⚙️ 工程深度:L4 · 生产级 | 📖 预计阅读:38 分钟
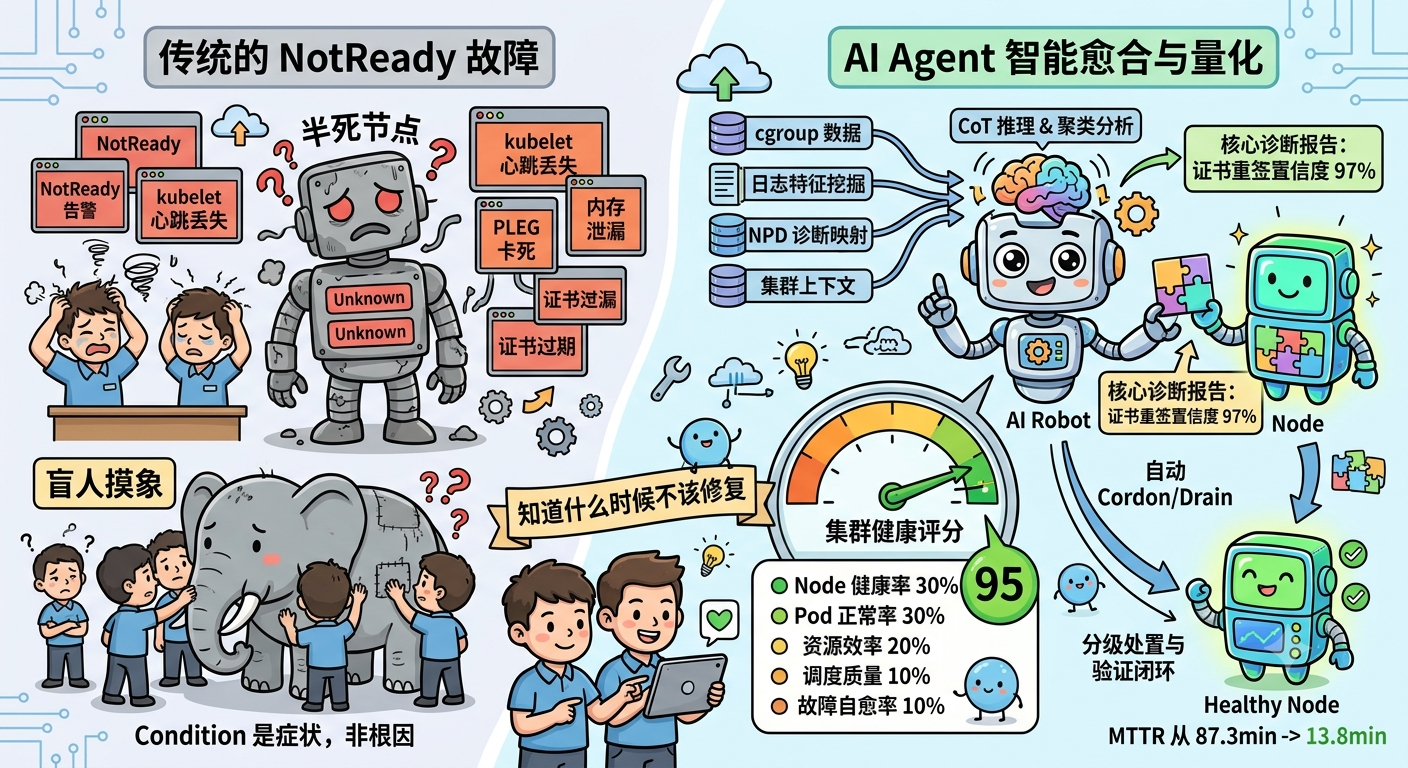
一句话理解 :Node Condition 是一套"症状报告系统"------它告诉你出问题了(DiskPressure=True),但不告诉你为什么出问题。AI Agent 的职责是把症状翻译成根因,然后自动执行修复。但"自动修复"并不是终点,知道什么时候不该自动修复,才是生产级系统的真正门槛。
凌晨 2:00,40 台节点齐刷刷变红
告警面板上,40 个节点集体变红。kubectl get nodes 的输出全是 NotReady。
第一反应是网络分区------CNI 挂了?但部分节点上的 Pod 还在响应请求,这排除了全局网络故障。kubelet 崩了?ssh 到一台节点,systemctl status kubelet 显示 running,但 kubectl get node 的 lastHeartbeatTime 已经冻结在 3 分钟前。
磁盘压力、内存泄漏、证书过期、PLEG 卡死、conntrack 表溢出......
排查用了 10 分钟,定位根因(证书批量过期)用了 5 分钟,修复用了不到 3 分钟。但这 13 分钟,触发了 300+ 条下游告警,值班群被@炸了,而大多数告警都是"节点 NotReady → Pod 重启 → 上游健康检查失败"这条链路产生的涟漪噪声,不是独立故障。
真正的问题不是节点挂了,而是根因只有一个,告警却有三百个。
这个场景每天都在发生。本文要解决的不是"如何排查 Node 故障"这个已经有无数文章回答的问题,而是更深一层:怎么构建一套可编程的自愈体系,让 AI Agent 具备"资深 SRE 的诊断推理",同时在人机协同边界上不越雷池。
为什么 K8s 把"症状"和"根因"分离设计?
在展开 AI Agent 的架构之前,必须先回答一个根本问题:K8s 为什么用 Condition 而不直接给出根因诊断?
这不是设计失误,而是边界哲学。K8s 的职责是编排 ,不是诊断 。Node Controller 只做一件事:通过心跳判断节点是否存活,超过 node-monitor-grace-period(默认 40 秒)心跳丢失就标记 Unknown,超过 pod-eviction-timeout(默认 5 分钟)就开始驱逐 Pod。kubelet 通过周期性检查更新 MemoryPressure、DiskPressure 等 Condition,但仅限于"有无压力"的布尔判断。
Condition 是结论 ,不是证据 。DiskPressure=True 告诉你"磁盘有压力",但它不会告诉你:是哪个路径满了、是日志轮转失效还是镜像层堆积、是物理磁盘还是 inode 耗尽。后者是 SRE 用 10-30 分钟手工定位的信息。
SRE 诊断边界
K8s 编排边界
Condition 是症状,非根因
物理磁盘使用率 > 85%
DiskPressure = True
Node Ready = Unknown\n开始驱逐 Pod
df -h 查全局使用率
du -sh 按目录下钻
区分:日志堆积 / 镜像层 / inode 耗尽
定位根因,执行修复
这个 Gap 就是 AI Agent 的介入点。它不替代 K8s 的 Condition 检测机制,而是在 Condition → Root Cause 的断层中,建立自动化的诊断推理链路。
一、Node NotReady 的五种死法------根因分类框架
1.1 五类根因,诊断路径完全不同
当节点状态变为 NotReady 时,底层原因通常落入五个维度。这五个维度之间不互斥------内核 OOM 可以杀掉 kubelet 进程,同时也会在磁盘留下 core dump,让磁盘压力同时触发。这种"连环"场景是最难诊断的。
💡 隐性知识 | 来源:多维度连环故障复盘 五类根因中的"kubelet 异常"和"内存压力"是诊断中最高频的混淆对:容器 OOM 被内核杀死 → kubelet 日志报 Failed to get recent checkpoint → 看起来像 kubelet 异常。但停止 kubelet 重启会掩盖内存溢出的证据(OOM 日志在 dmesg 中,重启后会清空环形缓冲区)。正确顺序是先查 dmesg 确认是否有 OOM,再决定是否重启 kubelet。
| 类型 | 典型根因 | 关键诊断信号 | 首诊命令 |
|---|---|---|---|
| kubelet 异常 | 进程崩溃 / 证书过期 / 配置错误 | kubelet 服务状态、心跳时间戳 | journalctl -u kubelet --priority err -n 50 |
| 网络故障 | CNI 插件挂死 / 网络分区 / IP 冲突 | Node Controller 到节点的连通性、CNI Pod 状态 | kubectl get pods -n kube-system -o wide |
| 磁盘压力 | 根分区 > 85% / 日志堆积 / 镜像层膨胀 / inode 耗尽 | DiskPressure=True、df 使用率 |
df -h && df -i |
| 内存压力 | 宿主机 OOM / Kube-Reserved 设置不足 | MemoryPressure=True、dmesg OOM 日志 |
`dmesg |
| PID 压力 | 进程泄漏 / 容器 fork 炸弹 | PIDPressure=True、pid_max 接近上限 |
`cat /proc/sys/kernel/pid_max && ps -eLf |
诊断的核心难点在于排除顺序。经验法则:先排网络(是否所有节点都失联?),再排进程(kubelet 是否存活?),再排资源(三个 Pressure Condition 是否触发?),最后看日志(kubelet 错误模式匹配)。这个顺序不是随意的------网络故障会导致所有其他诊断动作都无法执行(ssh 不通),排在最前面能最快排除"完全无法操作"的场景。
1.2 kubelet 日志:真正的"黑匣子"
kubelet 日志是诊断节点故障最重要的原始证据。但 journalctl -u kubelet 的原始输出每分钟可能有数百行,直接看等于不看。关键是识别高价值的错误模式:
"SyncLoop (PLEG): healthy=false"PLEG(Pod Lifecycle Event Generator)卡死,通常是容器运行时(containerd/dockerd)无响应。这是最严重的 kubelet 内部错误,意味着 kubelet 已经无法感知任何 Pod 的状态变化。
"Container GC failed: failed to garbage collect required amount"磁盘空间不足,容器垃圾回收失败。这条日志出现时,DiskPressure Condition 通常已经或即将触发。
"Failed to list *v1.Node: Unauthorized"证书过期或被吊销。kubelet 无法向 API Server 认证,心跳中断。这是批量节点同时 NotReady 最常见的根因------证书往往是集中批量签发、集中批量过期的。
"Failed to update node status: etcdserver: request timed out"API Server 或 etcd 过载。心跳上报超时,但 kubelet 进程本身健康。这种情况下重启 kubelet 不会有任何帮助,根因在控制面。
理解这些错误模式的价值不在于背诵,而在于构建 AI Agent 的 Prompt 路由逻辑------不同的错误模式指向不同的诊断分支,这是结构化推理的基础。
1.3 批量故障的特殊性:40 台同时 NotReady
单节点故障和批量节点故障的诊断策略根本不同,这一点在大多数文章中被忽视。
单节点故障:逐步排查该节点的网络、进程、资源、日志。
批量节点故障(> 3 台同时 NotReady):先问"这些节点有什么共同点",而不是立刻 ssh 进去排查。
> 3 台节点同时 NotReady 共同属性分析
同一 AZ / 机架?\n→ 物理网络故障
同一证书批次?\n→ 证书集中过期
同一时间段上线?\n→ 配置变更引入
随机分布?\n→ 全局性问题(etcd/控制面)
检查 AZ 级别网络
批量重签证书
回滚变更
优先检查 API Server / etcd 状态
批量故障场景下,AI Agent 的诊断逻辑必须先做聚类分析再做单点诊断,否则会陷入"逐台排查 → 每台都是同一个根因"的低效循环。这是从"脚本自动化"到"Agent 智能诊断"的关键差异之一。
1.4 Node Problem Detector(NPD):K8s 自带但常被忽视的检测层
在 AI Agent 落地前,K8s 社区已有标准化的节点问题检测组件------NPD(Node Problem Detector)。它是一个以 DaemonSet 运行的守护进程,职责正是自动检测节点级系统问题并上报到 API Server。
三大检测器及其覆盖范围:
| 检测器 | 检测方式 | 典型覆盖问题 | 输出方式 |
|---|---|---|---|
SystemLogMonitor |
扫描 kernel 日志(/dev/kmsg)和 systemd journal |
内核死锁、硬件错误(EDAC/MCE)、网络设备异常 | 自定义 NodeCondition + Event |
HealthChecker |
HTTP/gRPC 探针检测关键组件可达性 | kubelet API 端口可达性、容器运行时 socket、监控插件 | Event + Condition 更新 |
CustomPluginMonitor |
运行用户自定义检查脚本 | 磁盘 IO 延迟超阈值、NTPSync 失步、特定内核模块加载 | Condition 或 Event |
NPD 的上报机制 :检测到问题后,NPD 会调用 K8s API 更新 Node Condition。这意味着问题和 Node Condition 之间建立了直接映射------无需 SRE 通过 journalctl 手动关联错误日志和 Condition 变更。
但 NPD 有四个关键局限,这正是 AI Agent 的介入空间:
- NPD 的诊断是"单点"的------它检查本节点的日志和状态,无法做批量节点的聚类分析(类比 1.3 的 40 节点证书过期场景)
- NPD 不执行修复------它只检测和上报,修复动作需要外部的控制器或人工介入
- NPD 的 Condition 映射是静态的 ------
kern.log匹配到"soft lockup"就上报KernelDeadlock,但无法判断这是瞬时抖动还是趋势恶化 - NPD 没有"置信度"概念------每次检测结果都是二元判定(True/False),不存在"疑似内核问题,置信度 75%,建议进入建议模式"这类模糊推理
AI Agent 和 NPD 的协作关系是互补而非替代:NPD 负责低延迟的"第一道防线"(已知模式匹配),AI Agent 在 NPD 基础之上做更高维度的推理(跨节点聚类 + 趋势分析 + 置信度评估 + 分级处置)。
二、AI Agent 四层诊断架构------把专家经验编码为推理链
2.1 为什么不直接把日志丢给 LLM?
直觉上,把 kubectl get node -o yaml 的输出直接问 LLM "这个节点怎么了"似乎最简单。在实验室环境也确实可以得到还不错的回答。
但生产环境有两个根本制约:
制约一:数据规模。一个中等节点的状态对象包含 30+ Conditions、几十条事件。kubelet 日志可能上万行。全部塞进上下文窗口,Token 消耗巨大,更关键的是有效信息被噪声稀释------LLM 会在无关日志上浪费注意力。
制约二:推理质量。LLM 的自由推理没有固定顺序,可能先分析次要症状,再跳到主要根因,中间充斥大量不确定性表述。SRE 排查有固定的"先排除法"顺序,这个经验不会自然地出现在 LLM 的输出中------必须通过结构化 Prompt 强制注入。
四层架构解决的正是这两个问题:每一层只收集当前层需要的数据,只做当前层该做的推理判断。
2.2 四层架构详解
第四层:综合诊断报告
第三层:日志特征挖掘(精准提取,非全量扫描)
第一层:状态感知(读数据,不执行命令)
DiskPressure=True
MemoryPressure=True
PIDPressure=True
心跳丢失,无 Condition
触发:Node Ready = Unknown 或 NotReady
读取 node.status.conditions\[\]
哪些 Condition 异常?\nDiskPressure / MemoryPressure /\nPIDPressure / NetworkUnavailable
磁盘诊断路径\ndf -h / df -i / du top5 / crictl images
内存诊断路径\nfree -m / OOM 日志 / PSI 趋势
PID 诊断路径\npid_max / 进程数 / fork 异常进程
kubelet 诊断路径\n进程 → 证书 → API 连通性
journalctl -u kubelet --since 5min --priority err
PLEG / GC / 证书 / 运行时 → 模式匹配分类
根因判定 + 置信度
严重度分级:轻微 / 严重 / 致命
处置方案 + 自动执行决策
第一层------状态感知,是唯一"只读"的层。它的职责是从 Node 对象提取 Conditions,做初步分类,决定走哪条诊断路径。这一层不执行任何 ssh 命令,避免在节点完全失联时浪费时间。
第二层------专项诊断 ,按 Condition 类型分叉,每条路径有固定的命令序列。注意这四条路径可以并行执行(当多个 Condition 同时异常时),而不是顺序等待。
第三层------日志特征挖掘,这是最容易被忽视的层。不是全量扫描 kubelet 日志,而是精准提取过去 5-10 分钟的 Error 级别日志,然后做模式匹配。模式库是可以持续迭代的------每次人工处理的新型故障,都应该把错误特征添加进模式库。
第四层------综合诊断报告,输出结构化 JSON,包含根因、置信度、严重度、处置建议。置信度不是装饰------低置信度的诊断应该触发"建议模式"而不是"自动执行"(详见第六章)。
💡 为什么是四层不是三层或五层?| 来源:诊断链路设计权衡
这不是随意选择,而是由诊断链中数据获取方式的不同决定的:
| N | 层数 | 为什么不够或多余 |
|---|---|---|
| N-1 = 3层 | 合并状态感知 + 专项诊断 | 无法区分"只读操作"和"侵入式操作"------合并后 Agent 可能在节点完全失联时仍尝试执行 ssh 命令,浪费时间 |
| N = 4层 | 当前设计 | 第四层(综合报告)依赖前三层的全部结果,而前三层的执行顺序和时机完全不同,需要独立管理 |
| N+1 = 5层 | 在综合报告后增加"执行层" | 执行不是诊断的一部分------执行是单独的决策阶段,有自己的前置检查和回滚机制。把执行挂载到诊断链上会导致"诊断未完成就触发修复" |
四层结构的核心约束是**"读"和"写"分离**:前三层只读(分析状态、收集证据),第四层输出结论(仍不执行操作)。执行决策发生在另一条独立的处置链路中(第三章)。这是人机协同边界(第六章)的技术前提------如果诊断和执行在同一链路中完成,就无法在中间插入"人工确认"步骤。
2.3 PSI:比"利用率"更早感知压力
资源利用率监控有一个根本盲区:利用率是"已用量"的平均值,而不是"等待量"的实时值。
以 CPU 为例:利用率 60% 看起来有余量,但如果 10 个容器都在等同一批 CPU 时间片,调度延迟会急剧升高。这种"堵车"状态在利用率指标上看不出来,但会直接导致应用响应时间恶化,并最终触发 kubelet 的 PLEG 超时。
Linux 内核 4.20 引入的 PSI(Pressure Stall Information)指标解决了这个问题。它度量的是资源等待时间的百分比,而不是使用量:
bash
# 读取某个 Pod 的 CPU 压力数据(cgroup v2 路径)
cat /sys/fs/cgroup/kubepods/burstable/pod${POD_UID}/cpu.pressure
# 输出: some avg10=15.24 avg60=8.31 avg300=3.19 total=2357891
# Memory 压力------度量因内存不足导致的回收延迟
cat /sys/fs/cgroup/kubepods/burstable/pod${POD_UID}/memory.pressure
# 输出: some avg10=0.00 avg60=0.00 avg300=0.00 total=0
# full avg10=0.00 avg60=0.00 avg300=0.00 total=0
# full ≠ some:full 表示所有任务都被阻塞,some 表示至少一个任务被阻塞
# IO 压力------度量因磁盘 I/O 导致的等待时间
cat /sys/fs/cgroup/kubepods/burstable/pod${POD_UID}/io.pressure
# 输出: some avg10=2.14 avg60=1.87 avg300=0.92 total=342156
# full avg10=0.32 avg60=0.18 avg300=0.05 total=12983
# cgroup v2 内存统计(OOM 预防的关键数据源)
cat /sys/fs/cgroup/kubepods/burstable/pod${POD_UID}/memory.stat
# 关注字段: workingset_refault_anon(匿名页回收后重缺页中断数)
# workingset_refault_file(文件页回收后重缺页中断数)
# oom_group_oom(cgroup 级别 OOM 计数)avg10 是过去 10 秒内,至少有一个任务在等待 CPU 的时间百分比;avg300 是过去 5 分钟的同一数据。some 和 full 的区别是诊断的关键:some 高 = 部分线程受影响(服务降级),full 高 = 所有线程卡住(服务中断)。
AI Agent 的 diagnostic 路径中,这三条 PSI 数据的采集是并行 的(asyncio.gather),因为它们在独立的 cgroup 控制组文件中,互不依赖。
两个数据的组合才能判断压力类型:
avg10高 +avg300也高 → 趋势性恶化,系统持续处于资源竞争状态,需要立即干预avg10高 +avg300低 → 瞬时突发,可能是短暂负载峰值,可以观察等待自愈- 两者都低 → 正常,即使利用率看起来高,实际调度效率良好
在某 200 节点集群的实测中,PSI 感知比 CPU 利用率告警提前 3-5 分钟 发现调度延迟问题。这 3-5 分钟正好是 kubelet 从压力产生到 Condition 标记的窗口期------主动干预 vs 被动响应的差别就在这里。
💡 机制级解释 | 来源:Linux 内核 PSI 实现分析 + 实测对比
"提前 3-5 分钟"不是经验估计,而是由两个指标的数据采集机制差异决定的:
旧链路:CPU 利用率(/proc/stat 固定采样)→ 发现 idle% 持续下降 → 触发阈值告警 → 进入 kubelet Condition 检查周期
新链路:内核调度器记录 runqueue 等待时间 → PSI 触发式更新 → 每次调度事件即时更新 avg10 → 跨阈值即时告警前者的延迟环节是采样周期掩盖 ------/proc/stat 每秒采样一次 CPU 时间片分配,某 100ms 内的调度尖峰可能落在两次采样之间被平滑掉。后者的加速环节是事件驱动------内核在每次将任务放入 delay queue 时就更新 PSI 计数器,调度延迟 10ms 就开始累积压力,无需等待采样窗口。
| 对比项 | CPU 利用率 | PSI (some_avg10) | 为什么有差异 |
|---|---|---|---|
| 数据来源 | /proc/stat 时间片累计量 |
内核调度器 delay queue 直接统计 | 调度器最清楚线程在等什么 |
| 采样方式 | 固定周期 1-15s 读取 | 每次调度事件触发更新 | 采样周期掩盖微突发 |
| 盲区 | 线程在等锁、等 IO、等调度时都记为 "idle" | 准确区分 "running" vs "waiting" | 利用率把等待当成空闲 |
| 响应速度 | 需要连续 N 个采样周期确认趋势 | avg10 即刻反映最近 10s 的压力累积 | 快 3-5 分钟 = 180-300 个采样周期 |
这意味着:CPU 利用率 60% 时可能已经有大量线程在排队,因为利用率只统计 "CPU 在转"的时间,而不管运行的是主线程还是等待线程。PSI 告诉你的不是 "CPU 在不在转",而是 "线程能不能及时拿到 CPU"------这是两个完全不同的问题。
这也是 AI Agent 诊断报告中"严重度"判断的核心依据之一:同样是 MemoryPressure=True,PSI 趋势恶化的节点需要立刻 Cordon,而 PSI 只是短暂突发的节点可以先观察。
2.4 诊断代码核心实现
python
import asyncio
import json
class NodeDiagnosticAgent:
"""K8s 节点故障四层诊断 Agent"""
async def diagnose(self, node_name: str) -> dict:
# 第一层:状态感知(只读,不执行命令)
conditions = await self._get_node_conditions(node_name)
if self._is_healthy(conditions):
return {"status": "healthy", "node": node_name}
# 第二层:专项诊断(并行执行所有触发的路径)
active_conditions = [c for c, active in conditions.items() if active]
tasks = [self._run_diagnostic_path(node_name, c) for c in active_conditions]
diag_results = await asyncio.gather(*tasks, return_exceptions=True)
# 第三层:日志特征挖掘(精准提取 Error 级别,过去 10 分钟)
log_patterns = await self._extract_kubelet_patterns(node_name, since_minutes=10)
# 第四层:综合诊断 → 结构化报告
return self._synthesize(node_name, conditions, diag_results, log_patterns)
def _synthesize(self, node, conditions, diags, log_patterns) -> dict:
root_cause = self._determine_root_cause(diags, log_patterns)
severity = self._grade_severity(conditions, root_cause, log_patterns)
return {
"node": node,
"root_cause": root_cause,
"severity": severity, # "minor" / "serious" / "critical"
"confidence": root_cause.get("confidence", 0.0),
"recommendation": self._get_runcard(root_cause, severity),
"auto_execute": severity == "minor" and root_cause.get("confidence", 0) > 0.90
}
def _grade_severity(self, conditions, root_cause, log_patterns) -> str:
"""
严重度不只看 Condition,要综合 PSI 趋势和 kubelet 日志模式
PLEG 卡死 → 直接 critical,无需等待其他证据
"""
if log_patterns.get("pleg_unhealthy"):
return "critical"
if conditions.get("Ready") == "Unknown" and root_cause.get("type") != "transient":
return "serious"
return "minor"这里有一个容易被忽视的细节:auto_execute 字段。它不是简单地由严重度决定,而是严重度 + 置信度的联合判断。低置信度的"轻微"故障,应该进入"建议模式"等待人工确认,而不是自动执行。
三、从检测到闭环------分级处置与 Cordon/Drain 自动化
3.1 自动修复的代价:两个真实案例
在讨论"如何自动修复"之前,先看两个因为自动修复策略不当导致二次故障的案例。
案例一:磁盘清理触发数据丢失
某集群的 AI Agent 检测到节点 DiskPressure,自动执行 crictl rmi --prune 清理未使用镜像。但该节点上有一个有状态服务,其数据写入的底层存储挂载在 /var/lib/kubelet/pods/{uid}/volumes/ 路径下,镜像清理操作意外触发了目录遍历,导致一个临时挂载的数据卷被误删。
根因:自动修复逻辑没有检查节点上是否有有状态 Pod 在运行。
案例二:Drain 触发 PDB 死锁
某集群节点因内存泄漏被 AI Agent 自动 Cordon + Drain。该节点上运行了一个三副本的 StatefulSet,PDB 设置 minAvailable=3。Drain 命令尝试驱逐 Pod,但因为 PDB 要求始终保持 3 个可用,而其他节点上只有 2 个副本在运行(第三个副本正在该节点上),驱逐操作永久挂起,drain 命令卡死,整个自动修复链路陷入无响应。
根因:自动 Drain 之前没有检查目标节点上 Pod 的 PDB 合规状态。
这两个案例的共同教训:自动修复不是"执行修复命令",而是"在正确的前置条件下执行正确的修复命令"。前置检查比修复动作本身更重要。
3.2 分级处置策略矩阵
基于以上教训,处置策略必须分三级。三级边界由严重度 × 置信度的二维矩阵决定(详见第六章人机协同边界设计),每级有清晰的前置检查、自动动作和恢复验证:
| 严重级别 | 自动执行条件 | 自动动作 | 恢复验证 | 失败时 |
|---|---|---|---|---|
| 轻微 | kubelet 进程挂起,无有状态 Pod | systemctl restart kubelet |
30 秒后检查 Node Ready | 升级为严重 |
| 轻微 | DiskPressure,根分区 > 85%,无 PVC 写入 | 清理 7 天前容器日志 + 镜像 GC | 1 分钟后检查使用率 | 升级为严重 |
| 严重 | 内核错误 / 节点失联 > 5 分钟 | Cordon + Drain + 高优先级告警 | 验证 Pod 在健康节点重建完成 | 升级为致命 |
| 致命 | 节点完全失联 > 10 分钟 / Force Delete 需求 | 仅推送 P0 告警 | 手动确认 | --- |
3.3 Cordon/Drain 自动化的正确姿势
当判定节点需要进入维护状态时,执行流程必须包含三个阶段的前置检查,才能避免 3.1 中的案例场景:
bash
#!/bin/bash
# 自动化节点维护脚本(含前置检查)
NODE=$1
enter_maintenance() {
echo "=== 前置检查阶段 ==="
# 检查 1:集群剩余健康节点数是否足够
READY_NODES=$(kubectl get nodes --field-selector=status.conditions[0].status=True \
--no-headers | wc -l)
if [ "$READY_NODES" -lt 3 ]; then
echo "ERROR: 剩余健康节点 $READY_NODES 台,低于安全阈值,中止 Drain"
exit 1
fi
# 检查 2:目标节点上是否有违反 PDB 的 Pod
PDB_VIOLATIONS=$(kubectl get pdb -A -o json | \
jq --arg node "$NODE" '[.items[] | select(.status.disruptionsAllowed == 0)] | length')
if [ "$PDB_VIOLATIONS" -gt 0 ]; then
echo "WARNING: 存在 $PDB_VIOLATIONS 个 PDB 不允许中断,Drain 可能挂起"
echo "建议人工确认后执行"
exit 1
fi
echo "=== 前置检查通过,开始维护 ==="
# Step 1: Cordon --- 禁止新调度,已有 Pod 继续运行
kubectl cordon $NODE
# Step 2: Drain --- 优雅驱逐
# --ignore-daemonsets: DaemonSet Pod 由节点管理,驱逐后会在同节点重建,无意义
# --delete-emptydir-data: emptyDir 随 Pod 删除而清除,需业务确认可接受
kubectl drain $NODE \
--ignore-daemonsets \
--delete-emptydir-data \
--timeout=300s
# Step 3: 验证驱逐完成(DaemonSet 以外的 Pod 应为 0)
REMAINING=$(kubectl get pods --field-selector=spec.nodeName=$NODE -A \
--no-headers | grep -v "DaemonSet" | wc -l)
[ "$REMAINING" -eq 0 ] && echo "节点 $NODE 已安全进入维护状态" || \
echo "WARNING: 仍有 $REMAINING 个非 DaemonSet Pod 在节点上"
}
exit_maintenance() {
kubectl uncordon $NODE
# 轮询验证 Ready 状态,最多等 60 秒
for i in {1..6}; do
STATUS=$(kubectl get node $NODE \
-o jsonpath='{.status.conditions[?(@.type=="Ready")].status}')
[ "$STATUS" = "True" ] && echo "节点 $NODE 已恢复" && return 0
sleep 10
done
echo "ERROR: 节点 $NODE 60 秒内未恢复,请人工确认"
return 1
}
case $1 in enter) enter_maintenance ;; exit) exit_maintenance ;; esacPodDisruptionBudget 的陷阱 :如果某个 Deployment 有 3 副本,PDB 设置 minAvailable=3,drain 操作会因为无法将可用副本降至 3 以下而永久挂起。生产环境的 PDB 设置原则 :minAvailable 应为副本数的 50-80%,绝不能等于总副本数。
💡 隐性知识 | 来源:PDB 死锁事件复盘 更隐蔽的情况是:PDB 的 minAvailable 用百分比设置(如 minAvailable: 50%),但 Deployment 的副本数做了 HPA 自动伸缩。当 HPA 缩容到 2 副本时,50% 取整为 1------但 drain 操作计算 minAvailable 时会做 ceil 取整,认为需要保持至少 1 个 Pod 可用,而该节点上只有 1 个副本,驱逐后可用数变为 0,低于 PDB 约束。建议:副本数稳定的 Deployment 用绝对数值设置 PDB,HPA 场景用百分比但要设置 minAvailable: 0 或搭配 PDB 的 maxUnavailable 使用。
四、Pod Pending 与资源碎片------调度异常的"隐性饥饿"
4.1 节点 Ready ≠ Pod 能调度:认知偏差纠正
"节点全是 Ready 的,为什么我的 Pod 还 Pending?"
这是运维团队最高频的困惑之一。调度器的 Filter 阶段在节点通过 Ready 检查之后还有十几道过滤:资源充足性、端口冲突、污点容忍度、节点亲和性、存储拓扑、Volume Zone 匹配......任何一道失败,Pod 就保持 Pending。
bash
# 快速提取所有 Pending Pod 的调度失败原因
kubectl get pods --field-selector=status.phase=Pending -A -o json | \
jq -r '.items[] | "\(.metadata.namespace)/\(.metadata.name): \
\(.status.conditions[]? | select(.type=="PodScheduled") | .message)"'四类调度失败原因及对应处置:
| 失败类型 | 典型消息 | 直接原因 | Agent 建议 |
|---|---|---|---|
| 资源不足 | Insufficient cpu/memory |
Request 设置过高或集群容量不足 | 参考 VPA 建议降低 Request;触发 CA 扩容 |
| 污点不匹配 | node(s) had taints that the pod didn't tolerate |
Pod 缺少必要的 Toleration | 加 Toleration 或移除节点污点 |
| 亲和性冲突 | didn't match node affinity/selector |
NodeSelector 或 Affinity 规则过严 | 改为软偏好 preferredDuringScheduling |
| 存储拓扑失配 | no matching PersistentVolume found |
PVC 与节点不在同一可用区 | 检查 StorageClass 的 volumeBindingMode |
调度器的驱逐判断(Preemption)死锁是最难处理的场景:资源不足时调度器会尝试驱逐低优先级 Pod,但如果候选节点上的低优先级 Pod 被更高优先级的 PriorityClass 保护,驱逐无法执行,Pod 持续 Pending。这种场景下扩容是唯一解,降低 Request 解决不了问题。
💡 隐性知识 | 来源:PriorityClass 冲突导致调度死锁复盘 导致这类"驱逐死锁"的典型配置是:运营团队为所有关键服务设置了较高的 PriorityClass(如 production-critical: 1000000),但为日常任务 Pod 也分配了次高 PriorityClass(如 batch-jobs: 900000)。大批量 batch 任务的 Requests 总和超过了集群容量,调度器试图驱逐 batch 任务时发现它们也有不低的 PriorityClass,且节点上优先级更低的 Pod 数量不足以释放足够资源。建议:PriorityClass 的层级数控制在 3 级以内(critical / normal / best-effort),层级太多会导致驱逐优先级计算复杂度上升,排障时难以判断谁该让谁。
4.2 资源碎片的本质:俄罗斯方块效应
比调度失败更隐蔽的问题是资源碎片化。集群整体剩余资源充足,但分散在多个节点上,导致单个大 Pod 找不到连续空间。 例如:集群 3 个节点各有 4C/8G、3C/6G、2C/4G 的分散可用资源,新 Pod 需要 6C/12G------总剩余 9C/18G 足够,但没有一个单节点能容纳。这就是"俄罗斯方块效应"。Descheduler 将小 Pod 迁移集中后,可以释放出连续空间。(详见 4.3 节。)
碎片化的两个根源:
根源一:保守的 Requests 设置。开发者出于"OOM 恐惧",设置远高于实际使用量的 Requests。一个实际 CPU 使用率 0.1C 的服务,Request 设置 1C 是常见操作。这 0.9C 的差距在单个 Pod 上不明显,但在一个几百个 Pod 的集群里,"锁死"的资源量可能占总容量的 40-60%。
根源二:DaemonSet 税。每个节点上的日志采集、监控、安全插件等 DaemonSet Pod 会占据固定的 CPU/Memory。以每个 DaemonSet Request 0.1C 计,5 个 DaemonSet 在 100 节点集群就锁死 50 核,而实际使用可能不到 20%。控制 DaemonSet 的 Requests 比控制业务 Pod 的收益往往更高。
💡 隐性知识 | 来源:100节点 DaemonSet 资源审计 实际排查中,DaemonSet 的 Request 往往被严重低估。以一个典型的生产集群为例:Fluent-bit(0.2C/256Mi)+ Node Exporter(0.1C/128Mi)+ Datadog Agent(0.3C/512Mi)+ Cilium(0.2C/256Mi)+ kube-proxy(0.1C/64Mi)= 0.9C/1.2Gi 每节点。100 节点 = 90 核锁死。而实际每项 DaemonSet 的日常峰值使用率只有 Request 的 30-50%。先砍 DaemonSet Request 再调业务 Pod,收益通常是前者的 3-5 倍。
4.3 Descheduler:碎片重组的核心工具
Descheduler 的工作原理不是"重新调度"已运行的 Pod,而是识别"可以迁移"的 Pod,触发驱逐后让调度器重新分配,实现更优分布。
四个核心策略对比:
| 策略 | 核心目标 | 最适用场景 | 主要风险 |
|---|---|---|---|
| LowNodeUtilization | 把低负载节点的 Pod 赶向高负载节点,释放低负载节点 | 资源碎片化、准备缩容 | 可能给高负载节点增加压力 |
| HighNodeUtilization | 把 Pod 集中到少数节点,其余节点空出 | 集群整体缩容 | 与 LowNodeUtilization 策略目标相反,不能同时启用 |
| RemoveDuplicates | 确保同一 ReplicaSet 的 Pod 分散在不同节点 | 节点维护后分布不均 | 增加 Pod 迁移频率 |
| RemovePodsViolatingTopologySpread | 修复跨 AZ 分布不均 | 节点上下线后拓扑失衡 | 依赖 TopologySpreadConstraints 配置正确 |
yaml
# Descheduler LowNodeUtilization 生产配置
apiVersion: descheduler/v1alpha2
kind: DeschedulerConfiguration
deschedulingInterval: 15m # 15 分钟运行一次(过高频率导致 Pod 频繁迁移)
strategies:
LowNodeUtilization:
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds: # 低于此值 → 判定为"低负载节点",驱逐其 Pod
cpu: 20
memory: 20
pods: 10
targetThresholds: # 高于此值 → 判定为"高负载节点",不接收新 Pod
cpu: 60
memory: 60
pods: 30
evictableNamespaces:
exclude: ["kube-system", "monitoring"] # 保护系统和监控组件四条实施原则,缺一不可:
- Descheduler 必须配合 Cluster Autoscaler 或 Karpenter 使用,否则驱逐后的 Pod 可能在原节点重调度,毫无效果
- 先在非生产 Namespace 启用,观察 48 小时确认 Pod 迁移不影响业务后再全量
thresholds起点设为 20% CPU,不要过低,否则会频繁驱逐利用率稍高的节点- 有状态服务(StatefulSet)默认不可被 Descheduler 驱逐,需要显式配置
--evict-stateful-sets,且必须确认有状态数据已持久化
💡 规模化场景 | 200 节点集群批量 Descheduler 灰度策略
Descheduler 在全集群启用需要批量灰度,否则一次驱逐大量 Pod 可能导致控制面压力激增(每个被驱逐的 Pod 都会触发调度器重新计算)和业务大面积抖动。
| 阶段 | 范围 | 策略 | 验证指标 |
|---|---|---|---|
| 1. 自选 NS | 3 个非核心 Namespace | evictableNamespaces.include 白名单模式 |
48h 内无 Pod 启动失败、无 PDB 冲突 |
| 2. 全量非核心 | 所有非 kube-system/monitoring |
逐步放宽 to 120 个 NS | Pod 迁移率 < 5%/h、调度器 P99 延迟 < 200ms |
| 3. 核心业务(只驱逐副本数 > 3 的) | 生产 Namespace | thresholds 从 20% 上调至 30%(更保守) |
PDB 违规次数 = 0、关键业务 Pending 率 < 1% |
| 4. 全量 | 所有 Namespace(排除有状态) | 正式上线 | 碎片率从基线值降 50%+ |
并发控制 :Descheduler 默认串行驱逐 Pod,但可以通过 maxNoOfPodsToEvictPerNode 和 maxNoOfPodsToEvictPerNamespace 控制单节点/单 NS 的驱逐上限。生产建议:单节点 ≤ 3 Pod/次,单 NS ≤ 20 Pod/次。
排坑提示 :Descheduler 驱逐后的 Pod 会回到调度队列,调度器按 FIFO 处理。如果集群同时有大量新 Pod 提交和 Descheduler 驱逐的 Pod,调度队列会膨胀,导致新 Pod 等待时间增加。建议 Descheduler 运行时间避开业务高峰期 (如设置在凌晨 2:00-4:00),且 deschedulingInterval 不低于 15 分钟。
五、集群健康评分模型------把运维直觉变成可量化的数字
5.1 "节点都 Ready"是个危险的错觉
kubectl get nodes 全部 Running = 集群正常?这是运维中最危险的认知简化。
真实的集群健康涉及多个维度,节点 Ready 只是其中之一:
- 50% 的 Pod 处于 CrashLoopBackOff
- 调度器队列里积压了 200 个 Pending Pod
- etcd 的 follower 落后了 10 秒
- 某个关键 Namespace 的资源配额用尽了 95%
这些都不会影响 kubectl get nodes 的输出,但每一个都可能是正在恶化的隐患。
健康评分的价值不在于"这个数字好看",而在于用一个统一的信号驱动告警和自动修复的触发阈值。 分数低于 80,团队介入。分数低于 60,触发自动化复盘流程。
5.2 五维度加权评分模型设计
数据输入层
权重 30%
权重 30%
权重 20%
权重 10%
权重 10%
>= 90 75-89
60-74
< 60
Node Conditions\nAPI
Pod Status\nAPI
Metrics Server\n或 Prometheus
Scheduler Events\nAPI
AI Agent\n审计日志
Node 健康率\nReady节点 / 总节点
Pod 正常率\nRunning / 期望副本数
资源效率\n利用率落在 60-80% 理想区间
调度质量\n1 - Pending率
故障自愈率\n自动修复成功 / 总异常数
加权求和\n总分 0-100
🟢 Healthy
🟡 Warning
🟠 Degraded
🔴 Critical
权重设计的考量:Node 和 Pod 各占 30% 是因为它们是最直接的业务影响指标------节点挂了或 Pod 异常,用户直接感知。资源效率占 20% 是因为它影响成本和稳定性,但不是立即触发业务故障。调度质量和自愈率各占 10%,是"系统是否在良性状态运行"的过程指标。
💡 为什么是 30/30/20/10/10 而不是其他组合?| 来源:权重敏感性分析
这不是拍脑袋,而是由故障影响的层级递进关系决定的:
物理约束 → 层级递进:节点故障(L1)→ Pod 异常(L2)→ 资源瓶颈(L3)→ 调度阻塞(L4)→ 修复效率(L5)
权重逻辑:近端(用户直接感知)权重高于远端(后台指标)| 权重方案 | 为什么不够或多余 |
|---|---|
| 25/25/25/12.5/12.5(平均分配) | 资源效率和调度质量权重合计 37.5%,超过了 Node 和 Pod 合计的 50%。但实际经验是:资源效率再差,只要节点和 Pod 健康,用户感知不到。前一维度应占主导地位 |
| 40/30/15/10/5(极端侧重基础设施) | 忽视 Pod 异常会掩盖慢扩散问题------节点全健康但 Pod 在逐台 CrashLoopBackOff,需要 30% 的 Pod 权重才能被评分雷达发现 |
| 35/35/15/10/5(双 35 方案) | 和 30/30/20/10/10 的主要区别在于资源效率权重。试算:某集群资源利用率为 90%(超载)但节点和 Pod 全部健康,35/35/15 给出 35+35+15*60=79 分,30/30/20 给出 30+30+20*60=72 分------后者更能反映"资源紧但还没爆"的中间状态 |
核心约束:Node + Pod 合计 ≥ 60% (确保直接故障占主导),资源效率 ≥ 调度质量 + 自愈率合计(确保间接指标不压过直接指标)。
资源效率的评分逻辑值得特别说明:为什么理想区间是 60-80% 而不是越高越好?过低(< 40%)说明资源浪费,成本问题;过高(> 85%)说明安全余量不足,一旦流量峰值或节点故障,资源立刻耗尽。60-80% 是生产集群的"健康体脂率"。
5.3 评分计算代码实现
python
class ClusterHealthScore:
"""五维度集群健康评分引擎"""
WEIGHTS = {
"node_health": 0.30,
"pod_stability": 0.30,
"resource_efficiency": 0.20,
"scheduling_quality": 0.10,
"auto_recovery_rate": 0.10,
}
def calculate(self, metrics: dict) -> dict:
scores = {
"node_health": (metrics["ready_nodes"] / metrics["total_nodes"]) * 100,
"pod_stability": (metrics["running_pods"] / metrics["expected_pods"]) * 100,
"resource_efficiency": self._score_resource_efficiency(
metrics["cpu_util"], metrics["mem_util"]),
"scheduling_quality": (1 - metrics["pending_pods"] / metrics["total_pods"]) * 100,
"auto_recovery_rate": (metrics["auto_recovery_success"] /
max(metrics["total_anomalies"], 1)) * 100,
}
total = sum(scores[k] * self.WEIGHTS[k] for k in self.WEIGHTS)
return {
"total_score": round(total, 2),
"rating": self._rating(total),
"details": {k: {"raw": round(scores[k], 2),
"weighted": round(scores[k] * self.WEIGHTS[k], 2)}
for k in self.WEIGHTS},
"alerts": self._generate_alerts(scores, total)
}
def _score_resource_efficiency(self, cpu_util: float, mem_util: float) -> float:
"""理想区间 60-80% 得满分,偏离越多分越低"""
avg = (cpu_util + mem_util) / 2
if 60 <= avg <= 80:
return 100.0
if avg < 60:
return 60 + (avg / 60) * 40 # 线性插值到 60 分基线
return max(0, 100 - (avg - 80) * 2) # 超过 80% 每点扣 2 分
def _generate_alerts(self, scores: dict, total: float) -> list:
"""根据单项分数和总分生成告警"""
alerts = []
if scores["node_health"] < 90:
alerts.append({"level": "critical", "msg": f"节点健康率 {scores['node_health']:.1f}%,低于阈值 90%"})
if scores["pod_stability"] < 80:
alerts.append({"level": "warning", "msg": f"Pod 正常率 {scores['pod_stability']:.1f}%,存在异常副本"})
if total < 60:
alerts.append({"level": "critical", "msg": "集群整体评分低于 60,触发 P0 复盘流程"})
return alerts
def _rating(self, score: float) -> str:
if score >= 90: return "healthy"
if score >= 75: return "warning"
if score >= 60: return "degraded"
return "critical"5.4 健康报告自动化
评分模型的价值在于趋势追踪,不是单次快照。通过 CronJob 每天生成日报,每周生成周报:
yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: cluster-health-daily-report
namespace: aiops
spec:
schedule: "0 8 * * *" # 每天 8:00 生成日报
jobTemplate:
spec:
template:
spec:
serviceAccountName: health-reporter # 需要 Node/Pod 读权限
containers:
- name: reporter
image: aiops/health-reporter:latest
env:
- name: REPORT_TYPE
value: "daily"
- name: SLACK_WEBHOOK
valueFrom:
secretKeyRef:
name: aiops-secrets
key: slack-webhook
- name: PROMETHEUS_URL
value: "http://prometheus.monitoring:9090"
restartPolicy: OnFailure日报核心内容:今日总评分 + 昨日对比趋势、24 小时内异常事件 Top 5、各 Namespace 资源消耗变化、AI Agent 自动处置摘要(成功/失败次数)。
周报额外包含:7 天评分趋势图(节点波动幅度、Pod 重启次数累计)、高频异常 Top 3 及改进建议、资源效率变化(判断是否需要扩缩容)。
告警触发规则:总分低于 80 或 Node 健康率低于 90%,自动通知值班团队。总分低于 60 时触发 P0 复盘模板。
六、人机协同边界------AI Agent 的"自动驾驶"分级
AI Agent 在运维中的最大价值不是"替代人",而是把人从重复劳动中解放出来,专注于 Agent 处理不好的边界场景。
这需要非常清晰的"什么事该自动,什么事该人工"的边界定义:
C > 90% 且 低风险
C 70-90% 或 中高风险
C < 70% 或 高危操作
AI Agent 完成诊断\n置信度: C%\n操作风险: R
置信度 × 风险 矩阵
自动驾驶\n无需确认,立即执行
建议模式\n生成报告,等待人工确认
人工区\n仅推送告警,不做任何操作
✓ kubelet 重启\n✓ 日志清理(7天前)\n✓ 镜像 GC\n→ 执行 + 写审计日志
✓ Cordon\n✓ Drain\n✓ Pod 驱逐\n→ 报告 + 一键确认链接
✗ Force Delete Pod\n✗ 控制面操作\n✗ 数据相关操作\n→ 仅告警,等待人工
置信度的计算原则 :不是 LLM 输出的"我有 90% 的把握",而是基于证据数量和证据强度的加权计算。
💡 隐性知识 | 来源:置信度函数设计经验 实际工程中,置信度函数的设计遵循"加权投票"而非"乘积法则":每条日志模式匹配 +0.30,每次命令输出确认 +0.25,历史相似故障记录 +0.15,无矛盾证据 +0.15,基础可信度 +0.15。置信度上限 1.0,有矛盾证据时扣分而非重置为 0。为什么不用乘积?因为日志匹配失败不意味着根因推测错误------可能是日志被轮转清空了。乘积法则会因单个数据缺失将置信度降到 0,加权投票容忍个别数据源不可用。
- 多条 kubelet 日志指向同一根因 → 置信度高
- 只有一条模糊的错误日志,没有其他印证 → 置信度低
- 曾经在类似节点上成功修复过同类问题 → 置信度加权
"建议模式"的设计细节:不是简单地"发一条告警",而是生成包含完整诊断过程、命令清单、预期效果、回滚方案的结构化报告,并附带一个"一键确认执行"的链接。这样人工确认的成本极低,而决策权保留在人手中。
这个边界的价值是制度性的:它明确了自动化到什么程度,什么情况下保留人的判断,而不是追求 100% 自动化。在 L4 生产级系统中,"知道什么时候停下来"比"跑得更快"更重要。
七、实战场景
实战 1:证书批量过期的 40 台批量 NotReady
场景背景
生产集群 200 节点,凌晨 2:00 触发批量告警:40 台节点在 5 分钟内陆续变为 NotReady。值班工程师第一反应是网络分区,但部分节点上的 Pod 仍在正常响应请求。
AI Agent 的批量诊断逻辑
单节点诊断策略在这里不适用。40 台节点不能逐一 ssh 排查------Agent 首先做聚类分析(详见第一章 1.3 节的批量诊断决策树),通过 3 台随机抽样节点的 kubelet 日志确认了证书过期模式。
Agent 诊断推理过程(还原)
[第一层] 读取 40 台节点 Conditions
→ 全部 Ready=Unknown,无 DiskPressure/MemoryPressure
→ 判断:心跳丢失,kubelet 进程或证书问题
[第二层] 抽样 3 台节点(随机分布)
→ systemctl is-active kubelet → "active (running)"(进程存活)
→ 进程存活但心跳丢失 → 证书或 API Server 问题
[第三层] 日志特征挖掘
→ journalctl -u kubelet --priority err -n 20
→ 命中模式:"Failed to list *v1.Node: x509: certificate has expired"
→ 置信度:0.97(日志模式精确匹配 + 3 台节点相同日志)
[第四层] 综合诊断
→ 根因:kubelet 客户端证书过期
→ 严重度:critical(批量节点,无法自愈)
→ 置信度:0.97
→ auto_execute: false(证书重签是高风险操作,进入建议模式)
→ 推送建议报告 + 批量重签命令模板关键决策点:证书重签属于"高风险操作",即使置信度高达 0.97,Agent 也进入建议模式而不是自动执行。原因是批量操作一旦出错(比如新证书权限配置错误),会导致所有节点无法恢复,损失远大于人工等待几分钟的时间成本。
复盘数据:
| 指标 | 纯人工排查 | AI Agent 辅助 |
|---|---|---|
| 根因定位时间 | 15-30 分钟 | 45 秒(Agent 诊断)+ 3 分钟(人工确认) |
| 告警噪声 | 300+ 条(涟漪告警) | 1 条根因告警 + 摘要推送 |
| 二次故障风险 | 高(疲劳状态下人工执行易出错) | 低(标准化命令模板,逐节点验证) |
实战 2:资源碎片导致 GPU Pod 永久 Pending
场景背景
机器学习团队提交一个 8C 64G 的训练 Pod,Pending 超过 30 分钟。集群监控显示整体 CPU 利用率只有 35%,看起来资源充足。
诊断过程
kubectl describe pod 显示:0/12 nodes are available: 12 Insufficient memory
看起来是内存不足,但 12 个节点的内存总剩余量超过 200G,理论上完全能放下这个 Pod。
AI Agent 运行碎片检测:
节点内存剩余分布:
Node-1: 4.2G Node-2: 3.8G Node-3: 6.1G Node-4: 5.5G
Node-5: 4.9G Node-6: 3.2G Node-7: 7.1G Node-8: 5.8G
Node-9: 6.4G Node-10: 4.1G Node-11: 5.2G Node-12: 3.9G
最大单节点剩余: 7.1G < 64G 需求
碎片化率: 高(最大可用节点仅满足需求的 11.1%)
根因: 内存 Request 总和已接近节点容量,但无单节点满足大 Pod 需求
建议:
1. 扩容大内存节点(128G+)专用于 ML 训练负载
2. 启用 Descheduler LowNodeUtilization 整理现有碎片
3. 对现有 Pod 执行 VPA 分析,降低过度保守的 Memory Request事后分析:通过 VPA 分析发现,12 个节点上运行的 Pod 中,平均实际内存使用量只有 Request 值的 28%。这意味着每个节点名义上"被占用"的内存有 72% 是空置的锁定资源。引入 Descheduler 后,3 周内碎片率从 78% 降至 31%,ML 训练 Pod 的 Pending 率从 45% 降至 6%。
实战 3:Agent 误判案例------PSI 突发被错误判断为趋势恶化
这个案例专门呈现 AI Agent 的失误,因为理解失误比理解成功更有价值。
场景背景
某节点在每天 14:00-15:00 会运行批量报表计算任务,期间 CPU PSI 的 avg10 会飙升至 40%+。Agent 在某天检测到 avg10=42%,判断为"趋势性恶化"(因为 avg300 也因历史积累达到了 18%),触发了 Cordon 操作,导致这台节点上的 16 个在线服务 Pod 被迁移到其他节点,造成约 3 分钟的服务抖动。
根因分析:
- PSI
avg10高是正确的------批量任务确实造成了 CPU 竞争 - PSI
avg300偏高是历史数据的"误导"------前 4 天同时段都有类似任务,avg300 反映的是近 5 分钟,已经包含了任务开始的压力积累 - Agent 的
avg10 > threshold AND avg300 > threshold → 趋势恶化逻辑没有考虑时间窗口内的周期性模式
修复方案:为批量计算节点引入"任务时间窗口"白名单,在已知的批量任务时段内,PSI 告警阈值上调,或完全禁用自动 Cordon。
这个案例的教训 :AI Agent 的诊断逻辑需要理解业务周期,而不只是看瞬时指标。没有上下文的数据,再准确也会产生错误的结论。 这也是人机协同边界存在的另一个原因------Agent 缺乏"这台机器每天下午要跑报表"这类常识,人有。
总结:三个认知升级
读完本文,如果只记住三件事:
第一,Node Condition 是症状,不是根因。所有自动化诊断逻辑都要建立在"Condition → 证据收集 → 根因判断"的三阶段上,而不是"DiskPressure=True → 执行清理"的线性映射。跳过证据收集环节,是误判的根源。
第二,自动修复的价值在于前置检查,不在于执行动作 。systemctl restart kubelet 不是技术难点,难点是"在正确的时机,满足正确的前置条件,针对正确的节点"执行这个命令。分级处置策略的本质是把这些"正确的判断"编码为可验证的规则。
第三,健康评分不是"看板装饰",是决策信号。五维度评分模型的价值不在于让集群状态"可视化",而在于把分散的运维指标收敛为一个统一的决策阈值,驱动告警触发、自动修复启动和人工介入的边界判断。
产出物清单
| 产出物 | 类型 | 核心价值 | 位置 |
|---|---|---|---|
| 批量故障聚类分析决策树 | 框架 | 批量 NotReady 的诊断优先级顺序 | 第一章 1.3 |
| 四层 Agent 诊断架构 + Prompt 模板 | 架构 + 代码 | 结构化 CoT,按 Condition 类型路由 | 第二章 2.2 |
| PSI 趋势判断逻辑 | 原理 + 代码片段 | avg10 vs avg300 的语义区分 |
第二章 2.3 |
| Cordon/Drain 前置检查脚本 | 代码 | 含 PDB 合规检查和节点数安全验证 | 第三章 3.3 |
| 分级处置策略矩阵 | 框架 | 自动 / 建议 / 人工三级边界定义 | 第三章 3.2 |
| Descheduler 生产配置 YAML | 配置 | LowNodeUtilization 含安全 Namespace 排除 | 第四章 4.3 |
| 五维度健康评分引擎 | 代码 | 含告警生成和资源效率非线性评分 | 第五章 5.3 |
| 日报/周报 CronJob YAML | 配置 | 自动化健康报告生成 | 第五章 5.4 |
| 人机协同边界决策矩阵 | 框架 | 置信度 × 操作风险的二维决策模型 | 第六章 |
| Agent 误判案例分析 | 案例 | PSI 周期性业务模式的白名单设计 | 第七章 实战 3 |