YOLOv2 在 v1 的基础上引入了 BatchNorm、高分辨率分类器、Anchor Box、K-means 聚类先验框、直接位置预测、细粒度特征与多尺度训练等多项关键改进,彻底解决了 v1 在小目标检测和定位精度方面的痛点。本文逐层拆解 YOLOv2 的设计细节与实现逻辑,带你系统掌握这款经典实时检测器。
一、YOLO系列v2
YOLOv2(又称 YOLO9000)是 YOLO 系列的第二代版本,由 Joseph Redmon 和 Ali Farhadi 于 2016 年提出。它在 YOLOv1 的基础上引入了 BatchNorm、高分辨率分类器、Anchor Box、聚类先验框等一系列改进措施,并在保持实时性的前提下大幅提升了检测精度。
1、YOLO v1与v2对比
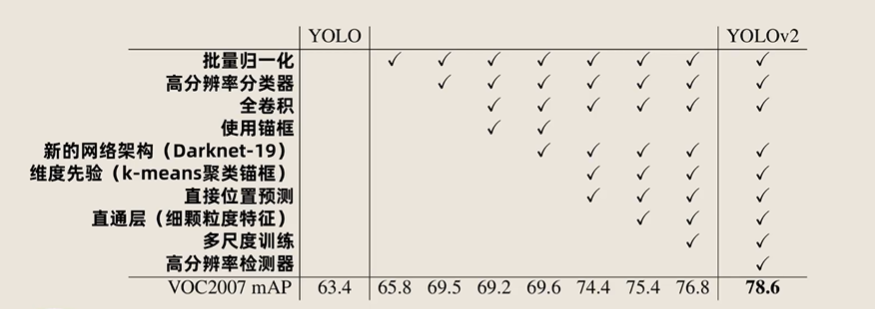
与 YOLOv1 相比,YOLOv2 的主要改进点如下:
| 改进点 | YOLOv1 | YOLOv2 |
|---|---|---|
| 归一化方法 | ❌ 无 | ✅ BatchNorm(每层卷积后都接) |
| 分类器分辨率 | 224×224(预训练) | 448×448(预训练 + 微调) |
| 骨干网络 | GoogLeNet | DarkNet-19 |
| 全连接层 | ✅ 有 | ❌ 无(全卷积) |
| 先验框生成 | 手动设置的 2 个 | K-means 聚类生成的 5 个 |
| 多尺度训练 | ❌ 不支持 | ✅ 支持(320~608) |
| 细粒度特征 | ❌ 无 | ✅ 拼接浅层特征(26×26) |
2、BatchNorm批次归一化
Batch Normalization(批次归一化)是 YOLOv2 引入的第一个重要改进。具体操作是在每个卷积层之后、激活函数之前加入 BatchNorm 层,对网络每一层的输入进行归一化处理,使其均值为 0、方差为 1。
BatchNorm 带来的三大收益:
-
大幅提升收敛速度:归一化后的数据分布更加稳定,可以使用更大的学习率来加速训练
-
起到正则化作用 :BatchNorm 引入了轻微的噪声,能够替代 Dropout ,因此在 YOLOv2 中舍弃了 Dropout
-
提升检测精度 :引入 BatchNorm 后,YOLOv2 的 mAP 提升了约 2%
如今,BatchNorm 已是绝大多数计算机视觉模型的标准配置,但它的开创性应用最早正是在 YOLOv2 中得以验证。

3、YOLO v2 更大的分辨率
在 YOLOv1 中,训练时的输入分辨率为 224×224 ,而测试时却需要用 448×448。这种训练与测试分辨率的不一致,会导致模型在测试时产生不适应(即所谓的"水土不服"),从而影响检测效果。
YOLOv2 对此进行了彻底改进,分两步走:
| 阶段 | 分辨率 | 说明 |
|---|---|---|
| 预训练 | 224×224 | 先在 ImageNet 上训练分类网络(约 160 轮) |
| 微调 | 448×448 | 再以 448×448 的分辨率微调 10 轮,让模型适应高分辨率输入 |
这种"高分辨率分类器微调 "的策略,使得 YOLOv2 的 mAP 相较于 v1 提升了约 4%。简单来说,这一步改进让模型在训练阶段就适应了高分辨率输入,避免训练与测试的割裂。

4、YOLO v2网络结构
1)YOLO v2网络结构
YOLOv2 不再沿用 YOLOv1 的 GoogLeNet 结构,而是设计了全新的 DarkNet-19 骨干网络。该网络借鉴了 VGG 的思想,大量使用 3×3 卷积核,并在每个卷积层后都接入 BatchNorm 层。

关键参数:
-
输入尺寸 :416×416(而不是 YOLOv1 的 448×448)
-
降采样次数:5 次(每次步长为 2)
-
最终特征图尺寸:13×13(416 ÷ 2⁵ = 13)
-
全连接层 :全部移除 ,网络为全卷积结构
为什么输入是 416×416? 因为经过 5 次降采样后,特征图的尺寸为 13×13。13 是奇数,使得最终的特征图有一个唯一的中心单元格。这对于检测占据图像中心的大目标非常有利,因为大目标的中心点往往落在中心网格内。
2)传统的卷积神经网络系统
为了更好地理解 YOLOv2 设计全卷积网络的意义,我们先回顾传统 CNN 架构:
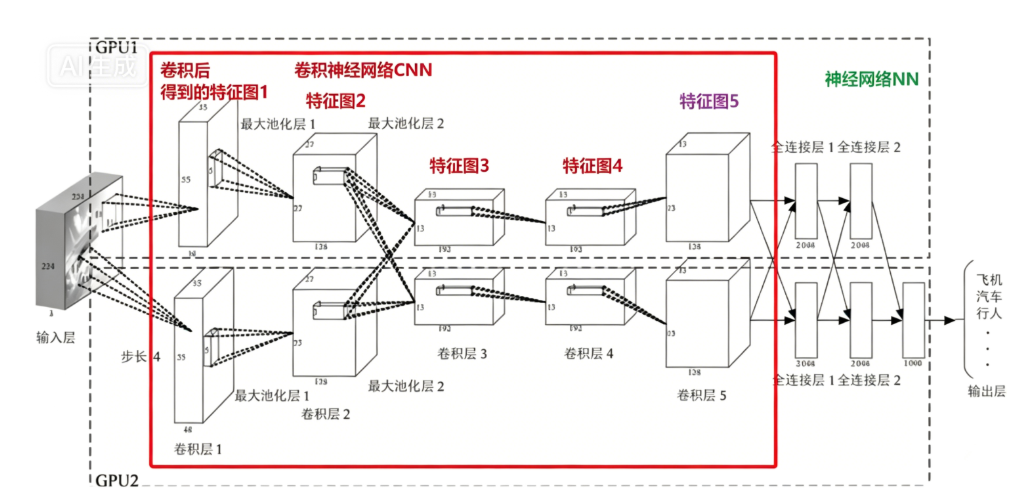
在传统的卷积神经网络中(如 AlexNet、VGG),网络最后通常会接入全连接层。假设某分类网络的卷积部分输出特征图尺寸为 13×13×128,接着将其展平后送入全连接层,得到 2048 个输出。
此时,全连接层的权重参数数量 为:13×13×128 × 2048 ≈ 4425 万。这是一个非常庞大的数字。
关键问题:如果输入图片的大小发生变化,全连接层的权重数量会随之改变,无法复用。这就是传统 CNN 无法接受任意尺寸输入的根本原因。
3)YOLO v2结构局限性
YOLOv2 采用全卷积结构,并在最后使用全局平均池化(Global Avg Pooling) 来替代全连接层。无论输入特征图的尺寸是多少,全局平均池化都会将其压缩为一个固定长度的向量,从而支持多尺度输入。
注意局限 :由于网络进行了 5 次步长为 2 的降采样(2⁵ = 32),因此输入图片的尺寸必须能被 32 整除。这是 YOLOv2 多尺度输入的最小约束条件。
5、YOLO v2聚类提取先验框
YOLOv1 中每个网格只有 2 个固定大小的先验框,这种粗放的设计难以适应不同尺度和形状的目标。
YOLOv2 参考 Faster R-CNN 中 Anchor 的设计思路,将先验框的数量增加到 5 个 ,但并没有像 Faster R-CNN 那样手动设置 9 种长宽比,而是通过 K-means 聚类算法,从训练数据集的所有真实标注框中自动学习出 5 种最具代表性的先验框尺寸。
1)k-means聚类
K-means 聚类是一种经典的无监督学习算法,能够将数据点划分为 K 个簇,使得同一簇内的数据点彼此相似,不同簇之间的数据点差异较大。
YOLOv2 中的距离度量:
传统 K-means 通常使用欧氏距离 来衡量数据点之间的差异。但在 YOLOv2 中,我们关心的是预测框与真实框之间的重叠程度,而不是它们中心点的绝对距离。因此,YOLOv2 将聚类距离函数定义为:
d(box, centroid) = 1 - IOU(box, centroid)这个设计的精妙之处在于:
-
IOU 越大,说明两个框重叠程度越高,距离越小
-
聚类出的先验框与真实框的 IOU 更高,更利于模型学习
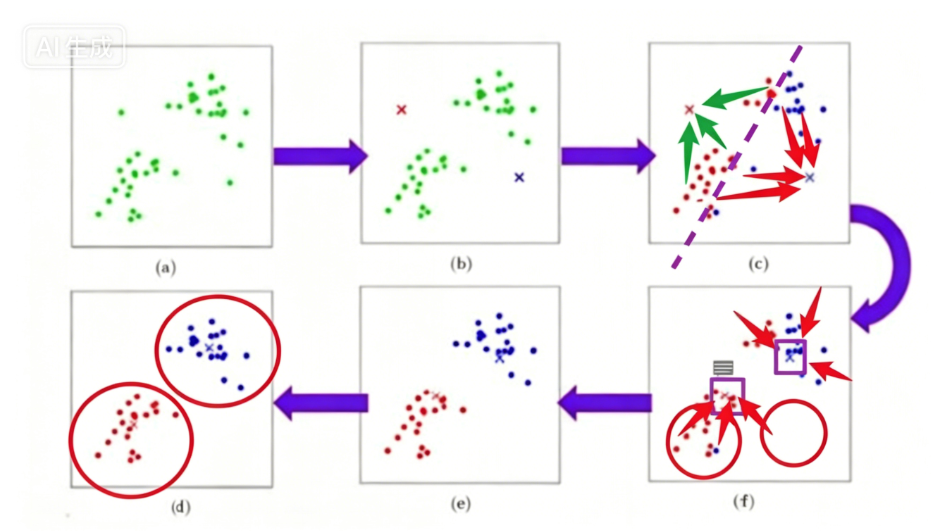
2)YOLO v2聚类流程
YOLOv2 聚类提取先验框的整体流程如下:
-
数据准备:从训练集中提取所有真实标注框,记录每个框的宽度 w 和高度 h,形成一个二维坐标点集合
-
执行 K-means:使用上述距离公式,将所有标注框聚为 K 个簇(实验中 K 取 5)
-
计算聚类中心:对每个簇内的所有框的宽高取平均值,得到 K 个簇中心点
-
得出先验框:将这 K 个聚类中心作为先验框的尺寸,用于后续的 Anchor Box 机制
3)YOLO v2聚类框个数由来
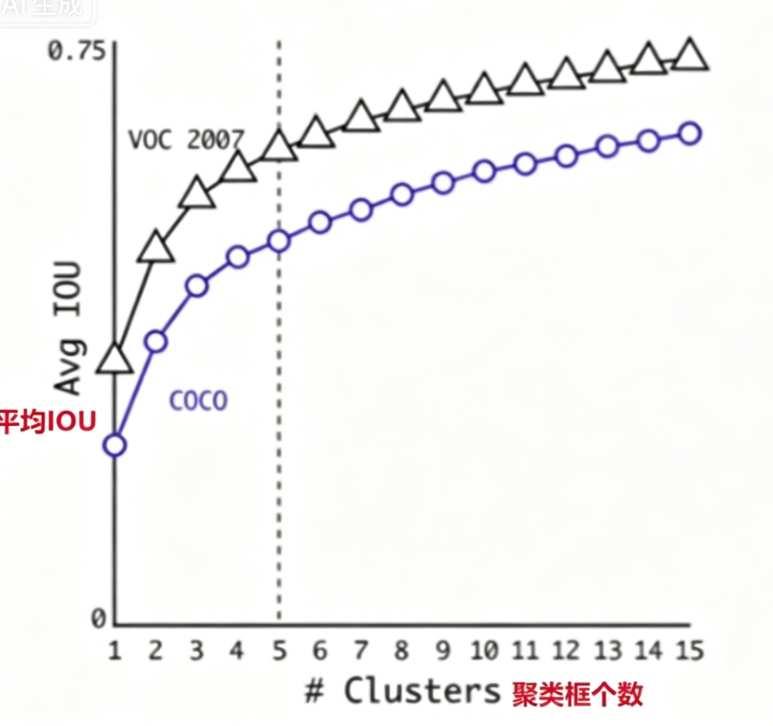
YOLOv2 最终选择了 5 个先验框。这个数字并非随意拍板,而是基于以下考虑:
| 先验框数量 | IOU 表现 | 计算开销 |
|---|---|---|
| 2~3 | 较低(不能很好地覆盖各种目标形状) | 小 |
| 5 | 平衡(覆盖大多数目标,且聚类 IOU 接近 9 个框) | 适中 |
| 9 | 最好(如 Faster R-CNN) | 大 |
选择 5 个是在"召回率"和"计算效率"之间做的一个精巧的平衡------既能够覆盖常见的目标形状,又不会带来过多的计算负担。
6、YOLO v2 Anchor Box聚类先验框
引入聚类先验框后,YOLOv2 预测的边界框总数大幅增加:
-
YOLOv1 :7×7×2 = 98 个
-
YOLOv2 :13×13×5 = 845 个
这意味着 YOLOv2 对每个图像区域提供了更密集的候选框覆盖,显著提升了对小目标和重叠目标的检测能力。

二、Directed Location Prediction直接位置预测
1、概念
在引入 Anchor Box 机制后,如何稳定地预测边界框的位置成为了一个新的挑战。如果预测的偏移量过大,边界框的位置很容易偏离目标位置,导致训练发散或产生大量的"无效框"。
Directed Location Prediction(直接位置预测) 是 YOLOv2 提出的一种解决方案。它与传统 Anchor Box 的偏移预测方式不同,通过 sigmoid 函数将预测偏移量约束在有限的范围内,使得预测框的中心点始终落在一个特定的网格内,从而大大提升了训练的稳定性。
2、计算
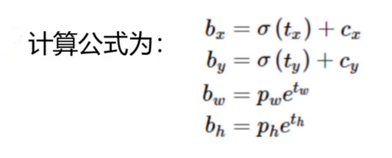
YOLOv2 的位置预测公式如上图所示,符号含义如下:
| 符号 | 含义 |
|---|---|
| t_x, t_y, t_w, t_h | 网络直接输出的原始坐标值(未经约束) |
| b_x, b_y, b_w, b_h | 经过约束计算后得到的最终预测框坐标 |
| c_x, c_y | 预测框所属网格的左上角坐标(即网格的位置编号) |
| p_w, p_h | 聚类先验框的宽度和高度 |
| σ | sigmoid 函数,将输入值压缩到 0, 1 区间 |
为什么要使用 sigmoid 函数?
网络输出的 t_x 和 t_y 可能会产生较大的数值,直接作为偏移量会导致预测框的中心点飘移到其他网格,造成收敛困难。通过 sigmoid 函数,我们将 t_x 和 t_y 的值映射到 (0, 1) 区间,然后再加上网格的左上角坐标 c_x、c_y,从而确保 预测框的中心点被强行约束在当前网格的范围内。
这种设计大大降低了训练的难度,也使得模型更容易收敛。
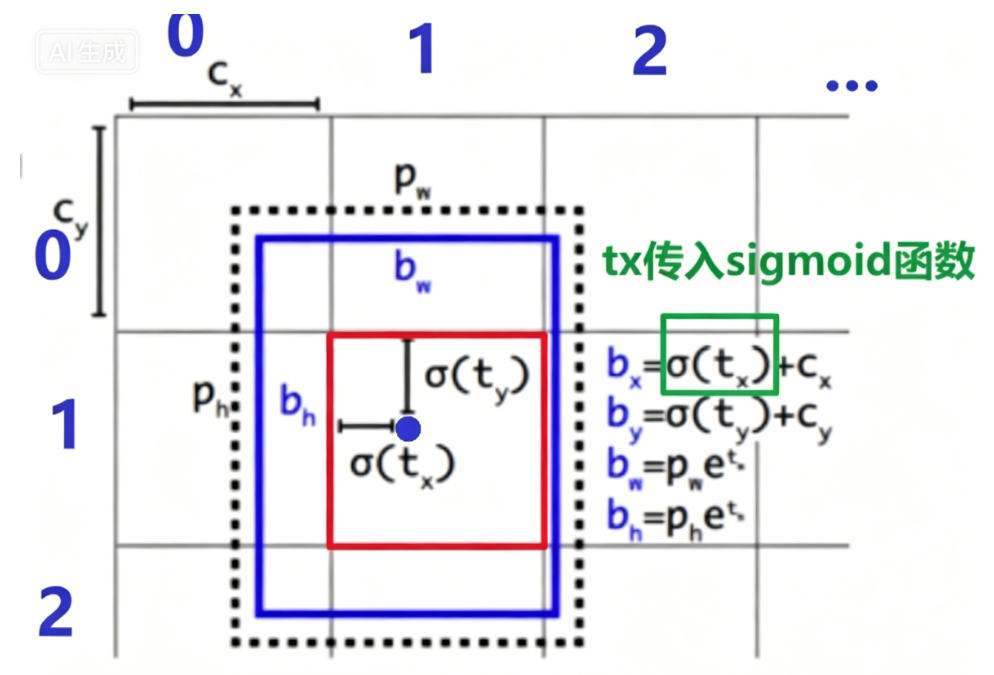
示例计算:

三、感受野
1、概念
感受野(Receptive Field) 指的是卷积神经网络中,特征图上的一个像素点,在原始输入图像中所对应的感知区域大小。
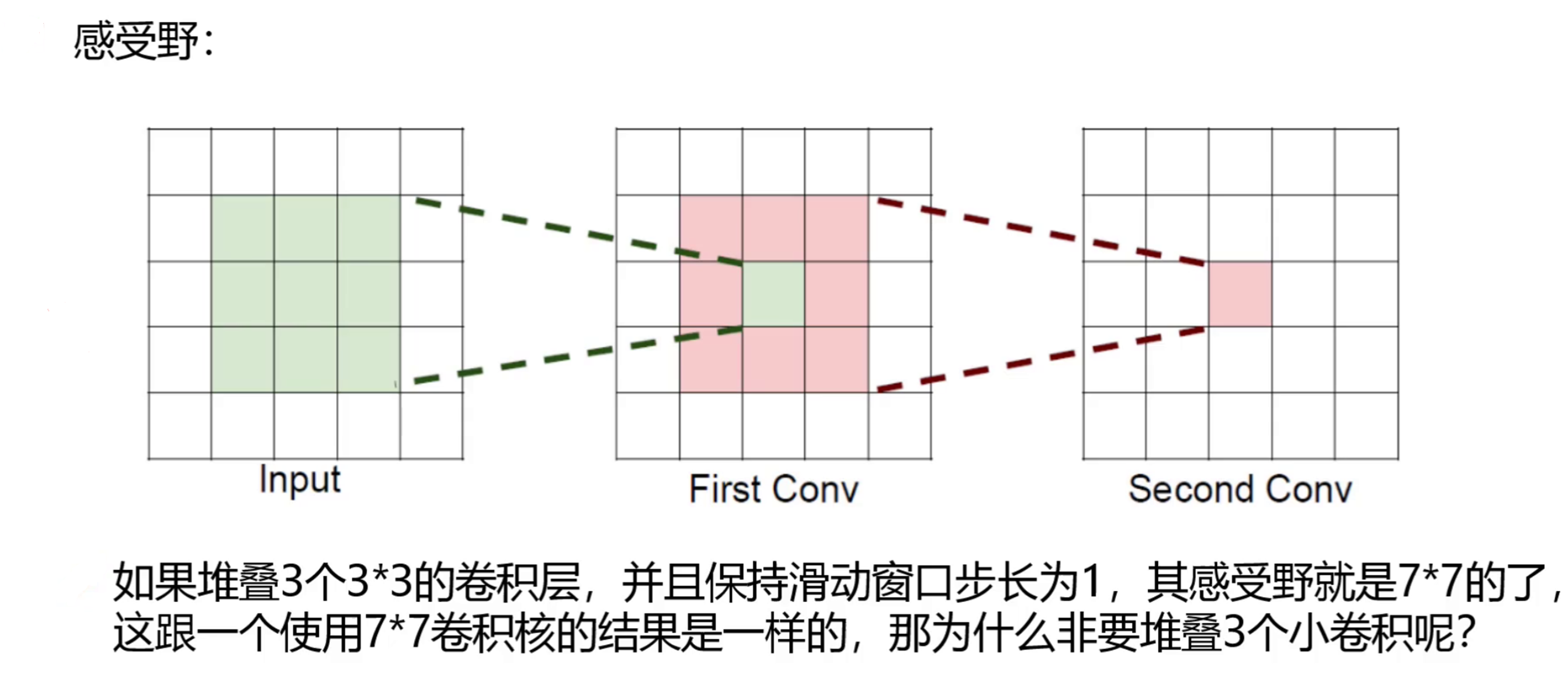

越靠近输入层的特征图,感受野越小,看到的是图像的局部细节;越靠近输出层的特征图,感受野越大,看到的是图像更大范围的上下文信息。
2、作用
感受野对于目标检测任务至关重要,它直接影响了网络对物体位置和大小的判断能力:
| 网络层次 | 感受野大小 | 擅长检测的目标 |
|---|---|---|
| 浅层 | 小 | 边缘、纹理、小物体 |
| 深层 | 大 | 物体整体、大物体、上下文 |
在 YOLOv2 中,随着卷积层和池化层的不断堆叠,特征图的尺寸逐渐减小,感受野逐渐增大。较大的感受野有助于网络捕捉更大范围的语义信息,但同时也可能导致小目标的特征被"稀释"而丢失。
YOLOv1 对小目标检测效果差的根本原因之一,正是其最终特征图的感受野过大,缺乏来自浅层网络的细粒度特征。
3、YOLO v2 Fine Grained Feature
为了解决感受野过大导致小目标丢失的问题,YOLOv2 引入了细粒度特征(Fine Grained Features) 机制。
操作流程如下:
-
在网络中间的某个位置(具体是 26×26×512 的特征图),额外复制一份特征图
-
将这一特征图按照空间位置进行拆分和重新排列,形成一个 13×13×2048 的特征图
-
将该特征图与最后输出的 13×13×1024 特征图拼接,得到 13×13×3072 的融合特征图
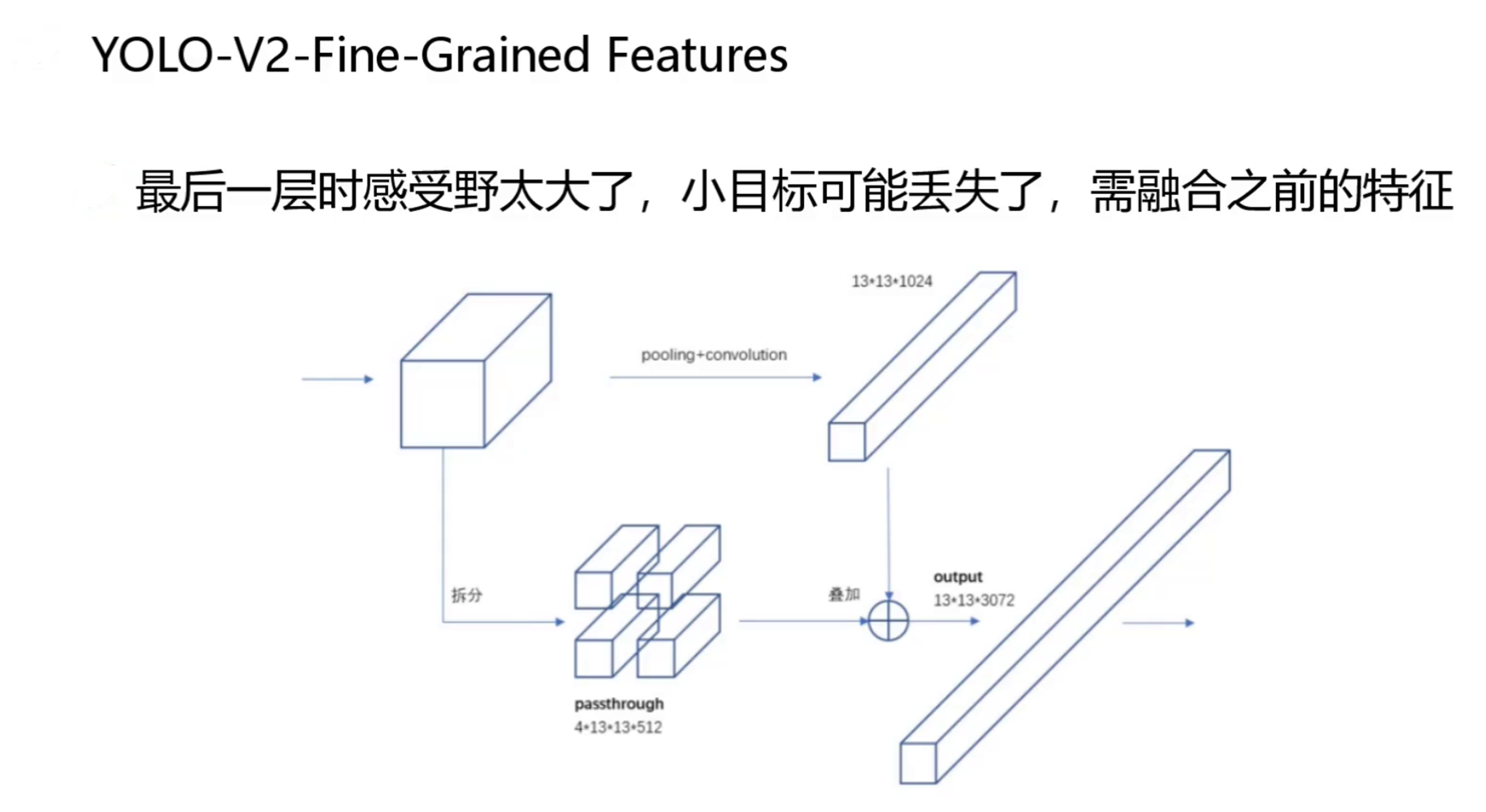
这种"跨层连接"的思路与后来流行的 FPN(特征金字塔网络)有异曲同工之妙。通过将浅层的细粒度信息与深层的语义信息相结合,YOLOv2 对小目标的检测能力得到了显著增强。
4、YOLO-V2-Multi-Scale多尺度融合
由于 YOLOv2 是全卷积网络,不含全连接层,因此它可以接受不同尺寸的输入图像。
-
最小输入尺寸:320×320(速度优先)
-
最大输入尺寸:608×608(精度优先)
-
步长约束 :输入尺寸必须能被 32 整除
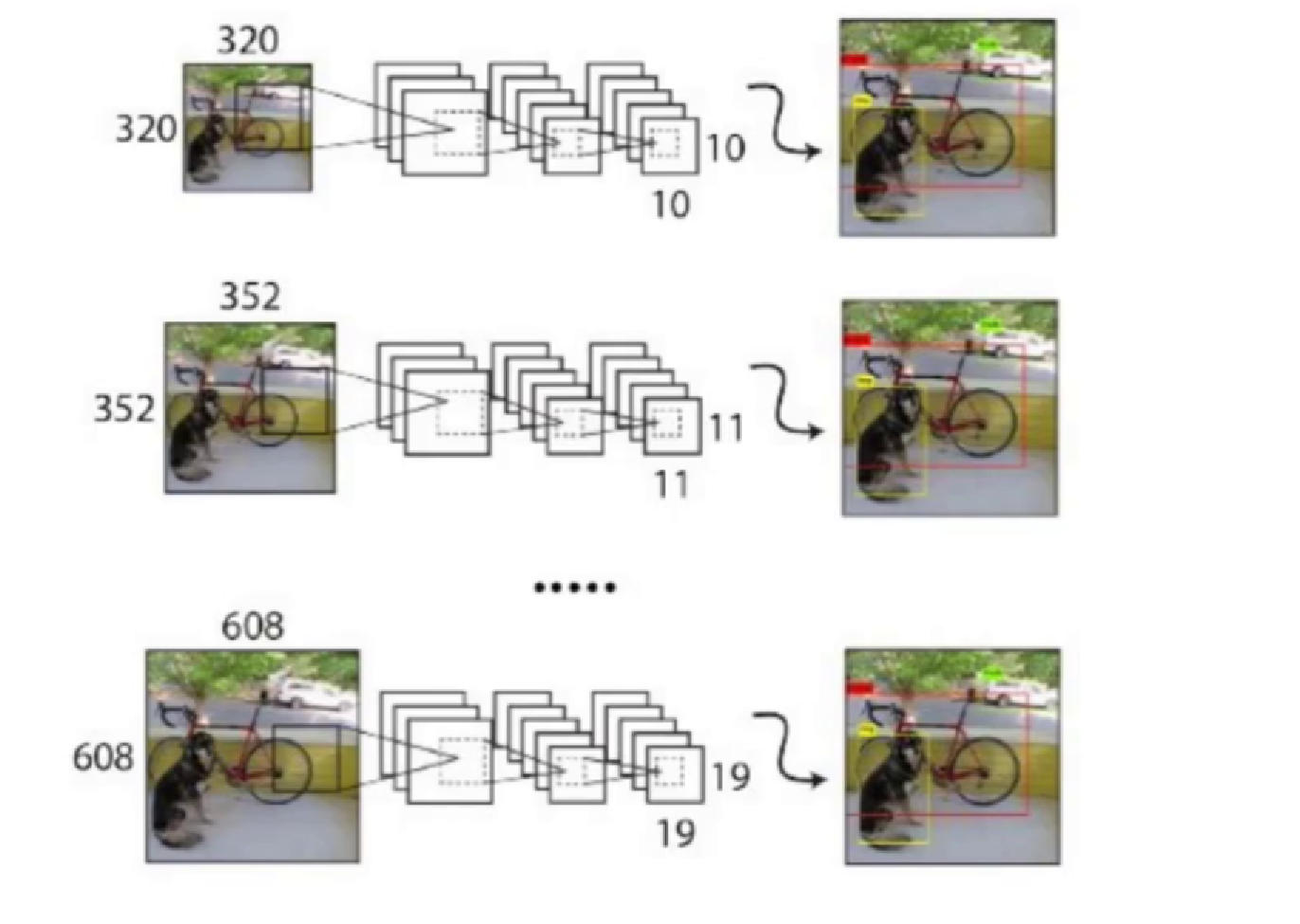
在训练过程中,YOLOv2 采用了多尺度训练策略:每经过 10 个批次(batch),网络会随机从 {320, 352, 384, ..., 608} 中选择一个新的输入尺寸进行训练。
这种策略的好处是:
-
增强模型的尺度不变性:使模型能更好地适应不同大小的目标
-
支持灵活部署:可以根据实际应用场景,在速度和精度之间做权衡
-
提高泛化能力:避免模型过拟合到单一尺度
总结
YOLOv2 的重要性常常被低估。它不仅是 YOLOv1 到 YOLOv3 之间的过渡产品,更是一系列经典技术的集成者:BatchNorm 的应用、高分辨率分类器的微调、聚类先验框的引入、直接位置预测的约束以及多尺度训练策略,这些思路中的许多已经成为现代目标检测算法的标准配置。
理解 YOLOv2 的设计选择,能够帮助你更深刻地理解"什么是一个好的 Anchor Box""如何平衡感受野与分辨率""怎样设计一个兼顾速度和精度的骨干网络"等核心问题。
如果您对 YOLO 系列后续版本(YOLOv3、v4、v5 乃至 v8/v9/v10)感兴趣,欢迎持续关注本专栏,我们下期再见!