注:以下习题参考 计算机网络(第八版)谢希仁 编著,数据结构与算法 王曙燕 主编。
一、计算机网络第3章 数据链路层(下) 习题与解答
3-21 什么叫作比特时间?使用这种时间单位有什么好处?100 比特时间是多少微秒?
答案:
比特时间:发送 1 比特所需的时间,即数据率(bit/s)的倒数。例如,10 Mbit/s 以太网的比特时间 = 1/(10×10⁶) = 0.1 μs。
好处:
-
使与速率相关的时延计算统一,方便在不同速率下进行比较分析
-
如:争用期 = 512 比特时间,无需关心具体速率,便于协议设计
100 比特时间换算:
-
10 Mbit/s 以太网:1 比特时间 = 0.1 μs → 100 比特时间 = 10 μs
-
100 Mbit/s 以太网:1 比特时间 = 0.01 μs → 100 比特时间 = 1 μs
-
1 Gbit/s 以太网:1 比特时间 = 0.001 μs → 100 比特时间 = 0.1 μs
3-22 假定在使用 CSMA/CD 协议的 10 Mbit/s 以太网中某个站在发送数据时检测到碰撞,执行退避算法时选择了随机数 r = 100。试问这个站需要等待多长时间后才能再次发送数据?如果是 100 Mbit/s 的以太网呢?
答案:
-
基本退避时间 = 2τ(争用期)= 512 比特时间
-
等待时间 = r × 512 比特时间
10 Mbit/s 以太网:
-
1 比特时间 = 0.1 μs
-
512 比特时间 = 51.2 μs
-
等待时间 = 100 × 51.2 μs = 5120 μs = 5.12 ms
100 Mbit/s 以太网:
-
1 比特时间 = 0.01 μs
-
512 比特时间 = 5.12 μs
-
等待时间 = 100 × 5.12 μs = 512 μs = 0.512 ms
3-23 公式(3-3)表示,以太网的极限信道利用率与连接在以太网上的站点数无关。能否由此推论出:以太网的利用率也与连接在以太网上的站点数无关?请说明你的理由。
答案:
不能推论。
理由:
-
极限信道利用率(公式给出的是最大值)是理论极限,假设各站点发送数据不会冲突,与站点数无关
-
实际利用率受冲突影响:站点数越多,冲突概率越高,实际利用率越低
-
极限利用率 ≠ 实际利用率,前者是上限,后者受站点数、发送频率等因素影响
3-24 假定站点 A 和 B 在同一个 10 Mbit/s 以太网段上。这两个站点之间的传播时延为 225 比特时间。现假定 A 开始发送一帧,并且在 A 发送结束之前 B 也发送一帧。如果 A 发送的是以太网所容许的最短的帧,那么 A 在检测到 B 发生碰撞之前能否把自己的数据发送完毕?换言之,如果 A 在发送完毕之前并没有检测到碰撞,那么能否肯定 A 所发送的帧不会和 B 发送的帧发生碰撞?(提示:在计算时应当考虑到每一个以太网帧在发送到信道上时,在 MAC 帧前面还要增加若干字节的前同步码和帧定界符。)
答案:
已知条件:
-
最短帧长(不含前同步码)= 64 字节 = 512 bit
-
前同步码(7 字节)+ 帧定界符(1 字节)= 8 字节 = 64 bit
-
实际发送的帧长(含前同步码)= 512 + 64 = 576 bit
-
传播时延 = 225 比特时间
-
A 开始发送时刻 t = 0
分析过程:
-
A 在 t = 576 比特时间(含前同步码)发送完毕
-
B 在 t = 225 比特时间检测到 A 的信号
-
若 B 在 t = 224 比特时间之前发送数据,则 A 在发送完毕之前一定能检测到碰撞
-
A 检测到碰撞的最早时间 = 2 × 225 = 450 比特时间
结论:
-
A 在检测到碰撞之前(450 比特时间)已发送 450 bit,尚未发送完(576 bit)
-
因此 A 不能把自己的数据发送完毕
-
如果 A 在发送完毕之前并没有检测到碰撞,那么就能够肯定 A 所发送的帧不会和 B 发送的帧发生碰撞(也不会和其他站点发生碰撞)
3-25 上题中的站点 A 和 B 在 t = 0 时同时发送了数据帧。当 t = 225 比特时间时,A 和 B 同时检测到发生了碰撞,并且在 t = 225 + 48 = 273 比特时间时完成了干扰信号的传输。A 和 B 在 CSMA/CD 算法中选择不同的 r 值选择。假定 A 和 B 选择的随机数分别是 rA = 0 和 rB = 1。试问 A 和 B 各在什么时间开始重传其数据帧?A 重传的数据帧在什么时候到达 B?A 重传的数据帧会不会和 B 重传的数据帧再次发生碰撞?B 会不会在预定的重传时间停止发送数据?
答案
时间线汇总:
| 事件 | 时间(比特时间) |
|---|---|
| A、B 同时开始发送 | 0 |
| A、B 检测到碰撞 | 225 |
| A、B 完成干扰信号传输 | 273 |
| A 退避时间结束(rA=0,退避时间=0),开始检测信道 | 273 |
| B 退避时间结束(rB=1,退避时间=512),开始检测信道 | 273+512=785 |
关键计算:
-
干扰信号在信道上的传播时间 :干扰信号在 t=273 时产生,需要传播到对方。A 的干扰信号到达 B 的时间 = 273 + 225 = 498
-
以太网帧间最小间隔:96 比特时间(12 字节)
A 开始重传的时间:
-
A 在 t=273 开始检测信道,但信道仍被干扰信号占用(直到 498)
-
A 检测到信道空闲后,还需等待 96 比特时间的帧间间隔
-
因此 A 开始重传时间 = 498 + 96 = 594
A 重传帧到达 B 的时间:
-
A 在 594 开始发送,传播时延 225
-
到达 B 时间 = 594 + 225 = 819
B 开始重传的时间:
-
B 在 t=785 开始检测信道
-
B 需要检测到信道连续空闲 96 比特时间才能发送
-
但 B 在 t=819 时(检测开始后 34 比特时间)检测到 A 的帧到达,信道变忙
-
因此 B 不能在预定的 785+96=881 时间发送
结论:
-
A 重传开始时间:594 比特时间
-
B 重传开始时间:无法开始(检测到信道忙)
-
A 重传帧到达 B 时间:819 比特时间
-
A 重传的数据帧不会和 B 重传的数据帧再次发生碰撞(因为 B 根本没能开始发送)
-
B 会在预定的重传时间停止发送数据(检测到信道忙后继续等待)
3-26 以太网上只有两个站,它们同时发送数据,产生了碰撞。于是按截断二进制指数退避算法进行重传。重传次数记为 i,i = 1, 2, 3, ...。试计算第 1 次重传失败的概率、第 2 次重传失败的概率、第 3 次重传失败的概率,以及一个站成功发送数据之前的平均重传次数 I。
答案:
| 重传次数 i | 失败概率 P_i | 计算 |
|---|---|---|
| 第 1 次 | 0.5 | (0.5)¹ |
| 第 2 次 | 0.25 | (0.5)² |
| 第 3 次 | 0.125 | (0.5)³ |
平均重传次数 I:
设 P(传送 i 次才成功) = (第1次失败)×(第2次失败)×...×(第i-1次失败)×(第i次成功)
-
第1次成功概率 = 1 - 0.5 = 0.5
-
第2次才成功概率 = 0.5 × (1 - 0.25) = 0.5 × 0.75 = 0.375
-
第3次才成功概率 = 0.5 × 0.25 × (1 - 0.125) = 0.5 × 0.25 × 0.875 = 0.109375
-
第4次才成功概率 = 0.5 × 0.25 × 0.125 × (1 - 0.0625) = ...
计算统计平均值:
I=∑ i×P(传送 i 次才成功)
最终结果:平均重传次数 I ≈ 1.637
3-27 有 10 个站连接到以太网上。试计算以下三种情况下每一个站所能得到的带宽。
(1) 10 个站都连接到一个 10 Mbit/s 以太网集线器;
(2) 10 个站都连接到一个 100 Mbit/s 以太网集线器;
(3) 10 个站都连接到一个 10 Mbit/s 以太网交换机。
答案:
| 情况 | 设备 | 总带宽 | 每站带宽 |
|---|---|---|---|
| (1) | 10 Mbit/s 集线器(共享) | 10 Mbit/s | 10/10 = 1 Mbit/s |
| (2) | 100 Mbit/s 集线器(共享) | 100 Mbit/s | 100/10 = 10 Mbit/s |
| (3) | 10 Mbit/s 交换机(独享) | 10×10 = 100 Mbit/s | 10 Mbit/s(每端口) |
3-28 10 Mbit/s 以太网升级到 100 Mbit/s,1 Gbit/s 和 10 Gbit/s 时,都需要解决哪些技术问题?为什么以太网能够在发展的过程中淘汰掉自己的竞争对手,并使自己的应用范围从局域网一直扩展到城域网和广域网?
答案:
技术问题:
-
保持帧格式不变,保证兼容性
-
缩短争用期,提高最短帧长要求
-
物理层编码升级(曼彻斯特→4B/5B→8B/10B)
-
介质升级(双绞线→光纤)
-
从共享到交换,解决冲突问题
淘汰竞争对手的原因:
-
以太网开放标准,成本低,兼容性好
-
速率平滑升级(10M→100M→1G→10G→40G→100G)
-
从共享到交换,解决冲突域问题
-
光纤技术使其扩展到城域/广域
-
生态系统完善,产业链成熟
3-29 以太网交换机有何特点?用它怎样组成虚拟局域网?
答案:
特点:
-
多端口网桥
-
每个端口独享带宽
-
存储转发或直通交换
-
隔离冲突域
-
学习 MAC 地址,建立交换表
-
支持全双工通信
VLAN 组网方法:
-
基于端口划分:将交换机的某些端口指定为一个 VLAN
-
基于 MAC 地址划分:根据 MAC 地址分配 VLAN
-
基于 IP 地址划分:根据网络层地址分配
-
跨交换机 VLAN:需 802.1Q 标记协议
3-30 在图 3-30 中,某学院的以太网交换机有三个端口分别和学院三个系的以太网相连,另外三个端口分别和电子邮件服务器、万维网服务器以及一个连接互联网的路由器相连。图中的 A、B 和 C 都是 100 Mbit/s 以太网交换机。假定所有的链路的速率都是 100 Mbit/s,并且图中的 9 台主机中的任何一台都可以和任何一台服务器或主机通信。试计算这 9 台主机和两台服务器产生的总吞吐量的最大值。
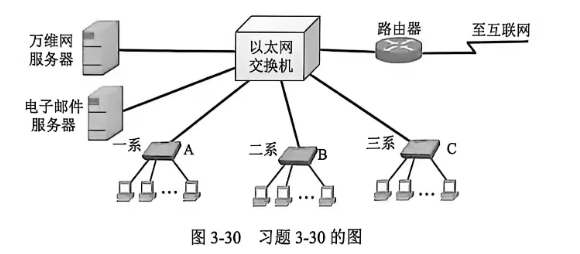
答案:
-
每个交换机端口 100 Mbit/s
-
共 11 个设备(9 台主机 + 2 台服务器)
-
交换机全双工,每对通信独立
-
理想情况:所有端口同时满速率通信
最大值 = 11 × 100 = 1100 Mbit/s
3-31 假定图 3-30 中的所有链路的速率仍然为 100 Mbit/s,但三个系的以太网交换机都换成 100 Mbit/s 的集线器。试计算这 9 台主机和两台服务器产生的总吞吐量的最大值。
答案:
-
每个系内的三台主机共享集线器带宽(100 Mbit/s)
-
每个系上行到主交换机的链路为 100 Mbit/s
-
三个系同时发送:3 × 100 = 300 Mbit/s
-
服务器和路由器通过交换机独立通信
最大值 ≈ 300 + 200 = 500 Mbit/s
3-32 假定图 3-30 中的所有链路的速率仍然为 100 Mbit/s,但所有的以太网交换机都换成 100 Mbit/s 的集线器。试计算这 9 台主机和两台服务器产生的总吞吐量的最大值。
答案:
所有设备都在同一个冲突域中,共享 100 Mbit/s 总带宽。
最大值 = 100 Mbit/s
3-33 在图 3-31 中,以太网交换机有 6 个端口,分别接到 5 台主机和一个路由器。在下面表中的"动作"一栏中,表示先后发送了 4 个帧。假定在开始时,以太网交换机的交换表是空的。试把该表中其他的栏目都填写完。
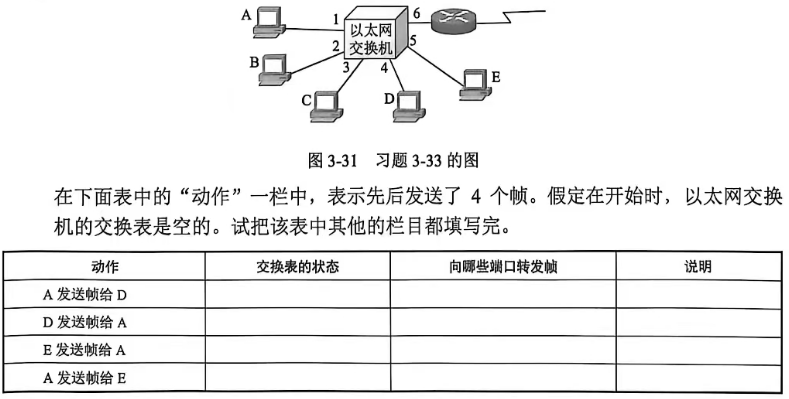
答案:
| 动作 | 交换表的状态 | 向哪些端口转发帧 | 说明 |
|---|---|---|---|
| A发送帧给D | 写入(A, A端口) | 除A端口外的所有端口(D、E、B、C、路由器端口) | 交换机自学习A的MAC地址,未知D的MAC地址,向除A端口外的所有端口泛洪帧 |
| D发送帧给A | 写入(A, A端口),写入(D, D端口) | 仅A端口 | 交换机自学习D的MAC地址,已知A的MAC地址,向A端口单播转发帧 |
| E发送帧给A | 写入(A, A端口),写入(D, D端口),写入(E, E端口) | 仅A端口 | 交换机自学习E的MAC地址,已知A的MAC地址,向A端口单播转发帧 |
| A发送帧给E | 写入(A, A端口),写入(D, D端口),写入(E, E端口) | 仅E端口 | 交换机已知A和E的MAC地址,向E端口单播转发帧 |
| B发送帧给C | 写入(A, A端口),写入(D, D端口),写入(E, E端口),写入(B, B端口) | 除B端口外的所有端口 | 交换机自学习B的MAC地址,未知C的MAC地址,向除B端口外的所有端口泛洪帧 |
二、数据结构------数组与广义表 习题与解答
1、单项选择题
(1) 假设整数数组 A1..8,-2..6,0..6 按行优先存储,第一个元素的首地址是 78,每个数组元素占用 4 个存储单元,那么元素 A423 的存储首地址为 ______。
A. 955
B. 958
C. 950
D. 900
答案:B
解析:
-
三维数组按行优先:先变化最右边下标
-
维度:d1=8, d2=9, d3=7
-
每个元素占 4 字节
-
A423 前面元素数:
-
第1维前3层:(4-1) × d2 × d3 = 3 × 9 × 7 = 189
-
第2维前1行:(2-(-2)) × d3 = 4 × 7 = 28
-
第3维前2个:(3-0) = 3
-
合计 = 189 + 28 + 3 = 220
-
-
地址 = 78 + 220 × 4 = 78 + 880 = 958
(2) 将一个 A1..100,1..100 的三对角矩阵按行优先存入一维数组 B1..298 中,A 中元素 A6665 在 B 数组中的位置 k 为 ______。
A. 198
B. 197
C. 196
D. 195
答案:D
解析:
-
三对角矩阵:每行最多3个非零元素(除首尾行2个)
-
按行优先存储,位置公式(从1开始):k = 2i + j - 2
-
A6665:k = 2×66 + 65 - 2 = 132 + 65 - 2 = 195
(3) 若对 n 阶对称矩阵 A,以行序为主序方式将其下三角形的元素(包括主对角线上的所有元素)依次存放于一维数组 B1..n(n+1)/2 中,则在 B 中确定 aᵢⱼ (i<j) 的位置 k 的关系为 ______。
A. i(i-1)/2 + j
B. j(j-1)/2 + i
C. i(i+1)/2 + j
D. j(j+1)/2 + i
答案:B
解析:
-
对称矩阵只需存下三角(含对角线)
-
当 i < j 时,aᵢⱼ = aⱼᵢ,位置按 (j, i) 计算
-
前 j-1 行元素总数 = (j-1)j/2
-
本行第 i 个位置(j 行前 i 列)
-
公式:k = j(j-1)/2 + i
(4) 设 A 是 n×n 的对称矩阵,将 A 的对角线及对角线以下的元素按行序存放在一维数组 B1..n(n+1)/2 中,对上述任一元素 aᵢⱼ (1≤i,j≤n),且 i≠j 在 B 中的位置为 ______。
A. i(i-1)/2 + j
B. j(j-1)/2 + i
C. i(i-1)/2 + j - 1
D. i(i-1)/2 + j
答案:B
(5) tail(head(((a,b,c,d,e)))) = ______。
A. a
B. bc
C. Φ
D. (b,c,d,e)
答案:D
解析:
-
head(L) 取第一个元素
-
tail(L) 取除第一个外的剩余元素(作为子表)
-
head(((a,b,c,d,e))) = (a,b,c,d,e)
-
tail((a,b,c,d,e)) = (b,c,d,e)
2、完成题
题目原文:
(1) 已知数组 A3..8,2..6 以列序为主顺序存储,起始地址为 1000,且每个元素占 4 个存储单元,求:
① 数组 A 的元素总数。
② 分别计算 A45 和 A63 的地址。
③ 表示元素 Aij 的地址计算公式。
(2) 写出 n 维数组按列序为主进行存储的地址计算公式。
(3) 一个 n 阶对称矩阵 A,其上三角各元素按行序为主序存放于一维数组 B 中,请给出 Bk 和 Aij 的关系(k 的下标从 1 开始)。
(4) 设有三对角矩阵 Aₙₓₙ,将其三条对角线上的元素逐行压缩存储到一个大小为 3n-2 的一维数组 B 中(下标从 1 开始),使得 Bk = Aij,求:
① 用 i,j 表示 k 的下标变换公式。
② 用 k 表示 i,j 的下标变换公式。
(1) 解答
已知:A3..8,2..6 → 行:3~8(共6行),列:2~6(共5列),列序优先,起始地址1000,每个元素4字节。
① 元素总数
6 × 5 = 30
② 地址计算
列序优先:先变化行下标
A45:
-
列号5在列范围2~6中是第4列(2→1, 3→2, 4→3, 5→4)
-
前面列数:4-1=3列,每列6行 → 3×6=18
-
本列前面行数:行4在行范围3~8中是第2行(3→1, 4→2)→ 前面1行
-
前面总元素 = 18 + 1 = 19
-
地址 = 1000 + 19×4 = 1076
A63:
-
列号3是第2列
-
前面列数:1×6=6
-
本列前面行数:行6是第4行 → 前面3行
-
前面总元素 = 6 + 3 = 9
-
地址 = 1000 + 9×4 = 1036
③ 地址计算公式
设 i∈3,8,j∈2,6
地址 = 1000 + (j-2) × 6 + (i-3) × 4
(2)解答
答案:设
-
数组为 Ad1d2d3...dn,各维长度分别为 d1,d2,...,dn
-
每个元素占用 L 个存储单元
-
起始地址为 Loc(0,0,...,0)(下标从0开始)
-
元素下标为 (i1,i2,...,in),其中 0≤ i(k)< d(k)
按列序为主的存储规则(以 n=3 为例说明规律)
列序优先(也称为"以最右边下标变化最慢"或"以最左边下标变化最快"):
对于三维数组 Ad1d2d3:
-
列序优先顺序:先变化 i1(最左边下标),再变化 i2,最后变化 i3(最右边下标变化最慢)
-
即:i3i3 每增加1,跳过 d1×d2 个元素
推广到 n 维:
Loc(i1,i2,...,in)=Loc(0,0,...,0)+in×(d1×d2×...×dn−1)+in−1×(d1×d2×...×dn−2)+...+i2×d1+i1×L
通用公式(下标从 0 开始)
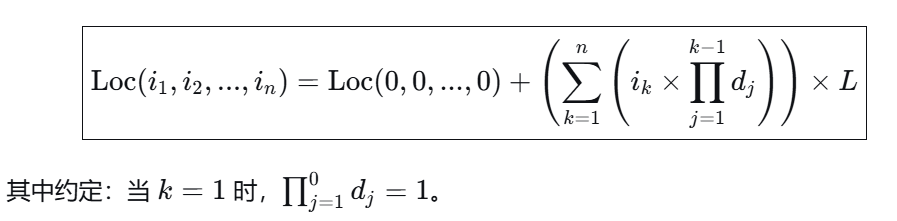
展开式(方便理解)
Loc(i1,i2,...,in)=Loc(0,0,...,0)+(i1+i2×d1+i3×(d1×d2)+i4×(d1×d2×d3)+...+in×(d1×d2×...×dn−1))×L
(3) 对称矩阵上三角存储
上三角元素(含对角线)按行优先存入B1..n(n+1)/2:
当 i ≤ j 时(上三角):
k = (i-1)(2n-i+2)/2 + (j-i+1)
当 i > j 时(下三角):
k = (j-1)(2n-j+2)/2 + (i-j+1)
(4) 三对角矩阵压缩
① 用 i,j 表示 k
三对角矩阵条件:|i - j| ≤ 1
k = 2i + j - 2(当 1≤i,j≤n,且 |i-j|≤1)
② 用 k 表示 i,j
已知 Bk = Aij
i = ⌊(k+1)/3⌋ + 1
j = k - 2i + 2
3、算法设计题
(1) 鞍点
题目原文:
鞍点是指矩阵中的元素 Aij 是第 i 行中值最小的元素,同时又是第 j 列中值最大的元素。试设计一个算法求矩阵 A 的所有鞍点。
核心思路:
-
遍历每一行,找出该行的最小值
-
对该行的每个最小值,检查它是否是其所在列的最大值
-
若是,则输出该鞍点
C语言代码:
void findSaddlePoint(int A[M][N]) {
for (int i = 0; i < M; i++) {
int minVal = A[i][0];
for (int j = 1; j < N; j++) {
if (A[i][j] < minVal) minVal = A[i][j];
}
for (int j = 0; j < N; j++) {
if (A[i][j] == minVal) {
int maxVal = A[0][j];
for (int k = 1; k < M; k++) {
if (A[k][j] > maxVal) maxVal = A[k][j];
}
if (A[i][j] == maxVal) {
printf("鞍点: A[%d][%d] = %d\n", i, j, A[i][j]);
}
}
}
}
}(2) 数组循环右移
题目原文:
设计一个算法,实现将一维数组 A(下标从 1 开始)中的元素循环右移 k 位,要求只用一个元素大小的辅助空间,并给出算法的复杂度。
核心思路(三步反转法):
-
反转整个数组
-
反转前 k 个元素
-
反转后 n-k 个元素
时间复杂度 O(n),空间复杂度 O(1)
C语言代码:
void reverse(int arr[], int start, int end) {
while (start < end) {
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
start++; end--;
}
}
void rightRotate(int arr[], int n, int k) {
if (n == 0) return;
k = k % n;
if (k == 0) return;
reverse(arr, 0, n - 1);
reverse(arr, 0, k - 1);
reverse(arr, k, n - 1);
}(3) 稀疏矩阵加法(三元组顺序表)
题目原文:
已知两个稀疏矩阵 A 和 B 以三元组顺序表进行存储,编写算法实现 A + B。
核心思路:
归并法:同时遍历两个三元组表,按行、列顺序相加
C语言代码:
TSMatrix addSparse(TSMatrix A, TSMatrix B) {
TSMatrix C;
C.rows = A.rows; C.cols = A.cols; C.nums = 0;
if (A.rows != B.rows || A.cols != B.cols) return C;
int i = 0, j = 0;
while (i < A.nums && j < B.nums) {
if (A.data[i].row < B.data[j].row) {
C.data[C.nums++] = A.data[i++];
} else if (A.data[i].row > B.data[j].row) {
C.data[C.nums++] = B.data[j++];
} else {
if (A.data[i].col < B.data[j].col) {
C.data[C.nums++] = A.data[i++];
} else if (A.data[i].col > B.data[j].col) {
C.data[C.nums++] = B.data[j++];
} else {
int sum = A.data[i].value + B.data[j].value;
if (sum != 0) {
C.data[C.nums].row = A.data[i].row;
C.data[C.nums].col = A.data[i].col;
C.data[C.nums].value = sum;
C.nums++;
}
i++; j++;
}
}
}
while (i < A.nums) C.data[C.nums++] = A.data[i++];
while (j < B.nums) C.data[C.nums++] = B.data[j++];
return C;
}(4) 十字链表输出三元组格式
题目原文:
编写程序以三元组格式输出十字链表表示的矩阵。
核心思路:
遍历行链表,输出每个非零结点的行号、列号、值
C语言代码:
void printCrossList(CrossList M) {
printf("行数=%d, 列数=%d, 非零元个数=%d\n", M.rows, M.cols, M.nums);
printf("三元组格式(行,列,值):\n");
for (int i = 1; i <= M.rows; i++) {
OLink p = M.rhead[i];
while (p) {
printf("(%d, %d, %d)\n", p->row, p->col, p->value);
p = p->right;
}
}
}(5) 十字链表转置
题目原文:
编写用十字链表存储稀疏矩阵的转置算法。
核心思路:
创建新矩阵,行列互换,遍历原矩阵每个非零结点,创建新结点(行列交换),插入新矩阵
C语言代码:
CrossList transpose(CrossList M) {
CrossList T;
T.rows = M.cols; T.cols = M.rows; T.nums = M.nums;
T.rhead = (OLink*)malloc((T.rows+1)*sizeof(OLink));
T.chead = (OLink*)malloc((T.cols+1)*sizeof(OLink));
for (int i = 1; i <= T.rows; i++) T.rhead[i] = NULL;
for (int j = 1; j <= T.cols; j++) T.chead[j] = NULL;
for (int i = 1; i <= M.rows; i++) {
OLink p = M.rhead[i];
while (p) {
OLink q = (OLink)malloc(sizeof(OLNode));
q->row = p->col; q->col = p->row; q->value = p->value;
// 插入行链表
if (T.rhead[q->row] == NULL) {
T.rhead[q->row] = q;
} else {
OLink r = T.rhead[q->row];
while (r->right && r->right->col < q->col) r = r->right;
q->right = r->right; r->right = q;
}
// 插入列链表
if (T.chead[q->col] == NULL) {
T.chead[q->col] = q;
} else {
OLink r = T.chead[q->col];
while (r->down && r->down->row < q->row) r = r->down;
q->down = r->down; r->down = q;
}
p = p->right;
}
}
return T;
}(6) 十字链表删除操作
题目原文:
编写十字链表的删除操作的算法。
核心思路:
找到待删除结点,分别从行链表和列链表中移除,释放内存
C语言代码:
int deleteNode(CrossList* M, int row, int col) {
// 从行链表删除
OLink p = M->rhead[row], prev = NULL;
while (p && p->col != col) { prev = p; p = p->right; }
if (p == NULL) return 0;
if (prev == NULL) M->rhead[row] = p->right;
else prev->right = p->right;
// 从列链表删除
OLink q = M->chead[col], prevCol = NULL;
while (q && q->row != row) { prevCol = q; q = q->down; }
if (prevCol == NULL) M->chead[col] = q->down;
else prevCol->down = q->down;
free(p);
M->nums--;
return 1;
}(7) 广义表原子结点求和
题目原文:
已知一个广义表 A,设计算法实现计算 A 中原子结点值的和。
核心思路:
递归遍历:若原子则返回值,若子表则递归调用
C语言代码:
int sumAtoms(GList L) {
if (L == NULL) return 0;
int sum = 0;
if (L->tag == ATOM) sum = L->atom;
else sum = sumAtoms(L->hp);
sum += sumAtoms(L->tp);
return sum;
}(8) 广义表查找值为 x 的结点
题目原文:
已知一个广义表 A,设计算法实现查找值为 x 的结点。
核心思路:
递归遍历:若原子且等于x则返回,若子表则递归查找
C语言代码:
GLNode* findNode(GList L, int x) {
if (L == NULL) return NULL;
if (L->tag == ATOM && L->atom == x) return L;
if (L->tag == LIST) {
GLNode* found = findNode(L->hp, x);
if (found) return found;
}
return findNode(L->tp, x);
}(9) 判断两个广义表是否相同
题目原文:
设计算法判断两个广义表是否相同。
核心思路:
递归比较:类型相同,若原子则值相同,若子表则递归比较
C语言代码:
int isEqual(GList A, GList B) {
if (A == NULL && B == NULL) return 1;
if (A == NULL || B == NULL) return 0;
if (A->tag != B->tag) return 0;
if (A->tag == ATOM) return A->atom == B->atom;
return isEqual(A->hp, B->hp) && isEqual(A->tp, B->tp);
}注:以上习题的解答基于作者自己的理解和计算,如果有任何错误,希望各位读者和大佬指出改正,非常感谢!!!