文章目录
残差连接的技术演进:从CNN到ResNet
一、CNN的缺陷
1、CNN的背景与原理
在CNN出现之前,图像处理是传统机器学习的一大难题,当时的主流方法是多层感知机MLP,由于使用全连接网络进行训练,若有一张像素点为 100 × 100 100 \times 100 100×100,通道数为 3 3 3 的简单RGB图像,假设神经网络的第一层神经元仅1000个,那么将图像拉平后输入第一个全连接层参数量就有 3 × 10 7 3 \times 10^7 3×107之多,而且现在大多数图像的像素点和神经元的数量都要远远超过假设数值,因此使用MLP进行图像处理是非常困难的。
💥1989年CNN的提出,直接让图像处理的参数量呈现指数级下降,CNN也正式成为了计算机视觉领域的绝对霸主。它对图像处理的成功主要取决于引入了 两个核心机制:
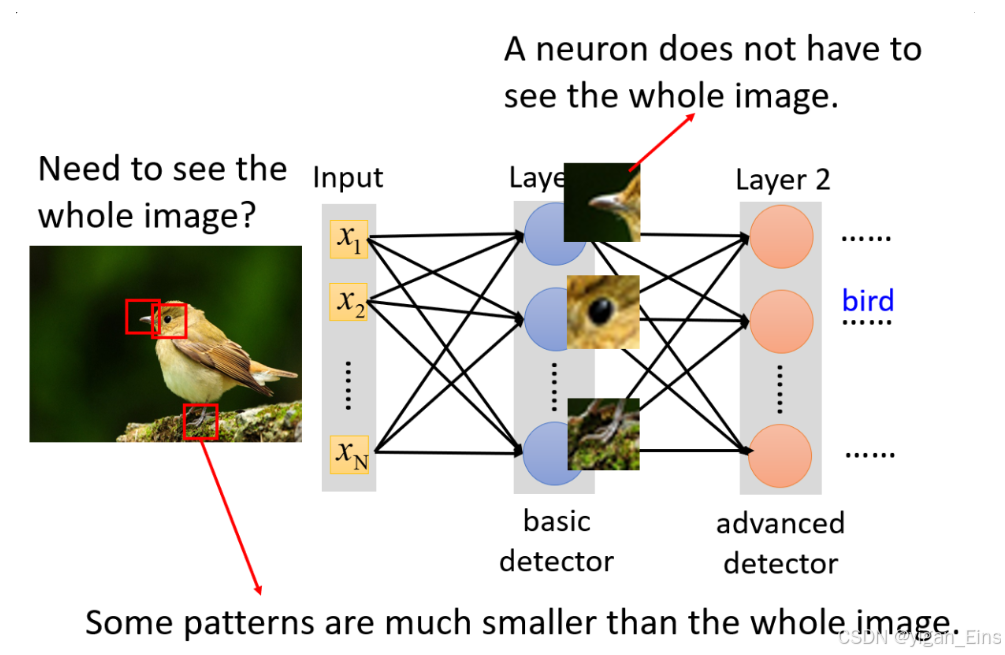
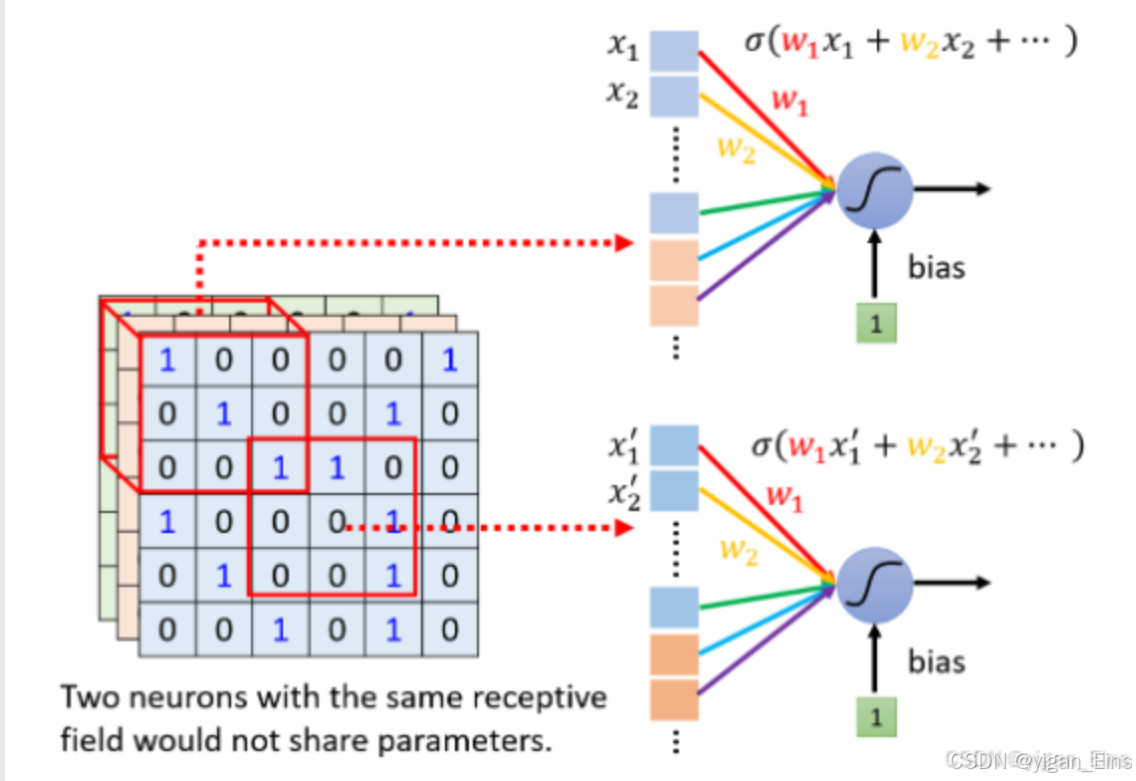
- 局部感受野:网络中的每个神经元不再关注整张图像的特征,而是只关注某个小块区域。这样,让整张图像的每个小块区域都对应着一个或多个神经元,即可训练整张图像。
- 权值共享:神经元对不同区域某一相同特征的识别的参数相同。虽然神经元识别的特征是相同的,但是由于区域不同,神经元的输出也是不同的。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
对于CNN的更多原理这里就不再赘述。
2、CNN的不足与缺陷
2014年前后,VGG 和 GoogleNet 将 CNN 的层数推向了19层甚至22层,然而当研究人员满怀期待地向更高层堆叠时,却迎头撞上了南墙:
-
梯度消失/爆炸:信息传递断层
深层网络的梯度更新依赖反向传播,误差梯度需要从输出层一层一层传回输入层,然而每经过一层网络,梯度累乘一次,当某一层梯度很大或很小时,传回浅层的梯度要么衰减为0,要么数值非常大,虽然引入ReLU轻微缓解了这一问题,但隐患依然存在。
-
网络退化:深不等于好
理论上,深层网络只需要复制浅层网络的结果,即恒等映射( H ( x ) = x H(x) = x H(x)=x),就可以保证模型的性能至少不退化。对于一个或多个微量参数,拟合出恒等映射当然容易,但是我们前面提到,对于图像处理而言,虽然
CNN已经让参数量极大的减少,但对于微量参数依然很大,基于梯度下降的优化器在极深的空间中,很难拟合出恒等映射这种复杂度极低的函数,这使得多出来的层不仅没学到有效的特征表示,反而扰乱了原本收敛的特征空间。
小结:CNN用局部感受野 和权值共享打开了j计算机视觉的大门,但在追求深度的狂奔中,却因为梯度消失和网络退化,陷入了"越深越差"的泥沼。网络退化问题的本质,是传统的多层非线性堆叠结构,无法保证信息无损地向前流动。
❓ 那么,如何才能既享受深度带来的强大表征能力,又避免信息在传递中丢失?在残差连接横空出世之前,一位重要的配角先登上了舞台,它为后续的突破铺平了道路。
二、BatchNorm崭露头角
2015年,Google提出了一个划时代的组件------批量归一化。它不仅在当时成了训练深层网络的标配,更为后来残差连接的成功铺平了道路。
1、为什么需要BatchNorm?
罪魁祸首:内部协变量偏移
在反向传播时,每一层的参数都在更新,这就导致该层输出的数据分布一直在变。对于下一层而言,它面对的输入数据分布就像一个不断移动的靶子,导致它不得不频繁调整自己来适应这种变化。网络越深,这种分布的偏移和累积就越严重,导致网络必须用极小的学习率去小心翼翼地试探,训练极其缓慢,且极易陷入梯度消失的泥沼。
2、BatchNorm的核心思想
💡 在每次训练迭代时,取一个Batch的数据,在每个特征维度上计算均值和方差,然后对数据进行标准化处理,强行将其拉回均值为0、方差为1的标准正态分布。
μ B = 1 m ∑ i = 1 m x i , σ B 2 = 1 m ∑ i = 1 m ( x i − μ B ) 2 . \mu_B = \dfrac{1}{m}\sum_{i=1}^m x_i,~~~ \sigma_B^2 = \dfrac{1}{m}\sum_{i=1}^m (x_i - \mu_B)^2 . μB=m1i=1∑mxi, σB2=m1i=1∑m(xi−μB)2.
其中 m m m 表示一个Batch内样本的数量, x i x_i xi表示一个样本特征。
💡 归一化 : x ^ i = x i − μ B σ B + ϵ \hat{x}_i = \dfrac{x_i - \mu_B}{\sqrt{\sigma_B + \epsilon}} x^i=σB+ϵ xi−μB.
其中 ϵ \epsilon ϵ 为常数因子,避免方差太小除以0。
💡 但如果只是简单粗暴地归一化,可能会破坏网络原本学到的有用特征 (比如原本某些特征需要保持在较大的值域)。因此,BN 引入了两个可学习的参数 γ \gamma γ(缩放)和 β \beta β(平移)让网络自己去决定归一化后的最佳分布。
y i = γ ⋅ x ^ i + β . y_i = \gamma \cdot \hat{x}_i + \beta . yi=γ⋅x^i+β.
🎉 BatchNorm的效果是立竿见影的,数据分布被控制在了激活函数的敏感区间内,梯度不再轻易消失或爆炸,每个卷积层的输入也不再剧烈变动,网络可以加快收敛,训练速度成倍提升。
💡 需要区分的是,
transformer中使用的norm并非BatchNorm,而是LayerNorm,他们的区别在于:BatchNorm对一个Batch内所有样本的一个特征进行归一化,而LayerNorm对每一个样本的所有特征进行归一化。这是因为在图像处理上,样本之间在空间分布有一定的联系,而
transformer主要用于自然语言处理,token之间相对独立,每个token可单独计算。
3、BatchNorm也有局限
然而,当研究人员试图将网络推进到几十层甚至上百层,网络还是越深越差,为什么呢?
BatchNorm的出现仅仅是解决内部协变量偏移问题,稳定了每层输入的数据分布,加速训练并稳定收敛,但并没有从根本上解决CNN的缺陷。虽然缓解了梯度消失和梯度爆炸,但是网络退化问题依然存在。
三、残差连接横空出世
网络退化问题的根源是:在高维非线性的参数空间中去拟合恒等映射( H ( x ) = x H(x) = x H(x)=x)这种线性直线极其困难。2015年,何恺明团队完成了一次堪称艺术级的思维跃迁。他们没有去改良激活函数,也没有去设计更复杂的卷积核,而是仅仅在网络层之间搭了一条"捷径"------残差连接。
1、从恒等映射到残差映射
💡 残差映射的思想在于:既然让网络直接学习参数,拟合恒等映射( H ( x ) = x H(x) = x H(x)=x)如此困难,不如让网络仅学习输出值与真实值的差值,即学习 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x,转化一下得到 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。然而这一简单的代数变换,带来了根本性的转变,网络不再直接拟合完整的特征分布 H ( x ) H(x) H(x),而是聚焦于拟合目标与输入之间的残差 F ( x ) F(x) F(x)。
当浅层网络已收敛时,当前网络模块即为冗余层,优化器只需将残差 F ( x ) F(x) F(x)的参数驱动至零,将参数向零逼近远比通过多层非线性变换拟合恒等映射容易得多,这极大地拓宽了优化器的收敛域,降低了陷入局部次优解的风险。
|----------------------------------------------------------------------------|
|  |
|
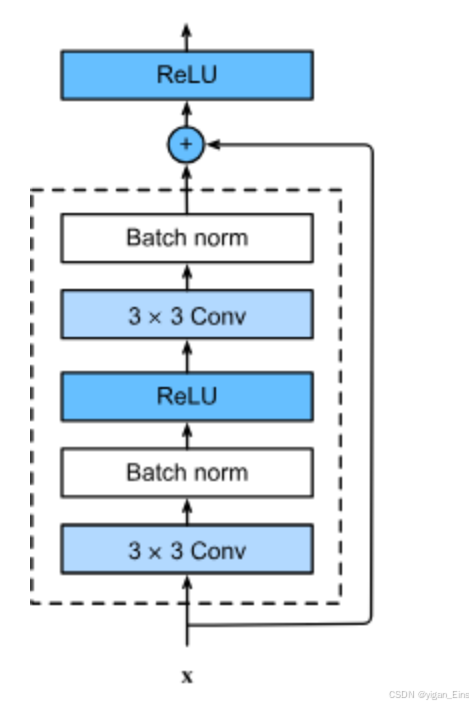
图示为一个残差块,但有时输入与输出之间的维度不一致,需要在加法时使用 1 × 1 1 \times 1 1×1的卷积核调整维度。
2、残差连接为什么有效
假设前向传播为 y = f ( x , w ) + x y = f(x,w) + x y=f(x,w)+x,在反向传播中,损失函数对输入的偏导数为:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ x = ∂ L ∂ y ⋅ ( ∂ f ∂ x + 1 ) = ∂ L ∂ y ⋅ ∂ f ∂ x + ∂ L ∂ y \dfrac{\partial L}{\partial x} = \dfrac{\partial L}{\partial y} \cdot \dfrac{\partial y}{\partial x} = \dfrac{\partial L}{\partial y} \cdot (\dfrac{\partial f}{\partial x} + 1) = \dfrac{\partial L}{\partial y} \cdot \dfrac{\partial f}{\partial x} + \dfrac{\partial L}{\partial y} ∂x∂L=∂y∂L⋅∂x∂y=∂y∂L⋅(∂x∂f+1)=∂y∂L⋅∂x∂f+∂y∂L
因此梯度由残差块的梯度和来自深层网络的梯度组成,即使残差块内部的梯度 ∂ f ∂ x \dfrac{\partial f}{\partial x} ∂x∂f极小甚至趋近于0,总梯度 ∂ L ∂ x \dfrac{\partial L}{\partial x} ∂x∂L依然至少等于 ∂ L ∂ y \dfrac{\partial L}{\partial y} ∂y∂L,这意味着梯度可以通过 + x +x +x的捷径无损地、无衰减地回传至浅层网络。
💡 这种架构设计在信息流转层面展现了卓越的梳理特性:
- 前向传播的特征无损性 : 输入特征 x x x经由捷径实现恒等传播,有效规避了逐层非线性激活带来的特征退化与信息损耗,即便是极深的网络,底层语义信息亦能无损地注入高层特征图。
- 反向传播的梯度完整性: 依据链式法则,反向传播的梯度在经过加法节点时会产生直通路径。即使中间卷积层对梯度的导数极度衰减,损失函数的梯度仍可通过捷径直接回传至浅层。这种梯度旁路机制从根本上抑制了梯度弥散现象,保障了极深网络参数更新的有效性。
3、残差连接的应用
🎉 在2015年的ImageNet大规模视觉识别挑战赛(ILSVRC)上,ResNet以断层式的优势斩获冠军。何恺明成功构建了高达152层的残差网络架构,相较于VGGNet-19在深度扩展时遭遇的优化停滞,ResNet-152不仅实现了极高的收敛效率,更在实验中证实:即便是1202层的超深残差网络,依然能够顺畅收敛(尽管受限于过拟合未能提升泛化性能)。
这使得几百层甚至几千层的超深网络成为可能,深度学习从此大放异彩。