接口铺垫
triton.language.multiple_of
python
@builtin
def multiple_of(input, values, _semantic=None):
"""
Let the compiler know that the values in :code:`input` are all multiples of :code:`value`.
"""
if isinstance(values, constexpr):
values = [values]
for i, d in enumerate(values):
if not isinstance(d, constexpr):
raise TypeError(f"values element {i} must have type `constexpr`")
if not isinstance(d.value, int):
raise TypeError(f"values element {i} must have type `constexpr[int]`, got `constexpr[{type(d.value)}]")
values = [x.value for x in values]
return _semantic.multiple_of(input, values)| 条目 | 名称 | 作用 / 含义 | 类型约束 |
|---|---|---|---|
| 输入参数 | input |
需要标记对齐属性的张量或指针。通常是计算出的内存地址偏移量。 | Tensor 或 Pointer |
| 输入参数 | values |
声明 input 能够被哪些数值整除。告诉编译器:"这里的数都是 X 的倍数"。 |
tl.constexpr 或其列表 |
| 输入参数 | _semantic |
Triton 内部语义解析对象(开发者通常无需手动干预)。 | 内部对象 |
| 返回值 | output |
返回与 input 数值完全相同的张量。区别在于该返回对象在编译器内部携带了对齐元数据。 |
与 input 类型相同 |
multiple_of 本质上是一个编译器提示(Compiler Hint) ,它在逻辑层面上是一个"恒等函数"(即 f ( x ) = x f(x) = x f(x)=x),但在物理建模层面它改变了编译器对数据的认知。
该函数并不会在运行时对数据执行取模运算或检查,它只是在编译阶段给 input 贴上了一个"标签"。编译器看到这个标签后,会意识到:"既然这些索引都是 16 的倍数,那我可以用最快的 128-bit 矢量指令来搬运数据,而不用担心跨行或非对齐访问的问题。"
在 GPU 体系结构中,内存合并(Memory Coalescing)是性能的生命线。
-
没有提示:编译器可能采取保守策略,生成多个标量加载指令,导致带宽利用率低下。
-
使用提示:编译器敢于生成宽矢量指令(如一次性读取 16 字节),大幅减少指令数量并提升吞吐量。
python
# 假设我们处理的是 float32 数据(4字节)
# 如果 BLOCK_SIZE 是 32,那么 offset 应该是 32 * 4 = 128 字节的倍数
# 这符合大多数 GPU 的内存对齐要求
offset = tl.program_id(0) * BLOCK_SIZE
aligned_offset = tl.multiple_of(offset, BLOCK_SIZE)
# 使用带标签的 aligned_offset 进行访存,编译器会生成优化后的加载指令
ptr = base_ptr + aligned_offset
data = tl.load(ptr)风险提示 :如果你对编译器"撒谎"(例如
input实际上不是values的倍数),编译器依然会按照对齐的方式生成指令,这通常会导致非法内存访问(Illegal Memory Access) 或得到错误的数据结果。
triton.language.advance
triton.language.advance 是专门用于 Block Pointer(块指针) 操作的函数。它允许你在多维空间中移动一个预先定义好的块指针。
python
@must_use_result(
"Note that tl.advance does not have any side effects. To move the block pointer, you need to assign the result of tl.advance to a variable."
)
@_tensor_member_fn
@builtin
def advance(base, offsets, _semantic=None):
"""
Advance a block pointer
:param base: the block pointer to advance
:param offsets: the offsets to advance, a tuple by dimension
"""
return _semantic.advance(base, offsets)| 条目 | 名称 | 作用 / 含义 | 类型约束 |
|---|---|---|---|
| 输入参数 | base |
现有的块指针(Block Pointer)。它是移动操作的起点。 | block_ptr |
| 输入参数 | offsets |
在每个维度上需要移动的偏移量。例如 (16, 32) 表示在第 0 维移动 16 个元素,第 1 维移动 32 个元素。 |
tuple of int 或 tl.constexpr |
| 输入参数 | _semantic |
Triton 内部语义解析对象。 | 内部对象 |
| 返回值 | new_ptr |
返回一个新的块指针 ,指向移动后的目标位置。原指针 base 不会发生改变。 |
block_ptr |
函数功能详解
advance 的核心功能是平移(Offset)一个块指针,类似于在多维数组上滑动一个窗口。
1. 纯函数属性(无副作用)
正如源码中 @must_use_result 警告所言,tl.advance 不会修改原指针 。在底层,块指针是一个包含基地址、形状、步长和当前位置的结构体。执行 advance 只是计算出一个位置更新后的新结构体。
错误写法 :
tl.advance(ptr, (16, 16))(指针没动)正确写法 :
ptr = tl.advance(ptr, (16, 16))
2. 与传统指针算术的区别
在 Triton 中,如果你使用常规指针(Scalar Pointer),你会手动加减偏移量;但当你使用 tl.make_block_ptr 创建了高级块指针后,必须使用 tl.advance 来切换到下一个数据块。
3. 典型应用场景:循环迭代
在矩阵乘法(GEMM)等算法中,我们需要沿着某个维度(如 K K K 维度)不断移动读取数据块。advance 是实现这种"滑动窗口"读取的标准方式。
4. 代码示例
python
# 创建一个指向矩阵 A 起始位置的块指针
a_ptr = tl.make_block_ptr(
base=A,
shape=(M, K),
strides=(stride_am, stride_ak),
offsets=(0, 0),
block_shape=(BLOCK_SIZE_M, BLOCK_SIZE_K),
order=(1, 0)
)
# 在循环中沿着 K 维度移动指针
for k in range(0, K, BLOCK_SIZE_K):
# 加载当前块的数据
a_block = tl.load(a_ptr)
# 将指针向 K 维度(第 1 维)移动 BLOCK_SIZE_K 个单位
# 注意:必须重新赋值给 a_ptr
a_ptr = tl.advance(a_ptr, (0, BLOCK_SIZE_K))总结
-
功能:移动块指针的位置。
-
关键点:必须接收返回值,否则移动无效。
-
优势:配合块指针使用,能够自动处理复杂的边界逻辑和步长计算,让代码更简洁且易于优化。
triton.language.make_block_ptr
python
@builtin
def make_block_ptr(base: tensor, shape, strides, offsets, block_shape, order, _semantic=None):
"""
Returns a pointer to a block in a parent tensor
:param base: The base pointer to the parent tensor
:param shape: The shape of the parent tensor
:param strides: The strides of the parent tensor
:param offsets: The offsets to the block
:param block_shape: The shape of the block
:param order: The order of the original data format
"""
warn("tl.make_block_ptr is deprecated. Use TensorDescriptor or tl.make_tensor_descriptor instead.")
return _semantic.make_block_ptr(base, shape, strides, offsets, block_shape, order) triton.language.make_block_ptr 是 Triton 中分块指针(Block Pointer)机制的核心。它将原本扁平的内存地址空间抽象为多维的"张量视图",使得在 Kernel 中处理多维数据块变得极其直观。
虽然源码中提示该函数已被标记为 deprecated(推荐使用 TensorDescriptor),但在目前的 Triton 生态中,它依然是理解和编写高性能 Kernel 的基石。
| 条目 | 名称 | 作用 / 含义 | 类型约束 |
|---|---|---|---|
| 输入参数 | base |
父张量的起始地址。通常是传入 Kernel 的全局内存指针。 | Pointer |
| 输入参数 | shape |
完整父张量的逻辑形状(如整个矩阵的行数和列数)。 | tuple of int |
| 输入参数 | strides |
指向张量各维度在内存中跨越的步长(通常用于处理非连续内存)。 | tuple of int |
| 输入参数 | offsets |
当前块在父张量中的起始坐标偏移量。 | tuple of int |
| 输入参数 | block_shape |
该指针所指向的数据块的大小(即每次 tl.load 读入的大小)。 |
tuple of int |
| 输入参数 | order |
数据的存储布局(维度优先级)。例如 (1, 0) 表示列优先。 |
tuple of int |
| 输入参数 | _semantic |
Triton 内部语义解析对象。 | 内部对象 |
| 返回值 | block_ptr |
返回一个封装好的块指针对象。它包含了访问该多维块所需的所有元数据。 | block_ptr |
make_block_ptr 的核心功能是创建一个高级指针,定义如何从物理内存中"切"出一个逻辑上的多维块。 |
1. 自动边界处理
传统的指针计算需要手动判断 if (offset < max_size)。而使用 make_block_ptr 后,搭配 tl.load(ptr, boundary_check=(...)),Triton 编译器会自动生成高效的边界检查逻辑,防止非法越界访问。
2. 硬件加速优化(TMA)
在 NVIDIA Hopper 架构(如 H100)上,块指针能直接映射到硬件级的 TMA (Tensor Memory Accelerator) 单元。这允许硬件自动异步地完成多维数据块的搬运,极大地降低了软件计算开销。
3. 布局(Order)的意义
order 参数决定了数据在内存中移动的"最快"维度。
-
(1, 0):行优先(Row-major),相邻地址在第 1 维移动。 -
(0, 1):列优先(Column-major),相邻地址在第 0 维移动。 正确配置order对实现合并访存(Coalesced Access)至关重要。
4. 典型用法示例
python
# 定义一个 2D 矩阵的块指针
a_block_ptr = tl.make_block_ptr(
base=a_ptr, # 矩阵首地址
shape=(M, K), # 矩阵总大小
strides=(stride_am, stride_ak), # 步长
offsets=(0, 0), # 从 (0,0) 开始读取
block_shape=(BLOCK_M, BLOCK_K), # 每次读取一个 BLOCK_M * BLOCK_K 的小块
order=(1, 0) # 内存中是行优先存储
)
# 直接加载整个块,无需手动计算 offset 向量
a_tile = tl.load(a_block_ptr, boundary_check=(0, 1))tl.load加载
在Triton笔记1核心概念-CSDN博客中,我们介绍load的时候没有介绍Block Pointer的情况,现在来看一下
python
"""
(3) If `pointer` is a block pointer defined by `make_block_ptr`, a
tensor is loaded. In this case:
- `mask` and `other` must be `None`, and
- `boundary_check` and `padding_option` can be specified to control the behavior of out-of-bound access.
:param boundary_check: tuple of integers, indicating the dimensions which should do the boundary check
:type boundary_check: tuple of ints, optional
:param padding_option: should be one of {"", "zero", "nan"}, the padding value to use while out of bounds. "" means an undefined value.
"""| 条目 | 名称 | 作用 / 含义 | 类型/取值约束 |
|---|---|---|---|
| 输入参数 | pointer |
加载数据的源地址。在此场景下必须是 block_ptr。 |
block_ptr |
| 输入参数 | mask |
逐元素的加载开关。 | 必须为 None (块指针自带范围信息) |
| 输入参数 | other |
掩码为假时的填充值。 | 必须为 None (由 padding_option 代替) |
| 输入参数 | boundary_check |
指明哪些维度需要进行越界检查。 | tuple of int (如 (0, 1)) |
| 输入参数 | padding_option |
越界时的填充策略。 | "", "zero", "nan" |
| 在这种模式下,你不再需要手动创建一个布尔矩阵(Mask)来告诉编译器哪些位置合法,而是直接告诉编译器:"请检查第 N 维的边界"。 |
boundary_check 接收一个元组,里面的数字代表 make_block_ptr 中定义的维度索引。
-
boundary_check=(0,):只检查行是否越界。如果块的某一部分超出了矩阵的总行数 M M M,则触发填充。 -
boundary_check=(0, 1):同时检查行和列。这在处理非对齐的矩阵末尾块时非常有用。
当 boundary_check 发现越界时,padding_option 参数决定补什么值:
-
"zero":越界部分填 0(最常用,尤其在矩阵乘法中,填 0 不影响加法累加)。 -
"nan":越界部分填 NaN。 -
""(默认):不确定的值(通常是内存中原有的垃圾数据),速度最快但安全性最低。
triton.language.tensor_descriptor
triton.language.make_tensor_descriptor 是 Triton 为了更好地支持 NVIDIA Hopper 架构(及后续架构) 中的 TMA (Tensor Memory Accelerator) 硬件特性而引入的高级接口。
它是 make_block_ptr 的继任者和增强版。虽然它们都用于描述多维数据块,但 tensor_descriptor 在设计上更加贴合底层硬件的搬运协议。
python
@builtin
def make_tensor_descriptor(
base: tensor,
shape: List[tensor],
strides: List[tensor],
block_shape: List[constexpr],
padding_option="zero",
_semantic=None,
) -> tensor_descriptor:
"""Make a tensor descriptor object
:param base: the base pointer of the tensor, must be 16-byte aligned
:param shape: A list of non-negative integers representing the tensor shape
:param strides: A list of tensor strides. Leading dimensions must be multiples
of 16-byte strides and the last dimension must be contiguous.
:param block_shape: The shape of block to be loaded/stored from global memory
Notes
*****
On NVIDIA GPUs with TMA support, this will result in a TMA descriptor object
and loads and stores from the descriptor will be backed by the TMA hardware.
Currently only 2-5 dimensional tensors are supported.
Example
*******
.. code-block:: python
@triton.jit
def inplace_abs(in_out_ptr, M, N, M_BLOCK: tl.constexpr, N_BLOCK: tl.constexpr):
desc = tl.make_tensor_descriptor(
in_out_ptr,
shape=[M, N],
strides=[N, 1],
block_shape=[M_BLOCK, N_BLOCK],
)
moffset = tl.program_id(0) * M_BLOCK
noffset = tl.program_id(1) * N_BLOCK
value = desc.load([moffset, noffset])
desc.store([moffset, noffset], tl.abs(value))
# TMA descriptors require a global memory allocation
def alloc_fn(size: int, alignment: int, stream: Optional[int]):
return torch.empty(size, device="cuda", dtype=torch.int8)
triton.set_allocator(alloc_fn)
M, N = 256, 256
x = torch.randn(M, N, device="cuda")
M_BLOCK, N_BLOCK = 32, 32
grid = (M / M_BLOCK, N / N_BLOCK)
inplace_abs[grid](x, M, N, M_BLOCK, N_BLOCK)
"""
padding_option = _unwrap_if_constexpr(padding_option)
return _semantic.make_tensor_descriptor(base, shape, strides, block_shape, padding_option)| 条目 | 名称 | 作用 / 含义 | 约束条件 |
|---|---|---|---|
| 输入参数 | base |
张量的基地址指针。 | 必须 16 字节对齐(由 TMA 硬件要求)。 |
| 输入参数 | shape |
完整父张量的形状列表(如 [M, N])。 |
支持 2 到 5 维。 |
| 输入参数 | strides |
张量的步长列表。 | 前导维度须 16 字节对齐,最后维度通常连续(stride 为 1)。 |
| 输入参数 | block_shape |
每次加载/存储的数据块形状。 | 必须是 tl.constexpr 类型。 |
| 输入参数 | padding_option |
越界时的填充策略。默认 "zero"。 |
目前主要支持 "zero"。 |
| 返回值 | desc |
返回一个张量描述符对象。 | tensor_descriptor 类型。 |
函数功能详解
make_tensor_descriptor 的核心目的是创建一个可以被硬件直接理解的"访存模板"。
1. 硬件级抽象:TMA 驱动
在之前的 make_block_ptr 模式下,地址计算往往还是由 GPU 的计算单元(CUDA Cores)完成的。而 make_tensor_descriptor 生成的对象会尽可能映射到 NVIDIA 的 TMA 硬件。
-
异步性:TMA 可以在不占用计算线程的情况下,在后台自动完成全局内存(Global Memory)到共享内存(Shared Memory)的数据搬运。
-
零开销寻址:多维索引到线性地址的转换由硬件电路完成,不消耗寄存器和指令。
2. "解耦"的思想
与 make_block_ptr 不同,描述符(Descriptor)将数据的几何结构(Shape/Stride)与具体的访问坐标(Offsets)彻底解耦了:
-
make_tensor_descriptor定义了"地块有多大,怎么排布"。 -
在实际使用时,调用
desc.load([offset_m, offset_n])才指定"我现在要搬哪一块"。
3. 严格的对齐要求
由于 TMA 硬件是为极致带宽设计的,它对内存地址非常挑剔:
-
对齐 :
base指针如果不满足 16 字节对齐,程序会直接报错或崩溃。 -
步长:行与行之间的跨度(Strides)也需要满足对齐要求,以确保硬件搬运效率。
使用方法对比:Descriptor vs Block Pointer
当你拿到一个描述符 desc 后,它的用法比以前更简洁:
python
# 1. 创建描述符 (类似定义一个模板)
desc = tl.make_tensor_descriptor(
base=ptr,
shape=[M, N],
strides=[N, 1],
block_shape=[BLOCK_M, BLOCK_N]
)
# 2. 计算当前 Block 的起点坐标
moffset = tl.program_id(0) * BLOCK_M
noffset = tl.program_id(1) * BLOCK_N
# 3. 直接加载,传入坐标即可
# 不需要像以前那样用 tl.advance 手动挪指针
tile = desc.load([moffset, noffset])
# 4. 同样支持直接存储
desc.store([moffset, noffset], tl.abs(tile))总结与建议
-
如果你在 H100 (SM90) 或更新的显卡上开发 :强烈建议优先使用
make_tensor_descriptor。它能解锁 TMA 的异步搬运能力,显著降低计算单元的访存压力。 -
如果你需要多维(3D-5D)支持:该函数提供了比以往更规范的 N-Dim 支持。
-
注意点 :使用此函数通常需要配合自定义的内存分配器(如示例中的
alloc_fn),以确保分配出的地址满足硬件对齐要求。
triton.language.maximum
triton.language.maximum 是一个逐元素(Element-wise)比较函数,用于从两个输入张量中挑选出较大的值。在深度学习中,它常用于实现 ReLU 激活函数或处理数值边界。
| 条目 | 名称 | 作用 / 含义 | 类型/取值约束 |
|---|---|---|---|
| 输入参数 | x |
第一个输入张量。 | Tensor (Block) |
| 输入参数 | y |
第二个输入张量。 | Tensor (Block),形状须与 x 匹配或可广播 |
| 输入参数 | propagate_nan |
控制如何处理 NaN(非数字)值。 |
tl.PropagateNan 枚举值 |
| 输入参数 | _semantic |
Triton 内部语义解析对象。 | 内部对象 |
| 返回值 | output |
返回逐元素比较后的最大值张量。 | 与输入形状相同的 Tensor |
函数功能详解
tl.maximum 执行的是 C i j = max ( A i j , B i j ) C_{ij} = \max(A_{ij}, B_{ij}) Cij=max(Aij,Bij) 的操作。它与 Python 原生的 max() 不同,它是针对整个数据块(Block)在硬件级并行执行的。
1. NaN 传播策略 (propagate_nan)
这是该函数最专业的一个参数。在 GPU 计算中,当遇到 NaN 时,不同的处理方式会影响结果的稳定性:
-
tl.PropagateNan.NONE(默认) :如果其中一个是NaN,结果通常倾向于返回另一个非NaN的数字(具体行为取决于底层硬件指令,通常遵循 IEEE 754 标准的fmax)。 -
tl.PropagateNan.ALL:只要x或y中有一个是NaN,结果就一定是NaN。
2. 硬件映射
在 NVIDIA GPU 上,对于 float 类型,这个函数通常映射为 FMNMX 指令或类似的算术单元操作,速度极快。对于 int 类型,则映射为整数比较指令。
典型应用场景
场景 A:实现 ReLU 激活函数
ReLU 的公式是 y = max ( 0 , x ) y = \max(0, x) y=max(0,x)。在 Triton 中这非常高效:
python
# 假设 x 是输入张量
zero = 0.0
# 这里的 0.0 会被广播到和 x 相同的形状
relu_out = tl.maximum(x, zero)场景 B:数值裁剪(Clamping)
虽然 Triton 有 tl.clamp,但你也可以组合使用 maximum 和 minimum:
Python
python
# 将数据限制在 [0, 1] 之间
out = tl.maximum(0.0, tl.minimum(1.0, x))注意:tl.maximum vs tl.max
这是初学者最容易搞混的地方:
-
tl.maximum(x, y):逐元素比较。输入两个张量,输出一个张量。例子:
max([1, 5], [2, 3]) -> [2, 5] -
tl.max(x, axis=...):规约(Reduction)操作。在一个张量内部找最大值,会减少维度。例子:
max([1, 5]) -> 5
triton.language.max
与上一个 maximum 不同,它是一个规约(Reduction)函数 。它的作用不是对比两个张量,而是在同一个张量内部沿着指定的维度寻找最大值。
| 条目 | 名称 | 作用 / 含义 | 类型约束 |
|---|---|---|---|
| 输入参数 | input |
需要进行求最大值操作的输入张量。 | Tensor |
| 输入参数 | axis |
进行规约的维度索引。如果不传,则对全量数据求最大值。 | int 或 None |
| 输入参数 | return_indices |
是否同时返回最大值所在的索引(即类似 argmax 的功能)。 |
bool |
| 输入参数 | return_indices_tie_break_left |
当有多个相同的最大值时,是否返回坐标最左边(较小)的索引。 | bool |
| 输入参数 | keep_dims |
是否保留原张量的维度(设为 True 则被规约的维度长度为 1)。 | bool |
| 返回值 | res / (res, idx) |
返回最大值张量 。如果 return_indices 为 True,则返回包含最大值和索引的元组。 |
Tensor 或 tuple(Tensor, Tensor) |
函数功能详解
tl.max 的核心功能是维度压缩。它通过比较指定轴上的所有元素,最终只保留该轴上的最大值。
1. 自动精度提升(Precision Promotion)
从源码中可以看到一个细节:
-
如果输入是
bfloat16,它会自动转为float32。 -
如果输入的位宽小于 32 位(如
float16或int16),它会强制提升到float32或int32进行计算。 -
原因 :规约操作涉及大量两两比较,提升精度可以减少累积误差(虽然对于
max影响较小,但对于sum等规约至关重要,Triton 对此类操作保持了统一的精度策略)。
2. Argmax 功能集成
通过设置 return_indices=True,这个函数可以一次性完成"找最大值"和"找最大值位置"两个任务。
- 这在深度学习中非常有用,例如在 Softmax 层找
max(x),或者在分类任务中提取预测标签。
3. 维度控制 (keep_dims)
-
如果输入形状是
[16, 32]:-
tl.max(input, axis=1, keep_dims=False)-> 输出形状[16]。 -
tl.max(input, axis=1, keep_dims=True)-> 输出形状[16, 1]。
-
典型应用场景
场景 A:Softmax 中的数值稳定性
为了防止计算 e x e^x ex 时溢出,通常会减去行内的最大值。
python
# 假设 x 形状为 [BLOCK_M, BLOCK_N]
# 沿着第 1 维(列方向)找每行的最大值
row_max = tl.max(x, axis=1) # 结果形状 [BLOCK_M]
# 利用广播机制减去最大值
safe_x = x - row_max[:, None] 场景 B:获取分类预测结果
python
# logits 形状为 [BATCH, CLASSES]
# 同时获取预测的概率最大值和所属类别索引
max_val, labels = tl.max(logits, axis=1, return_indices=True)固定Q块,遍历KV
python
# 这个函数不是完整 attention kernel
# 它负责固定一块 Q,也就是 BLOCK_M 行 query,然后分块遍历 K/V 的 BLOCK_N 列,
# 用 online softmax 的方式逐块更新 acc、l_i、m_i。
@triton.jit
def _attn_fwd_inner(
acc, # [BLOCK_M, HEAD_DIM],当前已经累积的 attention 输出分子,即 sum(P_ij * V_j),使用 float32 累加。
l_i, # [BLOCK_M],online softmax 的归一化分母,表示每一行目前累计的 exp 和。
m_i, # [BLOCK_M],online softmax 的每一行当前最大值,用于数值稳定。
q, # [BLOCK_M, HEAD_DIM],当前 Q block,外层 kernel 已经加载进来,会在整个 inner 循环中复用。
K_block_ptr, # Triton block pointer,指向 K 矩阵当前要读取的块;K 在这里按 [HEAD_DIM, N_CTX] 的逻辑形状读取。
V_block_ptr, # Triton block pointer,指向 V 矩阵当前要读取的块;V 按 [N_CTX, HEAD_DIM] 的逻辑形状读取。
start_m, # 当前 Q block 的 block id,对应第 start_m 个 BLOCK_M query 块。
qk_scale, # softmax 前的缩放系数,通常是 sm_scale * 1/log(2),因为这里用 exp2 而不是 exp。
BLOCK_M: tl.constexpr, # 一个 program 处理多少行 Q;编译期常量,影响 tile shape 和编译优化。
HEAD_DIM: tl.constexpr, # 每个 head 的维度,也就是 Q/K/V 最后一维大小;编译期常量。
BLOCK_N: tl.constexpr, # 每次循环处理多少列 K/V,也就是多少个 key/value token;编译期常量。
STAGE: tl.constexpr, # 当前 inner 处理哪一段注意力区域:1 表示 causal 对角线左侧,2 表示 causal 对角线所在块,其他表示非 causal 全范围。
offs_m: tl.constexpr, # [BLOCK_M],当前 Q block 内每一行对应的全局 token 下标。
offs_n: tl.constexpr, # [BLOCK_N],当前 K/V block 内的局部列偏移,通常是 0 到 BLOCK_N-1。
N_CTX: tl.constexpr, # 序列长度,也就是 token 数;Q/K/V 在序列维度上的长度。
fp8_v: tl.constexpr # V 是否是 float8e5 类型;如果是,P 也会转成 fp8 以匹配 dot 的输入类型。
):
# 根据 STAGE 决定当前 inner loop 需要遍历 K/V 的哪一段。
# 对 causal attention 来说,每个 Q block 可以分成:
# - off-band:严格在当前 Q block 左边的 K/V,可以无 mask 计算;
# - on-band:和当前 Q block 对角线相交的 K/V,需要 causal mask。
if STAGE == 1:
# STAGE == 1:处理当前 Q block 左边的所有 K/V token。
# 对第 start_m 个 Q block,它的起始行是 start_m * BLOCK_M。
# 因此它左侧可见的 K/V 范围是 [0, start_m * BLOCK_M)。
lo, hi = 0, start_m * BLOCK_M
elif STAGE == 2:
# STAGE == 2:处理当前 Q block 自己对应的对角线区域。
# 范围是 [start_m * BLOCK_M, (start_m + 1) * BLOCK_M)。
# 这一段需要 causal mask,因为 block 内有些 query 不能看到未来 key。
lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_M
# 告诉 Triton 编译器 lo 是 BLOCK_M 的倍数,帮助生成更好的地址计算代码。
lo = tl.multiple_of(lo, BLOCK_M)
else:
# 非 causal 情况:每个 Q 都可以看见全部 K/V,所以范围是 [0, N_CTX)。
lo, hi = 0, N_CTX
# 把 K block pointer沿着K的序列维度移动到lo的位置
# K 的逻辑 shape 是 [HEAD_DIM, N_CTX],所以第二维是 token 维,advance 参数是 (行偏移, 列偏移)。
K_block_ptr = tl.advance(K_block_ptr,(0,lo))
# 把 V block pointer 沿着 V 的序列维度移动到 lo 位置。
# V 的逻辑 shape 是 [N_CTX, HEAD_DIM],所以第一维是 token 维,advance 参数是 (行偏移, 列偏移)。
V_block_ptr = tl.advance(V_block_ptr, (lo, 0))
# 从 lo 到 hi,每次处理 BLOCK_N 个 K/V token。
for start_n in tl.range(lo,hi,BLOCK_N):
# 告诉编译器 start_n 是 BLOCK_N 的倍数,有利于优化内存访问和向量化。
start_n = tl.multiple_of(start_n,BLOCK_N)
# 加载当前 K tile。
# K_block_ptr 的 block_shape 是 [HEAD_DIM, BLOCK_N]。
# 所以 k 的形状是 [HEAD_DIM, BLOCK_N]。
k = tl.load(K_block_ptr)
# 计算 QK^T 的一个 tile。
# q 形状:[BLOCK_M, HEAD_DIM]
# k 形状:[HEAD_DIM, BLOCK_N]
# qk 形状:[BLOCK_M, BLOCK_N]
# qk[i, j] 表示当前 query 行 i 和当前 key 列 j 的点积。
qk = tl.dot(q, k)
if STAGE == 2:
# causal 对角线块需要 mask。
# offs_m[:, None] 形状是 [BLOCK_M, 1],表示 query 的全局 token 下标。
# start_n + offs_n[None, :] 形状是 [1, BLOCK_N],表示 key 的全局 token 下标。
# query_index >= key_index 表示当前 query 可以看到该 key。
# 该mask的形状是 [BLOCK_M,BLOCK_N],是一个下三角矩阵的部分列区域
mask = offs_m[:, None] >= (start_n + offs_n[None, :])
# 先乘 qk_scale,把点积缩放到 softmax logits。
# 对不满足 causal 条件的位置加上 -1e6,近似 -inf,使 softmax 后概率接近 0。
qk = qk * qk_scale + tl.where(mask, 0, -1.0e6)
# m_ij 是合并当前旧最大值 m_i 和当前 qk tile 每行最大值之后的新最大值。
# tl.max(qk, 1) 沿列方向取最大值,即每行的最大值,得到 [BLOCK_M]。
m_ij = tl.maximum(m_i, tl.max(qk, 1))
# 把 qk 减去每行最大值 m_ij,保证 exp2 的输入不会太大,提升数值稳定性。
# 这是softmax经典手法
qk -= m_ij[:, None]
else:
# 非对角线块直接计算,无需 mask
m_ij=tl.maximum(m_i,tl.max(qk,1)*qk_scale)
qk=qk*qk_scale-m_ij[:,None]
# 计算 P = exp2(QK^T - max)
# 注意:Triton 中 exp2 通常比 exp 更快,qk_scale 在外部预先乘了 1/log(2)
p=tl.math.exp2(qk)
# 计算当前块的归一化分母
l_ij=tl.sum(p,1)
# --- Online Softmax 核心更新逻辑 ---
# 计算新旧最大值之间的修正系数 alpha = 2^(m_old - m_new)
alpha=tl.math.exp2(m_i-m_ij)
# 更新分母:新分母 = 旧分母 * alpha + 当前块的分母
l_i=l_i*alpha+l_ij
# 更新分子(累加器):旧累加值也需要缩放以对齐新的最大值基准
acc=acc*alpha[:,None]
# 加载 V 块并更新累加器
v=tl.load(V_block_ptr)
# 将 P 转换为 V 的类型(fp16 或 fp8)以进行点积
if fp8_v:
p=p.to(tl.float8e5)
else:
p=p.to(tl.float16)
# acc = acc + P * V
acc=tl.dot(p,v,acc)
# 更新当前行的状态变量,进入下一个 K 块
m_i=m_ij
V_block_ptr=tl.advance(V_block_ptr,(BLOCK_N,0))
K_block_ptr=tl.advance(K_block_ptr,(0,BLOCK_N))
return acc,l_i,m_iCausal 模式"(因果模式)
Causal 模式"(因果模式)是自注意力机制(Self-Attention)在处理生成式任务(如 GPT 聊天机器人)时的核心逻辑。
简单来说:Causal 模式就是"不许看答案"模式。
在处理序列数据时,每个 Token(单词或字符)都在尝试关注其他 Token。
-
非 Causal 模式(如 BERT):每个单词都能看到整个句子。比如"我 爱 你",计算"我"的时候,它知道后面跟着"爱"和"你"。
-
Causal 模式(如 GPT) :每个单词只能看到它自己和它之前的单词。计算"爱"的时候,它只能看到"我",绝对不能看到后面的"你"。
矩阵几何表示:下三角矩阵
如果我们将 Q × K T Q \times K^T Q×KT 的结果看作一个方阵,行表示 Query(当前单词),列表示 Key(被关注的单词):
-
对角线(Diagonal):单词关注它自己。
-
下三角(Lower Triangle):单词关注它之前的单词(允许访问)。
-
上三角(Upper Triangle) :单词关注它之后的单词(被 Mask 掉,设为 − ∞ -\infty −∞)。
在内部函数里,stage有三个状态
| STAGE | 对应区域 | 说明 |
|---|---|---|
| STAGE 1 | Off-band (全下三角) | 这块 K K K 块完全在当前 Q Q Q 块的左边。所有 Key 都在过去,无需 Mask,直接全速计算。 |
| STAGE 2 | On-band (对角线块) | 这块 K K K 块正好和 Q Q Q 块的时间线重叠。必须进行逐元素的 Causal Mask。 |
| STAGE 3 | Future (上三角) | 这块 K K K 块完全在未来。 |
调用接口
python
# 尝试不同的分块策略 (BM, BN) 以及并行度 (num_warps)
configs = [
triton.Config({'BLOCK_M': BM, 'BLOCK_N': BN}, num_stages=s, num_warps=w) \
for BM in [64, 128]\
for BN in [32, 64]\
for s in ([1] if is_hip() else [3, 4, 7])\
for w in [4, 8]\
]
def keep(conf):
"""
过滤掉不合理的配置。
例如:如果 Tile 太小但 Warp 太多,会导致计算资源浪费和同步开销过大。
"""
BLOCK_M = conf.kwargs["BLOCK_M"]
BLOCK_N = conf.kwargs["BLOCK_N"]
if BLOCK_M * BLOCK_N < 128 * 128 and conf.num_warps == 8:
return False
return True
@triton.autotune(list(filter(keep, configs)), key=["N_CTX", "HEAD_DIM"])
@triton.jit
def _attn_fwd(
Q, K, V, sm_scale, M, Out,
stride_qz, stride_qh, stride_qm, stride_qk, # Q 的步长(Batch, Head, Seq, Dim)
stride_kz, stride_kh, stride_kn, stride_kk, # K 的步长
stride_vz, stride_vh, stride_vk, stride_vn, # V 的步长
stride_oz, stride_oh, stride_om, stride_on, # Output 的步长
Z, H, N_CTX, # Batch, Heads, 全局序列长度
HEAD_DIM: tl.constexpr,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
STAGE: tl.constexpr # 这里的 STAGE 决定了是否是 Causal 模式
):
tl.static_assert(BLOCK_N<=HEAD_DIM)
# --- 1. 计算当前程序(Program)在网格中的位置 ---
start_m = tl.program_id(0) # 处理第几个 Q 块
off_hz = tl.program_id(1) # 处理哪一个 Batch 和哪一个 Head
off_z = off_hz // H # 当前 Batch ID
off_h = off_hz % H # 当前 Head ID
# 计算该 Batch/Head 对应的基础内存偏移
qkv_offset=off_z.to(tl.int64)*stride_qz+off_h.to(tl.int64)
# --- 2. 初始化 Block Pointer (块指针) ---
# 块指针是 Triton 2.0+ 的特性,它能自动处理边界检查和复杂的步长计算
# Q 块:从 (start_m * BLOCK_M, 0) 开始,形状为 (BLOCK_M, HEAD_DIM)
Q_block_ptr = tl.make_block_ptr(
base=Q + qkv_offset,
shape=(N_CTX, HEAD_DIM),
strides=(stride_qm, stride_qk),
offsets=(start_m * BLOCK_M, 0),
block_shape=(BLOCK_M, HEAD_DIM),
order=(1, 0),
)
# V 块:形状 (BLOCK_N, HEAD_DIM)
# 对于 fp8 格式,V 的存储顺序(order)可能不同以适配硬件加速
v_order: tl.constexpr = (0, 1) if V.dtype.element_ty == tl.float8e5 else (1, 0)
V_block_ptr = tl.make_block_ptr(
base=V + qkv_offset,
shape=(N_CTX, HEAD_DIM),
strides=(stride_vk, stride_vn),
offsets=(0, 0),
block_shape=(BLOCK_N, HEAD_DIM),
order=v_order,
)
# K 块:注意这里 K 是被转置读取的 (HEAD_DIM, BLOCK_N),方便与 Q 做点积
K_block_ptr = tl.make_block_ptr(
base=K + qkv_offset,
shape=(HEAD_DIM, N_CTX),
strides=(stride_kk, stride_kn),
offsets=(0, 0),
block_shape=(HEAD_DIM, BLOCK_N),
order=(0, 1),
)
# Output 块指针
O_block_ptr = tl.make_block_ptr(
base=Out + qkv_offset,
shape=(N_CTX, HEAD_DIM),
strides=(stride_om, stride_on),
offsets=(start_m * BLOCK_M, 0),
block_shape=(BLOCK_M, HEAD_DIM),
order=(1, 0),
)
# --- 3. 初始化 Online Softmax 状态变量 ---
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)# 每一行的全局索引
offs_n = tl.arange(0, BLOCK_N)# 每一列的局部索引
# 初始化 m 和 l 的指针
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")# 最大值初始化为负无穷
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0 # 分母初始化(稍后会被修正)
acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)# 结果累加器
# 加载系数
qk_scale = sm_scale
# FlashAttention 使用 base 2 指数运算
qk_scale *= 1.44269504 # 1/log(2)
# 预加载 Q 块到 SRAM,因为它在遍历 K/V 时保持不变
q = tl.load(Q_block_ptr)
# --- 5. 分阶段调用内层循环 ---
# 使用位运算判断 STAGE。
# 如果 STAGE & 1 为真(例如非 Causal 模式 STAGE=1,或者 Causal 模式 STAGE=3),处理常规块。
if STAGE & 1:
# 在 Causal 模式下(STAGE=3),这里执行的是 STAGE=1 的逻辑(左侧全量块)
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M, HEAD_DIM, BLOCK_N, #
4 - STAGE, offs_m, offs_n, N_CTX, V.dtype.element_ty == tl.float8e5 #
)
# 如果 STAGE & 2 为真(Causal 模式 STAGE=2 或 3),处理对角线块
if STAGE & 2:
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M, HEAD_DIM, BLOCK_N, #
2, offs_m, offs_n, N_CTX, V.dtype.element_ty == tl.float8e5 #
)
# --- 6. 结尾处理(Epilogue) ---
# 最终输出为 acc / l_i
# 计算最终的 log-sum-exp,存入 M 矩阵,后续 Backward 阶段会用到
# 这里的m_i最终存的是一个教log-sum-exp(LSE)的东西,它在反向传播的时候有用
m_i += tl.math.log2(l_i)#LSE=max(x)+log(li),这里li是2为底的,所以用log2
acc = acc / l_i[:, None]
m_ptrs = M + off_hz * N_CTX + offs_m
tl.store(m_ptrs, m_i)
tl.store(O_block_ptr, acc.to(Out.type.element_ty))模型层定义
python
class _attention(torch.autograd.Function):
@staticmethod
def forward(ctx, q, k, v, causal, sm_scale):
# 形状约束
HEAD_DIM_Q, HEAD_DIM_K = q.shape[-1], k.shape[-1]
# 当 v 在 float8_e5m2 格式下时,进行转置。
HEAD_DIM_V = v.shape[-1]
assert HEAD_DIM_Q == HEAD_DIM_K and HEAD_DIM_K == HEAD_DIM_V
assert HEAD_DIM_K in {16, 32, 64, 128, 256}
o = torch.empty_like(q)
stage = 3 if causal else 1
extra_kern_args = {}
# Tuning for AMD target
# 为 AMD 设备调整
if is_hip():
waves_per_eu = 3 if HEAD_DIM_K <= 64 else 2
extra_kern_args = {"waves_per_eu": waves_per_eu, "allow_flush_denorm": True}
grid = lambda args: (triton.cdiv(q.shape[2], args["BLOCK_M"]), q.shape[0] * q.shape[1], 1)
M = torch.empty((q.shape[0], q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
_attn_fwd[grid](
q, k, v, sm_scale, M, o, #
q.stride(0), q.stride(1), q.stride(2), q.stride(3), #
k.stride(0), k.stride(1), k.stride(2), k.stride(3), #
v.stride(0), v.stride(1), v.stride(2), v.stride(3), #
o.stride(0), o.stride(1), o.stride(2), o.stride(3), #
q.shape[0], q.shape[1], #
N_CTX=q.shape[2], #
HEAD_DIM=HEAD_DIM_K, #
STAGE=stage, #
**extra_kern_args)
ctx.save_for_backward(q, k, v, o, M)
ctx.grid = grid
ctx.sm_scale = sm_scale
ctx.HEAD_DIM = HEAD_DIM_K
ctx.causal = causal
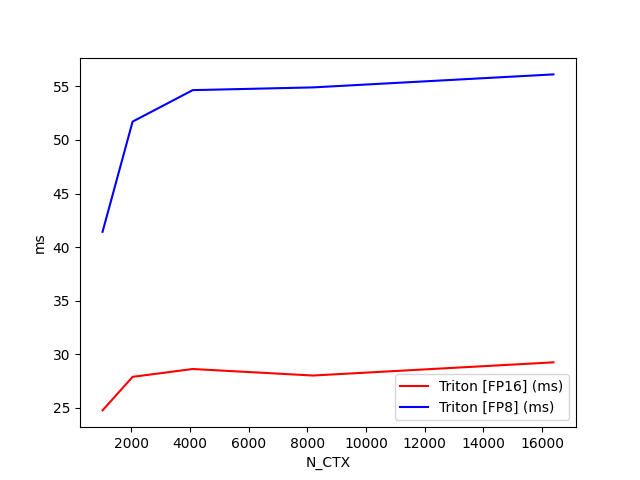
return o测试代码
python
try:
from flash_attn.flash_attn_interface import \
flash_attn_qkvpacked_func as flash_attn_func
HAS_FLASH = True
except BaseException:
HAS_FLASH = False
TORCH_HAS_FP8 = hasattr(torch, 'float8_e5m2')
BATCH, N_HEADS, HEAD_DIM = 4, 32, 64
# vary seq length for fixed head and batch=4
# 对于固定的 head 和 batch 为 4,变化序列长度。
configs = []
for mode in ["fwd"]:
for causal in [True, False]:
configs.append(
triton.testing.Benchmark(
x_names=["N_CTX"],
x_vals=[2**i for i in range(10, 15)],
line_arg="provider",
line_vals=["triton-fp16"] + (["triton-fp8"] if TORCH_HAS_FP8 else []) +
(["flash"] if HAS_FLASH else []),
line_names=["Triton [FP16]"] + (["Triton [FP8]"] if TORCH_HAS_FP8 else []) +
(["Flash-2"] if HAS_FLASH else []),
styles=[("red", "-"), ("blue", "-")],
ylabel="ms",
plot_name=f"fused-attention-batch{BATCH}-head{N_HEADS}-d{HEAD_DIM}-{mode}-causal={causal}",
args={
"H": N_HEADS,
"BATCH": BATCH,
"HEAD_DIM": HEAD_DIM,
"mode": mode,
"causal": causal,
},
))
@triton.testing.perf_report(configs)
def bench_flash_attention(BATCH, H, N_CTX, HEAD_DIM, causal, mode, provider, device="cuda"):
assert mode in ["fwd"]
warmup = 25
rep = 100
dtype = torch.float16
if "triton" in provider:
q = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
k = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
v = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
if mode == "fwd" and "fp8" in provider:
q = q.to(torch.float8_e5m2)
k = k.to(torch.float8_e5m2)
v = v.permute(0, 1, 3, 2).contiguous()
v = v.permute(0, 1, 3, 2)
v = v.to(torch.float8_e5m2)
sm_scale = 1.3
fn = lambda: attention(q, k, v, causal, sm_scale)
ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
if provider == "flash":
qkv = torch.randn((BATCH, N_CTX, 3, H, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)
fn = lambda: flash_attn_func(qkv, causal=causal)
ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
flops_per_matmul = 2.0 * BATCH * H * N_CTX * N_CTX * HEAD_DIM
total_flops = 2 * flops_per_matmul
if causal:
total_flops *= 0.5
return total_flops / ms * 1e-9
if __name__ == "__main__":
# only works on post-Ampere GPUs right now
# 目前只适用于安培架构 GPU。
bench_flash_attention.run(save_path=".", print_data=True)测试结果
causal=False
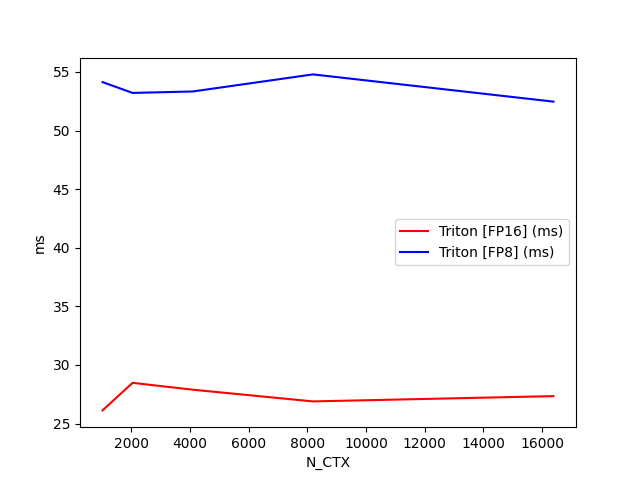
causal=True