一、云原生基石-K8s
1、什么是k8s
Kubernetes是谷歌开发的第三个容器管理系统,提供了资源调度、扩容缩容、服务发现、存储编排、自动部署和回滚,并且具有天生高可用、负载均衡、故障自动恢复等功能的"生态系统",目前已成为云原生领域的标准。
2、k8s的架构
ETCD 对硬盘性能有较高要求,因为其核心功能(如日志持久化、快照存储)依赖稳定的磁盘 I/O。以下是关键要求和建议:
磁盘类型
- SSD(推荐):必须使用 SSD,避免 HDD。ETCD 对延迟敏感,SSD 能提供稳定的低延迟和高吞吐量。
- NVMe SSD(高性能场景):对于高负载集群,NVMe SSD 可进一步提升性能。
性能指标
-
延迟 :写入延迟应低于 10ms,最佳实践为 1ms 以内。可通过
fio工具测试:bashfio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=22m --bs=2300 --name=sync-test -
吞吐量:单节点至少支持 50MB/s 的顺序写入速度。
文件系统与配置
-
文件系统 :推荐
ext4或XFS,并禁用atime更新以降低开销。bash# ext4 示例挂载选项 /dev/sdb /var/lib/etcd ext4 defaults,noatime,nodiratime 0 2 -
磁盘调度算法 :设置为
deadline或noop(SSD 适用),避免cfq。bashecho deadline > /sys/block/sdb/queue/scheduler
容量规划
- 最小空间:预留至少 2 倍于数据大小的空间(例如数据 8GB 则至少 16GB)。
- 监控与告警:设置磁盘使用率超过 80% 时触发告警,避免因空间不足导致集群不可用。
其他注意事项
- 避免共享磁盘:ETCD 磁盘不应与其他高 I/O 服务(如数据库)共享。
- RAID 配置:若使用 RAID,建议 RAID 10 而非 RAID 5/6,避免写入性能下降。
通过以上配置可确保 ETCD 在生产环境中稳定运行,避免因磁盘问题引发的性能瓶颈或数据丢失风险。
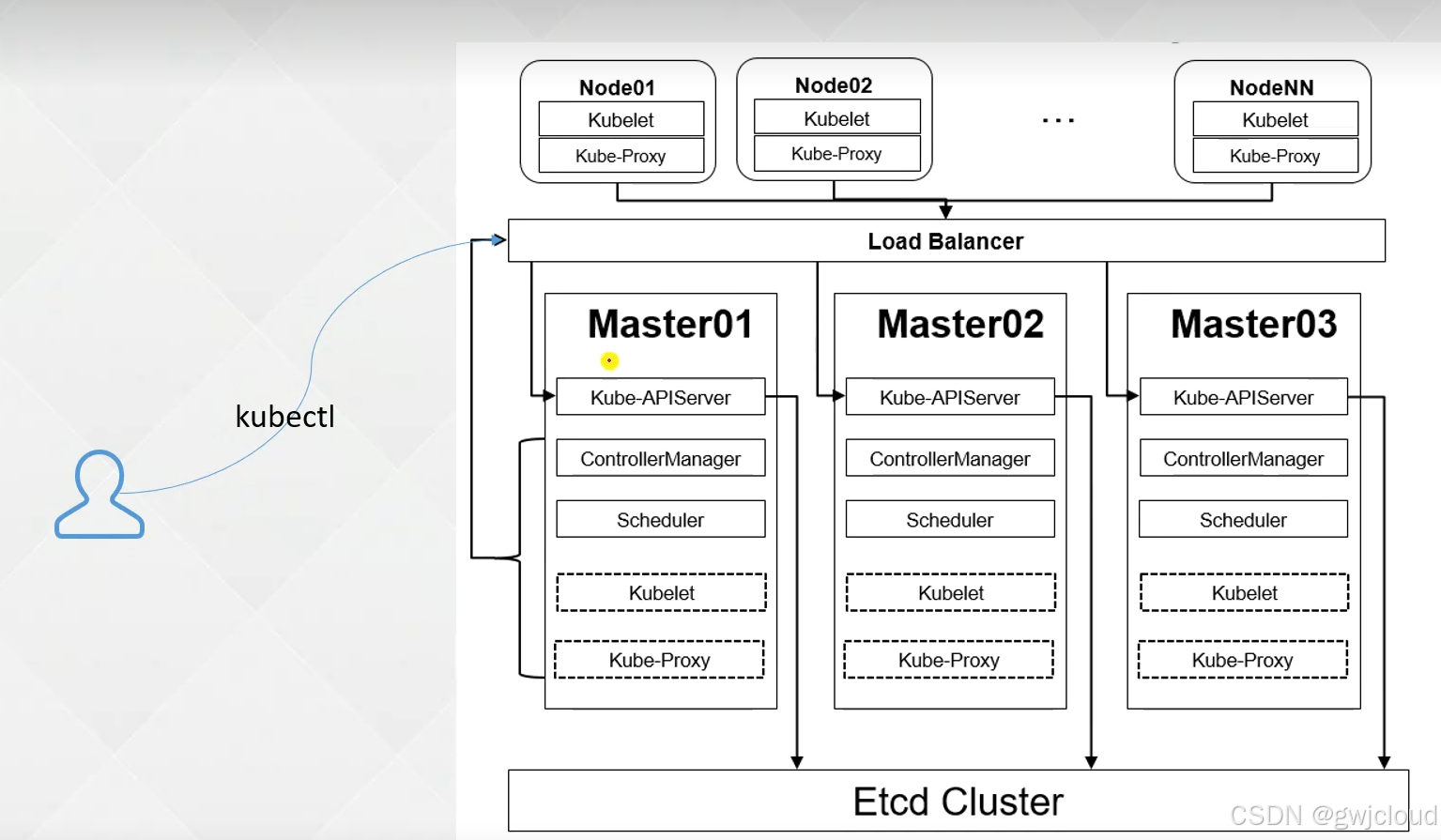
3、K8s组件解析
控制节点组件
- APIServer一APIServer是整个集群的控制中枢,提供集群中各个模块之间的数据交换,并将集群状态和信息存储到分布式键-值(key-value)存储系统Etcd集群中。同时它也是集群管理、资源配额、提供完备的集群安全机制的入口,为集群各类资源对象提供增删改查以及watch的RESTAPI接口。
- Scheduler一Scheduler是集群Pod的调度中心,主要是通过调度算法将Pod分配到最佳的Node节点,它通过APIServer监听所有Pod的状态,一旦发现新的未被调度到任何Node节点的Pod(PodSpec.NodeName为空),就会根据一系列策略选择最佳节点进行调度。
- Controller Manager一Controller Manager是集群状态管理器,以保证Pod或其他资源达到期望值。当集群中某个Pod的副本数或其他资源因故障和错误导致无法正常运行,没有达到设定的值时,Controller Manager会尝试自动修复并使其达到期望状态。
- Etcd一Etcd由coreOs开发,用于可靠地存储集群的配置数据,是一种持久性、轻量型、分布式的键-值(key-value)数据存储组件,作为Kubernetes集群的持久化存储系统。
其中Apiserver是无状态的:
Apiserver本身不任何数据,也不做只从选举,所有集群状态(pod,Deployment,Secret)全部存到etcd中
Scheduler和Controller Manager是有状态:
因为这两个组件必须进行选主(Leader),同一时间只能一个在工作,不然所有节点的Scheduler同时给一个Pod分配节点会冲突,同理Controller manager同时删副本、扩容是要混乱的
# 查询租约信息
[root@k8s-master01 ~]# kubectl get leases -n kube-system
NAME HOLDER AGE
apiserver-6z5gcnzqagv5p4h6bccr6hje2m apiserver-6z5gcnzqagv5p4h6bccr6hje2m_ceedf43b-3541-4105-a69d-5af62aa67275 4h34m
apiserver-hk4fzhyjdo2ayc5o2blltmf4pe apiserver-hk4fzhyjdo2ayc5o2blltmf4pe_94ba15e1-4e4f-4def-a6ad-78cb6546921e 2d1h
apiserver-l3o2wb47zcu4wv6xcvcptpja54 apiserver-l3o2wb47zcu4wv6xcvcptpja54_11a52805-fbb0-4969-8c65-d00efa458cda 4h34m
kube-controller-manager k8s-master01_a7d23801-f51c-4d3a-9c7c-67638bd79ae4 2d1h
kube-scheduler k8s-master03_b07bc7e8-97d3-4932-bed3-d689567d6143 2d1h
说明:
1. apiserver-xxx
Kubernetes APIServer 是多主并行运行的
它不需要选举 leader,所以每个 apiserver 都有自己的 lease
只代表心跳存活,不代表主从
2. kube-controller-manager
当前 leader 是:k8s-master01
同一时间只有一个节点在工作,其他节点待命
3. kube-scheduler
当前 leader 是:k8s-master03
调度器也必须选主,避免重复调度
# 查看详细租约信息(看谁是主、过期时间)
kubectl describe leases -n kube-system工作节点组件
- Kubelet:负责与Master通信协作,管理该节点上的Pod,对容器进行健康检查及监控,同时负责上报节点和节点上面Pod的状态。
- Kube-Proxy:负责各Pod之间的通信和负载均衡,将指定的流量分发到后端正确的机器上。
- Runtime:负责容器的管理。
必备的工具:
-
CoreDNS:用于Kubernetes集群内部Service的解析,可以让Pod把Service名称解析成Service的IP,然后通过Service的IP地址进行连接到对应的应用上。
-
Calico:符合CNI标准的一个网络插件,它负责给每个Pod分配一个不会重复的IP,并且把每个节点当做一各"路由器",这样一个节点的Pod就可以通过IP地址访问到其他节点的Pod。
K8s CoreDNS 运行示例说明
-
进入busybox容器查看DNS配置,可见容器DNS服务器指向10.96.0.10:
[root@k8s-master01 ~]# kubectl exec -it busybox -- sh
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.96.0.10
options ndots:5 -
查看kube-system命名空间下的Service,确认10.96.0.10对应名为kube-dns的ClusterIP Service:
[root@k8s-master01 ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.1053/UDP,53/TCP,9153/TCP 46h
metrics-server ClusterIP 10.96.41.20443/TCP 46h
说明:K8s集群中,kube-dns是Service的兼容名称,实际提供DNS解析服务的是CoreDNS组件,上述示例表明CoreDNS运行正常,Pod可通过该DNS服务实现集群内部及外部域名解析。
-
二、深入pod
1)NameSpace(命名空间)
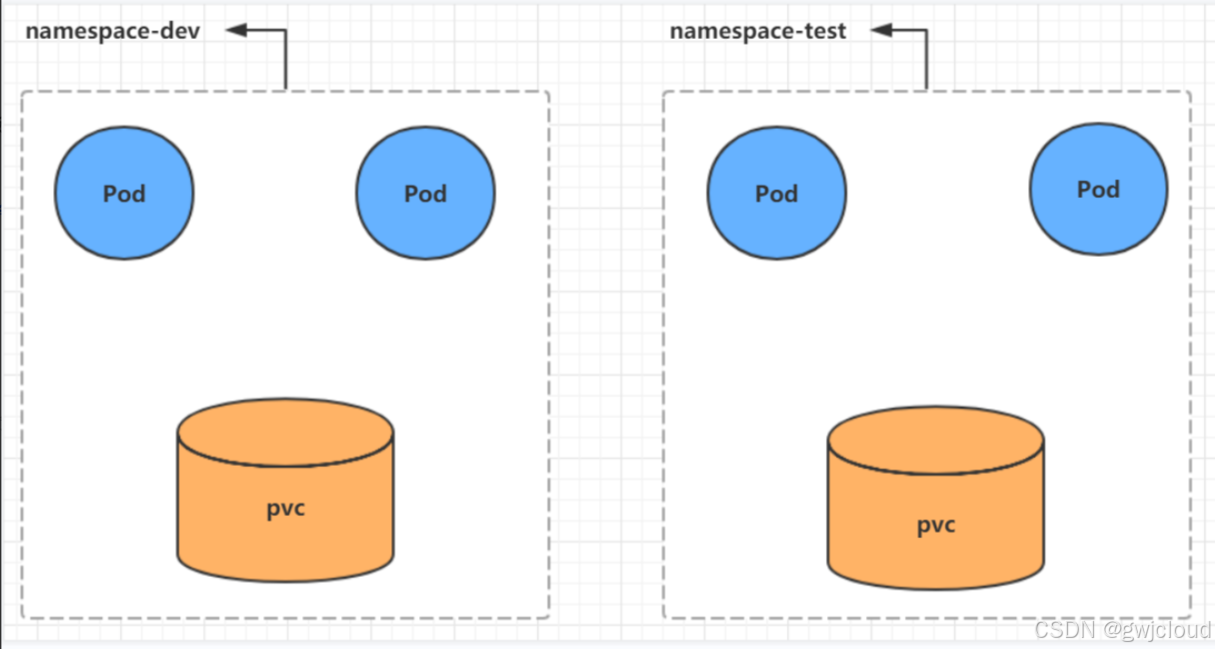
Namespace是kubernetes系统中的一种非常重要资源,它的主要作用是用来实现多套环境的资源隔离 或者多租户的资源隔离
默认情况下,kubernetes集群中的所有的Pod都是可以相互访问的。但是在实际中,可能不想让两个Pod之间进行互相的访问,那此时就可以将两个Pod划分到不同的namespace下。kubernetes通过将集群内部的资源分配到不同的Namespace中,可以形成逻辑上的"组",以方便不同的组的资源进行隔离使用和管理。
可以通过kubernetes的授权机制,将不同的namespace交给不同租户进行管理,这样就实现了多租户的资源隔离。此时还能结合kubernetes的资源配额机制,限定不同租户能占用的资源,例如CPU使用量、内存使用量等等,来实现租户可用资源的管理。
Kubernetes使用命名空间的概念帮助解决集群中在管理对象时的复杂性问题。命名空间允许将对象分组到一起,便于将它们作为一个单元进行筛选和控制。无论是应用自定义的访问控制策略,还是为了测试环境而分离所有组件,命名空间都是一个按照组来处理对象、强大且灵活的概念。
# Kubernetes在集群启动之后,会默认创建几个NameSpace
[root@k8s-master01 ~]# kubectl get ns
NAME STATUS AGE
default Active 2d2h
kube-node-lease Active 2d2h
kube-public Active 2d2h
kube-system Active 2d2h
说明:
default # 所有未指定Namespace的对象都会被分配在default命名空间
kube-node-lease # 集群节点之间的心跳维护,v1.13开始引入
kube-public # 此命名空间下的资源可以被所有人访问(包括未认证用户)
kube-system # 所有由Kubernetes系统创建的资源都处于这个命名空间
#查看指定的命名空间
kubectl get ns default
#查看所有命名空间的pod
kubectl get pod -A
#查看指定命名空间的指定格式(kubernetes支持的格式有很多,比较常见的是wide、json、yaml)
kubectl get ns default -o yaml
#查看命名空间的详细信息
[root@k8s-master01 ~]# kubectl describe ns default
Name: default
Labels: kubernetes.io/metadata.name=default
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
[root@k8s-master01 ~]# kubectl describe ns default
Name: default
Labels: kubernetes.io/metadata.name=default
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
说明:
# Active 命名空间正在使用中 Terminating 正在删除命名空间
# ResourceQuota 针对namespace做的资源限制
# LimitRange针对namespace中的每个组件做的资源限制
#创建命名空间
kubectl create ns ocloud
#删除命名空间
kubectl delete ns ocloud
注意:删除一个namespace会自动删除所有属于该namespace的资源。
default和kube-system命名空间不可删除。
#切换默认的命名空间
kubectl config set-context --current --namespace=kube-system
说明:切换命名空间后,kubectl get pods 如果不指定-n,查看的就是kube-system命名空间的资源了。
#查看那些资源属于命名空间级别的
kubectl api-resources --namespaced=true2)Label(标签)和Selector(标签选择器)
Label是kubernetes系统中的一个重要概念。它的作用就是在资源上添加标识,用来对它们进行区分和选择。
Label的特点:
- 一个Label会以key/value键值对的形式附加到各种对象上,如Node、Pod、Service等等
- 一个资源对象可以定义任意数量的Label ,同一个Label也可以被添加到任意数量的资源对象上去
- Label通常在资源对象定义时确定,当然也可以在对象创建后动态添加或者删除
可以通过Label实现资源的多维度分组,以便灵活、方便地进行资源分配、调度、配置、部署等管理工作。
一些常用的Label 示例如下:
- 版本标签:"version":"release", "version":"stable"......
- 环境标签:"environment":"dev","environment":"test","environment":"pro"
- 架构标签:"tier":"frontend","tier":"backend"
标签定义完毕之后,还要考虑到标签的选择,这就要使用到Label Selector ,即:
Label用于给某个资源对象定义标识
Label Selector用于查询和筛选拥有某些标签的资源对象
当前有两种Label Selector:
- 基于等式的Label Selectorname = slave: 选择所有包含Label中key="name"且value="slave"的对象env != production: 选择所有包括Label中的key="env"且value不等于"production"的对象
- 基于集合的Label Selectorname in (master, slave): 选择所有包含Label中的key="name"且value="master"或"slave"的对象name not in (frontend): 选择所有包含Label中的key="name"且value不等于"frontend"的对象
标签的选择条件可以使用多个,此时将多个Label Selector进行组合,使用逗号","进行分隔即可。例如:
name=slave,env!=production
name not in (frontend),env!=production
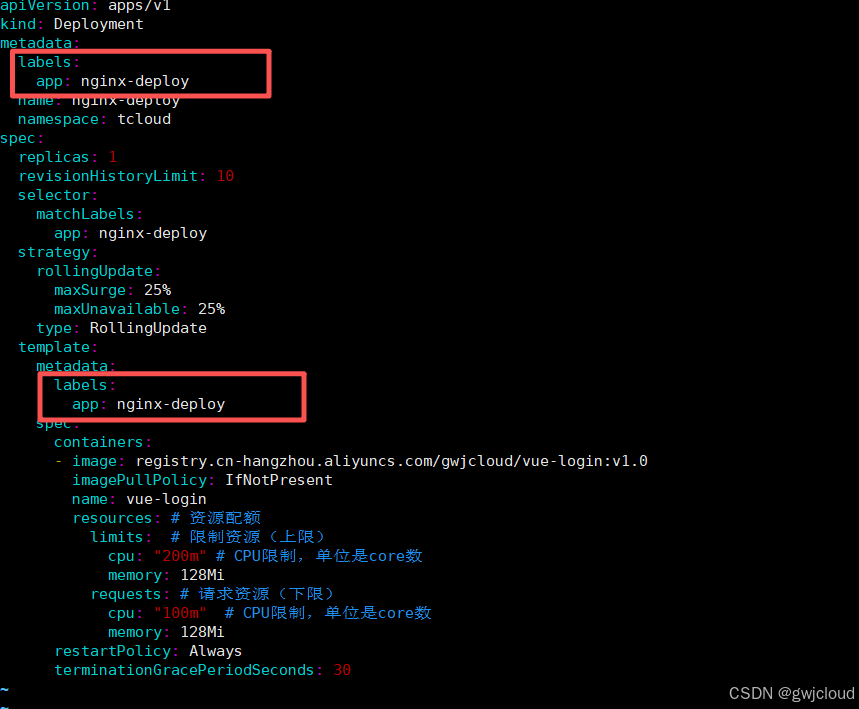
意思是:所有由这个 Deployment 创建的 Pod,都会带上 app: nginx-deploy 标签。
看service文件
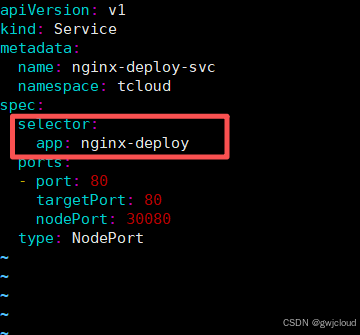
意思是:Service 会自动找到集群中所有带 app: nginx-deploy 标签的 Pod,是pod而不是deployment,并把流量转发给它们。
#为pod资源打标签
[root@k8s-master01 ~]# kubectl label pod busybox version=1.
#查看pod资源的标签
[root@k8s-master01 ~]# kubectl get pod busybox --show-labels
NAME READY STATUS RESTARTS AGE LABELS
busybox 1/1 Running 9 (33m ago) 2d16h version=1.0
#更换pod资源的标签
[root@k8s-master01 ~]# kubectl label pod busybox version=2.0 --overwrite
#查看pod资源的标签
[root@k8s-master01 ~]# kubectl get pod busybox --show-labels
NAME READY STATUS RESTARTS AGE LABELS
busybox 1/1 Running 9 (34m ago) 2d16h version=2.0
#筛选标签
[root@k8s-master01 ~]# kubectl get pod -l version=2.0 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
busybox 1/1 Running 9 (34m ago) 2d16h version=2.0
#删除标签
[root@k8s-master01 ~]# kubectl label pod busybox version-3)pod
什么是pod
Pod是Kubernetes中能够创建和部署的最小单元,是Kubernetes集群中的一个应用实例,总是部署在同一个节点node上。Pod中包含了一个或多个容器,还包括了存储、网络等各个容器共享的资源。Pod支持多种容器环境,Docker则是最流行的容器环境。
Pod并不提供保证正常运行的能力,因为可能遭受Node节点的物理故障、网络分区等等的影响,整体的高可用是Kubernetes集群通过在集群内调度Node来实现的。通常情况下我们不要直接创建Pod,一般都是通过Controller来进行管理,但是了解Pod对于我们熟悉控制器非常有好处。
pod资源清单
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,资源类型,例如 Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #Pod所属的命名空间,默认为"default"
labels: #自定义标签列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
lifecycle: #生命周期钩子
postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启
preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略
nodeName: <string> #设置NodeName表示将该Pod调度到指定到名称的node节点上
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: stringpod状态以及pod故障排查
| Pod 状态 | 中文含义 | 常见原因 | 快速排查命令 |
|---|---|---|---|
| Pending | 等待调度 | 1. 资源不足(CPU / 内存)2. 节点有污点没容忍3. PV/PVC 没准备好4. 节点下线 | kubectl describe pod <pod-name>看 Events 部分 |
| ContainerCreating | 容器创建中 | 1. 镜像拉取慢 / 失败2. 网络插件异常3. 存储挂载卡住 | kubectl describe pod <pod-name>``journalctl -u kubelet |
| ImagePullBackOff | 镜像拉取失败 | 1. 镜像地址错2. 私有仓库没认证3. 网络不通、镜像不存在 | kubectl describe pod <pod-name>检查镜像地址、权限、网络 |
| ErrImagePull | 拉镜像出错 | 同上,比 ImagePullBackOff 更早 | 同上 |
| Running | 正常运行 | 服务正常 | kubectl logs <pod-name>``kubectl exec -it <pod-name> -- sh |
| Completed | 正常退出 | 容器执行完命令退出(如脚本、job) | 正常状态,无需处理 |
| CrashLoopBackOff | 反复崩溃重启 | 1. 应用启动失败2. 配置错误3. 端口被占用4. 权限不足 | kubectl logs <pod-name>``kubectl logs <pod-name> --previous |
| Terminating | 正在删除 | 1. 容器无法优雅退出2. 挂载盘卡住3. 网络插件异常 | 等 30 秒 或 强制删除:kubectl delete pod <pod-name> --force --grace-period=0 |
| Unknown | 状态未知 | 1. 节点失联2. kubelet 挂了3. 网络不通 | 看节点状态:kubectl get nodes登录节点看 kubelet |
| Evicted | 被驱逐 | 节点磁盘 / 内存 / 资源满了 | 清理节点资源,重新调度 |
| OOMKilled | 内存溢出被杀 | 内存不足、程序内存泄漏 | kubectl describe pod <pod-name>加大内存限制 |
| Init:Error | Init 容器失败 | Init 容器执行错误 | kubectl logs <pod-name> -c <init容器名> |
| PodInitializing | 初始化中 | Init 容器还在运行 / 卡住 | kubectl describe pod <pod-name> |
pod镜像拉取策略
| 策略名称 | 含义 | 触发条件 / 默认规则 | 适用场景 |
|---|---|---|---|
| IfNotPresent | 节点本地已有镜像就不拉,本地没有才拉取 | • 默认规则 :镜像 tag 是具体版本号 (如 nginx:1.15.12)默认策略 = IfNotPresent |
・内网环境・私有仓库・稳定版本,不想每次都拉取 |
| Always | 每次创建 / 重启容器都重新拉取镜像,不管本地有没有 | • 默认规则 :镜像 tag 是 latest (如 nginx:latest)默认策略 = Always |
・测试环境・镜像经常更新・确保用最新版本 |
| Never | 永远不从仓库拉取镜像,只使用本地镜像 | 必须手动写明 | ・完全离线环境・禁止访问外部仓库 |
# 先用kubectl run命令生成一个简单的yaml文件
[root@k8s-master01 yaml]# kubectl run login-nginx --image=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:1.15.12 -o yaml --dry-run > nginx.yaml
# 创建tcloud命名空间
[root@k8s-master01 yaml]# kubectl create ns tcloud
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: login-nginx
name: login-nginx
namespace: tcloud
spec:
containers:
- image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
name: login-nginx
imagePullPolicy: IfNotPresent
# 部署pod
[root@k8s-master01 yaml]# kubectl apply -f nginx.yaml pod生命周期
pod对象从创建至终的这段时间范围称为pod的生命周期,它主要包含下面的过程:
- pod创建过程
- 运行初始化容器(init container)过程
- 运行主容器(main container)
- 容器启动后钩子(post start)、容器终止前钩子(pre stop)
- 容器的存活性探测(liveness probe)、就绪性探测(readiness probe)
- pod终止过程
在整个生命周期中,Pod会出现5种状态(相位),分别如下:
- 挂起(Pending):apiserver已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中
- 运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成
- 成功(Succeeded):pod中的所有容器都已经成功终止并且不会被重启
- 失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态
- 未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所导致
创建和终止
pod创建过程:
1、用户通过kubectl或其他api客户端提交需要创建的pod信息给apiServer
2、apiServer开始生成pod对象的信息,并将信息存入etcd,然后返回确认信息至客户端
3、apiServer开始反映etcd中的pod对象的变化,其它组件使用watch机制来跟踪检查apiServer上的变动
4、scheduler发现有新的pod对象要创建,开始为Pod分配主机并将结果信息更新至apiServer
5、node节点上的kubelet发现有pod调度过来,尝试调用docker启动容器,并将结果回送至apiServer
6、apiServer将接收到的pod状态信息存入etcd中
pod的终止过程:
1、用户向apiServer发送删除pod对象的命令
2、apiServcer中的pod对象信息会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead
3、将pod标记为terminating状态
4、kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程
5、端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除
6、如果当前pod对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行
7、pod对象中的容器进程收到停止信号
8、宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到立即终止的信号
9、kubelet请求apiServer将此pod资源的宽限期设置为0从而完成删除操作,此时pod对于用户已不可见
pod钩子函数
| 钩子名称 | 执行时机 | 作用 | 特点 |
|---|---|---|---|
| postStart | 容器创建成功后、启动命令执行同时(不保证顺序) | 做初始化、预热、配置修改 | 执行失败会导致容器重启 |
| preStop | 容器收到删除 / 终止信号后、真正被杀前 | 优雅关闭、保存数据、注销服务、发通知 | 会阻塞删除,执行完才删容器 |
钩子函数有3种实现方式
| 实现方式 | 写法 | 作用 | 适用场景 |
|---|---|---|---|
| 1. exec 执行命令 | exec: |
在容器内部执行一条 Linux 命令 | 99% 场景都用这个(最常用) |
| 2. httpGet 请求 | httpGet: |
向容器发送一个 HTTP GET 请求 | 给应用发一个优雅关闭接口 |
| 3. tcpSocket | tcpSocket: |
尝试连接容器端口(极少用) | 几乎不用,了解即可 |
1、exec命令:在容器内执行一次命令
......
lifecycle:
postStart:
exec:
command:
- cat
- /tmp/healthy
......
2、TCPSocket:在当前容器尝试访问指定的socket
......
lifecycle:
postStart:
tcpSocket:
port: 8080
......
3、HTTPGet:在当前容器中向某url发起http请求
......
lifecycle:
postStart:
httpGet:
path: / #URI地址
port: 80 #端口号
host: 192.168.5.3 #主机地址
scheme: HTTP #支持的协议,http或者https
......使用案例
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: tcloud
spec:
containers:
- name: main-container
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo 'pod started by postStart hook' > /usr/share/nginx/html/index.html"]
preStop:
exec:
command:
- "/bin/sh"
- "-c"
- |
echo "开始执行优雅下线..." >> /var/log/stop.log
sleep 3 # 等待流量切走,避免5xx
nginx -s quit # 优雅停止 Nginx
echo "容器已正常停止" >> /var/log/stop.log
# 创建pod
[root@k8s-master01 yaml]# kubectl apply -f nginx.yaml
# 访问测试
[root@k8s-master01 ~]# curl 10.244.195.3
pod started by postStart hookpod重启策略
| 重启策略 | 说明 | 触发重启的场景 | 不会重启的场景 | 适用场景 | 默认值 |
| Always | 容器退出总是重启 | 容器正常退出 (exit 0)容器异常退出 (exit≠0)容器被 OOM 杀死 | 无,只要停止就会重启 | 长期运行服务:Nginx、Vue、Java、MySQL 等 | 默认值 |
| OnFailure | 只有异常退出才重启 | exit≠0、OOM、程序崩溃 | 正常退出 (exit 0) | 定时任务、脚本、批处理、Job | - |
| Never | 永远不重启 | 任何情况都不重启 | 所有退出场景 | 一次性任务、调试 Pod、不希望自动恢复 | - |
|---|
pod探针(健康检查)
容器探测用于检测容器中的应用实例是否正常工作,是保障业务可用性的一种传统机制。如果经过探测,实例的状态不符合预期,那么kubernetes就会把该问题实例" 摘除 ",不承担业务流量。kubernetes提供了三种探针来实现容器探测,分别是:
| 探针名称 | 英文 | 作用 | 检测时机 | 典型配置 |
|---|---|---|---|---|
| 就绪探针 | ReadinessProbe |
判断服务是否就绪未就绪:Service 不转发流量 | 容器运行全程,周期性检测 | httpGet、tcpSocket、exec |
| 存活探针 | LivenessProbe |
判断容器是否活着死了 / 卡死:kubelet 重启容器 | 容器运行全程,周期性检测 | httpGet、tcpSocket、exec |
| 启动探针 | StartupProbe |
判断应用是否启动完成启动失败:重启容器启动成功:才交给前两个探针 | 只在启动阶段检测 | httpGet、tcpSocket、exec |
这几种探针都有3种实现方式exec、httpGet、tcpSocket
# exec命令:在容器内执行一次命令,如果命令执行的退出码为0,则认为程序正常,否则不正常
......
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
......
# TCPSocket:将会尝试访问一个用户容器的端口,如果能够建立这条连接,则认为程序正常,否则不正常
......
livenessProbe:
tcpSocket:
port: 8080
......
# HTTPGet:调用容器内Web应用的URL,如果返回的状态码在200和399之间,则认为程序正常,否则不正常
......
livenessProbe:
httpGet:
path: / #URI地址
port: 80 #端口号
host: 127.0.0.1 #主机地址
scheme: HTTP #支持的协议,http或者https
......startupProbe(启动探针)
# HTTPGet方式
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
labels:
type: app
namespace: tcloud
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
startupProbe:
httpGet:
path: /index.html
port: 80
initialDelaySeconds: 0
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
restartPolicy: OnFailure我们去用http的去访问index.html文件,但是生成环境不能这样去做,index.html只是一个静态文件,不能去真正代表服务存活
生产标准做法:必须用专门健康检查接口
Spring Boot → /actuator/health
Go/Python/Node → /health
微服务网关 → /health/check
# 构建pod
[root@k8s-master01 yaml]# kubectl apply -f nginx.yaml
# 查看详细信息
[root@k8s-master01 yaml]# kubectl describe pod nginx-demo -n tcloud
...
Startup: http-get http://:80/index.html delay=0s timeout=5s period=10s #success=1 #failure=3
说明:
方式:HTTP GET
地址:http://:80/index.html
延迟:0s
超时:5s
周期:10s
成功阈值:1
失败阈值:3
# TCPSocket方式
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
labels:
type: app
namespace: tcloud
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
startupProbe:
tcpSocket:
port: 80
initialDelaySeconds: 0
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
restartPolicy: OnFailure
# 构建pod
[root@k8s-master01 yaml]# kubectl apply -f nginx.yaml
# 查看详细信息
[root@k8s-master01 yaml]# kubectl describe pod nginx-demo -n tcloud
...
Startup: tcp-socket :80 delay=0s timeout=5s period=10s #success=1 #failure=3
# exec方式
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
labels:
type: app
namespace: tcloud
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
startupProbe:
exec:
command:
- sh
- -c
- "echo success > /inited"
initialDelaySeconds: 0
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
restartPolicy: OnFailure
# 构建pod
[root@k8s-master01 yaml]# kubectl apply -f nginx.yaml
# 查看详细信息
[root@k8s-master01 yaml]# kubectl describe pod nginx-demo -n tcloud
...
Startup: exec [sh -c echo success > /inited] delay=0s timeout=5s period=10s #success=1 #failure=3
[root@k8s-master01 yaml]# kubectl exec -it nginx-demo -n tcloud -- cat /inited
successLivenessProbe(存活探针)
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
labels:
type: app
namespace: tcloud
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
startupProbe:
exec:
command:
- sh
- -c
- "echo success > /inited"
initialDelaySeconds: 0
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
livenessProbe:
httpGet:
path: /index.html
port: 80
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
restartPolicy: OnFailure
# 构建pod后看详细信息
[root@k8s-master01 yaml]# kubectl describe pod -n tcloud nginx-demo
...
Liveness: http-get http://:80/index.html delay=0s timeout=5s period=10s #success=1 #failure=3
Startup: exec [sh -c echo success > /inited] delay=0s timeout=5s period=10s #success=1 #failure=3
Environment: <none>ReadinessProbe(就绪探针)
[root@k8s-master01 yaml]# vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
labels:
type: app
namespace: tcloud
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
startupProbe:
exec:
command:
- sh
- -c
- "echo success > /inited"
initialDelaySeconds: 0
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /index.html
port: 80
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
restartPolicy: OnFailure
# 构建pod查看详细信息
[root@k8s-master01 yaml]# kubectl describe pod -n tcloud nginx-demo
...
Readiness: http-get http://:80/index.html delay=0s timeout=5s period=10s #success=1 #failure=3
Startup: exec [sh -c echo success > /inited] delay=0s timeout=5s period=10s #success=1 #failure=3三、资源调度
Pod是kubernetes的最小管理单元,在kubernetes中,按照pod的创建方式可以将其分为两类:
- 自主式pod:kubernetes直接创建出来的Pod,这种pod删除后就没有了,也不会重建
- 控制器创建的pod:kubernetes通过控制器创建的pod,这种pod删除了之后还会自动重建
什么是Pod控制器
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod。
在kubernetes中,有很多类型的pod控制器,每种都有自己的适合的场景,常见的有下面这些:
- ReplicationController:比较原始的pod控制器,已经被废弃,由ReplicaSet替代
- ReplicaSet:保证副本数量一直维持在期望值,并支持pod数量扩缩容,镜像版本升级
- Deployment:通过控制ReplicaSet来控制Pod,并支持滚动升级、回退版本
- Horizontal Pod Autoscaler:可以根据集群负载自动水平调整Pod的数量,实现削峰填谷
- DaemonSet:在集群中的指定Node上运行且仅运行一个副本,一般用于守护进程类的任务
- Job:它创建出来的pod只要完成任务就立即退出,不需要重启或重建,用于执行一次性任务
- Cronjob:它创建的Pod负责周期性任务控制,不需要持续后台运行
- StatefulSet:管理有状态应用
无状态:
无状态服务不会在本地存储持久化数据.多个服务实例对于同一个用户请求的响应结果是完全一致的.这种多服务实例之间是没有依赖关系,比如web应用,在k8s控制器 中动态启停无状态服务的pod并不会对其它的pod产生影响.有状态:
有状态服务需要在本地存储持久化数据,典型的是分布式数据库的应用,分布式节点实例之间有依赖的拓扑关系.比如,主从关系. 如果K8S停止分布式集群中任 一实例pod,就可能会导致数据丢失或者集群的crash.
1、ReplicaSet
ReplicaSet的主要作用是保证一定数量的pod正常运行,它会持续监听这些Pod的运行状态,一旦Pod发生故障,就会重启或重建。同时它还支持对pod数量的扩缩容和镜像版本的升降级。
ReplicaSet的资源清单文件:
apiVersion: apps/v1 # 版本号
kind: ReplicaSet # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: rs
spec: # 详情描述
replicas: 3 # 副本数量
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
# 编写创建RS控制器的yaml文件
[root@k8s-master01 yaml]# vim replicaset.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs-nginx
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
# 创建rs控制器
[root@k8s-master01 yaml]# kubectl apply -f replicaset.yaml
# 查看资源
[root@k8s-master01 yaml]# kubectl get replicasets -n tcloud
NAME DESIRED CURRENT READY AGE
rs-nginx 3 3 3 2m12s
# 查看RS控制器构建出来的pod
[root@k8s-master01 yaml]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
rs-nginx-254ln 1/1 Running 0 3m32s
rs-nginx-p8b4c 1/1 Running 0 3m32s
rs-nginx-vjsnm 1/1 Running 0 3m32s
[root@k8s-master01 yaml]#
# 扩容pod的副本数量
[root@k8s-master01 yaml]# kubectl edit rs rs-nginx -n tcloud
# 编辑rs的副本数量,修改spec:replicas: 6即可
# 查看pod的数量
[root@k8s-master01 yaml]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
rs-nginx-254ln 1/1 Running 0 5m34s
rs-nginx-c99vm 1/1 Running 0 24s
rs-nginx-hg7x7 1/1 Running 0 24s
rs-nginx-p8b4c 1/1 Running 0 5m34s
rs-nginx-r4g82 1/1 Running 0 24s
rs-nginx-vjsnm 1/1 Running 0 5m34s
# 也可以使用命令实现
[root@k8s-master01 ~]# kubectl scale rs rs-nginx -n tcloud --replicas=3
# 查看pod数量
[root@k8s-master01 ~]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
rs-nginx-254ln 1/1 Running 0 6m46s
rs-nginx-p8b4c 1/1 Running 0 6m46s
rs-nginx-vjsnm 1/1 Running 0 6m46s
# 删除其中一个pod数量
[root@k8s-master01 ~]# kubectl delete pod rs-nginx-254ln -n tcloud
# 继续查询pod数量
[root@k8s-master01 ~]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
rs-nginx-5fgc6 1/1 Running 0 6s
rs-nginx-p8b4c 1/1 Running 0 7m33s
rs-nginx-vjsnm 1/1 Running 0 7m33s
# 删除RS控制器
[root@k8s-master01 yaml]# kubectl delete -f replicaset.yaml
# 同理这里也可以做镜像的替换和升级。2、Deployment
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。值得一提的是,这种控制器并不直接管理pod,而是通过管理ReplicaSet来简介管理Pod,即:Deployment管理ReplicaSet,ReplicaSet管理Pod。所以Deployment比ReplicaSet功能更加强大。
Deployment一般用于部署公司的无状态服务,这个也是最常用的控制器,因为企业内部现在都是以微服务为主,而微服务实现无状态化也是最佳实践,可以利用Deployment的高级功能做到无缝迁移、自动扩容缩容、自动灾难恢复、键回滚等功能。
创建Deployment
很多情况下我们不知道如何去写yaml文件,可以用命令创建一个deployment用yaml输出到yaml文件种
[root@k8s-master01 yaml]# kubectl create deployment nginx-deploy --image=registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0 -n tcloud
# 查看deploy输出到yaml文件
[root@k8s-master01 yaml]# kubectl get deployments -n tcloud -o yaml > deploy.yaml
# 编辑一下yaml文件,保留需要的配置
[root@k8s-master01 yaml]# vim deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy
name: nginx-deploy
namespace: tcloud
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx-deploy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: nginx-deploy
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
name: vue-login
restartPolicy: Always
terminationGracePeriodSeconds: 30
apiVersion: apps/v1 # Deployment 资源使用的 API 版本
kind: Deployment # 资源类型:Deployment(用于管理应用 Pod)
metadata: # 资源元数据(名称、标签、命名空间)
labels: # 标签,用于识别和匹配
app: nginx-deploy # 标签键值对:app=nginx-deploy
name: nginx-deploy # Deployment 名称:nginx-deploy
namespace: tcloud # 部署在命名空间 tcloud 下
spec: # Deployment 期望状态配置
replicas: 1 # 运行 1 个 Pod 副本
revisionHistoryLimit: 10 # 保留 10 个历史版本,用于回滚
selector: # 标签选择器,用来找到要管理的 Pod
matchLabels: # 匹配下面的标签
app: nginx-deploy # 匹配标签 app=nginx-deploy
strategy: # 更新策略
rollingUpdate: # 滚动更新配置
maxSurge: 25% # 更新时最多额外启动 25% 副本
maxUnavailable: 25% # 更新时最多不可用 25% 副本
type: RollingUpdate # 更新类型:滚动更新(不停机)
template: # Pod 模板(创建 Pod 用的"模具")
metadata: # Pod 的元数据
labels: # Pod 自带的标签
app: nginx-deploy # Pod 标签 app=nginx-deploy(必须和上面 selector 匹配)
spec: # Pod 内部容器等配置
containers: # 容器列表
- image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
# 容器使用的镜像(Vue 前端登录项目,不是 nginx)
imagePullPolicy: IfNotPresent
# 镜像拉取策略:本地有就不拉,没有才拉
name: vue-login # 容器名称:vue-login
restartPolicy: Always # Pod 异常退出时总是自动重启
terminationGracePeriodSeconds: 30
# 删除 Pod 时,优雅等待时间 30 秒
# 查看创建的资源
[root@k8s-master01 yaml]# kubectl get pod,rs,deploy -n tcloud --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod/nginx-deploy-795697b5bb-cd8cd 1/1 Running 0 8s app=nginx-deploy,pod-template-hash=795697b5bb
NAME DESIRED CURRENT READY AGE LABELS
replicaset.apps/nginx-deploy-795697b5bb 1 1 1 8s app=nginx-deploy,pod-template-hash=795697b5bb
NAME READY UP-TO-DATE AVAILABLE AGE LABELS
deployment.apps/nginx-deploy 1/1 1 1 8s app=nginx-deploy扩容Deployment
# 扩缩容变更副本数量为3个
[root@k8s-master01 yaml]# kubectl scale deploy -n tcloud nginx-deploy --replicas=3
# 查看pod
[root@k8s-master01 yaml]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
nginx-deploy-795697b5bb-8sfvn 1/1 Running 0 4m44s
nginx-deploy-795697b5bb-cd8cd 1/1 Running 0 13m
nginx-deploy-795697b5bb-f58xq 1/1 Running 0 4m44s
# 也可以使用edit来扩容
[root@k8s-master01 yaml]# kubectl edit deployments -n tcloud nginx-deploy
修改spec:replicas: 5即可
# 查看pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-795697b5bb-8sfvn 1/1 Running 0 6m4s
nginx-deploy-795697b5bb-bssjd 1/1 Running 0 7s
nginx-deploy-795697b5bb-cd8cd 1/1 Running 0 14m
nginx-deploy-795697b5bb-f58xq 1/1 Running 0 6m4s
nginx-deploy-795697b5bb-kkvrc 1/1 Running 0 7s更新Deployment
只有修改了 .spec.template 下面的配置,才会触发 Pod 重建 → 触发 Deployment 更新。
有两种更新方式
滚动更新(RollingUpdate)
- 逐批替换旧 Pod
- 先启动新 Pod → 再销毁旧 Pod
- 业务全程不中断
- 生产环境必须用这个
重建更新(Recreate)
- 停机更新
- 先杀光旧的 → 再起新的
- 会短暂业务不可用
- 适合测试环境、非关键业务
重建更新
# 编辑yaml文件修改为重建更新
[root@k8s-master01 yaml]# vim deploy.yaml
...
spec:
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx-deploy
strategy:
#rollingUpdate:
# maxSurge: 25%
# maxUnavailable: 25%
type: Recreate
template:
metadata:
labels:
app: nginx-deploy
...
[root@k8s-master01 yaml]# kubectl apply -f deploy.yaml
# 变更镜像
[root@k8s-master01 yaml]# kubectl set image deployments -n tcloud nginx-deploy vue-login=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
# 可以执行kubectl get pod -n dev -w查看升级过程
可以发现重建更新是先杀掉所有的旧的pod,在起新的pod,这样是停机更新,生成环境不能这样去做滚动更新
# 编辑yaml文件修改为重建更新
[root@k8s-master01 yaml]# vim deploy.yaml
...
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
...
[root@k8s-master01 yaml]# kubectl apply -f deploy.yaml
# 更改镜像
[root@k8s-master01 yaml]# kubectl set image deployments -n tcloud nginx-deploy vue-login=registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
# 查看更新过程
[root@k8s-master01 yaml]# kubectl get pod -n tcloud -w
NAME READY STATUS RESTARTS AGE
nginx-deploy-bb6447776-6xfv8 1/1 Running 0 11s
nginx-deploy-bb6447776-cxvzp 1/1 Running 0 10s
nginx-deploy-bb6447776-qqg2s 1/1 Running 0 11s
nginx-deploy-795697b5bb-jz75d 0/1 Pending 0 0s
nginx-deploy-795697b5bb-jz75d 0/1 Pending 0 0s
nginx-deploy-795697b5bb-jz75d 0/1 ContainerCreating 0 0s
nginx-deploy-795697b5bb-jz75d 1/1 Running 0 1s
nginx-deploy-bb6447776-cxvzp 1/1 Terminating 0 16s
nginx-deploy-795697b5bb-pv5fp 0/1 Pending 0 0s
nginx-deploy-bb6447776-cxvzp 1/1 Terminating 0 16s
nginx-deploy-795697b5bb-pv5fp 0/1 Pending 0 0s
nginx-deploy-795697b5bb-pv5fp 0/1 ContainerCreating 0 0s
nginx-deploy-bb6447776-cxvzp 0/1 Completed 0 16s
nginx-deploy-bb6447776-cxvzp 0/1 Completed 0 17s
nginx-deploy-bb6447776-cxvzp 0/1 Completed 0 17s
nginx-deploy-795697b5bb-pv5fp 1/1 Running 0 1s
nginx-deploy-bb6447776-qqg2s 1/1 Terminating 0 18s
nginx-deploy-795697b5bb-8wbjs 0/1 Pending 0 0s
nginx-deploy-795697b5bb-8wbjs 0/1 Pending 0 0s
nginx-deploy-bb6447776-qqg2s 1/1 Terminating 0 18s
nginx-deploy-795697b5bb-8wbjs 0/1 ContainerCreating 0 0s
nginx-deploy-bb6447776-qqg2s 0/1 Completed 0 18s
nginx-deploy-bb6447776-qqg2s 0/1 Completed 0 19s
nginx-deploy-bb6447776-qqg2s 0/1 Completed 0 19s
nginx-deploy-795697b5bb-8wbjs 1/1 Running 0 2s
nginx-deploy-bb6447776-6xfv8 1/1 Terminating 0 20s
nginx-deploy-bb6447776-6xfv8 1/1 Terminating 0 20s
nginx-deploy-bb6447776-6xfv8 0/1 Completed 0 20s
nginx-deploy-bb6447776-6xfv8 0/1 Completed 0 21s
nginx-deploy-bb6447776-6xfv8 0/1 Completed 0 21s
可以看到是逐批替换旧Pod,我们也可以看详细信息
[root@k8s-master01 yaml]# kubectl describe deployments -n tcloud nginx-deploy
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 36m deployment-controller Scaled up replica set nginx-deploy-795697b5bb from 1 to 3
Normal ScalingReplicaSet 30m (x2 over 32m) deployment-controller Scaled up replica set nginx-deploy-795697b5bb from 3 to 5
Normal ScalingReplicaSet 19m (x2 over 31m) deployment-controller Scaled down replica set nginx-deploy-795697b5bb from 5 to 3
Normal ScalingReplicaSet 14m deployment-controller Scaled down replica set nginx-deploy-795697b5bb from 3 to 0
Normal ScalingReplicaSet 14m deployment-controller Scaled up replica set nginx-deploy-7699c758d4 from 0 to 3
Normal ScalingReplicaSet 13m deployment-controller Scaled down replica set nginx-deploy-7699c758d4 from 3 to 0
Normal ScalingReplicaSet 13m deployment-controller Scaled up replica set nginx-deploy-bb6447776 from 0 to 3
Normal ScalingReplicaSet 10m deployment-controller Scaled down replica set nginx-deploy-bb6447776 from 3 to 2
Normal ScalingReplicaSet 3m (x3 over 44m) deployment-controller Scaled up replica set nginx-deploy-795697b5bb from 0 to 1
Normal ScalingReplicaSet 2m59s (x2 over 10m) deployment-controller Scaled up replica set nginx-deploy-795697b5bb from 1 to 2
Normal ScalingReplicaSet 2m58s (x2 over 10m) deployment-controller Scaled down replica set nginx-deploy-bb6447776 from 2 to 1
Normal ScalingReplicaSet 2m56s (x11 over 10m) deployment-controller (combined from similar events): Scaled down replica set nginx-deploy-bb6447776 from 1 to 0滚动更新的过程:
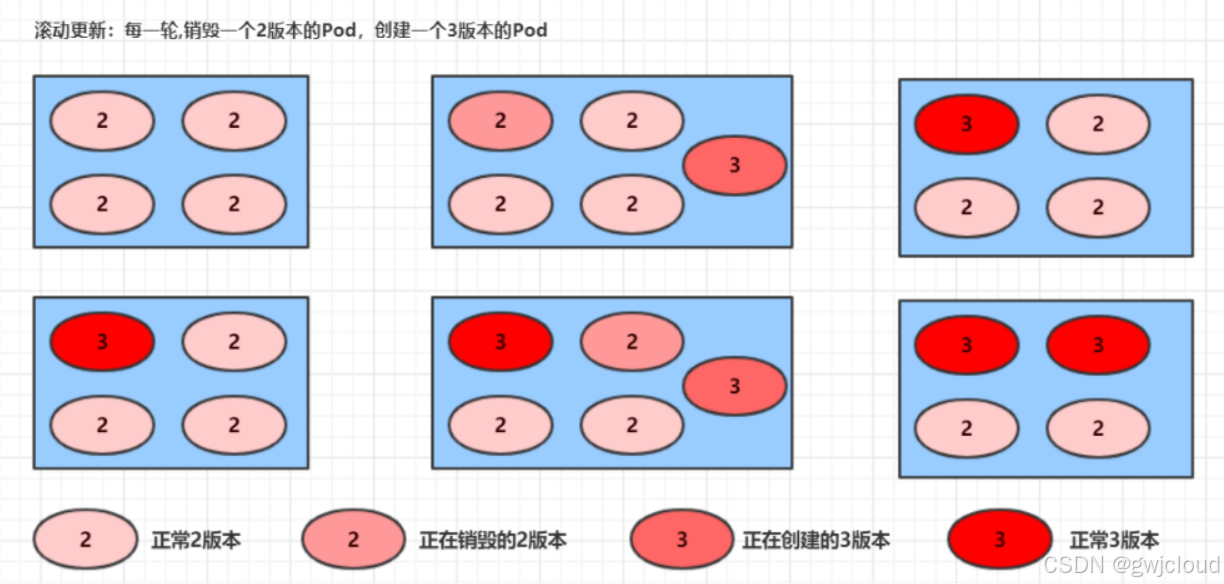
回滚Deployment
deployment支持版本升级过程中的暂停、继续功能以及版本回退等诸多功能,下面具体来看.
kubectl rollout: 版本升级相关功能,支持下面的选项:
-
status 显示当前升级状态
-
history 显示 升级历史记录
-
pause 暂停版本升级过程
-
resume 继续已经暂停的版本升级过程
-
restart 重启版本升级过程
-
undo 回滚到上一级版本(可以使用--to-revision回滚到指定版本)
查看当前deployment的升级状态
[root@k8s-master01 ~]# kubectl rollout status deployment nginx-deploy -n tcloud
deployment "nginx-deploy" successfully rolled out查看历史版本
[root@k8s-master01 ~]# kubectl rollout history deployment nginx-deploy -n tcloud
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
2
5
6
说明:CHANGE-CAUSE=的原因是在做升级镜像的操作后没有加--record这个参数(kubectl set image deployments -n tcloud nginx-deploy vue-login=registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0 --record) 查看版本的详细信息
[root@k8s-master01 ~]# kubectl rollout history deployment -n tcloud nginx-deploy --revision=2
deployment.apps/nginx-deploy with revision #5
Pod Template:
Labels: app=nginx-deploy
pod-template-hash=7699c758d4
Containers:
vue-login:
Image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:lates
Port:
Host Port:
Environment:
Mounts:
Volumes:
Node-Selectors:
Tolerations:
...查看当前deployment使用的镜像
[root@k8s-master01 ~]# kubectl get deployments -n tcloud -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx-deploy 3/3 3 3 104m vue-login registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0 app=nginx-deploy回退版本
[root@k8s-master01 ~]# kubectl rollout undo deployment -n tcloud nginx-deploy --to-revision=5
查看当前deployment使用的版本
[root@k8s-master01 ~]# kubectl get deployments -n tcloud -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx-deploy 3/3 3 3 106m vue-login swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest app=nginx-deploy
这里要注意是我们在配置文件种是定义了保存版本的数量,如果值为0,就不保存历史版本了,就不能实现回退功能。
spec:
replicas: 3
revisionHistoryLimit: 10 #保存历史版本的数量K8s 回滚 不是靠记忆 ,而是靠 旧版本的 ReplicaSet(RS)。
- 每一次更新 → 生成一个新 RS
- 每一次回滚 → 启用旧 RS,把 Pod 扩回去
你删除了旧 RS = 把历史版本的 "存档" 删了,就不能进行回滚
暂停和恢复Deployment
由于每次对pod template种的信息发生修改后,都会触发更新deployment操作,那么此时如果频繁修改信息,都会产生多次更新,而实际上只需要执行最后一次更新即可,就出现此类似情况可以暂停deployment的rollout。
# 暂停Deployment的更新
[root@k8s-master01 ~]# kubectl rollout pause deployment -n tcloud nginx-deploy
# 修改deploy的资源限制
[root@k8s-master01 ~]# kubectl set resources deployment -n tcloud nginx-deploy -c=vue-login --limits=cpu=200m,memory=256Mi --requests=cpu=100m,memory=128Mi
# 查看更新状态
[root@k8s-master01 ~]# kubectl rollout status deployment -n tcloud nginx-deploy
Waiting for deployment "nginx-deploy" rollout to finish: 0 out of 3 new replicas have been updated...
# 恢复更新
[root@k8s-master01 ~]# kubectl rollout resume deployment -n tcloud nginx-deploy
# 去观察pod
[root@k8s-master01 ~]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
nginx-deploy-795697b5bb-cczsd 1/1 Running 0 4s
nginx-deploy-795697b5bb-hvhcb 1/1 Running 0 5s
nginx-deploy-795697b5bb-ldt9g 1/1 Running 0 2s
# 删除deployment
[root@k8s-master01 ~]# kubectl delete -f yaml/deploy.yaml 3、StatefulSet
StatefulSet(有状态集,缩写为sts)常用于部署有状态的且需要有序启动的应用程序,比如在进行SpringCloud项目容器化时,Eureka的部署是比较适合用StatefulSet部署方式的,可以给每个Eureka实例创建一个唯一且固定的标识符,并且每个Eureka实例无需配置多余的service,其余SpringBoot应用可以直接通过Eureka的Headless Service即可进行注册。
什么是Headless:
和Deployment类似,一个StatefulSet也同样管理着基于相同容器规范的Pod。不同的是,StatefulSet为每个Pod维护了一个粘性标识。
而StatefulSet创建的Pod一般使用Headless Service(无头服务)进行Pod之前的通信,和普通的Service的区别在于Headless Service没有ClusterlP,它使用的是Endpoint进行互相通信,Headless一般的格式为:
statefulSetName-{0..N-1}.serviceName.namespace.svc.cluster.local
和普通Service的区别
| 特性 | 普通 Service (ClusterIP) | Headless Service (clusterIP: None) |
|---|---|---|
| 集群 IP | ✅ 分配一个固定 VIP | ❌ 无 IP |
| 负载均衡 | ✅ 自动轮询 / 随机转发 | ❌ 不负载均衡 |
| DNS 解析 | 返回 Service IP | 返回 所有匹配 Pod 的 IP 列表 |
| 访问方式 | service-name.namespace.svc |
直接访问单个 Pod :pod-name.service-name... |
| 适用场景 | 无状态应用(Deployment) | **有状态应用(StatefulSet)**Kubernetes |
创建StatefulSet
# 编辑创建StatefulSet的yaml文件
[root@k8s-master01 yaml]# vim statefulset.yaml
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: tcloud
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: tcloud
spec:
serviceName: "nginx"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
# 创建StatefulSet
[root@k8s-master01 yaml]# kubectl apply -f statefulset.yaml
# 查看创建的StatefulSet
[root@k8s-master01 yaml]# kubectl get statefulsets -n tcloud
NAME READY AGE
web 3/3 85s
# 查看创建的svc,和pod
[root@k8s-master01 yaml]# kubectl get svc,pod -n tcloud
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx ClusterIP None <none> 80/TCP 2m11s
NAME READY STATUS RESTARTS AGE
pod/web-0 1/1 Running 0 2m11s
pod/web-1 1/1 Running 0 2m10s
pod/web-2 1/1 Running 0 2m9s
# 测试pod访问StatefulSet创建的pod
[root@k8s-master01 ~]# kubectl run -it --image swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28 dns-test --restart=Never -n tcloud --rm /bin/sh
# 测试和pod是否可以通信 #web-0是pod名称,nginx是service名称
/ # ping web-0.nginx
PING web-0.nginx (10.244.195.17): 56 data bytes
64 bytes from 10.244.195.17: seq=0 ttl=62 time=1.441 ms
64 bytes from 10.244.195.17: seq=1 ttl=62 time=0.351 ms
--- web-0.nginx ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max = 0.303/0.561/1.441 ms
/ # ping web-1.nginx
PING web-1.nginx (10.244.32.141): 56 data bytes
64 bytes from 10.244.32.141: seq=0 ttl=62 time=4.195 ms
--- web-1.nginx ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 4.195/4.195/4.195 ms
/ # ping web-2.nginx
PING web-2.nginx (10.244.135.139): 56 data bytes
64 bytes from 10.244.135.139: seq=0 ttl=62 time=0.736 ms
--- web-2.nginx ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.736/0.736/0.736 ms
# 测试pod映射的dns信息
/ # nslookup web-0.nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.195.17 web-0.nginx.tcloud.svc.cluster.local扩缩容StatefulSet
和 Deployment 类似,可以通过更新 replicas 字段扩容/缩容 StatefulSet,也可以使用kubectlscale、kubectl edit 和 kubectl patch 来扩/缩一个 StatefulSet.
# 把创建的StatefulSet的副本扩容为5个
[root@k8s-master01 ~]# kubectl scale sts -n tcloud web --replicas=5
# 查看pod部分数量
[root@k8s-master01 ~]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 1 (4m59s ago) 16h
web-1 1/1 Running 1 (4m58s ago) 16h
web-2 1/1 Running 1 (4m51s ago) 16h
web-3 1/1 Running 0 22s
web-4 1/1 Running 0 21s
# 把创建statefulset副本缩容为3个
[root@k8s-master01 ~]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 1 (6m9s ago) 16h
web-1 1/1 Running 1 (6m8s ago) 16h
web-2 1/1 Running 1 (6m1s ago) 16hStatefulSet更新策略
StatefulSet 提供两种更新策略:RollingUpdate(默认)与OnDelete ,核心区别在于是否自动有序更新 Pod,且 RollingUpdate 支持通过 partition 与 maxUnavailable 精细控制更新过程
RollingUpdate(金丝雀发布)
核心行为 :自动、有序、从高序号到低序号(如 web-2 → web-1 → web-0)更新,前一个 Pod 就绪后才更新下一个,确保稳定性。
例如我们有5个pod,如果当前partition设置为3,那么此时滚动更新时,只会更新那些序号>=3的pod
利用该机制,我们可以通过控制partition的值,来决定只更新其中一部分pod,确认没有问题后再主键增大更新的pod数量,最终实现全部pod更新
# 修改partition的数量
[root@k8s-master01 ~]# kubectl edit sts -n tcloud web
...
updateStrategy:
rollingUpdate:
partition: 2
type: RollingUpdate
# 这样我们更新的时候,只有pod名称大于2等于2的podvai进行更新
# 修改镜像
[root@k8s-master01 ~]# kubectl set image statefulset -n tcloud web nginx=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
# 查看pod使用的镜像
[root@k8s-master01 ~]# kubectl get pods -n tcloud -o custom-columns=NAME:.metadata.name,IMAGE:.spec.containers[*].image
NAME IMAGE
web-0 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-1 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-2 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
web-3 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
web-4 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
可以看到只有>=2的pod进行了镜像更新
# statefulset也支持版本回滚
[root@k8s-master01 ~]# kubectl rollout history statefulset -n tcloud
statefulset.apps/web
REVISION CHANGE-CAUSE
1 <none>
2 <none>
# 回退版本
[root@k8s-master01 ~]# kubectl rollout undo statefulset -n tcloud web --to-revision=1
# 查看pod的镜像
[root@k8s-master01 ~]# kubectl get pods -n tcloud -o custom-columns=NAME:.metadata.name,IMAGE:.spec.containers[*].image
NAME IMAGE
web-0 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-1 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-2 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-3 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-4 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0OnDelete(手动触发)
核心行为 :不自动更新,仅在手动删除 Pod 时,才用新模板重建,完全由运维控制顺序与节奏
# 修改更新策略OnDelete
[root@k8s-master01 ~]# kubectl edit statefulset -n tcloud web
...
updateStrategy:
#rollingUpdate:
# partition: 2
type: OnDelete
# 修改StatefulSet的镜像
[root@k8s-master01 ~]# kubectl set image statefulset -n tcloud web nginx=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
# 查看pod的镜像是否发生改变
[root@k8s-master01 ~]# kubectl get pods -n tcloud -o custom-columns=NAME:.metadata.name,IMAGE:.spec.containers[*].image
NAME IMAGE
web-0 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-1 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-2 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-3 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-4 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
# 删除其中一个pod
[root@k8s-master01 ~]# kubectl delete pod web-2 -n tcloud
# 查看pod的镜像,可以看到只有删除的pod做了更新操作
[root@k8s-master01 ~]# kubectl get pods -n tcloud -o custom-columns=NAME:.metadata.name,IMAGE:.spec.containers[*].image
NAME IMAGE
web-0 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-1 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-2 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
web-3 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
web-4 registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0StatefulSet删除
级联删除
删除StaefulSet时,同时删除pod和service,但是pvc不能删除(重要数据不会丢失)
# 删除statefulSet和service
[root@k8s-master01 ~]# kubectl delete statefulset -n tcloud web
[root@k8s-master01 ~]# kubectl delete service -n tcloud nginx
# 查看pod,发现pod也同时删除了
[root@k8s-master01 ~]# kubectl get pod -n tcloud
No resources found in tcloud namespace.非级联删除
只删除StatefulSet本身,pod不会删除,还可以继续提供服务
# 重新创建出来
[root@k8s-master01 ~]# kubectl create -f yaml/statefulset.yaml
# 使用非级联删除,或者在kubectl delete命令后面加--cascade=orphan也是可以的
[root@k8s-master01 ~]# kubectl delete -f yaml/statefulset.yaml --cascade=orphan
service "nginx" deleted from tcloud namespace
statefulset.apps "web" deleted from tcloud namespace
# 查看statefulSet,service,pod
[root@k8s-master01 ~]# kubectl get statefulsets -n tcloud
No resources found in tcloud namespace.
[root@k8s-master01 ~]# kubectl get service -n tcloud
No resources found in tcloud namespace.
[root@k8s-master01 ~]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2m17s
web-1 1/1 Running 0 2m16s
web-2 1/1 Running 0 2m15s
web-3 1/1 Running 0 2m14s
web-4 1/1 Running 0 2m13s
可以看到pod还在继续提供服务
# 删除tcloud下的所有pod
[root@k8s-master01 ~]# kubectl delete pods -n tcloud --all
# 删除ControllerRevision(StatefulSet的快照版本),如果不删除这个这个快照就是一个残留垃圾
[root@k8s-master01 ~]# kubectl delete controllerrevision --all -n tcloud4、DaemonSet
DaemonSet类型的控制器可以保证在集群中的每一台(或指定)节点上都运行一个副本。一般适用于日志收集、节点监控等场景。也就是说,如果一个Pod提供的功能是节点级别的(每个节点都需要且只需要一个),那么这类Pod就适合使用DaemonSet类型的控制器创建。
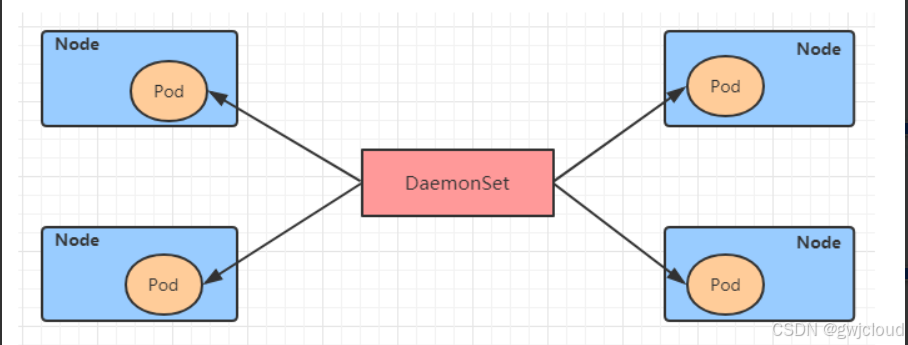
DaemonSet控制器的特点:
- 每当向集群中添加一个节点时,指定的 Pod 副本也将添加到该节点上
- 当节点从集群中移除时,Pod 也就被垃圾回收了
典型使用场景:
-
节点日志收集:fluentd、filebeat
-
节点监控采集:prometheus-node-exporter
-
网络插件:Calico、Flannel、Cilium
-
安全 / 运维代理:节点级堡垒机、监控探针
-
存储客户端:每个节点挂载存储驱动
查看Calico网络的信息
[root@k8s-master01 ~]# kubectl get pod -n kube-system -o wide | grep calico-node
calico-node-8krq6 1/1 Running 4 (88m ago) 4d18h 192.168.1.13 k8s-node01
calico-node-fs4zn 1/1 Running 4 (88m ago) 4d18h 192.168.1.10 k8s-master01
calico-node-g6pr2 1/1 Running 4 (88m ago) 4d18h 192.168.1.11 k8s-master02
calico-node-l9m8k 1/1 Running 4 (88m ago) 4d18h 192.168.1.15 k8s-node03
calico-node-nj6jh 1/1 Running 4 (88m ago) 4d18h 192.168.1.14 k8s-node02
calico-node-ps59q 1/1 Running 4 (88m ago) 4d18h 192.168.1.12 k8s-master03
[root@k8s-master01 ~]# kubectl get daemonset -A
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system calico-node 6 6 6 6 6 kubernetes.io/os=linux 4d18h
可以看到Calico网络插件是在每一个节点都有一个的
创建DaemonSet
# 编辑创建DaemonSet的yaml文件
[root@k8s-master01 yaml]# vim daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: vue-login-ds
namespace: tcloud
spec:
selector:
matchLabels:
app: vue-login
template:
metadata:
labels:
app: vue-login
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# apply
[root@k8s-master01 yaml]# kubectl apply -f daemonset.yaml
# 查看pod,是在每一个不同的节点都运行了一个pod
[root@k8s-master01 yaml]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-ds-7vgdk 1/1 Running 0 2m24s 10.244.32.147 k8s-master01 <none> <none>
vue-login-ds-bbjff 1/1 Running 0 2m24s 10.244.85.210 k8s-node01 <none> <none>
vue-login-ds-hmfbh 1/1 Running 0 2m24s 10.244.122.135 k8s-master02 <none> <none>
vue-login-ds-kfcfz 1/1 Running 0 2m24s 10.244.58.211 k8s-node02 <none> <none>
vue-login-ds-lhdhg 1/1 Running 0 2m24s 10.244.195.26 k8s-master03 <none> <none>
vue-login-ds-p249q 1/1 Running 0 2m24s 10.244.135.147 k8s-node03 <none> <none>DaemonSet选择合适节点
# 给节点打标签,来指定Daemonset部署在匹配标签的节点上
[root@k8s-master01 yaml]# kubectl label nodes k8s-node02 k8s-node03 disktype=ssd
# 修改配置
[root@k8s-master01 yaml]# vim daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: vue-login-ds
namespace: tcloud
spec:
selector:
matchLabels:
app: vue-login
template:
metadata:
labels:
app: vue-login
spec:
nodeSelector:
disktype: ssd
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# apply
[root@k8s-master01 yaml]# kubectl apply -f daemonset.yaml
# 查看pod部署的节点
[root@k8s-master01 yaml]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-ds-9pkch 1/1 Running 0 54s 10.244.58.212 k8s-node02 <none> <none>
vue-login-ds-mlwjh 1/1 Running 0 54s 10.244.135.148 k8s-node03 <none> <none>
可以看到是匹配到我们定义的标签部署的
# 现在给K8S-node01加上标签
[root@k8s-master01 yaml]# kubectl label nodes k8s-node01 disktype=ssd
# 查看pod节点
[root@k8s-master01 yaml]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-ds-9pkch 1/1 Running 0 2m55s 10.244.58.212 k8s-node02 <none> <none>
vue-login-ds-fdh9p 1/1 Running 0 6s 10.244.85.211 k8s-node01 <none> <none>
vue-login-ds-mlwjh 1/1 Running 0 2m55s 10.244.135.148 k8s-node03 <none> <none>
可以看到k8s-node01节点自动部署了一个pod上去DaemonSet的更新回滚
如果添加了新节点或修改了节点标签(Label),DaemonSet将立刻向新匹配上的节点添加Pod,同时删除不能匹配的节点上的Pod。
在Kubernetes 1.6以后的版本中,可以在 DaemonSet 上执行滚动更新,未来的Kubernetes 版本将支持节点的可控更新。
DaemonSet 滚动更新 参考: https://kubernetes.io/docs/tasks/manage-daemon/update-daemon-
set/
DaemonSet 更新策略和 StatefulSet 类似,也有 OnDelete 和 RollingUpdate两种方式。
建议DaemonSet使用OnDelete更新策略:
-
DaemonSet是跑在每一台节点上的底层组件(日志、网络、监控),不能自动乱更、不能批量滚动重启,必须手动、一台一台更新。
-
如果使用RollingUpdate(自动滚动更新):节点 1 重启 → 节点 2 重启 → 节点 3 重启,日志瞬间消失、网络瞬间闪断、监控瞬间丢失
查看创建的DaemonSet的默认更新策略
[root@k8s-master01 yaml]# kubectl get daemonsets -n tcloud -o yaml
...
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate # 默认是RollingUpdate更新镜像
[root@k8s-master01 yaml]# kubectl set image daemonset -n tcloud vue-login-ds vue-login=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
查看历史版本,其实都是和Deployment和StatefulSet的一样
[root@k8s-master01 yaml]# kubectl rollout history daemonset -n tcloud vue-login-ds
daemonset.apps/vue-login-ds
REVISION CHANGE-CAUSE
1
2
3
4回退
[root@k8s-master01 yaml]# kubectl rollout undo daemonset -n tcloud vue-login-ds --to-revision=1
查看pod
[root@k8s-master01 yaml]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
vue-login-ds-87fkk 1/1 Running 0 12s
vue-login-ds-8qwcr 1/1 Running 0 12s
vue-login-ds-d2tst 1/1 Running 0 12s
vue-login-ds-hh65z 1/1 Running 0 12s
vue-login-ds-rt25j 1/1 Running 0 12s
vue-login-ds-smw9j 1/1 Running 0 12sDaemonSet的快照版本是保存到controllerrevisions里面的
[root@k8s-master01 yaml]# kubectl get controllerrevisions -n tcloud
NAME CONTROLLER REVISION AGE
vue-login-ds-549bd696c4 daemonset.apps/vue-login-ds 7 22m
vue-login-ds-588b567448 daemonset.apps/vue-login-ds 6 15m
vue-login-ds-59c4448d8b daemonset.apps/vue-login-ds 4 5m10s
vue-login-ds-5c8c5db5f6 daemonset.apps/vue-login-ds 5 14m删除DaemonSet相关的资源
[root@k8s-master01 yaml]# kubectl delete -f daemonset.yaml
删除标签
[root@k8s-master01 yaml]# kubectl label nodes k8s-node01 k8s-node02 k8s-node03 disktype-
5、HPA
HPA:Horizontal Pod Autoscaler,pod水平自动扩缩容
- 水平:增加 / 减少pod数量(横向扩容)
- 垂直:升级CPU内存
- 作用:根据负载指标,自动调整Deployment,StatefulSet的副本数
支持管控对象:
- Deployment
- StatefulSet
常用监控指标
- cpu使用率(最常用)
- 内存使用率
- 自定义指标:QPS、连接数、列队长度等
工作原理
- HPA 定期(默认 15s)从 Metrics Server 采集指标
- 对比你设定的阈值
- 计算公式算出需要的副本数
- 调用控制器 API 修改 replicas
前提:集群必须安装了Metrics Server,否则HPA拿不到数据。
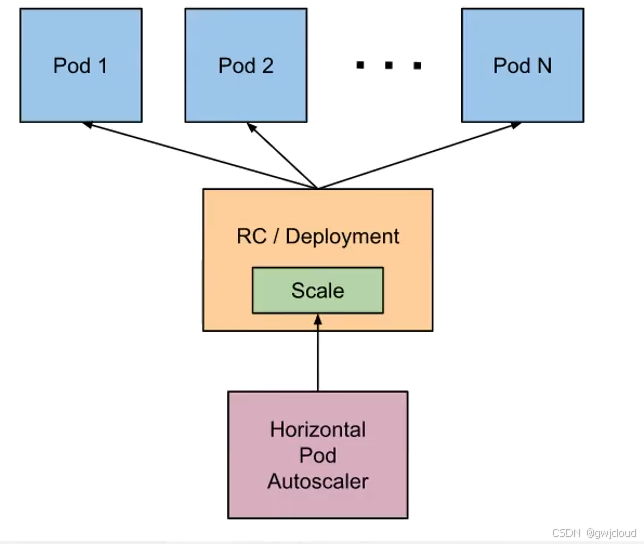
# 创建Deployment配置文件,副本数量为1
# 注意实现cpu或内存的监控,首先有个前提条件是该对象必须配置了
resources.requests.cpu
resources.requests.memory
才可以,可以配置当cpu/memory达到上述配置的百分比后进行扩容或缩
[root@k8s-master01 yaml]# vim deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy
name: nginx-deploy
namespace: tcloud
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx-deploy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: nginx-deploy
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
name: vue-login
resources: # 资源配额
limits: # 限制资源(上限)
cpu: "200m" # CPU限制
memory: 128Mi
requests: # 请求资源(下限)
cpu: "100m" # CPU限制
memory: 128Mi
restartPolicy: Always
terminationGracePeriodSeconds: 30
# apply
[root@k8s-master01 yaml]# kubectl apply -f deploy.yaml
# 查看pod
[root@k8s-master01 yaml]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
nginx-deploy-795697b5bb-bhjtv 1/1 Running 0 6s
# 准备service文件,我们需要压力测试,所以要配置service
[root@k8s-master01 HPA]# vim service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-deploy-svc
namespace: tcloud
spec:
selector:
app: nginx-deploy
ports:
- port: 80
targetPort: 80
nodePort: 30080
type: NodePort
[root@k8s-master01 HPA]# kubectl apply -f service.yaml
# 准备hpayaml文件
[root@k8s-master01 HPA]# vim hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-deploy-hpa
namespace: tcloud
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deploy
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 5
[root@k8s-master01 HPA]# kubectl apply -f hpa.yaml
说明:
minReplicas: 1 #最小pod数量
maxReplicas: 10 #最大pod数量
targetCPUUtilizationPercentage: 5 # CPU使用率指标,,如果cpu使用率达到5%就会进行扩容;为了测试方便,将这个数值调小一些
生成环境一般是70%~80%
HPA不是靠标签匹配对应的控制器!是靠 名字 + 类型 + 版本 匹配!
# 查看HPA的信息
[root@k8s-master01 HPA]# kubectl get hpa -n tcloud
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deploy-hpa Deployment/nginx-deploy cpu: 0%/5% 1 10 1 4m5s
# 使用webbench压力测试
[root@k8s-node03 ~]# wget http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gz
[root@k8s-node03 ~]# tar -zxvf webbench-1.5.tar.gz
[root@k8s-node03 ~]# mkdir -p /usr/local/man/man1
[root@k8s-node03 ~]# cd webbench-1.5/
[root@k8s-node03 webbench-1.5]# make install
# 只执行压力测试命令前,打开3个检测窗口查看hpa,deployment和pod的变化
[root@k8s-master01 HPA]# kubectl get pod -n tcloud -w
[root@k8s-master01 ~]# kubectl get hpa -n tcloud -w
[root@k8s-master01 ~]# kubectl get deployment -n tcloud -w
# 用500个并发用户,持续访问60s,压力测试
[root@k8s-node03 ~]# webbench -t 60 -c 500 http://192.168.1.100:30080/
# 可以看到pod在持续的增加
[root@k8s-master01 HPA]# kubectl get pod -n tcloud -w
NAME READY STATUS RESTARTS AGE
nginx-deploy-69c945b7dd-cqqqb 1/1 Running 0 15m
nginx-deploy-69c945b7dd-8ggxr 0/1 Pending 0 0s
nginx-deploy-69c945b7dd-5cjgz 0/1 Pending 0 0s
nginx-deploy-69c945b7dd-8ggxr 0/1 Pending 0 0s
nginx-deploy-69c945b7dd-gm64x 0/1 Pending 0 0s
nginx-deploy-69c945b7dd-5cjgz 0/1 Pending 0 0s
nginx-deploy-69c945b7dd-gm64x 0/1 Pending 0 0s
nginx-deploy-69c945b7dd-8ggxr 0/1 ContainerCreating 0 0s
nginx-deploy-69c945b7dd-5cjgz 0/1 ContainerCreating 0 0s
nginx-deploy-69c945b7dd-gm64x 0/1 ContainerCreating 0 0s
nginx-deploy-69c945b7dd-8ggxr 1/1 Running 0 1s
nginx-deploy-69c945b7dd-5cjgz 1/1 Running 0 1s
nginx-deploy-69c945b7dd-gm64x 1/1 Running 0 1s
# HPA的负载值也要持续的升高
[root@k8s-master01 ~]# kubectl get hpa -n tcloud -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deploy-hpa Deployment/nginx-deploy cpu: 0%/5% 1 10 1 12m
nginx-deploy-hpa Deployment/nginx-deploy cpu: 59%/5% 1 10 1 16m
nginx-deploy-hpa Deployment/nginx-deploy cpu: 0%/5% 1 10 4 16m
nginx-deploy-hpa Deployment/nginx-deploy cpu: 40%/5% 1 10 8 17m
nginx-deploy-hpa Deployment/nginx-deploy cpu: 29%/5% 1 10 10 17m
nginx-deploy-hpa Deployment/nginx-deploy cpu: 27%/5% 1 10 10 17m
# deployment的副本数也在持续的增加
[root@k8s-master01 ~]# kubectl get deployment -n tcloud -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 1/1 1 1 15m
nginx-deploy 1/4 1 1 18m
nginx-deploy 1/4 1 1 18m
nginx-deploy 1/4 1 1 18m
nginx-deploy 1/4 4 1 18m
nginx-deploy 2/4 4 2 18m
nginx-deploy 3/4 4 3 18m
nginx-deploy 4/4 4 4 18m
nginx-deploy 4/8 4 4 19m
nginx-deploy 4/8 4 4 19m
nginx-deploy 4/8 4 4 19m
nginx-deploy 4/8 8 4 19m
nginx-deploy 5/8 8 5 19m
nginx-deploy 6/8 8 6 19m
nginx-deploy 7/8 8 7 19m
nginx-deploy 8/8 8 8 19m
nginx-deploy 8/10 8 8 19m
nginx-deploy 8/10 8 8 19m
nginx-deploy 8/10 8 8 19m
nginx-deploy 8/10 10 8 19m
nginx-deploy 9/10 10 9 19m
nginx-deploy 10/10 10 10 19m等待自动缩容
k8s的HPA有两个默认等待时间:扩容3分钟,缩容5分钟,即使CPU立刻降到0%,HPA也会等待5分钟才开始缩容,为了防止流量抖动
# 5分钟后我们查看pod 只剩下我们默认的1副本了
[root@k8s-master01 HPA]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
nginx-deploy-69c945b7dd-75m9v 1/1 Running 0 10m四、服务发布
1、Servcie
1)service介绍
在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。
为了解决这个问题,kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址。通过访问Service的入口地址就能访问到后面的pod服务。
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行着一个kube-proxy服务进程。当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种Service的变动,然后它会将最新的Service信息转换成对应的访问规则。
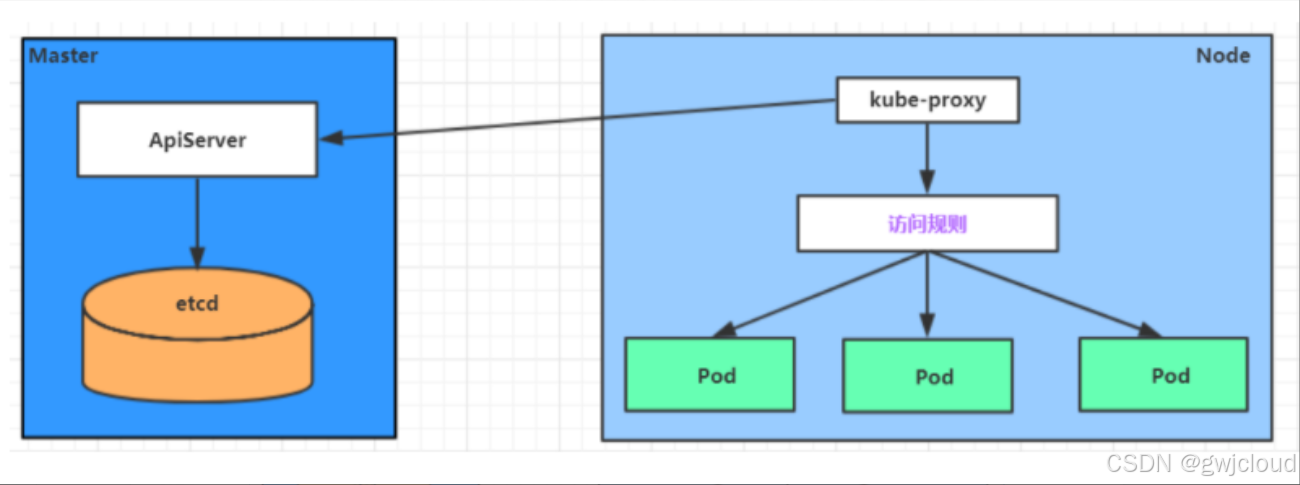
kube-proxy目前支持三种工作模式:
userspace 模式
userspace模式下,kube-proxy会为每一个Service创建一个监听端口,发向Cluster IP的请求被Iptables规则重定向到kube-proxy监听的端口上,kube-proxy根据LB算法选择一个提供服务的Pod并和其建立链接,以将请求转发到Pod上。 该模式下,kube-proxy充当了一个四层负责均衡器的角色。由于kube-proxy运行在userspace中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然比较稳定,但是效率比较低。
iptables 模式
iptables模式下,kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod IP。 该模式下kube-proxy不承担四层负责均衡器的角色,只负责创建iptables规则。该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端Pod不可用时也无法进行重试。
ipvs模式
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。
此模式必须安装ipvs内核模块,否则会降级为iptables
2)Service、pod、endpoint的关系
-
Service 定义筛选规则 Service 通过
spec.selector定义标签规则(比如app: nginx-pod),表示:"我要管理所有带这个标签的 Pod"。但 Service 本身不直接管理 Pod,它只负责提供访问入口。
-
Endpoint 自动匹配并记录 Pod 地址 Kubernetes 控制器会监听 Service 的
selector,自动:- 筛选出集群中所有匹配标签的 Pod
- 把这些 Pod 的
IP:容器端口记录到对应的 Endpoint 对象里这个过程是全自动 的,你不用手动创建或修改 Endpoint。(K8s 1.21+ 已默认用更高效的EndpointSlice替代传统Endpoint,但逻辑是一样的)
-
Service 通过 Endpoint 转发流量当你访问 Service 的 ClusterIP/NodePort/ 域名时:
- 集群内的 kube-proxy 会根据 Service 的配置,从对应的 Endpoint 列表里拿到所有健康的 Pod 地址
- 按负载均衡策略(轮询、随机等)把请求转发给其中一个 Pod
- 如果 Pod 挂了 / 重建了,Endpoint 会自动更新列表,Service 永远只会转发给健康的 Pod

3)servcie类型
| 类型 | 作用 | 访问方式 | 适用场景 |
|---|---|---|---|
| ClusterIP(默认) | 集群内部 IP,仅集群内可访问 | ClusterIP:端口 |
内部服务间调用,比如后端服务、中间件 |
| NodePort | 节点上开端口,外部可访问 | 节点IP:NodePort |
开发 / 测试环境,快速对外暴露服务 |
| LoadBalancer | 云厂商提供的外部负载均衡器 | LB公网IP:端口 |
生产环境,云平台上对外提供服务 |
| ExternalName | 将服务映射到外部域名 | 集群内访问服务名 → 转发到外部域名 | 访问外部服务、第三方接口 |
| Headless(ClusterIP: None) | 无 ClusterIP,直接返回 Pod IP | DNS 解析返回所有 Pod IP | StatefulSet、数据库、有状态应用 |
# 首先创建一个deployment
[root@k8s-master01 Service]# vim deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-login-pod
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# apply
[root@k8s-master01 Service]# kubectl apply -f deployment.yaml
# 写入测试数据
kubectl exec -it pod/vue-login-pod-775f6f875-2mg9r -n tcloud -- bash
echo "nginx1" > /usr/share/nginx/html/index.html
kubectl exec -it pod/vue-login-pod-775f6f875-77njk -n tcloud -- bash
echo "nginx2" > /usr/share/nginx/html/index.html
kubectl exec -it pod/vue-login-pod-775f6f875-h2b4m -n tcloud -- bash
echo "nginx3" > /usr/share/nginx/html/index.htmlClusterIP
ClusterIP 是 K8s Service 默认类型。
作用:给 Service 分配一个集群内部的固定虚拟 IP。
核心特点
-
仅集群内部可访问(其他 Pod、节点能通,外网 / 外部机器访问不了)
-
IP 永久固定,不会随 Pod 删除、重建、漂移而改变
-
自动关联 Endpoint,实现负载均衡,分发流量到后端多个 Pod
创建ClusterIP的yaml文件
[root@k8s-master01 Service]# vim service-clusterip.yaml
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: tcloud
spec:
selector:
app: nginx-pod
clusterIP:
type: ClusterIP
ports:- port: 80 # Service端口
targetPort: 80 # pod端口
apply
[root@k8s-master01 Service]# kubectl apply -f service-clusterip.yaml
查看Service的信息
[root@k8s-master01 Service]# kubectl get svc -n tcloud
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-clusterip ClusterIP 10.96.231.7480/TCP 104s 查看Service的详细信息
在这里有一个Endpoints列表,里面就是当前service可以转发到的pod
[root@k8s-master01 Service]# kubectl describe svc service-clusterip -n tcloud
Name: service-clusterip
Namespace: tcloud
Labels:
Annotations:
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.231.74
IPs: 10.96.231.74
Port:80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.195.31:80,10.244.135.157:80,10.244.58.220:80
Session Affinity: None
Internal Traffic Policy: Cluster
Events:也创建了一个endpoint
[root@k8s-master01 Service]# kubectl get endpoints -n tcloud
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
NAME ENDPOINTS AGE
service-clusterip 10.244.135.157:80,10.244.195.31:80,10.244.58.220:80 6m12s查看ipvs的映射关系
[root@k8s-master01 Service]# ipvsadm -Ln
...
TCP 10.96.231.74:80 rr
-> 10.244.58.220:80 Masq 1 0 0
-> 10.244.135.157:80 Masq 1 0 0
-> 10.244.195.31:80 Masq 1 0 0
是我们的Service IP转发到3个pod上看到上面的规则是rr(轮询),访问测试
[root@k8s-master01 Service]# while true;do curl 10.96.231.74;sleep 2; done;
nginx3
nginx1
nginx2创建pod通过service name镜像访问,是pod来通信的方式
创建2个不同命名空间下的pod(busybox)
[root@k8s-master01 yaml]# kubectl get pods -l app=dnstest --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default busybox 1/1 Running 0 10m
tcloud busybox 1/1 Running 0 9m36s基于同命名空间下的访问
[root@k8s-master01 yaml]# kubectl exec -it busybox -n tcloud -- sh
/ # wget http://service-clusterip
Connecting to service-clusterip (10.96.231.74:80)
index.html 100% |****************************************************************************************************************************************************************| 7 0:00:00 ETA
/ # cat index.html
nginx3
/ # rm -rf index.html进入默认命名空间下的pod(busybox)
service-clusterip是Service的名字
[root@k8s-master01 yaml]# kubectl exec -it busybox -n default -- sh
/ # wget http://service-clusterip.tcloud
Connecting to service-clusterip.tcloud (10.96.231.74:80)
index.html 100% |****************************************************************************************************************************************************************| 7 0:00:00 ETA
/ # cat index.html
nginx3
/ # rm -rf index.html - port: 80 # Service端口
负载分发策略
对Service的访问被分发到了后端的Pod上去,目前kubernetes提供了两种负载分发策略:
- 如果不定义,默认使用kube-proxy的策略,比如随机、轮询
- 基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上
此模式可以使在spec中添加sessionAffinity:ClientIP选项
# 修改yaml文件配置基
[root@k8s-master01 Service]# vim service-clusterip.yaml
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: tcloud
spec:
sessionAffinity: ClientIP
selector:
app: nginx-pod
clusterIP:
type: ClusterIP
ports:
- port: 80 # Service端口
targetPort: 80 # pod端口
# apply
[root@k8s-master01 Service]# kubectl apply -f service-clusterip.yaml
# 查看ipvs规则【persistent 代表持久】
[root@k8s-master01 Service]# ipvsadm -Ln
TCP 10.96.152.16:80 rr persistent 10800
-> 10.244.58.220:80 Masq 1 0 0
-> 10.244.135.157:80 Masq 1 0 0
-> 10.244.195.31:80 Masq 1 0 0
# 用不同的节点访问测试
[root@k8s-master01 Service]# while true;do curl 10.96.152.16:80; sleep 2; done;
nginx2
nginx2
[root@k8s-master02 ~]# while true;do curl 10.96.152.16:80; sleep 2; done;
nginx1
nginx1
# 删除service
[root@k8s-master01 Service]# kubectl delete -f service-clusterip.yaml HeadLiness
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询。
[root@k8s-master01 Service]# vim service-headliness.yaml
apiVersion: v1
kind: Service
metadata:
name: service-headliness
namespace: tcloud
spec:
selector:
app: nginx-pod
clusterIP: None # 将clusterIP设置为None,即可创建headliness Service
type: ClusterIP
ports:
- port: 80
targetPort: 80
# apply
[root@k8s-master01 Service]# kubectl apply -f service-headliness.yaml
# 查看service信息
[root@k8s-master01 Service]# kubectl get svc -n tcloud
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-headliness ClusterIP None <none> 80/TCP 20s
[root@k8s-master01 Service]# kubectl describe svc service-headliness -n tcloud
Name: service-headliness
Namespace: tcloud
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: None
IPs: None
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.195.31:80,10.244.135.157:80,10.244.58.220:80
Session Affinity: None
Internal Traffic Policy: Cluster
Events: <none>
# 进入pod测试访问
[root@k8s-master01 Service]# kubectl exec -it busybox -n tcloud -- sh
/ # nslookup service-headliness
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: service-headliness
Address 1: 10.244.135.157 10-244-135-157.service-headliness.tcloud.svc.cluster.local
Address 2: 10.244.58.220 10-244-58-220.service-headliness.tcloud.svc.cluster.local
Address 3: 10.244.195.31 10-244-195-31.service-headliness.tcloud.svc.cluster.local
# 删除svc
[root@k8s-master01 Service]# kubectl delete -f service-headliness.yaml 注意:
核心:K8s 不做负载均衡
- 没有 ClusterIP
- kube-proxy 不转发、不轮询
- DNS 直接解析出全部后端 Pod 真实 IP(你刚才 nslookup 看到的 3 个 IP)
- 谁调用,谁自己决定连哪个 Pod(客户端自己选、自己做负载 / 轮询)
NodePort
在之前的样例中,创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外部使用,那么就要使用到另外一种类型的Service,称为NodePort类型。NodePort的工作原理其实就是将service的端口映射到Node的一个端口上,然后就可以通过NodeIp:NodePort来访问service了。
# 创建NodePort的yaml文件
[root@k8s-master01 Service]# vim service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
namespace: tcloud
spec:
selector:
app: nginx-pod
type: NodePort # service类型
ports:
- port: 80
nodePort: 30002 # 指定绑定的node的端口(默认的取值范围是:30000-32767), 如果不指定,会默认分配
targetPort: 80
# apply
[root@k8s-master01 Service]# kubectl apply -f service-nodeport.yaml
# 查看SVC信息
[root@k8s-master01 Service]# kubectl get svc -n tcloud
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-nodeport NodePort 10.96.82.157 <none> 80:30002/TCP 6s
[root@k8s-master01 Service]# kubectl describe svc -n tcloud service-nodeport
[root@k8s-master01 Service]# kubectl get endpoints -n tcloud
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
NAME ENDPOINTS AGE
service-nodeport 10.244.135.157:80,10.244.195.31:80,10.244.58.220:80 66s
# 通过游览器访问或者某个节点访问,访问任何一个节点的ip加上端口都可以访问
[root@k8s-master01 Service]# while true;do curl 192.168.1.100:30002; sleep 2; done;
nginx1
nginx2
nginx3
注意:生成环境不推荐使用NodePort
核心原因:
- 端口范围受限NodePort 端口固定范围:30000--32767,端口号固定、不灵活。
- 安全风险高所有集群节点都会统一监听该端口,外网 / 内网只要能连通任意节点 IP + 端口,就能直接访问服务,暴露面太大。
- 性能一般、架构不优雅流量链路:外网IP → 节点NodePort → kube-proxy → Pod多层转发,不适合高并发生产。
- 无统一入口、不好维护集群多节点时,用户要记多个节点 IP,无法统一域名接入。
LoadBalancer
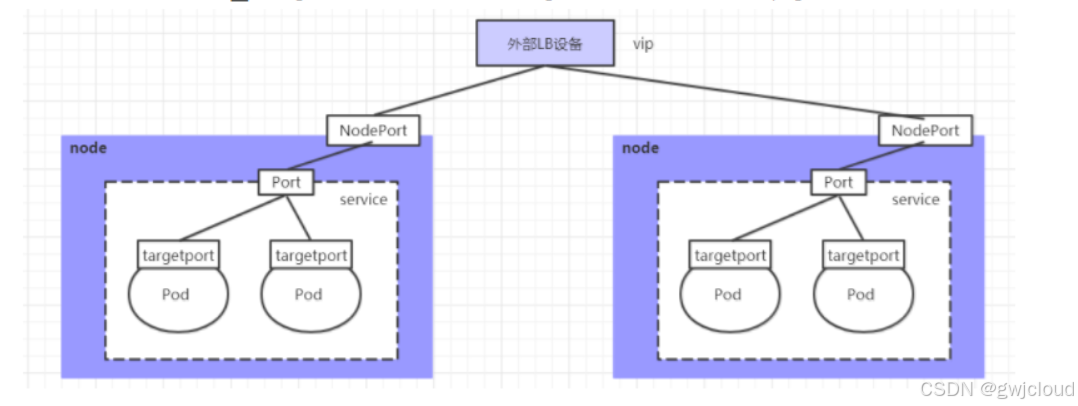
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群的外部再来做一个负载均衡设备,而这个设备需要外部环境支持的,外部服务发送到这个设备上的请求,会被设备负载之后转发到集群中。
ExternalName
ExternalName类型的Service用于引入集群外部的服务,它通过externalName属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务了。
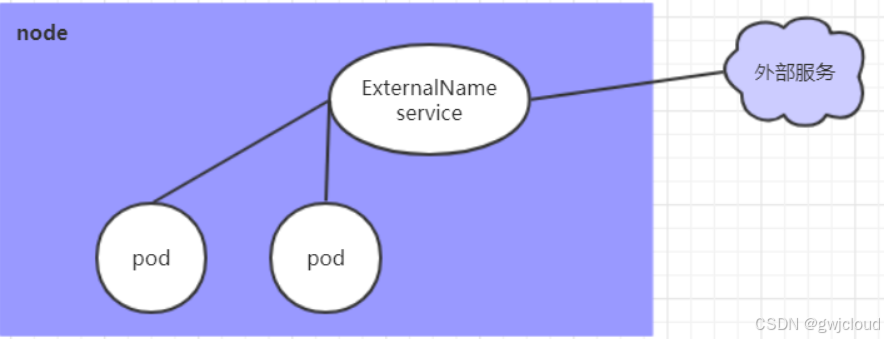
代理外部域名
使用场景:
对方服务不在本集群、不在本命名空间,只有一个外网域名;内部统一用 k8s 内网域名访问,方便治理、权限收敛。
# 创建externalnam.yaml
[root@k8s-master01 Service]# vim externalnam.yaml
apiVersion: v1
kind: Service
metadata:
name: service-externalname
namespace: tcloud
spec:
type: ExternalName # service类型
externalName: www.baidu.com #改成ip地址也可以
# apply
[root@k8s-master01 Service]# kubectl apply -f externalnam.yaml
[root@k8s-master01 Service]# kubectl get svc -n tcloud
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-externalname ExternalName <none> www.baidu.com <none> 12s
# pod访问测试
[root@k8s-master01 Service]# kubectl exec -it busybox -n tcloud -- sh
/ # nslookup service-externalname
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: service-externalname
Address 1: 240e:83:205:1cd:0:ff:b0b8:dee9
Address 2: 240e:83:205:381:0:ff:b00f:96a2
Address 3: 220.181.111.232
Address 4: 220.181.111.1
说明:
ExternalName 正常解析到 www.baidu.com 的真实 IP/IPv6;
K8s DNS 转发域名解析 一切正常;
/ # wget http://service-externalname
Connecting to service-externalname (220.181.111.1:80)
wget: server returned error: HTTP/1.1 403 Forbidden
说明:
映射成功这里403只是百度服务器做了限制,不允许IP方式访问
# 删除Service
[root@k8s-master01 Service]# kubectl delete -f externalnam.yaml 代理多个外部ip
只有一种情况,架构不规范,没做中间件高可用层,不然是由统一的服务入口的
场景 :K8s 内部要访问 2 台外部 MySQL(192.168.5.10、192.168.5.11) 通过 Service 统一入口 + 自动负载均衡
方案:无 selector 的 ClusterIP Service + 手动 Endpoint 写入多个外部 IP
# 创建service-mysql.yaml
[root@k8s-master01 Service]# vim service-mysql.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-external-svc
namespace: tcloud
spec:
type: ClusterIP # 默认类型,自带负载均衡
ports:
- port: 3306 # Service 访问端口
targetPort: 3306 # 外部真实端口
# 查看信息发现是没有创建endpoint的,因为没有selector去代理的pod
[root@k8s-master01 Service]# kubectl get svc -n tcloud
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql-external-svc ClusterIP 10.96.243.240 <none> 3306/TCP 5s
[root@k8s-master01 Service]# kubectl get endpoints -n tcloud
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
No resources found in tcloud namespace.
# 看servcie的详细信息
[root@k8s-master01 Service]# kubectl describe svc -n tcloud mysql-external-svc
Name: mysql-external-svc
Namespace: tcloud
Labels: <none>
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.243.240
IPs: 10.96.243.240
Port: <unset> 3306/TCP
TargetPort: 3306/TCP
Endpoints: <none>
Session Affinity: None
Internal Traffic Policy: Cluster
Events: <none>
发现Endpoints是空的
# 创建endpoint yaml文件
[root@k8s-master01 Service]# vim endpoint-mysql.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: mysql-external-svc # 必须和 Service 名字一模一样
namespace: tcloud
subsets:
- addresses:
- ip: 192.168.5.10 # 外部MySQL 1
- ip: 192.168.5.11 # 外部MySQL 2
ports:
- port: 3306 # 端口必须一致
# apply
[root@k8s-master01 Service]# kubectl apply -f endpoint-mysql.yaml
# 查看ipvsadm规则
[root@k8s-master01 Service]# ipvsadm -Ln
TCP 10.96.243.240:3306 rr
-> 192.168.5.10:3306 Masq 1 0 0
-> 192.168.5.11:3306 Masq 1 0 0
# 这样就可以在pod中通过创建的service和外部的服务进行通信了
# 删除service和endpoint
[root@k8s-master01 Service]# kubectl delete -f service-mysql.yaml
我们是分开创建的,但是我们在后面把Servcie和Endpoint关联上了 所以只需要删除Service,endpoint也自动删除了2、Ingress
1)什么是Ingress
Ingress = K8s 七层反向代理 + 统一入口
核心作用:
用一个统一入口 ,通过域名 / 路径,转发到后端多个 Service
比喻:
- ClusterIP:内网房间,只能内部串门
- NodePort:每个房间单独开一扇小窗
- Ingress:小区统一大门,门卫按门牌(域名 / 路径)分发访客
核心能力
- 统一域名、统一 80/443 端口不用每个服务开端口,外网只暴露一个入口
- 域名路由
a.xxx.com→ 转发给 A-Serviceb.xxx.com→ 转发给 B-Service
- 路径路由
xxx.com/api→ 接口服务xxx.com/web→ 前端服务
- 强制 HTTPS、SSL 证书、限流、黑白名单、重定向
- 生产环境对外暴露业务的标准方案
架构组成
Ingress 由两部分组成:
- **Ingress 资源(规则)**YAML 写的路由规则:域名、路径、对应哪个 Service
- **Ingress Controller(真正干活的)**实际是一个 Nginx/Traefik 这类反向代理 Pod没有 Controller,Ingress 规则只是摆设,不生效
2)Ingress Controller安装
安装有2种方式
1、使用yaml安装:kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/cloud/deploy.yaml
2、Helm安装(企业生产标准)
二进制包下载地址:https://github.com/helm/helm/releases
首先要确认Helm和Kubernetes适配的版本:
https://helm.sh/zh/docs/topics/version_skew/#supported-version-skew
| Helm Version | Supported Kubernetes Versions |
|---|---|
| 4.1.x | 1.35.x - 1.32.x |
| 4.0.x | 1.34.x - 1.31.x |
# 安装Helm(这里是使用的是最新版)
[root@k8s-master01 helm]# wget https://get.helm.sh/helm-v4.1.4-linux-amd64.tar.gz
# 解压
[root@k8s-master01 helm]# tar -zxvf helm-v4.1.4-linux-amd64.tar.gz
[root@k8s-master01 helm]# mv linux-amd64/helm /usr/local/bin/
[root@k8s-master01 helm]# helm version
version.BuildInfo{Version:"v4.1.4", GitCommit:"05fa37973dc9e42b76e1d2883494c87174b6074f", GitTreeState:"clean", GoVersion:"go1.25.9", KubeClientVersion:"v1.35"}
# helm 添加ingress-nginx源
[root@k8s-master01 helm]# helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
# 查看helm仓库
[root@k8s-master01 helm]# helm repo list
NAME URL
ingress-nginx https://kubernetes.github.io/ingress-nginx
# 搜索ingress-nginx
[root@k8s-master01 helm]# helm search repo ingress-nginx
NAME CHART VERSION APP VERSION DESCRIPTION
ingress-nginx/ingress-nginx 4.15.1 1.15.1 Ingress controller for Kubernetes using NGINX a...
# 下载ingress-nginx安装包
[root@k8s-master01 helm]# helm pull ingress-nginx/ingress-nginx
# 解压 下载完成后会有一个.tgz的安装包
[root@k8s-master01 helm]# tar -xf ingress-nginx-4.15.1.tgz
# 修改配置参数
[root@k8s-master01 ingress-nginx]# vim values.yaml
使用华为云的镜像:
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/ingress-nginx/controller:v1.15.1
wr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.6.9修改镜像仓库地址:默认是国内拉取不到
修改ingress-nginx/controller镜像,把sha注释掉

修改kube-webhook-certgen镜像,把sha注释掉
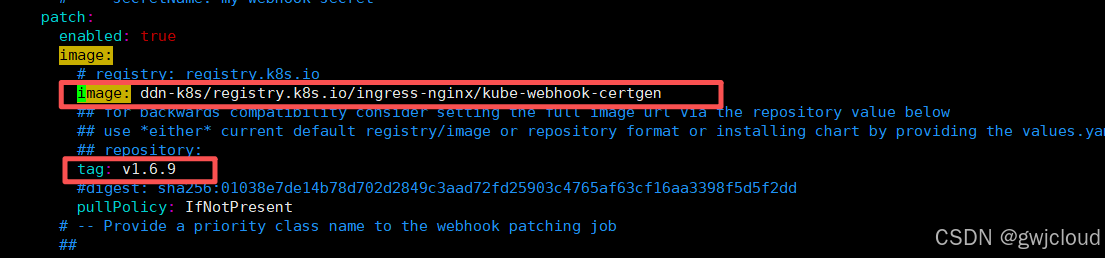
内网自建 K8s 集群 + HostNetwork 模式 → 必须用 DaemonSet
- 每个节点自动起一个 Ingress Pod LB 可以把流量转发到任意节点
- 高可用一个节点挂了,其他节点还能提供服务
- 端口不冲突HostNetwork 模式一个节点只能跑一个 Pod
- 性能最好无 Service 转发损耗,直接监听节点 80/443
修改DaemonSet
增加选择器,如果node上有ingress=true就部署ingress
更改hostNetwork为true(使用宿主机的网络)
- 开了 = Ingress 直接占用节点 80/443 端口 LB 才能把流量转发到 节点IP:80
- 不开 = 端口在容器内,外部访问不到 LB 无法对接,你的服务无法对外提供

更改dnsPolicy: ClusterFirstWithHostNet
使用Kubernetes 集群内部 DNS
修改service的类型 默认是LoadBalancer改成ClusterIP
关闭配置验效器enabled: false
# 创建ingress-nginx命名空间
[root@k8s-master01 ingress-nginx]# kubectl create ns ingress-nginx
# 给我们的节点k8s-master01打上我们自定义的标签ingress=true
[root@k8s-master01 ingress-nginx]# kubectl label nodes k8s-master01 ingress=true
# 安装ingress-nginx
[root@k8s-master01 ingress-nginx]# helm install ingress-nginx . -n ingress-nginx
看到STATUS: deployed 就是成功了3)创建ingress实例
# 准备deployment和Service的yaml文件
[root@k8s-master01 ingress]# pwd
/root/yaml/ingress
# deployment
[root@k8s-master01 ingress]# vim vue-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-login-pod
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# service
[root@k8s-master01 ingress]# vim vue-service.yaml
apiVersion: v1
kind: Service
metadata:
name: vue-login-service
namespace: tcloud
spec:
selector:
app: nginx-pod
ports:
- port: 80
targetPort: 80
type: ClusterIP
# apply
[root@k8s-master01 ingress]# kubectl apply -f deployment.yaml
[root@k8s-master01 ingress]# kubectl apply -f service.yaml
# 创建ingress yaml文件
[root@k8s-master01 ingress]# vim vue-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vue-login-ingress
namespace: tcloud
spec:
ingressClassName: nginx
rules:
- host: www.tcloud.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vue-login-service
port:
number: 80
# 说明
# 1. 固定配置:K8s 1.19+ 标准 Ingress API 版本(必填,低版本会报错)
apiVersion: networking.k8s.io/v1
kind: Ingress
# 2. 元数据(必须和你的服务保持一致)
metadata:
name: vue-login-ingress # Ingress 名称(自定义,唯一即可)
namespace: tcloud # ✅ 关键:必须和 Service/Deployment 同命名空间
# 3. 核心路由规则(最重要部分)
spec:
ingressClassName: nginx # ✅ 关键:指定使用 Nginx Ingress 控制器(必须写)
rules:
- host: www.tcloud.com # ✅ 关键:你指定的访问域名(本地要配 hosts)
http:
paths:
- path: / # ✅ 关键:匹配根路径(所有访问域名的流量都转发)
pathType: Prefix # 固定配置:前缀匹配(前端项目标准写法)
backend:
service:
name: vue-login-service # ✅ 关键:必须和你 Service 的 name 完全一致
port:
number: 80 # ✅ 关键:必须和你 Service 的 port 端口一致
# 测试访问
修改本机的C:\Windows\System32\drivers\etc\hosts 文件最后添加
192.168.1.10 www.tcloud.com
说明:192.168.1.10是集群中的任意一个节点IP
# 删除ingress
[root@k8s-master01 ingress]# kubectl delete -f vue-ingress.yaml 4)ingress域名主机http和https代理
准备基于tomcat镜像的deployment,servcie文件
# deployment
[root@k8s-master01 ingress]# vim tomcat-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-pod
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: tomcat-pod
template:
metadata:
labels:
app: tomcat-pod
spec:
containers:
- name: tomcat
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/tomcat:8.5-jdk8
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
# service
[root@k8s-master01 ingress]# vim tomcat-service.yaml
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
namespace: tcloud
spec:
selector:
app: tomcat-pod
ports:
- port: 80
targetPort: 8080
type: ClusterIP
# apply
[root@k8s-master01 ingress]# kubectl apply -f tomcat-deployment.yaml
[root@k8s-master01 ingress]# kubectl apply -f tomcat-service.yaml http代理
# 创建ingress httpd代理是的形式,我们前面创建的ingress就是http的代理
[root@k8s-master01 ingress]# vim http-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tcloud-ingress
namespace: tcloud
spec:
ingressClassName: nginx
rules:
# 第一个域名:Vue 前端
- host: www.tcloud.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vue-login-service
port:
number: 80
# 第二个域名:Tomcat 后端
- host: www.spring.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: tomcat-service
port:
number: 80
注意:复制格式有问题,vim的时候先执行:set paste(打开复制模式)
# apply
[root@k8s-master01 ingress]# kubectl apply -f http-ingress.yaml
# 查看ingress
[root@k8s-master01 ingress]# kubectl get ingress -n tcloud
NAME CLASS HOSTS ADDRESS PORTS AGE
tcloud-ingress nginx www.tcloud.com,www.spring.com 80 6s
# 查看详细信息,能看到域名已经代理到pod上
[root@k8s-master01 ingress]# kubectl describe ingress -n tcloud tcloud-ingress
Name: tcloud-ingress
Labels: <none>
Namespace: tcloud
Address: 10.96.26.248
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
www.tcloud.com
/ vue-login-service:80 (10.244.195.34:80,10.244.58.222:80,10.244.135.160:80)
www.spring.com
/ tomcat-service:80 (10.244.58.223:8080,10.244.195.35:8080,10.244.135.161:8080)
Annotations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 5s (x2 over 22s) nginx-ingress-controller Scheduled for sync配置本地的hosts文件
192.168.1.10 www.tcloud.com
192.168.1.10 www.spring.com
访问测试
这里404不是ingress没有代理到,是容器镜像本身的问题,tomcat没有默认的访问页。
# 删除http ingress
[root@k8s-master01 ingress]# kubectl delete -f http-ingress.yaml https代理
# 创建证书
[root@k8s-master01 ingress]# openssl req -x509 -nodes -days 3650 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=www.tcloud.com" -config <(cat <<EOF
[req]
distinguished_name = req_distinguished_name
x509_extensions = v3_req
prompt = no
[req_distinguished_name]
CN = www.tcloud.com
[v3_req]
subjectAltName = DNS:www.tcloud.com,DNS:www.spring.com
EOF
)
当前目录会直接生成两个文件:tls.crt(证书),tls.key(私钥)
# 把刚生成的 HTTPS 证书,存入 Kubernetes 集群,让 Ingress 可以读取并启用 HTTPS 加密访问
[root@k8s-master01 ingress]# kubectl create secret tls tcloud-tls -n tcloud --cert=tls.crt --key=tls.key
# 配置https的ingress yaml文件
[root@k8s-master01 ingress]# vim https-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vue-login-ingress
namespace: tcloud
annotations:
# 强制HTTP跳转HTTPS(访问http://xxx会自动跳https://xxx)
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/force-ssl-redirect: "true"
# 推荐的TLS协议版本(安全合规)
nginx.ingress.kubernetes.io/ssl-protocols: "TLSv1.2 TLSv1.3"
spec:
ingressClassName: nginx
# HTTPS TLS配置(关键部分)
tls:
- hosts:
- www.tcloud.com
- www.spring.com
secretName: tcloud-tls # 对应你刚才创建的Secret名称
# 保留你原来的HTTP路由规则
rules:
- host: www.tcloud.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vue-login-service
port:
number: 80
- host: www.spring.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: tomcat-service
port:
number: 80
# apply
[root@k8s-master01 ingress]# kubectl apply -f https-ingress.yaml
# 查看ingress的详细信息
[root@k8s-master01 ingress]# kubectl describe ingress -n tcloud vue-login-ingress
Name: vue-login-ingress
Labels: <none>
Namespace: tcloud
Address: 10.96.26.248
Ingress Class: nginx
Default backend: <default>
TLS:
tcloud-tls terminates www.tcloud.com,www.spring.com
Rules:
Host Path Backends
---- ---- --------
www.tcloud.com
/ vue-login-service:80 (10.244.195.34:80,10.244.58.222:80,10.244.135.160:80)
www.spring.com
/ tomcat-service:80 (10.244.58.223:8080,10.244.195.35:8080,10.244.135.161:8080)
Annotations: nginx.ingress.kubernetes.io/force-ssl-redirect: true
nginx.ingress.kubernetes.io/ssl-protocols: TLSv1.2 TLSv1.3
nginx.ingress.kubernetes.io/ssl-redirect: true
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 42s (x2 over 76s) nginx-ingress-controller Scheduled for sync
说明:
看到 TLS 那一列绑定了两个域名 + tcloud-tls,就代表 HTTPS 配置正常。添加本地hosts文件
192.168.1.10 www.tcloud.com
192.168.1.10 www.spring.com
访问测试
# 删除创建的资源
[root@k8s-master01 ingress]# kubectl delete secret tcloud-tls -n tcloud
[root@k8s-master01 ingress]# kubectl delete -f https-ingress.yaml
[root@k8s-master01 ingress]# kubectl delete -f tomcat-service.yaml
[root@k8s-master01 ingress]# kubectl delete -f tomcat-deployment.yaml
[root@k8s-master01 ingress]# kubectl delete -f vue-deployment.yaml
[root@k8s-master01 ingress]# kubectl delete -f vue-service.yaml五、配置管理
1、配置存储
ConfigMap
一、什么是ConfigMap
- ConfigMap 是 K8s 里专门存 "非敏感配置" 的键值对资源,用来把配置和容器镜像分开,改配置不用重新打包镜像Kubernetes。
生产业务痛点(为什么必须用 ConfigMap)
- 业务多环境:开发、测试、预发、生产,同一套程序镜像,数据库地址、Redis 地址、日志等级、接口域名、超时参数完全不一样;
- 禁止镜像固化配置:如果把
mysql地址、接口地址写死在代码 / 镜像里,改个参数就要重新打包、推送镜像、重启服务,上线风险极高; - 配置文件解耦:Nginx 配置、SpringBoot yml、日志 logback 配置、定时任务 cron 表达式,统一外部管理;
- 统一运维:运维统一维护配置,开发不用改代码,权限分离。
二、生产ConfigMap到底存什么
应用基础配置
- 环境标识:
env=prod、日志级别:log.level=info - 业务超时:接口超时、连接池大小、线程池参数
- 第三方接口:短信、OSS、支付非密钥类域名 / 地址
中间件连接非敏感参数
- Redis 集群地址、MQ 集群地址、ES 节点地址
- 数据库连接地址、库名(账号密码放 Secret)
完整的配置文件
- Nginx 反向代理配置、限流配置、静态资源配置
- SpringBoot
application-prod.yml - 日志配置文件、脚本配置、定时任务配置
三、pod如何使用ConfigMap
- 环境变量:把 ConfigMap 的 key 注入容器环境变量Kubernetes。
- 命令行参数:启动命令里引用 ConfigMap 的值Kubernetes。
- 挂载成文件:把 ConfigMap 里的 key 变成容器里的文件(最常用,比如 nginx 配置)Kubernetes。
key value形式创建加载ConfigMap
真实生产场景:用 ConfigMap 环境变量注入SpringBoot项目的 MySQL 连接地址
# 创建键值对的ConfigMap
[root@k8s-master01 configmap]# kubectl create configmap mysql-cm -n tcloud --from-literal=MYSQL_HOST=192.168.1.111 --from-literal=MYSQL_PORT=3306 --from-literal=MYSQL_DB=order_prod
[root@k8s-master01 configmap]# kubectl get configmap -n tcloud
NAME DATA AGE
kube-root-ca.crt 1 4d7h
mysql-cm 3 20s
[root@k8s-master01 configmap]# kubectl describe configmap -n tcloud mysql-cm
Name: mysql-cm
Namespace: tcloud
Labels: <none>
Annotations: <none>
Data
====
MYSQL_DB:
----
order_prod
MYSQL_HOST:
----
192.168.1.111
MYSQL_PORT:
----
3306
BinaryData
====
Events: <none>
可以看到configmap中有3个key=value形势的键值对这里使用busybox镜像代替SpringBoot项目的镜像
# 创建deployment挂载ConfigMap(mysql-cm)
[root@k8s-master01 configmap]# vim app-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-deploy
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: app
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sleep", "3600"]
# 重点:从 ConfigMap 注入环境变量
env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: mysql-cm #必须和我们的configmap文件一致
key: MYSQL_HOST
- name: DB_PORT
valueFrom:
configMapKeyRef:
name: mysql-cm
key: MYSQL_PORT
- name: DB_NAME
valueFrom:
configMapKeyRef:
name: mysql-cm
key: MYSQL_DB
#-------------使用envFrom全部引用(使用任意一种即可,推荐使用envFrom)-------------#
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-deploy
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: app
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sleep", "3600"]
# envFrom:一次性把 mysql-cm 里所有 key 都变成环境变量
envFrom:
- configMapRef:
name: mysql-cm原方式(env)
- 一个一个写
- 麻烦、容易写错
- 变量名可以自己改(DB_HOST → MYSQL_HOST)
envFrom 方式(推荐)
-
一行搞定全部
-
干净、简洁、不会错
apply
[root@k8s-master01 configmap]# kubectl apply -f app-deployment.yaml
验证pod是否挂载ConfigMap
[root@k8s-master01 configmap]# kubectl exec -it springboot-deploy-576698db4f-gbjvz -n tcloud -- env | grep DB
DB_HOST=192.168.1.111
DB_PORT=3306
DB_NAME=order_prod可以看到设置的没有问题
然后开发层面就可以是使用env的形式去定义SpringBoot的配置文件(application.yaml)当前这里不用演示。
spring:
datasource:
url: jdbc:mysql://{SPRING_DATASOURCE_HOST}:{SPRING_DATASOURCE_PORT}/${SPRING_DATASOURCE_DATABASE}比如我们现在数据库进行了迁移 IP地址更换了,需要在业务pod上更改SpringBoot项目数据库的连接地址
切换数据库地址
[root@k8s-master01 configmap]# kubectl edit cm mysql-cm -n tcloud
apiVersion: v1
data:
MYSQL_DB: order_prod
MYSQL_HOST: 192.168.1.100 # 修改连接地址
MYSQL_PORT: "3306"
kind: ConfigMap注意:修改完 ConfigMap → Pod 不会自动生效
必须 重建 / 重启 Pod 新 MySQL 地址才会生效
先验证一下pod的env受否修改
[root@k8s-master01 configmap]# kubectl exec -it springboot-deploy-576698db4f-gbjvz -n tcloud -- env | grep DB
DB_HOST=192.168.1.111
DB_PORT=3306
DB_NAME=order_prod重建pod 验证env
[root@k8s-master01 configmap]# kubectl delete pod springboot-deploy-576698db4f-gbjvz -n tcloud
查看pod中env的地址
[root@k8s-master01 configmap]# kubectl exec -it springboot-deploy-576698db4f-nswxc -n tcloud -- env | grep DB
DB_HOST=192.168.1.100
DB_PORT=3306
DB_NAME=order_prod
文件形式创建并加载ConfigMap
真实生产场景:配置文件(application.yml)挂载到 SpringBoot 项目服务里面
这里准备2个配置文件,创建到同一个ConfigMap里面,在pod中只单独加载application.yml文件
# 准备application.yml和nginx.conf文件
# -----application.yml----- #
spring:
datasource:
url: jdbc:mysql://192.168.1.100:3306/testdb
username: root
password: 123456
# -----nginx.conf----- #
# nginx配置
server {
# 可以写 80 最后运行可以重新映射
listen 80;
server_name localhost;
#charset koi8-r;
access_log /var/log/nginx/host.access.log main;
error_log /var/log/nginx/error.log error;
location / {
# root 根目录,默认nginx镜像的html文件夹,可以指定其他
root /usr/share/nginx/html;
index index.html index.htm;
# 如果vue-router使用的是history模式,需要设置这个
try_files $uri $uri/ /index.html;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
# 指定文件创建ConfigMap
[root@k8s-master01 configmap]# kubectl create configmap spring-configmap -n tcloud --from-file=application.yml --from-file=nginx.conf
# 查看ConfigMap的详细信息
[root@k8s-master01 configmap]# kubectl describe configmap -n tcloud spring-configmap
...
Data
====
application.yml:
----
spring:
datasource:
url: jdbc:mysql://192.168.1.100:3306/testdb
username: root
password: 123456
nginx.conf:
----
# nginx配置
server {
# 可以写 80 最后运行可以重新映射
listen 80;
server_name localhost;
...
# 创建加载ConfigMap的deployment文件
[root@k8s-master01 configmap]# vim springboot-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: springboot
template:
metadata:
labels:
app: springboot
spec:
containers:
- name: app
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sleep", "3600"]
# 挂载配置文件
volumeMounts:
- name: config-volume
mountPath: /app/config/application.yml
subPath: application.yml
# 定义卷:来自 configmap
volumes:
- name: config-volume
configMap:
name: spring-configmap
# 加载指定配置
items:
- key: application.yml
path: application.yml注意:mountPath: /app/config/application.yml 这里必须是完整文件路径
如果写成这样

kubernetes会把整个/app/config/目录替换掉,只保留application.yml文件,很多配置目录,不只有一个配置文件。
# apply
[root@k8s-master01 configmap]# kubectl apply -f springboot-deployment.yaml
# 查看springboot业务的pod的是否加载application.yml
[root@k8s-master01 configmap]# kubectl exec -it -n tcloud deployments/springboot -- ls /app/config/
application.yml
[root@k8s-master01 configmap]# kubectl exec -it -n tcloud deployments/springboot -- cat /app/config/application.yml
spring:
datasource:
url: jdbc:mysql://192.168.1.100:3306/testdb
username: root
password: 123456
# 修改application.yml配置中的数据库连接地址
[root@k8s-master01 configmap]# kubectl edit cm -n tcloud spring-configmap
spring:
datasource:
url: jdbc:mysql://192.168.1.111:3306/testdb # 修改连接地址
# 重启pod或者重启deployment
[root@k8s-master01 configmap]# kubectl rollout restart deployment -n tcloud springboot
# 查看配置生效
[root@k8s-master01 configmap]# kubectl exec -it -n tcloud deployments/springboot -- cat /app/config/application.yml
spring:
datasource:
url: jdbc:mysql://192.168.1.111:3306/testdb
username: root
password: 123456
# 如果这个时候想整个替换application.yml文件,不单纯是修改其中某一个值的情况
# 拿到新的application.yml文件可以执行
kubectl create configmap spring-configmap -n tcloud \
--from-file=application.yml \
--from-file=nginx.conf \
--dry-run=client -o yaml | kubectl replace -f -
# 在重启deployment即可
kubectl rollout restart deployment -n tcloud springboot
# 该命令的重点在于--dry-run参数,该参数的意思打印yaml文件,但不会将该文件发送给apiserver
# 再结合-oyaml输出 yaml文件就可以得到一个配置好但是没有发给apiserver的文件,
# 然后再结合replace监听控制台输出得到yaml数据即可实现替换
# 删除创建的deployment和configmap加载ConfigMap补充说明
如果我们很多文件创建了一个ConfigMap,挂载到同一个目录需要:
-
去掉 items(不限制文件,自动挂载全部)
-
挂载到一个目录,不要挂载到具体文件名
-
不要用 subPath(目录挂载不能用)
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: springboot
template:
metadata:
labels:
app: springboot
spec:
containers:
- name: app
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sleep", "3600"]# 挂载整个目录(两个文件都会进来) volumeMounts: - name: config-volume mountPath: /app/config # 挂载到目录,不是具体文件 volumes: - name: config-volume configMap: name: spring-configmap # 不写 items → 自动挂载所有文件
很多文件创建了一个ConfigMap文件,这个需要不同的文件需要挂载到pod中不同的目录下
- application.yml → 挂到 /app/config
- nginx.conf → 挂到 /etc/nginx
两个文件来自同一个 ConfigMap,但挂载到不同目录!
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: springboot
template:
metadata:
labels:
app: springboot
spec:
containers:
- name: app
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sleep", "3600"]
volumeMounts:
# 1. 挂载 application.yml 到 /app/config 目录
- name: app-config
mountPath: /app/config/application.yml
subPath: application.yml
# 2. 挂载 nginx.conf 到 /etc/nginx 目录
- name: nginx-config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
volumes:
# 第一个卷:只拿 application.yml
- name: app-config
configMap:
name: spring-configmap
items:
- key: application.yml
path: application.yml
# 第二个卷:只拿 nginx.conf
- name: nginx-config
configMap:
name: spring-configmap
items:
- key: nginx.conf
path: nginx.confSecret
Secret 是一种轻量级、用于存放敏感数据 的资源对象,底层做 Base64 编码(不是加密,仅简单编码防明文直看)
场景 1:容器环境变量注入敏感信息
将 Secret 内的键值对,直接作为 Pod 环境变量注入容器,程序读取环境变量拿密码。
场景 2:私有镜像仓库拉取认证
imagePullSecrets 绑定 Secret,存放镜像仓库账号密码,拉取私有镜像免认证配置。
secret的类型
| 类型 | 说明 | 适用场景 |
|---|---|---|
| Opaque | 默认通用类型(对应 generic 创建) |
密码、配置、自定义键值、任意私密文本 |
| kubernetes.io/service-account-token | 服务账号令牌 | SA 认证 |
| kubernetes.io/dockerconfigjson | 镜像仓库凭证 | 私有镜像仓库登录 |
| kubernetes.io/tls | TLS 证书秘钥 | HTTPS 证书、ssl 证书 |
Opaque
场景:springboot业务项目加载configmap配置文件夹,Secret存放数据库用户密码,防止明文查看
# 准备application.yml文件
[root@k8s-master01 secret]# vim application.yml
spring:
datasource:
url: jdbc:mysql://192.168.1.100:3306/testdb
username: ${DB_USERNAME}
password: ${DB_PASSWORD}
driver-class-name: com.mysql.cj.jdbc.Driver
# 创建configmap
[root@k8s-master01 secret]# kubectl create configmap springboot-cm -n tcloud --from-file=./application.yml
# 创建 Secret 注意:,密码有特殊符号,要使用单引号引起来
# generic 就是创建类型 Opaque
[root@k8s-master01 secret]# kubectl create secret generic db-secret -n tcloud --from-literal=DB_USERNAME='db_root' --from-literal=DB_PASSWORD='Qwe@123456!#'
# 查看secret的信息
[root@k8s-master01 secret]# kubectl get secret -n tcloud
NAME TYPE DATA AGE
db-secret Opaque 2 13s
[root@k8s-master01 secret]# kubectl describe secrets -n tcloud db-secret
Name: db-secret
Namespace: tcloud
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
DB_PASSWORD: 12 bytes
DB_USERNAME: 7 bytes
# 明文看不到,可以通过吧base64解码看到
[root@k8s-master01 secret]# kubectl get secret db-secret -n tcloud -o jsonpath='{.data.DB_USERNAME}' | base64 -d;echo
db_root
[root@k8s-master01 secret]# kubectl get secret db-secret -n tcloud -o jsonpath='{.data.DB_PASSWORD}' | base64 -d;echo
Qwe@123456!#
# 创建deployment清单加载configmap和secret
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: springboot
template:
metadata:
labels:
app: springboot
spec:
containers:
- name: app
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sleep", "3600"]
# ========== ConfigMap 挂载 ==========
volumeMounts:
- name: config-volume # 与下方volumes名称必须一致
mountPath: /app/config/application.yml # 容器内配置文件路径
subPath: application.yml # 单文件挂载必须加,防止目录覆盖
# ========== Secret 环境变量注入 ==========
envFrom:
- secretRef:
name: db-secret # 引用Secret名称,自动注入所有key=value
# ========== 关联ConfigMap ==========
volumes:
- name: config-volume # 自定义卷名,与上面对应
configMap:
name: springboot-cm # 引用的ConfigMap名称
# apply
[root@k8s-master01 secret]# kubectl apply -f springboot.yaml
# 验证
# 查看pod
[root@k8s-master01 secret]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
springboot-984d56d47-4h2gg 1/1 Running 0 4s
springboot-984d56d47-prtn7 1/1 Running 0 4s
# 查看pod中的内容
[root@k8s-master01 secret]# kubectl exec -it -n tcloud deployments/springboot -- cat /app/config/application.yml
spring:
datasource:
url: jdbc:mysql://192.168.1.100:3306/testdb
username: ${DB_USERNAME}
password: ${DB_PASSWORD}
driver-class-name: com.mysql.cj.jdbc.Driver
[root@k8s-master01 secret]# kubectl exec -it -n tcloud deployments/springboot -- env | grep DB
DB_USERNAME=db_root
DB_PASSWORD=Qwe@123456!#
# 注意:文件里的 ${xxx} 不会变! SpringBoot 启动时会自己读取环境变量并替换!
# 删除deployment和secret
[root@k8s-master01 secret]# kubectl delete -f springboot.yaml
[root@k8s-master01 secret]# kubectl delete cm -n tcloud springboot-cm kubernetes.io/dockerconfigjson
场景:secret存放阿里云的私有镜像仓库账号密码信息 完成镜像拉取部署(应该是Harbor这里用阿里云的私有镜像仓库代替,Horbor后面会使用)
现在要拉取这个centos的镜像来完成业务pod运行,正常情况是拉取不到的,因为是私有的需要登录信息,在secret中配置账号密码地址,来完成拉取镜像的操作。
# 在集群任意一个节点镜像镜像拉取测试(拉取失败)
[root@k8s-node03 ~]# crictl pull registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest
E0427 12:21:16.565405 38586 remote_image.go:238] "PullImage from image service failed" err="rpc error: code = Unknown desc = failed to pull and unpack image \"registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest\": failed to resolve reference \"registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest\": pull access denied, repository does not exist or may require authorization: server message: insufficient_scope: authorization failed" image="registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest"
FATA[0001] pulling image: rpc error: code = Unknown desc = failed to pull and unpack image "registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest": failed to resolve reference "registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest": pull access denied, repository does not exist or may require authorization: server message: insufficient_scope: authorization failed
# 创建 docker-registry 类型的 Secret 认证私有镜像仓库
[root@k8s-master01 secret]# kubectl create secret docker-registry aliyun-registry-secret -n tcloud \
--docker-server=registry.cn-hangzhou.aliyuncs.com \
--docker-username=guoweijie \
--docker-password=<替换为你的password> \
--docker-email=test@example.com # 邮箱可随意填写,不影响认证
# 查看secret信息
[root@k8s-master01 secret]# kubectl get secret -n tcloud
NAME TYPE DATA AGE
aliyun-registry-secret kubernetes.io/dockerconfigjson 1 3m57s
db-secret Opaque 2 56m
# 创建配置secret的deployment文件
[root@k8s-master01 secret]# vim centos-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: centos-deploy # Deployment名称
namespace: tcloud # 指定tcloud命名空间
spec:
replicas: 1 # 副本数
selector:
matchLabels:
app: centos
template:
metadata:
labels:
app: centos
spec:
# 关键:引用刚才创建的镜像拉取密钥
imagePullSecrets:
- name: aliyun-registry-secret
containers:
- name: centos
# 阿里云私有镜像完整地址
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/centos:latest
imagePullPolicy: IfNotPresent
# centos镜像默认启动命令,防止容器退出
command: ["/usr/sbin/init"]
# apply
[root@k8s-master01 secret]# kubectl apply -f centos-deployment.yaml
# 查看pod
[root@k8s-master01 secret]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
centos-deploy-8688bd4587-sbp9z 1/1 Running 0 25s
pod状态running,说明镜像拉取成功
# 删除资源
[root@k8s-master01 secret]# kubectl delete secrets -n tcloud aliyun-registry-secret
[root@k8s-master01 secret]# kubectl delete -f centos-deployment.yaml 其实使用最多还有一种是TLS类型,在前面Ingress中的https已经说明过了。
Secret和ConfigMap只读功能
防止:意外修改、误改配置、密钥被篡改、集群内人为 / 程序乱改核心参数
-
防止运维手滑误改(最常见)
-
防止配置被 CI/CD、自动化工具乱覆盖
-
防止入侵 / 权限泄露后密钥被窃取篡改
创建ConfgiMap
[root@k8s-master01 secret]# kubectl create configmap my-config -n tcloud --from-literal=app.conf="mode=prod"
编辑configmap设置只读(immutable: true)
Please edit the object below. Lines beginning with a '#' will be ignored,
and an empty file will abort the edit. If an error occurs while saving this file will be
reopened with the relevant failures.
apiVersion: v1
data:
app.conf: mode=prod
kind: ConfigMap
metadata:
creationTimestamp: "2026-04-27T07:47:23Z"
name: my-config
namespace: tcloud
resourceVersion: "524515"
uid: 1caecd41-b2a5-4c86-9879-8e320d8ab32e
immutable: true # 和 kind、metadata 同级加了immutable: true再次修改,顺便删些内容
提示:
immutable: Forbidden: field is immutable whenimmutableis set
data: Forbidden: field is immutable whenimmutableis set不让修改,只能删除重建 Secret也是一样的
2、持久化存储
Volumes
Pod 内容器的临时文件系统是生命周期绑定 Pod 的,Pod 删除 / 重建,数据全部丢失。K8s Volume :为 Pod 提供独立生命周期的存储目录,用来:
- 持久化数据
- 多容器共享目录
- 对接集群外部存储
HostPath
把宿主机(Node 节点)本地的文件 / 目录,直接挂载到 Pod 容器内。
简单理解:容器里的路径 ➜ 直接对应 服务器本地磁盘路径。
| type 类型 | 说明 |
|---|---|
Directory |
必须存在宿主机目录,不存在则启动失败 |
DirectoryOrCreate |
不存在就自动创建目录 |
File |
必须是宿主机单个文件 |
FileOrCreate |
不存在则创建空文件 |
Socket |
挂载宿主机套接字(如 docker.sock) |
严重缺点
-
节点强绑定Pod 调度到别的节点,数据不一致、直接丢失
-
无高可用、无迁移、无快照
-
集群管理混乱,每个节点目录不一致
-
存在安全风险:容器越权读写宿主机本地文件
创建挂载HostPath的deployment的文件
[root@k8s-master01 volumes]# vim hostpath.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-pd
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: nginx-volume-hostpath
template:
metadata:
labels:
app: nginx-volume-hostpath
spec:
containers:
- image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
name: nginx-volume
imagePullPolicy: IfNotPresent # 从本地拉取,没有才去仓库拉
volumeMounts:
- mountPath: /test-pd # 容器内挂载目录
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data # 宿主机节点目录
type: DirectoryOrCreate # 没有/data目录则创建apply
[root@k8s-master01 volumes]# kubectl apply -f hostpath.yaml
查看pod运行在那个节点
[root@k8s-master01 volumes]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd-b69fb7f75-sdhp8 1/1 Running 0 2m39s 10.244.135.170 k8s-node03
test-pd-b69fb7f75-wnbw2 1/1 Running 0 2m39s 10.244.195.40 k8s-master03看到运行到master03和node03节点,创建一个测试文件,注意操作的节点
[root@k8s-master03 ~]# cd /data/
[root@k8s-master03 data]# touch index.html、进入pod查看,创建的文件也存在了
[root@k8s-master01 volumes]# kubectl exec -it test-pd-b69fb7f75-wnbw2 -n tcloud -- bash
root@test-pd-b69fb7f75-wnbw2:/# cd /test-pd/
root@test-pd-b69fb7f75-wnbw2:/test-pd# ls
index.html
root@test-pd-b69fb7f75-wnbw2:/test-pd# echo "container...." > index.html去pod对应的节点查看文件内容
[root@k8s-master03 data]# cat index.html
container....
[root@k8s-master03 data]# echo "hsotpath..." >> index.html去pod查看内容
root@test-pd-b69fb7f75-wnbw2:/test-pd# cat index.html
container....
hsotpath...操作的是master03上面的pod,去看node03节点的/data目录,是没有数据的
[root@k8s-node03 ~]# cd /data/
[root@k8s-node03 data]# ls删除deployment
[root@k8s-master01 volumes]# kubectl delete -f hostpath.yaml
多副本 Deployment 用 HostPath,每个 Pod 数据不一样
现在 2 个副本:
- 副本 1 → master03 的 /data
- 副本 2 → node03 的 /data数据完全不一致! 这就是生产环境不能用 HostPath 跑业务的原因!
EmptyDir
EmptyDir = 临时空目录,跟着 Pod 一起创建、一起删除。(pod的临时共享文件夹)
特点:
- Pod 一创建 → 自动生成空目录
- Pod 一删除 → 目录和数据一起消失
- Pod 内多个容器可以共享这个目录
- 不持久化,不跨节点,不跨 Pod
- 不需要指定宿主机路径,K8s 自动管理
核心用途:
-
Pod 内多容器共享数据(最常用)
-
临时缓存
-
临时日志
-
临时文件交换
创建empty的deployment的yaml文件
[root@k8s-master01 volumes]# vim empty.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: empty-pod
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: empty-pod
template:
metadata:
labels:
app: empty-pod
spec:
containers:
# 第一个容器
- image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/alpine:latest
name: nginx-emptydir1
command: ["sh", "-c", "sleep 3600"]
# 挂载emptyDir卷到容器内目录
volumeMounts:
- mountPath: /cache
name: cache-volume
# 第二个容器
- image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/alpine:latest
name: nginx-emptydir2
command: ["sh", "-c", "sleep 3600"]
# 同一emptyDir卷挂载至不同目录,实现多容器数据共享
volumeMounts:
- mountPath: /opt
name: cache-volume
volumes:
- name: cache-volume
# emptyDir临时空卷,生命周期绑定Pod,仅用于临时数据共享,不持久化
emptyDir: {}apply
[root@k8s-master01 volumes]# kubectl apply -f empty.yaml
查看pod
[root@k8s-master01 volumes]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
empty-pod-84d48b6bf-9n2tw 2/2 Running 0 55s进入容器,创建测试文件
[root@k8s-master01 volumes]# kubectl exec -it -n tcloud empty-pod-84d48b6bf-9n2tw -c nginx-emptydir1 -- sh
/ # echo "hello emptydir ..." > /cache/share.txt
/ # cat /cache/share.txt
hello emptydir ...进入pod的第二个容器
[root@k8s-master01 ~]# kubectl exec -it -n tcloud empty-pod-84d48b6bf-9n2tw -c nginx-emptydir2 -- sh
/ # cat /opt/share.txt
hello emptydir ...删除pod看数据是否存在
[root@k8s-master01 volumes]# kubectl delete pod -n tcloud empty-pod-84d48b6bf-9n2tw
[root@k8s-master01 volumes]# kubectl exec -it -n tcloud empty-pod-84d48b6bf-jqlzb -c nginx-emptydir1 -- ls /cache/
目录为空 = EmptyDir 数据随 Pod 销毁删除deployment
[root@k8s-master01 volumes]# kubectl delete -f empty.yaml
NFS
NFS:跨节点共享存储
-
数据存放在独立 NFS 服务端
-
所有节点、所有 Pod 挂载同一份目录
-
Pod 漂移、重建、删除,数据永久保留
-
生产核心用途:多副本应用共享数据、统一文件存储
所有节点安装NFS的客户端
yum install -y nfs-utils
在NFS服务器上创建共享的目录(这里用master01代替)
[root@k8s-master01 ~]# mkdir -p /data/{ro,rw}
编辑nfs的配置文件
[root@k8s-master01 ~]# vim /etc/exports
/data/rw 192.168.1.0/24(rw,sync,no_root_squash)
/data/ro 192.168.1.0/24(ro,sync,no_root_squash)生效配置文件
[root@k8s-master01 ~]# exportfs -rv
[root@k8s-master01 ~]# systemctl restart nfs创建测试文件
[root@k8s-master01 nfs]# echo "this is nfs rw page" > /data/rw/index.html
[root@k8s-master01 nfs]# echo "this is nfs ro page" > /data/ro/info.html创建挂载NFS的的ployment yaml文件01
[root@k8s-master01 nfs]# vim nfs-nginx-01.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-nginx-01
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: nfs-nginx-01
template:
metadata:
labels:
app: nfs-nginx-01
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /usr/share/nginx/html/rw
name: nfs-rw
# NFS只读目录挂载到Nginx配置目录,防止业务篡改
- mountPath: /usr/share/nginx/html/ro
name: nfs-ro
readOnly: true
volumes:
# NFS可写卷,用于存放网页内容
- name: nfs-rw
nfs:
server: 192.168.1.10
path: /data/rw
# NFS只读卷,用于存放Nginx配置,安全加固
- name: nfs-ro
nfs:
server: 192.168.1.10
path: /data/ro创建创建挂载NFS的的ployment yaml文件02
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-nginx-02
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: nfs-nginx-02
template:
metadata:
labels:
app: nfs-nginx-02
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
volumeMounts:
# 共享同一个 NFS 可写目录
- mountPath: /usr/share/nginx/html/rw
name: nfs-rw
# 共享同一个 NFS 只读目录
- mountPath: /usr/share/nginx/html/ro
name: nfs-ro
readOnly: true
volumes:
# 共享 NFS 可读写存储,跨 Deployment 数据互通
- name: nfs-rw
nfs:
server: 192.168.1.10
path: /data/rw
# 共享 NFS 只读存储,全局统一
- name: nfs-ro
nfs:
server: 192.168.1.10
path: /data/roapply
[root@k8s-master01 nfs]# kubectl apply -f nfs-nginx-01.yaml
[root@k8s-master01 nfs]# kubectl apply -f nfs-nginx-02.yaml查看pod
[root@k8s-master01 nfs]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nfs-nginx-01-6f7f4856cf-dwwz4 1/1 Running 0 34s 10.244.195.42 k8s-master03
nfs-nginx-02-f6685c7fd-x4hfv 1/1 Running 0 32s 10.244.58.233 k8s-node02访问测试
访问【可写 NFS 页面】
[root@k8s-master01 nfs]# curl 10.244.195.42/rw/index.html
this is nfs rw page
[root@k8s-master01 nfs]# curl 10.244.58.233/rw/index.html
this is nfs rw page访问【只读 NFS 页面】
[root@k8s-master01 nfs]# curl 10.244.195.42/ro/info.html
this is nfs ro page
[root@k8s-master01 nfs]# curl 10.244.58.233/ro/info.html
this is nfs ro page进入pod写入文件测试
[root@k8s-master01 nfs]# kubectl exec -it -n tcloud nfs-nginx-01-6f7f4856cf-dwwz4 -- bash
root@nfs-nginx-01-6f7f4856cf-dwwz4:/# echo "write by nginx01" > /usr/share/nginx/html/rw/write.html访问测试
[root@k8s-master01 nfs]# curl 10.244.195.42/rw/write.html
write by nginx01
[root@k8s-master01 nfs]# curl 10.244.58.233/rw/write.html
write by nginx01只读目录防篡改验证
[root@k8s-master01 nfs]# kubectl exec -it -n tcloud nfs-nginx-01-6f7f4856cf-dwwz4 -- bash
root@nfs-nginx-01-6f7f4856cf-dwwz4:/# echo "123" > /usr/share/nginx/html/ro/test.html
bash: /usr/share/nginx/html/ro/test.html: Read-only file system
只读:不允许修改删除资源
[root@k8s-master01 nfs]# kubectl delete -f nfs-nginx-01.yaml
[root@k8s-master01 nfs]# kubectl delete -f nfs-nginx-02.yaml
[root@k8s-master01 ~]# rm -rf /data/rw/*
PV / PVC
什么是pv和pvc
PV(PersistentVolume):集群级存储资源,提前定义 NFS / 本地存储 / 云盘,统一管理存储
PVC(PersistentVolumeClaim):业务申请存储,Pod 不直接写死 NFS 地址,只绑定 PVC
访问模式:
- ReadWriteOnce(RWO):单节点读写(最常见)
- ReadOnlyMany(ROX):多节点只读
- ReadWriteMany(RWX):多节点读写(NFS/CephFS 等)
1. accessModes: ReadWriteOnce(RWO)
现状
node1 已经挂载这个卷。
现象
- 同节点 node1 再启多个 Pod → ✅ 正常挂载读写
- 跨节点 node3 起 Pod → ❌ 挂载失败
核心规则:只能被单个节点挂载,别的节点不能挂
2. accessModes: ReadOnlyMany(ROX)
现状
node1 已挂载使用
现象
- node1、node3、所有节点 → ✅ 都能同时挂载
- 全局只能读,不能写
- 你的业务如果需要写入数据 → ❌ 直接报错
3. accessModes: ReadWriteMany(RWX)
现状
node1 已挂载读写
现象
- node1、node3 跨节点同时挂载 ✅ 完全允许
- 所有节点的 Pod 都能读、都能写
- 依赖底层存储支持:NFS/CephFS/ 对象存储类,本地盘、云硬盘不支持 RWX
PV状态
| 状态 | 含义 | 核心场景 |
|---|---|---|
| Available | 空闲可用 | PV 已创建、未绑定任何 PVC,可被申请绑定 |
| Bound | 已绑定 | 成功和 PVC 一对一绑定,正常使用中 |
| Released | 已释放 | PVC 被删除,但PV 保留(回收策略 = Retain),数据还在,不可重新绑定 |
| Failed | 异常失效 | 存储挂载 / 读写失败、底层存储故障 |
| Pending | 等待就绪 | 动态创建 PV、存储初始化中、等待 SC 分配 |
| Terminating | 删除中 | PV 正在被删除(回收策略 = Delete) |
回收策略
1、Retain(保留,默认):PVC删除后,PV保留,状态变为Released,数据完全保留,不会删除,该PV无法被新PVC绑定,需要手动清理数据+解绑
2、Delete(删除):PVC删除后,自动删除对应PV+底层存储数据,资源自动删除,无需人工维护
3、Recycle(回收,已废弃):PVC删除后,自动情况PV内数据(PV状态变为可用),生产禁止使用。
| 回收策略 | 核心行为 | 支持存储 | 集群现状 | 典型场景 |
|---|---|---|---|---|
| Retain | 删除 PVC:1.PV 保留,状态变为Released2. 后端数据完全保留3.PV 不可直接复用,需手动解绑 |
NFS、NAS、HostPath、所有文件存储 | ✅ 长期稳定使用 | 共享文件存储、数据重要、防止误删 |
| Delete | 删除 PVC:1. 自动删除绑定 PV2. 后端底层存储 / 磁盘自动销毁3. 资源彻底释放 | 云硬盘、Ceph RBD、Longhorn、CSI 块存储 | ✅ 生产主流 | 临时业务、测试环境、数据无需保留 |
| Recycle | 删除 PVC:1. 自动清空卷内所有数据(rm -rf)2.PV 保留,可直接被新 PVC 绑定复用 | 仅老旧 NFS/HostPath | ❌ K8s 1.20+ 彻底废弃 | 早期老旧集群,现已全面淘汰 |
PV的生命周期
资源供应:管理员手动创建底层存储和PV
资源绑定:用户创建PVC,kubernetes负责根据PVC的声明去寻找PV,并绑定在用户定义好PVC之后,系统将根据PVC对存储资源的请求在已存在的PV中选择一个满足条件的,一旦找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了,如果找不到,PVC则会无限期处于Pending状态,直到等到系统管理员创建了一个符合其要求的PV,PV一旦绑定到某个PVC上,就会被这个PVC独占,不能再与其他PVC进行绑定了
资源使用:用户可在pod中像volume一样使用pvc
资源释放:用户删除pvc来释放pv,当存储资源使用完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为"已释放",但还不能立刻与其他PVC进行绑定。通过之前PVC写入的数据可能还被留在存储设备上,只有在清除之后该PV才能再次使用。
资源回收:kubernetes根据pv设置的回收策略进行资源的回收,对于PV,管理员可以设定回收策略,用于设置与之绑定的PVC释放资源之后如何处理遗留数据的问题。只有PV的存储空间完成回收,才能供新的PVC绑定和使用
PV存储类型
块存储(Block)
对应 PV:云硬盘、本地盘、SAN
- 有状态数据库:MySQL、PostgreSQL、MongoDB 等核心业务库
- 高性能业务:需要低延迟、高 IOPS、随机读写频繁的服务
- 系统级存储:虚拟机系统盘、容器专属独占数据盘
- 业务特点:单实例独占、需格式化建文件系统、支持快照 / 克隆扩容
不适用
多节点并发共享读写、海量非结构化文件归档
文件存储(File)
对应 PV:NFS、NAS、CIFS
适用场景
- 集群共享数据:多 Pod、多节点同时读写同一目录
- 业务共享目录:程序配置文件、运行日志、导出报表、上传文件
- 办公 & 业务协同:企业共享文档、网站静态资源目录、集群中间件共享存储
- 业务特点:天然共享挂载、保留目录树、兼容标准文件读写接口
不适用
超大规模海量文件、低频冷数据长期归档
对象存储(Object)
对应 PV:OSS、COS、S3 兼容存储
适用场景
- 非结构化资源:图片、短视频、音频、附件、安装包、静态前端资源
- 数据归档备份:数据库全量备份、容器镜像归档、历史日志、冷数据长期留存
- 大数据 & 离线业务:离线分析文件、跨地域资源分发、静态资源加速
- 业务特点:海量扩容、低成本、按需访问,HTTP 接口访问,无需挂载磁盘
不适用
数据库读写、程序直接挂载运行、高频增量读写场景
PV和PVC使用
本案例使用NFS类型的PV的来讲解,后面讲到Rook部署Ceph的方式来讲解
# 共享出NFS的目录
[root@k8s-master01 pv-pvc]# vim /etc/exports
/data/rw 192.168.1.0/24(rw,sync,no_root_squash)
# 生效
[root@k8s-master01 pv-pvc]# exportfs -rv
[root@k8s-master01 pv-pvc]# systemctl restart nfsRetain
PVC删除后,PV保留,状态变为Released,数据完全保留,不会删除,该PV无法被新PVC绑定,需要手动清理数据+解绑
# 创建pv
[root@k8s-master01 Retain]# vim pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv-retain
spec:
capacity:
# 存储容量:声明此PV可提供5G存储空间
storage: 5Gi
# 访问模式:ReadWriteMany = 多节点、多Pod可同时挂载读写
# 只有 文件存储(NFS/NAS) 支持该模式
accessModes:
- ReadWriteMany
# 回收策略:Retain = 保留数据
persistentVolumeReclaimPolicy: Retain
# 创建PV的存储类名字需要和PVC的一致
storageClassName: cloud
nfs:
server: 192.168.1.10
path: /data/rw
# apply后查看pv的信息
# pv是集群资源,没有命名空间
[root@k8s-master01 Retain]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfs-pv-retain 5Gi RWX Retain Available <unset> 3s
说明:
1、STATUS: Available 创建成功
2、ACCESS MODES: RWX 多节点、多 Pod 可以同时挂载读写
# 创建绑定PV的PVC
[root@k8s-master01 Retain]# vim pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc-retain
namespace: tcloud
spec:
# 访问模式:和PV一样
accessModes:
- ReadWriteMany
resources:
requests:
# 申请存储容量:5GB,必须与匹配的 PV 容量一致
storage: 5Gi
# 需要和pv的一致
storageClassName: cloud
# 查看pv和pvc的状态
[root@k8s-master01 Retain]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfs-pv-retain 5Gi RWX Retain Bound tcloud/nfs-pvc-retain cloud <unset> 3m32s
[root@k8s-master01 Retain]# kubectl get pvc -n tcloud
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
nfs-pvc-retain Bound nfs-pv-retain 5Gi RWX cloud <unset> 3m10s
# 状态Bound,已经绑定了
# 创建deployment使用PVC
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-nfs-retain
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: nginx-nfs
template:
metadata:
labels:
app: nginx-nfs
spec:
containers:
- name: nginx
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
# 与下方 volumes.name 对应
- name: nfs-data
# 容器内挂载目录
mountPath: /usr/share/nginx/html
# 数据卷声明:使用 PVC 绑定 PV 实现持久化
volumes:
# 自定义卷名称,供容器挂载引用
- name: nfs-data
persistentVolumeClaim:
# 绑定的 PVC 名称
claimName: nfs-pvc-retain
# apply
[root@k8s-master01 Retain]# kubectl apply -f deployment.yaml
# 查看pod的信息
[root@k8s-master01 Retain]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-nfs-retain-5dd87dcbd7-g5gjc 1/1 Running 0 5m24s 10.244.58.234 k8s-node02 <none> <none>
# 访问测试
[root@k8s-master01 Retain]# curl 10.244.58.234
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
因为我们的目录是空的,把nginx中的html目录覆盖了,没有访问到任何资源
# 创建测试文件
[root@k8s-master01 Retain]# kubectl exec -it nginx-nfs-retain-5dd87dcbd7-g5gjc -n tcloud -- bash
root@nginx-nfs-retain-5dd87dcbd7-g5gjc:/# echo "this is Retain.." > /usr/share/nginx/html/index.html
# 访问测试
[root@k8s-master01 Retain]# curl 10.244.58.234
this is Retain..
# 测试删除pod,看index.html文件是否还存在
[root@k8s-master01 Retain]# kubectl delete pod -n tcloud nginx-nfs-retain-5dd87dcbd7-g5gjc
[root@k8s-master01 Retain]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-nfs-retain-5dd87dcbd7-gdx57 1/1 Running 0 14s 10.244.135.171 k8s-node03 <none> <none>
[root@k8s-master01 Retain]# curl 10.244.135.171
this is Retain..
# 测试Retain策略
# 删除deployment
[root@k8s-master01 Retain]# kubectl delete deployment -n tcloud nginx-nfs-retain
# 删除pvc
[root@k8s-master01 Retain]# kubectl delete pvc nfs-pvc-retain -n tcloud
persistentvolumeclaim "nfs-pvc-retain" deleted from tcloud namespace
# 查看pv状态
[root@k8s-master01 Retain]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfs-pv-retain 5Gi RWX Retain Released tcloud/nfs-pvc-retain cloud <unset> 17h
可以看到在状态为Released,nfs的数据被保留的了,需要人工解绑和清楚数据才可以重新使用
# 再次绑定测试
[root@k8s-master01 Retain]# kubectl apply -f pvc.yaml
[root@k8s-master01 Retain]# kubectl get pvc
No resources found in default namespace.
[root@k8s-master01 Retain]# kubectl get pvc -n tcloud
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
nfs-pvc-retain Pending cloud <unset> 10s
可以看到是Pending
#删除pvc
[root@k8s-master01 Retain]# kubectl delete -f pvc.yaml
# 清除PV绑定残留
[root@k8s-master01 Retain]# kubectl patch pv nfs-pv-retain -p '{"spec":{"claimRef":null}}'
persistentvolume/nfs-pv-retain patched
[root@k8s-master01 Retain]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfs-pv-retain 5Gi RWX Retain Available cloud <unset> 17h
可以看到pv重新变成Available状态了,就可以去重新使用了
# 创建pvc
[root@k8s-master01 Retain]# kubectl apply -f pvc.yaml
# 查看pv和pvc的状态
[root@k8s-master01 Retain]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfs-pv-retain 5Gi RWX Retain Bound tcloud/nfs-pvc-retain cloud <unset> 17h
[root@k8s-master01 Retain]# kubectl get pvc -n tcloud
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
nfs-pvc-retain Bound nfs-pv-retain 5Gi RWX cloud <unset> 6s
# Bound就是已经绑定了
# 删除相关的资源
[root@k8s-master01 Retain]# kubectl delete -f pvc.yaml
[root@k8s-master01 Retain]# kubectl delete -f pv.yaml
[root@k8s-master01 ~]# rm -rf /data/rw/index.html Delete
PVC删除后,自动删除对应PV+底层存储数据,资源自动删除,无需人工维护
# 创建pv策略Delete
[root@k8s-master01 Delete]# vim pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv-retain
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
# 改为 Delete 回收策略
persistentVolumeReclaimPolicy: Delete
storageClassName: cloud
nfs:
server: 192.168.1.10
path: /data/rwpvc.yaml和deployment使用Retain模式的,不用修改
# apply
[root@k8s-master01 Delete]# kubectl apply -f pv.yaml
[root@k8s-master01 Delete]# kubectl apply -f pvc.yaml
[root@k8s-master01 Delete]# kubectl apply -f deployment.yaml
# 确认一下pv和pvc的状态,已经Bound
[root@k8s-master01 Delete]# kubectl get pv,pvc -n tcloud
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/nfs-pv-retain 5Gi RWX Delete Bound tcloud/nfs-pvc-retain cloud <unset> 69s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/nfs-pvc-retain Bound nfs-pv-retain 5Gi RWX cloud <unset> 59s
# 进入pod写入测试数据
[root@k8s-master01 Delete]# POD=$(kubectl get pod -n tcloud | grep nginx-nfs | awk '{print $1}')
[root@k8s-master01 Delete]# kubectl exec -it $POD -n tcloud -- bash
root@nginx-nfs-retain-5dd87dcbd7-qv82b:/# echo "Delete..." > /usr/share/nginx/html/index.html
# 访问测试省略,直接测试Delete策略
# 查看NFS的挂载目录的数据
[root@k8s-master01 ~]# ls /data/rw/
index.html
# 删除deployment和pvc(Delete 策略触发点)
[root@k8s-master01 Delete]# kubectl delete -f deployment.yaml
[root@k8s-master01 Delete]# kubectl delete -f pvc.yaml
# 查看pv的状态
[root@k8s-master01 Delete]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfs-pv-retain 5Gi RWX Delete Failed tcloud/nfs-pvc-retain cloud <unset> 6m34s
Kubernetes 对 NFS 类型的 PV,不支持 Delete 回收策略!
Delete 策略本意:删除 PVC 时,自动删除 PV + 销毁后端存储数据
但 NFS 是文件共享存储,K8s 无权删除远端 NFS 目录
所以 K8s 尝试删除失败 → PV 状态变成 Failed
如果是块存储,就可以自动删除PV
NFS 存储 只能用 Retain,绝对不能用 Delete!
# 强制删除pv
[root@k8s-master01 Delete]# kubectl delete -f pv.yaml Recycle
Recycle 太弱、不安全、只支持老旧存储,被 K8s 官方废弃;现在只推荐 Retain (文件存储)和 Delete(块存储)。