一、算法原理
Sort-Merge Join 是一种用于连接两个数据集的算法,主要分为两个阶段:
-
排序阶段:根据连接键对两个数据集进行排序
-
合并阶段:使用类似归并排序的合并过程找到匹配的记录
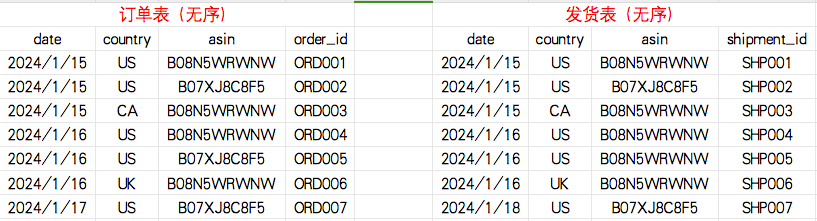
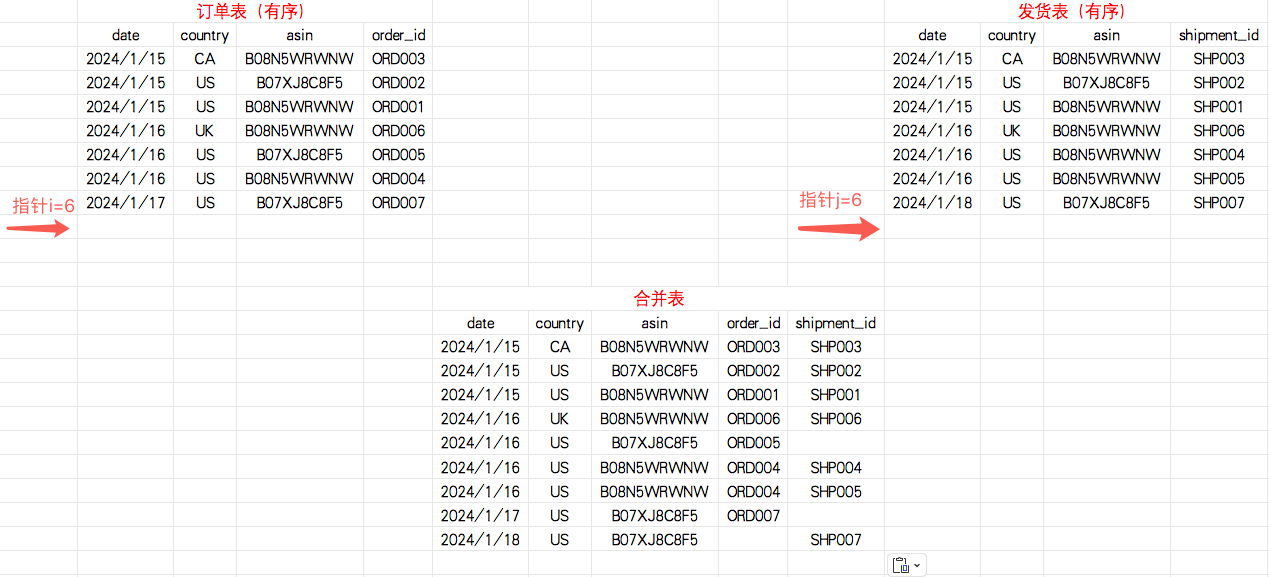
1.1 准备数据(以订单表和发货表为例)
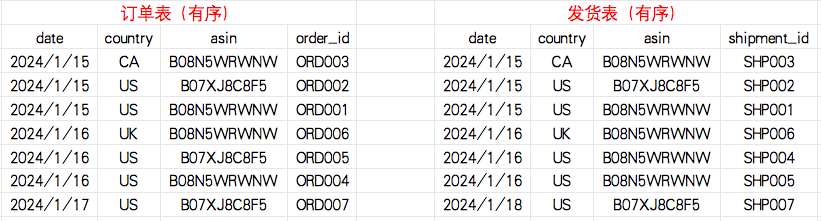
1.2 排序
根据date+country+asin进行排序
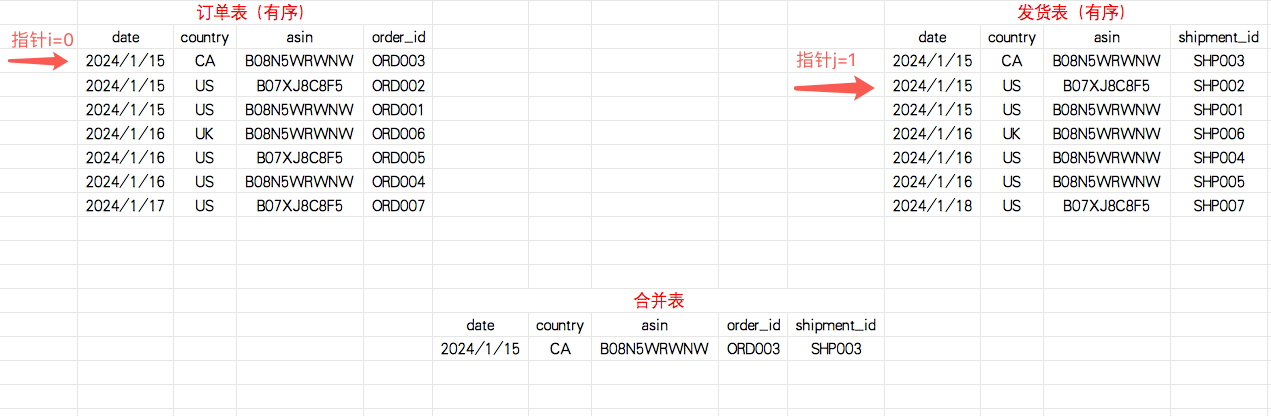
1.3 合并
- 如果订单表指针i指向的数据的date、country、asin字段与发货表指针j指向的数据的date、country、asin字段一致,将两条数据合并,输出到合并表,指针j++(指向下一条数据)
- 如果订单表指针i指向的数据的date、country、asin字段的键值 > 发货表指针j指向的数据的date、country、asin字段的键值,指针j++
- 如果订单表指针i指向的数据的date、country、asin字段的键值 < 发货表指针j指向的数据的date、country、asin字段的键值,指针i++
- 循环上面的步骤,直至i ≥ 订单表行数、j ≥ 发货表最大行数
第一步:定义两个指针i、j,分别指向订单表和发货表的首行数据

指针i和指针j指向数据的date、country、asin字段键值一致,合并输出,指针j++(指向下一条数据)
第二步:指针j++(指向下一条数据)
指针i指向数据的date、country、asin字段键值 < 指针j指向数据的date、country、asin字段键值,合并输出,指针i++(指向下一条数据)
第三步:指针i++(指向下一条数据)
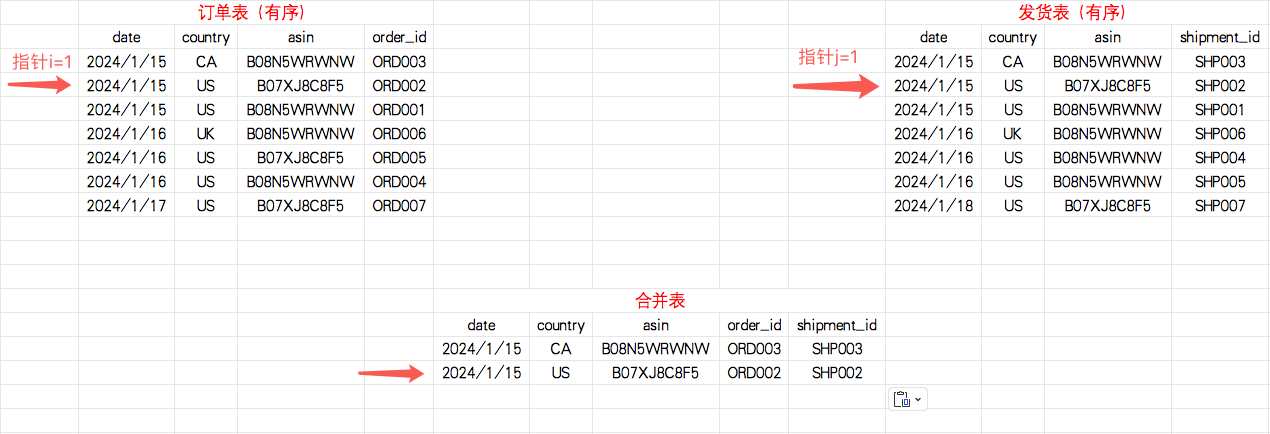
指针i和指针j指向数据的date、country、asin字段键值一致,合并输出,指针j++(指向下一条数据)
第四步:重复上述步骤,直至i ≥ 订单表数据量、j ≥ 发货表数据量,数据合并完毕(以全连接为例)
二、python代码实现(以全连接为例)
python
from typing import List, Dict
def sort_merge_full_join(R: List[Dict], S: List[Dict], join_keys: List[str]) -> List[Dict]:
"""
以全连接为例,实现Sort-Merge Join算法
:param R: 表1数据(订单表)
:param S: 表2数据(发货表)
:param join_keys: 连接字段
:return: 输出全连接之后的数据
"""
"""排序阶段,按join_keys进行排序"""
r_sorted = sorted(R, key=lambda x: tuple(x[key] for key in join_keys))
s_sorted = sorted(S, key=lambda x: tuple(x[key] for key in join_keys))
"""定义指针i,j"""
i = j = 0
"""定义指针j的偏移量j_,用于处理S表有连续多条数据键值一样的情况"""
j_ = 0
"""获取表最大行数"""
r_lens = len(r_sorted)
s_lens = len(s_sorted)
"""标记已匹配的记录"""
r_matched = [False] * r_lens
s_matched = [False] * s_lens
"""声明结果变量"""
results = []
"""合并阶段"""
while i < r_lens and j < s_lens:
# 获取指针指向的数据
r_one = r_sorted[i]
s_one = s_sorted[j + j_]
# 获取键值
r_one_key = tuple(r_one[key] for key in join_keys)
s_one_key = tuple(s_one[key] for key in join_keys)
# 如果r_one键值更大
if r_one_key > s_one_key:
if not s_matched[j]:
s_matched[j] = True
results.append({**{k: None for k in r_one.keys()}, **s_one})
j += 1
# 如果s_one键值更大
elif r_one_key < s_one_key:
if not r_matched[i]:
r_matched[i] = True
results.append({**r_one, **{k: None for k in s_one.keys() if k not in join_keys}})
i += 1
# 如果键值一样大
else:
r_matched[i] = True
s_matched[j + j_] = True
results.append({**r_one, **s_one})
if (j + j_ + 1) >= s_lens:
j_ = 0
i += 1
continue
s_next_one = s_sorted[j + j_ + 1]
s_next_one_key = tuple(s_next_one[key] for key in join_keys)
if s_one_key == s_next_one_key:
j_ += 1
else:
j_ = 0
i += 1
"""处理剩余的R表记录"""
while i < r_lens:
if not r_matched[i]:
results.append({**r_sorted[i], **{k: None for k in s_one.keys()}, **{k: r_sorted[j][k] for k in join_keys}})
r_matched[i] = True
i += 1
"""处理剩余的S表记录"""
while j < s_lens:
if not s_matched[j]:
results.append({**{k: None for k in r_one.keys()}, **s_sorted[j]})
s_matched[j] = True
j += 1
return results三、复杂度分析
| 指标 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 排序阶段 | O(N log N + M log M) | O(N + M) |
| 合并阶段 | O(N + M) | O(1) 额外 |
| 总计 | O(N log N + M log M) | O(N + M) |
四、使用场景
✅ 适合的场景:
-
大表连接:数据量较大且已按连接键排序
-
等值连接:JOIN 条件为等值比较
-
多个连接:需要多次使用相同排序结果的场景
-
数据倾斜不严重:连接键分布相对均匀
❌ 不适合的场景:
-
小表连接:嵌套循环连接可能更高效
-
非等值连接:如 >, <, LIKE 等
-
严重数据倾斜:某个键值出现频率极高
-
实时查询:排序开销太大
五、不要重复造轮子(Pandas实现)
python
import pandas as pd
"""准备数据"""
df_orders = pd.DataFrame([
{'date': '2024/1/15', 'country': 'US', 'asin': 'B08N5WRWNW', 'order_id': 'ORD001'},
{'date': '2024/1/15', 'country': 'US', 'asin': 'B07XJ8C8F5', 'order_id': 'ORD002'},
{'date': '2024/1/15', 'country': 'CA', 'asin': 'B08N5WRWNW', 'order_id': 'ORD003'},
{'date': '2024/1/16', 'country': 'US', 'asin': 'B08N5WRWNW', 'order_id': 'ORD004'},
{'date': '2024/1/16', 'country': 'US', 'asin': 'B07XJ8C8F5', 'order_id': 'ORD005'},
{'date': '2024/1/16', 'country': 'UK', 'asin': 'B08N5WRWNW', 'order_id': 'ORD006'},
{'date': '2024/1/17', 'country': 'US', 'asin': 'B07XJ8C8F5', 'order_id': 'ORD007'}
])
df_shipments = pd.DataFrame([
{'date': '2024/1/15', 'country': 'US', 'asin': 'B08N5WRWNW', 'shipment_id': 'SHP001'},
{'date': '2024/1/15', 'country': 'US', 'asin': 'B07XJ8C8F5', 'shipment_id': 'SHP002'},
{'date': '2024/1/15', 'country': 'CA', 'asin': 'B08N5WRWNW', 'shipment_id': 'SHP003'},
{'date': '2024/1/16', 'country': 'US', 'asin': 'B08N5WRWNW', 'shipment_id': 'SHP004'},
{'date': '2024/1/16', 'country': 'US', 'asin': 'B08N5WRWNW', 'shipment_id': 'SHP005'},
{'date': '2024/1/16', 'country': 'UK', 'asin': 'B08N5WRWNW', 'shipment_id': 'SHP006'},
{'date': '2024/1/18', 'country': 'US', 'asin': 'B07XJ8C8F5', 'shipment_id': 'SHP007'}
])
"""合并"""
result = pd.merge(
df_orders,
df_shipments,
on=['date', 'country', 'asin'], # 按这三个字段连接
how='outer', # 全连接
sort=True
)
# 如果传入的数据是已排序的
# result = pd.merge(df_orders, df_shipments, on=['date', 'country', 'asin'], how='outer', sort=False)
print(result)运行结果:
python
date country asin order_id shipment_id
0 2024/1/15 CA B08N5WRWNW ORD003 SHP003
1 2024/1/15 US B07XJ8C8F5 ORD002 SHP002
2 2024/1/15 US B08N5WRWNW ORD001 SHP001
3 2024/1/16 UK B08N5WRWNW ORD006 SHP006
4 2024/1/16 US B07XJ8C8F5 ORD005 NaN
5 2024/1/16 US B08N5WRWNW ORD004 SHP004
6 2024/1/16 US B08N5WRWNW ORD004 SHP005
7 2024/1/17 US B07XJ8C8F5 ORD007 NaN
8 2024/1/18 US B07XJ8C8F5 NaN SHP007六、 总结
Sort-Merge Join 是一种稳定可靠的连接算法,特别适合:
-
大数据集连接
-
需要对结果排序的场景
-
连接键有索引或已预排序