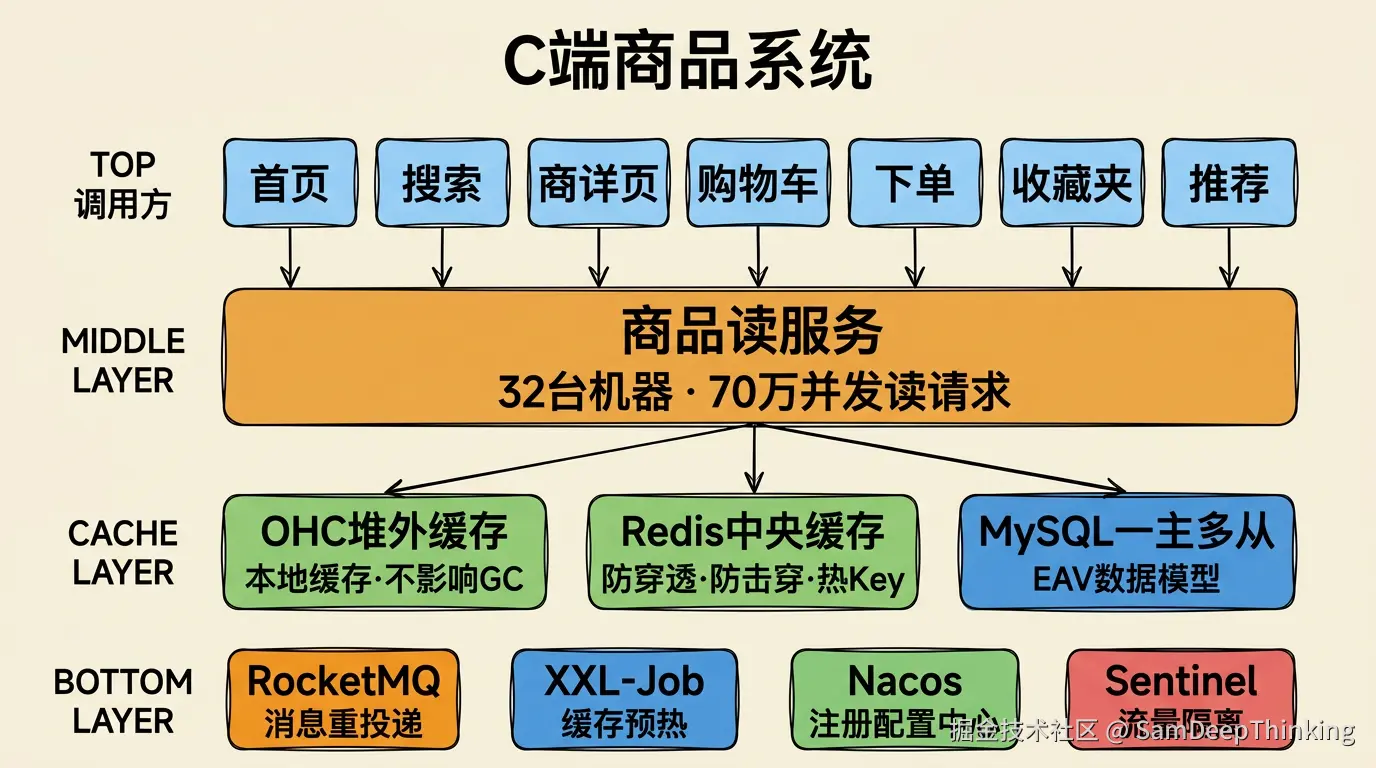
我之前在一家几亿用户规模的互联网公司做Java高级开发,深度参与设计的核心项目之一就是C端商品系统。32台机器,70万并发读请求,这是某次大促时的峰值数据。现在的流量规模比这个数字大得多。
商品系统在技术架构里的位置比较特殊。它是基础数据服务,公司几乎所有面向C端用户的业务系统都依赖它:首页、搜索、商详页、购物车、下单、收藏夹、推荐。平时流量就不小,一到大促,商品域的流量在整个公司排第一。
这套系统我从0参与设计,经历过无数次大促,扛住了每一次流量高峰。这个专栏把当时的设计思路、关键代码和踩过的坑完整写出来。
这不是概念层面的架构介绍。你能看到完整的EAV表设计、OHC堆外缓存体系、生产级的读接口设计、大促流量隔离方案、主从延迟处理,以及一次从PHP到Java的十几亿数据迁移的大重构全过程。所有代码可获取。
和市面上的内容有什么不一样
市面上讲商品系统的内容,大多集中在商品信息管理、SKU设计、分类体系这些功能层面。技术上建个表、写个CRUD、加一层Redis缓存就结束了。
真实的C端商品系统面对的问题完全不同。
拿缓存来说。网上讲缓存的文章,Caffeine做本地缓存,Redis做分布式缓存,两层堆起来似乎就够了。实际的生产环境中,商品数据有好几个G,放JVM堆内存会严重影响GC。我们用的是OHC做堆外缓存,数据存储在JVM堆外的直接内存中,不参与垃圾回收扫描。每种商品数据都有各自独立的Loader,负责从数据源加载和反序列化。缓存命中率统计也是手写的。当时没有现成框架,这些全靠自己实现。
再看表设计。商品系统是销售属性系统,运营会频繁提需求新增字段:这个商品是不是爆款、是否支持某种折扣、要不要在特定频道展示。如果每加一个属性就DDL改一次表结构,上线频率和风险都不可控。我们用的是EAV模型(Entity-Attribute-Value,实体-属性-值),每新增一个属性,就在表里加一行记录,这行记录包含字段名称、字段类型、字段值等完整的元数据信息。新增属性不需要改表结构,不需要发版。代价是查询和数据组装的逻辑复杂了不少,而且代码层面也跟常规做法完全不同。比如参数校验,传统做法直接校验字段类型就行,EAV模式下要先读取这条属性记录的元数据,拿到字段类型,再判断入参是否合法。整张表的设计和对应的代码设计都是这个专栏的重点内容。
还有大促流量隔离。用户在大促前会提前收藏商品,活动一开始就从收藏夹涌入商品详情页,瞬间产生远超日常水平的读流量。如果这部分流量和普通商品浏览走同一条链路,正常用户也会受到影响。这种场景下的隔离方案,在专栏里会完整展开。
这个专栏给你的,是一套在生产环境中扛过真实大促流量的C端商品系统的完整技术方案。
你能学到什么
整个专栏围绕C端商品系统的真实场景展开。下面列一些在其他地方大概率看不到的设计细节。
OHC堆外缓存与Loader机制
商品数据量大,堆内缓存放不下。OHC把数据存储在JVM堆外的直接内存中,不影响GC。OHC需要自己处理序列化和反序列化,每种商品数据(基础信息、销售属性、价格)都有独立的Loader,负责数据加载、序列化转换和缓存未命中的处理。
当时这些全靠手写。现在不少缓存框架已经内置了类似能力,因此专栏里我会写两个版本:一个手写版本,让你看到底层实现的每一步;一个基于现代框架的版本,直接对接框架的扩展点。缓存命中率统计也是手写实现的,命中次数、未命中次数、命中率,用来调优缓存参数。后来很多框架都自带了这个功能,但理解底层统计逻辑对调优仍然有帮助。
Redis中央缓存与防穿透
Redis承担中央缓存的角色。你会看到对接Redis的生产级实践:Key的命名与过期策略、大Value的拆分、缓存穿透防护、缓存击穿防护、热Key的识别与处理。这些技术点单独看都有成熟的方案,难的是在一个完整的商品系统里把它们组合成一套自洽的缓存体系。
缓存预热与更新策略
本地缓存如何预热,过期后如何更新。我在秒杀专栏里详细对比过四种本地缓存更新策略:请求驱动加长TTL、refreshAfterWrite异步刷新、短TTL自动失效、Redis发布订阅主动推送。商品系统选了哪种方案,为什么选它,背后的决策逻辑在专栏里会讲清楚。
EAV表设计与属性校验
商品系统用MySQL,不用MongoDB。运营频繁新增销售属性的需求,通过EAV模型解决:每个属性在表里是一行记录,包含字段名称、字段类型、字段值等元数据。新增属性不需要DDL,不需要发版。查询和数据组装比传统宽表复杂:查一个商品的完整信息需要聚合多行数据,列表查询需要做行转列。
EAV模式下的代码设计也和常规做法完全不同。拿参数校验来说,传统的宽表模式下,每个字段的类型在代码里是确定的,直接用注解或硬编码校验就行。EAV模式下,字段类型存在数据库里,校验一个入参是否合法,需要先查出这条属性记录的元数据,拿到它的类型定义,再根据类型做对应的校验逻辑。这套表设计和代码设计在专栏里完整展示。
大促流量隔离
大促开始的瞬间,用户从收藏夹涌入商品详情页。这部分流量的特征是短时间内高度集中在同一批商品上,热度远超正常浏览。如果不做隔离,连接池和线程资源会被这波流量占满,正常的商品浏览请求排队甚至超时。在专栏里会展示用隔离技术处理这个问题的完整方案。
商品读接口设计
商品是基础数据,公司很多业务系统都要对接:首页展示只要名称和图片,商详页要全量信息,下单接口只要价格和库存,搜索系统要分类和标签。不同调用方需要的字段差异很大。给每个调用方定制接口,接口数量会爆炸;只提供一个全量接口,调用方拿到一大堆用不到的数据。在专栏里你会看到一种干净的API设计方式,让不同调用方各取所需。
一主多从与主从延迟处理
数据库采用一主多从架构。运营后台刚修改了商品信息,C端用户读请求落到从库时,可能读到旧数据。主从延迟的处理代码、以及消息重投递技术的应用,在专栏里都有对应的实现。
PHP到Java大重构
这是我经历过的一次完整的系统级重构。原来的商品系统是PHP写的,全部重构成Java,表也重新设计。数据量在十几亿级别。几个关键问题:如何双写保证新老系统数据一致、如何迁移十几亿条数据且不影响线上、上线策略怎么设计(灰度比例、回滚方案)、迁移完成后如何验证数据准确。数据质检是接口质检还是SQL自检,各自适合什么场景,这些决策都会详细说。
这种规模的大重构,我经历过这一次,后面再也没遇到了。从0到1完整参与,每一步的决策都记得很清楚。
技术栈
项目的核心技术栈和秒杀专栏一致,列在这里方便提前准备环境。
| 类别 | 技术 | 版本 |
|---|---|---|
| 语言 | Java | 17 |
| 核心框架 | Spring Boot | 2.7.17 |
| 微服务 | Spring Cloud | 2021.0.8 |
| 微服务 | Spring Cloud Alibaba | 2021.0.1.0 |
| RPC | Dubbo | 3.2.0 |
| 注册中心 / 配置中心 | Nacos | 随Spring Cloud Alibaba版本 |
| 限流熔断 | Sentinel | 随Spring Cloud Alibaba版本 |
| ORM | MyBatis Plus | 3.5.1 |
| 数据库 | MySQL | 8.0(一主多从) |
| 缓存 / 分布式锁 | Redis + Redisson | Redisson 3.17.4 |
| 本地缓存(堆外) | OHC | 待定 |
| 消息队列 | RocketMQ | Spring Boot Starter 2.2.3 |
| 定时任务 | XXL-Job | 2.4.0 |
| 对象映射 | MapStruct | 1.5.5.Final |
| 日志 | Log4j2 + Disruptor | Log4j2 2.17.2 |
| 工具 | Lombok | 1.18.30 |
和秒杀专栏的区别主要在本地缓存:秒杀用Caffeine(堆内缓存),商品系统用OHC(堆外缓存),因为商品数据量远大于秒杀活动数据。
专栏目录
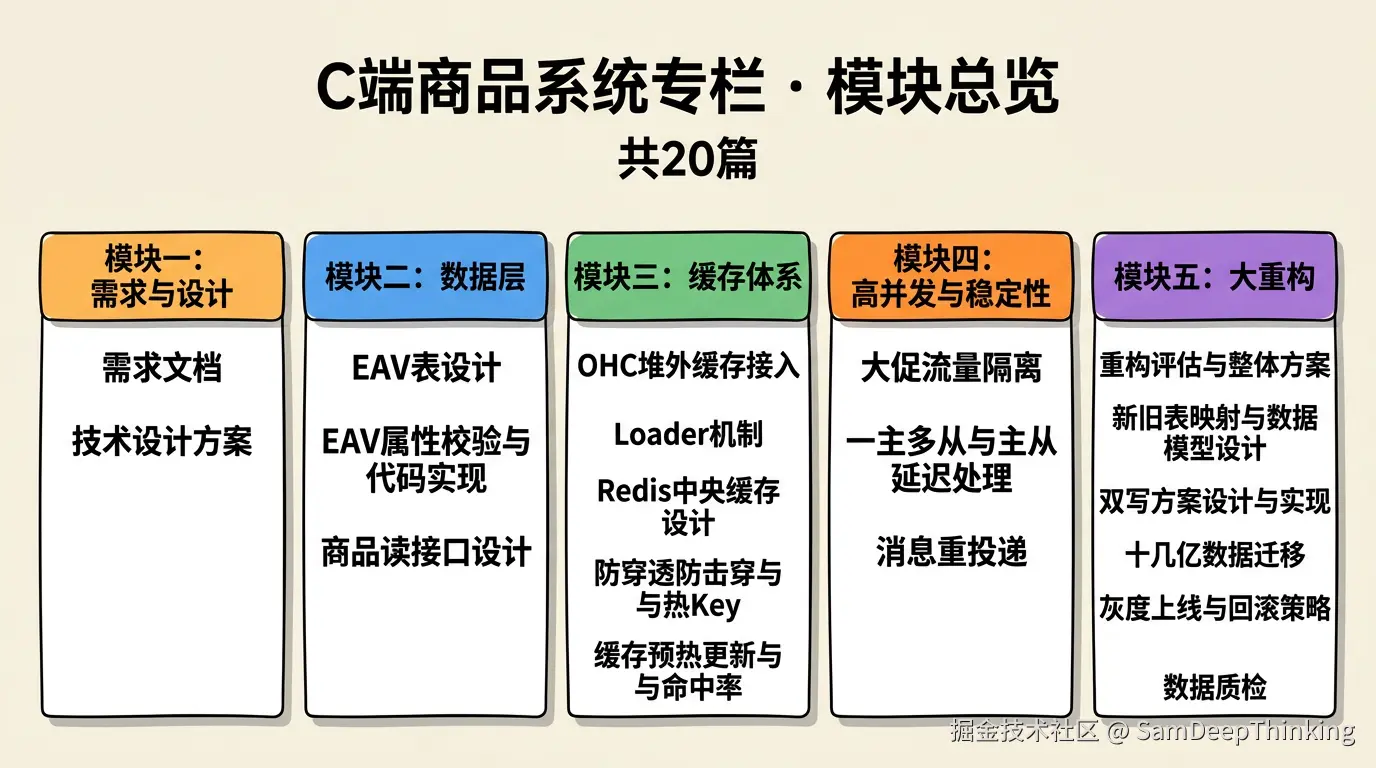
整个专栏分为五个模块:
模块一:需求与设计
从业务需求出发,分析C端商品系统的技术挑战,完成整体技术方案设计。
- 需求文档
- 技术设计方案
模块二:数据层
EAV模型的表结构设计、属性元数据与参数校验的代码实现。商品读接口的API设计,满足不同调用方的差异化需求。
- EAV表设计
- EAV属性校验与代码实现
- 商品读接口设计
模块三:缓存体系
从本地缓存到中央缓存的完整方案。OHC堆外缓存的接入,每种商品数据独立Loader的手写实现与框架版本,Redis中央缓存的生产级实践,缓存预热与更新策略。
- OHC堆外缓存接入
- Loader机制(手写版与框架版)
- Redis中央缓存设计
- 防穿透、防击穿与热Key处理
- 缓存预热、更新与命中率统计
模块四:高并发与稳定性
大促场景下的流量隔离方案,一主多从架构下的主从延迟处理,消息重投递技术。
- 大促流量隔离
- 一主多从与主从延迟处理
- 消息重投递
模块五:大重构
从PHP到Java的系统级重构全过程。重构前的评估与规划,新旧表的映射设计,双写方案,十几亿数据迁移,灰度上线与回滚,数据质检。
- 重构评估与整体方案
- 新旧表映射与数据模型设计
- 双写方案设计与实现
- 十几亿数据迁移
- 灰度上线与回滚策略
- 数据质检
每周更新两篇。
小结
C端商品系统和秒杀系统的压力模型不一样。秒杀有明确的时间窗口,扛过那几分钟就结束了。商品系统的压力是持续的、日常的。公司所有面向用户的业务都依赖它,任何性能问题都会直接体现在用户体验上。你不能靠活动结束来释放压力,必须让系统在常态下就能稳定地扛住百万级的读请求。
这个专栏里你看到的每一个技术选择,都不是为了展示技术本身,而是为了解决真实的业务问题。EAV模型不是因为它高级,是因为运营真的每隔一段时间就要加字段。OHC堆外缓存不是因为它新奇,是因为商品数据真的有好几个G放不进堆内。流量隔离不是因为这个概念好听,是因为大促那一刻收藏夹的流量真的会把普通浏览的请求挤掉。
一个技术方案好不好,看的不是它用了多少新技术,而是它在生产环境里能不能持续、稳定地工作。
定价:早鸟价29.9元(限前50名),之后恢复原价49.9元。
所有的代码都可以在知识星球里获取。这个专栏在星球里是免费的,也可以接受无限次的咨询。后续新写的所有付费专栏,在知识星球里都是免费的。我的星球是:
- 老码头的技术浮生录
专栏发布在知乎,我的知乎名是:
- SamDeepThinking