文章目录
- 一、Reids简介
- 二、安装Redis
-
- [2.1 默认启动](#2.1 默认启动)
- [2.2 指定配置启动](#2.2 指定配置启动)
- [2.3 设置开机自启动](#2.3 设置开机自启动)
- 三、Redis界面客户端
- [四、Redis 数据结构](#四、Redis 数据结构)
-
- [4.1 通用命令](#4.1 通用命令)
- [4.2 String类型](#4.2 String类型)
- [4.3 哈希(Hash)](#4.3 哈希(Hash))
- [4.4 列表(List)](#4.4 列表(List))
- [4.5 集合(Set)](#4.5 集合(Set))
- [4.6 有序集合(sorted set)](#4.6 有序集合(sorted set))
- 五、Redis使用
-
- [5.1 Java 使用 Redis](#5.1 Java 使用 Redis)
- [5.2 python 操作Redis](#5.2 python 操作Redis)
- [六、 Redis 持久化](#六、 Redis 持久化)
-
- [6.1 RDB 持久化(快照)](#6.1 RDB 持久化(快照))
- [6.2 AOF 持久化(追加文件)](#6.2 AOF 持久化(追加文件))
- 七、应用问题解决
-
- [7.1 缓存穿透](#7.1 缓存穿透)
- [7.2 缓存击穿](#7.2 缓存击穿)
- [7.3 缓存雪崩](#7.3 缓存雪崩)
一、Reids简介
NoSQL 也称为"not only SQL"或"non-SQL",它是一种数据库设计方法,可以在关系数据库中的传统结构之外存储和查询数据,NoSQL 数据库并非采用关系数据库的典型表结构,而是将数据存储在一个数据结构中,例如 JSON 文档。由于这种非关系数据库设计不需要使用架构,因此,它提供快速可扩展性以管理通常为非结构化的大型数据集。
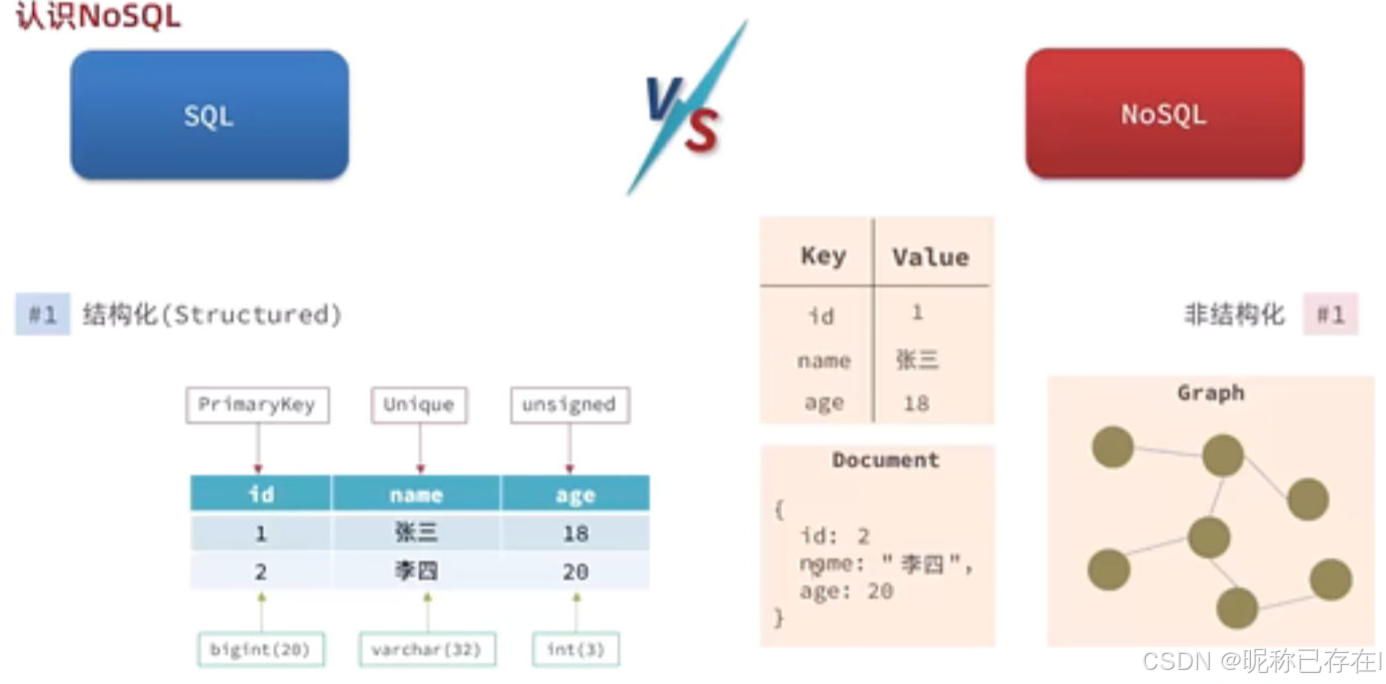
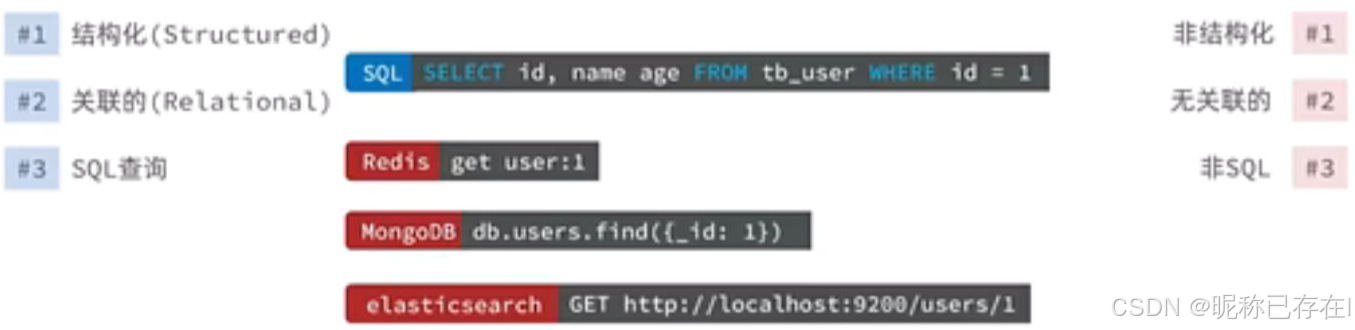
简单来说,NoSQL数据库通过放弃关系型数据库的某些严格限制(如固定的表结构、强一致性、Join操作),换取了极高的扩展性、灵活性和特定场景下的高性能。
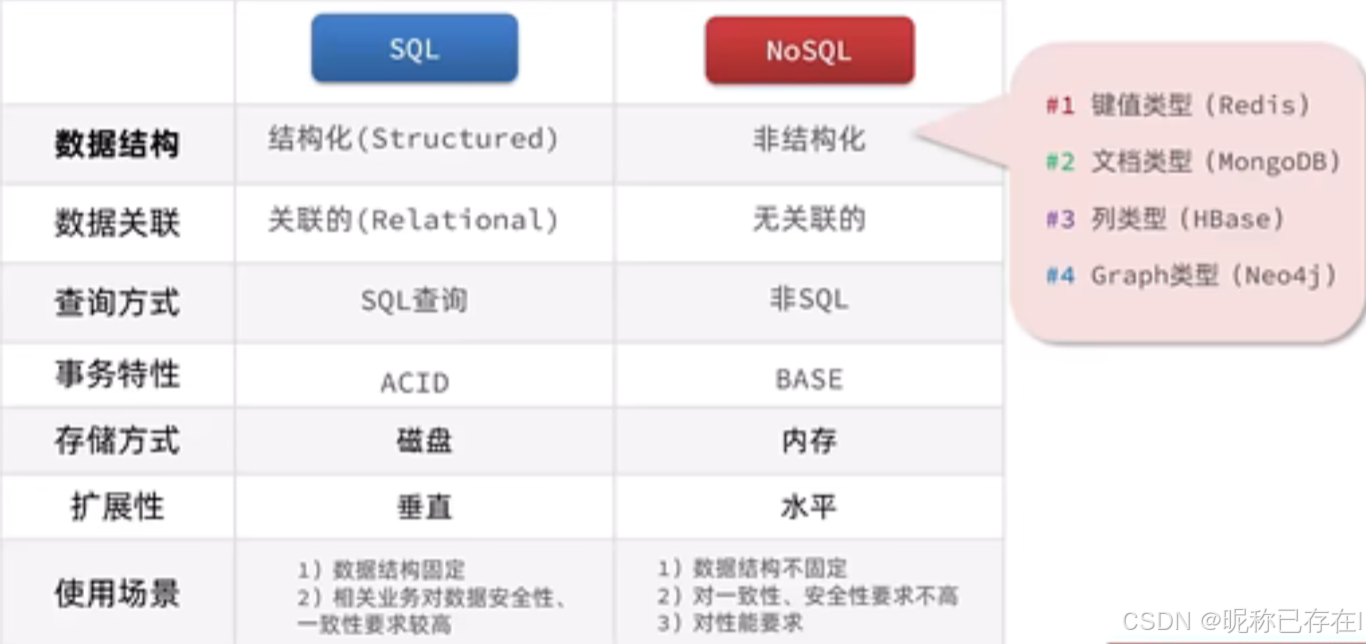
灵活的数据模型 :可以存储没有固定结构的数据,非常适合处理经常变化的非结构化或半结构化数据。
高可扩展性 :多数NoSQL数据库天生支持分布式架构,通过增加更多的普通服务器(节点)来分担负载,而不是仅仅依赖提升单台服务器的硬件性能(垂直扩展)。
最终一致性 :为了在分布式环境中实现高性能和高可用性,不提供传统关系型数据库的强ACID事务保证,而是采用最终一致性模型。

不同NoSQL比对:
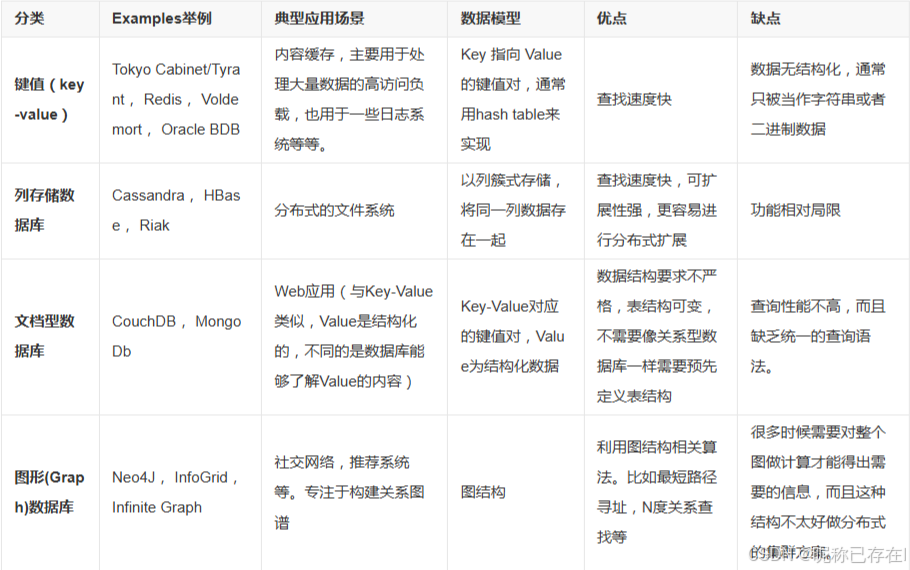
在NoSQL家族的众多成员中,Redis像一个身法奇快的"全能选手"。它把所有数据都放在内存里操作,因此速度极快。但它又不止于快------它还能存储列表、集合等多种结构,既能当缓存使,又能做消息管道,是现代高并发应用不可或缺的加速器。


二、安装Redis
下载 : https://download.redis.io/releases/
或 https://github.com/redis-windows/redis-windows/releases
Redis官方推荐在生产环境中使用Linux系统进行部署,以获得最佳性能和稳定性。不过,在开发和测试环境中,它也可以运行在macOS和Windows(通过WSL2)上。以下是几种主流的安装方式.
python
# Redis的编译依赖于gcc和make等基础开发工具。
# Ubuntu/Debian
sudo apt update
sudo apt install -y build-essential tcl
# CentOS/RHEL
sudo yum groupinstall "Development Tools"
sudo yum install -y tcl
# 下载解压
tar xzf redis-6.2.21.tar.gz
ln -s redis-6.2.21 redis
# 编译与安装
cd redis
make&&make install
# 默认安装路径 /usr/local/bin/
验证安装
2.1 默认启动
python
# 默认启动 默认安装路径 /usr/local/bin/
redis-server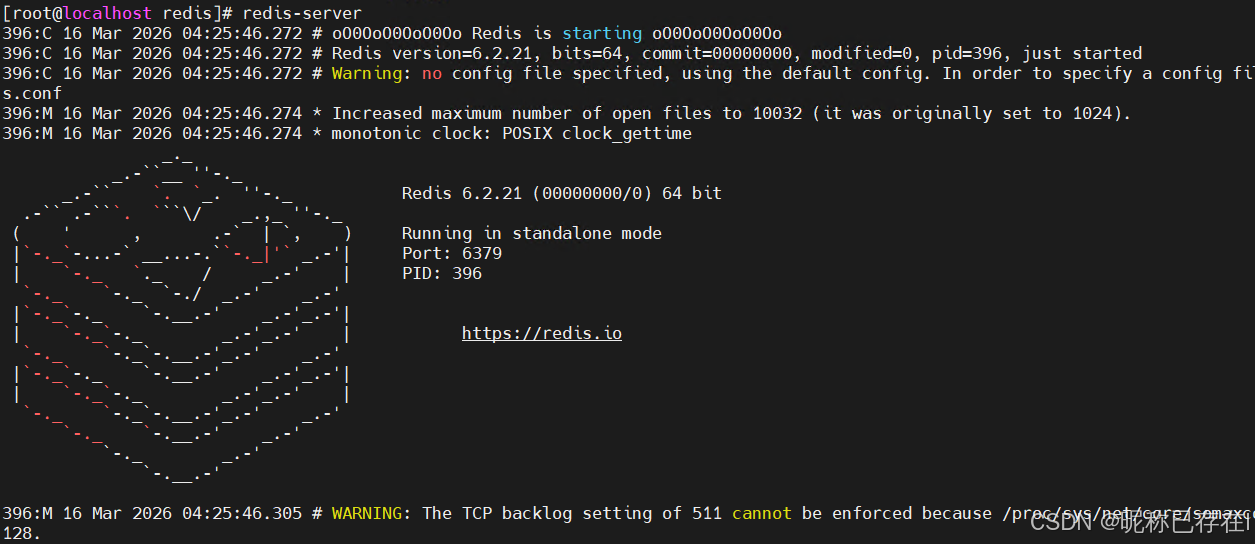
使用客户端连接测试
python
#自带的命令行工具redis-cli连接本机Redis服务,
#并发送PING命令。如果返回PONG,则表示安装成功且服务运行正常。
redis-cli ping
# 互式命令行进行操作
redis-cli
SET name "Redis"
GET name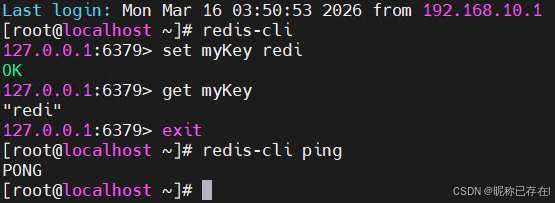
2.2 指定配置启动
安装文件中的配置文件名redis.conf
python
cp redis.conf redis.conf.bak
vim redis.conf
-----------------------------------------------------------------------------------------
# 指定 Redis 监听的 IP 地址。默认是 127.0.0.1,意味着 Redis 仅接受本地连接。如果你想要远程访问,可以设置为 0.0.0.0
bind 127.0.0.1
# Redis 服务的端口号,默认是 6379
port 6379
# 是否以守护(后台)进程的方式启动,默认no
daemonize no
# 传统认证方式:所有连接使用同一个密码
requirepass yourpassword123
# redis默认有16个数据库,编号从0开始。
databases 16
# 指定Redis最大内存限制。达到内存限制时,Redis将尝试删除已到期或即将到期的Key。
maxmemory <bytes> # 512mb
---------------------------------------------------------------------
# 用 * 号获取所有配置项
CONFIG GET *
# 指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning,默认为 notice
loglevel notice
----------
# 启动
redis-server redis.conf
python
redis-cli -a 你的密码 ping
# 1. 连接(不输入密码)
redis-cli
# 2. 进入后认证
127.0.0.1:6379> AUTH 你的密码2.3 设置开机自启动
python
1.#创建服务单元文件
vim /etc/systemd/system/redis.service
-----------------------------------------------------------------------------------------------
[Unit]
Description=Redis In-Memory Data Store
After=network.target
Wants=network.target
[Service]
Type=forking
# 如果redis.conf中daemonize yes,使用forking类型
# aemonize yes,则使用Type=forking;如果设置为daemonize no,则使用Type=simple
ExecStart=/usr/local/bin/redis-server /etc/redis/redis.conf
ExecStop=/usr/local/bin/redis-cli shutdown
Restart=always
# 注意添加用户和组或改为root
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
# 路径为配置文件中路径需保持一致。 cat redis.conf | grep -E "^(pidfile|dir|dbfilename)" 注意目录文件权限改redis
PIDFile=/var/run/redis/redis_6379.pid
[Install]
WantedBy=multi-user.target
---------------------------------------------------------------------------------------------
python
# 重新加载systemd配置
sudo systemctl daemon-reload
# 启用开机自启动
sudo systemctl enable redis
# 立即启动服务
sudo systemctl start redis
# 检查状态
sudo systemctl status redis
python
# 创建 redis 用户和组
sudo groupadd redis
sudo useradd -r -g redis -s /sbin/nologin redis
# 设置目录权限
sudo mkdir -p /var/run/redis
sudo chown redis:redis /var/run/redis
sudo chown -R redis:redis /usr/app/redis
chasudo chown -R redis:redis /var/log/redis 2>/dev/null || sudo mkdir -p /var/log/redis && sudo chown redis:redis /var/log/redis
# 重新启动服务
sudo systemctl daemon-reload
sudo systemctl start redis
sudo systemctl status redis三、Redis界面客户端
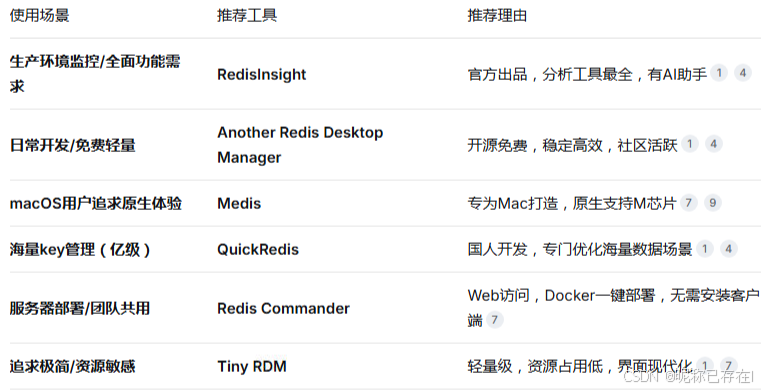
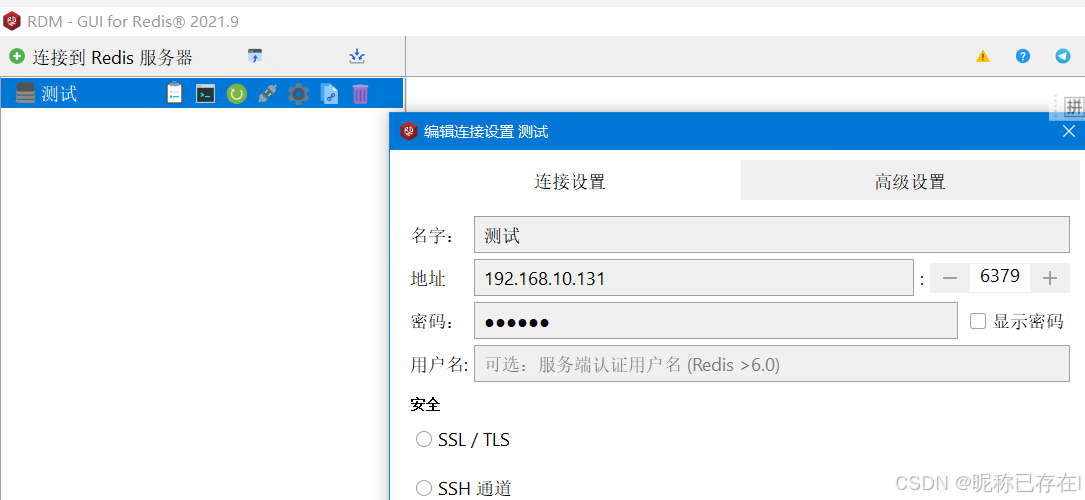
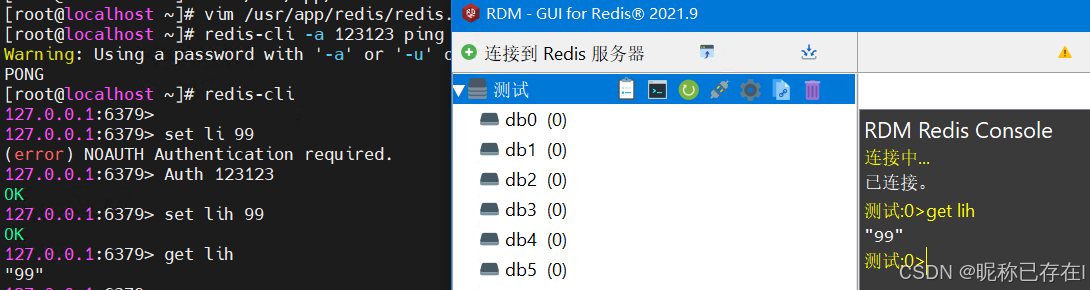
Redis Desktop Manager (RDM)
地址:https://github.com/lework/RedisDesktopManager-Windows
四、Redis 数据结构
Redis经常被称为"数据结构服务器",因为它支持丰富的数据类型

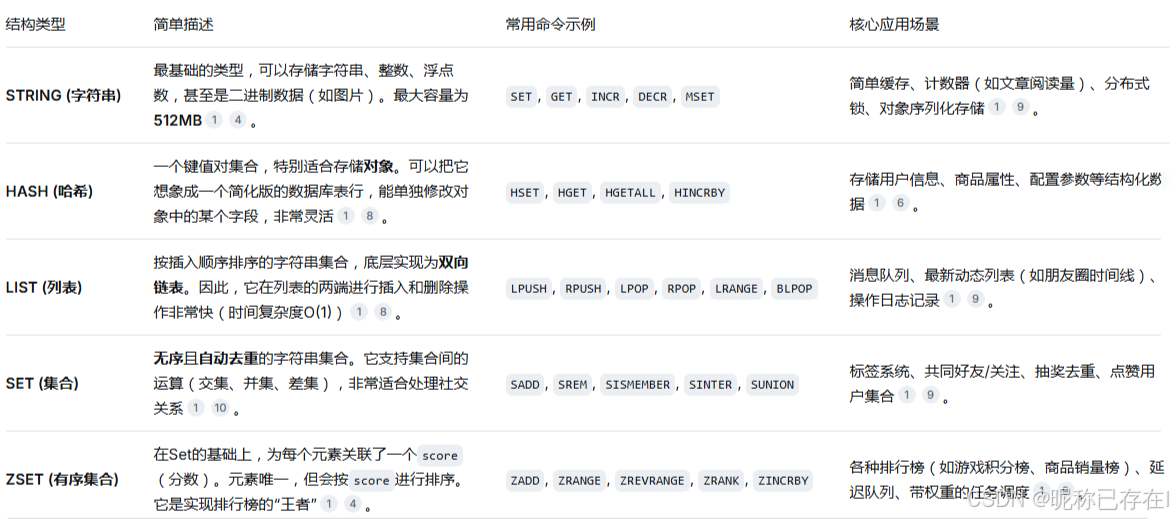

Redis 命令参考:http://doc.redisfans.com/
4.1 通用命令
python
# 添加k-v
set k1 v1
# 删Key
del k3
#给一个Key设置有效期
expire k1 60
# 查看Key的剩余有效期
ttl k1
# 查看当前 timeout 值
config get timeout
# 查看一个命令的具体用法
help del
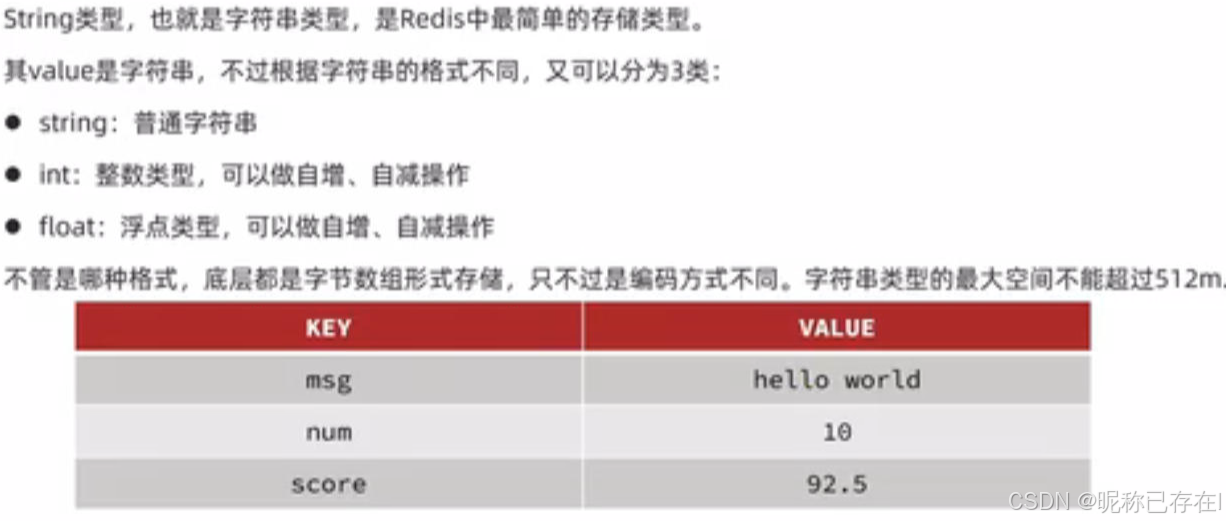
4.2 String类型
python
# 同时设置一个或多个 key-value 对。
127.0.0.1:6379>mset k1 1 k2 "2" k3 x
ok
127.0.0.1:6379>mget k1 k2 k3
1) "1"
2) "2"
3) "x"
# INCR key 将 key 中储存的数字值增一。
127.0.0.1:6379> incr k1
(integer) 2
127.0.0.1:6379> incr k2
(integer) 3
127.0.0.1:6379> incr k3
(error) ERR value is not an integer or out of range
#将 key 所储存的值加上给定的增量值(increment)
INCRBY key increment
#将 key 所储存的值加上给定的浮点增量值(increment) 。
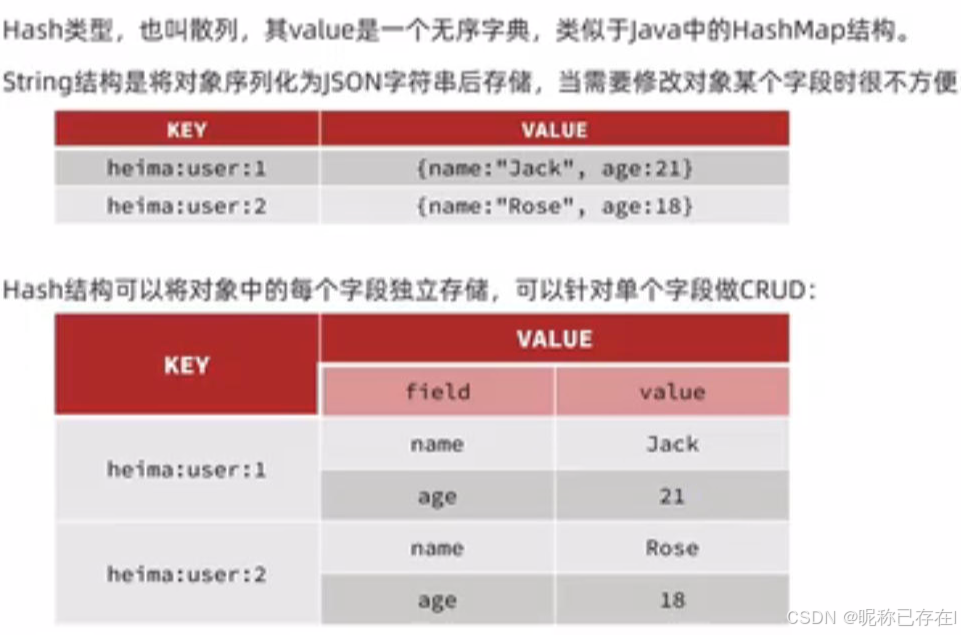
INCRBYFLOAT key increment4.3 哈希(Hash)
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)
python
# 设置描述信息(name, description, likes, visitors) 到哈希表的 runoobkey 中
127.0.0.1:6379> HMSET runoobkey name "redis tutorial" description "redis basic commands for caching" likes 10 visitors 23000
OK
# 获取存储在哈希表中指定字段的值。
127.0.0.1:6379> HGET runoobkey likes
"10"
# 获取哈希表中的所有字段
127.0.0.1:6379> HKEYS runoobkey
1) "name"
2) "description"
3) "likes"
4) "visitors"
# 获取在哈希表中指定 key 的所有字段和值
127.0.0.1:6379> HGETALL runoobkey
1) "name"
2) "redis tutorial"
3) "description"
4) "redis basic commands for caching"
5) "likes"
6) "10"
7) "visitors"
8) "2300"4.4 列表(List)
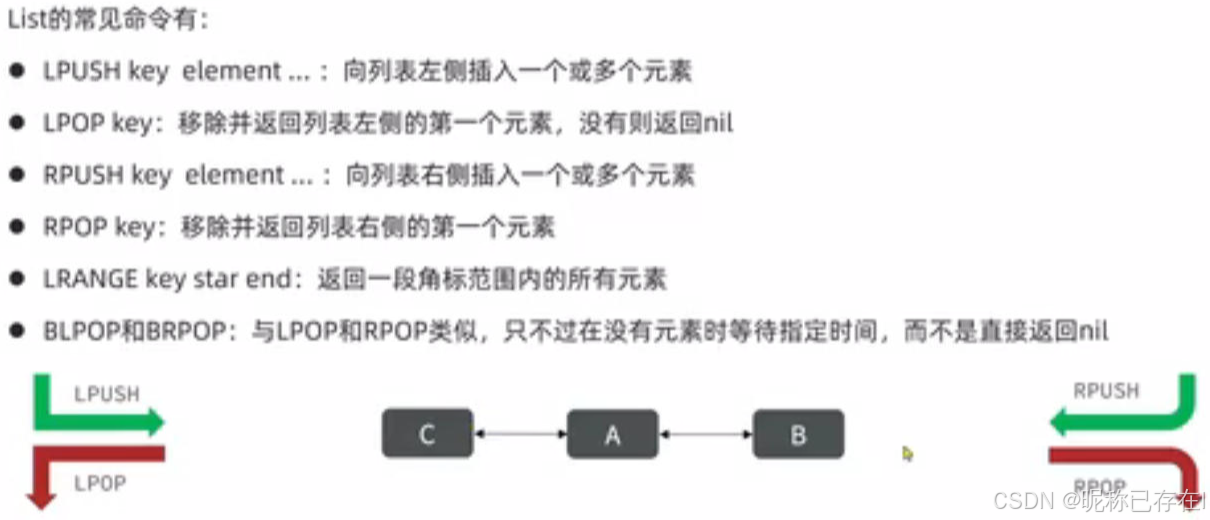
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)
python
# LPUSH key value1 [value2]将一个或多个值插入到列表头部
27.0.0.1:6379> lpush user 1 2 3
(integer) 3
# LRANGE key start stop获取列表指定范围内的元素
127.0.0.1:6379> lrange user 0 2
1) "3"
2) "2"
3) "1"
# RPUSH key value1 [value2]在列表中添加一个或多个值到列表尾部
127.0.0.1:6379> rpush user 4 5 6
(integer) 6
127.0.0.1:6379> lrange user -6 -1
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"
127.0.0.1:6379> lrange user 0 5
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"
# 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除
127.0.0.1:6379> ltrim user 2 3
OK
127.0.0.1:6379> lrange user 0 5
1) "1"
2) "4"4.5 集合(Set)
Redis 的 Set 是 String 类型的无序集合。
集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)

python
# 张三好友
127.0.0.1:6379> sadd zs lisi wangwu zhaoliu
(integer) 3
# 李四好友
127.0.0.1:6379> sadd ls wangwu maiz ergou
(integer) 3
# 获取集合的成员数
127.0.0.1:6379> scard zs
(integer) 3
# 返回集合中的所有成员
127.0.0.1:6379> smembers zs
1) "wangwu"
2) "lisi"
3) "zhaoliu"
# 判断 member 元素是否是集合 key 的成员
127.0.0.1:6379> sismember zs lisi
(integer) 1
# 返回给定所有集合的交集
127.0.0.1:6379> sinter zs ls
1) "wangwu"
# 返回第一个集合与其他集合之间的差异。
127.0.0.1:6379> sdiff zs ls
1) "lisi"
2) "zhaoliu"
# 返回第一个集合与其他集合之间的差异。
127.0.0.1:6379> sdiff ls zs
1) "maiz"
2) "ergou"r4.6 有序集合(sorted set)
redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复


z集合默认按分数值低到高排序

python
# ZADD 向 redis 的有序集合stus中添加了5个值并关联上分数
127.0.0.1:6379> zadd stus 99 lih 80 hei 66 ta 79 matao 88 lina
(integer) 5
# 移除有序集合中的一个或多个成员
127.0.0.1:6379> zrem stus hei
(integer) 1
# 返回有序集合中指定成员的索引 0开始为第一个
127.0.0.1:6379> zrank stus ta
(integer) 0
# 通过索引区间返回有序集合指定区间内的成员
127.0.0.1:6379> zrange stus 0 2
1) "ta"
2) "matao"
3) "lina"
# 返回有序集中指定区间内的成员,通过索引,分数从高到低
127.0.0.1:6379> zrevrange stus 0 2
1) "lih"
2) "lina"
3) "matao"
# 计算在有序集合中指定区间分数的成员数
127.0.0.1:6379> zcount stus 80 90
(integer) 1
# 通过索引区间返回有序集合指定区间内的成员
127.0.0.1:6379> zrangebyscore stus 80 90
1) "lina"五、Redis使用
5.1 Java 使用 Redis
安装了 redis 服务及 Java redis 驱
jedis下载: https://github.com/redis/jedis
python
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>7.1.0</version>
</dependency>
python
## 未做测试 请参考
import redis.clients.jedis.Jedis;
public class RedisStringJava {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("localhost");
// 如果 Redis 服务设置了密码,需要下面这行,没有就不需要
// jedis.auth("123456");
System.out.println("连接成功");
//设置 redis 字符串数据
jedis.set("runoobkey", "www.runoob.com");
// 获取存储的数据并输出
System.out.println("redis 存储的字符串为: "+ jedis.get("runoobkey"));
}
}5.2 python 操作Redis
连接到 redis 服务
python
#!/usr/bin/env python3
"""
Redis 测试数据 - 可选择保留时间
"""
import redis
def add_test_data(redis_client, minutes=5):
"""添加测试数据,指定保留分钟数"""
print(f"\n📝 添加测试数据(保留 {minutes} 分钟)...")
# 列表数据 - 用户会话
list_key = 'test:session:logs'
redis_client.delete(list_key)
redis_client.rpush(list_key,
'用户登录',
'查询订单',
'修改资料',
'退出登录'
)
redis_client.expire(list_key, minutes * 60)
print(f"✅ 列表数据: {list_key}")
# 哈希数据 - 用户信息
hash_key = 'test:user:1001'
redis_client.delete(hash_key)
redis_client.hset(hash_key, mapping={
'name': '李四',
'age': '32',
'email': 'lisi@example.com',
'phone': '13800138000'
})
redis_client.expire(hash_key, minutes * 60)
print(f"✅ 哈希数据: {hash_key}")
# 返回所有键名
return [list_key, hash_key]
# 连接Redis
r = redis.Redis(
host='192.168.10.131',
port=6379,
password='123123',
decode_responses=True
)
# 测试连接
r.ping()
print("✅ Redis连接成功")
# 选择保留时间
print("\n请选择数据保留时间:")
print("1. 1分钟 (快速测试)")
print("2. 5分钟 (默认)")
print("3. 10分钟")
print("4. 30分钟")
print("5. 60分钟 (1小时)")
choice = input("\n请输入选项 (1-5): ").strip()
time_map = {
'1': 1,
'2': 5,
'3': 10,
'4': 30,
'5': 60
}
minutes = time_map.get(choice, 5) # 默认5分钟
# 添加数据
keys = add_test_data(r, minutes)
print(f"\n✅ 数据已添加,将在 {minutes} 分钟后自动删除")
print(f"📌 你可以用以下命令验证:")
for key in keys:
print(f" - 查看 {key}: {r.type(key)}")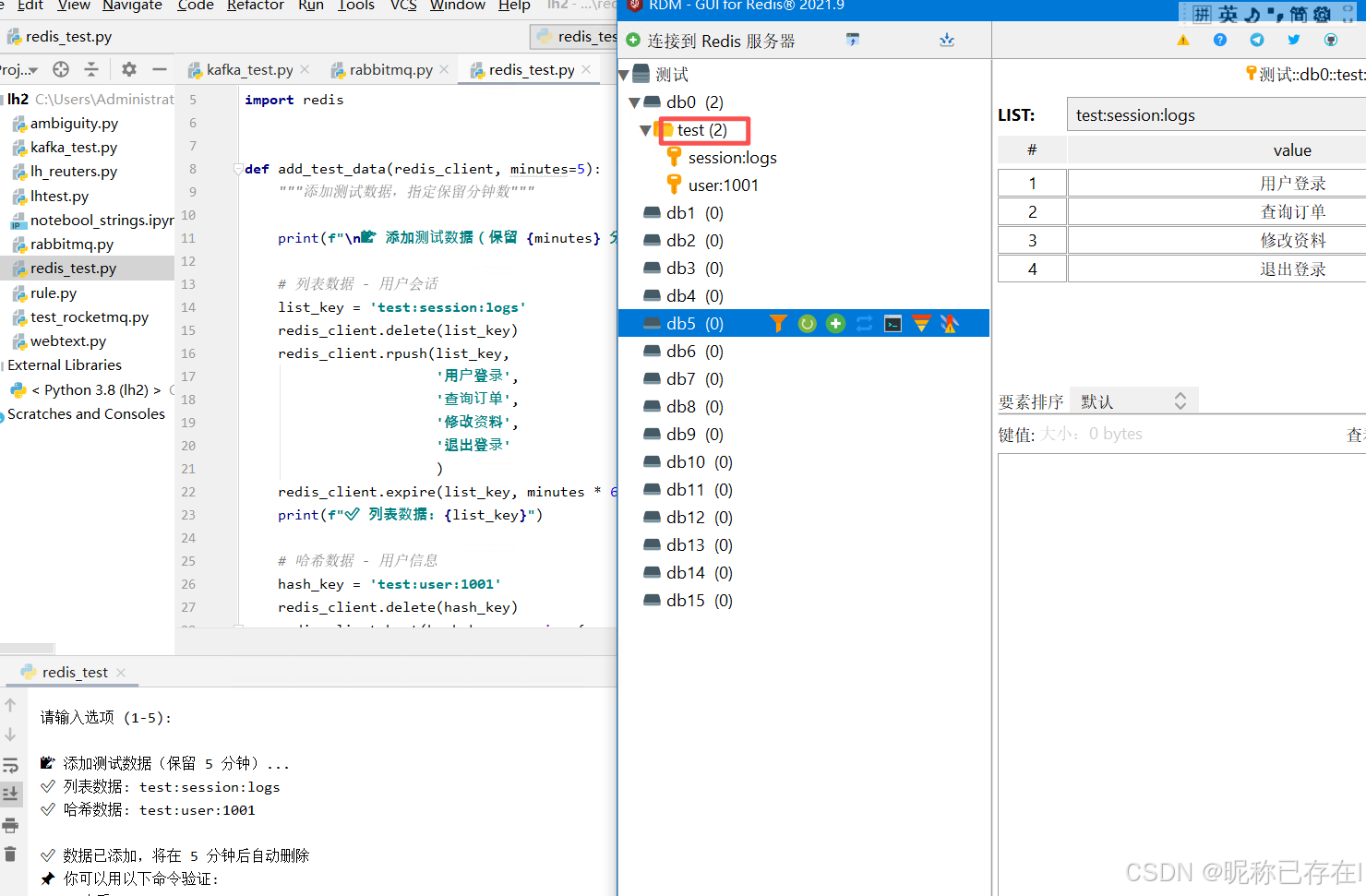
六、 Redis 持久化
Redis 作为内存数据库,数据默认存储在内存中,服务器重启或崩溃时会丢失。持久化就是为了解决这个问题,将数据保存到磁盘上。
Redis 提供两种主要持久化方式:
- RDB(Redis Database):定期生成数据快照
- AOF(Append Only File):记录所有写操作日志

6.1 RDB 持久化(快照)
工作原理
RDB 会在指定时间间隔 生成内存数据的二进制快照,保存到 dump.rdb 文件中
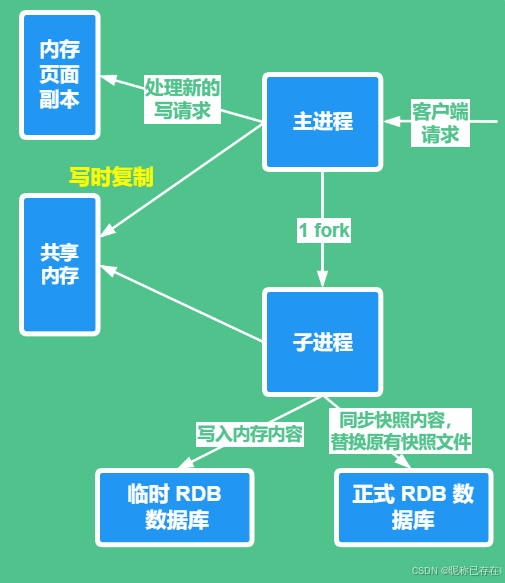
redis 通过 fork 的方式创建一个子进程来专门做持久化的动作,
python
# redis.conf 配置
# ## SNAPSHOTTING ##配置大概364行开始
# sed -n '364,458p' redis.conf |grep -v '^#'|grep -v '^$'
#自动触发
save 900 1 # 900秒(15分钟)内至少有1个key变化
save 300 10 # 300秒(5分钟)内至少有10个key变化
save 60 10000 # 60秒(1分钟)内至少有10000个key变化
# RDB文件配置
dbfilename dump.rdb # 文件名
dir /var/lib/redis # 保存路径
rdbcompression yes # 是否压缩默认配置:

python
# 检查配置:
redis-cli CONFIG GET save
------
# 默认配置
1) "save"
2) "3600 1 300 100 60 10000"
3600 1 # 3600秒(1小时)内至少有1个key改变
300 100 # 300秒(5分钟)内至少有100个key改变
60 10000 # 60秒内至少有10000个key改变
-------
# 监控RDB状态
redis-cli INFO Persistence
---------------------------------------------
rdb_changes_since_last_save:0 - #上次成功保存后,有多少个key发生了变化
rdb_bgsave_in_progress:0 - #是否正在执行后台RDB保存(0=否,1=是)
rdb_last_save_time:1773869532 - #最后一次成功RDB保存的Unix时间戳
rdb_last_bgsave_status:ok - #最后一次后台RDB保存的状态(ok/err)
rdb_last_bgsave_time_sec:-1 - #最后一次后台保存耗时(秒),-1表示从未执行过
rdb_current_bgsave_time_sec:-1 - #当前正在进行的后台保存已耗时,-1表示没有进行中
rdb_last_cow_size:0 - #最后一次RDB保存时的Copy-On-Write内存大小(字节)
--------------------------------------------------save报错:
dump.db保存文件目录确保该目录存在且 redis 用户拥有写权限:
python
vim redis.conf
--------------------------------------------------------------
# The working directory.
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
# The Append Only File will also be created inside this directory.
# Note that you must specify a directory here, not a file name.
dir ./
#将 dir ./ 改为 dir /var/lib/redis,并确保该目录存在且 redis 用户拥有写权限:
----------------------------------------------------------
# 手动测试
127.0.0.1:6379> CONFIG SET dir /usr/app/redis
OK
127.0.0.1:6379> CONFIG SET dbfilename dump.rdb
OKRedis 会根据配置文件中的 dir 和 dbfilename 设置寻找 RDB 文件,
RDB 文件的恢复速度通常比 AOF 快,适合大数据集的恢复,如果同时开启了 AOF 和 RDB,Redis 会优先使用 AOF 文件恢复数据(因为 AOF 通常包含更完整的数据)。
6.2 AOF 持久化(追加文件)
AOF(Append Only File)是Redis中另一种关键的持久化机制。
将我们的写命令全部记录下来,只允许追加文件,不允许改写文件。恢复的时候,将文件中的记录全部执行一遍
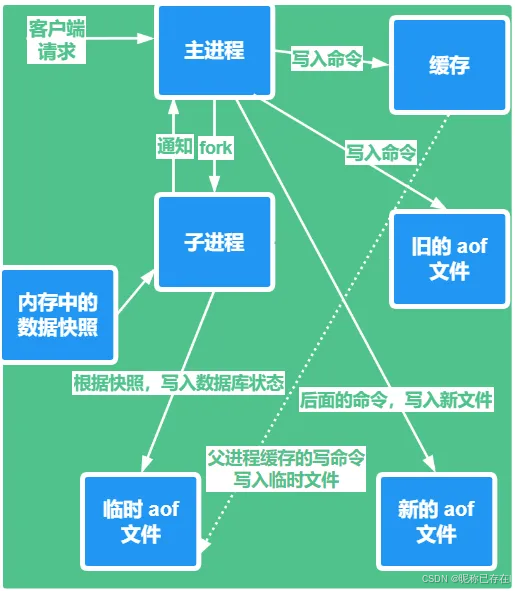
redis 重启的时候,就会根据日志文件的内容将写指令按照写入顺序执行,完成数据恢复。aof 保存的是 appendonly.aof 文件
默认配置:
python
sed -n '1238,1367p' redis.conf |grep -v '^#'|grep -v '^$'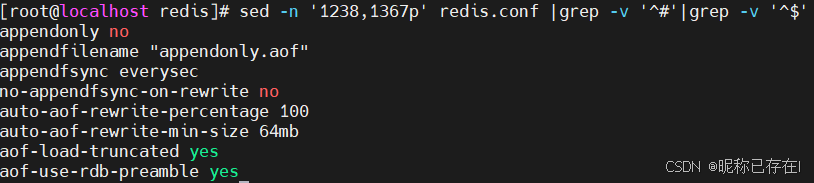
python
appendonly no # AOF开关:no=关闭,yes=开启
appendfilename "appendonly.aof" # AOF文件名
appendfsync everysec # 写回策略:always/everysec/no,everysec是每秒同步(推荐)
no-appendfsync-on-rewrite no # 重写时是否暂停fsync:no=不暂停(继续同步),yes=暂停
auto-aof-rewrite-percentage 100 # AOF重写增长率:文件大小比上次重写时增长100%时触发
auto-aof-rewrite-min-size 64mb # AOF重写最小触发尺寸:文件达到64MB才考虑重写
aof-load-truncated yes # 加载时是否截断损坏的AOF文件:yes=允许启动并截断,no=启动失败
aof-use-rdb-preamble yes # 混合持久化开关:yes=开启(RDB头+AOF尾),no=纯AOF关于 aof 的配置基本上其他的都是使用默认的配置即可,我们只需要把 aof 模式打开即可
python
appendonly yes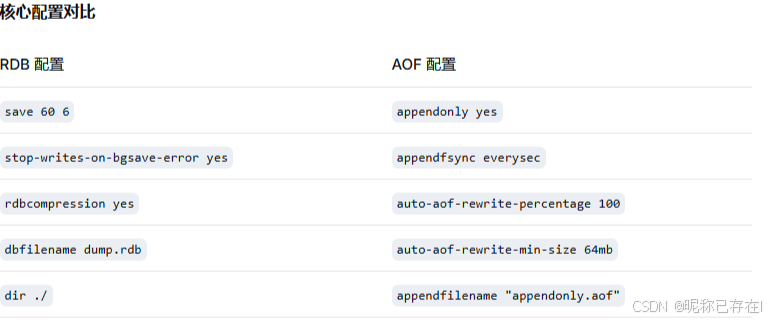
当 Redis 同时开启 RDB 和 AOF 时,重启后默认会优先使用 AOF 文件进行数据恢复。因为你当前的 AOF 文件是空的,如果直接重启,Redis 会加载一个空的数据集,导致你的 RDB 文件被忽略。
可以通过在线热修改 的方式来完成,避免再次重启造成服务中断。
在线开启 AOF:
python
127.0.0.1:6379> CONFIG SET appendonly yes
OK这个命令会立即启用 AOF,Redis 会在后台开始将当前内存中的数据写入到一个新的 AOF 文件中,这个过程不会阻塞你的服务
python
[root@localhost redis] ll | grep -E "dump.rdb|appendonly.aof"
-rw-r--r--. 1 redis redis 298 Mar 19 03:50 appendonly.aof
-rw-r--r--. 1 redis redis 298 Mar 19 03:51 dump.rdb持久化配置到文件
python
# 用当前的内存配置来更新你的 redis.conf 文件,将 appendonly 重新设为 yes
CONFIG REWRITE
# 或手工修改配置文件后重启,因为appendonly以有数据了这套流程的核心思想是:先让 Redis 以 RDB-only 模式启动来恢复数据,数据确认无误后,再在线启用 AOF,避免空 AOF 文件造成的数据丢失
RDB的快速恢复 + AOF的高安全性"的实现方式
混合持久化
同时开启 RDB 和 AOF,并设置 aof-use-rdb-preamble yes,AOF 文件前半段是 RDB 格式快照,后半段是增量命令,兼具RDB 的快速恢复和AOF 的高安全性。
七、应用问题解决
7.1 缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,导致每次请求都要穿过缓存层,直接查询数据库现象.
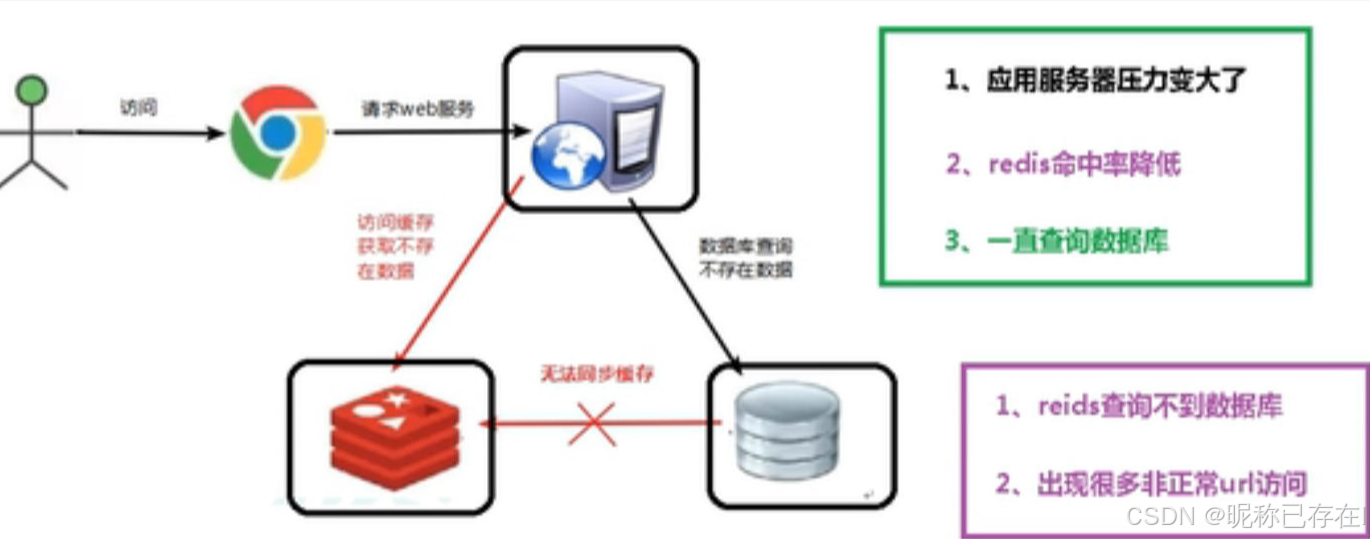
典型场景
恶意攻击:爬虫或攻击者持续扫描不存在的用户ID(如 id = -1、id = 999999 等
解决方案
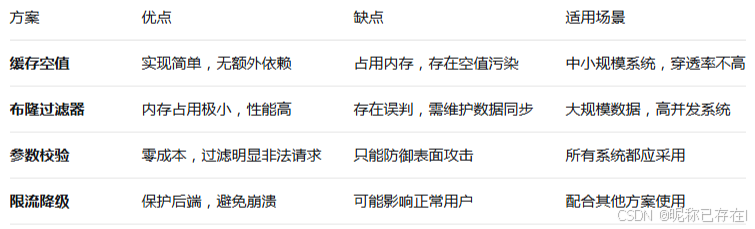
例 参数合法性校验:
在业务入口层对请求参数进行严格的格式校验,提前过滤掉明显不合法的请求
python
public Result queryById(String id) {
// 1. 基本格式校验
if (id == null || id.length() == 0) {
return Result.fail("ID不能为空");
}
// 2. 业务规则校验(例如ID必须是数字且大于0)
if (!StringUtils.isNumeric(id) || Long.parseLong(id) <= 0) {
return Result.fail("ID格式不正确");
}
// 3. 权限校验
if (!checkPermission(id)) {
return Result.fail("无权访问");
}
// 4. 正常查询流程
// ...
}7.2 缓存击穿
缓存击穿是指某一个热点key在缓存过期的瞬间,同时有大量并发请求访问这个key,导致所有请求都直接穿透到数据库的现象。
与缓存穿透不同,缓存击穿访问的数据在数据库中是真实存在的,只是在某个时间点缓存刚好失效了
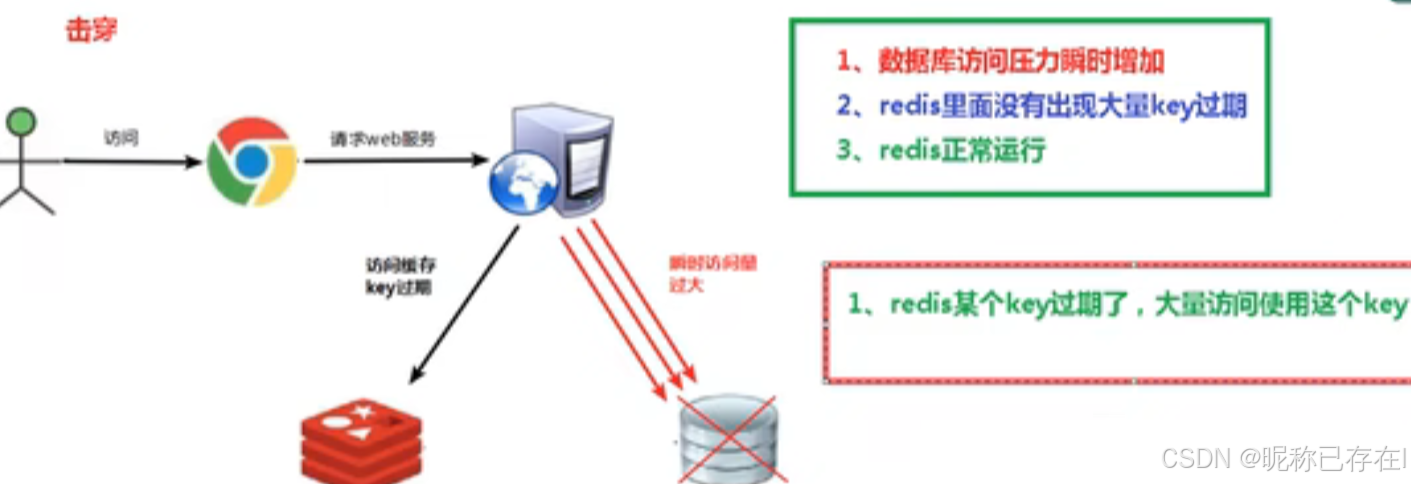
典型场景
秒杀商品:某个爆款商品的详情页缓存过期,大量用户同时刷新
解决方案

普通热点key → 互斥锁保护
超高热点key → 逻辑过期 + 异步刷新
稳定热点key → 永不过期 + 定时刷新
例如 方案一:互斥锁(Mutex Lock):
当缓存失效时,只允许一个线程去查询数据库重建缓存,其他线程等待重建完成。
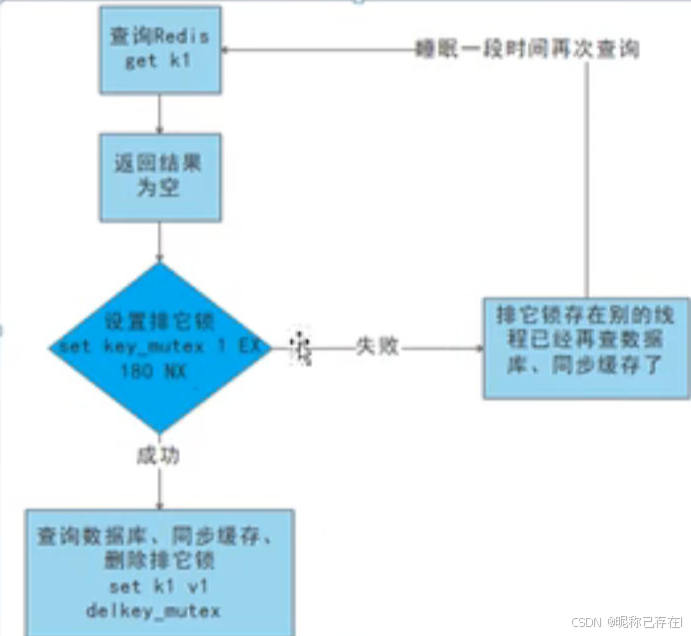
python
public Result queryById(Long id) {
String key = "cache:shop:" + id;
String lockKey = "lock:shop:" + id;
// 1. 从缓存查询
String shopJson = redis.get(key);
if (StrUtil.isNotBlank(shopJson)) {
return Result.ok(JSONUtil.toBean(shopJson, Shop.class));
}
// 2. 缓存未命中,尝试获取互斥锁
String lockValue = UUID.randomUUID().toString();
Boolean isLock = redis.setnx(lockKey, lockValue, 10); // 10秒过期
if (isLock) {
// 3. 获取锁成功,查询数据库
try {
Shop shop = db.query(id);
if (shop == null) {
redis.setex(key, "NULL", 300);
return Result.fail("数据不存在");
}
redis.setex(key, JSONUtil.toJsonStr(shop), 3600);
return Result.ok(shop);
} finally {
// 4. 释放锁(需要校验是否是自己的锁)
String currentLock = redis.get(lockKey);
if (lockValue.equals(currentLock)) {
redis.del(lockKey);
}
}
} else {
// 5. 获取锁失败,等待一段时间后重试
Thread.sleep(50);
return queryById(id); // 递归重试(实际应用需设置重试次数)
}
}7.3 缓存雪崩
缓存雪崩是指在某一个时间段内,大量的缓存key同时失效,或者缓存层整体宕机.
如果说缓存击穿是"单点失效",那缓存雪崩就是"群体事件"。
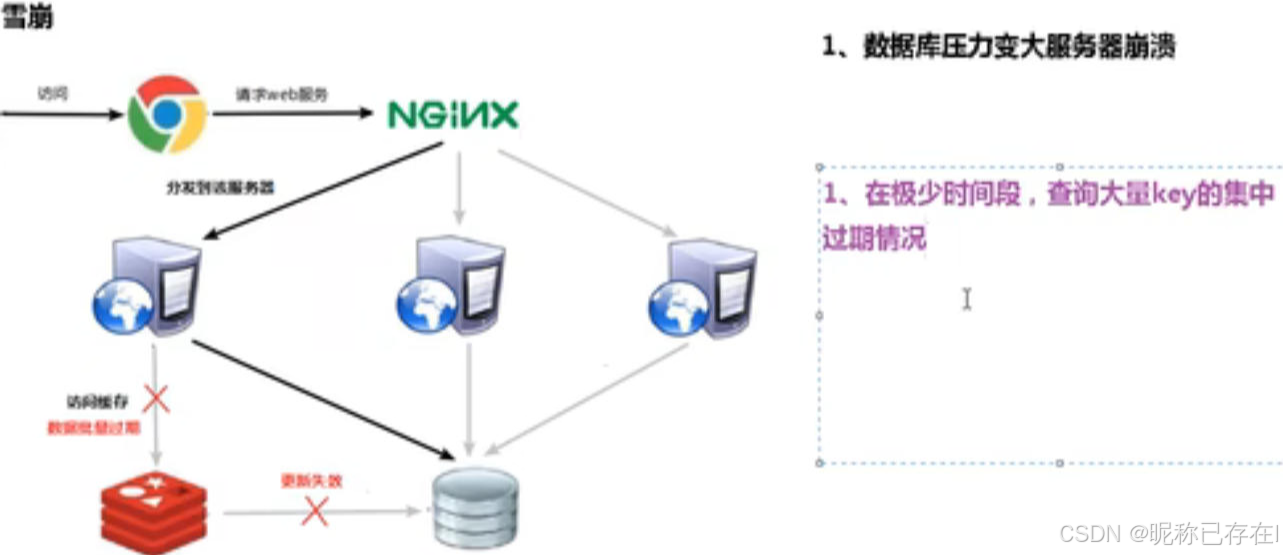
缓存雪崩的破坏力远大于击穿和穿透,因为它往往是大规模、系统级的故障:
典型场景
批量失效:所有缓存的过期时间设置成相同值(如统一凌晨过期)
缓存服务宕机:Redis集群整体故障
网络分区:应用服务器与缓存服务器网络中断
重启恢复:缓存服务重启后,大量key需要重建
解决方案
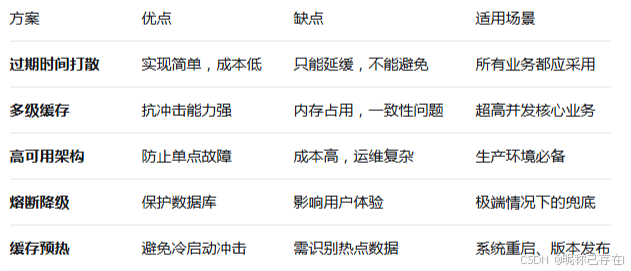
在实际生产环境中,需要构建多层次的雪崩防御体系:
第一层:过期时间打散 + 永不过期策略
↓ 第二层:多级缓存(本地缓存)
↓ 第三层:Redis高可用(主从/集群)
↓ 第四层:数据库连接池限流
↓ 第五层:熔断降级 + 优雅降级页面
python
@Service
public class CacheService {
// 本地缓存(一级缓存)
private Cache<String, Object> localCache = Caffeine.newBuilder()
.maximumSize(100000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
@Autowired
private StringRedisTemplate redisTemplate; // Redis(二级缓存)
@Autowired
private DatabaseService databaseService; // 数据库
@Autowired
private RateLimiter rateLimiter; // 限流器
public Object query(String key) {
// 1. 限流前置
if (!rateLimiter.tryAcquire()) {
return getFallback(key);
}
// 2. 查询本地缓存
Object value = localCache.getIfPresent(key);
if (value != null) {
return value;
}
// 3. 查询Redis(带随机过期时间)
String json = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(json)) {
value = JSONUtil.toBean(json, Object.class);
localCache.put(key, value); // 回填本地缓存
return value;
}
// 4. 分布式锁保护数据库
String lockKey = "lock:" + key;
String lockValue = UUID.randomUUID().toString();
Boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, lockValue, 3, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(locked)) {
try {
// 双重检查
json = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(json)) {
return JSONUtil.toBean(json, Object.class);
}
// 查询数据库
value = databaseService.query(key);
if (value != null) {
// 写入Redis(基础过期时间 + 随机偏移)
int baseExpire = 3600;
int randomOffset = ThreadLocalRandom.current().nextInt(600);
redisTemplate.opsForValue()
.set(key, JSONUtil.toJsonStr(value), baseExpire + randomOffset, TimeUnit.SECONDS);
localCache.put(key, value); // 写入本地缓存
} else {
// 缓存空值(短过期时间)
redisTemplate.opsForValue()
.set(key, "NULL", 300, TimeUnit.SECONDS);
}
return value;
} finally {
// 释放锁
String currentLock = redisTemplate.opsForValue().get(lockKey);
if (lockValue.equals(currentLock)) {
redisTemplate.delete(lockKey);
}
}
} else {
// 未获取到锁,等待后重试
Thread.sleep(50);
return query(key); // 递归重试(实际应用需限制次数)
}
}
// 降级方案
private Object getFallback(String key) {
// 1. 尝试从本地缓存获取(即使已过期)
Object local = localCache.getIfPresent(key);
if (local != null) {
return local; // 返回可能过期的数据,优于返回空
}
// 2. 返回默认值
return "系统繁忙,请稍后重试";
}
}缓存雪崩 vs 缓存击穿 vs 缓存穿透
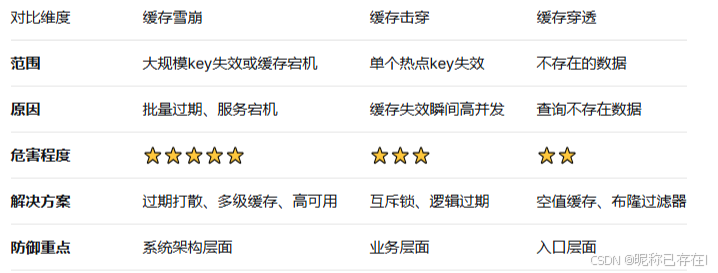
一句话总结:缓存雪崩是大规模的灾难,需要从架构层面构建防御体系;击穿和穿透是局部问题,可以通过业务逻辑解决.
总结
Redis 不仅仅是一个缓存工具,更是一个高性能的内存数据存储系统。
本文主要内容:
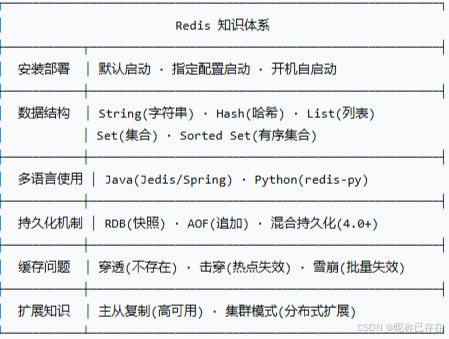
在实际生产环境中,需要牢记以下几点:
-
数据有价,持久化先行:根据数据重要性选择合适的持久化策略
-
监控是眼睛,日志是耳朵:部署完善的监控系统(Prometheus +
Grafana),及时发现异常
-
容量规划要提前:预估数据增长,提前做好分片和扩容准备
-
安全问题不放松:设置强密码、绑定内网IP、开启防火墙
-
缓存问题防患于未然:在系统设计阶段就考虑穿透、击穿、雪崩的防护措施
Redis和Kafka

你去找 Redis 要东西(读请求),它直接从内存拿给你,快。
你往 Kafka 扔东西(写请求/事件),它先稳稳收下存好,让别的系统慢慢来拿,稳