PySpark
PySpark 是 Apache Spark 的 Python API 接口,通过Py4J库实现 Python 与 JVM (Java虚拟机)的交互,允许开发者用Python编写Spark应用程序。
其核心优势在于将 Spark 的分布式计算能力与 Python 的易用性结合,支持大规模数据处理、机器学习和实时分析。
最近我花了一天时间,从零搭建 PySpark 环境,跑通了一条数据治理管道。
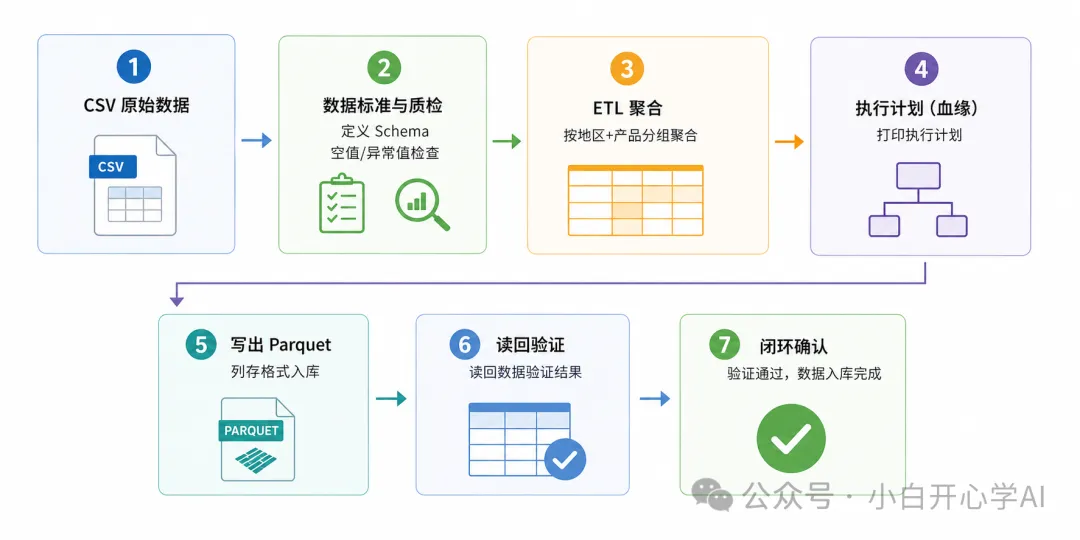
输入:一张模拟销售 CSV,有订单号、地区、产品、金额、日期。
输出:按地区+产品汇总后的 Parquet 文件,包含总销售额、均价、订单数等信息,外加质检报告和血缘执行计划。
这条流水线不是能跑就行,而是从源头保证数据结构确定、中间有质量卡点、落盘格式为下游 AI 训练或分析优化、事后可追溯来源。
下面是我踩到的 7 个坑。

Bug A:pip 安装找不到包 / 下载龟速
- 现象
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
ERROR: No matching distribution found for pyspark
切回官方源,455MB 源码包下载速度仅几十 KB/s,几乎卡死。
- 根本原因
PySpark 4.1.1 刚发布,清华镜像同步延迟,尚未收录该版本。
官方源从境外拉取,带宽受限。
- 修复策略与方法
策略:换源。
方法:切换至阿里云镜像
pip install pyspark -i https://mirrors.aliyun.com/pypi/simple/。
实测 7.1 MB/s,455MB 秒级完成。
- 意义
建立了可靠的依赖供应链。
国内开发环境优先选择同步速度快的镜像源,避免环境搭建成为瓶颈。

Bug B:Java 运行时缺失
- 现象
from pyspark.sql import SparkSession
PySparkRuntimeError: Java gateway process exited
pip install pyspark 成功,但 SparkSession 创建失败。
- 根本原因
架构的未声明依赖。
PySpark 是 Python 客户端,底层 Spark Core、Catalyst 优化器、Task 调度全部在 JVM 中运行。
pip install pyspark 只装了 Python 侧的胶水代码,JVM 运行时需自行安装。
- 修复策略与方法
策略:补齐运行时依赖。
方法:
安装 Eclipse Temurin JDK 17(开源,Windows .msi 安装包)
设置 JAVA_HOME,并将 %JAVA_HOME%\bin 加入 PATH
- 意义
揭示了 PySpark 的架构本质。
它是 Python ↔ JVM 的双进程系统,而非纯 Python 库。
理解这一点是排查后续所有底层错误的起点。

Bug C:Hadoop 辅助工具缺失(winutils.exe)
- 现象
读取 CSV 和分组聚合均正常,但写出 Parquet 时崩溃:
HADOOP_HOME and hadoop.home.dir are unset
数据已算完,却无法落地。
- 根本原因
Windows 平台缺少文件权限模拟层。
Spark 文件 I/O 底层走 Hadoop 的 FileSystem API,创建目录需要调用系统权限操作。
Linux 原生支持,Windows 必须借助 winutils.exe 模拟。
- 修复策略与方法
策略:补齐 Windows 适配层。
方法:
从 github.com/cdarlint/winutils
下载 hadoop-3.3.6/bin/winutils.exe
放入本地目录 D:\PySpark\hadoop\bin\,设置 HADOOP_HOME
- 意义
打通了数据从计算到落地的最后一公里。生产环境跑 Linux 不存在此问题,但本地开发必须补这一层。

Bug D:本地方法链接失败(hadoop.dll)
- 现象
winutils.exe 就绪后,写入仍然失败:
UnsatisfiedLinkError: NativeIO$Windows.access0
- 根本原因
DLL 依赖的物理分割。
winutils.exe 调用了 NativeIO$Windows 的 Native 方法,该方法实现在 hadoop.dll 中。
仅有可执行文件,缺少动态链接库。
- 修复策略与方法
策略:补齐运行时链接。
方法:从同一仓库目录下载 hadoop.dll,与 winutils.exe 放至同一 bin 目录。
- 意义
完成了 Windows 适配层的闭环。winutils.exe + hadoop.dll 是一对不可分割的运行时组件,缺一不可。

Bug E:Unicode 编码冲突
- 现象
质检通过的提示中打印了 emoji ✅:
UnicodeEncodeError: 'gbk' codec can't encode character '\u2705'
程序几乎全线跑完,在打印一条提示信息时因一个装饰符号崩溃。
- 根本原因
终端字符集的上下文冲突。
Windows 中文 PowerShell 默认编码为 GBK,只覆盖中文字符集,不包含 emoji。
Python 字符串默认 UTF-8,两者在输出管道中遭遇字符集边界。
- 修复策略与方法
策略:降级输出符号。
方法:将脚本中所有 ✅(\u2705)替换为纯 ASCII 文本 OK。
- 意义
建立了跨平台输出的健壮性。
日志输出不应依赖 Unicode 装饰符号,纯 ASCII 是环境兼容性的最大公约数。

Bug F:函数命名空间污染
- 现象
脚本最后统计 Parquet 文件大小时:
PySparkTypeError: NOT_COLUMN_OR_STR Argument `col` should be a Column or str, got generator.
此前所有步骤正常,仅最后一步崩溃。
- 根本原因
全局命名空间覆盖。
脚本开头导入了 from pyspark.sql.functions import sum,将 Python 内置函数 sum() 覆盖为 PySpark 的列聚合函数。结尾 sum(generator) 被 PySpark 的 sum 接管,企图将生成器当列名解析。
- 修复策略与方法
策略:显式区分框架语义与语言语义。
方法:将 sum(generator) 改为显式循环 for r, _, files in os.walk(...) 累加。
- 意义
揭示了 from xxx import * 的风险。
框架函数与内置函数发生命名冲突时,不在编译时报错,只在运行时以匪夷所思的方式暴露------排查成本极高。

Bug G:干净数据掩盖了质检盲区
- 现象
质检报告全部通过:
OK 数据质检通过,无异常
空值 0 个、异常金额 0 个、重复订单号 0 个。一切完美。但我心里不踏实:是真没问题,还是测试数据太干净了?
- 根本原因
测试数据的幸存者偏差。
我用 Python 手写的 10 行 CSV 是人工构造的"理想数据"------没有缺失值、没有异常金额、没有重复单号。
质检逻辑在这个数据集上永远通过,不等于它在真实脏数据面前站得住。
- 修复策略与方法
策略:注入脏数据做对抗测试。
方法:
在 CSV 中手动加入一条 amount=-500 的异常行,一条重复 order_id 的脏行,一条 region 为空的行
重新跑质检,确认每条规则都能正确捕获异常
阈值不能写死:将 amount > 100000 配置化,方便业务方根据实际金额分布调整
- 意义
质检逻辑的正确性 ≠ 质检覆盖面的充分性。
干净数据只能验证不误杀,脏数据才能验证不漏放。
生产环境的数据质检规则,必须用真实脏数据样本反复校准,否则上线第一天就会被刷到怀疑人生。