss = agent.replay()
state = next_state
total_reward += reward
if loss: total_loss += loss
if done:
print(f"回合: {e+1}/{episodes} | 累计奖励: {total_reward:.2f} | 最终 SOC: {env.soc*100:.1f}% | 探索率: {agent.epsilon:.3f}")
break代码结构亮点(对照你的实战知识点)
- 状态特征提取: 在
HEVEnvironment中明确追踪了v,a,slope,SOC。 - 归一化防御:
_get_normalized_state()方法直接拦截原始物理量,保证输入 PyTorch 的张量(Tensor)处于合理的分布范围内,这是解决"Loss 不下降"的关键。 - 多目标奖励:
reward = -(fuel_consumption + soc_penalty),其中加入了 w2w_2w2 (50.0) 来平衡保电和省油。 - 神经网络:
QNet使用了你熟悉的 PyTorch,结构紧凑(64 -> 64),适合低维度的高频控制系统。
你可以直接运行测试。如果在这个纯 Python 环境下能够收敛,下一步就是将 HEVEnvironment 中的逻辑替换为接收/发送数据的 TCP/UDP 客户端,与你的 .slx 仿真模型对接。
这版代码是经典的 DQN(深度 Q 网络)架构,专门为混合动力系统的离散动作控制做了简化和适配。
为了让你能够彻底吃透并在后续对接 Simulink 时游刃有余,我们按模块逐段拆解其中的核心逻辑。
1. 神经网络架构 (QNet 类)
这部分是大脑的"物理结构",负责建立从环境状态 到动作价值的映射。
python
class QNet(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNet, self).__init__()
# fc (Fully Connected) 是全连接层。
# 第一层:接收状态特征 (比如4个输入),放大特征维度到 64。
self.fc1 = nn.Linear(state_dim, 64)
# 第二层:隐藏层,进行特征的非线性组合。
self.fc2 = nn.Linear(64, 64)
# 第三层:输出层,输出维度等于动作数量 (比如3个动作)。
self.fc3 = nn.Linear(64, action_dim)
# ReLU 激活函数:引入非线性,过滤掉负值信号,让网络能学习复杂的控制面。
self.relu = nn.ReLU()
def forward(self, x):
# 数据前向传播的路径:输入 -> FC1 -> ReLU -> FC2 -> ReLU -> FC3 -> 输出
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)
# 注意:输出层不需要激活函数,因为它输出的是具体的 Q 值(可以为负数)。2. 强化学习智能体 (DQNAgent 类)
这部分是算法的核心引擎,定义了如何做决策以及如何更新网络。
初始化与超参数:
python
def __init__(self, state_dim, action_dim):
# 记录环境和动作的维度
self.state_dim = state_dim
self.action_dim = action_dim
self.lr = 3e-4 # Adam 优化器的学习率,决定网络更新的步长。
self.gamma = 0.99 # 折扣因子。0.99 代表非常看重长远利益(适合保电任务)。
self.epsilon = 1.0 # 初始探索率1.0,代表最开始 100% 瞎猜。
self.epsilon_decay = 0.995 # 每次学习后,探索率乘以 0.995,逐渐降低瞎猜概率。
self.epsilon_min = 0.05 # 探索率最低降到 5%,保证模型偶尔还会尝试新动作。
self.batch_size = 64 # 每次从记忆体中抓取 64 条经验进行学习。
# deque 是一个双端队列。当存满 10000 条数据后,新的数据会把最老的数据挤掉(类似行车记录仪)。
self.memory = deque(maxlen=10000)
self.q_net = QNet(state_dim, action_dim) # 实例化刚才定义的网络
self.optimizer = optim.Adam(self.q_net.parameters(), lr=self.lr) # 优化器
self.loss_fn = nn.MSELoss() # 使用均方误差作为损失函数计算差异决策函数 (act):
python
def act(self, state):
# 生成一个 0 到 1 的随机数。如果小于 epsilon,就随机选一个动作(探索)。
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_dim)
# 如果大于 epsilon,就利用现有知识。把 numpy 数组转为 PyTorch 张量。
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad(): # 推理阶段,不需要计算梯度,节省算力。
q_values = self.q_net(state_tensor)
# 选出 Q 值最大的那个动作的索引(比如 0, 1, 2)返回。
return torch.argmax(q_values).item()核心学习函数 (replay):
python
def replay(self):
# 记忆库里数据不够 64 条时,直接返回,不训练。
if len(self.memory) < self.batch_size:
return 0
# 从记忆库中随机打乱并抽取 64 条经验。打乱是为了消除数据之间的时间相关性。
batch = random.sample(self.memory, self.batch_size)
# 解包数据,把状态、动作、奖励等分门别类放好。
states, actions, rewards, next_states, dones = zip(*batch)
# 转换成 PyTorch 需要的张量格式。
states = torch.FloatTensor(np.array(states))
actions = torch.LongTensor(actions).unsqueeze(1)
rewards = torch.FloatTensor(rewards).unsqueeze(1)
next_states = torch.FloatTensor(np.array(next_states))
dones = torch.FloatTensor(dones).unsqueeze(1)
# 1. 计算当前 Q 值:把状态输入网络,得到所有动作的 Q 值,然后用 gather 抽出当时真正执行的那个动作的 Q 值。
curr_q = self.q_net(states).gather(1, actions)
# 2. 计算目标 Q 值 (Target Q):这是基于贝尔曼方程的核心。
with torch.no_grad():
# 看看下一个状态下,所有动作中最大的 Q 值是多少。
max_next_q = self.q_net(next_states).max(1)[0].unsqueeze(1)
# 目标 Q 值 = 当前奖励 + 折扣因子 * 下一步的最大期望。如果 done 为 1 (游戏结束),则没有下一步期望。
target_q = rewards + (1 - dones) * self.gamma * max_next_q
# 3. 梯度下降:计算当前 Q 和目标 Q 的均方误差(Loss)。
loss = self.loss_fn(curr_q, target_q)
self.optimizer.zero_grad() # 清空上一轮的梯度残余
loss.backward() # 反向传播,计算每个网络权重的梯度
self.optimizer.step() # 更新网络权重
# 衰减 epsilon
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return loss.item()3. 环境模拟 (HEVEnvironment 类)
这部分是你未来要替换为 Simulink 接口的地方。
python
def _get_normalized_state(self):
# 关键步骤:把具有物理量纲的数据,压缩到 0 到 1 或者 -1 到 1 的范围内。
# 这防止了例如"车速(120)"在数值上碾压"坡度(0.05)",导致网络只关注车速的问题。
v_norm = self.v / 120.0
a_norm = (self.a + 5.0) / 10.0
slope_norm = (self.slope + 0.1) / 0.2
soc_norm = self.soc
return np.array([v_norm, a_norm, slope_norm, soc_norm], dtype=np.float32)
def step(self, action):
self.step_count += 1
# 模拟路况:随机生成加速度和坡度(这部分未来由工况数据或 Simulink 提供)。
self.a = np.random.uniform(-1, 2)
self.slope = np.random.uniform(-0.05, 0.05)
# v = v0 + at,并把车速限制在 0-120 之间。
self.v = np.clip(self.v + self.a * 3.6, 0, 120)
# 核心物理逻辑:动作如何影响油耗和电量。
fuel_consumption = 0
soc_change = 0
if action == 0: # 纯电
fuel_consumption = 0.0
soc_change = -0.005 if self.v > 0 else -0.001
elif action == 1: # 混动
fuel_consumption = 2.0 * (self.v/120)
soc_change = -0.001
elif action == 2: # 充电
fuel_consumption = 4.0 * (self.v/120)
soc_change = +0.003
# 更新真实 SOC 并限制在 10% 到 90% 之间,防止电池过充过放。
self.soc = np.clip(self.soc + soc_change, 0.1, 0.9)
# 奖励函数:因为强化学习默认是"最大化"奖励,所以我们要最小化的东西(油耗、SOC偏离)都加上负号。
soc_penalty = 50.0 * abs(self.soc - self.soc_target)
reward = -(fuel_consumption + soc_penalty)
# 设定一个回合结束的条件(这里是简单运行 100 步)。
done = self.step_count >= 100
return self._get_normalized_state(), reward, done4. 训练主循环
将前面的组件拼装起来运行。
python
if __name__ == "__main__":
env = HEVEnvironment()
agent = DQNAgent(state_dim=env.state_dim, action_dim=env.action_dim)
episodes = 200 # 总共跑 200 个回合
for e in range(episodes):
state = env.reset() # 每次开始前,车辆状态归零
while True:
# 标准的强化学习交互四大步:
# 1. 观察状态,决定动作
action = agent.act(state)
# 2. 执行动作,环境给出反馈(新状态和奖励)
next_state, reward, done = env.step(action)
# 3. 记住这次经历
agent.remember(state, action, reward, next_state, done)
# 4. 从过往经历中抽样学习
loss = agent.replay()
# 进入下一时刻
state = next_state
if done: # 如果达到 100 步,回合结束,打印信息并跳出内层循环
break通过这套逻辑,算法就能从最初的"乱踩油门",逐渐收敛到你之前日志里看到的"能稳住 SOC 并在一定范围内寻求燃油最优"。
代码解析
第一段代码是 QNet 类 。在强化学习中,这部分相当于智能体(Agent)的**"大脑物理结构"**。它的任务很简单:接收当前车辆的状态,输出每个可选动作的预期长期价值(Q 值)。
我们逐行来剖析:
1. 类的定义与初始化 (__init__)
python
class QNet(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNet, self).__init__()nn.Module: 这是 PyTorch 中所有神经网络的"基类"。继承了它,你的QNet就自动拥有了保存权重、计算梯度、反向传播等高级能力,不需要你手动去写复杂的微积分求导代码。state_dim与action_dim: 这是网络的"入口"和"出口"宽度。在我们的 HEV 实战中,输入维度state_dim是 4(车速、加速度、坡度、SOC),输出维度action_dim是 3(纯电、混动、充电)。super(QNet, self).__init__(): 这是 Python 面向对象编程的标准动作,用来唤醒父类nn.Module的内在机制,准备好接收后续的网络层定义。
2. 构建网络层 (全连接层)
python
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)nn.Linear(全连接层 / 线性层) : 它的底层数学逻辑就是矩阵乘法加偏置向量:y=Wx+by = Wx + by=Wx+b。每一个神经元都会与上一层的所有神经元相连,以此来捕捉特征之间的相关性(比如"高车速"加上"大坡度"通常意味着高能耗)。- 为什么是 64? : 这是一个典型的工程经验值。因为我们的输入只有 4 个物理量,属于极低维度的数据。如果把隐藏层神经元设成 512 或 1024,不仅会极大地拖慢 Python 与 Simulink 通信的实时计算速度,还容易导致过拟合(网络记住了特定工况,但泛化能力差)。64 个神经元对于 HEV 能量管理来说,通常是一个算力与表达能力的完美平衡点。
3. 定义激活函数
python
self.relu = nn.ReLU()nn.ReLU(): 全称是线性整流函数 (Rectified Linear Unit)。它的数学表达极其简单:f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)(小于 0 的值全变成 0,大于 0 的值保持不变)。- 核心意义 : 如果没有 ReLU 这样的非线性激活函数,无论你叠多少层
nn.Linear,整个网络在数学上都可以被等效压缩成单一的线性乘法,根本无法拟合车辆动力学这种高度非线性的系统。
4. 前向传播 (forward 方法)
这是数据真正在网络中流动的路线图。当你调用 q_values = self.q_net(state_tensor) 时,底层执行的就是这个 forward 函数。
python
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)- 第一步 : 输入特征
x(比如归一化后的 0.5, 0.2, 0.0, 0.6) 进入fc1变成 64 维,接着经过relu剔除无效负信号。 - 第二步 : 这 64 个处理后的信号进入
fc2,再次进行特征重组,并经过relu激活。 - 第三步 (极其重要) : 数据进入最后一层
fc3,被压缩成 3 维(对应 3 个动作的 Q 值),直接return,后面没有加relu!
细节避坑:为什么输出层坚决不能加 ReLU?
因为 Q 值代表的是"期望奖励"。回忆一下你上一次跑出的日志,你的累计奖励是 -400 多,这说明这三个动作算出来的 Q 值全都是负数 (因为我们在惩罚油耗和 SOC 偏离)。如果在 fc3(x) 后面加了 relu,所有负数的 Q 值都会被强行变成 0,智能体就彻底变成了"瞎子",无法分辨"略微费油(-5)"和"油耗爆炸(-50)"的区别了。
第一段"大脑结构"的逻辑就是这样,非常精简但完全贴合控制工程的需求。
好的,我们继续"解剖"第二段代码:DQNAgent 类。
如果说 QNet 是智能体的大脑结构,那么 DQNAgent 就是它的**"思维方式"。这一段包含了强化学习中最核心的两个机制:如何收集经验(记忆库),以及如何从经验中学习(Q-Learning 更新公式)**。
我们分模块来详细拆解:
1. 初始化大脑与设定"性格" (__init__)
python
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
# --- 学习参数 ---
self.lr = 3e-4
self.gamma = 0.99
# --- 探索机制 (Epsilon-Greedy) ---
self.epsilon = 1.0
self.epsilon_decay = 0.995
self.epsilon_min = 0.05
# --- 经验回放 (Experience Replay) ---
self.batch_size = 64
self.memory = deque(maxlen=10000)
# --- 实例化网络与优化器 ---
self.q_net = QNet(state_dim, action_dim)
self.optimizer = optim.Adam(self.q_net.parameters(), lr=self.lr)
self.loss_fn = nn.MSELoss()self.gamma = 0.99(折扣因子): 这是强化学习的灵魂参数。当 γ\gammaγ 接近 1 时,智能体会非常看重未来的奖励;当 γ\gammaγ 接近 0 时,智能体只看重眼前的利益。在 HEV 能量管理中,为了防止电池过快耗尽,我们必须看得很远,所以通常设为 0.99 甚至更高。- 探索率 (
epsilon系列):- 初始
1.0意味着第一局它完全在瞎按按钮(探索环境)。 0.995意味着每学一次,瞎按的概率就降低 0.5%。0.05意味着哪怕到了训练末期(比如你日志里看到的 159 回合之后),它依然保留 5% 的概率去尝试随机动作。这是为了防止它陷入"局部最优",错过更好的策略。
- 初始
self.memory:deque是 Python 标准库里的双端队列。maxlen=10000意味着它的记忆容量是 10000 步。当存满后,新的仿真数据会自动把最老的数据"挤出"记忆库。- 优化器 (
optim.Adam): 负责根据计算出的误差,微调QNet中那几百个权重参数,让网络变得更聪明。
2. 行为决策:探索还是利用? (act)
这是智能体决定"下一步该干嘛"的函数。
python
def act(self, state):
# 1. 探索阶段:根据 epsilon 概率随机选择动作
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_dim)
# 2. 利用阶段:使用 Q 网络预测最佳动作
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
q_values = self.q_net(state_tensor)
return torch.argmax(q_values).item()- 核心逻辑 (Epsilon-Greedy): 每次做决定前,先掷个骰子(生成一个 0 到 1 的随机数)。如果骰子点数比当前的
epsilon小,它就无视规则,随机选一个动作(比如明知道上坡还偏要纯电驱动试试看)。如果点数大于epsilon,它就会很乖地向大脑(QNet)请教,拿出预估 Q 值最高的那套方案。 unsqueeze(0): 这是一个 PyTorch 数据处理的细节。网络期望接收的是一批数据(Batch),比如[64, 4],即便你只传入 1 个状态,也需要把它变成[1, 4]的形状,否则网络会报错。torch.argmax: 找出 3 个动作中 Q 值最大(在我们的场景里就是负得最少、惩罚最小)的那一个。
3. 数据入库 (remember)
python
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))极其简单但极其重要的一步。在每个仿真步长(Step)结束时,将刚刚经历的"五元组"打包扔进记忆库 self.memory 中。
4. 经验重放与学习:算法的心脏 (replay)
这是整套代码最复杂的数学和逻辑部分,它负责让网络"涨知识"。
python
def replay(self):
# 如果记忆太少,不足以凑齐一个批次,就先不学
if len(self.memory) < self.batch_size:
return 0
# 1. 随机抽样
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)- 为什么必须"随机抽样 (Experience Replay)"?
如果车辆连续跑了一段长下坡,最近的 100 步全都是下坡状态。如果直接拿这 100 步去训练网络,网络会产生"遗忘",以为全世界都是下坡,从而把平路的驾驶技巧全忘了。随机抽样打破了数据之间的时间相关性,让网络能均衡地学习各种路况。
python
# (张量转换部分略过,主要就是把 Python 数组变成 PyTorch 张量)
# ...
# 2. 计算当前预测的 Q 值
curr_q = self.q_net(states).gather(1, actions)gather的作用:q_net(states)会吐出 64 行、每行 3 个 Q 值(分别对应 3 种动作)。但我们在这一步只关心当时实际执行的那个动作 的 Q 值。gather就像一个镊子,根据actions这个索引,把当时真正执行的动作的 Q 值给挑出来。
python
# 3. 计算"目标 Q 值 (Target Q)" ------ DQN 的精髓
with torch.no_grad():
max_next_q = self.q_net(next_states).max(1)[0].unsqueeze(1)
target_q = rewards + (1 - dones) * self.gamma * max_next_q- 贝尔曼方程 (Bellman Equation): 这一行代码就是 RL 中最著名的贝尔曼方程。智能体认为一个状态动作的理想价值应该等于:这一步拿到的实打实的奖励 (
rewards) + 站在下一步的状态上看,能拿到的最大预期收益 (max_next_q) 乘以折扣因子 (gamma)。 1 - dones: 如果这是最后一步(游戏结束),那么未来就没有收益了。done为 True(1) 时,1 - dones就是 0,未来的预期收益就会被抹除。
python
# 4. 梯度下降与网络更新
loss = self.loss_fn(curr_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 5. 降低探索率
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return loss.item()- 最后,网络对比了自己当前的看法 (
curr_q) 和根据现实反馈修正后的看法 (target_q),计算出差距 (loss),然后调用 PyTorch 的自动求导机制 (backward和step) 去修正权重参数。
第二段的拆解到此结束。这里的核心难点通常在于理解贝尔曼方程的逻辑 和经验重放的意义。
我们继续拆解第三段代码:HEVEnvironment 类。
在强化学习的术语中,这是**"环境 (Environment)"**;在你的具体工程实践中,这其实就是你未来那个 .slx (Simulink 模型) 的 Python 替身。
目前的这个 Python 类是一个简化的运动学和能量模型,目的是为了让算法在没有连上庞大 Simulink 的情况下也能快速验证闭环逻辑。我们逐块来看:
1. 状态初始化与重置 (__init__ 与 reset)
python
class HEVEnvironment:
def __init__(self):
self.state_dim = 4 # 状态维度:[v, a, slope, SOC]
self.action_dim = 3 # 动作维度:0纯电, 1混动, 2充电
self.soc_target = 0.6 # CS模式(电量维持)的目标电量
self.reset()
def reset(self):
# 每次训练回合开始时,车辆状态归零
self.v = 0.0
self.a = 0.0
self.slope = 0.0
self.soc = 0.6
self.step_count = 0
return self._get_normalized_state()reset的作用: 强化学习是基于"回合制 (Episode)"训练的。一趟仿真跑完(或触发了终止条件),必须通过reset把车拉回起点,重新加满油、设定初始 SOC,并返回初始时刻的环境观测值。
2. 核心防御机制:数据归一化 (_get_normalized_state)
这是绝大多数新手在做深度强化学习控制时最容易翻车的地方,必须敲黑板重点关注。
python
def _get_normalized_state(self):
# 把不同物理量纲的数据压缩到近似 [0, 1] 或 [-1, 1] 的区间
v_norm = self.v / 120.0
a_norm = (self.a + 5.0) / 10.0
slope_norm = (self.slope + 0.1) / 0.2
soc_norm = self.soc
return np.array([v_norm, a_norm, slope_norm, soc_norm], dtype=np.float32)- 为什么要归一化?
如果不做这一步,直接把物理量喂进QNet。此时车速 v=120v=120v=120,坡度 θ=0.05\theta=0.05θ=0.05。在神经网络的矩阵乘法中,数值大的特征(车速)会产生巨大的梯度,彻底掩盖掉数值小的特征(坡度)。AI 就会变成一个"只看车速,不管上下坡"的笨蛋。 - 物理映射逻辑:
例如加速度 a∈−5,5a \in -5, 5a∈−5,5 m/s2m/s^2m/s2。通过(a + 5.0) / 10.0,当急刹车 a=−5a=-5a=−5 时,归一化值为 0;急加速 a=5a=5a=5 时,归一化值为 1。这样所有输入特征都在同一个起跑线上了。
3. 仿真步进与物理引擎 (step)
这是环境的核心,它接收大脑发出的指令(action),然后利用物理规则推演下一秒世界会变成什么样,并结算这步的得分(reward)。
python
def step(self, action):
self.step_count += 1
# --- 3.1 模拟外部干扰 (路况) ---
self.a = np.random.uniform(-1, 2)
self.slope = np.random.uniform(-0.05, 0.05)
# 简单的纵向运动学推算,并限制最高车速
self.v = np.clip(self.v + self.a * 3.6, 0, 120) 这里为了简化,加速度和坡度是随机生成的。在真实的联合仿真中,这一段代码会被替换为:"从一段真实的 NEDC/WLTC 速度曲线上读取下一秒的期望车速,并计算出需求加速度"。
python
# --- 3.2 模拟内部动力学响应 ---
fuel_consumption = 0
soc_change = 0
if action == 0: # 纯电驱动 (EV Mode)
fuel_consumption = 0.0
soc_change = -0.005 if self.v > 0 else -0.001
elif action == 1: # 混合驱动 (HEV Mode)
fuel_consumption = 2.0 * (self.v/120)
soc_change = -0.001
elif action == 2: # 行车充电 (Engine Charging Mode)
fuel_consumption = 4.0 * (self.v/120)
soc_change = +0.003
# 限制电池的安全工作区间 [10%, 90%]
self.soc = np.clip(self.soc + soc_change, 0.1, 0.9) 这段 if-elif 语句就是一个极简版的整车能量流模型:
- 纯电不费油,但掉电极快。
- 充电模式极其费油(因为发动机既要驱动车辆前进,又要带动发电机给电池充电),但能让 SOC 抬升。
python
# --- 3.3 结算奖励 (Reward) ---
soc_penalty = 50.0 * abs(self.soc - self.soc_target)
reward = -(fuel_consumption + soc_penalty)
done = self.step_count >= 100
return self._get_normalized_state(), reward, done- 多目标优化公式: R=−(Fuel+w⋅∣SOC−SOCtarget∣)R = -(\text{Fuel} + w \cdot |SOC - SOC_{target}|)R=−(Fuel+w⋅∣SOC−SOCtarget∣)
- 权重因子 w=50.0w=50.0w=50.0: 为什么是 50 这么大的数?因为 Fuel\text{Fuel}Fuel 的量级可能在 1 到 4 之间,而 ∣SOC−SOCtarget∣|SOC - SOC_{target}|∣SOC−SOCtarget∣ 的偏差通常在 0.01 到 0.1 之间。如果不乘以一个大的权重系数,SOC 惩罚项在油耗面前就如同刮痧,模型会为了省那一点点油,毫无底线地透支电池。
到这里,第三段物理环境的逻辑也拆解完毕了。第四段主循环就是将这三者(大脑、思维、环境)组装起来让时间向前滚动,逻辑相对线性。
终于来到了最后一块拼图:第四段代码(主训练循环)。
这是整个程序的"时间齿轮",它负责驱动强化学习的四大核心步骤(观察、决策、执行、学习)不断循环,直到智能体收敛。
1. 引擎启动与回合初始化
python
if __name__ == "__main__":
env = HEVEnvironment()
agent = DQNAgent(state_dim=env.state_dim, action_dim=env.action_dim)
episodes = 200 # 设定训练的总回合数
for e in range(episodes):
state = env.reset() # 极其重要:每一回合开始前,重置车辆和环境到初始状态
total_reward = 0
total_loss = 0- 回合(Episode)的概念: 在车辆仿真中,一个 Episode 通常代表跑完一整段特定的工况(比如跑完一次 1800 秒的 WLTC 循环),或者触发了失败条件(比如电池电量 SOC 掉到了 0%)。每次重新开始,就像是打游戏重新开局。
2. 强化学习的标准"交互四步曲"
进入 while True 循环后,就是智能体与环境实时交互的微观过程:
python
while True:
# 第一步:感知与决策 (Agent -> Action)
# 大脑根据当前归一化后的状态 [v, a, slope, SOC],决定是用电、用油还是充电
action = agent.act(state)
# 第二步:与环境交互 (Environment -> Next State, Reward)
# 车辆执行动作,物理引擎计算出下一秒的车况,并给出这一步的评分
next_state, reward, done = env.step(action)
# 第三步:记忆 (Memory)
# 把这完整的经历(状态、动作、奖励、新状态)存入双端队列,作为历史经验
agent.remember(state, action, reward, next_state, done)
# 第四步:学习与进化 (Learn)
# 从过往经验中随机抓取一批数据(64条),利用贝尔曼方程进行神经网络梯度下降
loss = agent.replay()- 实时性与异步反馈: 注意这里的逻辑流。
action是瞬间给出的,但reward是环境经过物理推演后反馈的。这就构成了典型的闭环控制系统。
3. 时间步进与回合结算
python
# 时间推进:将下一秒的状态更新为当前状态,准备进入下一次循环
state = next_state
# 累计数据,用于监控训练情况
total_reward += reward
if loss: total_loss += loss
if done:
# 当回合结束(跑完100步),打印这一局的最终"体检报告"
print(f"回合: {e+1}/{episodes} | 累计奖励: {total_reward:.2f} | 最终 SOC: {env.soc*100:.1f}% | 探索率: {agent.epsilon:.3f}")
break # 跳出 while 循环,进入下一个 Episode至此,纯 Python 版本的强化学习闭环逻辑已经全部拆解完毕。
实战进阶:跨平台数字孪生环境对接
目前我们的环境 env.step() 是用几行简单的 Python 逻辑模拟的。但在真正的实战中,要实现高精度的能量管理策略,我们需要把这个"大脑"接入到真实的整车动力学模型中。
为了让你在 HEV_Env.slx 这样的 MATLAB/Simulink 环境中跑通这套算法,构建一个真正的跨平台数字孪生系统,通常有两种主流的通信方案:
- MATLAB Engine API for Python:
- 原理: 直接在 Python 代码中导入
matlab.engine,通过 Python 脚本控制 Simulink 模型的启动、步进(Step)和暂停。 - 优点: 官方原生支持,数据传输极其精确,不用担心丢包。
- 缺点: 仿真速度往往较慢,且环境配置比较挑剔(MATLAB 和 Python 版本必须严格对应)。
- 原理: 直接在 Python 代码中导入
- TCP/UDP Socket 通信:
- 原理: 在 Python 端写一个 Socket 服务端,在 Simulink 中拖入
TCP/IP Send和TCP/IP Receive模块。每次 Python 算出action就通过网络端口发给 Simulink,Simulink 算完后把[v, a, slope, SOC]发回给 Python。 - 优点: 工业界极其常用的硬件在环(HiL)前置方案,实时性好,且完全解耦(甚至可以让 Python 跑在装有 NVIDIA A800/A40 的 GPU 服务器上,Simulink 跑在本地 Windows 上)。
- 原理: 在 Python 端写一个 Socket 服务端,在 Simulink 中拖入
第一阶段:配置 Python 与 MATLAB 的通信桥梁
在你运行 PyTorch 的 Python 虚拟环境中,打开终端,确保安装了官方的引擎库:
bash
pip install matlabengine第二阶段:构建 Simulink 物理环境 (HEV_Env2.slx)
在这个阶段,我们要搭建一个极其纯粹的被控对象(Plant),通过标准模块传参,彻底避开底层 C/C++ 代码生成的限制。
1. 新建与配置模型
- 打开 MATLAB,新建一个 Blank Model,保存为
HEV_Env2.slx(确保与 Python 脚本在同一文件夹下)。 - 按
Ctrl+E打开 Model Settings:- Type 选择
Fixed-step。 - Solver 选择
discrete (no continuous states)。 - Fixed-step size 输入
0.1。
- Type 选择
2. 搭建模块拓扑图
在模型库 (Library Browser) 中拖入以下模块并连线:
- Constant 模块 :双击设值为
0。选中模块,将下方的名字重命名为ActionCmd(区分大小写,Python 将通过这个名字寻找它)。 - MATLAB Function 模块 :将其输入端口连到
ActionCmd的输出端。 - Terminator 模块:拖入 5 个,分别连到 MATLAB Function 产生的 5 个输出端口上。
3. 植入核心能量流代码
双击 MATLAB Function 模块,将内部代码全部替换为以下防报错版本:
matlab
function [v, a, slope, soc, fuel_rate] = HEV_Plant(action)
% 声明仅允许调用 MATLAB 工作区写入指令,不再强行读取
coder.extrinsic('assignin');
% 持久化变量,作为离散系统的状态记忆
persistent sys_v sys_soc sys_fuel;
if isempty(sys_v)
sys_v = 0.0;
sys_soc = 0.6;
sys_fuel = 0.0;
end
% 模拟外部环境扰动 (随机加速度与坡度)
a_current = -1.0 + 3.0 * rand();
slope_current = -0.05 + 0.1 * rand();
sys_v = max(0, min(120, sys_v + a_current * 3.6));
% 混合动力能量分配控制逻辑
current_fuel_rate = 0.0;
soc_change = 0.0;
if action == 0 % 纯电驱动
soc_change = -0.005;
elseif action == 1 % 混合驱动
current_fuel_rate = 2.0 * (sys_v/120);
soc_change = -0.001;
elseif action == 2 % 行车充电
current_fuel_rate = 4.0 * (sys_v/120);
soc_change = 0.003;
end
% 更新整车能量状态
sys_soc = max(0.1, min(0.9, sys_soc + soc_change));
sys_fuel = sys_fuel + current_fuel_rate;
% 端口输出
v = sys_v;
a = a_current;
slope = slope_current;
soc = sys_soc;
fuel_rate = current_fuel_rate;
% 核心同步机制:将结果推送到工作区,供 Python 读取
assignin('base', 'sim_v', v);
assignin('base', 'sim_a', a);
assignin('base', 'sim_slope', slope);
assignin('base', 'sim_soc', soc);
assignin('base', 'sim_fuel', fuel_rate);
end保存并关闭 MATLAB 窗口。
第三阶段:一键运行的 Python 联合仿真主程序
在 HEV_Env2.slx 所在的文件夹中,新建 main_ems_cosim.py,粘贴以下完整代码。这段代码已经集成了 DQN 算法与修复后的安全通信协议(使用 set_param 直接修改 Constant 模块的值)。
python
import matlab.engine
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
import os
# ==========================================
# 1. 神经网络大脑 (QNet)
# ==========================================
class QNet(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNet, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)
# ==========================================
# 2. DQN 强化学习算法 (Agent)
# ==========================================
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
self.lr = 3e-4
self.gamma = 0.99
self.epsilon = 1.0
self.epsilon_decay = 0.995
self.epsilon_min = 0.05
self.batch_size = 64
self.memory = deque(maxlen=10000)
self.q_net = QNet(state_dim, action_dim)
self.optimizer = optim.Adam(self.q_net.parameters(), lr=self.lr)
self.loss_fn = nn.MSELoss()
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_dim)
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
q_values = self.q_net(state_tensor)
return torch.argmax(q_values).item()
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def replay(self):
if len(self.memory) < self.batch_size:
return 0
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(np.array(states))
actions = torch.LongTensor(actions).unsqueeze(1)
rewards = torch.FloatTensor(rewards).unsqueeze(1)
next_states = torch.FloatTensor(np.array(next_states))
dones = torch.FloatTensor(dones).unsqueeze(1)
curr_q = self.q_net(states).gather(1, actions)
with torch.no_grad():
max_next_q = self.q_net(next_states).max(1)[0].unsqueeze(1)
target_q = rewards + (1 - dones) * self.gamma * max_next_q
loss = self.loss_fn(curr_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return loss.item()
# ==========================================
# 3. 联合仿真环境接口 (Simulink Wrapper)
# ==========================================
class HEVSimulinkEnv:
def __init__(self):
print(">>> 正在启动 MATLAB 引擎,请耐心等待 (约需10-30秒)...")
self.eng = matlab.engine.start_matlab()
current_dir = os.path.dirname(os.path.abspath(__file__))
self.eng.cd(current_dir, nargout=0)
self.model_name = 'HEV_Env2' # 确保这里与你的 slx 文件名一致
print(f">>> 正在加载 Simulink 模型: {self.model_name}.slx")
self.eng.load_system(self.model_name, nargout=0)
self.state_dim = 4
self.action_dim = 3
self.soc_target = 0.6
self.max_steps = 100
def reset(self):
self.eng.set_param(self.model_name, 'SimulationCommand', 'stop', nargout=0)
# 将 ActionCmd 模块重置为 '0'
action_block_path = f"{self.model_name}/ActionCmd"
self.eng.set_param(action_block_path, 'Value', '0', nargout=0)
self.eng.set_param(self.model_name, 'SimulationCommand', 'start', nargout=0)
self.eng.set_param(self.model_name, 'SimulationCommand', 'pause', nargout=0)
self.step_count = 0
self.eng.set_param(self.model_name, 'SimulationCommand', 'step', nargout=0)
return self._get_normalized_state()
def step(self, action):
self.step_count += 1
# 1. 直接修改 Simulink 中 Constant 模块的值,实现动作下发
action_block_path = f"{self.model_name}/ActionCmd"
self.eng.set_param(action_block_path, 'Value', str(float(action)), nargout=0)
# 2. 步进仿真
self.eng.set_param(self.model_name, 'SimulationCommand', 'step', nargout=0)
# 3. 获取状态与反馈
state_norm = self._get_normalized_state()
current_soc = float(self.eng.workspace['sim_soc'])
current_fuel_rate = float(self.eng.workspace['sim_fuel'])
# 4. 结算奖励
soc_penalty = 50.0 * abs(current_soc - self.soc_target)
reward = -(current_fuel_rate + soc_penalty)
done = self.step_count >= self.max_steps
if done:
self.eng.set_param(self.model_name, 'SimulationCommand', 'stop', nargout=0)
return state_norm, reward, done
def _get_normalized_state(self):
v = float(self.eng.workspace['sim_v'])
a = float(self.eng.workspace['sim_a'])
slope = float(self.eng.workspace['sim_slope'])
soc = float(self.eng.workspace['sim_soc'])
v_norm = v / 120.0
a_norm = (a + 5.0) / 10.0
slope_norm = (slope + 0.1) / 0.2
return np.array([v_norm, a_norm, slope_norm, soc], dtype=np.float32)
def close(self):
self.eng.quit()
# ==========================================
# 4. 主训练循环
# ==========================================
if __name__ == "__main__":
env = HEVSimulinkEnv()
agent = DQNAgent(state_dim=env.state_dim, action_dim=env.action_dim)
episodes = 50
try:
for e in range(episodes):
state = env.reset()
total_reward = 0
while True:
action = agent.act(state)
next_state, reward, done = env.step(action)
agent.remember(state, action, reward, next_state, done)
loss = agent.replay()
state = next_state
total_reward += reward
if done:
final_soc = float(env.eng.workspace['sim_soc']) * 100
print(f"回合: {e+1}/{episodes} | 累计奖励: {total_reward:.2f} | 最终 SOC: {final_soc:.1f}% | Epsilon: {agent.epsilon:.3f}")
break
except KeyboardInterrupt:
print("\n>>> 训练被手动中断。")
finally:
print(">>> 正在关闭 MATLAB 引擎并清理内存...")
env.close()现在,这段代码完全符合 Simulink 的编译标准,数据链路也非常清晰。
bash
(hev) PS D:\software\opera_file\file\file\homework\train_project\python\hev_test01> & "D:/Program Files/anaconda/envs/hev/python.exe" d:/software/opera_file/file/file/homework/train_project/python/hev_test01/train_hev_env2.py
>>> 正在启动 MATLAB 引擎,请耐心等待 (约需10-30秒)...
>>> 正在加载 Simulink 模型: HEV_Env2.slx
回合: 1/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.831
回合: 2/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.503
回合: 3/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.305
回合: 4/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.185
回合: 5/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.112
回合: 6/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.068
回合: 7/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 8/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 9/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 10/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 11/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 12/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 13/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 14/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 15/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 16/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 17/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 18/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 19/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 20/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 21/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 22/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 23/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 24/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 25/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 26/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 27/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 28/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 29/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 30/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 31/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 32/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 33/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 34/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 35/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 36/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 37/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 38/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 39/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 40/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 41/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 42/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 43/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 44/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 45/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 46/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 47/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 48/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 49/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
回合: 50/50 | 累计奖励: -2500.00 | 最终 SOC: 10.0% | Epsilon: 0.050
>>> 正在关闭 MATLAB 引擎并清理内存...我们将这段运行在 Simulink MATLAB Function 模块中的代码逐段拆开。它的核心使命是:在离散时间步长下,模拟一个带有物理记忆特性的混合动力汽车(被控对象 Plant)。
1. 函数声明与编译指令
matlab
function [v, a, slope, soc, fuel_rate] = HEV_Plant(action)
% 声明仅允许调用 MATLAB 工作区写入指令,不再强行读取
coder.extrinsic('assignin');function [v, a, ... ] = HEV_Plant(action):- 这是函数的标准入口。
action是输入参数(由外部的 Constant 模块传入,也就是 Python 算出来的决策:0, 1 或 2)。 - 方括号里的是输出参数,它们对应了模块右侧长出来的 5 个连线端口。即使我们主要通过工作区传递数据,也必须保留这些物理端口连接到
Terminator(终端)模块,否则 Simulink 的底层优化器会认为这个模块"没有输出",从而在编译时直接把它当废代码优化掉。
- 这是函数的标准入口。
coder.extrinsic('assignin');(极其核心的一句) :- 底层逻辑:Simulink 为了保证仿真极速运行,在点击"Run"的时候,会偷偷把你的 MATLAB 代码翻译成底层的 C/C++ 代码执行。
- 冲突点 :
assignin是一个纯粹的 MATLAB 桌面环境指令(它的作用是向工作区写变量),C 语言里根本没有这个概念。如果不加这句声明,Simulink 就会报 Coder 生成错误。 - 作用 :这行代码是在告诉 Simulink 编译器:"遇到
assignin这个词的时候,不要把它翻译成 C 代码,而是跳出 C 环境,呼叫 MATLAB 引擎来代为执行。" 这是实现跨平台数据同步的关键后门。
2. 离散系统的"记忆":持久化变量
matlab
% 持久化变量,作为离散系统的状态记忆
persistent sys_v sys_soc sys_fuel;
if isempty(sys_v)
sys_v = 0.0;
sys_soc = 0.6;
sys_fuel = 0.0;
endpersistent(持久化变量) :- 在标准的编程中,函数一旦运行结束,里面的局部变量就会被销毁。但在车辆控制中,车速 vvv 和电量 SOC 是典型的状态量 (State Variables),下一秒的速度必须基于上一秒的速度累加,系统必须有"惯性"和"记忆"。
persistent就相当于 C 语言里的static变量,或者 Simulink 里的 Unit Delay (1/z1/z1/z) 模块。它能把上一个步长(Step)算出的车速和电量保存下来,带到下一个步长使用。
if isempty(...)初始化 :- 在仿真的第 0 秒(第一步),这些持久化变量还是空的。这段代码只会在仿真刚刚启动(
reset后)触发一次。它相当于给车辆设定了初始边界条件:静止起步(车速 0),初始电量 60%,累计油耗 0。
- 在仿真的第 0 秒(第一步),这些持久化变量还是空的。这段代码只会在仿真刚刚启动(
3. 外部环境干扰与运动学推演
matlab
% 模拟外部环境扰动 (随机加速度与坡度)
a_current = -1.0 + 3.0 * rand();
slope_current = -0.05 + 0.1 * rand();
sys_v = max(0, min(120, sys_v + a_current * 3.6)); - 生成工况 :
rand()会生成 0 到 1 之间的随机小数。经过线性映射,加速度被限制在 −1,2 m/s2-1, 2\text{ m/s}^2−1,2 m/s2(模拟车辆加减速需求),坡度被限制在 −5%,5%-5\\%, 5\\%−5%,5%(模拟上下坡起伏)。在后期实战中,这里会被替换为读取真实的 WLTC 速度曲线。 - 车速积分推演 :
sys_v + a_current * 3.6- 物理公式是:vk=vk−1+a⋅Δtv_{k} = v_{k-1} + a \cdot \Delta tvk=vk−1+a⋅Δt。
- 这里的 3.6 是一个单位换算系数。假设加速度单位是 m/s2\text{m/s}^2m/s2,车速单位是 km/h\text{km/h}km/h,那么 1 m/s1\text{ m/s}1 m/s 对应 3.6 km/h3.6\text{ km/h}3.6 km/h。这里为了极简化模型,相当于默认了时间步长 Δt=1\Delta t = 1Δt=1 秒产生的速度增量。
max(0, min(120, ...)): 这是控制工程中典型的限幅器 (Saturation)。保证车速既不会变成负数(不考虑倒车),也不会超过 120 km/h 的物理极速。
4. HEV 能量分配规则库 (Rule-based Logic)
matlab
% 混合动力能量分配控制逻辑
current_fuel_rate = 0.0;
soc_change = 0.0;
if action == 0 % 纯电驱动
soc_change = -0.005;
elseif action == 1 % 混合驱动
current_fuel_rate = 2.0 * (sys_v/120);
soc_change = -0.001;
elseif action == 2 % 行车充电
current_fuel_rate = 4.0 * (sys_v/120);
soc_change = 0.003;
end- 这段代码扮演了车辆内部 整车控制器 (VCU) 响应动作的物理反馈。
- 它用极简的线性公式替代了复杂的发动机万有特性 MAP 图和电机效率 MAP 图。
- 比如在"混合驱动 (1)"模式下,油耗
current_fuel_rate与当前车速sys_v成正比(车速越快,所需功率越大,油耗越高),同时 SOC 会微弱下降(因为电机也在辅助出力)。 - 在"行车充电 (2)"模式下,油耗是混动模式的两倍(因为发动机负荷极大),但换来的是 SOC 的正向增长
+0.003。
5. 状态更新与边界保护
matlab
% 更新整车能量状态
sys_soc = max(0.1, min(0.9, sys_soc + soc_change));
sys_fuel = sys_fuel + current_fuel_rate;- 电池保护 :动力电池不能过充过放。
max(0.1, min(0.9, ...))强行将 SOC 锁定在 10% 到 90% 之间。如果强化学习智能体在 SOC 达到 90% 时依然疯狂发出"充电"指令,物理环境将不再增加电量,只会白白增加油耗,这种"吃亏"的反馈会让智能体长记性。 - 油耗直接进行累加计算。
6. 数据双通道输出
matlab
% 端口输出
v = sys_v;
a = a_current;
slope = slope_current;
soc = sys_soc;
fuel_rate = current_fuel_rate;
% 核心同步机制:将结果推送到工作区,供 Python 读取
assignin('base', 'sim_v', v);
assignin('base', 'sim_a', a);
assignin('base', 'sim_slope', slope);
assignin('base', 'sim_soc', soc);
assignin('base', 'sim_fuel', fuel_rate);- 第一通道(端口输出) :把变量赋给函数声明里的输出参数
v, a, ...,防止 Simulink 报错。 - 第二通道(跨平台输出) :
assignin('base', '变量名', 值)。'base'指的是 MATLAB 的基础工作区(就是你打开 MATLAB 软件时,右侧那个能看到所有变量的面板)。- 当这一步执行完毕后,Simulink 的时间轴暂停,此时 Python 脚本会立刻通过 Engine API 去抓取工作区里的
sim_v,sim_a等变量,从而完成一次状态反馈。
这个 Python 脚本不仅包含了 DQN 强化学习算法,还承担了跨进程指挥调度的重任。为了方便理解,我们按代码的四大核心模块逐行拆解:
1. 神经网络结构 (QNet 类) ------ 智能体的脑神经
这是整个 AI 的物理载体,负责把"环境状态"映射为"各个动作的长期价值(Q值)"。
python
class QNet(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNet, self).__init__()
# state_dim 是 4(车速、加速度、坡度、SOC)
# action_dim 是 3(纯电、混动、充电)
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
self.relu = nn.ReLU()- 为什么用
Linear且只有 64 个神经元?
车辆底层的物理状态维度极低(只有 4 个标量),不涉及图像或庞大的序列序列。过深、过宽的网络反而会引起"过拟合",导致仿真计算极度拖沓。64 个神经元(特征通道)足以刻画这四个物理量的复杂组合。
python
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)- 核心避坑: 最后一层
fc3(x)之后绝对不能加relu激活函数 。因为我们需要输出真实的 Q 值(期望奖励),而我们定义的奖励基本都是负数(扣除油耗和电量偏离)。如果加了relu,所有负数都会变成 0,AI 会彻底丧失分辨好坏的能力。
2. 强化学习核心引擎 (DQNAgent 类) ------ 思维与学习逻辑
这里定义了 AI 如何做选择,以及如何在错误中进化。
python
# 初始化部分超参数
self.lr = 3e-4 # 学习率:决定每次网络权重更新的幅度
self.gamma = 0.99 # 折扣因子:0.99 代表极度重视未来长远收益(对维持电量至关重要)
self.epsilon = 1.0 # 初始探索率:1.0 代表第一局100%瞎按按钮
self.epsilon_decay = 0.995 # 探索率衰减系数
self.epsilon_min = 0.05 # 保底探索率
self.batch_size = 64
self.memory = deque(maxlen=10000) # 记忆容量:最多记一万步的经验
python
def act(self, state):
# Epsilon-Greedy (ε-贪婪策略)
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_dim) # 探索:随机瞎选一个动作
# 利用:向神经网络请教
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad(): # 推理时关闭梯度计算,省显存提速度
q_values = self.q_net(state_tensor)
return torch.argmax(q_values).item() # 选出 Q 值最大的那个动作的索引- 你的 AI 在前 100 个回合表现极差,就是因为
epsilon很高,它在不断探索环境的边界(比如在高速上强行切纯电)。
python
def replay(self):
# 记忆不到 64 条时不学习
if len(self.memory) < self.batch_size: return 0
# 随机抽取一批经验 (打破时间相关性)
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
# ... (转换为 PyTorch 张量) ...
# 1. 查表:当前网络对过去这 64 个状态的看法
curr_q = self.q_net(states).gather(1, actions)
# 2. 预测未来:下一个状态的最大预期收益
with torch.no_grad():
max_next_q = self.q_net(next_states).max(1)[0].unsqueeze(1)
# 贝尔曼方程:目标 Q 值 = 即时奖励 + (1-结束标志) * 0.99 * 下一步最高收益
target_q = rewards + (1 - dones) * self.gamma * max_next_q
# 3. 产生痛觉并进化
loss = self.loss_fn(curr_q, target_q) # 计算均方误差
self.optimizer.zero_grad() # 清空旧梯度
loss.backward() # 反向传播求导
self.optimizer.step() # 更新大脑权重target_q是精髓: 它强迫现在的网络去对齐"现实奖励 + 未来预期"。这是强化学习能学会"放长线钓大鱼"的核心数学公式。
3. 联合仿真通信接口 (HEVSimulinkEnv 类) ------ 跨界调度官
这段代码是两套软件的桥梁。
python
def __init__(self):
# 启动后台 MATLAB 引擎
self.eng = matlab.engine.start_matlab()
# 将 MATLAB 的工作目录切换到 Python 脚本当前所在目录,否则找不到 slx 文件
current_dir = os.path.dirname(os.path.abspath(__file__))
self.eng.cd(current_dir, nargout=0)
# 在后台静默加载模型
self.model_name = 'HEV_Env2'
self.eng.load_system(self.model_name, nargout=0)
python
def reset(self):
# 1. 如果模型在跑,先强制刹车
self.eng.set_param(self.model_name, 'SimulationCommand', 'stop', nargout=0)
# 2. 【核心通信点】将 Simulink 里的那个 Constant 模块的值改写为 '0'
action_block_path = f"{self.model_name}/ActionCmd"
self.eng.set_param(action_block_path, 'Value', '0', nargout=0)
# 3. 启动引擎,但处于"暂停"状态,等待 Python 下达步进命令
self.eng.set_param(self.model_name, 'SimulationCommand', 'start', nargout=0)
self.eng.set_param(self.model_name, 'SimulationCommand', 'pause', nargout=0)
self.step_count = 0
# 强制走第 1 步,产生初始车辆状态
self.eng.set_param(self.model_name, 'SimulationCommand', 'step', nargout=0)
return self._get_normalized_state()nargout=0的生死攸关: MATLAB 的set_param命令本身是没有返回值的。如果 Python 这里不写nargout=0,Python 就会傻乎乎地一直等 MATLAB 给它回传计算结果,导致两个软件死锁卡住。
python
def step(self, action):
self.step_count += 1
# 将神经网络给出的指令 (0,1,2) 写进 Simulink 模型里
action_block_path = f"{self.model_name}/ActionCmd"
self.eng.set_param(action_block_path, 'Value', str(float(action)), nargout=0)
# 让 Simulink 的时间轴往前滚 0.1 秒
self.eng.set_param(self.model_name, 'SimulationCommand', 'step', nargout=0)
# 去工作区"收菜",把算好的新状态拿回来
state_norm = self._get_normalized_state()
current_soc = float(self.eng.workspace['sim_soc'])
current_fuel_rate = float(self.eng.workspace['sim_fuel'])
# 多目标奖励结算
soc_penalty = 50.0 * abs(current_soc - self.soc_target)
reward = -(current_fuel_rate + soc_penalty)- 这就是最标准的硬件在环/软件在环 (SiL/HiL) 步进控制逻辑。Python 是主控,Simulink 彻底沦为受控的物理计算器。
4. 主循环调度区
python
if __name__ == "__main__":
env = HEVSimulinkEnv()
agent = DQNAgent(state_dim=env.state_dim, action_dim=env.action_dim)
episodes = 50
try:
for e in range(episodes):
state = env.reset() # 每次打完一局,重置车况
total_reward = 0
while True:
# 经典的 RL 交互四步走
action = agent.act(state)
next_state, reward, done = env.step(action)
agent.remember(state, action, reward, next_state, done)
loss = agent.replay()
state = next_state
total_reward += reward
if done: # 跑够 100 步,结算打印
final_soc = float(env.eng.workspace['sim_soc']) * 100
print(f"回合: {e+1} | 奖励: {total_reward:.2f} | 最终 SOC: {final_soc:.1f}%")
break
finally:
# 无论报错还是训练完成,保证体面地关闭引擎释放内存
env.close()到这里,整个 Python 端如何调度 DQN 算法并远程控制 Simulink 的脉络就全部打通了。