大家有没有发现,市面上数据分析方法和模型越来越多了,从PEST分析到杜邦分析,再到漏斗模型,种类多得让人眼花缭乱。
学的时候感觉自己掌握了一堆绝招,但一到实际项目就懵了------面对原始数据,不知道该从哪里开始,脑海里的知识点到处打架,今天学的明天就忘,效率奇低。
**问题不在于方法少,而是缺少一个指导全局的完整流程。**这套流程就是数据分析的骨架,是所有方法模型的基石。
今天这篇文章我就结合从业十多年的观察和思考,把这套从0到1的数据分析完整流程讲清楚。干货满满!建议直接收藏,跟着一步步实践。
刚好我这里整理了一份数字化全流程资料包 ,内容非常全面,包括数字化知识图谱、优质案例以及多个场景的解决方案。除此之外,还有结合具体企业实践的详细讲解,一步步剖析企业如何从0到1完成数据建设,推动数字化转型。需要自取:https://s.fanruan.com/tyac0(复制到浏览器)
一、数据采集
数据采集是整条流程的起点,质量直接决定最终结果的天花板。实际业务中,不同场景有不同的采集策略。
- **电商平台:**通过埋点技术捕捉用户点击、浏览、加购等行为轨迹,这些数据是后续用户画像和转化分析的基础。
- **线下连锁零售:**依靠POS系统和会员扫码,把每一笔交易转化为结构化数据。
- **制造业:**在生产线部署传感器,实时收集设备运行参数和良品率数据。物流企业:在仓储和运输环节使用RFID和GPS,追踪货物流转全过程。
从技术上分,数据采集主要有三条路径。
1.数据库同步
适用于已有信息系统完备的企业。MySQL、Oracle这些传统数据库仍是主流数据存储方式。技术实现上,Sqoop和ETL工具负责跨系统数据搬运,像Kettle、Talend这类开源工具已经集成了数据集成模块,支持HDFS、HBase和主流NoSQL数据库之间的双向同步。关键是设计好同步频率和字段映射规则,避免数据冗余和延迟。
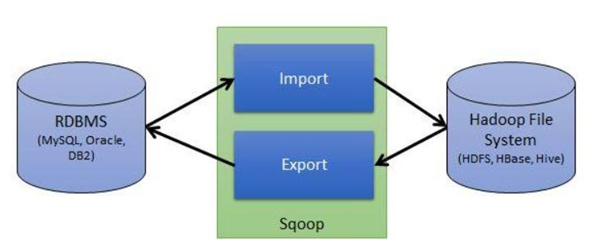
2.网络爬虫
针对外部公开数据。通过模拟浏览器行为或调用网站开放API,把网页上的非结构化信息转化为本地结构化数据。这里要注意反爬机制和法律法规,合理设置请求频率,优先选择官方API通道。
3.日志文件采集
处理系统运行轨迹。Flume适合做实时日志流抓取,ELK栈是日志分析的标配组合。**对于增量采集,关键是设计好时间戳或版本号字段,**确保每次只抓新增和变更数据,不重复不遗漏。
二、数据处理
原始数据就像刚开采出来的矿石,没法直接用。数据处理环节就是把矿石提纯成精矿,为分析做准备。这一步包括:
- 清洗脏数据
- 填补缺失值
- 合并多源表
- 统一规格标准
- 检验逻辑一致性
具体操作清单:**删除重复记录,处理空值,修正逻辑错误,转换数据格式,按业务规则分组,备份异常数据。**这些工作占分析师60%以上的时间,枯燥但关键。
我认识的很多团队都是使用FineBI 这个BI工具来完成数据处理工作的,它内部有自助数据集功能,支持可视化拖拽完成数据关联、过滤、分组聚合,不用人员写复杂SQL,可以大大提升工作效率。
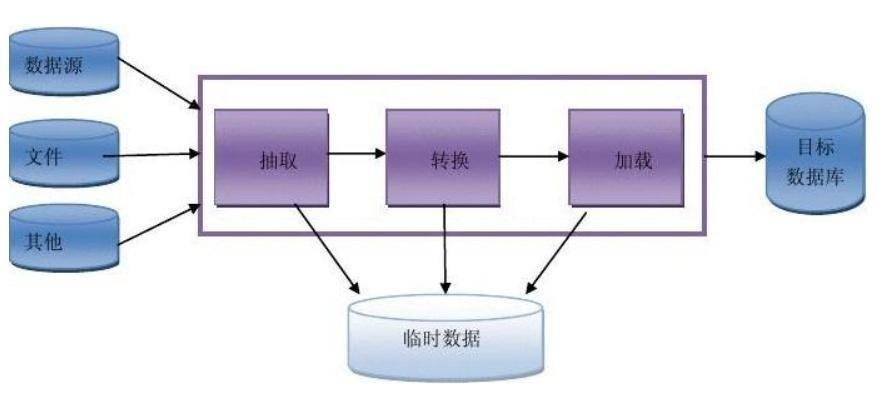
三、数据分析
数据处理完才到分析环节,很多人一上来就急着跑模型,这是大忌。分析前必须明确两件事:用什么思路框架,用什么技术方法。
1.思路框架
PEST模型 适合宏观环境分析,从政治、经济、社会、技术四个维度看市场趋势。4P营销理论 聚焦产品、价格、渠道、促销,诊断营销问题。5W2H 帮助梳理业务场景,七个问题把业务逻辑拆透。用户行为理论 按认知-熟悉-试用-使用-忠诚的路径分析转化瓶颈。逻辑树像树枝一样把大问题层层拆解成小问题,找到根因。
2.技术方法
杜邦分析法 把净资产收益率逐层拆解,定位利润下滑到底出在销售、成本还是资产效率。对比分析法 最常用,同比看趋势,环比看变化,横向对标找差距。结构分析法 算占比,识别主要矛盾和次要矛盾。漏斗图分析转化路径,每一步流失多少一目了然。交叉分析法做维度下钻,比如销售额下降,交叉分析地区和产品线,可能发现只是华东区某单品的问题。
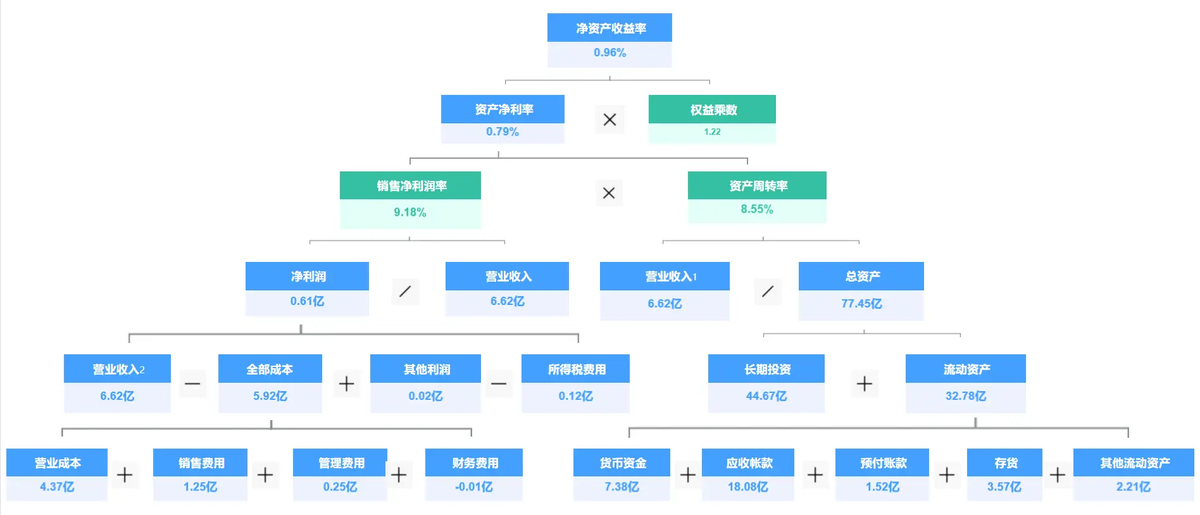
**这些框架和方法不是孤立的,实际项目中经常组合使用。**比如先用逻辑树定位问题范围,再用对比分析找异常点,最后用杜邦分析深挖原因。
四、数据展现
分析结果得用图表说话,但图表不是越多越好。选对图表类型,关键是清楚下面四个核心点。
- **业务观点:**是展示趋势、对比大小还是呈现分布
- **目标受众:**给管理层看要简洁,给业务人员看要细致
- **数据特征:**时间序列用折线图,分类对比用柱状图,占比关系用饼图或矩形树图
- **引导结论:**图表设计要突出这个结论,避免信息过载
高频使用的图表其实就几种。折线图看趋势,柱状图做对比,散点图找相关性,热力图看密度分布,漏斗图分析转化。
记住一个原则:一张图只讲一个核心观点,复杂信息拆成多图联动。
五、数据可视化
数据展现是静态的图表,数据可视化是动态的、可交互的决策界面。这个环节要把分析成果产品化,让业务方和领导能自助探索数据。
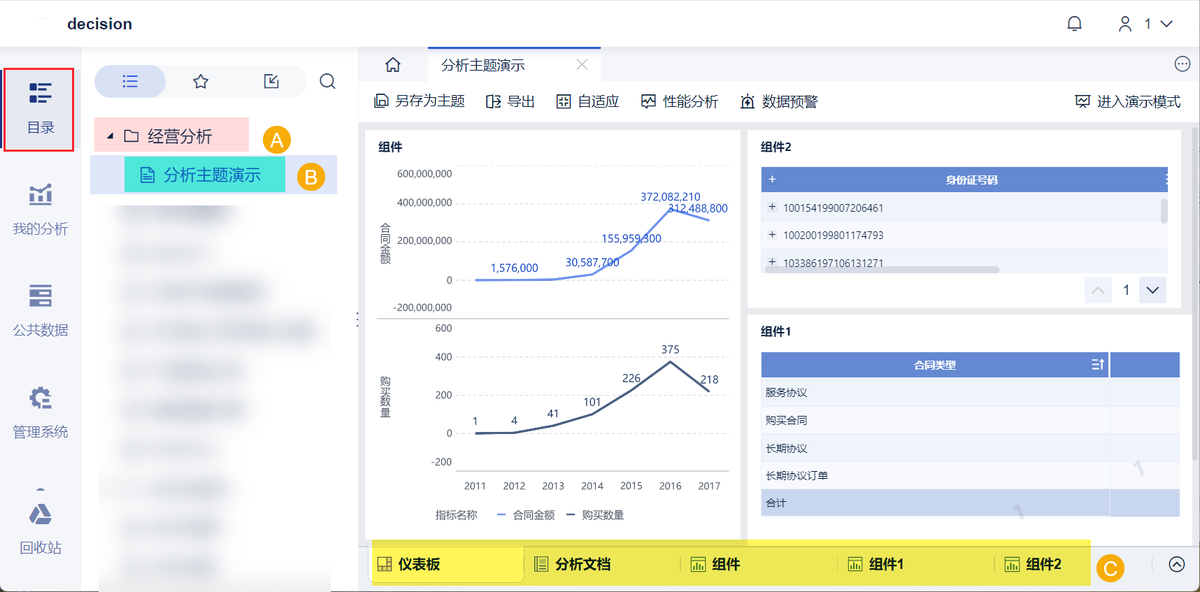
月度经营分析会是最典型的场景。传统做法是提前三天准备PPT,领导一问细节就得回去翻数据。现在大家都会用BI工具来搭建实时更新的经营驾驶舱,把核心指标、趋势分析、异常预警整合在一个大屏里。会议现场直接投屏,领导问到某个区域为什么下滑,当场就能点击下钻到城市维度,再下钻到门店,实时看到问题门店的客流、客单价、SKU动销数据。
现在很多企业用的FineBI 平台,就是这个场景的落地。它的交互式分析界面仅需拖拽就可以生成图表,还可以设置多图表联动,比如点击A图的某个柱子,B图和C图就会自动过滤对应数据。同时,它的移动端适配做得格外好,领导在手机上也能查看和批注:https://s.fanruan.com/0j1bm(复制到浏览器)
六、数据分析报告
走完前面五步,最后必须输出一份数据分析报告。**报告不是图表堆砌,而是价值传递。**很多新人习惯把过程写得很详细,领导看了三页还不知道结论是什么,这是大忌。
好报告的结构:一页纸说清核心结论,三页纸讲关键数据支撑,最后一页给可落地的建议。
开头直接亮明观点,比如本季度用户流失率上升5个百分点,主要原因是新客首单转化率下降。接着用数据论证,新客转化率从40%降到28%,其中18-25岁年龄段下降最显著。最后给出建议,优化新人专区选品,增加这个年龄段的高频商品曝光。
记住,**报告的价值在于推动行动。**每个结论后面要跟一个建议,每个建议都要有数据支撑。不要写用户活跃度下降这种描述性结论,要写用户活跃度下降30%,主要原因是push点击率降低,建议优化push文案并增加个性化推荐这种诊断性结论。
七、总结
这套流程的本质是把数据分析从随机游走变成标准作业。 在实际工作中不必拘泥于线性顺序。探索性分析时可能先可视化发现异常,再回去处理数据。报告阶段可能发现数据不足,再补充采集。但主线流程不变,每个环节都有明确产出和质量标准。我建议你从一个小项目开始完整跑一遍流程,比如分析上个月的销售数据。亲手经历从导出数据、清洗、分析、做图表到写报告的全过程,比看十篇方法论都有用。