一、引言
在日常的Flink应用开发上线流程中,我们通常会基于生产数据流量的评估进行资源参数配置与性能测试,测试准出后才去进行生产上线。然而,实际的生产业务流量往往呈现出明显的 "潮汐效应"-白天流量高峰,夜间流量低谷,传统的静态资源配置方式面临着两大无法调和的痛点:
- 资源利用率低:为了应对峰值流量,不得不预留大量冗余资源,导致平时资源利用率普遍低于 30%,造成巨大的成本浪费。
- 性能瓶颈与故障风险:当突发流量超过预留资源时,会导致作业出现严重的反压、延迟增加甚至崩溃,直接影响业务可用性。
针对上述痛点,Flink 的扩缩容能力随着版本迭代,也经历了一个从无到有、从手动到自动的演进过程。本文将介绍 Flink 从诞生至今发展出的多种主流扩缩容方案与适用场景。
二、Flink扩缩容方案详解
Flink扩缩容的本质是改变"可用的 Slot 数量"与"算子的并行度"之间的匹配关系。从调整粒度来看,有两条路径:
- 调整 TaskManager 数量(粗粒度):通过增减 TaskManager 来改变 Slot 总供给。
- 调整算子并行度(细粒度):不改变 TM 数量,而是在 Slot 总供给不变的前提下,动态调整每个算子的并行度设定。
1.传统手动扩缩容方案
核心机制:停止作业 → 创建 savepoint → 以新并行度重启作业。
xml
# 1. 触发 savepoint
flink savepoint <job-id> <target-directory>
# 2. 停止作业
flink cancel <job-id>
# 3. 从 savepoint 重启并指定新并行度
flink run -d -s <savepoint-path> -p <new-parallelism> <job-jar>官方之前提供了flink modify命令,可以将上述三个步骤合并为一个命令(现已废弃):
xml
flink modify <jobID> -p <newParallelism>尽管手动扩缩容简单可靠,但它存在几个致命的缺陷:
- 需要停机:整个扩缩容过程中作业会停止运行,导致数据处理中断
- 恢复时间长:对于大状态作业,从 Savepoint 恢复可能需要几十分钟甚至几小时
- 无法应对突发流量:人工操作存在延迟,无法及时应对流量突增
适用场景:业务对停机时间要求不高、作业状态非常小、流量变化非常缓慢且可预测。
2.AdaptiveScheduler(自适应调度器)
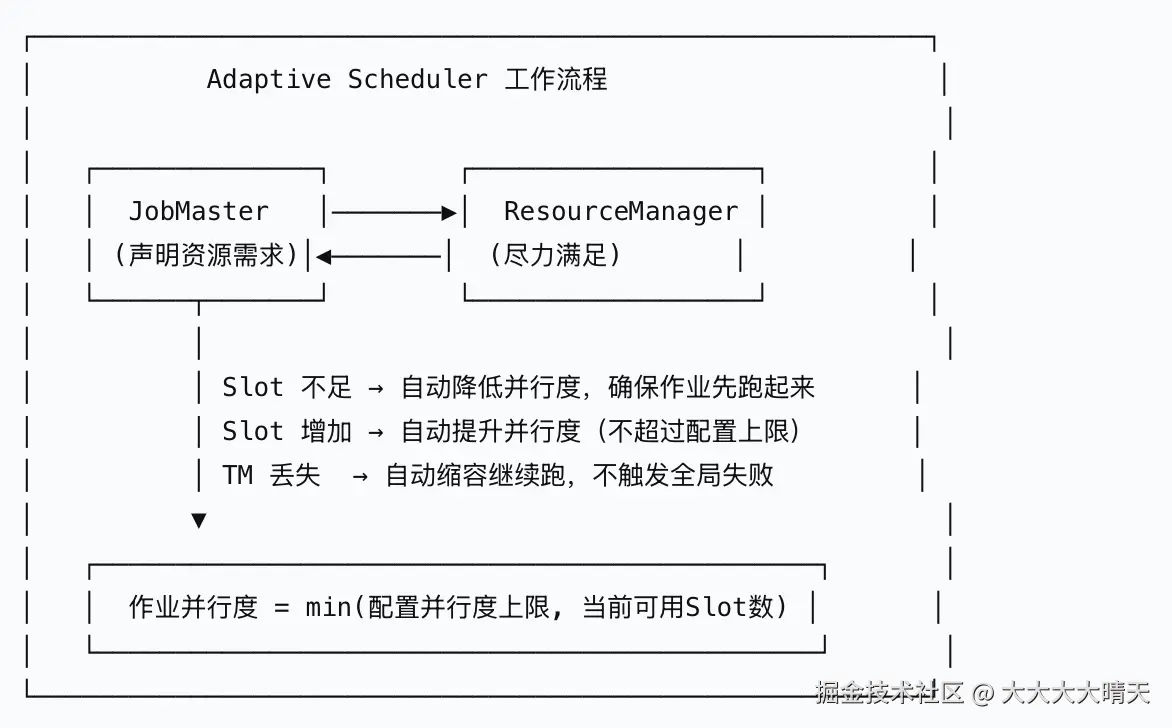
自适应调度器是 Flink 1.13 版本引入的一个特性,它彻底改变了 Flink 的资源调度模型。传统的 Flink 调度器采用 "命令式" 资源管理模式 ------ 作业提交时明确要求 N 个 slot,如果资源不足,作业就无法启动。而自适应调度器采用 "声明式" 资源管理模式 ------ 作业只声明资源需求的上下限,由 ResourceManager 尽力满足。
核心机制:根据当前可用的 slot 数量动态调整作业的并行度。当 JobMaster 在运行时获得更多资源,它会自动利用最近的可用状态点触发 rescale。
配置方式:
python
# ========== 调度器选择 ==========
jobmanager.scheduler: Adaptive
# 实际并行度 = min(可用 slots, parallelism.default)
parallelism.default: 100 # 期望的最大并行度
# 定义了并行度扩增时的最小增加值,用于避免频繁扩缩容导致的作业不稳定
jobmanager.adaptive-scheduler.min-parallelism-increase:2
# 定义了资源稳定超时时间,用于平衡启动速度与资源利用率
jobmanager.adaptive-scheduler.resource-stabilization-timeout:20 s
# 定义了作业提交或重启后,等待获取所需资源的最长时间,用于增强集群对临时资源短缺的弹性
jobmanager.adaptive-scheduler.resource-wait-timeout:5 min当发生扩缩容事件时,自适应调度器会自动从最近完成的 Checkpoint 恢复作业,而不需要手动创建 Savepoint,这大大减少了扩缩容的开销。不过,自适应调度器也存在以下不足:
- 仅支持流作业(批处理作业可设置jobmanager.scheduler: AdaptiveBatch)
- 不支持细粒度的本地恢复,故障时需整个作业重启
- 状态恢复需从远程存储全量下载
- 对输入速率变化不敏感,调整粒度依然依赖 Slot 供给
适用场景:多作业共享资源池、集群资源会波动的环境、需要提升容错能力的场景。
Flink 1.18 版本引入了外部化声明式资源管理是 Flink 扩缩容技术的一个重大突破,外部化声明式资源管理提供了一个新的 REST API 端点,允许用户在作业运行时重新声明每个顶点的并行度上下限,自适应调度器会自动调整相应顶点的并行度,以匹配新的资源需求;同时只需要重启受影响的顶点,大大减少了扩缩容对业务的影响。虽然提供了细粒度的作业间资源控制,但外部化声明式资源管理仍处于MVP阶段,谨慎在生产使用。
3.Reactive Mode(响应式模式)
响应式模式是自适应调度器的一个特殊变种,它将作业配置为总是使用集群中所有可用的资源。在响应式模式下,作业的配置并行度会被忽略,Flink 会自动将并行度设置为当前可用 slot 的数量。
配置方式:
makefile
scheduler-mode: reactive响应式模式的最大优势是可以与外部资源编排系统(如 Kubernetes Cluster Autoscaler)完美配合。外部系统负责根据业务指标调整 TaskManager 的数量,而 Flink 则负责自动调整作业的并行度以匹配可用资源。

自适应调度器存在的不足也适用于响应式模式,此外响应式模式还存在以下限制:
- 仅支持Standalone Application部署,不支持YARN、Native Kubernetes等主动资源提供者
- 缩容时如果TaskManager未正确关闭,可能需要等待心跳超时(默认50秒)
适用场景:单作业独享集群(Application Mode)、Kubernetes + HPA 部署。
4.第三方生态自动扩缩容方案
- 基于 Kubernetes HPA 的扩缩容方案
Kubernetes Horizontal Pod Autoscaler(HPA)是 Kubernetes 提供的标准水平扩缩容组件。它可以基于 CPU、内存等资源指标自动调整 Deployment 的副本数。
对于 Flink 作业来说,基于 HPA 的扩缩容方案通常是直接调整 TaskManager Deployment 的副本数,然后结合 Flink 的响应式模式来自动调整作业的并行度。
- KEDA(Kubernetes Event-driven Autoscaling)
KEDA 是一个轻量级的开源 Kubernetes 事件驱动自动缩放器,用于根据外部事件或触发器水平扩展 Pod。它的核心价值在于将扩缩容的触发条件从"资源利用率"扩展到"任意业务事件",与 HPA 是互补关系而非替代关系。
比如对于 Flink 作业来说,基于 Kafka Consumer Lag 或Prometheus 自定义指标触发扩缩容:当 Lag 超过阈值时自动增加 TaskManager 副本数以实现扩容。
- Flink Kubernetes Operator 自动扩缩容
Flink Kubernetes Operator 是官方推荐的在 Kubernetes 上部署和管理 Flink 作业的方式,从 Flink 1.18 开始,Flink Operator 可以与外部化声明式资源管理完美配合,实现真正的无感知扩缩容。
Operator定期从运行中的Flink作业收集算子级指标(如每个Source的背压时间、输入/输出速率、任务处理速率、繁忙时间等),基于这些指标和用户配置的目标利用率区间,计算每个算子的合适并行度,以消除背压并维持预定利用率。然后做出扩缩容决策,通过 Flink 的 REST API 将决策下发给 Flink 集群,由 Flink 负责执行扩缩容操作。
三、总结展望
Flink 的扩缩容技术已经从最初的手动重启发展到了当前的顶点级无感知自动扩缩容,为实时计算作业的弹性伸缩提供了强大的支持。对于大多数生产环境来说,Flink 1.18 + 外部化声明式资源管理 + Flink Kubernetes Operator 自动扩缩容是目前最推荐的组合。它提供了最高的自动化程度、最精细的扩缩容粒度和最小的业务影响。
在选择扩缩容方案时,没有绝对的 "最好" 方案,只有 "最适合" 的方案。我们需要根据自己的业务特点、技术栈、团队能力和成本预算来选择最合适的方案。