在人工智能技术飞速发展的今天,大语言模型已经从云端服务走向本地部署,轻量化大模型凭借体积小、速度快、无需联网、隐私安全等优势,成为 AI 开发者、编程爱好者入门学习的最佳选择。Qwen2.5-1.5B-Instruct 作为通义千问系列的轻量级开源模型,参数规模适中,推理性能优秀,完美适配个人电脑本地运行,既能实现智能对话,也能轻松完成文本分类、情感分析、信息提取等 NLP 任务。
本文将从零开始,手把手带你完成Ollama 一键部署 Qwen2.5-1.5B、魔搭社区 Git 克隆模型 + Git LFS 拉取大文件、Python 代码本地推理三大核心流程,全程保姆级教学,即使是零基础新手,也能顺利在自己的电脑上跑通轻量化大模型,实现文本情感分类实战。
一、方案 1:Ollama 一键部署(最快上手)
1. 下载安装 Ollama
第一步:打开 Ollama 官方网站(https://ollama.com/),首页直接显示对应系统的下载按钮,点击下载 Windows 版本。
第二步:双击安装包,全程默认下一步即可完成安装,Ollama 会自动配置系统环境变量,无需手动设置。
2.下载Qwen2.5-1.5B
在ollama中搜索qwen2.5,复制1.5b版本命令。
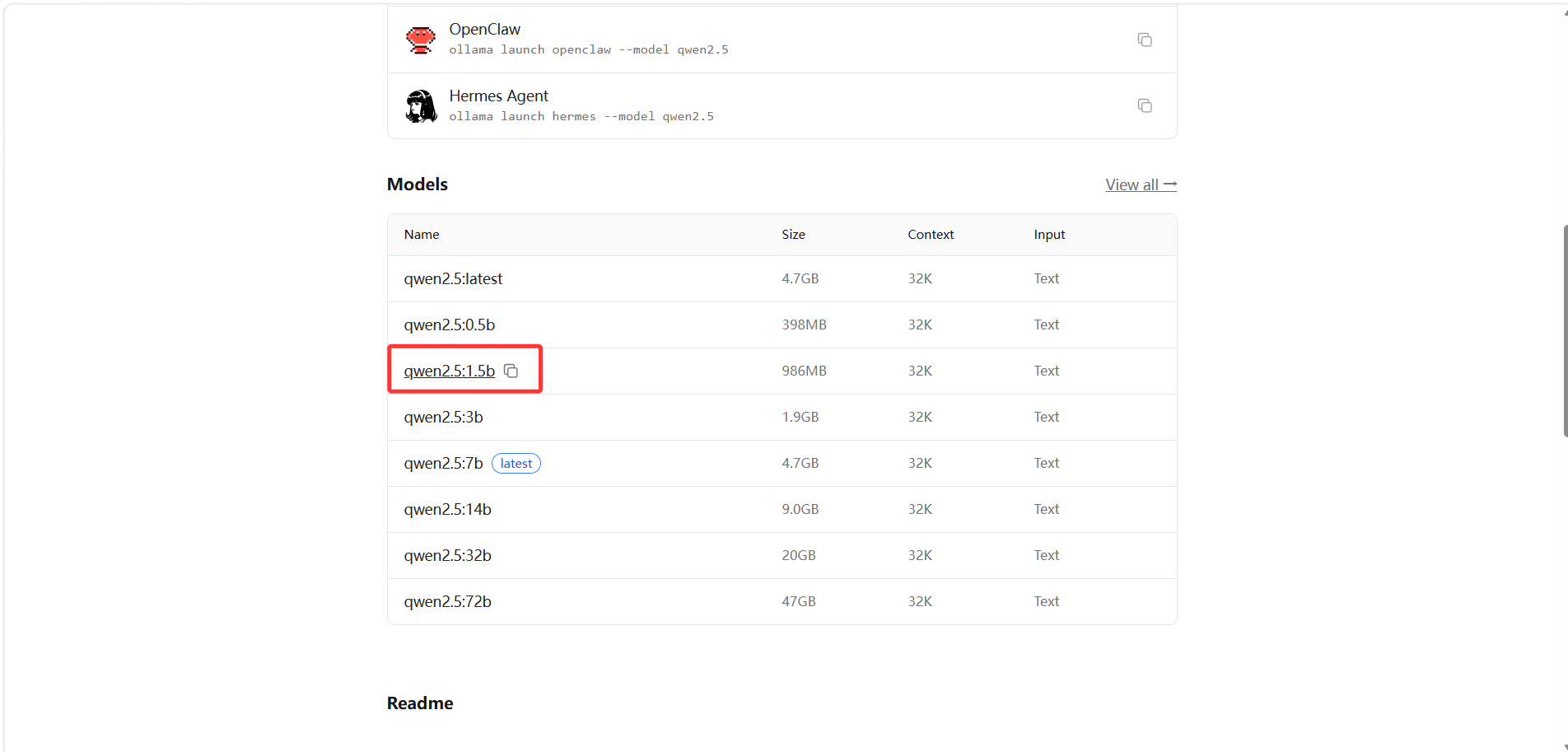
打开 CMD / PowerShell,直接运行:
ollama run qwen2.5:1.5b输入问题即可本地离线对话,无需联网。

二、方案 2:魔搭社区源码部署(可二次开发)
1. 准备工具
- 安装 Git
- 安装 Git LFS(必须,否则大文件下载失败)
- Python 3.8+
2. 魔搭搜索并克隆模型
- 打开魔搭社区:https://modelscope.cn/
- 模型库搜索:
qwen2.5-1.5b-instruct - 复制 Git 地址
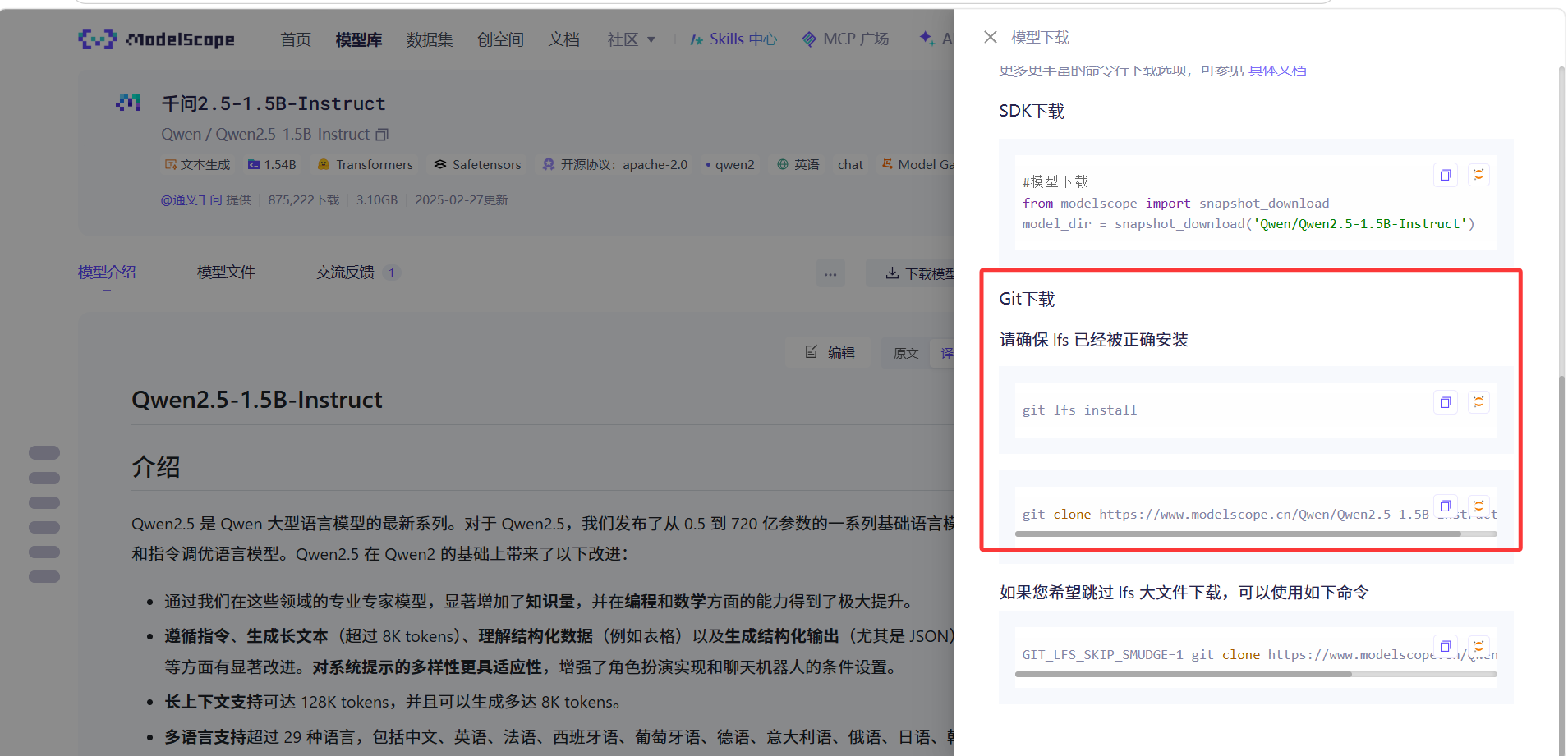
CMD 执行克隆(指定路径):
git clone https://www.modelscope.cn/qwen/Qwen2.5-1.5B-Instruct.git C:\Users\Asus\Qwen2.5-1.5B-Instruct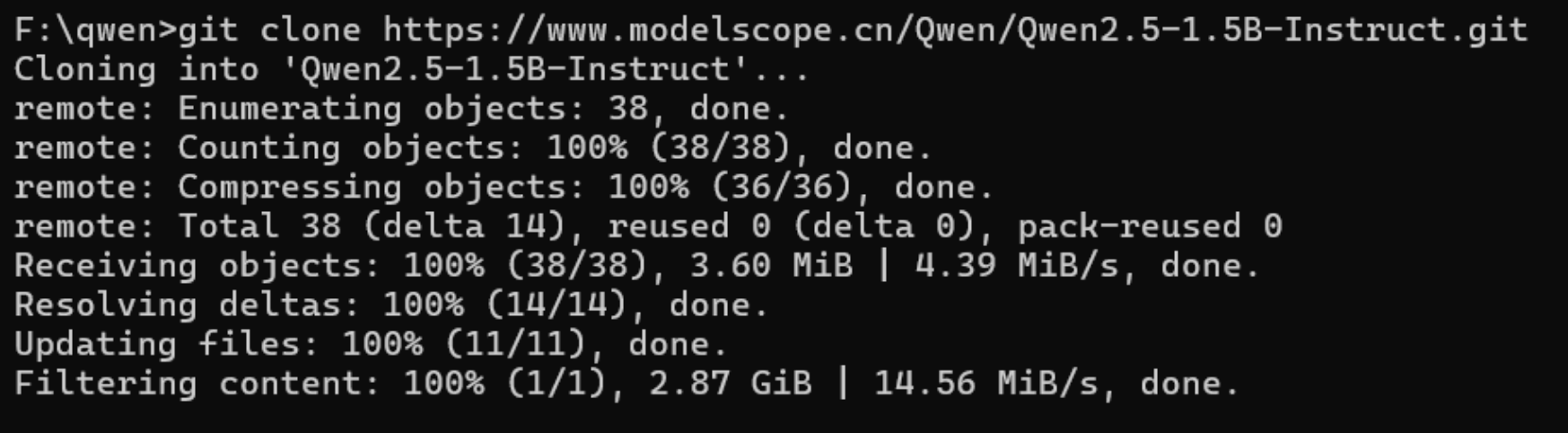
3. 解决 Git 大文件下载问题
Git 默认会忽略大模型权重,必须执行:
cd C:\Users\Asus\Qwen2.5-1.5B-Instruct
git lfs pull
等待拉取完成,模型文件就完整了。
4. 安装 Python 依赖
pip install transformers三、Python 实战:基于 Qwen2.5-1.5B 实现文本情感分类
本文以情感三分类(正面、负面、中立)为实战任务,编写 Python 代码,加载本地 Qwen2.5-1.5B-Instruct 模型,实现对文本的情感判断,代码完整可直接运行。
新建文件:Qwen 文本分类.py复制以下代码:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载本地模型
model_name = r"C:\Users\Asus\Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 分类 Prompt 模板
prompt_template = "请判断以下文本属于哪个类别:{text}。可选类别有:正面、负面、中立。"
input_text = "这部电影真是太差劲,我非常不喜欢!"
prompt_input = prompt_template.format(text=input_text)
# 编码输入
inputs = tokenizer(prompt_input, return_tensors="pt")
# 模型推理
output_sequences = model.generate(
inputs.input_ids,
max_new_tokens=512,
attention_mask=inputs.attention_mask
)
# 解码结果
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
result = generated_text[len(prompt_input):]
print("模型输出:", generated_text)
print("分类结果:", result.strip())四、代码关键说明
- AutoModelForCausalLM:加载生成式大模型结构
- AutoTokenizer:文本分词、编码、解码工具
- Prompt 模板:明确告诉模型要做文本三分类
- generate:生成式推理,控制输出长度
- 截取结果:去掉 Prompt,只保留模型回答
五、运行效果
执行代码后输出:
模型输出:请判断以下文本属于哪个类别:这部电影真是太差劲,我非常不喜欢!。可选类别有:正面、负面、中立。负面
分类结果:负面模型成功判断出负面情感。

六、两种部署方式对比
| 方式 | 难度 | 速度 | 适用场景 |
|---|---|---|---|
| Ollama | 极低 | 极快 | 快速体验、对话、简单调用 |
| 魔搭源码 | 中等 | 灵活 | 二次开发、改代码、训练微调 |
七、总结与拓展
本文完整实现了轻量化大模型本地部署的全流程,从 Ollama 极速体验,到魔搭源码完整下载,再到 Python 文本分类实战,覆盖了新手入门大模型的所有核心步骤。Qwen2.5-1.5B-Instruct 作为轻量级模型,性能强悍,不仅能做情感分类,还能拓展到意图识别、文本摘要、代码生成、问答系统等多种任务。
本地部署大模型的核心优势在于隐私安全、离线可用、低成本、高度自定义,无论是学习大模型原理,还是开发小型 AI 项目,都是绝佳的选择。希望这篇教程能帮助大家顺利入门大模型部署,开启自己的 AI 开发之旅!
后续可以在此基础上,拓展更多功能:比如封装成 Web 界面、批量处理文本数据、结合其他工具实现自动化任务,让轻量化大模型真正服务于我们的学习与工作。