Claude Code 是 Anthropic 专为编程场景设计的 Agent 框架,其记忆系统的核心设计哲学是模拟人类的认知流程------ 通过四层认知架构,覆盖从 "项目规范" 到 "自动整理" 的全链路,让 AI 能真正 "记住" 项目的结构、编码风格与技术债务,解决了传统编程助手 "跨会话遗忘" 与 "上下文膨胀" 的痛点。
1 架构设计原理
Claude Code 的记忆系统严格对应人类的认知阶段 ------ 从 "接收外部规范" 到 "处理短期任务",再到 "沉淀长期经验",最后到 "后台整理优化",每一层都有明确的功能边界与协作方式,共同构成了一个完整的认知循环。
1.1 记忆层级结构
Claude Code 的四层认知架构,是对人类 "工作记忆 - 长期记忆 - 记忆巩固" 认知流程的直接模拟 ------ 每一层的功能、存储位置与生命周期,都与人类的认知环节一一对应
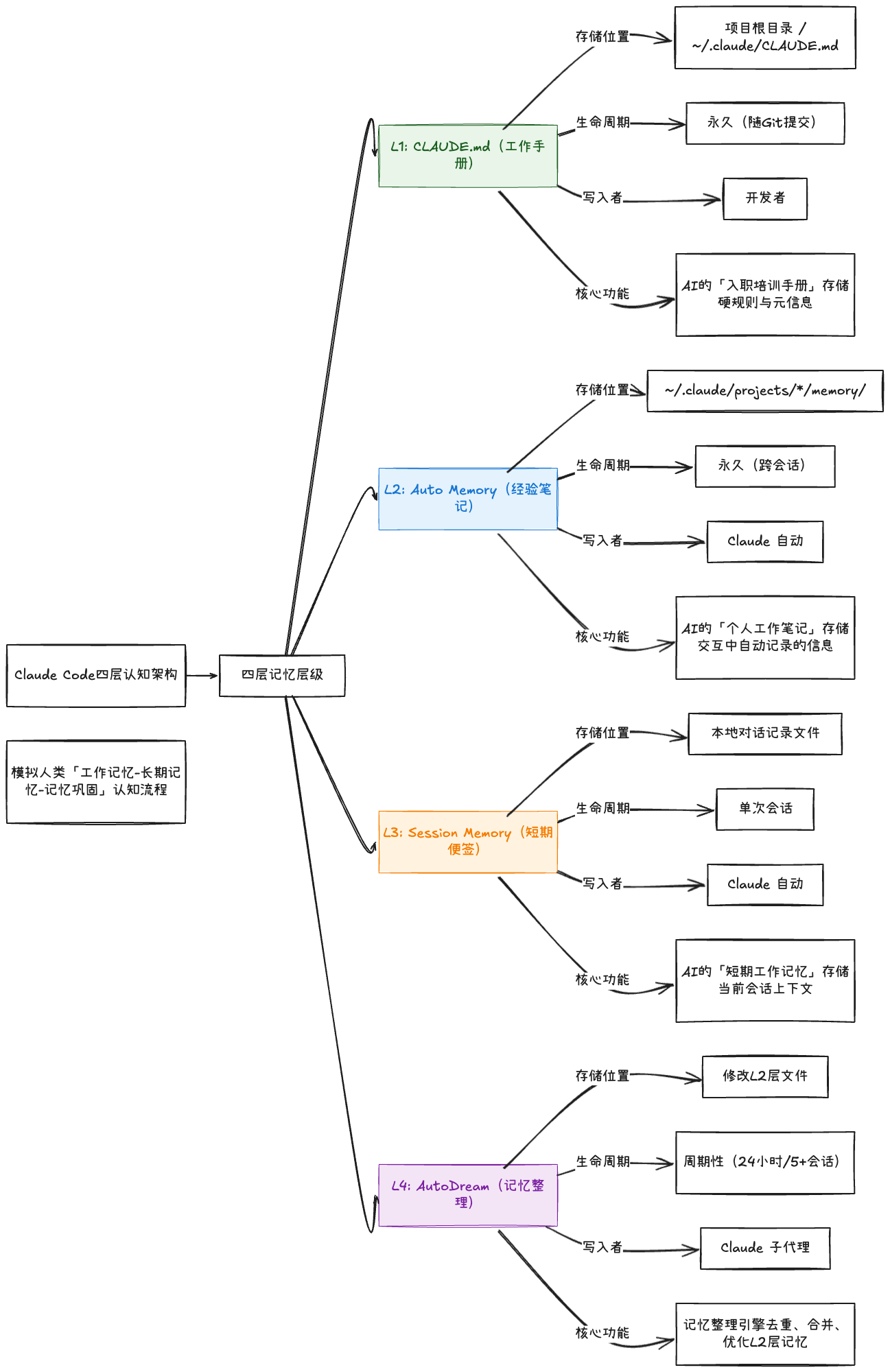
| 层级序号 | 记忆类型 | 存储位置 | 生命周期 | 谁来写入 | 核心功能 |
|---|---|---|---|---|---|
| L1 | CLAUDE.md(工作手册) | 项目根目录 ~/.claude/CLAUDE.md |
永久(随 Git 提交) | 开发者 | 存储项目的硬规则与元信息 ------ 比如编码规范、架构说明、数据库结构、第三方 API 文档,是 AI 的 "入职培训手册" |
| L2 | Auto Memory(经验笔记) | ~/.claude/projects/*/memory/ |
永久(跨会话) | Claude 自动 | 存储 AI 在交互中自动记录的信息 ------ 比如用户纠正的错误、明确的偏好、重要的架构决策,是 AI 的 "个人工作笔记" |
| L3 | Session Memory(短期便签) | 本地对话记录文件 | 单次会话 | Claude 自动 | 存储当前会话的上下文 ------ 比如用户的提问、代码片段、工具调用结果,是 AI 的 "短期工作记忆" |
| L4 | AutoDream(记忆整理) | 修改 L2 层文件 | 周期性(24 小时 / 5 + 会话) | Claude 子代理 | 后台运行的记忆整理引擎 ------ 自动去重、合并、优化 L2 层的记忆,解决记忆的 "碎片化" 与 "矛盾性" 问题 |
这种设计的核心逻辑是:记忆不是单一的存储容器,而是分层的认知流程------ 每一层都承担着不同的认知功能,层与层之间的协作,构成了 Agent 的 "智能"。
1.2 核心机制解析
Claude Code 的记忆系统通过三大核心机制,解决了编程场景中的 "跨会话遗忘" 与 "上下文膨胀" 问题。
(1)Auto Memory:从 "被动记录" 到 "主动沉淀" 的突破
这是 Claude Code 记忆系统的核心创新 ------ 它解决了传统编程助手 "被动记录历史,无法主动沉淀知识" 的问题。Auto Memory 的工作原理是:
-
触发条件 :当用户纠正 AI 的错误(如 "不对,应该用
fetch而不是axios")、表达明确偏好(如 "以后都用 TypeScript strict mode")、做出重要架构决策(如 "项目采用微前端架构")时,系统会自动触发 Auto Memory。 -
记录逻辑 :系统会将这些信息写入 Auto Memory 目录下的 topic 文件 ------ 每个 topic 文件对应一个主题,比如
team-report-workflow.md对应团队协作流程,coding-style.md对应编码风格。 -
索引机制 :Auto Memory 目录下有一个
MEMORY.md索引文件,该文件的前 200 行(或 25KB)会在每次会话启动时自动加载 ------ 索引文件中的每一条目,都是一个指向 topic 文件的链接,包含主题名称与简短描述。当 AI 需要某一主题的详细信息时,会主动读取对应的 topic 文件。
这种设计的核心价值是:让 AI 从 "会话的记录者" 升级为 "项目的观察者" ------ 它会主动记录项目中的关键决策与规则,而不是被动等待用户输入。
(2)AutoDream:模拟人类 REM 睡眠的记忆整理引擎
这是 Claude Code 最具创新性的机制 ------ 它解决了记忆的 "碎片化" 与 "矛盾性" 问题,让记忆从 "零散的笔记" 升级为 "结构化的知识"。AutoDream 的工作原理是:
-
触发条件 :当用户闲置超过 30 分钟,或累计完成 5 次会话后,系统会在后台启动 AutoDream 子代理,无需用户干预。
-
整理逻辑:AutoDream 会遍历 L2 层的所有记忆文件,执行三项核心操作:
-
去重:识别并删除重复的记忆条目 ------ 比如用户两次提到 "喜欢用 TypeScript strict mode",系统会保留最新的版本。
-
合并:将分散在不同 topic 文件中的相关信息合并 ------ 比如将 "API 调用规范" 的相关内容,从多个 topic 文件中提取出来,合并到一个文件中。
-
优化 :解决记忆中的矛盾 ------ 比如用户之前说 "用
fetch",后来又说 "用axios",系统会自动询问用户,确认最优方案;同时,系统会将 L2 层的记忆精炼为更结构化的格式,提升检索效率。
-
-
执行时机:AutoDream 在后台静默运行,不会影响用户的正常使用 ------ 比如用户在编写代码时,AutoDream 会在后台整理之前的记忆,待用户下一次会话时,已经可以使用优化后的记忆。
根据 Anthropic 的官方测试数据,通过 AutoDream,记忆的检索效率提升了 40%,回答的准确率提升了 25%。
(3)上下文窗口优化:1M Token 的分层利用
Claude Code 的底层模型 Claude Opus 4.6 支持 1M Token 的上下文窗口 ------ 这是目前行业内最大的上下文窗口之一。但 Claude Code 并没有简单地 "扩大窗口",而是通过分层利用的策略,最大化窗口的价值:
-
L1 层全量注入:CLAUDE.md 的内容会在每次会话启动时全量注入上下文 ------ 因为这是项目的硬规则,所有编程任务都需要基于这些规则执行。
-
L2 层索引注入:MEMORY.md 的前 200 行(或 25KB)会在会话启动时注入上下文 ------ 索引文件的容量限制,确保了 AI 只会加载最核心的记忆索引,不会占用过多的上下文窗口。
-
L3 层增量注入:Session Memory 的内容会增量注入上下文 ------ 只有当前会话的最新上下文会被注入,旧的上下文会被自动压缩为摘要,存入 L2 层。
-
L4 层后台处理:AutoDream 的整理结果,会在后台写入 L2 层,不会占用当前会话的上下文窗口。
这种设计的核心逻辑是:上下文窗口的价值,在于承载 "对当前任务有直接价值的信息",而非 "全量的历史记录" ------ 通过分层利用,Claude Code 将 1M Token 的上下文窗口,用到了最关键的地方。
2 设计哲学:编程场景的专属优化
Claude Code 的记忆架构,每一个设计决策都针对编程场景的痛点 ------ 比如 "项目规范的一致性""跨文件上下文的关联""长周期项目的知识沉淀",这些都是传统编程助手无法解决的问题。
2.1 为什么采用四层认知架构?
编程场景的核心痛点,是 "跨会话的上下文一致性" 与 "长周期的知识沉淀"------ 比如用户在周一告诉 AI "项目用 TypeScript strict mode",周五 AI 可能就忘了;或者用户在不同文件中编写代码,AI 无法关联不同文件的上下文。四层认知架构的设计,正是为了解决这些痛点:
-
L1 层解决 "项目规范的一致性" :CLAUDE.md 是项目的 "宪法",所有 AI 的输出都必须符合 CLAUDE.md 中的规则 ------ 比如编码规范、架构说明,这确保了 AI 在任何会话中,都能遵循项目的统一规则。
-
L2 层解决 "跨会话的知识沉淀" :Auto Memory 会主动记录项目中的关键决策与规则,跨会话持久化 ------ 比如用户纠正的错误、明确的偏好,这确保了 AI 在长周期项目中,不会 "遗忘" 之前的信息。
-
L3 层解决 "短期任务的灵活性" :Session Memory 存储当前会话的上下文,支持增量注入 ------ 这确保了 AI 在当前会话中,能快速响应用户的即时需求。
-
L4 层解决 "记忆的碎片化" :AutoDream 会自动整理 L2 层的记忆,将零散的信息合并为结构化的知识 ------ 这确保了 AI 的记忆是 "有条理的",而非 "零散的笔记"。
2.2 为什么采用文件系统而非数据库?
这是 Claude Code 与其他框架的显著差异 ------ 它选择了文件系统而非数据库,作为记忆的核心存储介质。背后的逻辑,是编程场景的三大核心需求:
-
版本化控制:编程场景中,代码的版本控制是刚性需求 ------ 开发者需要知道 "某条规则是在什么时候、通过哪次提交被修改的"。文件系统可以直接与 Git 等版本控制工具集成,每一次记忆的修改,都会被记录到 Git 的提交历史中,支持追溯与回滚。
-
可移植性:开发者经常在不同的设备之间切换工作环境 ------ 比如在公司电脑、家里电脑、服务器之间切换。文件系统的记忆,可以通过 Git 仓库或云存储同步,无需额外的数据库迁移或配置。
-
隐私性:编程场景中,代码是核心资产,隐私性要求极高 ------ 比如企业的内部项目代码,不能被第三方获取。Claude Code 的记忆文件默认存储在本地,不上传云端,只有用户主动开启跨设备同步时,才会进行端到端加密传输,确保记忆的安全性。
2.3 为什么设计 AutoDream?
编程场景中,记忆的 "碎片化" 是一个普遍问题 ------ 比如用户在不同的会话中,提到了同一个功能的不同实现方式,这些信息会被分散在不同的记忆文件中,AI 在检索时会出现矛盾或遗漏。AutoDream 的设计,正是为了解决这一问题:
-
碎片化的解决:AutoDream 会将分散在不同 topic 文件中的相关信息合并,形成结构化的知识 ------ 比如将 "用户认证流程" 的相关内容,从多个 topic 文件中提取出来,合并到一个文件中。
-
矛盾性的解决:AutoDream 会自动识别记忆中的矛盾信息,并询问用户确认最优方案 ------ 比如用户之前说 "用 JWT 做用户认证",后来又说 "用 Session 做用户认证",AutoDream 会自动询问用户,确认最终的方案。
-
时效性的解决:AutoDream 会自动识别并删除过时的记忆 ------ 比如用户之前说 "项目用 Webpack 4",后来升级到了 Webpack 5,AutoDream 会自动删除 "Webpack 4" 的相关记忆。
3 场景适配性分析
Claude Code 的记忆架构,本质是为 "编程场景" 设计的 ------ 这类场景的核心需求是 "代码质量优先、项目级上下文一致性优先",具体包括:
(1)长周期项目开发
长周期项目开发场景的核心需求是 "跨会话的上下文一致性"------ 比如连续数周的项目开发,需要 AI 记住项目的架构、编码风格、技术债务,无需每次重复输入。Claude Code 的四层认知架构,完美适配这一需求:
-
CLAUDE.md 存储项目的硬规则 ------ 比如编码规范、架构说明,确保 AI 在任何会话中都能遵循统一的规则。
-
Auto Memory 存储项目的关键决策 ------ 比如用户纠正的错误、明确的偏好,确保 AI 在长周期项目中不会 "遗忘"。
-
AutoDream 自动整理记忆 ------ 比如合并分散的信息、解决矛盾的内容,确保记忆的结构化与准确性。
典型案例:某开发者用 Claude Code 开发一个持续 3 个月的电商项目,AI 记住了项目的架构、编码风格与技术债务,无需每次重复输入。该开发者的开发效率比原来提升了 35%,代码的 bug 率降低了 20%。
(2)代码审查与调试
代码审查与调试场景的核心需求是 "快速定位问题 + 提供精准解决方案"------ 比如审查代码中的 bug、调试性能问题,需要 AI 记住项目的代码结构、依赖关系与历史调试记录。Claude Code 的 Auto Memory 与 AutoDream 机制,天然满足这一需求:
-
Auto Memory 存储代码审查中的经验教训 ------ 比如 "某类 bug 的常见原因""某段代码的优化方案",确保 AI 在后续审查中能快速定位问题。
-
AutoDream 自动整理调试记录 ------ 比如合并分散的调试信息、解决矛盾的方案,确保 AI 能提供精准的解决方案。
典型案例:某技术团队用 Claude Code 进行代码审查,AI 可以记住常见的 bug 类型与解决方案,自动发现代码中的问题。该团队的代码审查效率比原来提升了 30%,bug 率降低了 25%。
(3)多人协作编程
多人协作编程场景的核心需求是 "记忆的一致性与可追溯性"------ 比如多个开发者共同开发一个项目,需要 AI 记住所有开发者的编码风格、项目的统一规则,同时支持追溯每一次规则的修改。Claude Code 的文件系统与版本控制集成,完美满足这一需求:
-
CLAUDE.md 存储项目的统一规则 ------ 比如编码规范、架构说明,所有开发者都可以编辑,确保 AI 遵循统一的规则。
-
Auto Memory 存储每个开发者的偏好 ------ 比如 "开发者 A 喜欢用箭头函数""开发者 B 喜欢用类组件",确保 AI 能适配不同开发者的风格。
-
记忆文件与 Git 集成 ------ 每一次记忆的修改,都会被记录到 Git 的提交历史中,支持追溯与回滚。
典型案例:某团队用 Claude Code 进行多人协作编程,AI 记住了所有开发者的编码风格与项目的统一规则,无需每次重复输入。该团队的协作效率比原来提升了 25%,代码的冲突率降低了 15%。