一 模型结构的搭建
1.模型检测的类别数和模型的尺寸
| 特性 | 您的配置 (YOLOv5 风格) | 右侧配置 (YOLOv8及以后,如YOLO11) |
|---|---|---|
| 缩放参数 | depth_multiple和 width_multiple |
scales(深度、宽度、最大通道数的复合系数) |
| 设计理念 | 统一缩放:通过两个全局乘子,对整个模型的深度和宽度进行固定比例的缩放。 | 复合分层缩放:为不同尺寸的模型(n, s, m, l, x)预定义一组独立的、更精细的缩放系数。 |
| 模型定义 | 一个YAML文件通常对应一个特定尺寸的模型。要改变尺寸,需要手动调整 depth_multiple和 width_multiple的值。 |
一个YAML文件包含了所有尺寸(n/s/m/l/x) 的定义。scales字典里为每个尺寸都预设了 depth、width和 max_channels,结构更清晰、更模块化。 |
| 灵活性 | 灵活,但需要用户理解每个参数如何影响结构。 | 更"开箱即用",用户只需选择模型尺寸标签(如 model='yolo11n.yaml'),框架会自动加载对应的缩放系数。 |
- 您的 YOLOv5 配置(左侧):
depth_multiple: 0.33:控制模型"块"的重复次数。例如,如果某个C3块的 number是9,实际重复次数是 9 * 0.33 = 3。
width_multiple: 6.25:控制每一层的通道数(卷积核数量)。例如,如果某层定义的通道是64,实际通道数是 64 * 6.25 = 400。
这种方式没有独立的 scales字典,缩放逻辑是"在线计算"的。
- YOLO11 的配置(右侧):
可以看到 scales:字典,里面为 n、s、m、l、x五个尺寸分别定义了 depth、width、max_channels三个系数。
在后面的 backbone和 head定义中,会通过类似 width_multiple=scales[model_size][1]这样的方式来引用这些预设值。
这种设计将结构定义和尺寸参数分离,管理多尺寸模型更加清晰、方便。
3.如何对应与迁移?
如果您看到YOLO11的配置,想在自己的YOLOv5风格项目中实现类似效果,可以这样理解它们的等效关系:
例如,对于 YOLOv5s 模型,其典型配置是:
depth_multiple: 0.33
width_multiple: 0.50这大致等价于 YOLOv8/YOLO11 的 scales字典中,s尺寸的:
s:
depth: 0.33
width: 0.50
max_channels: 10242.depth_multiple和width_multiple的理解
depth_multiple(深度系数) = 大楼的层数
它是干什么的:它控制你的模型有多"深",也就是网络有多少"层"或者重复的"模块"。
参数是0.33意味着什么:
原始设计师画了一张标准版的蓝图,比如设计这栋楼应该有 9 个完全相同的房间(对应图中的number: 9)。但你觉得这个标准版太大了,想要一个更轻量、更快的版本。你决定:只盖其中3层。怎么算出来的: 9(标准层数) * 0.33(你的深度系数) = 3(实际建造的层数)
一句话总结:depth_multiple决定了你的模型是"瘦高型"还是"矮胖型"。系数越小,模型越浅,运算通常越快,但能力可能变弱;系数越大,模型越深,能力可能更强,但更慢。
width_multiple(宽度系数) = 大楼每层的房间数量
它是干什么的:它控制你的模型有多"宽",也就是网络每一层有多少"通道"(你可以简单理解为每一层能提取信息的"工人"或"特征数量")。
参数是6.25意味着什么:
在标准蓝图里,设计师说某一层应该安排 64 个工人(对应图中的 通道: 64)。但你觉得这个标准版的工人不够,想要一个能力更强、看得更细的版本。你决定:这层我要派400个工人。怎么算出来的? 64(标准工人数) * 6.25(你的宽度系数) = 400(实际派的工人数)
一句话总结:width_multiple决定了你的模型是"苗条型"还是"强壮型"。系数越大,每层的"信息通道"越多,模型能处理更复杂的模式,但计算量也越大;系数越小,模型越窄,计算越快,但可能漏掉一些细节。
| 系数 | 调大时的影响 | 调小时的影响 |
|---|---|---|
深度系数 depth_multiple |
**模型更"深"** | **模型更"浅"** |
| ✅ 特征提取能力更强 | ✅ 推理速度更快 | |
| ❌ 推理速度更慢 | ✅ 内存占用更小 | |
| ❌ 内存占用更大 | ❌ 特征提取能力较弱 | |
| ❌ 可能容易过拟合 | ||
宽度系数 width_multiple |
**模型更"宽"** | **模型更"窄"** |
| ✅ 能捕捉更多细节 | ✅ 计算量小 | |
| ✅ 对小物体检测更有利 | ✅ 显存需求低 | |
| ❌ 计算量大幅增加 | ❌ 可能漏掉细节 | |
| ❌ 显存需求激增 | ❌ 精度可能下降 |





3.模型结构参数和训练超参数
模型结构参数 (depth_multiple, width_multiple):决定了你建造的是一辆什么样的车(是轿车、SUV还是卡车?发动机排量多大?)。这是在训练前就定好的。
训练超参数 (epochs, batch-size, imgsz):决定了如何训练这辆车的"驾驶员"(模型)。让他学多久?一次看多少路况?看多大清晰度的路况?
| 模型 | 深度系数 | 宽度系数 | 特点 |
|---|---|---|---|
| YOLOv5n (纳米) | 0.33 | 0.25 | 极快,适合移动设备 |
| YOLOv5s (小) | 0.33 | 0.50 | 快,精度适中 |
| YOLOv5m (中) | 0.67 | 0.75 | 平衡性好 |
| YOLOv5l (大) | 1.0 | 1.0 | 精度高 |
| YOLOv5x (超大) | 1.33 | 1.25 | 精度最高,但最慢 |
4.YOLO的终端命令使用
5 模型结构的搭建

6 添加数据和训练
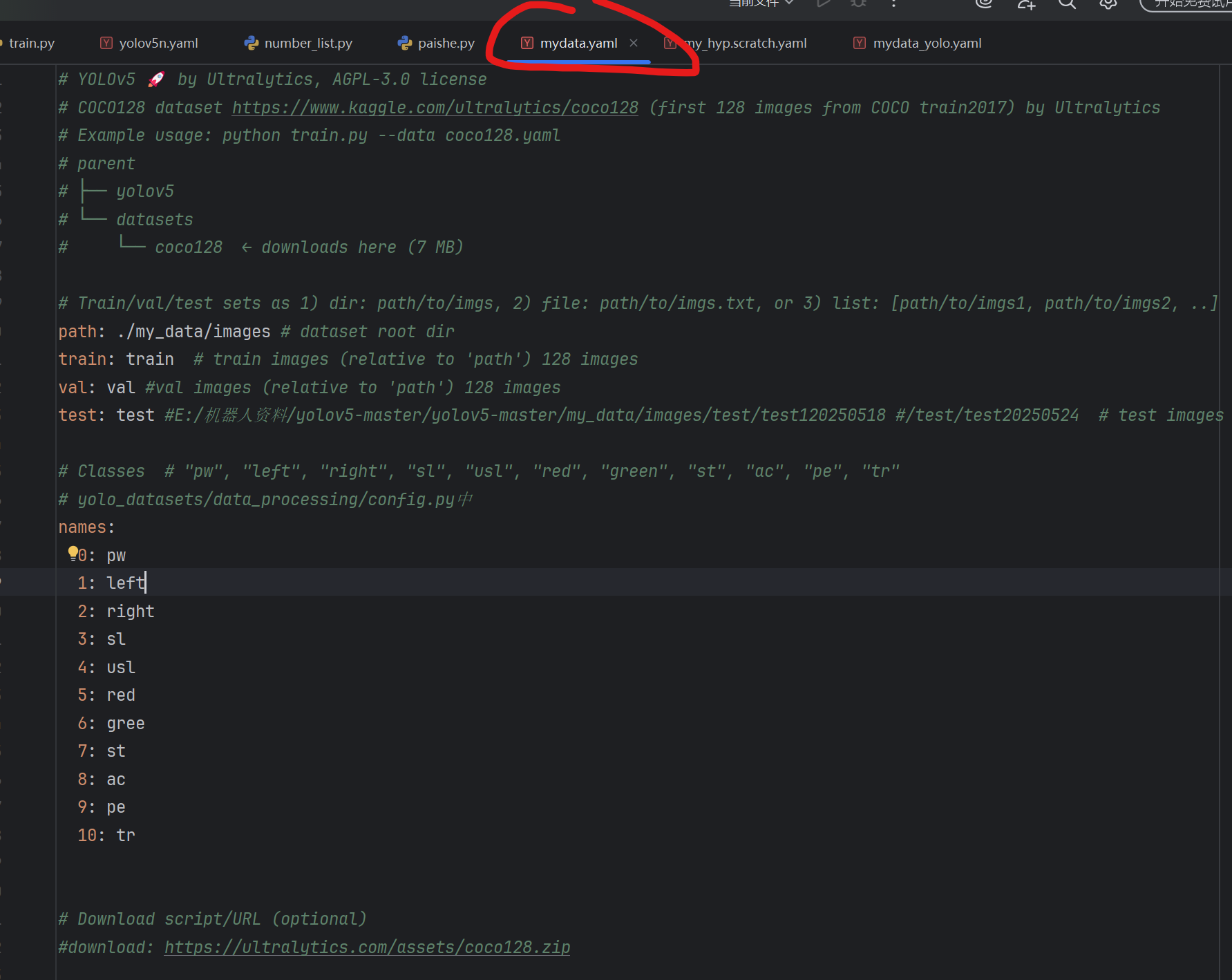
7.数据的训练




meta进行的超参数进化
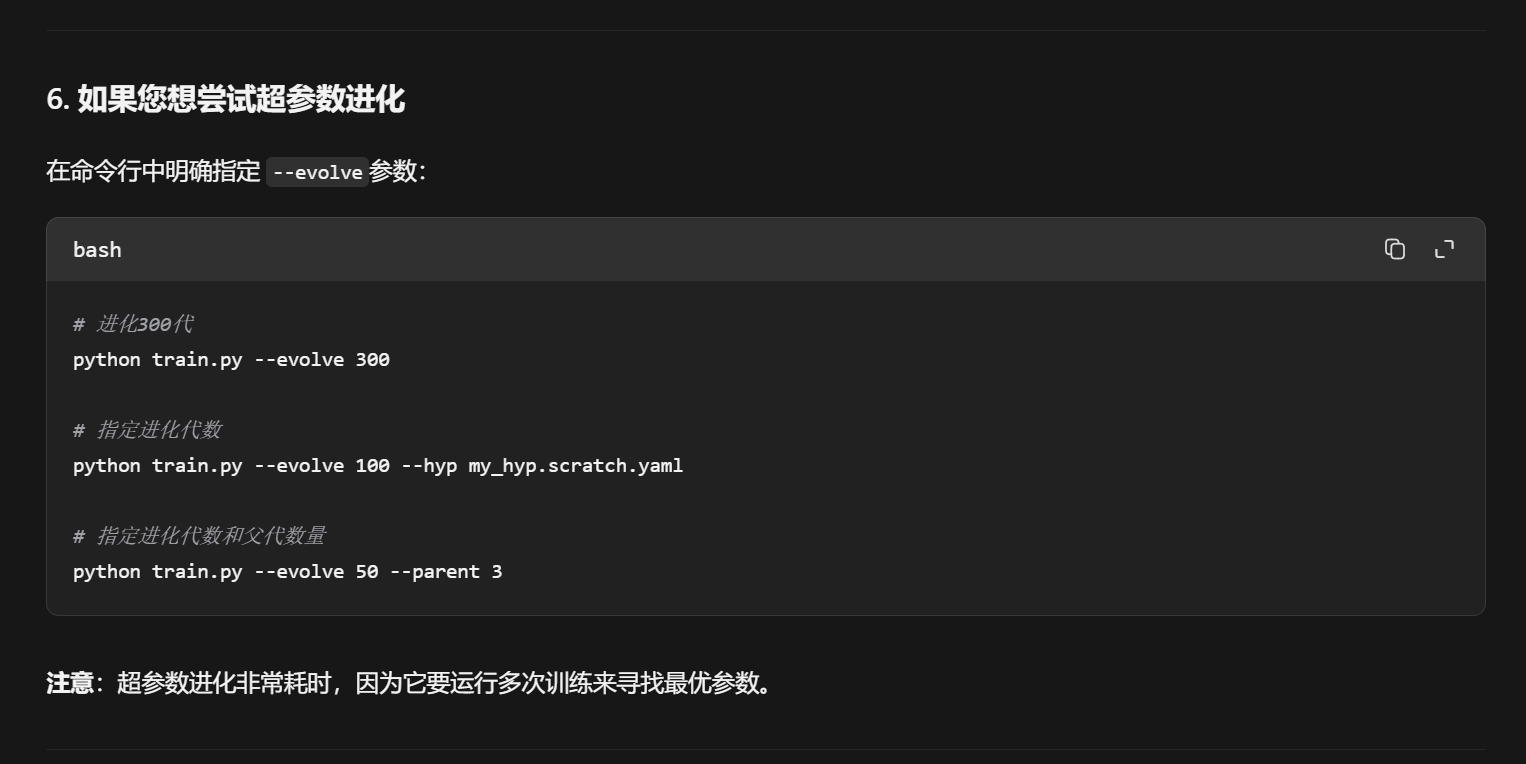
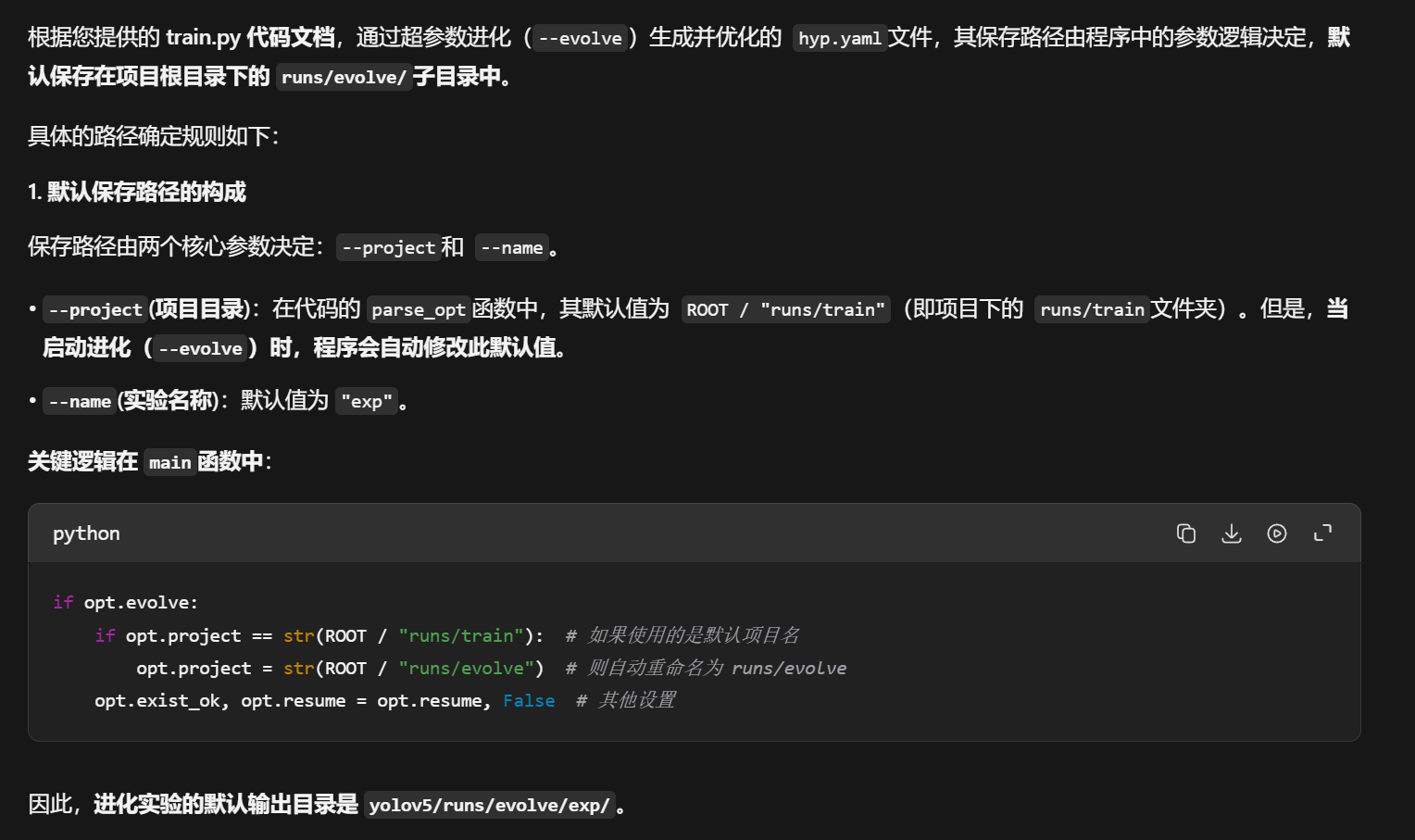

动态参数缩放是YOLOv5训练流程中一个嵌入在每次训练迭代内部的、不可或缺的步骤。它确保了无论超参数来自初始文件还是进化算法,都能被自动适配到当前的训练环境中。因此,您完全不必担心进化会"绕过"这个重要步骤。
python
python train.py --evolve 3008.模型参数和训练结果的分析
数据的分析


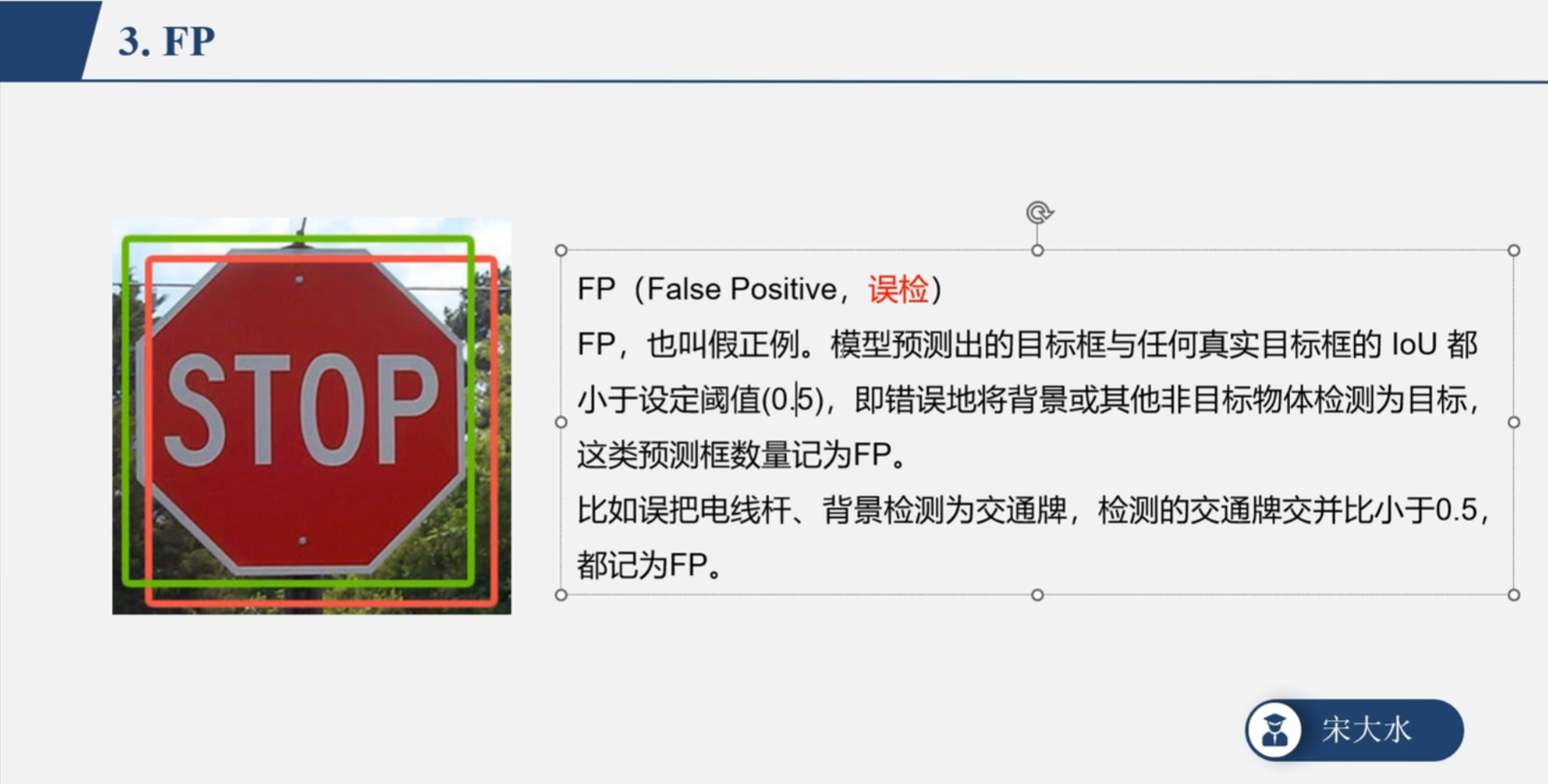


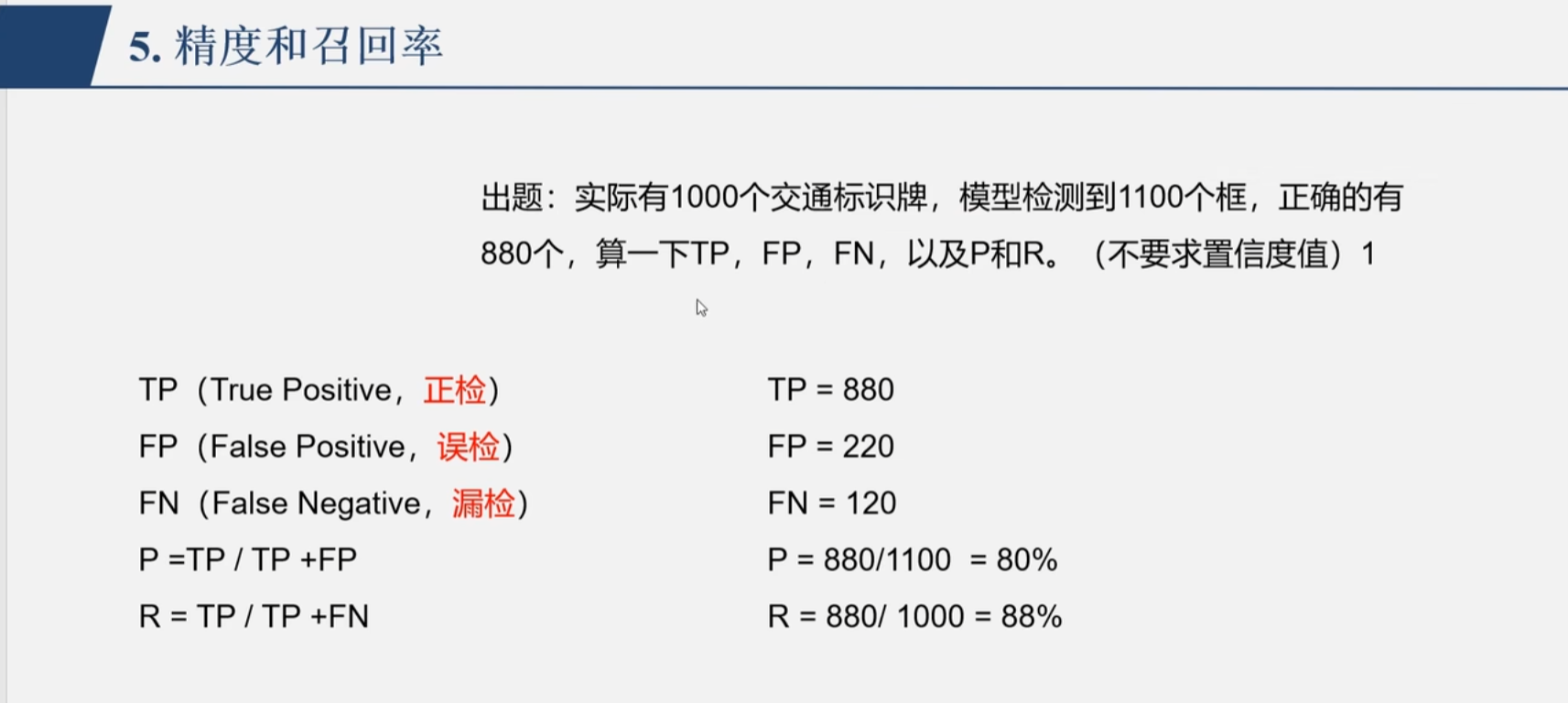

图像的分析
p图像和r图像
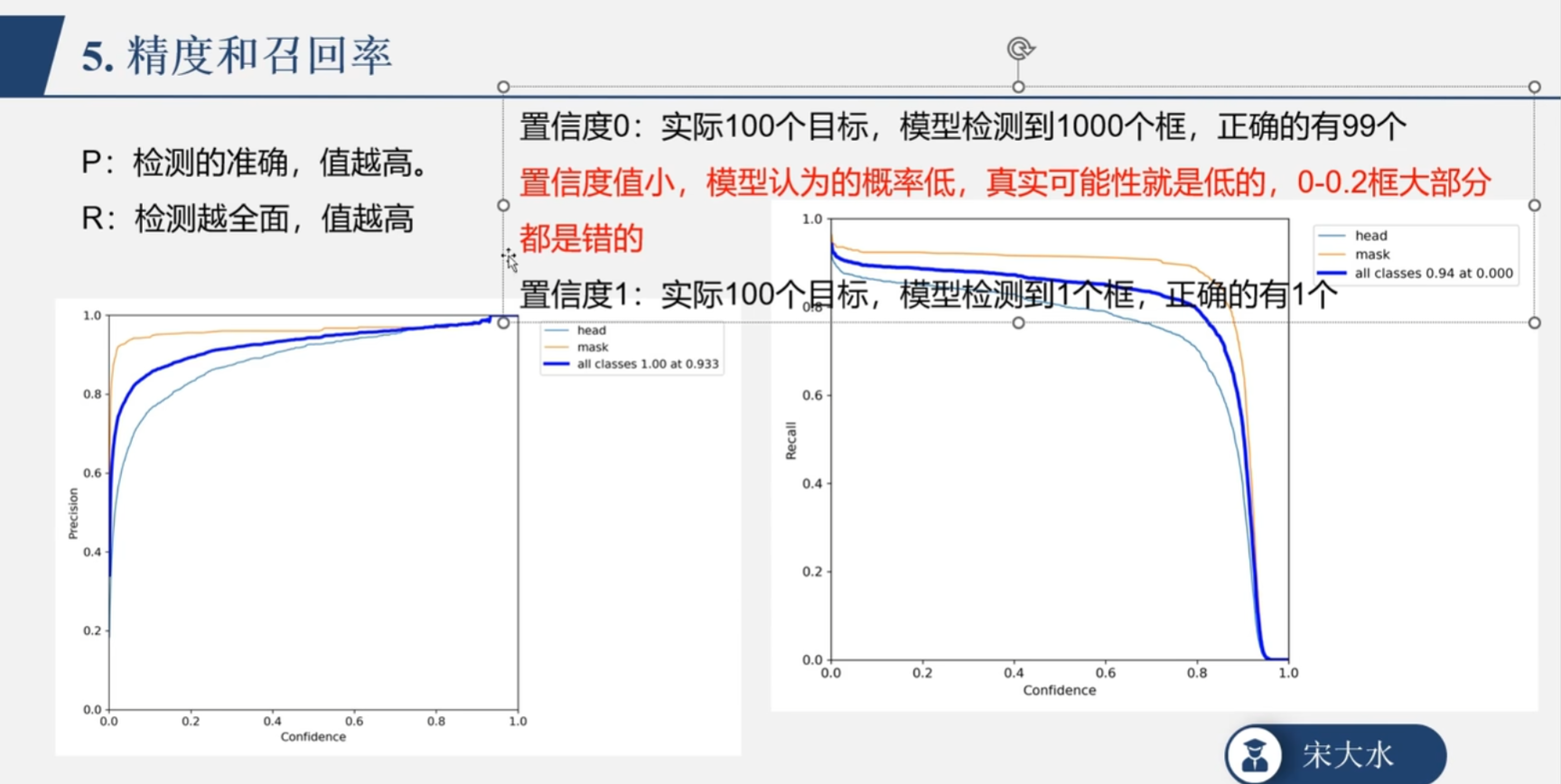
PR图象
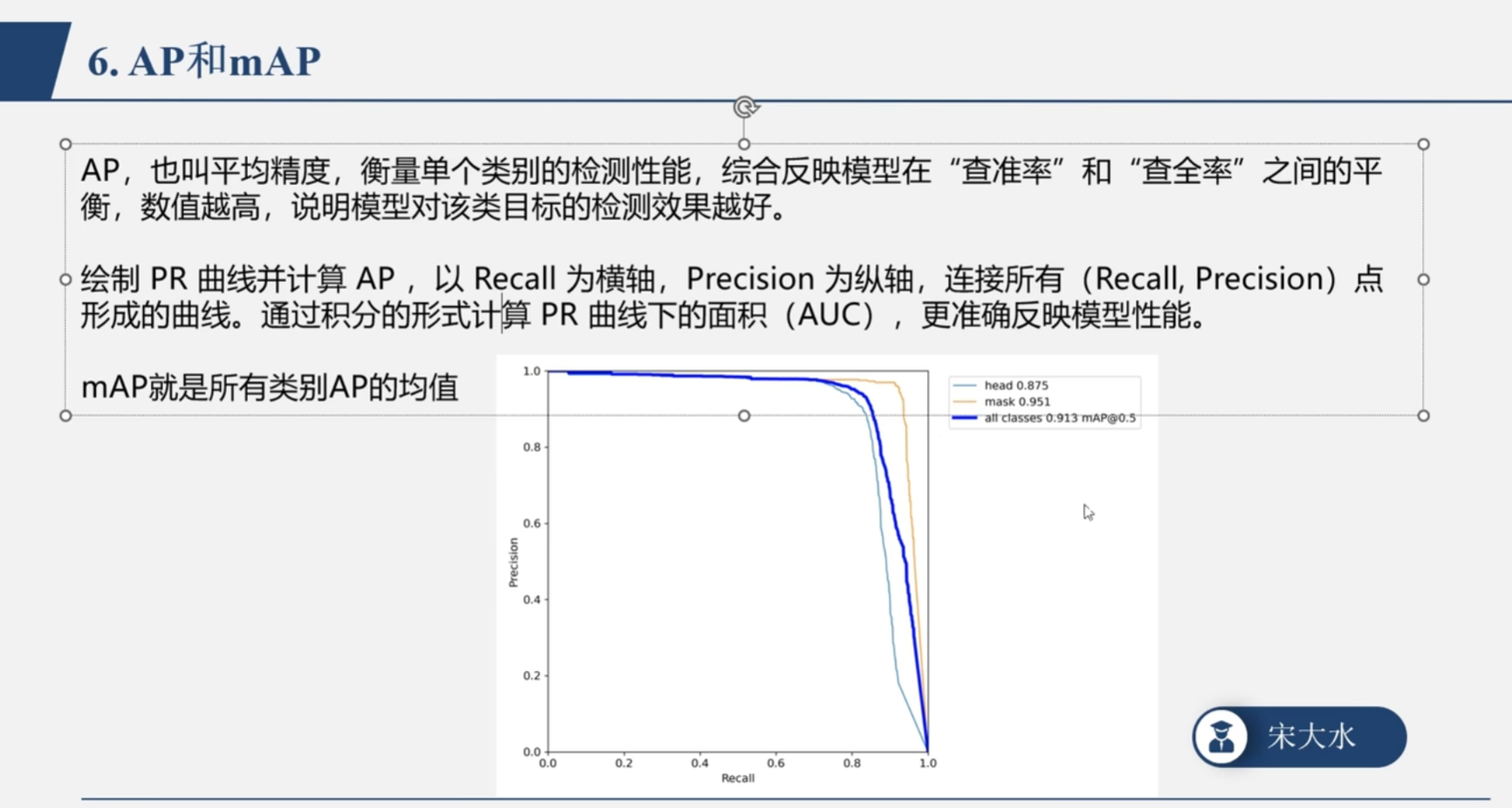
在目标检测和机器学习领域,AP(Average Precision,平均精度)就像是一次考试的"综合总分"。它的核心作用只有一个:综合评估你的模型在识别某一个特定类别时。
为了让你透彻理解它的重要性,我们可以分三步来拆解它的作用:
- 为什么需要 AP?(解决"顾此失彼"的痛点)
在目标检测中,我们有两个方程式的死对头:
-
精确率(Precision):模型找出的目标里,有多少是对的?(怕误检)
-
召回率(Recall):真实的 target 里,模型找出了多少?(怕漏检)
这两个指标往往是矛盾的。比如:
-
如果模型为了"不漏掉任何一个目标"而疯狂画框,它的召回率高,但精确率极低(满地都是假警报)。
-
如果模型极其保守,只框它有100%把握的目标,它的精确率高,但召回率极低(错过了很多真目标)。
👉 AP 的作用一:做一个"端水大师"
AP 就是为了综合评判这两个指标而生的。它不会因为你某一方面强就给你高分,只有当你既"找得准"又"找得全"时,AP 才会给出漂亮的分数。这就避免了模型"偏科"。
- AP 在实际应用中有什么具体用处?
作用一:充当"找茬专家",精准定位模型的弱点
AP 是针对单个类别的评估(比如专门看模型找"猫"的能力)。
假设你做了一个能识别 10 种动物的模型,总体成绩看着不错,但你发现其中"识别蛇"的 AP 特别低。这就一针见血地告诉你:你的模型在"蛇"这个类别上拉胯了。你需要去专门收集更多蛇的照片来重新训练。
作用二:提供一个"不近人情"的客观死理性派评分
在之前介绍 F1 曲线时我们提到过"置信度阈值"。有些模型调一调阈值,成绩单就能好看不少。
但 AP 的计算方式极其严苛------它会把模型在所有可能的置信度阈值下的表现全部算一遍,然后算一个"平均水准"。这意味着,AP 是一个不受人为调参影响的终极审判,最能反映模型的真实功底。
- 用一句人话总结 AP 的本质
如果把模型检测某类目标的过程,比作"在一个乱七八糟的仓库里按清单找特定的零件":
-
精确率是你拿给你的零件里,有多少是清单上真正需要的。
-
召回率是清单上的零件,你找回来多少。
-
AP 就是看你在整个寻找过程中,是不是一直保持着高水平的准头和全面性。
最终,我们把所有类别的 AP 求个平均,就得到了大名鼎鼎的 mAP(mean Average Precision) ------这也是工业界衡量一个目标检测模型到底是"青铜"还是"王者"的终极黄金标准。

F1图像

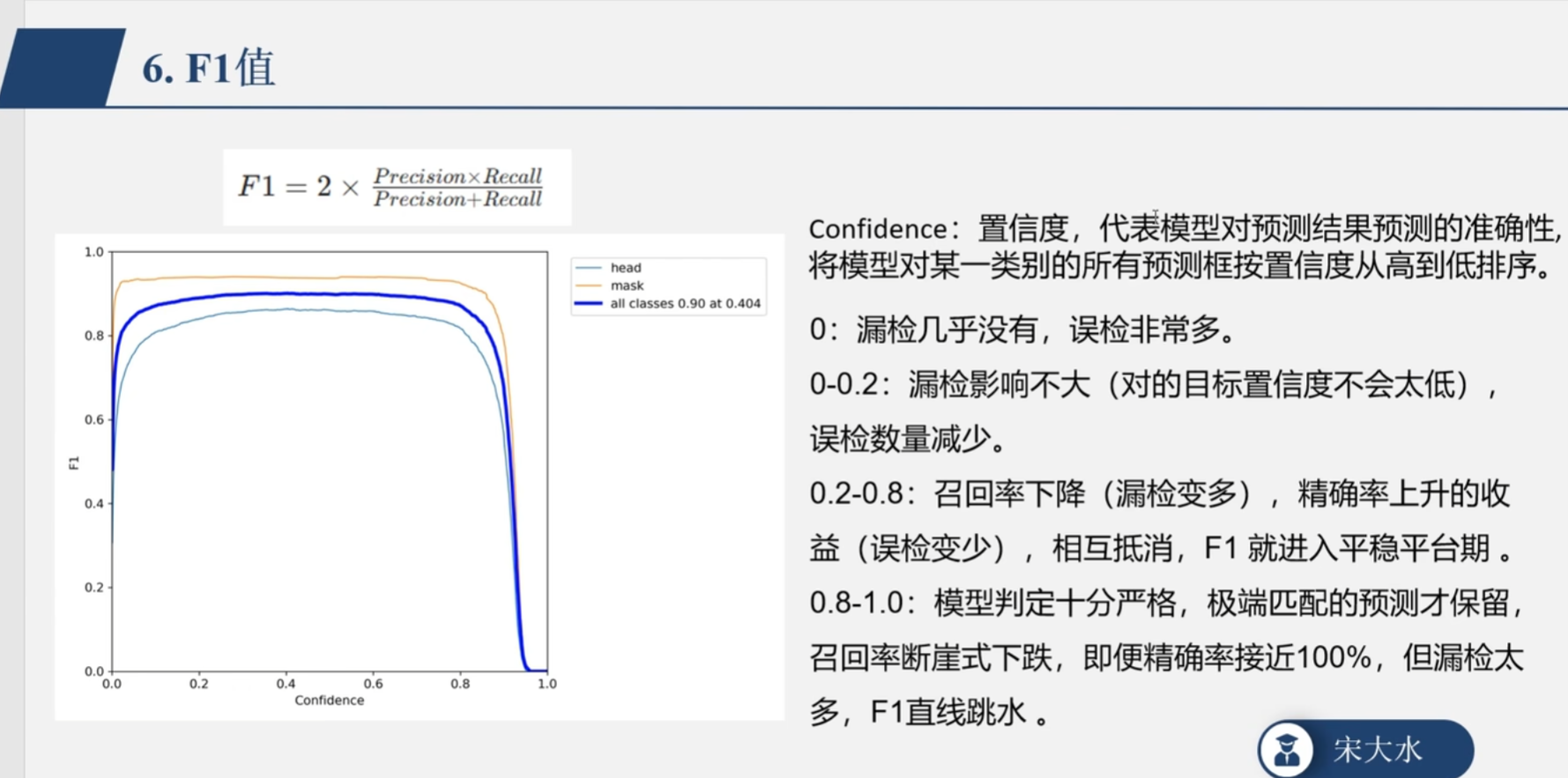
图像作用 :帮你找到模型的最佳置信度阈值 。F1分数是精确率(Precision)和召回率(Recall)的调和平均数。这条曲线会先上升后下降,其最高点(Peak)对应的横坐标,就是该模型在验证集上表现最好的置信度阈值

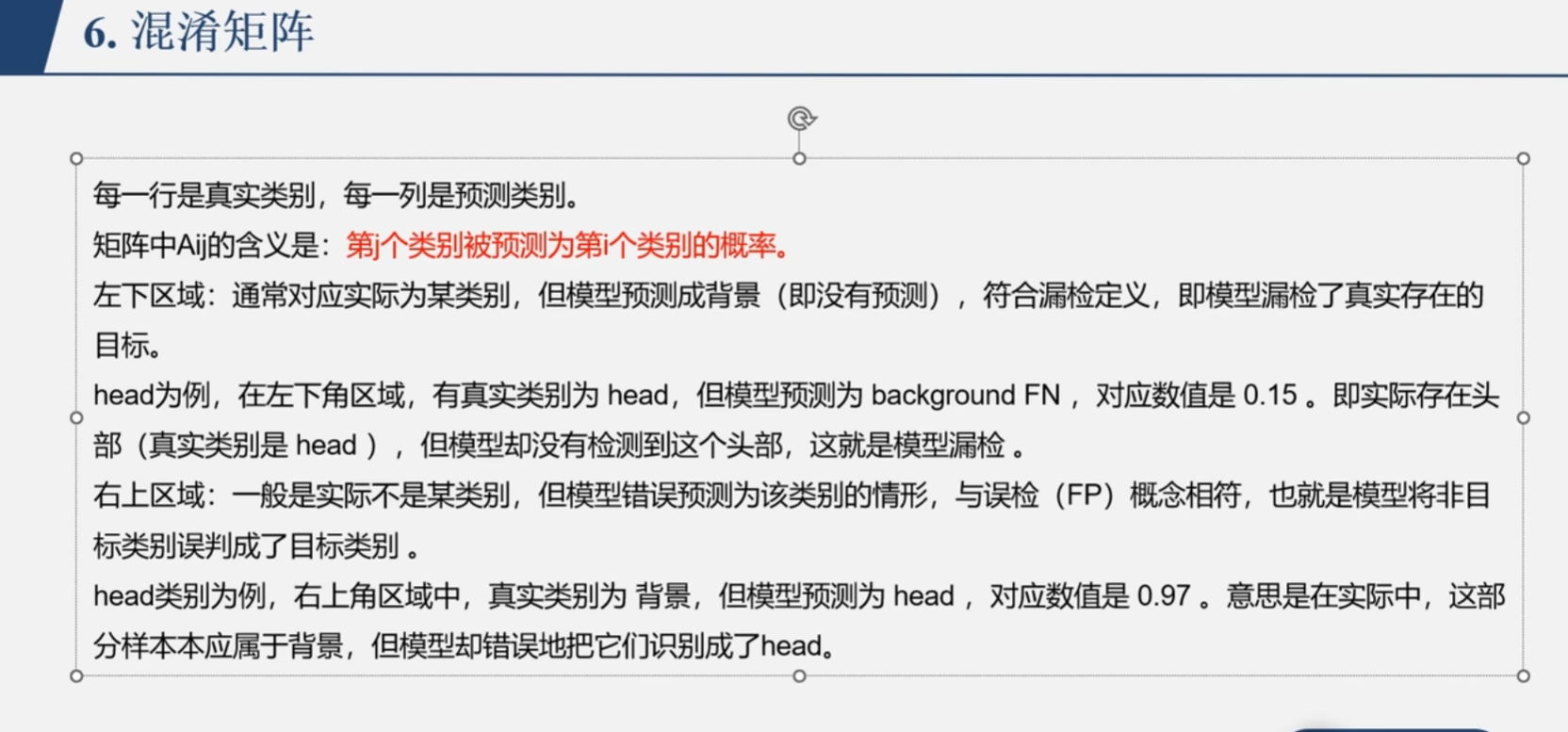
混淆矩阵
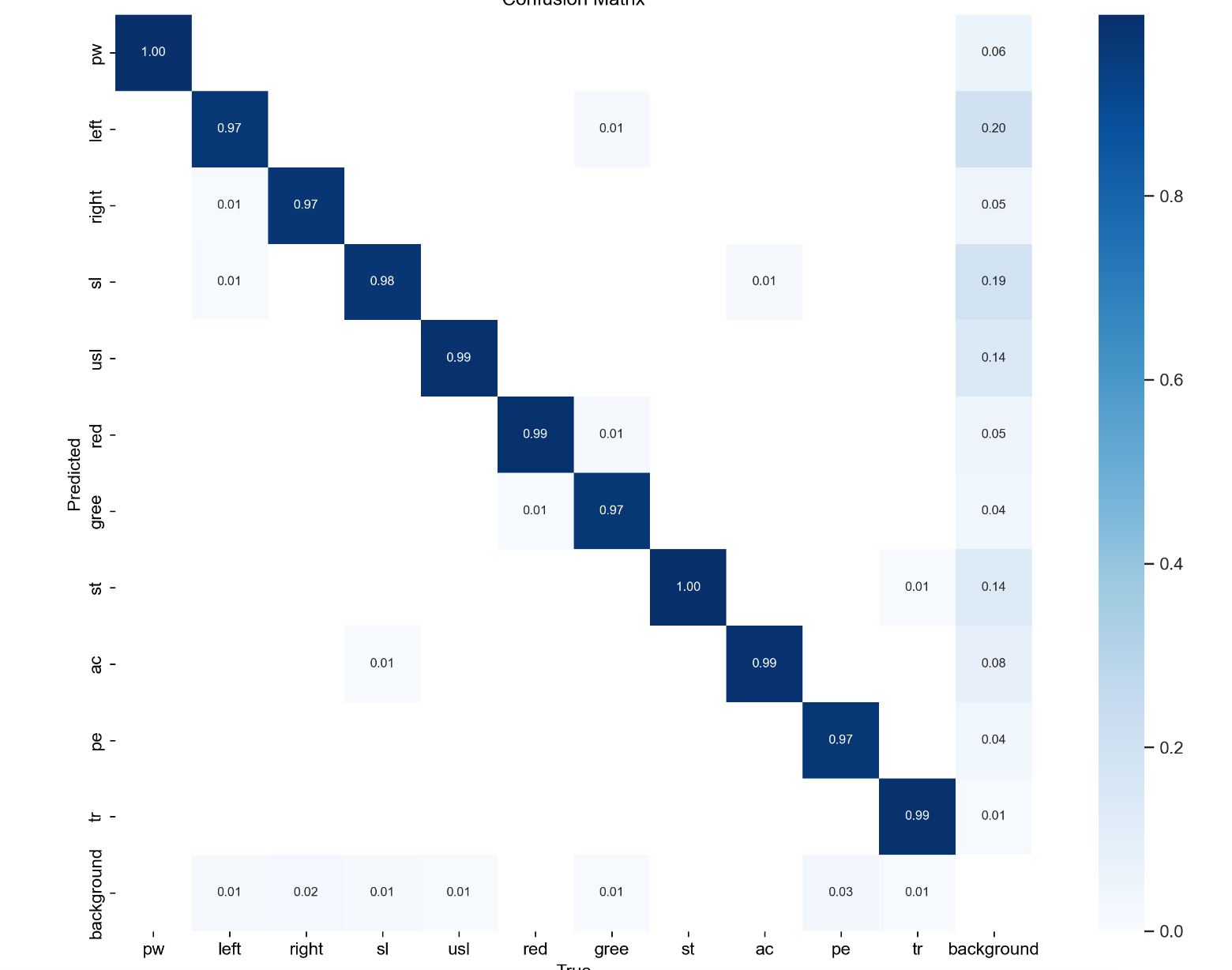

labels
左上角:柱状图(类别-实例数量分布)
-
横轴:不同类别(标签,如
pw、left、right、sl等)。 -
纵轴:
instances(实例数量,即该类别在数据集中的样本数)。 -
含义:展示每个类别包含的实例数量,直观反映类别均衡性。例如:
-
pw、left、st等类别实例数多(柱子高),属于"高频类别"; -
red、gree等类别实例数少(柱子低),属于"低频类别"。
-
- 右上角:多类别分布范围可视化(箱线图/小提琴图变体)
-
图中彩色条带代表不同类别,垂直方向展示该类别在某属性(如目标框位置、尺寸)上的分布范围(如最小值、最大值、中位数等,具体需结合数据背景)。
-
含义:对比不同类别在某一维度(如目标框的上下边界、左右边界)的分布差异,辅助分析"哪些类别位置/尺寸更分散/集中"。
- 左下角:位置密度图(x-y 坐标分布)
-
横轴:
x(目标在图像中的水平坐标);纵轴:y(目标在图像中的垂直坐标)。 -
颜色深浅(蓝色调)表示实例密度(颜色越深,该区域实例越多)。
-
含义:展示目标在图像中的空间分布偏好。例如:
-
若中间区域(
x≈0.4~0.6, y≈0.4~0.6)颜色最深,说明多数目标集中在图像中心; -
边缘区域颜色浅,则说明目标很少出现在图像边缘。
-
- 右下角:尺寸密度图(宽度-高度分布)
-
横轴:
width(目标宽度);纵轴:height(目标高度)。 -
颜色深浅表示实例密度,同时可观察
width与height的相关性(如是否存在"宽度大则高度大"的正相关趋势)。 -
含义:分析目标的尺寸范围与尺寸关系。例如:
-
深色带集中在
width≈0.1~0.2, height≈0.3~0.5区域,说明多数目标尺寸在此区间; -
若颜色带呈"斜线",则说明
width和height正相关(目标宽高比相对稳定)。
-
labels_correlogram
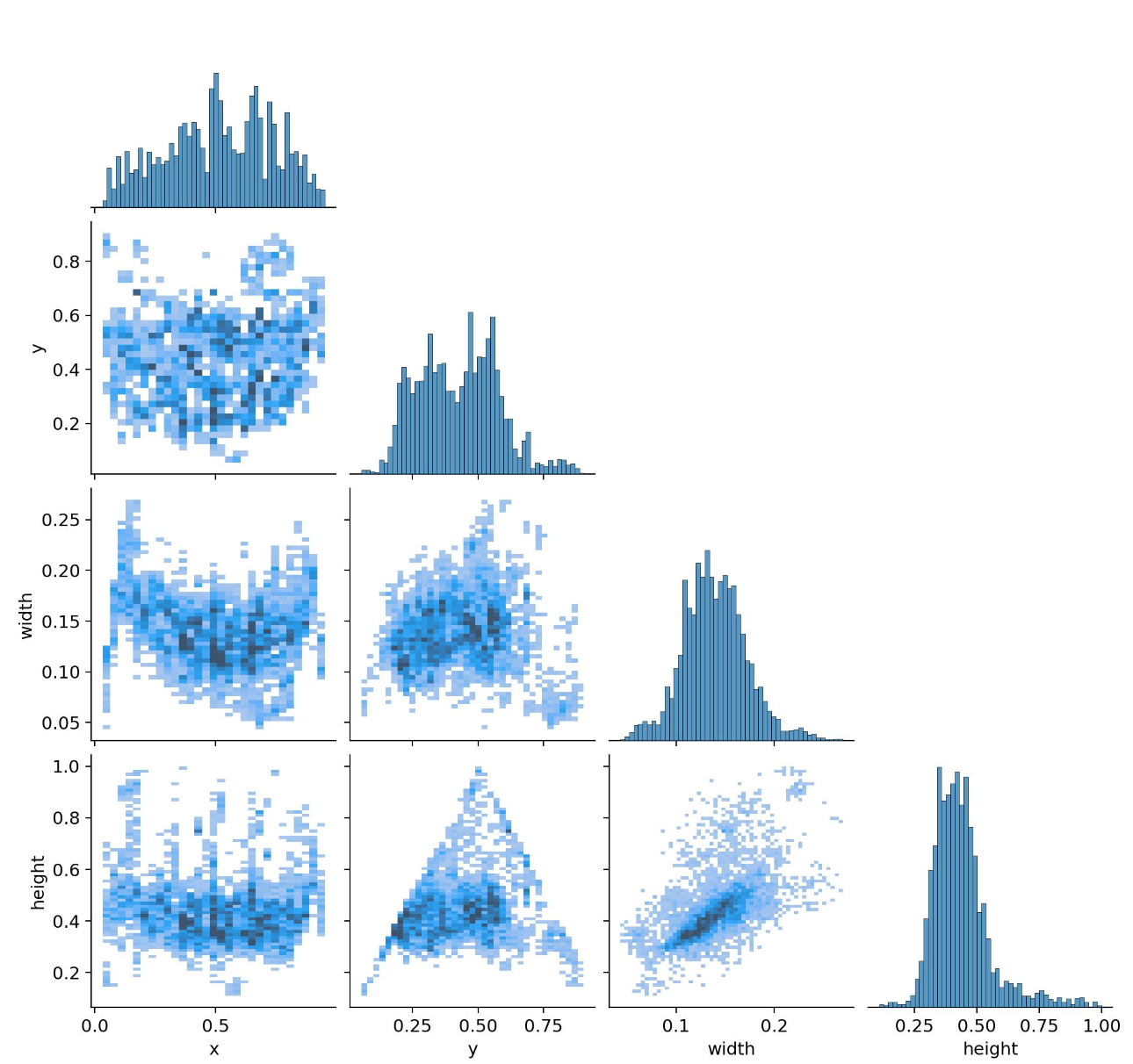
图的结构与子图含义
图中行和列的标签均为 x、y、width、height,形成一个 3行×4列 的矩阵(行对应 y、width、height;列对应 x、y、width、height)。
-
对角线子图(行=列):展示单个变量的边缘分布(直方图),反映该变量的数值范围和频率特征。
-
非对角线子图(行≠列):展示两个变量的联合分布(用"颜色密度"表示点的密集程度),反映变量间的相关性或互动模式。
- 单变量分布(对角线直方图)
对角线的4个子图分别对应 x、y、width、height各自的分布:
-
x的直方图(第1行第1列):x的取值范围约为[0, 1],直方图显示其频率分布(非均匀,存在集中区间)。 -
y的直方图(第1行第2列):y的取值范围约为[0, 0.8],直方图反映y的频率峰值和离散程度。 -
width的直方图(第2行第3列):width集中在[0.1, 0.2]左右,直方图展示其高频区间。 -
height的直方图(第3行第4列):height取值范围约为[0.25, 1.0],直方图显示其峰值(约0.5附近)。
- 双变量联合分布(非对角线密度图)
非对角线子图展示两两变量的关联模式(颜色越深,点越密集):
-
(y, x)(第1行第1列):y与x的联合分布,可见二者在某些区间内高度聚集,反映位置变量的协同性。 -
(y, width)(第1行第3列):y与width的分布,密度模式揭示二者是否存在"位置-宽度"的互动(如大宽度是否更易出现在特定y区间)。 -
(y, height)(第1行第4列):y与height的分布,类似地,可观察"位置-高度"的关联。 -
(width, x)(第2行第1列):width与x的分布,若x靠近图像右边界,width可能受限于图像范围(如不能过大),需关注约束关系。 -
(width, y)(第2行第2列):width与y的分布,分析"宽度-位置"的潜在规律。 -
(width, height)(第2行第4列):width与height的分布,若为目标检测的 bounding box 数据,二者常因"宽高比约束"呈现正相关(或特定模式)。 -
(height, x)(第3行第1列):height与x的分布,类似width与x的逻辑,关注高度与水平位置的关联。 -
(height, y)(第3行第2列):height与y的分布,若呈现"三角形",可能是几何约束导致(如x/y靠近边界时,height最大值受限)。 -
(height, width)(第3行第3列):height与width的分布,若为 bounding box 数据,二者常因"物体形状"或"标注规则"呈现强关联(如正方形物体宽高近似)。
results
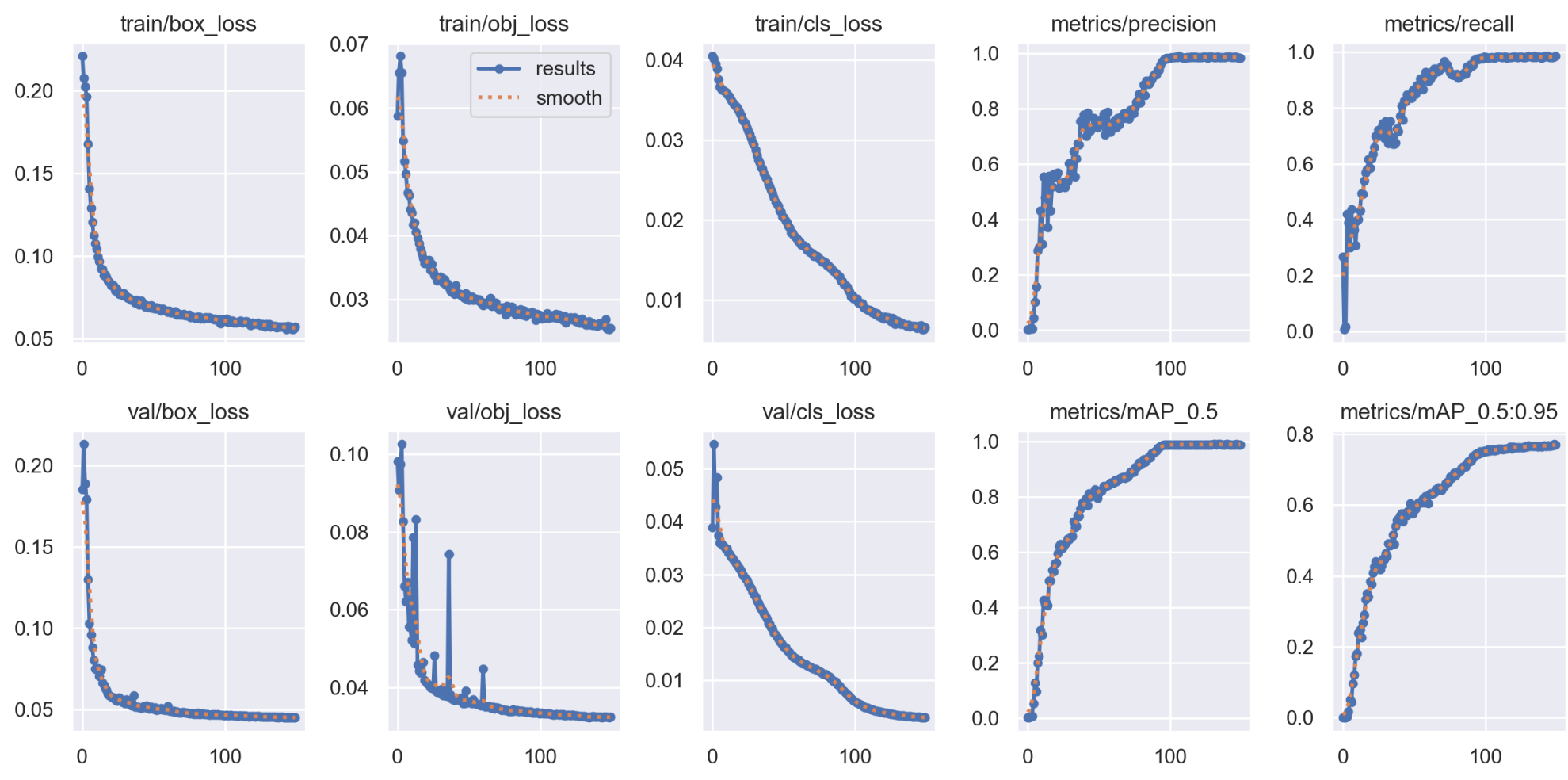
- 训练集损失类(第一行前3张 + 第二行前3张)
损失(Loss)是模型预测结果与真实标签之间的"误差",损失越低,模型学习效果越好。
-
train/box_loss(第一行第1张):训练集的边界框损失,衡量模型预测的边界框(目标位置、宽高)与真实边界框的差异(如坐标偏移、宽高误差等)。
-
train/obj_loss(第一行第2张):训练集的目标存在损失(Objectness Loss),判断"该位置是否有物体"(区分前景和背景)。损失降低表示模型对"有无目标"的判断更准确。
-
train/cls_loss(第一行第3张):训练集的分类损失,对检测到的目标,判断其属于哪一类别(如区分"人""车""狗"等)。损失降低表示分类准确性提升。
- 验证集损失类(第二行中间3张)
验证集(Val)是模型未见过的数据,用于评估模型的泛化能力(避免过拟合)。指标逻辑与训练集一致,但重点看"训练 vs 验证"的差距:若验证损失远高于训练损失,可能存在过拟合。
-
val/box_loss(第二行第1张):验证集的边界框损失,反映模型在未知数据上预测边界框的误差。
-
val/obj_loss(第二行第2张):验证集的目标存在损失,反映模型在未知数据上判断"有无目标"的准确性。
-
val/cls_loss(第二行第3张):验证集的分类损失,反映模型在未知数据上分类的准确性。
- 评估指标类(第一行后2张 + 第二行后2张)
这些是目标检测任务的核心性能评估指标,需结合"精度(Precision)""召回率(Recall)""mAP(平均精度均值)"理解。
-
metrics/precision(第一行第4张):精度(精确率),公式:Precision=TP+FPTP(TP=真正例,FP=假正例)。
表示"模型预测为正类的结果中,实际确实是正类的比例"。数值越高,预测越精准(减少误检)。
-
metrics/recall(第一行第5张):召回率(查全率),公式:Recall=TP+FNTP(FN=假负例)。
表示"实际为正类的样本中,被模型成功预测为正类的比例"。数值越高,漏检越少(覆盖更多真实目标)。
-
metrics/mAP_0.5(第二行第4张):mAP(Mean Average Precision)在 IoU=0.5 时的结果。
-
IoU(Intersection over Union)是"预测边界框与真实边界框的重叠度",IoU=0.5 是目标检测中常用的"宽松匹配标准"。
-
mAP 是对所有类别 AP(Average Precision)的平均,AP 本身是"Precision-Recall 曲线下的面积"。mAP 越高,模型整体检测性能越强。
-
-
metrics/mAP_0.5:0.95(第二行第5张):mAP 在 IoU 从 0.5 到 0.95(步长0.05) 时的平均值(即计算 IoU=0.5, 0.55, ..., 0.95 共10个阈值的 mAP 后取平均)。
该指标更严格,要求模型在不同重叠度要求下都有稳定表现。数值越高,模型鲁棒性越强。
二 问题的处理
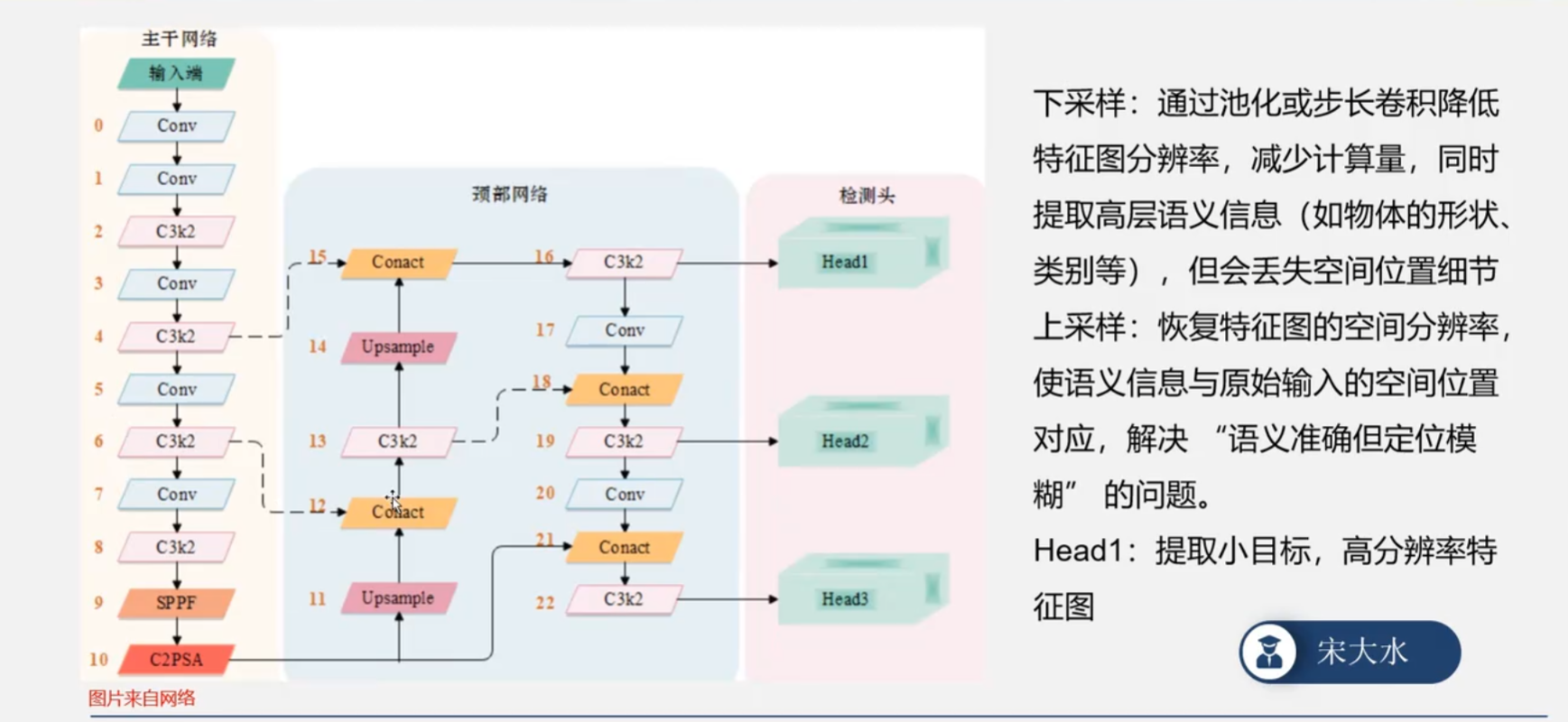
1.YOLOv5的核心架构由哪几个主要部分组成?
YOLOv5的核心架构主要由以下四个部分组成:
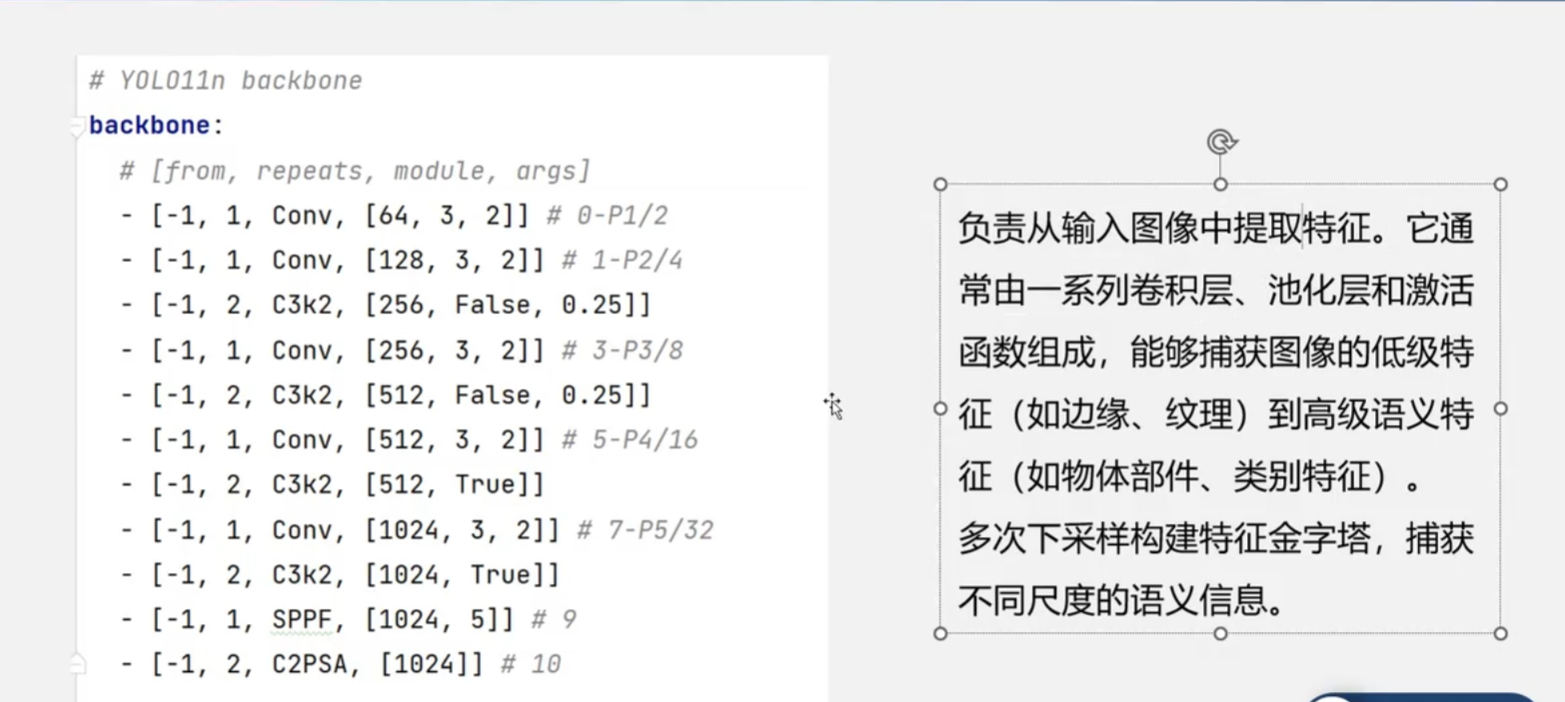
-
Backbone(主干网络):采用CSPDarknet,负责从输入图像中提取多层次的特征。它使用了CSPNet结构来增强网络的学习能力并减少计算量。
-
Neck(颈部):采用PANet(Path Aggregation Network),负责融合来自Backbone不同层次的特征图。它通过自底向上和自顶向下的路径,将深层语义特征与浅层定位特征有效结合,提升对不同尺度目标的检测能力。
-
Head(检测头):负责最终的预测。YOLOv5采用了三个不同尺度的检测头(大、中、小),分别对应检测大、中、小目标。每个检测头会输出边界框坐标、置信度以及类别概率。
-
Input(输入端):集成了Mosaic数据增强、自适应锚框计算、自适应图片缩放等技术,用于在训练前对输入数据进行预处理,提升模型的鲁棒性和训练效率。
2. YOLOv5是如何进行目标检测的,它的检测流程是怎样的?
YOLOv5的检测流程遵循典型的单阶段(one-stage)检测器范式,核心思想是"只看一次"(You Only Look Once)。
-
图像预处理与缩放:输入图像被统一缩放到一个标准尺寸(如640x640),并进行归一化。
-
特征提取:预处理后的图像送入Backbone(CSPDarknet),网络逐层卷积,生成一系列具有不同抽象程度的特征图。
-
特征融合:这些多尺度特征图被送入Neck(PANet)。PANet通过上采样和拼接操作,将深层的语义信息(利于分类)传递到浅层,同时通过下采样将浅层的细节信息(利于定位)传递到深层,生成三个融合了丰富信息的特征金字塔。
-
预测生成:三个融合后的特征图分别进入三个Head(检测头)。每个网格单元会预测多个边界框。对于每个边界框,Head会输出:
-
4个坐标值(中心点x, y,宽度w,高度h)
-
1个目标置信度(表示框内包含目标的概率)
-
N个类别概率(N为数据集的类别数)
-
-
后处理:对Head输出的所有预测框进行过滤:
-
置信度过滤:根据置信度阈值(如
conf-thres=0.25)剔除低置信度的预测框。 -
非极大值抑制(NMS):根据交并比阈值(如
iou-thres=0.45)合并重叠度高的预测框,保留最优的一个,消除冗余框。
-
3. 在YOLOv5中,如何准备自己的数据集进行训练?
准备自定义数据集主要分为以下几个步骤:
-
图像收集与标注:
-
收集包含待检测目标的图片。
-
使用标注工具(如LabelImg、CVAT、Roboflow)对图片中的目标进行标注,标注格式通常为YOLO格式(
.txt文件)。每个.txt文件对应一张图片,每行包含:<class_id> <x_center> <y_center> <width> <height>,其中坐标均为相对于图片宽高的归一化值(0-1之间)。
-
-
组织目录结构:按照YOLOv5要求的格式组织数据集。
custom_dataset/ ├── images/ │ ├── train/ # 存放训练图片 │ └── val/ # 存放验证图片 └── labels/ ├── train/ # 存放训练标签(.txt文件) └── val/ # 存放验证标签(.txt文件) -
创建数据集配置文件:创建一个
.yaml文件(如custom_data.yaml),定义数据集的路径、类别数和类别名。path: ../custom_dataset # 数据集根目录 train: images/train # 训练集路径(相对于path) val: images/val # 验证集路径(相对于path) nc: 3 # 类别数量 names: ['cat', 'dog', 'person'] # 类别名称列表
4.开始训练:使用命令行启动训练,并指定数据集配置文件。
python train.py --data custom_data.yaml --weights yolov5s.pt --epochs 1004. 怎样调整YOLOv5的超参数来优化检测效果?
YOLOv5的超参数主要定义在data/hyps/目录下的.yaml文件中(如hyp.scratch-low.yaml)。关键超参数包括:
-
学习率(lr0, lrf):
lr0是初始学习率,lrf是最终学习率系数(最终学习率 = lr0 * lrf)。调整学习率是影响训练稳定性和效果的关键。学习率过大可能导致震荡不收敛,过小则收敛慢。通常可以从默认值(如0.01)开始,根据训练损失曲线进行调整。 -
优化器动量(momentum):帮助加速SGD在相关方向的收敛并抑制震荡。一般保持在0.9左右。
-
权重衰减(weight_decay):用于防止过拟合的正则化项。默认值(如0.0005)通常效果不错,如果模型过拟合可适当增加。
-
数据增强参数:
-
hsv_h,hsv_s,hsv_v:色调、饱和度、明度增强强度。 -
degrees,translate,scale,shear:旋转、平移、缩放、剪切增强的幅度。 -
mosaic:是否使用Mosaic数据增强(0.0为关闭,1.0为100%使用)。 -
增强强度不宜过大,否则可能引入过多噪声,损害模型性能。对小目标检测,可适当增强
scale和mosaic。
-
-
损失函数权重:
-
box_loss_gain:边界框回归损失权重。 -
cls_loss_gain:分类损失权重。 -
obj_loss_gain:目标置信度损失权重。 -
如果某一项任务(如定位或分类)表现不佳,可以尝试微调其对应的权重。
-
-
调整策略:建议使用超参数进化功能。YOLOv5内置了超参数进化算法,可以自动搜索一组更优的超参数组合。
python
python train.py --data custom_data.yaml --weights yolov5s.pt --epochs 100 --evolve5. YOLOv5中的损失函数是如何计算的,有什么作用?
YOLOv5的损失函数由三部分组成,共同指导模型学习如何准确预测目标的位置、置信度和类别。
-
边界框回归损失(Box Loss) :衡量预测框与真实框之间的差异。YOLOv5默认使用CIoU Loss。它不仅考虑重叠面积(IoU)、中心点距离,还考虑了宽高比的相似性,比传统的IoU Loss收敛更快、定位更准。
-
目标置信度损失(Objectness Loss) :衡量预测框内是否包含目标的置信度。使用二元交叉熵损失(BCEWithLogitsLoss)。对于正样本(有目标),希望其置信度接近1;对于负样本(背景),希望其置信度接近0。
-
分类损失(Classification Loss) :衡量预测框内目标类别的准确性。同样使用二元交叉熵损失(BCEWithLogitsLoss),允许一个目标属于多个类别(多标签分类)。
-
总损失 :
总损失 = λ1 * Box Loss + λ2 * Obj Loss + λ3 * Cls Loss,其中λ1, λ2, λ3是各部分损失的权重系数(即超参数中的box_loss_gain,obj_loss_gain,cls_loss_gain)。 -
作用:损失函数是模型训练的"指南针"。在训练过程中,通过反向传播算法,模型根据损失值计算梯度并更新网络权重,目标是使总损失值不断减小,从而使模型的预测结果越来越接近真实情况。
6. 如何评估YOLOv5模型的性能,有哪些常用的评估指标?
训练完成后,YOLOv5会在验证集上自动进行评估,并生成详细的评估报告。核心评估指标包括:
-
精确率(Precision) :模型预测为正的样本中,真正为正的比例。
Precision = TP / (TP + FP)。高精确率意味着模型"找得准",误报少。 -
召回率(Recall) :所有真实为正的样本中,被模型正确预测为正的比例。
Recall = TP / (TP + FN)。高召回率意味着模型"找得全",漏检少。 -
平均精度(Average Precision, AP):在不同召回率阈值下的精确率的平均值。它是衡量单个类别检测性能的核心指标。计算方式是在精确率-召回率曲线(P-R曲线)下求面积。
-
平均精度均值(mAP) :所有类别AP的平均值。mAP@0.5 是指在IoU阈值为0.5时计算的mAP,是YOLO系列最常用的综合性能指标。mAP@0.5:0.95 是指在IoU阈值从0.5到0.95(步长0.05)区间内,计算多个mAP后再取平均值,这是一个更严格的指标。
-
推理速度(Inference Time):模型处理单张图片所需的时间,通常以毫秒(ms)计,或每秒帧数(FPS)。这对实际部署至关重要。
-
模型大小(Model Size) :模型权重文件(
.pt)的大小,关系到模型在边缘设备上的存储和加载效率。
7. 怎样在YOLOv5中处理小目标检测的问题?
小目标检测是YOLOv5的挑战之一,可以通过以下方法进行优化:
-
数据层面:
-
提高输入分辨率 :在训练和推理时,增加
--img-size参数(如从640提高到1280)。更高的分辨率能为小目标保留更多像素信息。 -
针对性数据增强 :在超参数中增强Mosaic、随机缩放(
scale)和复制-粘贴(Copy-Paste)等增强,可以增加小目标出现的多样性和频率。 -
过采样小目标丰富的图片:在数据集中,如果某些图片包含大量小目标,可以重复采样这些图片。
-
-
模型层面:
-
使用更小的检测头 :YOLOv5的**小目标检测头(P5/20尺度)** 负责检测小目标。确保其设计合理,并关注其训练效果。
-
修改Neck结构:可以尝试引入更强大的特征融合模块,如BiFPN,以更好地融合浅层的高分辨率特征(包含小目标细节)。
-
-
训练策略:
-
调整锚框(Anchor):YOLOv5会通过K-means聚类在您的数据集上自动计算锚框尺寸。确保聚类生成的小尺寸锚框适合您的小目标。
-
调整损失函数权重:可以尝试略微提高小目标对应的检测头在损失函数中的权重,让模型更关注小目标的学习。
-
-
后处理层面:
-
降低置信度阈值 :在推理时,适当降低
--conf-thres(如从0.25降到0.1),以避免过滤掉一些置信度不高的小目标预测。 -
调整NMS参数 :对于密集的小目标,可以适当提高
--iou-thres,防止NMS过度抑制相邻的小目标。
-
8. YOLOv5中的多尺度训练是如何实现的,有什么好处?
具体操作步骤分解:
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=320, help="train, val image size (pixels)")在这里面修改默认的尺寸
# 查看 train.py 中的参数定义
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%')
action='store_true' 意味着:
命令行中指定 --multi-scale时,参数值为 True
不指定时,参数值为 False
-
参数设定:
当您启动训练命令,例如
python train.py --img-size 640,这实际上设定了基础训练尺寸 为640x640。YOLOv5内部会以此为基础计算多尺度范围。默认的多尺度范围是[0.5 * 640, 1.5 * 640] = [320, 960],并且缩放步长通常为32(网络下采样倍数的要求)。 -
训练循环:
训练是按"轮次"进行的。假设总训练轮次为100轮。
- YOLOv5会每训练10轮(这是一个默认频率,对应源码中的参数),触发一次"多尺度尺寸更新"。
-
尺寸更新算法:
当触发更新时,系统会执行以下操作:
-
在预设的最小尺寸 (如320)和最大尺寸 (如960)之间,随机选择一个整数 作为新的训练尺寸。例如,可能随机选中了
704。 -
这个新尺寸必须是32的整数倍 (因为YOLOv5网络总共下采样5次,2^5=32)。所以如果随机到700,系统会自动将其调整为最近的32的倍数,即
704或672。 -
这个新尺寸(如704)将成为接下来10轮训练中,所有训练图片统一被缩放到的目标尺寸。
-
-
图片缩放:
在每一批数据加载时,数据加载器会将这批数据中的所有图片,统一缩放到当前生效的尺寸(比如704x704)。
-
缩放不是简单的拉伸,而是保持原图长宽比的"等比例缩放",然后用灰色边缘填充到正方形。
-
这意味着,在不同的10轮周期里,同一张图片会以不同的绝对像素大小输入网络。
-
-
好处:
-
提升模型鲁棒性:迫使模型适应不同尺度的输入,使其在推理时对不同分辨率的图像都具有良好的检测能力,相当于一种正则化,有助于防止过拟合。
-
模拟多尺度目标 :同一张图片在不同输入尺寸下,其中的目标相对大小会发生变化。这有助于模型学习到更通用的尺度不变特征,尤其有利于提升小目标的检测性能(因为当图片被缩放到较小时,小目标在特征图上的相对尺寸会变大)。
-
加速训练:在训练早期使用较小的尺寸可以加快训练速度。
-
9. 如何将训练好的YOLOv5模型部署到实际应用场景中?
YOLOv5提供了灵活的部署路径,主要步骤如下:
-
模型导出 :使用YOLOv5的
export.py脚本将训练好的PyTorch模型(.pt)转换为部署所需的格式。-
TorchScript :
python export.py --weights best.pt --include torchscript。适用于PyTorch生态的C++或移动端部署。 -
ONNX :
python export.py --weights best.pt --include onnx。一种开放的模型交换格式,被TensorRT, OpenVINO, ONNX Runtime等多种推理引擎支持。 -
TensorRT :
python export.py --weights best.pt --include engine --device 0。需要先导出ONNX,再用TensorRT的转换工具生成.engine文件,这是NVIDIA GPU上性能最优的部署格式。 -
CoreML:用于苹果设备(iOS/macOS)。
-
OpenVINO:用于英特尔CPU、集成显卡等硬件。
-
-
选择推理引擎:根据目标硬件平台选择合适的推理框架进行加速。
-
NVIDIA GPU :首选TensorRT,能实现极致的推理速度。
-
Intel CPU/GPU :使用OpenVINO Toolkit。
-
移动端/边缘设备 :可使用ONNX Runtime 、TFLite (需转换)或NCNN 、MNN等轻量级框架。
-
服务器端Python:可直接使用YOLOv5原始的PyTorch模型或ONNX模型配合ONNX Runtime。
-
-
开发应用接口:使用选定的推理引擎加载导出的模型,编写前处理(图像缩放、归一化)、推理、后处理(解码、NMS)的代码,并封装成API、服务或嵌入式应用程序。
-
性能优化与测试:在目标硬件上进行性能测试和优化,如调整批量大小(batch size)、使用半精度(FP16)或整型(INT8)量化以进一步提升速度。
10. YOLOv5相比之前的YOLO版本有哪些改进之处?
YOLOv5并非YOLO原作者团队发布,但其在工程实现和易用性上取得了巨大成功,主要改进包括:
-
框架与易用性:
-
基于PyTorch:YOLOv5使用PyTorch框架,相比YOLOv4的Darknet,拥有更庞大活跃的社区、更易用的API和更丰富的生态资源,大大降低了研究和部署门槛。
-
工程化完善:提供了极其完整的代码库,包含数据准备、训练、验证、测试、导出、部署的全流程脚本,并配有详细的文档和教程,开箱即用体验极佳。
-
-
训练优化:
-
自适应锚框计算:训练前自动在自定义数据集上计算最优的锚框尺寸,无需手动修改。
-
自适应图片缩放:在推理时,对输入图片进行最小化的填充(黑边),减少计算量,提升推理速度。
-
超参数进化:内置了超参数自动搜索优化功能。
-
-
数据增强:
- 默认集成了强大的Mosaic 和MixUp 数据增强,并在后续版本中引入了Copy-Paste等增强,有效提升了模型泛化能力,特别是对小目标和遮挡目标的检测。
-
模型结构:
-
Backbone :采用CSPDarknet,通过Cross Stage Partial connections减少了计算量并保持了精度。
-
Neck :采用PANet进行特征融合,加强了不同层级特征的信息流动。
-
激活函数 :使用**SiLU(Swish)** 激活函数替代LeakyReLU,性能略有提升。
-
-
模型系列 :提供了从轻量到高精度的多个预定义模型(YOLOv5n/s/m/l/x),用户可以根据速度和精度需求灵活选择。
-
损失函数 :使用CIoU Loss作为边界框回归损失,收敛更快,定位更准确。
总结来说 ,YOLOv5最大的贡献在于其卓越的工程化实现,它将当时先进的目标检测技术(如CSP、PANet、Mosaic等)整合到一个高度易用、模块化、性能强大的PyTorch框架中,极大地推动了YOLO系列在工业界的普及和应用。