(一).传输层的协议
1.协议的概念
在传输层中,最重要的两个协议,一个是TCP协议 ,另一个是UDP协议
在应用层中,操作系统提供了一组api,用于传输层给应用层提供服务,这组api又叫做socket.api,由于TCP和UDP的差别非常大,在进行代码编写的时候也是不同的风格,所以对于socket.api来说,提供了两套接口。
2.协议的区别
对于TCP来说,是有连接,可靠传输,面向字节流,全双工
对于UDP来说,是无连接,不可靠传输,面向数据报,全双工
(1).有连接 vs 无连接
对于有无连接,事实上是一个抽象的概念,是虚拟的,逻辑上的连接并不是物理上的连接
对于TCP来说,TCP协议中就保存的对端的信息,即A和B进行通信,A和B先建立连接,然后A保存了B的信息,B保存了A的信息,这就是有连接
对于UDP来说,UDP协议本身不保存对方的信息,则就是无连接
(2).可靠传输 vs 不可靠传输
在进行网络传输的过程中,被传输的数据是非常容易造成**"丢包"**的,即如果传输的是"0101"但是在传输的过程中某些bit位就被修改了,这样乱了的数据就会被识别出来,然后将这样的数据给丢弃掉。例如光信号和电信号都是会受到外界的干扰的,或者说在传输过程中,某个时间点,路由器/交换机中实际需要转发的数据超过了设备能转发的上限,此时也会产生"丢包"现象
对于可靠的传输 ,不是保证数据包100%到达,而是尽可能的提高传输成功的效率,如果出现了丢包现象,能被感知到。虽然降低了丢包的概率,但是也是需要付出代价的,就是运行效率比较低
对于不可靠的传输,只是把数据发了,剩下的就不管了
(3).面向字节流 vs 面向数据报
面向字节流,即读取数据的时候,是以"字节"为单位的,支持任意长度,但是会发生"粘包问题",后面会具体介绍
面向数据报,即读写数据的时候,以一个数据报为单位,一次必须读一个UDP数据报,不能是半个,所以读取长度会进行限制,不存在"粘包"问题
(4).全双工 vs 半双工
对于全双工来说,一个通信链路,支持双向通信,既能读也能写
对于半双工来说,一个通信链路,只支持单向通信,要么能读要么能写
(二).UDP数据报套接字编程
1.概念
上面介绍过,操作系统提供了socket.api,我们可以通过socket.api进行网络编程。这是为什么?
这是因为, 对于计算机中的"文件"来说,还能够指代一些硬件设备,操作系统管理硬件设备也是抽象成文件,来进行统一管理的。
对于我们电脑中的网卡来说,就是抽象成了一个socket文件,在进行操作网卡的时候,流程和操作普通文件差不多,即 "打开 -> 读写 -> 关闭",对于直接操作网卡来说,是不好进行操控的,但是将网卡转换成socket文件,那么操作这个socket文件就相当于操作网卡了
2.具体的类
在使用UDP数据报套接字编程的时候,具体用到了两个类,一个类是DatagramSocket ,另一个类是DatagramPacket
3.构造方法
构造方法相当于打开文件
(1).DatagramSocket类
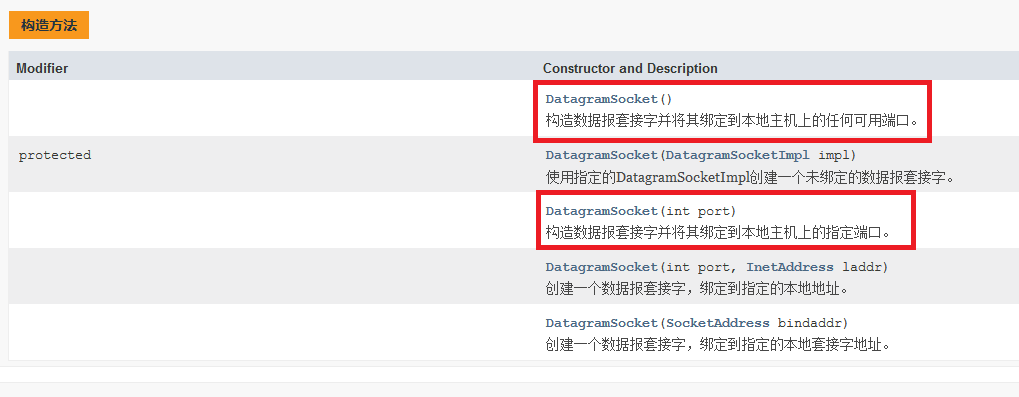
对于不带参数的构造方法,则会随机选择一个端口进行绑定
对于第三个构造方法,则会在创建socket的时候就会关联上一个端口号,使用端口号的目的就是为了区分主机上的不同的应用程序
(2).DatagramPacket类
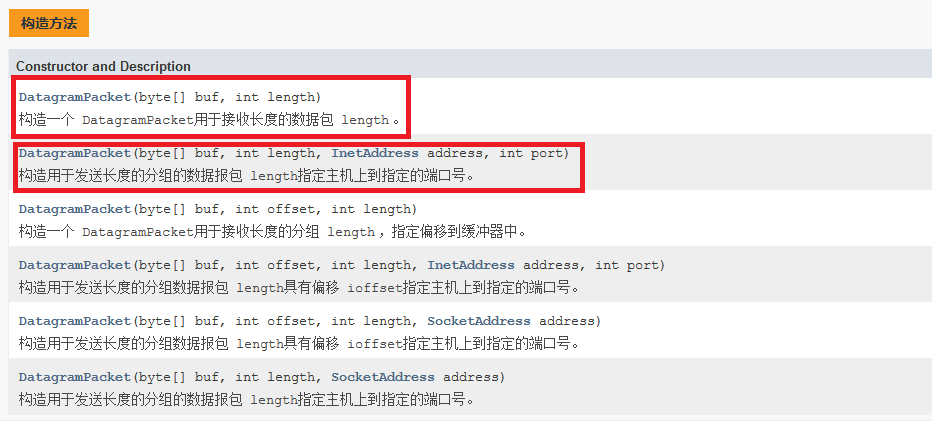
DatagramPacket表示一个完整的UDP数据报,对于UDP数据报的载荷数据,就可以通过构造方法来指定
4.其他方法


receive()方法就是从套接字中接收数据报,如果没有接收到数据报,则会阻塞等待
send()放啊就是从套接字发送数据报,直接发送
可以看到,receive()和send()方法,里面的参数都是一个DatagramPacket引用对象

close()关闭此数据报套接字
5.模拟实现回显服务器和客户端
客户端给放服务器发送一个数据称为"请求",服务器返回一个数据称为"响应"
"回显服务器"就是请求是啥响应就是啥
(1).回显服务器
Ⅰ.创建对象
Ⅱ.写出构造方法
在构造方法中,指定一个端口号,让服务器来使用

Ⅲ.写出主循环
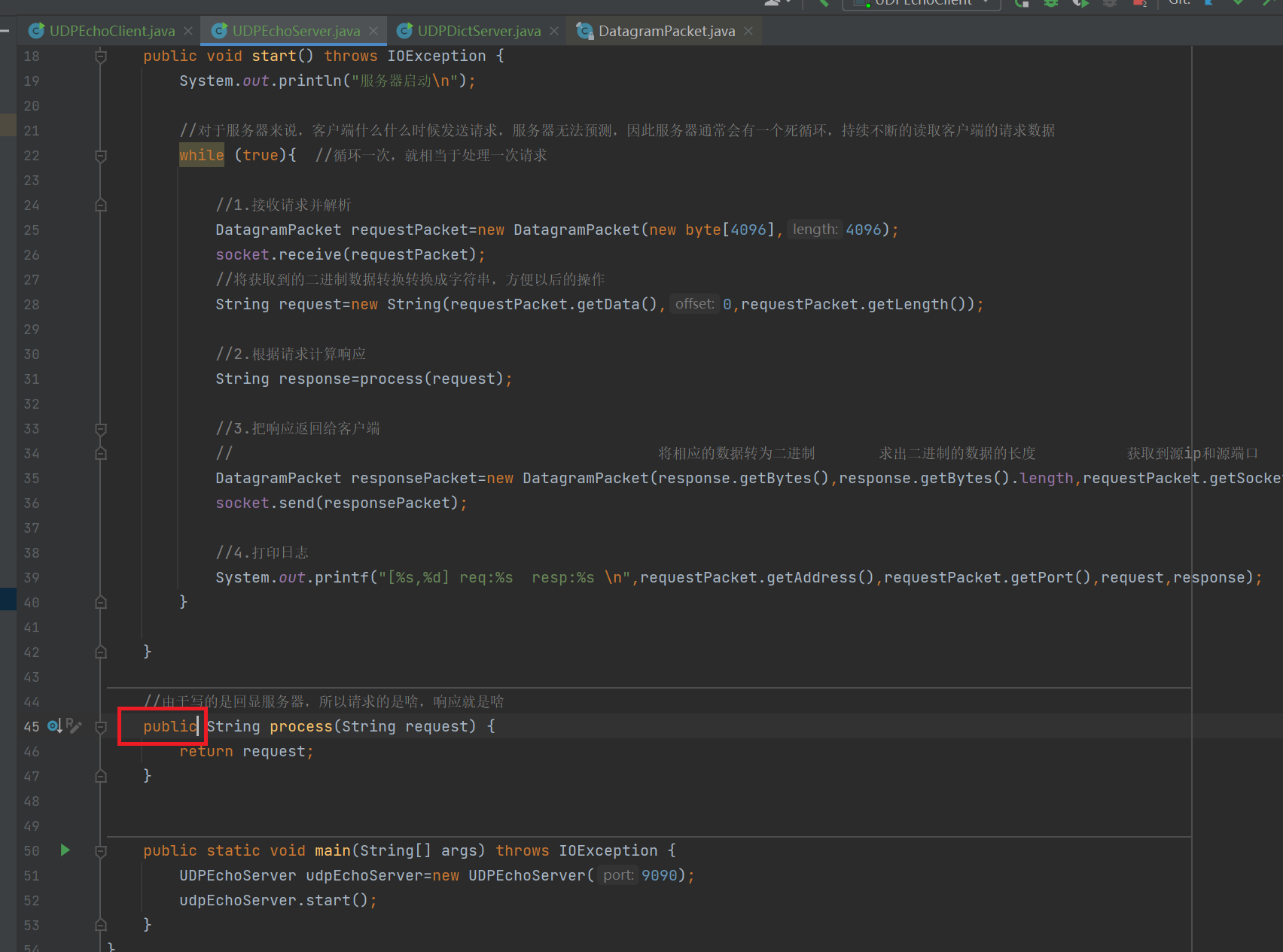
在主循环中,服务器的通常流程为①.接收请求并解析②.根据请求,计算响应③.把响应返回给客户端
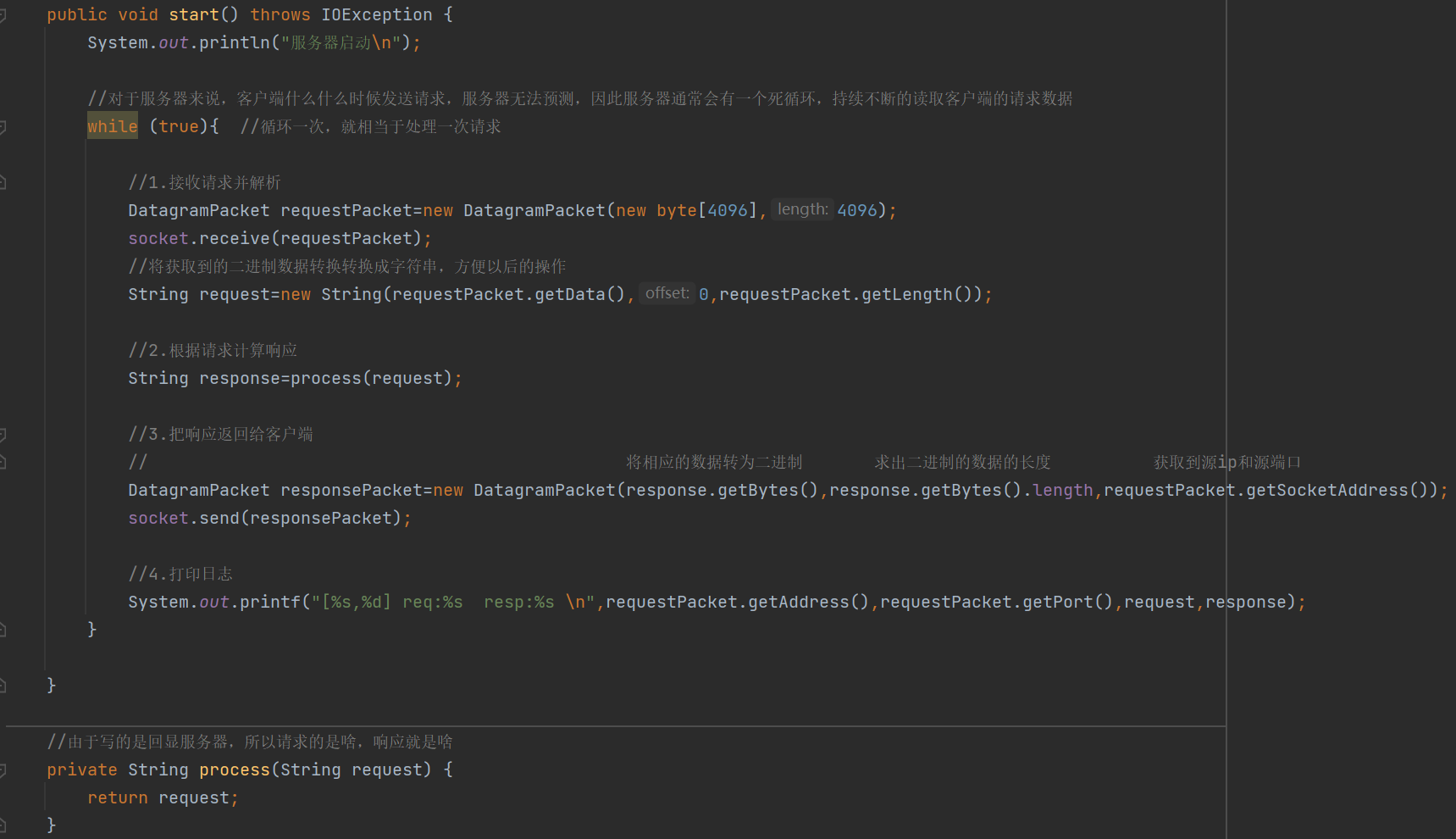
上述代码就是主循环的过程

receive()这个方法,里面的参数requestPacket,其实是一个"输出型参数",receive()方法会将数据从网卡中读取出来,然后填充到参数中,所以我们在执行receive()方法之前,要先构造出一个空的DatagramPacket的对象,然后把这个对象传递到receive()方法的参数中

在进行"把响应返回给客户端"的代码中,我们首先要将响应之后的结果由String类型再转为二进制,然后计算出二进制数据的长度,注意:这里只能用response.getBytes().length,不能使用response.length(),因为二进制数据的长度和String类型的长度是不一样的。
同时,在进行返回客户端的操作的时候,由于UDP协议中并没有保存对方的信息,即目的ip和目的端口,所以在responPacket中要获取到目的ip和目的端口
那么我们应该如何获取?
我们可以想到,客户端在给服务器发送数据的时候,那么这个客户端就相当于源ip和源端口,所以说我们我们要找的目的ip和目的端口就可以从requestPacket中获取到,即服务器应该使用请求中的源ip和源端口作为响应的目的ip和目的端口

当我们点到getSocketAddress()内部中可以看到,它调用的是**InetSocketAddress()**方法来获取到的源ip和源端口
Ⅳ.写出主函数

可以看到,我这里指定的端口是9090
Ⅴ.完整版代码
java
package network;
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.SocketException;
public class UDPEchoServer {
//创建对象
//socket对象代表网卡文件,读这个文件等于从网卡收数据,写这个文件等于让网卡发数据
private DatagramSocket socket=null;
public UDPEchoServer(int port) throws SocketException {
//指定一个端口号,让服务器进行使用
socket=new DatagramSocket(port);
}
public void start() throws IOException {
System.out.println("服务器启动\n");
//对于服务器来说,客户端什么什么时候发送请求,服务器无法预测,因此服务器通常会有一个死循环,持续不断的读取客户端的请求数据
while (true){ //循环一次,就相当于处理一次请求
//1.接收请求并解析
DatagramPacket requestPacket=new DatagramPacket(new byte[4096],4096);
socket.receive(requestPacket);
//将获取到的二进制数据转换转换成字符串,方便以后的操作
String request=new String(requestPacket.getData(),0,requestPacket.getLength());
//2.根据请求计算响应
String response=process(request);
//3.把响应返回给客户端
// 将相应的数据转为二进制 求出二进制的数据的长度 获取到源ip和源端口
DatagramPacket responsePacket=new DatagramPacket(response.getBytes(),response.getBytes().length,requestPacket.getSocketAddress());
socket.send(responsePacket);
//4.打印日志
System.out.printf("[%s,%d] req:%s resp:%s \n",requestPacket.getAddress(),requestPacket.getPort(),request,response);
}
}
//由于写的是回显服务器,所以请求的是啥,响应就是啥
private String process(String request) {
return request;
}
public static void main(String[] args) throws IOException {
UDPEchoServer udpEchoServer=new UDPEchoServer(9090);
udpEchoServer.start();
}
}注意:
①.这里socket文件是不需要关闭的。因为这个socket伴随着整个UTP服务器自始至终,当服务器关闭,那么进程就结束了,此时PCB的文件描述符表中的所有资源就会被释放掉,也就不需要手动调用close()方法了。
②.当服务器启动的之后,客户端还没有发送请求,在客户端发送请求之前,服务器都在receive()方法中进行阻塞等待,只有当客户端请求发来了,receive()才会返回
(2).回显客户端
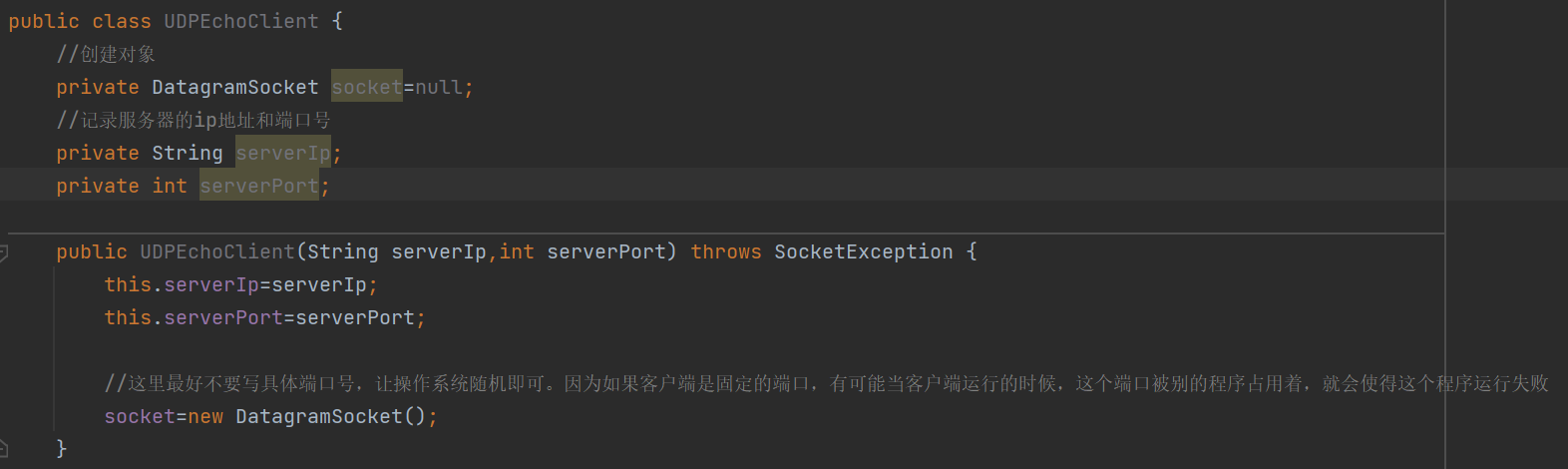
Ⅰ.创建对象
Ⅱ.写出构造方法
对于客户端来说,访问服务器时,要明确要访问的服务器的ip地址和端口号,所以在写构造方法的时候要明确服务器的ip地址和端口号
Ⅲ.写出主循环
在主循环中,客户端的通常流程为①.发送请求②.接收服务器的响应
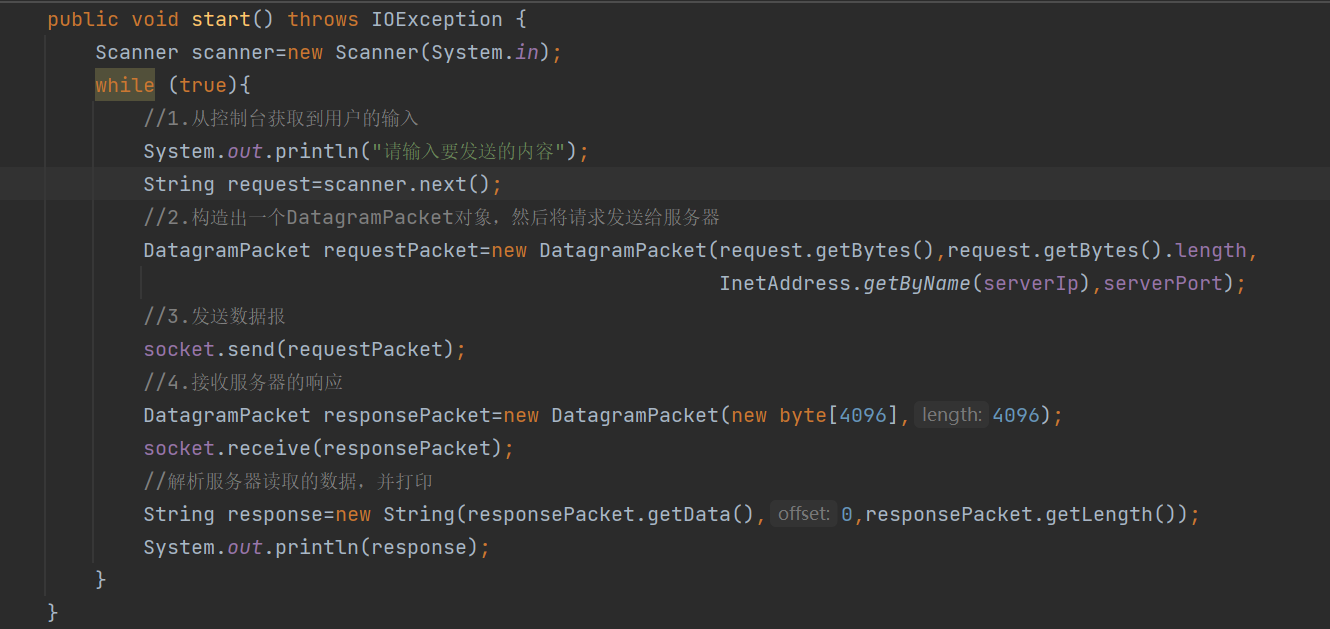
上述就是主循环的代码

这里在构建DatagramPacket对象的时候,要将服务器的ip地址和端口号传进去,但是如果直接传String类型的serverIp的话,是会报错的
这是因为DatagramPacket的构造方法中并没有提供一个直接传递String类型的IP地址的构造方法,所以要用InetAddress.getByName()方法进行封装
Ⅳ.写出主函数

由于是在本机上进行客户端和服务器的传输,所以ip地址直接写本机地址即可,即127.0.0.1(环回ip),端口要和服务器用的端口一样,即9090
Ⅴ.完整版代码
java
package network;
import java.io.IOException;
import java.net.*;
import java.util.Scanner;
public class UdpEchoClient {
private DatagramSocket socket=null;
//记录服务器的ip地址和端口号
private String serverIp;
private int serverPoot;
public UdpEchoClient(String serverIp, int serverPoot) throws SocketException {
this.serverIp = serverIp;
this.serverPoot = serverPoot;
this.socket =new DatagramSocket();
}
public void start() throws IOException {
Scanner scanner=new Scanner(System.in);
while (true){
System.out.println("请输入要发送的内容");
//1.从控制台读取用户输入的内容
if (!scanner.hasNext()){
break;
}
String request=scanner.next();
//2.把请求发送给服务器,需要构造DatagramPacket对象
//在构造的过程中,不光需要载荷,还需要目的服务器的ip地址和端口号 这里需要对serverIp进行转换
DatagramPacket requestPacket=new DatagramPacket(request.getBytes(),request.getBytes().length, InetAddress.getByName(serverIp),serverPoot);
//3.发送数据报
socket.send(requestPacket);
//4.接收服务器的响应
DatagramPacket responsePacket=new DatagramPacket(new byte[4096],4096);
socket.receive(responsePacket);
//5.从服务器读取的数据进行解析,打印出来
String response=new String(responsePacket.getData(),0,responsePacket.getLength());
System.out.println(response);
}
}
public static void main(String[] args) throws IOException {
UdpEchoClient udpEchoClient=new UdpEchoClient("127.0.0.1",9090);
udpEchoClient.start();
}
}注意:
这里socket文件是不需要关闭的。因为这个socket伴随着整个UTP客户端自始至终,当客户端关闭,那么进程就结束了,此时PCB的文件描述符表中的所有资源就会被释放掉,也就不需要手动调用close()方法了。
(3).程序运行结果
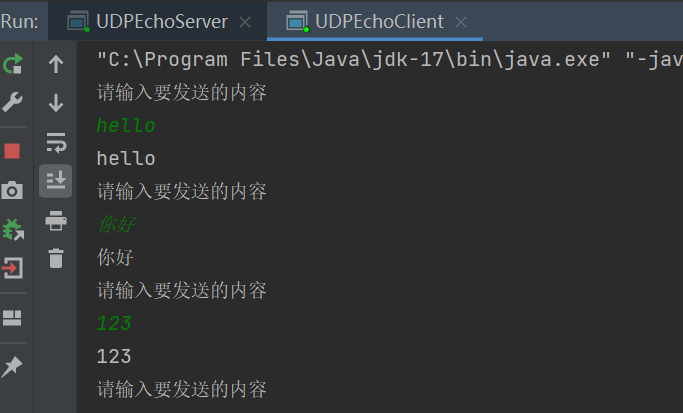
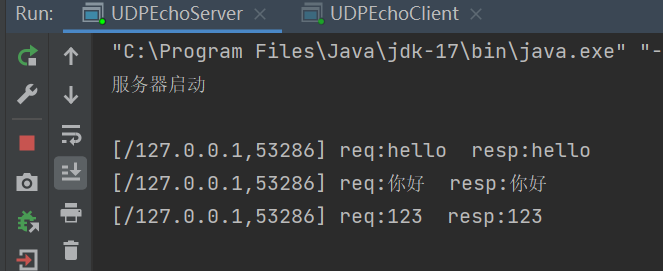
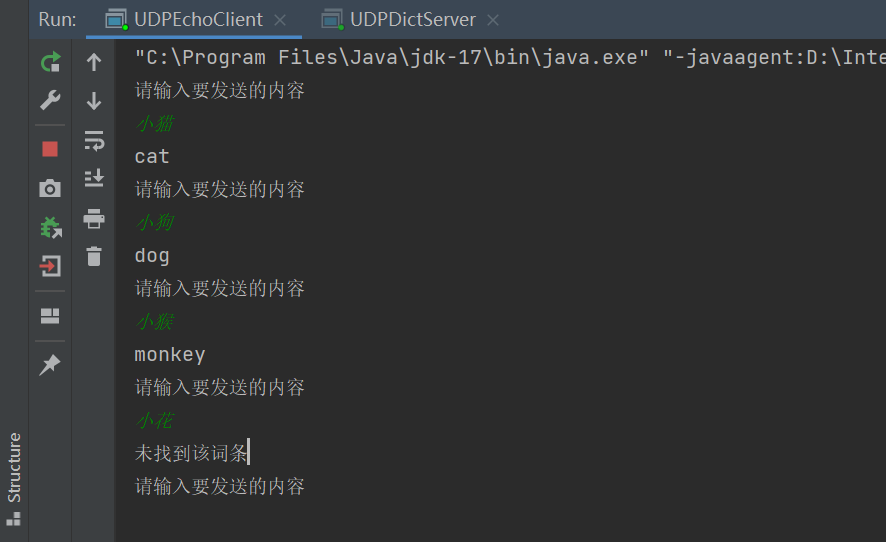
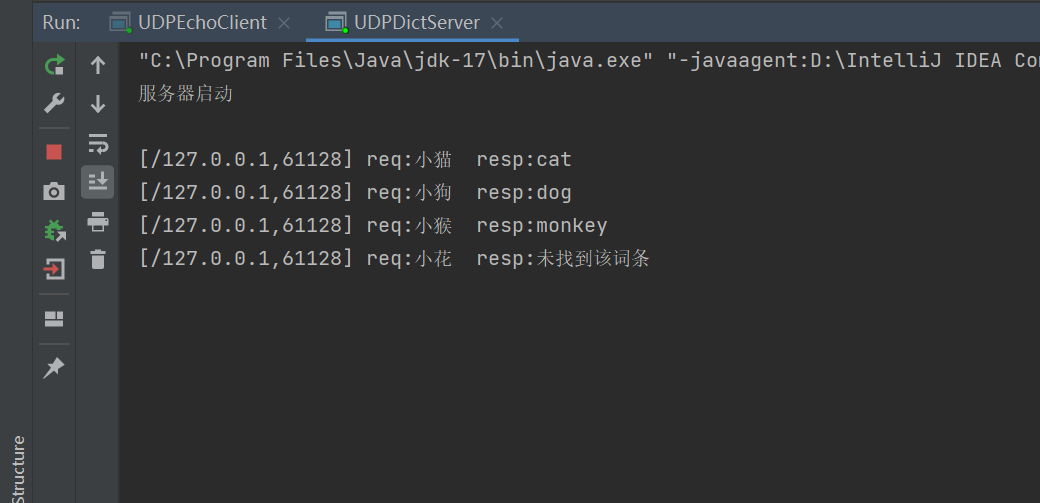
6.模拟实现翻译服务器和客户端
对于不同服务器来说,不同的往往就是业务逻辑不同,上面写的回显服务器,客户端发来什么内容,那么服务器就返回什么内容。现在要写的这个翻译服务器,无非就是客户端发来汉语,服务器返回英语即可,所以只需要修改**process()**方法即可
那么我们对于这个翻译服务器来说,只需要继承回显服务器然后重写里面的process()方法即可,其他的基本没有改变
java
package network;
import java.io.IOException;
import java.net.SocketException;
import java.util.HashMap;
public class UDPDictServer extends UDPEchoServer{
public HashMap<String,String> hashMap=new HashMap<>();
public UDPDictServer(int port) throws SocketException {
super(port);
//初始化字典
hashMap.put("小猫","cat");
hashMap.put("小狗","dog");
hashMap.put("小鱼","fish");
hashMap.put("小猴","monkey");
hashMap.put("小虎","tiger");
}
public String process(String request){
return hashMap.getOrDefault(request,"未找到该词条");
}
public static void main(String[] args) throws IOException {
UDPDictServer udpDictServer=new UDPDictServer(9090);
udpDictServer.start();
}
}同时注意,在重写process()方法的时候,要将父类的process()方法的访问修饰限定符修改为public,如果父类的方法是私有的,那么子类是无法进行重写的