目录:
-
- 一、实现流程梳理
- 二、需求背景
- [三、环境准备 & 数据加载](#三、环境准备 & 数据加载)
-
- [3.1 首先安装需要的依赖:](#3.1 首先安装需要的依赖:)
- [3.2 代码第一步:加载数据](#3.2 代码第一步:加载数据)
- [3.3 数据预处理](#3.3 数据预处理)
- 四、构建CNN模型
-
- [4.1 换成224×224的图片参数计算](#4.1 换成224×224的图片参数计算)
- [4.2 加层,一般4次池化到14×14(也可以根据你需要增减) 为啥到14x14就不池化了 不是池化到1x1](#4.2 加层,一般4次池化到14×14(也可以根据你需要增减) 为啥到14x14就不池化了 不是池化到1x1)
- 五、模型训练
- [六、模型评估 & 预测](#六、模型评估 & 预测)
- 七、关键细节
一、实现流程梳理
- 问题理解 & 数据准备
↓- 数据预处理(特征工程)
↓- 构建CNN模型
↓- 模型训练 & 评估
↓- 预测 & 部署
二、需求背景
手机价格分类就是:根据手机的各项属性(比如品牌、CPU、内存、电池、屏幕尺寸...),预测它属于哪个价格档位(比如:低/中/高 三档,或者 0-1000/1000-3000/3000+ 等)
CNN 在这里一般处理两种输入:
- 如果是手机图片数据:直接用CNN提取图片特征做分类
- 如果是结构化表格数据(比如参数表格):我们把一维特征reshape成二维特征图,再用CNN提取特征分类
我们这里以最常见的结构化表格数据 为例(如果是图片,流程基本一致,只是输入不同),用经典的 Mobile Price Classification 数据集 做演示。
训练数据集的地址:
https://www.kaggle.com/datasets/iabhishekofficial/mobile-price-classification/data
三、环境准备 & 数据加载
3.1 首先安装需要的依赖:
powershell
pip install pandas numpy scikit-learn torch matplotlib3.2 代码第一步:加载数据
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 加载数据集(kaggle下载的csv)
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
print(train_df.head())
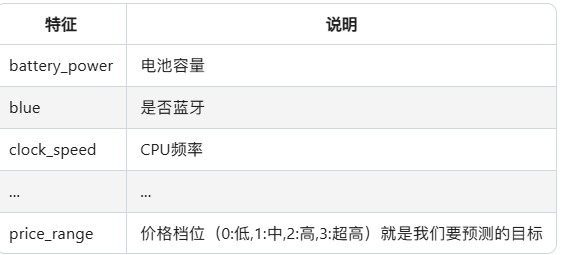
print("数据形状:", train_df.shape)数据集截图效果:
3.3 数据预处理
我们把表格数据转为CNN能处理的格式:
python
# 分离特征和标签
X = train_df.drop("price_range", axis=1).values # 所有特征
y = train_df["price_range"].values # 标签
# 拆分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化特征
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
# ========== 关键一步:把一维特征转为二维 "特征图" 给CNN ==========
# 我们有20个特征,把它 reshape 成 (4,5) 或者 (5,4) 二维,就可以当成图片输入CNN了
# 形状变化:(batch_size, 20) → (batch_size, 1, 4, 5) → channel=1, 高4宽5
feature_count = X_train.shape[1]
# 这里我们凑成正方形:如果特征数不能开方,补0即可,这里20个特征→(4,5)=20,刚好
img_h = 4
img_w = 5
X_train = X_train.reshape(-1, 1, img_h, img_w) # (样本数, 通道数, 高, 宽)
X_val = X_val.reshape(-1, 1, img_h, img_w)
# 转成PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_val_tensor = torch.tensor(y_val, dtype=torch.long)
# 创建DataLoader
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
val_dataset = TensorDataset(X_val_tensor, y_val_tensor)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)💡 如果是图片数据,这一步不一样:
python
# 如果是手机图片,直接读取图片,resize到统一大小,归一化即可
# 比如每张图片是 (224,224,3) → 转成 (3,224,224) 张量,直接输入CNN代码疑点解析:
python
# 分离特征和标签
X = train_df.drop("price_range", axis=1).values # 所有特征
y = train_df["price_range"].values # 标签
我们先理清楚概念:
- 特征(X):就是用来做预测的"输入信息",在手机价格分类这个任务里,就是手机的所有参数:电池容量、CPU频率、内存大小...这些是我们已知的信息
- 标签(y):就是我们想要预测的目标,这里就是手机的价格档位(price_range列,0=低/1=中/2=高/3=超高)
然后逐行解释代码:
1. train_df.drop("price_range", axis=1)
- train_df:是我们加载进来的整个训练数据表(pandas的DataFrame格式)
- .drop("price_range", axis=1):把price_range这一列从表格里删掉
- axis=1的意思是"按列删除",axis=0是按行删除,这里我们删列,所以写1
2. .values:把删掉之后剩下的表格,转成numpy的二维数组,方便后续处理,结果赋值给X,所以X就是所有特征,形状是(样本数, 特征数)
3. y = train_df["price_range"].values
- train_df["price_range"]:把我们要预测的目标列单独拿出来
- .values:同样转成numpy数组,赋值给y,所以y就是所有标签,形状是(样本数,)
举个例子:如果我们有1000条手机数据,20个参数,那么:
- X.shape = (1000, 20) → 1000个手机,每个手机20个特征
- y.shape = (1000,) → 每个手机对应1个价格档位标签四、构建CNN模型
我们来搭一个简单的CNN分类网络,结构非常清晰:
python
class CNNPhonePriceClassifier(nn.Module):
def __init__(self, num_classes=4, in_channels=1):
super().__init__()
# 卷积层提取特征
self.conv_layers = nn.Sequential(
# 第一层卷积:输入1通道,输出16个卷积核,kernel 3x3,padding保持大小
nn.Conv2d(in_channels, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2), # 池化,尺寸减半
# 第二层卷积
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
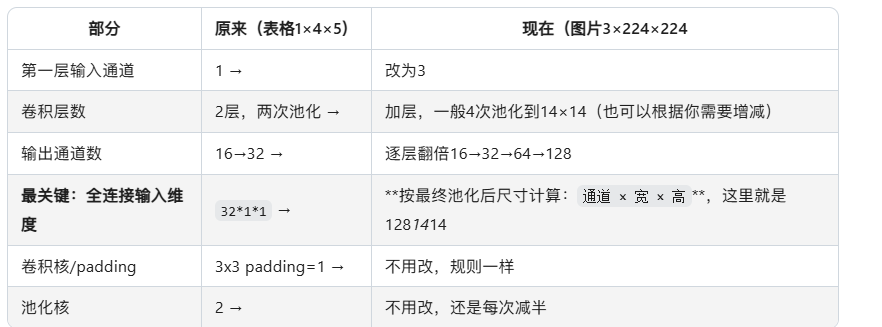
# 计算全连接层输入维度:输入是(1,4,5) → 池化两次后 → 32通道,1x1(如果输入更大,这里维度会变)
# 这里我们的例子:4x5 → 第一次池化→2x2 → 第二次池化→1x1 → 32*1*1 = 32
self.fc_layers = nn.Sequential(
nn.Dropout(0.3), # 防止过拟合
nn.Linear(32 * 1 * 1, 64),
nn.ReLU(),
nn.Linear(64, num_classes) # 最后输出,对应类别数
)
def forward(self, x):
x = self.conv_layers(x) # 卷积提取特征
x = x.view(x.size(0), -1) # 展平
x = self.fc_layers(x) # 全连接分类
return x
# 初始化模型
model = CNNPhonePriceClassifier(num_classes=4)
print(model)如果你的输入是大尺寸图片,比如(3, 224, 224),只需要修改全连接层的输入维度就行,卷积部分逻辑不变。
💡 一句话总结参数来源

举例:padding=1:为了保持卷积后的尺寸不变,计算出来的:
python
padding的作用是给输入边缘补0,我们这里要卷积后尺寸不变,所以可以算出来:
公式:卷积后尺寸 = (输入尺寸 + 2*padding - kernel_size)/stride + 1
我们的默认 stride=1(卷积步长,不写就是1),想要尺寸不变,代入:
输入尺寸 = 输出尺寸
输入尺寸 = (输入尺寸 + 2*padding - 3)/1 + 1
解这个方程:→ padding = 14.1 换成224×224的图片参数计算
池化简易逻辑:
MaxPool2d(2) 就是直接把尺寸除以2,向下取整:
原始 4 × 5 → 第一次除以2:4/2=2,5/2=2.5向下取整=2 → 2×2
再除以2:2/2=1,2/2=1 → 1×1 刚好两次池化就变成1×1了~
如果原始宽是6不是5,那第一次池化就是4×6 → 2×3,第二次池化就是1×1,还是会得到1×1,本质就是我们原始输入本身就很小,两次减半之后自然就到1了😀
4.2 加层,一般4次池化到14×14(也可以根据你需要增减) 为啥到14x14就不池化了 不是池化到1x1
其实池化不是必须到1×1,不继续池化是两个原因:性能需求+计算效率:
1. 为什么原来小输入要池化到1×1?
原来我们输入只有4×5,本身尺寸就极小:
- 两次池化自然就到1×1了,没得选,再池化尺寸就变成0了,没法继续
- 而且小输入特征少,到1×1刚好,所有信息都浓缩完了,直接接全连接就可以
2. 为什么224×224不用池化到1×1?
我们先算一下,如果要把224×224池化到1×1,需要池化几次:
224 → 112 → 56 → 28 → 14 → 7 → 3 → 1 → 一共要 7次池化
不继续池化到1×1,是两个核心原因:
① 会丢失大量空间信息,效果变差
② 参数会爆炸,计算量太大
3. 那什么时候需要池化到1×1?
只有两种场景:
- 输入本身极小:就像我们原来的4×5表格特征,本身尺寸小,自然到1×1
- 全局池化:不管输入多大,最后用一层AdaptiveAvgPool2d(1)直接强制到1×1,目的是让模型支持任意输入尺寸,这是分类任务的一种技巧,不是必须的。比如现在很多backbone 都会最后加全局池化到1×1,那是另外的设计了。
五、模型训练
现在开始训练,写训练循环:
python
# 定义损失函数和优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss() # 多分类用交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 训练轮数
num_epochs = 20
train_losses = []
val_losses = []
val_accs = []
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_train_loss = 0.0
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
# 前向传播
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
# 反向传播 + 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_train_loss += loss.item() * batch_x.size(0)
epoch_train_loss = running_train_loss / len(train_loader.dataset)
train_losses.append(epoch_train_loss)
# 验证阶段
model.eval()
running_val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for batch_x, batch_y in val_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
running_val_loss += loss.item() * batch_x.size(0)
# 计算准确率
_, predicted = torch.max(outputs.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
epoch_val_loss = running_val_loss / len(val_loader.dataset)
epoch_val_acc = correct / total
val_losses.append(epoch_val_loss)
val_accs.append(epoch_val_acc)
# 打印日志
print(f"Epoch [{epoch+1}/{num_epochs}] "
f"Train Loss: {epoch_train_loss:.4f} "
f"Val Loss: {epoch_val_loss:.4f} "
f"Val Acc: {epoch_val_acc:.4f}")
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label="Train Loss")
plt.plot(val_losses, label="Val Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(val_accs, label="Val Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()六、模型评估 & 预测
训练完了我们来评估一下,做个测试预测:
python
# 在验证集上输出最终准确率
print(f"最终验证准确率: {val_accs[-1]:.4f}")
# 保存模型
torch.save(model.state_dict(), "cnn_phone_classifier.pth")
print("模型已保存")
# ========== 预测新样本 ==========
# 加载测试数据
X_test = test_df.drop("id", axis=1).values if "id" in test_df.columns else test_df.values
X_test = scaler.transform(X_test)
X_test = X_test.reshape(-1, 1, img_h, img_w)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32).to(device)
model.eval()
with torch.no_grad():
outputs = model(X_test_tensor)
_, predictions = torch.max(outputs, 1)
# 输出预测结果
predictions = predictions.cpu().numpy()
print("预测结果(前10个):", predictions[:10])
# 可以把结果保存成csv
test_df["predicted_price_range"] = predictions
test_df.to_csv("predictions.csv", index=False)七、关键细节
1.为什么CNN能处理表格数据?
- 我们把一维特征 reshape 成二维,CNN可以捕捉特征之间的局部关联,比纯全连接网络泛化能力更强
- 如果特征很多,reshape成更大的二维,效果更好
2.输入尺寸怎么计算?
- 卷积后尺寸公式:
output_size = floor((input_size + 2*padding - kernel_size)/stride) + 1
池化一般是kernel=2, stride=2,所以尺寸直接减半
3.过拟合怎么办?
- 加 Dropout(我们代码里已经加了)
- 加 L2 正则(weight_decay)
- 增加数据,或者做数据增强(如果是图片数据)
4.如果是图片数据,整个流程哪里不一样?
python
# 只需要改输入预处理和输入通道数
from torchvision import transforms
from PIL import Image
# 图片预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 模型把in_channels改成3
model = CNNPhonePriceClassifier(num_classes=4, in_channels=3)
# 剩下的训练预测代码完全一样!