构建具备按需技能的 SQL 助手
本教程展示了如何使用 渐进式披露(progressive disclosure) ------ 一种上下文管理技术,智能体(agent)按需加载信息而不是预先加载 ------ 来实现 技能(skills)(基于提示词的专门指令)。智能体通过工具调用(tool calls)加载技能,而不是动态更改系统提示词(system prompt),仅发现并加载每个任务所需的技能。
用例: 想象一下,构建一个智能体来帮助在大型企业的不同业务垂直领域编写 SQL 查询。您的组织可能为每个垂直领域设有单独的数据存储,或者拥有一个包含数千张表的单一巨型数据库。无论哪种方式,预先加载所有模式(schemas)都会使上下文窗口超载。渐进式披露通过仅在需要时加载相关的模式来解决这个问题。这种架构还允许不同的产品所有者和利益相关者独立地为他们特定的业务垂直领域贡献和维护技能。
你将构建什么: 一个具备两项技能(销售分析和库存管理)的 SQL 查询助手。智能体在其系统提示词中看到轻量级的技能描述,然后仅在与用户查询相关时,才通过工具调用加载完整的数据库模式和业务逻辑。
有关具备查询执行、错误纠正和验证功能的 SQL 智能体的完整示例,请参阅我们的SQL Agent 教程。本教程侧重于可应用于任何领域的渐进式披露模式。
渐进式披露由 Anthropic 推广,作为一种构建可扩展智能体技能系统的技术。这种方法使用三层架构(元数据 → 核心内容 → 详细资源),智能体仅在需要时加载信息。有关此技术的更多信息,请参阅 Equipping agents for the real world with Agent Skills。
工作原理
当用户请求 SQL 查询时的流程如下:
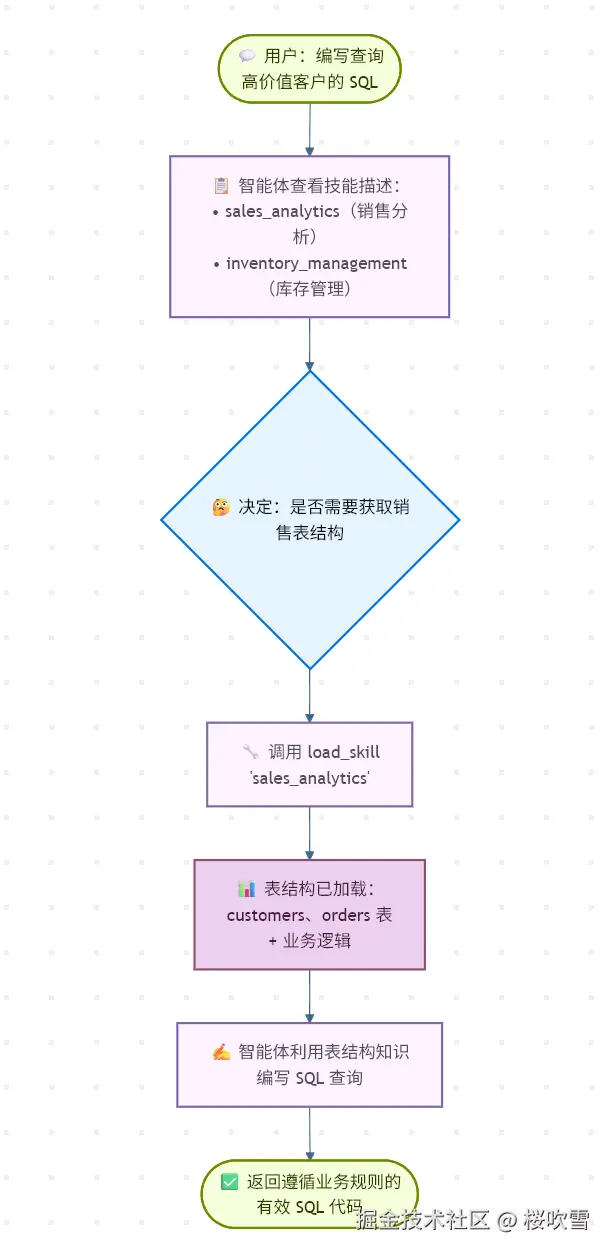
为什么使用渐进式披露:
- 减少上下文使用 - 仅加载任务所需的 2-3 项技能,而不是所有可用技能
- 实现团队自治 - 不同团队可以独立开发专门的技能(类似于其他多智能体架构)
- 高效扩展 - 添加数十或数百项技能而不会使上下文超载
- 简化对话历史 - 具有单一对话线程的单一智能体
什么是技能: 正如 Claude Code 所推广的那样,技能主要是基于提示词的:针对特定业务任务的专门指令的独立单元。在 Claude Code 中,技能作为文件系统上包含文件的目录暴露出来,通过文件操作被发现。技能通过提示词引导行为,并可以提供有关工具使用的信息,或包含供编码智能体执行的示例代码。
采用渐进式披露的技能可以被视为一种 RAG(检索增强生成) 形式,其中每项技能都是一个检索单元------尽管不一定由向量嵌入(embeddings)或关键字搜索支持,而是由用于浏览内容的工具(如文件操作,或在本教程中的直接查找)支持。
权衡(Trade-offs):
- 延迟:按需加载技能需要额外的工具调用,这会增加需要每项技能的首次请求的延迟
- 工作流控制:基本实现依赖于提示词来引导技能的使用------如果没有自定义逻辑,您无法强制执行诸如"在尝试技能 B 之前始终尝试技能 A"之类的硬约束
实现您自己的技能系统在构建您自己的技能实现时(正如我们在本教程中所做的那样),核心概念是渐进式披露------按需加载信息。除此之外,您在实现上拥有充分的灵活性:
- 存储:数据库、S3、内存数据结构或任何后端
- 发现:直接查找(本教程)、用于大型技能集合的 RAG、文件系统扫描或 API 调用
- 加载逻辑:自定义延迟特性并添加逻辑以搜索技能内容或对相关性进行排序
- 副作用(Side effects):定义加载技能时发生的情况,例如暴露与该技能关联的工具(在第 8 节中介绍)
这种灵活性使您可以针对围绕性能、存储和工作流控制的特定需求进行优化。
1. 定义技能
首先,定义技能的结构。每项技能都有一个名称、一个简短的描述(显示在系统提示词中)和完整的内容(按需加载):
ts
import { z } from "zod";
// A skill that can be progressively disclosed to the agent
const SkillSchema = z.object({
name: z.string(), // Unique identifier for the skill
description: z.string(), // 1-2 sentence description to show in system prompt
content: z.string(), // Full skill content with detailed instructions
});
type Skill = z.infer<typeof SkillSchema>;现在为 SQL 查询助手定义示例技能。这些技能被设计为描述轻量级 (预先展示给智能体)但内容详细(仅在需要时加载):
ts
import { context } from "langchain";
const SKILLS: Skill[] = [
{
name: "sales_analytics",
description:
"Database schema and business logic for sales data analysis including customers, orders, and revenue.",
content: context`
# Sales Analytics Schema
## Tables
### customers
- customer_id (PRIMARY KEY)
- name
- email
- signup_date
- status (active/inactive)
- customer_tier (bronze/silver/gold/platinum)
### orders
- order_id (PRIMARY KEY)
- customer_id (FOREIGN KEY -> customers)
- order_date
- status (pending/completed/cancelled/refunded)
- total_amount
- sales_region (north/south/east/west)
### order_items
- item_id (PRIMARY KEY)
- order_id (FOREIGN KEY -> orders)
- product_id
- quantity
- unit_price
- discount_percent
## Business Logic
**Active customers**:
status = 'active' AND signup_date <= CURRENT_DATE - INTERVAL '90 days'
**Revenue calculation**:
Only count orders with status = 'completed'.
Use total_amount from orders table, which already accounts for discounts.
**Customer lifetime value (CLV)**:
Sum of all completed order amounts for a customer.
**High-value orders**:
Orders with total_amount > 1000
## Example Query
-- Get top 10 customers by revenue in the last quarter
SELECT
c.customer_id,
c.name,
c.customer_tier,
SUM(o.total_amount) as total_revenue
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.status = 'completed'
AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'
GROUP BY c.customer_id, c.name, c.customer_tier
ORDER BY total_revenue DESC
LIMIT 10;`,
},
{
name: "inventory_management",
description:
"Database schema and business logic for inventory tracking including products, warehouses, and stock levels.",
content: context`
# Inventory Management Schema
## Tables
### products
- product_id (PRIMARY KEY)
- product_name
- sku
- category
- unit_cost
- reorder_point (minimum stock level before reordering)
- discontinued (boolean)
### warehouses
- warehouse_id (PRIMARY KEY)
- warehouse_name
- location
- capacity
### inventory
- inventory_id (PRIMARY KEY)
- product_id (FOREIGN KEY -> products)
- warehouse_id (FOREIGN KEY -> warehouses)
- quantity_on_hand
- last_updated
### stock_movements
- movement_id (PRIMARY KEY)
- product_id (FOREIGN KEY -> products)
- warehouse_id (FOREIGN KEY -> warehouses)
- movement_type (inbound/outbound/transfer/adjustment)
- quantity (positive for inbound, negative for outbound)
- movement_date
- reference_number
## Business Logic
**Available stock**:
quantity_on_hand from inventory table where quantity_on_hand > 0
**Products needing reorder**:
Products where total quantity_on_hand across all warehouses is less
than or equal to the product's reorder_point
**Active products only**:
Exclude products where discontinued = true unless specifically analyzing discontinued items
**Stock valuation**:
quantity_on_hand * unit_cost for each product
## Example Query
-- Find products below reorder point across all warehouses
SELECT
p.product_id,
p.product_name,
p.reorder_point,
SUM(i.quantity_on_hand) as total_stock,
p.unit_cost,
(p.reorder_point - SUM(i.quantity_on_hand)) as units_to_reorder
FROM products p
JOIN inventory i ON p.product_id = i.product_id
WHERE p.discontinued = false
GROUP BY p.product_id, p.product_name, p.reorder_point, p.unit_cost
HAVING SUM(i.quantity_on_hand) <= p.reorder_point
ORDER BY units_to_reorder DESC;`,
},
];2. 创建技能加载工具
创建一个工具以按需加载完整的技能内容:
load_skill 工具将完整的技能内容作为字符串返回,该字符串作为 ToolMessage 成为对话的一部分。有关创建和使用工具的更多详细信息,请参阅 Tools 指南。
ts
import { tool } from "langchain";
import { z } from "zod";
const loadSkill = tool(
async ({ skillName }) => {
// Find and return the requested skill
const skill = SKILLS.find((s) => s.name === skillName);
if (skill) {
return `Loaded skill: ${skillName}\n\n${skill.content}`;
}
// Skill not found
const available = SKILLS.map((s) => s.name).join(", ");
return `Skill '${skillName}' not found. Available skills: ${available}`;
},
{
name: "load_skill",
description: `Load the full content of a skill into the agent's context.
Use this when you need detailed information about how to handle a specific
type of request. This will provide you with comprehensive instructions,
policies, and guidelines for the skill area.`,
schema: z.object({
skillName: z.string().describe("The name of the skill to load"),
}),
}
);3. 构建技能中间件 (middleware)
创建自定义中间件,将技能描述注入到系统提示词中。该中间件使技能可被发现,而无需预先加载其完整内容。
本指南演示了如何创建自定义中间件。有关中间件概念和模式的综合指南,请参阅 自定义中间件文档。
ts
import { createMiddleware } from "langchain";
// Build skills prompt from the SKILLS list
const skillsPrompt = SKILLS.map(
(skill) => `- **${skill.name}**: ${skill.description}`
).join("\n");
const skillMiddleware = createMiddleware({
name: "skillMiddleware",
tools: [loadSkill],
wrapModelCall: async (request, handler) => {
// Build the skills addendum
const skillsAddendum =
`\n\n## Available Skills\n\n${skillsPrompt}\n\n` +
"Use the load_skill tool when you need detailed information " +
"about handling a specific type of request.";
// Append to system prompt
const newSystemPrompt = request.systemPrompt + skillsAddendum;
return handler({
...request,
systemPrompt: newSystemPrompt,
});
},
});该中间件将技能描述附加到系统提示词中,使智能体意识到可用的技能,而无需加载其完整内容。load_skill 工具被注册为类变量,使其可供智能体使用。
生产环境注意事项 :为简单起见,本教程在 __init__ 中加载技能列表。在生产系统中,您可能希望改为在 before_agent 钩子(hook)中加载技能,允许它们定期刷新以反映最新的更改(例如,当添加新技能或修改现有技能时)。有关详细信息,请参阅 before_agent 钩子文档。
4. 创建支持技能的智能体
现在使用技能中间件和用于状态持久化的 checkpointer 创建智能体:
ts
import { createAgent } from "langchain";
import { MemorySaver } from "@langchain/langgraph";
// Create the agent with skill support
const agent = createAgent({
model,
systemPrompt:
"You are a SQL query assistant that helps users " +
"write queries against business databases.",
middleware: [skillMiddleware],
checkpointer: new MemorySaver(),
});现在,智能体可以在其系统提示词中访问技能描述,并在需要时调用 load_skill 来检索完整的技能内容。checkpointer 在多轮对话中维护对话历史记录。
5. 测试渐进式披露
使用一个需要特定技能知识的问题来测试智能体:
ts
import { v4 as uuidv4 } from "uuid";
// Configuration for this conversation thread
const threadId = uuidv4();
const config = { configurable: { thread_id: threadId } };
// Ask for a SQL query
const result = await agent.invoke(
{
messages: [
{
role: "user",
content:
"Write a SQL query to find all customers " +
"who made orders over $1000 in the last month",
},
],
},
config
);
// Print the conversation
for (const message of result.messages) {
console.log(`${message._getType()}: ${message.content}`);
}预期输出:
ts
================================ Human Message =================================
Write a SQL query to find all customers who made orders over $1000 in the last month
================================== Ai Message ==================================
Tool Calls:
load_skill (call_abc123)
Call ID: call_abc123
Args:
skill_name: sales_analytics
================================= Tool Message =================================
Name: load_skill
Loaded skill: sales_analytics
# Sales Analytics Schema
## Tables
### customers
- customer_id (PRIMARY KEY)
- name
- email
- signup_date
- status (active/inactive)
- customer_tier (bronze/silver/gold/platinum)
### orders
- order_id (PRIMARY KEY)
- customer_id (FOREIGN KEY -> customers)
- order_date
- status (pending/completed/cancelled/refunded)
- total_amount
- sales_region (north/south/east/west)
[... rest of schema ...]
## Business Logic
**High-value orders**: Orders with `total_amount > 1000`
**Revenue calculation**: Only count orders with `status = 'completed'`
================================== Ai Message ==================================
Here's a SQL query to find all customers who made orders over $1000 in the last month:
\`\`\`sql
SELECT DISTINCT
c.customer_id,
c.name,
c.email,
c.customer_tier
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.total_amount > 1000
AND o.status = 'completed'
AND o.order_date >= CURRENT_DATE - INTERVAL '1 month'
ORDER BY c.customer_id;
\`\`\`
This query:
- Joins customers with their orders
- Filters for high-value orders (>$1000) using the total_amount field
- Only includes completed orders (as per the business logic)
- Restricts to orders from the last month
- Returns distinct customers to avoid duplicates if they made multiple qualifying orders6. 进阶:使用自定义状态添加约束
可选:跟踪已加载的技能并强制执行工具约束
您可以添加约束,强制要求某些工具只有在加载了特定技能之后才可用。这需要在自定义的代理状态(agent state)中跟踪哪些技能已被加载。
定义自定义状态
首先,扩展代理状态以跟踪已加载的技能:
ts
import { StateSchema } from "@langchain/langgraph";
import { z } from "zod";
const CustomState = new StateSchema({
skillsLoaded: z.array(z.string()).optional(), // Track which skills have been loaded
});更新 load_skill 以修改状态
修改 load_skill 工具,使其在加载技能时更新状态:
ts
import { tool, ToolMessage, type ToolRuntime } from "langchain";
import { Command } from "@langchain/langgraph";
import { z } from "zod";
const loadSkill = tool(
async ({ skillName }, runtime: ToolRuntime<typeof CustomState.State>) => {
// Find and return the requested skill
const skill = SKILLS.find((s) => s.name === skillName);
if (skill) {
const skillContent = `Loaded skill: ${skillName}\n\n${skill.content}`;
// Update state to track loaded skill
return new Command({
update: {
messages: [
new ToolMessage({
content: skillContent,
tool_call_id: runtime.toolCallId,
}),
],
skillsLoaded: [skillName],
},
});
}
// Skill not found
const available = SKILLS.map((s) => s.name).join(", ");
return new Command({
update: {
messages: [
new ToolMessage({
content: `Skill '${skillName}' not found. Available skills: ${available}`,
tool_call_id: runtime.toolCallId,
}),
],
},
});
},
{
name: "load_skill",
description: `Load the full content of a skill into the agent's context.`,
schema: z.object({
skillName: z.string().describe("The name of the skill to load"),
}),
}
);创建受约束的工具
创建一个只有在加载了特定技能之后才能使用的工具:
ts
const writeSqlQuery = tool(
async ({ query, vertical }, runtime: ToolRuntime<typeof CustomState.State>) => {
// Check if the required skill has been loaded
const skillsLoaded = runtime.state.skillsLoaded ?? [];
if (!skillsLoaded.includes(vertical)) {
return (
`Error: You must load the '${vertical}' skill first ` +
`to understand the database schema before writing queries. ` +
`Use load_skill('${vertical}') to load the schema.`
);
}
// Validate and format the query
return (
`SQL Query for ${vertical}:\n\n` +
`\`\`\`sql\n${query}\n\`\`\`\n\n` +
`✓ Query validated against ${vertical} schema\n` +
`Ready to execute against the database.`
);
},
{
name: "write_sql_query",
description: `Write and validate a SQL query for a specific business vertical.
This tool helps format and validate SQL queries. You must load the
appropriate skill first to understand the database schema.`,
schema: z.object({
query: z.string().describe("The SQL query to write"),
vertical: z.string().describe("The business vertical (sales_analytics or inventory_management)"),
}),
}
);更新中间件和代理
更新中间件以使用自定义状态模式(schema):
ts
const skillMiddleware = createMiddleware({
name: "skillMiddleware",
stateSchema: CustomState,
tools: [loadSkill, writeSqlQuery],
// ... rest of the middleware implementation stays the same
});使用注册了该受约束工具的中间件来创建代理:
ts
const agent = createAgent({
model,
systemPrompt:
"You are a SQL query assistant that helps users " +
"write queries against business databases.",
middleware: [skillMiddleware],
checkpointer: new MemorySaver(),
});现在,如果代理在加载所需技能之前尝试使用 write_sql_query,它将收到一条错误消息,提示其首先加载相应的技能(例如 sales_analytics 或 inventory_management)。这确保了代理在尝试验证查询之前,已经具备必要的数据库模式知识。
完整案例
为了方便学习,这里我使用ai翻译了一遍,方便学习理解,需要英文原版可以去看原文
ts
import {
tool,
createAgent,
createMiddleware,
ToolMessage,
context,
type ToolRuntime,
} from 'langchain'
import { MemorySaver, Command } from '@langchain/langgraph'
import { ChatOpenAI } from '@langchain/openai'
import { v4 as uuidv4 } from 'uuid'
import { z } from 'zod'
import 'dotenv/config'
// 一个可以逐步向智能体披露的技能
const SkillSchema = z.object({
name: z.string(), // 技能的唯一标识符
description: z.string(), // 在系统提示词中显示的1-2句话描述
content: z.string(), // 包含详细说明的完整技能内容
})
type Skill = z.infer<typeof SkillSchema>
const SKILLS: Skill[] = [
{
name: 'sales_analytics',
description:
'用于销售数据分析的数据库架构和业务逻辑,包含客户、订单和收入信息。',
content: context`
# 销售数据分析架构
## 数据表
### customers(客户表)
- customer_id (主键)
- name (姓名)
- email (邮箱)
- signup_date (注册日期)
- status (状态:active/inactive)
- customer_tier (客户等级:bronze/silver/gold/platinum)
### orders(订单表)
- order_id (主键)
- customer_id (外键 -> customers)
- order_date (订单日期)
- status (状态:pending/completed/cancelled/refunded)
- total_amount (总金额)
- sales_region (销售区域:north/south/east/west)
### order_items(订单明细表)
- item_id (主键)
- order_id (外键 -> orders)
- product_id (产品ID)
- quantity (数量)
- unit_price (单价)
- discount_percent (折扣百分比)
## 业务逻辑
**活跃客户**:status = 'active' 且 signup_date <= CURRENT_DATE - INTERVAL '90 days'
**收入计算**:
仅统计 status = 'completed' 的订单。使用 orders 表中的 total_amount,
该字段已扣除折扣。
**客户生命周期价值 (CLV)**:
客户所有已完成订单金额的总和。
**高价值订单**:
total_amount > 1000 的订单
## 示例查询
-- 获取上一季度收入排名前 10 的客户
SELECT
c.customer_id,
c.name,
c.customer_tier,
SUM(o.total_amount) as total_revenue
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.status = 'completed'
AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'
GROUP BY c.customer_id, c.name, c.customer_tier
ORDER BY total_revenue DESC
LIMIT 10;`,
},
{
name: 'inventory_management',
description:
'用于库存跟踪的数据库架构和业务逻辑,包含产品、仓库和库存水平信息。',
content: context`
# 库存管理架构
## 数据表
### products(产品表)
- product_id (主键)
- product_name (产品名称)
- sku (库存单位)
- category (类别)
- unit_cost (单位成本)
- reorder_point (补货点:触发补货的最低库存水平)
- discontinued (是否停产:布尔值)
### warehouses(仓库表)
- warehouse_id (主键)
- warehouse_name (仓库名称)
- location (位置)
- capacity (容量)
### inventory(库存表)
- inventory_id (主键)
- product_id (外键 -> products)
- warehouse_id (外键 -> warehouses)
- quantity_on_hand (现有数量)
- last_updated (最后更新时间)
### stock_movements(库存变动表)
- movement_id (主键)
- product_id (外键 -> products)
- warehouse_id (外键 -> warehouses)
- movement_type (变动类型:inbound/outbound/transfer/adjustment)
- quantity (数量:入库为正,出库为负)
- movement_date (变动日期)
- reference_number (参考单号)
## 业务逻辑
**可用库存**:
inventory 表中的 quantity_on_hand,且 quantity_on_hand > 0
**需要补货的产品**:
所有仓库中 quantity_on_hand 总和小于或等于该产品 reorder_point 的产品
**仅统计在售产品**:
除非专门分析停产商品,否则排除 discontinued = true 的产品
**库存估值**:
每个产品的 quantity_on_hand * unit_cost
## 示例查询
-- 查找所有仓库中库存低于补货点的产品
SELECT
p.product_id,
p.product_name,
p.reorder_point,
SUM(i.quantity_on_hand) as total_stock,
p.unit_cost,
(p.reorder_point - SUM(i.quantity_on_hand)) as units_to_reorder
FROM products p
JOIN inventory i ON p.product_id = i.product_id
WHERE p.discontinued = false
GROUP BY p.product_id, p.product_name, p.reorder_point, p.unit_cost
HAVING SUM(i.quantity_on_hand) <= p.reorder_point
ORDER BY units_to_reorder DESC;`,
},
]
const loadSkill = tool(
async ({ skillName }) => {
// 查找并返回请求的技能
const skill = SKILLS.find((s) => s.name === skillName);
if (skill) {
return `已加载技能:${skillName}\n\n${skill.content}`;
}
// 未找到技能
const available = SKILLS.map((s) => s.name).join(", ");
return `未找到技能 '${skillName}'。可用技能:${available}`;
},
{
name: "load_skill",
description: `将技能的完整内容加载到智能体的上下文中。
当你需要关于如何处理特定类型请求的详细信息时,请使用此工具。
它将为你提供该技能领域的全面说明、策略和指导原则。`,
schema: z.object({
skillName: z.string().describe("要加载的技能名称"),
}),
}
);
// 根据 SKILLS 列表构建技能提示词
const skillsPrompt = SKILLS.map(
(skill) => `- **${skill.name}**: ${skill.description}`,
).join('\n')
const skillMiddleware = createMiddleware({
name: 'skillMiddleware',
tools: [loadSkill],
wrapModelCall: async (request, handler) => {
// 构建技能补充说明
const skillsAddendum =
`\n\n## 可用技能\n\n${skillsPrompt}\n\n` +
'当你需要关于如何处理特定类型请求的详细信息时,请使用 load_skill 工具。'
// 追加到系统提示词
const newSystemPrompt = request.systemPrompt + skillsAddendum
return handler({
...request,
systemPrompt: newSystemPrompt,
})
},
})
const model = new ChatOpenAI({
model: 'Qwen/Qwen3.5-4B',
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
apiKey: process.env.OPENAI_API_KEY,
},
temperature: 0,
})
// 创建支持技能的智能体
const agent = createAgent({
model,
systemPrompt: '你是一个 SQL 查询助手,帮助用户针对业务数据库编写查询语句。',
middleware: [skillMiddleware],
checkpointer: new MemorySaver(),
})
// 当前对话线程的配置
const threadId = uuidv4()
const config = { configurable: { thread_id: threadId } }
// 请求生成 SQL 查询
const result = await agent.invoke(
{
messages: [
{
role: 'user',
content:
'编写一个 SQL 查询,找出上个月订单金额超过 1000 美元的所有客户',
},
],
},
config,
)
// 打印对话记录
for (const message of result.messages) {
console.log(`${message.type}: ${message.content}`)
}实现变体
查看实现选项和权衡
本教程将技能实现为通过工具调用加载的内存 Python 字典。然而,有几种方法可以实现技能的渐进式披露:存储后端:
- 内存(In-memory)(本教程):技能定义为 Python 数据结构,访问速度快,无 I/O 开销
- 文件系统 (Claude Code 方法):技能作为包含文件的目录,通过诸如
read_file的文件操作被发现 - 远程存储:技能存储在 S3、数据库、Notion 或 API 中,按需获取
技能发现(智能体如何了解存在哪些技能):
- 系统提示词列表:系统提示词中的技能描述(本教程中使用)
- 基于文件:通过扫描目录发现技能(Claude Code 方法)
- 基于注册表:查询技能注册表服务或 API 以获取可用技能
- 动态查找:通过工具调用列出可用技能
渐进式披露策略(如何加载技能内容):
- 单次加载:在一次工具调用中加载整个技能内容(本教程中使用)
- 分页:对于大型技能,分多个页面/块(chunks)加载技能内容
- 基于搜索:在特定技能的内容中搜索相关部分(例如,对技能文件使用 grep/read 操作)
- 分层:首先加载技能概述,然后深入到特定的子部分
大小注意事项(未校准的心理模型 - 请针对您的系统进行优化):
- 小型技能(< 1K tokens / 约 750 词):可以直接包含在系统提示词中,并通过提示词缓存(prompt caching)进行缓存,以节省成本并加快响应速度
- 中型技能(1-10K tokens / 约 750-7.5K 词):受益于按需加载,以避免上下文开销(本教程)
- 大型技能(> 10K tokens / 约 7.5K 词,或 > 上下文窗口的 5-10%):应使用渐进式披露技术,如分页、基于搜索的加载或分层探索,以避免消耗过多的上下文
选择取决于您的需求:内存方式最快,但技能更新需要重新部署,而基于文件或远程存储则可以在不更改代码的情况下实现动态技能管理。
渐进式披露与上下文工程 (context engineering)
结合少样本提示(few-shot prompting)和其他技术
渐进式披露从根本上来说是一种 上下文工程 技术------您在管理哪些信息对智能体可用以及何时可用。本教程侧重于加载数据库模式,但相同的原则也适用于其他类型的上下文。
结合少样本提示
对于 SQL 查询用例,您可以扩展渐进式披露,以动态加载与用户查询匹配的少样本示例(few-shot examples) :示例方法:
- 用户提问:"查找 6 个月未下单的客户"
- 智能体加载
sales_analytics模式(如本教程所示) - 智能体还加载 2-3 个相关的示例查询(通过语义搜索或基于标签的查找):
- 用于查找非活跃客户的查询
- 带有基于日期过滤的查询
- 连接客户和订单表的查询
- 智能体同时使用模式知识和示例模式编写查询
这种渐进式披露(按需加载模式)和动态少样本提示(加载相关示例)的结合,创造了一种强大的上下文工程模式,该模式可扩展到大型知识库,同时提供高质量、有根据的输出。
后续步骤
- 了解 中间件(middleware) 以获取更动态的智能体行为
- 探索用于管理智能体上下文的上下文工程 技术
- 探索用于顺序工作流的 交接模式(handoffs pattern)
- 阅读用于并行任务路由的 子智能体模式(subagents pattern)
- 查看 多智能体模式(multi-agent patterns) 以了解专门智能体的其他方法
- 使用 LangSmith 调试和监控技能加载