摘要
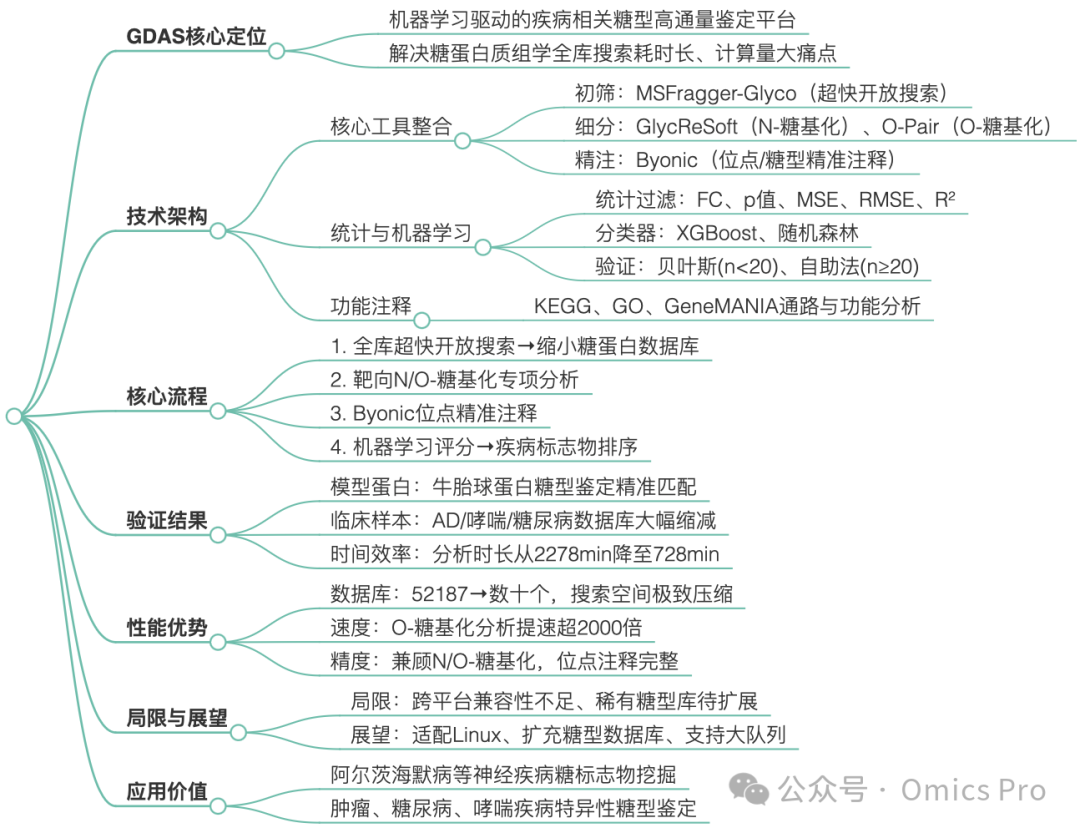
糖基化是类关键的蛋白质翻译后修饰,也是疾病生物标志物的重要来源,但在蛋白质组水平上开展糖基化位点与糖型的全面、位点特异性鉴定仍存在计算量大、耗时久的问题。本文开发糖蛋白质组学数据分析软件(GDAS),这是款可从质谱数据中快速、可靠鉴定疾病特异性糖型的高通量计算平台。GDAS将超快开放搜索策略(如MSFragger-Glyco)与统计过滤相结合,将大规模蛋白质组数据库高效精简为显著差异调控糖蛋白的核心集合,进而简化后续使用GlycReSoft、O-Pair等专用工具开展的靶向N-糖基化与O-糖基化分析。专属的最终分析模块进一步通过高级统计建模与机器学习算法(自助法、贝叶斯推断、XGBoost、随机森林)整合定量输出结果,生成稳健的糖基化评分以实现生物标志物优先级排序。将GDAS应用于已发表的阿尔茨海默病数据集,验证其可捕获具有生物学意义的糖基化异常改变。
https://github.com/Yang-LabSUMC/GDAS
#糖基化 #糖蛋白质组学 #质谱 #机器学习 #疾病特异性糖型 #生物标志物 #GDAS

结果与讨论
GDAS流程界面
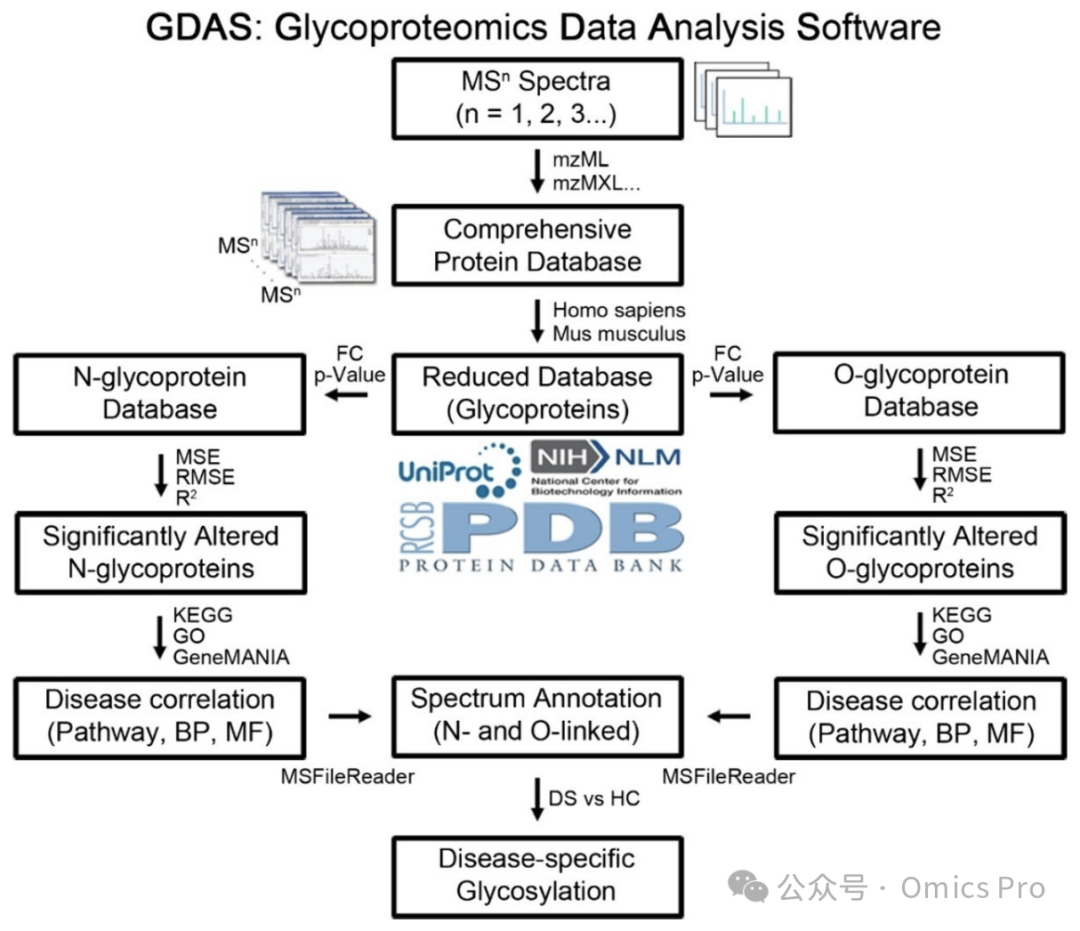
图 1 GDAS平台工作流程示意图
GDAS整合基于质谱的糖蛋白质组学分析、统计过滤与功能注释,实现疾病特异性糖基化的高通量鉴定。首先将多级质谱数据与全面蛋白质组数据库进行搜索,生成精简糖蛋白库;再基于统计学显著性(倍数变化、p值、均方误差、均方根误差、决定系数)进一步过滤;目标蛋白进行位点特异性糖基化注释,随后利用京都基因与基因组百科全书(KEGG)、基因本体(GO)、基因互作综合分析平台(GeneMANIA)开展通路与功能分析,鉴定疾病相关糖基化标志物。
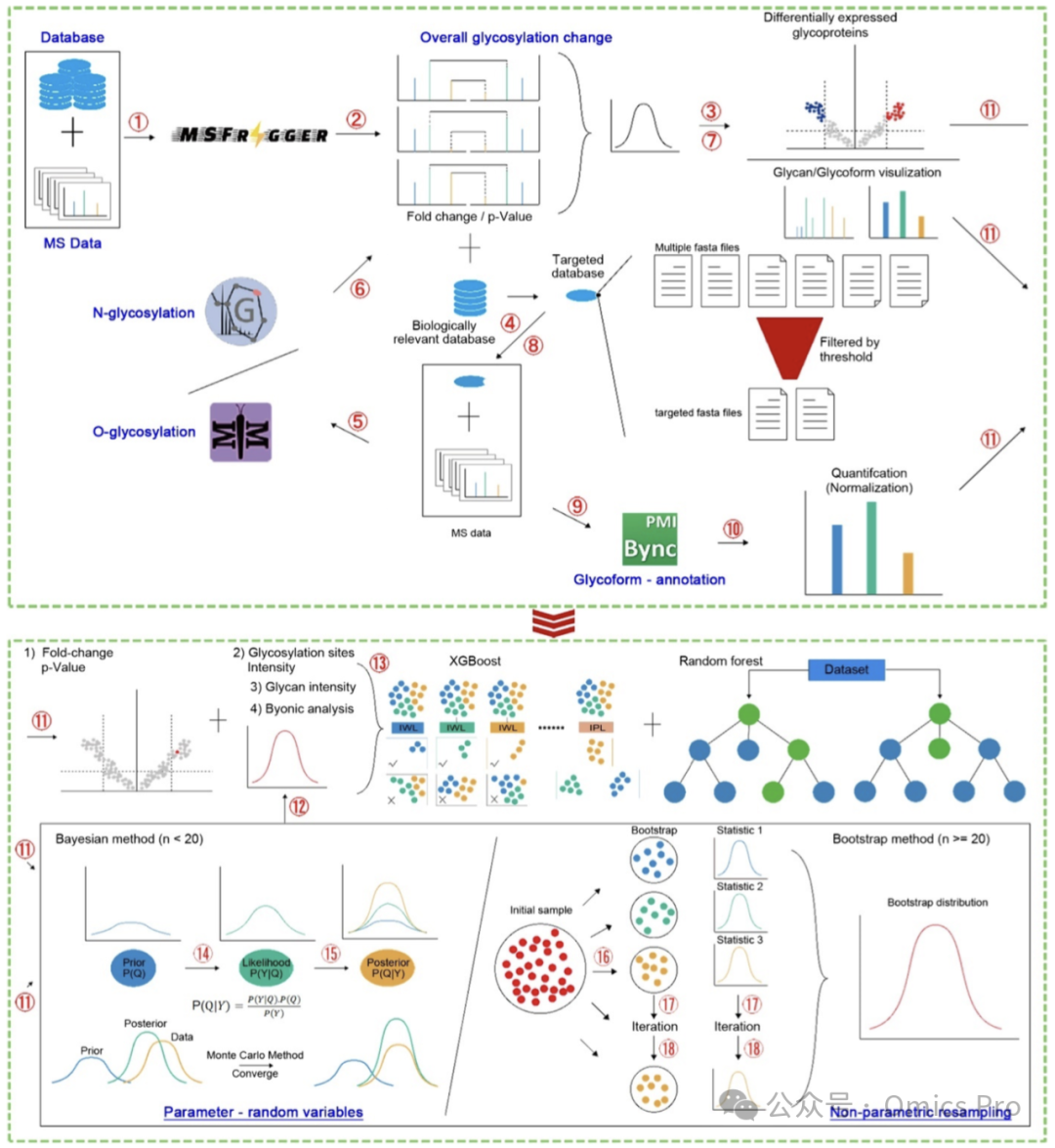
图 2 GDAS计算算法工作流程示意图
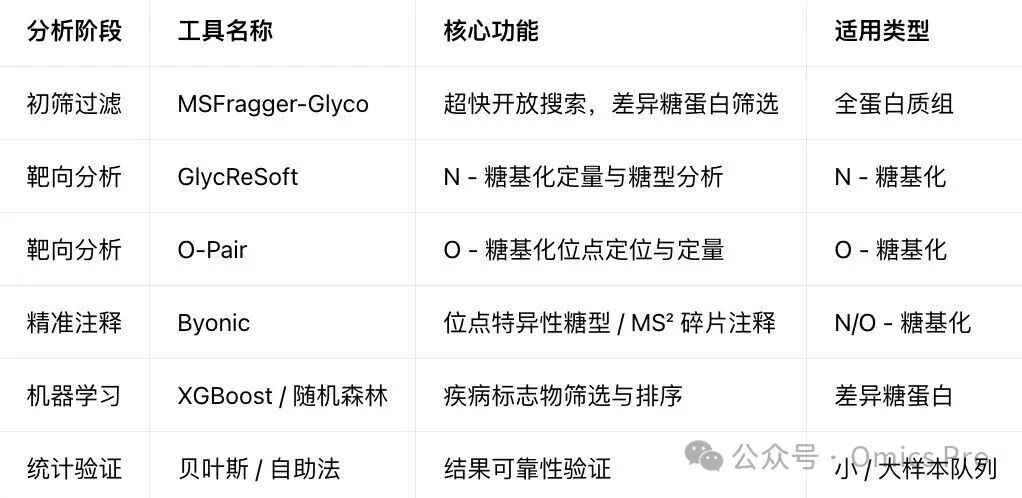
GDAS流程整合基于质谱的糖蛋白质组学分析、数据库精简、机器学习与统计验证以实现生物标志物挖掘。原始质谱数据首先经MSFragger处理鉴定差异糖基化蛋白,通过火山图可视化并生成过滤后的靶向蛋白质数据库;随后使用GlycReSoft与O-Pair分别开展N-糖基化与O-糖基化分析,再通过Byonic完成糖型注释;所得数据经预处理后,基于XGBoost机器学习进行生物标志物筛选;小样本量(n<20)采用贝叶斯模型统计验证,大样本队列(n≥20)采用自助重抽样法验证。
显著差异调控糖蛋白的计算算法
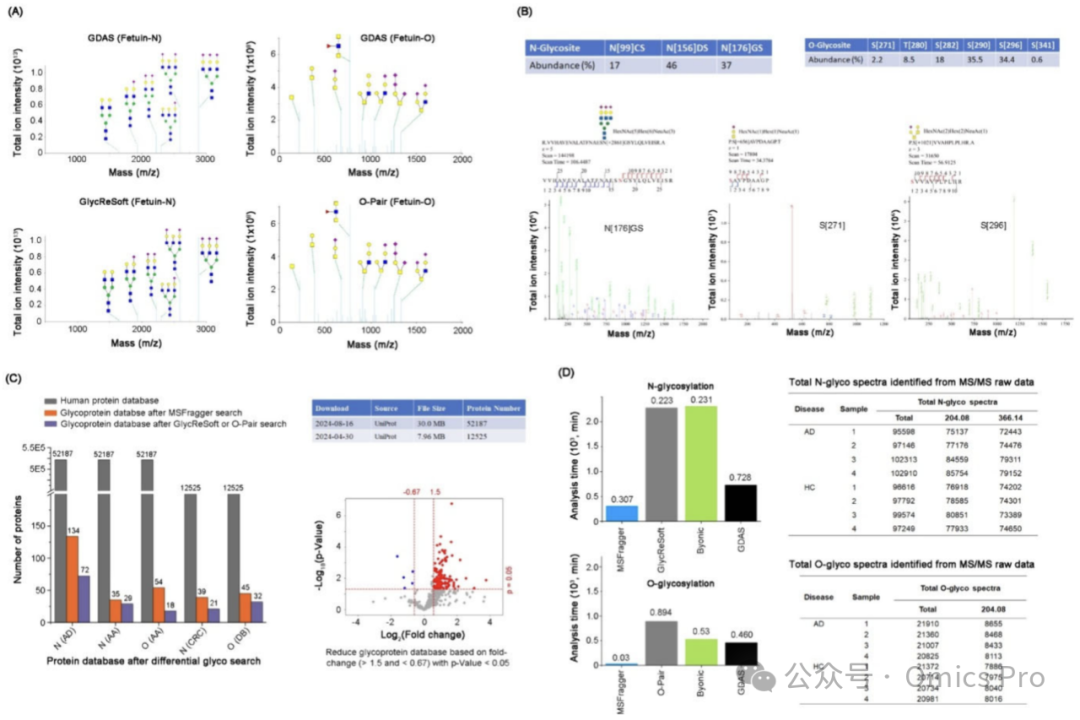
图 3 GDAS工作流程的验证与性能比较
(A) 将GDAS分析牛胎球蛋白所得糖链谱与GlycReSoft(N-糖链)、O-Pair(O-糖链)结果对比,糖链组成与相对丰度高度一致。
(B) 牛胎球蛋白糖基化位点的质谱/质谱注释,定量3个N-糖基化位点与6个O-糖基化位点,展示N176、S271、S296位点的代表性图谱。
(C) GDAS在多种疾病样本中分步精简数据库的效果,基于MSFragger快速筛选候选糖蛋白,验证其高效精简能力。
(D) 不同软件的分析时长对比,证明GDAS整合速度优势与数据库精简能力。
复杂生物样本中疾病特异性糖基化标志物的鉴定
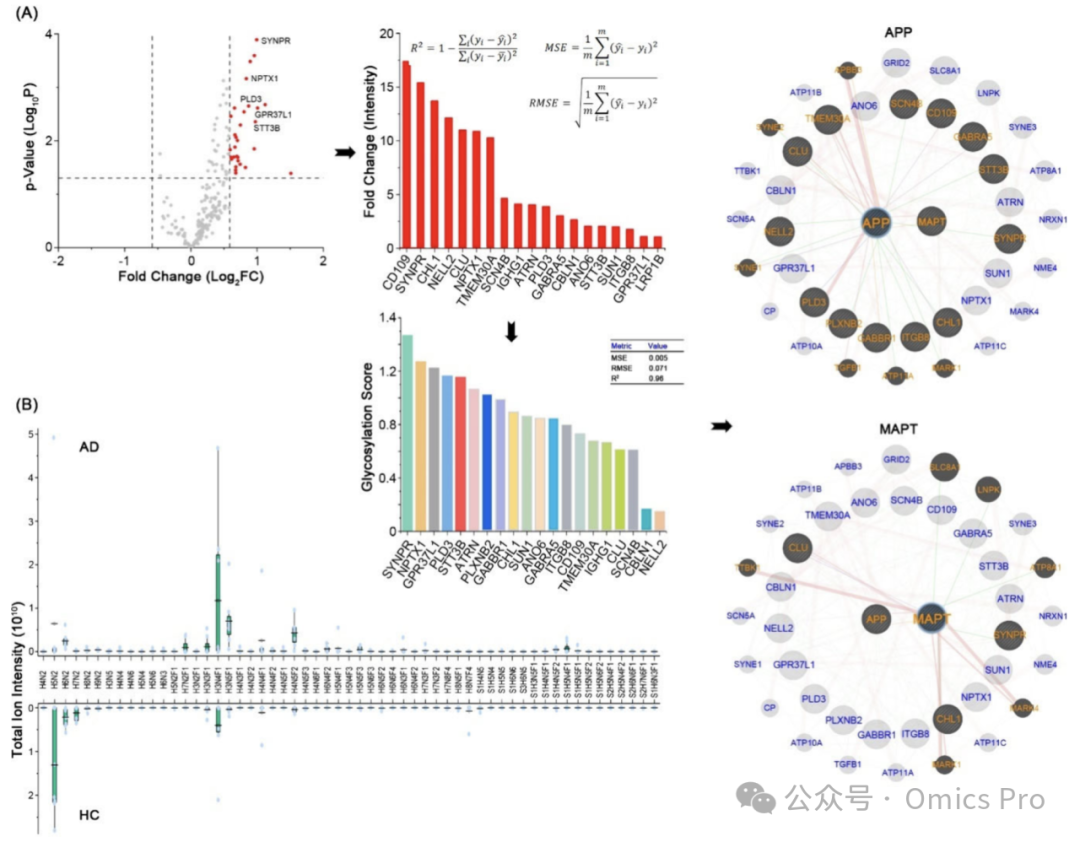
图 4 GDAS鉴定阿尔茨海默病组织中疾病特异性N-糖基化
(A) 对4例阿尔茨海默病(AD)与4例健康对照(HC)样本的质谱数据进行人类蛋白质组与糖组数据库搜索;火山图展示基于倍数变化与p值的差异糖蛋白,标注显著差异蛋白;对排名靠前的蛋白进行决定系数、均方误差、均方根误差验证,再经Byonic分析与KEGG、GO、GeneMANIA功能注释;以淀粉样前体蛋白(APP)、微管相关蛋白Tau(MAPT)为中心的蛋白互作网络,突出参与阿尔茨海默病相关通路的显著差异糖蛋白。
(B) 基于糖链组成总离子强度的阿尔茨海默病与健康对照样本的全局N-糖组谱对比(H:己糖;N:N-乙酰葡糖胺;F:岩藻糖;S:N-乙酰神经氨酸;G:N-乙酰羟神经氨酸)。
详细总结
思维导图
关键工具整合
分析时间对比

参考
Anal Chem. 2026 May 18. doi: 10.1021/acs.analchem.6c01321.
GDAS: A Machine Learning-Driven Approach for the High-Throughput Identification of Disease-Associated Glycoforms
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。