一、知识融合(Knowledge Fusion)
-
知识融合,简单理解是将来自不同来源、格式、结构的异构数据统一整合到一个一致的知识图谱中,在这个过程中,这一过程中,主要解决以下问题:
- 消除冗余:多个来源可能描述相同的实体或关系,知识融合要消除重复项,并确保图谱的精简性。
- 统一表达:不同来源中的实体可能使用不同的名称、格式或结构表示相同的概念或关系,融合需要将它们统一为一致的表示方式。
- 解决冲突:不同数据源对同一个实体或关系的描述可能存在冲突,知识融合需要在这些冲突中找到一致性,或通过可信度评估决定保留哪个版本。
- 知识扩展:融合过程可以从多个来源中挖掘新知识,丰富知识图谱的内容,提升知识的全面性和完整性。
-
主要关键技术包含指代消解、实体消歧(实体链接)、实体统一(实体对齐)、关系对齐等。
- 指代消解(Coreference Resolution)
- 一般在语言学及我们日常用语当中,在下文采用简称或代称来代替上文已经出现的某一词语,语言学中把这种情况称为"指代现象",也即是指代。指代现象能够避免同一词语重复出现所造成的语句臃肿、赘述等问题;但也因为这种省略造成"指代不明"的问题。形式上,将代表同一实体(Entity)的不同指称(Mention)划分到一个等价集合的过程称为指代消解。
- 作用:确保数据一致性,避免在图谱中生成溶于或者矛盾的节点。
- 实体消歧(Entity Disambiguation)
- 实体消歧是指根据上下文信息来解决同一名称可能指代多个不同对象的问题,也就是解决"一词多义"的问题!其主要目标是确定文本中提到的具体对象,以消除歧义。
- 作用:将不同来源的相同实体合并,避免在知识图谱中生成重复的节点;确保同一实体在不同上下文中的一致性,提高数据质量。
- 实体统一(Entity Normalization)
- 实体统一是指判断多个实体是不是属于一个实体,目的是将来自不同数据源中的同一实体进行识别和合并。
- 作用:确保在知识图谱中同一实体仅有一个表示。
- 关系对齐(Relation Alignment)
- 不同数据源可能使用不同的方式描述相同的关系,关系对齐的目的:将不同数据源中表示相同的关系进行对齐和融合。
- 作用:避免在知识图谱中相同关系间数据重复。
- 指代消解(Coreference Resolution)
小结:
(1)什么是知识融合?
知识融合,简单理解是将来自不同来源、格式、结构的异构数据统一整合到一个一致的知识图谱中。
(2)主要有哪些问题?
消除冗余:有重复的spo三元组,需要去重
- 去重的方式:使用python进行数据清洗、借助图数据库
统一表达:不同名称的实体或关系,但表示的意思相同,需要统一。如鲁迅和周树人是同一人、父亲和爸爸是同一关系
- 实体消歧、实体统一、关系对齐
解决冲突:同一个实体或关系的描述可能存在冲突,需要找到一致性或保留一个。如 张三-籍贯-河北 与 张三-籍贯-北京 冲突
- 找到一致性、可信度评估
知识扩展:挖掘新知识,丰富知识图谱
- 处理更多的语料,从而获取更多的三元组数据;可以查阅相关的资料,获取更多的信息,直接补充到知识图谱中。
(3)主要的技术有哪些?
指代消解、实体消歧(实体链接)、实体统一(实体对齐)、关系对齐
- 其中指代消解指的是将代词替换成实际的名词。
拓展:企业级知识融合流程图
三元组抽取
↓
数据预处理
├─ 数据清洗(去重、格式统一)
├─ 实体标准化(名称、编码)
└─ 属性规范化(格式、单位)
↓
实体消歧与对齐
├─ 候选实体生成(阻塞/索引)
├─ 相似度计算(字符串、上下文、属性)
├─ 判别模型/规则
└─ 实体聚合(合并重复实体)
↓
关系对齐
├─ 关系名称映射(同义词库、标签映射)
├─ 结构对齐(本体映射)
└─ 关系合并(同义或等价关系)
↓
冲突检测与解决
├─ 可信度评估(来源可信度、时间权重)
├─ 冲突标识(值冲突、缺失补全)
├─ 决策策略(优先级、投票、融合函数)
└─ 融合结果生成(含来源追溯)
↓
知识扩展
├─ 外部知识链接(Wikidata、行业库)
├─ 新知识抽取(OpenIE、文本挖掘)
├─ 图谱推理(嵌入预测、规则推理)
└─ 新实体/关系补充
↓
融合结果验证
├─ 质量评估(准确率、召回率、覆盖率)
├─ 人工抽检/专家审核
└─ 反馈调整(迭代优化)
↓
知识图谱存储与发布
├─ 存储(图数据库,如Neo4j)
├─ 版本管理(数据溯源)
└─ API接口/应用集成
二、知识融合常见问题解决方式
2.1实体消岐
实体消歧的本质在于一个单词很可能有多个意思,也就是在不同的上下文中所表达的含义可能不太一样。
解决方式
- 在标准库里面存放不同含义实体的描述
- 把待审查的实体描述、标准库实体描述向量化
- 计算相似度来判断是哪一种类型的实体(苹果可能是水果实体也可能是公司实体)
-
举例说明:
- 首先我们需要准备一个类似于下面的这种实体库(待消岐样本):
id 实体名称 实体描述 1001 苹果 今天苹果发布了新的手机 1002 苹果 水果的一种,一般产自于。。。 - 当我们拿到text时,比如"今天苹果发布了新的手机",可以将其转成向量。同时将确定实体库中的实体描述,全部转换为向量。
苹果是一种常见的水果,外形圆润,果皮多为红色、绿色或黄色,果肉多汁香甜,富含营养。 ⇒ 向量(tf-idf);
美国一家高科技公司,经典的产品有iphone 手机 ⇒ 向量(tf-idf)
- 基于上述向量做相似度的计算,如果S1>S2 分类成Fruit, 反之分类成苹果公司
2.2实体统一
实体统一是指判断多个实体是不是属于一个实体,其实这种情况也比较常见,比如大家在填写地址的时候,有很多种写法但指的是同一个地址,这些都是实体统一要做的工作。
-
实现方法:
- 1.计算两个实体(字符串)之间的相似度,一般使用编辑距离即可,设定阈值,判断是否属于一个实体。【用的很少】
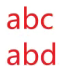 差为1
差为1
 差为2
差为2
- 2.基于规则:根据领域专家提供的规则,如对同义词或缩写的映射。
- 3.基于有监督的学习方法:训练模型,然后分类模型自动判断实体是否相同。
- 1.计算两个实体(字符串)之间的相似度,一般使用编辑距离即可,设定阈值,判断是否属于一个实体。【用的很少】
-
举例说明(基于规则)
-
假设从 不同数据源抽取出两个实体
- 数据源1: 百度有限公司
- 数据源2: 百度科技有限公司
-
实体统一步骤:
-
我们通过人工的设计一些库,或者说是一些词典,这些库包含相同实体的特点:
词典1:公司、有限公司、分公司...
词典2:北京,天津,上海...
词典3:科技,技术...
-
如果实体中的词出现在库中将其删掉
1、百度有限公司------作为原型,删掉出现在词典中的词后为:百度
2、百度科技有限公司 ---删掉出现词典中的词后为:百度
3、判定相同实体
-
-
3.基于有监督的学习方法:训练模型自动判断实体是否相同。
- 直接训练模型进行二分类,判断是否相关
-
2.3关系对齐
不同数据源可能使用不同的方式描述相同的关系,我们需要将不同数据源中表示相同的关系进行对齐和融合。
解决方式
方式一:
维护一个关系字典,对比多个关系是否统一;
若统一,再检查关系对应的实体,如果涉及到相同的实体,那么两条关系合并成一条关系
方式二:
对关系进行向量化,计算相似度判断语义是否一致
- 实现方法
- 关系同义词映射:根据已知的同义词表或通过上下文分析,统一表示相同的关系。
- 基于嵌入的语义相似度:将关系文本编码成向量表示,在向量空间中计算它们之间的相似度,以判断不同关系是否语义一致。
- 举例说明:
- 假设从不同数据源获取到两条关系:
- 数据源1:
<John, is married to, Jane> - 数据源2:
<John, spouse of, Jane>
- 数据源1:
- 对齐步骤:
- 同义词映射:通过关系同义词表,识别出"is married to"和"spouse of"是同义词,表示相同的婚姻关系。
- 上下文分析:检查两条关系中的实体,发现两条关系涉及相同的实体"John"和"Jane"。
- 结果:两条关系被合并为
<John, is married to, Jane>。
- 假设从不同数据源获取到两条关系:
2.4小结
实体消岐(实体链接)
定义:根据上下文信息来解决同一名称可能指代多个不同对象的问题(即一词多义)。
目标:确定文本中提到的具体对象,以消除歧义。
作用:合并同一实体,区分不同实体。
方法:基于规则、机器学习、深度学习
==比如:可以使用 tf-idf 生成向量,然后计算向量相似度==
实体统一(实体对齐)
定义:判断多个实体是不是属于一个实体。
目标:将来自不同数据源中的同一实体进行识别和合并。
作用:确保在知识图谱中同一实体仅有一个表示。
实现方法:
计算两个实体(字符串)之间的相似度,一般使用编辑距离即可,设定阈值,判断是否属于一个实体。
基于规则:根据领域专家提供的规则,如对同义词或缩写的映射。
基于有监督的学习方法:训练分类模型自动判断实体是否相同。
关系对齐(关系统一)
定义:不同数据源可能使用不同的方式描述相同的关系,需要进行判断。
目标:将不同数据源中表示相同的关系进行对齐和融合。
作用:避免在知识图谱中相同关系间数据重复。
方法:
关系同义词映射:根据已知的同义词表或通过上下文分析,统一表示相同的关系。
基于嵌入的语义相似度:将关系文本编码成向量表示,在向量空间中计算它们之间的相似度,以判断不同关系是否语义一致。
三、实体消歧任务
针对上述知识融合任务,这里使用实体消歧举例子详细展示。
3.1整体处理思路
1.读取数据:首先读取包含实体列表的entity_list.csv和包含待处理句子的valid_data.csv。
2.处理实体名称:将entity_list.csv中的实体名称添加到分词词典中,确保可以在后续分词和匹配过程中识别这些实体。
3.计算TF-IDF特征矩阵:将每个实体的描述通过分词处理后生成TF-IDF特征矩阵,用于后续的相似度计算。
4.匹配句子中的实体:在valid_data.csv中的句子中找到关键词,并通过TF-IDF相似度计算找到与关键词匹配的实体ID。
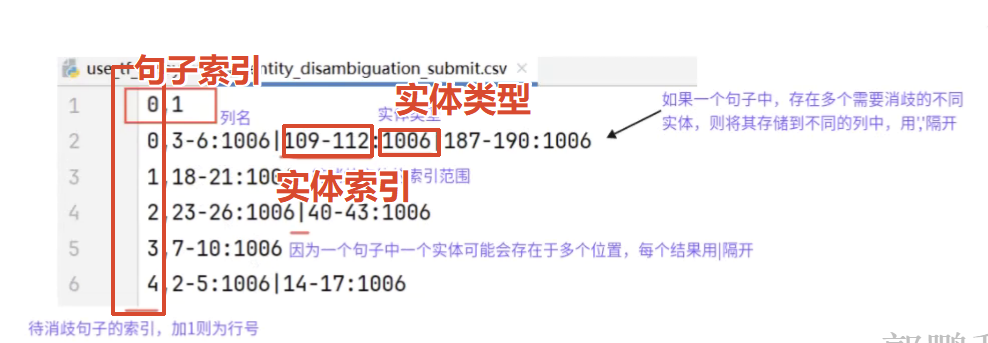
5.输出结果:将句子中匹配到的实体及其位置与对应的实体ID存储为新的CSV文件。
entity_list.csv格式分为三列,第一列entity_id代表实体的编号;第二列entity_name为实体名称,第三列desc为实体的描述信息,不同列之间用","分隔开。实体名称添加到分词字典中,确保在后续分词和匹配的过程中识别到这些实体;
entity_id,entity_name,desc1001,小米|小米公司|小米科技有限责任公司|XIAOMI,"北京小米科技有限责任公司成立于2010年3月3日 1 ,是一家专注于智能硬件和电子产品研发的移动互联网公司,同时也是一家专注于高端智能手机、互联网电视以及智能家居生态链建设的创新型科技企业。 2
为发烧而生"是小米的产品概念。小米公司创造了用互联网模式开发手机操作系统、发烧友参与开发改进的模式。小米还是继苹果、三星、华为之后第四家拥有手机芯片自研能力的科技公司。"
1002,小米,小米,原名:粟,也称作粱、狗尾草、黄粟、粟米,拉丁文名:Setaria italica (L.) Beauv. var. germanica (Mill.) Schrad. 禾本科、狗尾草属一年生草本,须根粗大,秆粗壮,粟是谷子去皮后的结果,谷子是谷类植物,禾木本的一种,粟的营养价值很高,含丰富的蛋白质和脂肪和维生素,它不仅供食用,入药有清热、清渴,滋阴,补脾肾和肠胃,利小便、治水泻等功效,又可酿酒。其茎叶又是牲畜的优等饲料,它含粗蛋白质5-7%,超过一般牧草的含量1.5-2倍,而且纤维素少,质地较柔软,为骡、马所喜食;其谷糠又是
1003,小米,小米是在电视剧《武林外传》中登场的次要人物,同福客栈门口的乞丐,丐帮四袋弟子。他是一个有休息日的乞丐,每逢初一十五,小米自己给自己放假,如果你把铜板扔到他的破碗里,他会毫不犹豫还给你。不过你可别以为他就这么不要了,哈哈,当休息日一过,小米又开工时,他可是会抢回本属于自己的铜板的哦!
3.2详细处理思路
读取entity_list第二列entity_name,这一列的实体名称全部使用竖线凭借在一起,然后使用竖线分割读取以后放到jieba分词的词典里面(防止在分词的时候被切开)。
实体名合并结果:
然后根据实体抽取结果判断每个实体的数量是否大于1,小于1的默认没有语义消歧的需求。
- 上面的结果对每个实体的计数结果;
- keyword_list里面保存的是待消歧的实体;
然后就是使用序列描述对tf-idf模型的训练
提取序列列,然后使用jieba分词器对序列进行分词,然后再使用空格把分词结果连接起来,tf-idf模型对象默认对空格序列进行处理。
处理结果是把分词以后的序列结果保存到一个大的列表中。
使用tf-idf对序列进行处理以后,形状是(16,619)
16表示样本有16行,619表示总共有619个分词结果
(15,427)表示第16行的第427个词的表示为0.32........................
(15,577表示)第16行的第577个词表示为0.32...............................
因为是稀疏向量表示,所以只有有值的地方才会有向量表示。
最后使用待消歧的样本和这16个样本计算之间的相似度,最后判断其实体类型。




代码:P05_DF/entity_disambiguation/use_tf_idf.py
from collections import Counter
import numpy as np
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 1.读取数据:首先读取包含实体列表的entity_list.csv和包含待处理句子的valid_data.csv。
# 样本库中的数据
entity_data = pd.read_csv('data/entity_list.csv', encoding='utf-8')
print(f'entity_data-->{entity_data.head()}')
# 待消歧数据
valid_data = pd.read_csv('data/valid_data.csv', encoding='gbk')
print(f'valid_data-->{valid_data.head()}')
# 2.处理实体名称:将entity_list.csv中的实体名称添加到分词词典中,确保可以在后续分词和匹配过程中识别这些实体。
# 2.1 获取所有的实体名称
total_entity = ''
for entity in entity_data['entity_name']:
total_entity += entity + '|'
# print(f'total_entity-->{total_entity}')
# 2.2 将实体名称添加到分词词典中,防止这些实体在分词时被分开
for word in total_entity[:-1].split('|'):
jieba.add_word(word)
# 2.3 需要统计每个实体出现的次数,对于出现次数大于1次的实体就是需要消歧的实体,我们把它存到一个列表中
keyword_list = [] # 用来存储待消歧的实体
# print(Counter(total_entity[:-1].split('|')).items())
for k, v in Counter(total_entity[:-1].split('|')).items():
if v > 1:
keyword_list.append(k)
print(f'keyword_list-->{keyword_list}')
# 3.计算TF-IDF特征矩阵:将每个实体的描述通过分词处理后生成TF-IDF特征矩阵,用于后续的相似度计算。
# 3.1 将每个实体的描述通过分词处理,将分词结果保存到一个列表中,后续将这个列表作为TF-IDF模型训练的输入数据
train_sentences = []
for desc in entity_data['desc']:
# 需要将分词后的结果用空格连接起来,原因就是在 TF-IDF对象中,默认使用的空格进行分词
train_sentences.append(' '.join(jieba.lcut(desc)))
# print(f'train_sentences-->{train_sentences}')
# 3.2 创建TF-IDF模型,并训练模型
tfidf = TfidfVectorizer()
x = tfidf.fit_transform(train_sentences) # 将数据送入模型进行训练,并且获取TF-IDF特征矩阵
# print(f'x-->{x}') # 稀疏矩阵
print(f'x.shape-->{x.shape}')
def get_entityid(neighbor_sentence):
id_start = 1001 # 假设实体ID从1001开始
# ①对该实体的上下文进行分词
cut_result = [' '.join(jieba.lcut(neighbor_sentence))]
# print(f'cut_result-->{cut_result}')
# ②将分词结果送到模型中生成TF-IDF的向量
vec = tfidf.transform(cut_result)
# print(f'vec-->{vec}')
# ③计算基于上下文生成的TF-IDF向量和样本库中向量的余弦相似度
sim = cosine_similarity(vec, x)[0]
# print(f'sim-->{sim}')
# ④获取余弦相似度最大的实体类型作为实体的类型
# 使用argsort()方法,获取相似度最大的索引
# print(f'np.argsort()-->{np.argsort(sim)}')
top_index = np.argsort(sim)[-1]
return id_start + top_index
# 4.匹配句子中的实体:在valid_data.csv中的句子中找到关键词,并通过TF-IDF相似度计算找到与关键词匹配的实体ID。
# 第一次循环:需要消歧的句子有多个,需要对每个句子进行处理,所以需要遍历
final_result = []
for index, row in enumerate(valid_data['sentence']):
# print(f'row-->{row}')
# 第二次循环: 在一个句子中,可能存在多个需要消歧的实体,需要进行遍历
row_result = [index] # 默认有一个index,用于存储句子的索引
for keyword in keyword_list:
keyword_len = len(keyword) # 待消歧实体的长度
if keyword not in row:
continue
# 第三次循环:一个句子中,同一个需要消歧的实体可能出现多次,需要进行遍历
keyword_range_type = ''
for i in range(len(row) - keyword_len + 1):
if keyword == row[i:i + keyword_len]: # 通过字符串匹配的方式,找到待消歧实体的位置
# print(f'keyword-->{keyword}')
# print(f'i-->{i}')
# 1)获取该实体在句子中的位置
entity_range = str(i) + '-' + str(i + keyword_len) + ':'
# 2)获取该实体的上下文,用于生成的TF-IDF的向量
neighbor_sentence = ''
if i > 10 and i + keyword_len < len(row) - 9:
neighbor_sentence = row[i - 10:i + keyword_len + 9]
elif i < 10:
neighbor_sentence = row[:20]
elif i + keyword_len > len(row) - 9:
neighbor_sentence = row[-20:]
# 3)基于上下文生成的TF-IDF的向量与样本库中的向量计算余弦相似度,获取该实体的类型
entity_type = get_entityid(neighbor_sentence)
entity_range += str(entity_type)
# print(f'entity_range-->{entity_range}')
# 4)进行结果字符串拼接
keyword_range_type += entity_range + '|'
# break
# print(f'keyword_range_type-->{keyword_range_type}')
row_result.append(keyword_range_type[:-1])
# print(f'row_result-->{row_result}')
final_result.append(row_result)
# break
# print(f'final_result-->{final_result}')
# 5.输出结果:将句子中匹配到的实体及其位置与对应的实体ID存储为新的CSV文件。
pd.DataFrame(final_result).to_csv('data/result.csv', index=False, header=True)最终处理结果: