动态规划(DP)
动态规划是运筹学的一个分支,通常用来解决多阶段决策过程最优化问题。
动态规划的基本想法就是将原问题转换为一系列相互关联的子问题,然后通过逐层递推来求得最后的解。
1 引子
1.1 阶乘与递归
递归是一种 执果索因 的 思维方式 。
阶乘是最简单的一种情形。因为N!,仅仅依赖(N-1)!这 一个历史状态 。
(N-1)!这个历史状态就是N!的 子问题 ,并且需要注意的一点是阶乘的子问题是 不重叠 的。
什么叫 不重叠 ?------在递归地计算父问题时,子问题只被计算一次,就叫 子问题不重叠,如下图所示:
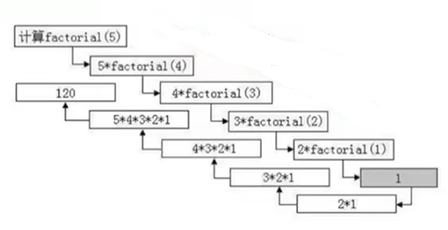
下面的代码是用python实现的N!递归版:
python
def factorial(n):
if n < 0:
raise ValueError("n must be non-negative")
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)当N非常大时,使用递归实现会导致栈空间溢出风险增大,并且函数栈的开辟和回收会导致耗时增加,迭代实现是性价比更高的实现方式(并不一定是思维方式------后续学到DP的各种问题建模时更能体会到这点)。
下述代码是用python实现的N!的迭代版:
python
def factorial(n):
if n < 0:
raise ValueError("n must be non-negative")
result = 1
for i in range(2, n + 1):
result *= i
return result这段代码比较简单,但是值得注意的是result这个变量------它会记录 历史状态 ,而且,对于本问题来说,只需要记录一个 ------因为该问题的 最小历史状态集 只有一个(N-1)! 。
最后总结一下:
我们通过阶乘引入了 递归的思维方式 , 引入了 子问题 以及 子问题是否重叠 的概念。
同时,发现并阐明了子问题是否重叠与 最小历史状态集 的关系。
1.2 斐波那契数列
我们先来看一个小青蛙跳楼梯的问题:
有一只小青蛙要跳上一个 共有 N 级台阶的楼梯。
小青蛙每次可以选择跳 1 级台阶 或 2 级台阶。
请问:
小青蛙跳到第 N 级台阶一共有多少种不同的跳法?
我们用递归的思维方式来分析一下这个问题。我们假设小青蛙已经跳到了第N级台阶上,然后思考它是从哪个台阶跳上来的。有两个来源,一个是从N-1级台阶跳上来(小青蛙可以选择跳1级台阶),另外一个是从N-2级台阶跳上来(小青蛙可以选择跳2级台阶)。
设f(n)为跳到N级台阶的总跳法,递推关系为:f(n)=f(n−1)+f(n−2),其中,f(0)=1, f(1)=1。
斐波那契数列的的递推关系为:g(n)=g(n-1)+g(n-2), 其中,g(0)=0, g(1)=1。f(n)=g(n+1)。
1.2.1 递归实现
下面是计算复杂度为O(2^n)的递归实现:
python
def fib(n):
if n < 0:
raise ValueError("n must be non-negative")
if n == 0:
return 0
if n == 1:
return 1
return fib(n - 1) + fib(n - 2)我们用一个递归图来表示这个问题:
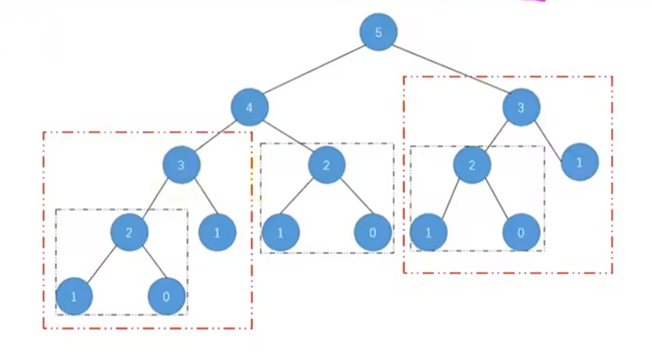
我们发现如果递归地思考或处理这个问题,会存在大量重复计算------因为存在大量 重叠子问题。
为什么这里的子问题会 重叠 ,而在阶乘的例子中子问题 不重叠 ? 想明白这一点非常重要。
从斐波那契数列的递推公式可以发现g(n)不仅依赖了g(n-1)一个历史状态,还依赖了g(n-2)。也就是说g(n)依赖的历史状态不唯一(2阶马尔科夫),因此,它的递归图是一颗树形结构,从而产生 子问题重叠 。而阶乘问题的递归图是一个线性结构,子问题不重叠 。
复杂性增长的根本原因就是递归图的拓扑结构变得复杂了。
1.2.2 带有备忘录的递归实现
既然递归实现时 重叠子问题 被计算了不止一次,那我们用表格(变量)把计算结果记录下来,再次遇到时直接查表,而不是再计算一次不就好了。一般把这个表格称作 备忘录 。
下面是带有备忘录的递归实现:
python
def fib(n, memo=None):
if memo is None:
memo = {}
if n < 0:
raise ValueError
if n in memo:
return memo[n]
if n < 2:
return n
memo[n] = fib(n-1, memo) + fib(n-2, memo)
return memo[n]1.2.3 迭代实现
看起来带备忘录的递归实现算法复杂度已经从O(2^n)降低到了O(n),但是从代码实现角度来看,每次的函数递归调用和判断memo中是否已经计算过当前子问题都是有CPU开销的。
另外,从空间复杂度来讲,带备忘录的递归实现算法是O(n),但是迭代实现的空间复杂度仅为O(1)。
因此,迭代实现比备忘录递归更省内存,也更省CPU算力。
下面是迭代实现代码,我们发现它的 最小历史状态集 为2------只需要记录2个历史状态即可。
python
def fib(n):
if n < 0:
raise ValueError
state = [0, 1] # [F(0), F(1)]
for _ in range(n):
state = [state[1], state[0] + state[1]]
return state[0]1.2.4 总结
从小青蛙跳台阶的例子中,我们进一步理解了 递归 是一种很好用的思维方式,但是如果当成实现方式,CPU和内存的资源开销则比较大。
另外,搞明白了 重叠子问题 产生的根本原因是 最小历史状态集 大于1 。
1.3 第一个DP问题
1.3.1 打家劫舍
有一排房屋,每间房屋里都有一定数量的现金。
盗贼不能偷相邻的两间房屋(否则会触发报警)。
给定一个非负整数数组 nums,其中 f(i)=numsi-1 表示第 i 间房屋中存放的现金数额。
目标:在不触发报警的前提下,偷到的最大金额。
示例1:
shell
输入:nums = [1, 2, 3, 1]
输出:4
解释:偷第 1 间和第 3 间房屋(1 + 3 = 4)示例2:
shell
输入:nums = [2, 7, 9, 3, 1]
输出:12
解释:偷第 2、4、5 间房屋(2 + 9 + 1 = 12)1.3.2 问题分析
我们仍然使用递归的思维方式来分析这个问题。
给房子进行编号1-N,任意一间房子编号用k表示;偷盗的最大总金额为v(k)。
约定:盗贼从第1间房子开始盗窃,一直盗窃到第N间房子完成整个盗窃任务(即使不盗窃第k间房子,也从第k间房子走过并思考要不要偷到这间房子------意识到这点很重要)。
假设,目前盗贼已经站在了第N间房屋前面选择偷不偷这间房,他有两种选择,一种是偷,一种是不偷。我们进行 分类讨论 :(1)如果他偷了第N间房子,那么根据约束条件,说明他 一定 没偷第N-1间房,这种情况下v_1(N)=v(N-2)+f(N)。(2)如果他没偷第N间房子,这种情况下v_2(N)=v(N-1)。
Tips:到这里一定有人会有这两个疑问。
(1)如果盗贼没偷第N间房子,那么我们也不知道他到底偷没偷第N-1间房,为什么可以直接用v(N-1)?------这就是递归思想的魅力,可以认为v(N-1)在当前迭代周期是已经确定的计算完的结果,它的不确定性会在下个周期进行确定。我们在当前周期能确定的是v(N-1)已知,并且不偷第N间房子,那么v(N)的值就等于v(N-1),即v_2(N)=v(N-1)。
(2)另外一个疑问:如果盗贼偷了第N间房子,那他一定没偷第N-1间房,那此时v(N-1)=v(N-2),有v_2(N)=v(N-2)+fN=v(N-1)+f(N),这看起来是有问题的,问题到底出在了哪里?问题出在v(N-1)=v(N-2)这里,正确的写法应该是v_2(N-1)=v(N-2)------虽然在某种情况下(某个坍缩的确定路径下)v(N-1)的值和v(N-2)的值相等,但是不能写成v(N-1)=v(N-2)
,因为v(N-1)精确的定义是所有可能情况(所有路径分支)下偷盗的最大金额,用数学语言描述是v(N-1)=maxv_1(N-1), v_2(N-1)。
问题分析完,可以很容易写出递推公式:
v(N)={max(v(N−1),v(N−2)+f(N)),N≥20,N=0f(1)=nums(0),N=1(1-1) \begin{align} v(N) = \begin{cases} &\max\bigl(v(N-1), v(N-2)+f(N)\bigr), \quad &N \ge 2\\ &0, \quad &N=0 \\ &f(1)=nums(0), \quad &N=1 \\ \end{cases} \end{align} \tag{1-1} v(N)=⎩ ⎨ ⎧max(v(N−1),v(N−2)+f(N)),0,f(1)=nums(0),N≥2N=0N=1(1-1)
1.3.3 问题求解
根据递推公式使用python实现如下:
python
def house_robber_optimized(nums):
N = len(nums)
if N == 0:
return 0
if N == 1:
return nums[0]
v_k_2 = 0 # v(0)
v_k_1 = nums[0] # v(1)
for k in range(2, N + 1):
v_k = max(
v_k_1,
v_k_2 + nums[k - 1]
)
v_k_2, v_k_1 = v_k_1, v_k
return v_k_12 DP基本概念
动态规划可以用来解决多阶段决策/序贯决策的最优问题,也可以用来求解方案数。
2.1 概念
(1) 子问题和原问题
子问题是和原问题相似,但是规模较小的问题。
(2) 状态
状态是某个空间内某个时刻或者阶段的 快照 。用数学语言描述:一个向量的某个取值就对应一个状态。状态 相对于 输入和输出 来说,是描述系统内部的变量。
当然,也可以参照有限状态机中对状态的定义。
(3) 状态空间方程
状态空间方程(包含了状态转移方程)描述了如何从一个状态转移到另外一个状态,以及每个状态对应的输入输出关系。
可以类比有限状态机中的状态转移和某状态下的输入输出定义。
(4) DP数组
DP数组用来存储历史状态对应的输出结果。
2.2 建模思路
解决问题的过程,需要经历多个阶段,每个阶段都可以看成一个子问题,每个子问题对应着一组状态。
所以,建模时主要做2件事:定义状态和推导状态空间方程。
2.2.1 定义状态
DP状态(State)之间的依赖关系是 单方向 的,因此,可以将State的概念退化/等效为Stage进行理解。Stage的思维方式就变得简单和有迹可循。比如剥洋葱的Stage就是先剥外层,再剥内层。只要能沿着某个维度将问题进行分阶段拆解,那这个维度对应的变量就可以定义为State。
2.2.2 推导状态空间方程
DP中的状态转移方程一般很简单,大部分都是等差数列。
状态到输出的映射关系一般比较复杂或者抽象,因为当前状态下对应的输出不仅仅依赖单一历史状态对应的输出,并且依赖的历史状态不一定连续------变化形式很多。这些依赖关系往往隐藏在约束中(比如小青蛙一次只能跳1个或2个台阶;盗贼不能偷盗相邻的2间房屋),将这些约束转换为递推公式是DP建模的核心。
3 练习
3.1 礼物的最大价值
3.1.1 问题描述
在一个 m × n 的网格 中,每个格子里放着一个礼物,礼物都有一定的价值(正整数)。
你从 左上角 (0,0) 出发,每一步 只能向右或向下 移动,直到到达 右下角 (m−1,n−1)。
问题是:
在这条路径上,你能拿到的礼物最大总价值是多少?
3.1.2 问题分析
最终的目标是走到右下角,并且拿到总价值最大的礼物。第一步,将最终目标进行拆解------找到驱动变量------网格编号,网格编号递增可以驱动整个任务的推进,达到最终的目标。
可以把网格的编号(i, j)定义为当前状态 SkS_kSk。
状态迁移方程:
Sk+1=T(Sk,a)(3-1) S_{k+1} = T(S_k, a) \tag{3-1} Sk+1=T(Sk,a)(3-1)
其中,a∈Aa \in Aa∈A, A={(0,1),(1,0)}A = \{(0, 1), (1, 0)\}A={(0,1),(1,0)}. T=AddT=AddT=Add 是状态迁移函数。
我们光拿到状态迁移方程还不够,还需要得到每个状态对应的输出。
设 Ok=v(Sk,Sk−1)O_k = v(S_k, S_{k-1})Ok=v(Sk,Sk−1),其中,OkO_kOk代表状态处于 SkS_kSk时对应的输出(拿到的礼物的最大总价值),vvv 代表从状态到输出的映射函数。
关键就是求解函数 vvv。假设你已经处于状态 Sk=(i,j)S_k=(i, j)Sk=(i,j),那么在该状态拿到的礼物的最大总价值包含两部分:一部分是 Sk=(i,j)S_k=(i, j)Sk=(i,j)对应的礼物价值;另一部分是 Sk−1=(i,j−1)or(i−1,j)S_{k-1}=(i, j-1) or (i-1, j)Sk−1=(i,j−1)or(i−1,j) 对应的礼物总价值(并且要取这两者中更大的那个)。
于是,得到状态对应的输出方程如下:
Ok=V(i,j)={G(0,0),i=0, j=0,G(i,0)+V(i−1,0),i∈1,m−1, j=0,G(0,j)+V(0,j−1),i=0, j∈1,n−1,G(i,j)+max(V(i−1,j),,V(i,j−1)),i∈1,m−1, j∈1,n−1.(3-2) O_k=V(i,j)= \begin{cases} G(0,0), & i=0,\ j=0, \\6pt G(i,0)+V(i-1,0), & i\in1,m-1,\ j=0, \\6pt G(0,j)+V(0,j-1), & i=0,\ j\in1,n-1, \\6pt G(i,j)+\max\big(V(i-1,j),,V(i,j-1)\big), & i\in1,m-1,\ j\in1,n-1. \end{cases} \tag{3-2} Ok=V(i,j)=⎩ ⎨ ⎧G(0,0),G(i,0)+V(i−1,0),G(0,j)+V(0,j−1),G(i,j)+max(V(i−1,j),,V(i,j−1)),i=0, j=0,i∈1,m−1, j=0,i=0, j∈1,n−1,i∈1,m−1, j∈1,n−1.(3-2)
其中,
V(i,j)V(i,j)V(i,j):到达网格 (i,j)(i,j)(i,j) 时可获得的最大礼物总价值.
G(i,j)G(i,j)G(i,j):网格 (i,j)(i,j)(i,j) 中礼物的价值.
状态空间:(i,j)∈0,m−1×0,n−1(i,j)\in0,m-1\times0,n-1(i,j)∈0,m−1×0,n−1.
3.1.3 代码实现
保留完整的二维dp数组:
python
def max_gift_value(grid):
"""
grid: List[List[int]], shape = (m, n)
return: int, maximum gift value
"""
if not grid or not grid[0]:
return 0
m, n = len(grid), len(grid[0])
dp = [[0] * n for _ in range(m)]
dp[0][0] = grid[0][0]
# first row
for j in range(1, n):
dp[0][j] = grid[0][j] + dp[0][j - 1]
# first column
for i in range(1, m):
dp[i][0] = grid[i][0] + dp[i - 1][0]
# main DP
for i in range(1, m):
for j in range(1, n):
dp[i][j] = grid[i][j] + max(dp[i - 1][j], dp[i][j - 1])
return dp[m - 1][n - 1]将路径也输出:
python
def max_gift_with_path(grid):
if not grid or not grid[0]:
return 0, []
m, n = len(grid), len(grid[0])
dp = [[0] * n for _ in range(m)]
prev = [[None] * n for _ in range(m)]
dp[0][0] = grid[0][0]
for j in range(1, n):
dp[0][j] = dp[0][j - 1] + grid[0][j]
prev[0][j] = (0, j - 1)
for i in range(1, m):
dp[i][0] = dp[i - 1][0] + grid[i][0]
prev[i][0] = (i - 1, 0)
for i in range(1, m):
for j in range(1, n):
if dp[i - 1][j] >= dp[i][j - 1]:
dp[i][j] = grid[i][j] + dp[i - 1][j]
prev[i][j] = (i - 1, j)
else:
dp[i][j] = grid[i][j] + dp[i][j - 1]
prev[i][j] = (i, j - 1)
# recover path
path = []
cur = (m - 1, n - 1)
while cur:
path.append(cur)
cur = prev[cur[0]][cur[1]]
path.append((0, 0))
return dp[m - 1][n - 1], path[::-1]3.2 0-1背包问题
3.2.1 问题描述
给定 nnn 个物品和一个容量为 WWW 的背包。
第 iii 个物品的重量为 wiw_iwi,价值为 viv_ivi,每个物品 最多只能选择一次(即 0 或 1)。
在不超过背包容量的前提下,选择若干物品放入背包,使得背包中物品的 总价值最大。
问题是:
在给定容量限制 WWW 下,能够获得的最大总价值是多少?
3.2.2 问题分析
在 0-1 背包问题中,建模的关键在于状态的选择。
所有会影响未来决策的历史信息,都必须进入状态 。
这是动态规划建模中的一个通用原则:
状态必须包含足以决定后续决策可行性的全部信息。
在本问题中,历史决策对未来选择产生影响的关键信息是 背包容量的消耗情况。因此,需要将"背包容量"作为状态的一维。
为拆解该问题,可以从 两个维度 来刻画状态:
- 已考虑的物品编号
- 当前背包的剩余容量(或已使用容量)
据此,将状态定义为:
Sk=(i,c)S_k = (i, c)Sk=(i,c)
其中,iii 表示当前考虑的物品编号,ccc 表示当前背包容量。
状态迁移
对第 iii 个物品,有两种决策(动作):
- 不选第 iii 个物品(a=0a=0a=0)
- 选第 iii 个物品(a=1a=1a=1,前提是 c≥wic \ge w_ic≥wi)
执行决策后,系统由当前状态 Sk=(i,c)S_k = (i, c)Sk=(i,c) 迁移至下一个子问题的状态 Sk+1S_{k+1}Sk+1。对应的状态迁移函数 TTT 为:
Sk+1=T(Sk,a)={(i−1,c),a=0(i−1,c−wi),a=1 (需满足 c≥wi) S_{k+1} = T(S_k, a) = \begin{cases} (i - 1, c), & a = 0 \\ (i - 1, c - w_i), & a = 1 \ (\text{需满足 } c \ge w_i) \end{cases} Sk+1=T(Sk,a)={(i−1,c),(i−1,c−wi),a=0a=1 (需满足 c≥wi)
状态输出定义
设
Ok=V(Sk)=V(i,c) O_k = V(S_k) = V(i, c) Ok=V(Sk)=V(i,c)
其中:
- V(i,c)V(i,c)V(i,c) 表示 在只考虑前 iii 个物品(注意,这里有一个隐含的物品顺序固定)、背包容量为 ccc 时可以获得的最大总价值
关键在于求解函数 VVV。
状态转移逻辑
当考虑第 iii 个物品时:
- 若不选第 iii 个物品,总价值为 V(i−1,c)V(i-1,c)V(i−1,c)
- 若选第 iii 个物品(需满足 c≥wic \ge w_ic≥wi),总价值为
V(i−1,c−wi)+vi V(i-1, c-w_i) + v_i V(i−1,c−wi)+vi
因此,当前状态的最优解应取两者中的最大值。
状态对应的输出方程
V(i,c)={0,i=0 or c=0,V(i−1,c),c<wi,max(V(i−1,c), V(i−1,c−wi)+vi),c≥wi.(3-3) V(i,c)= \begin{cases} 0, & i=0\ \text{or}\ c=0, \\6pt V(i-1,c), & c < w_i, \\6pt \max\big(V(i-1,c),\ V(i-1,c-w_i)+v_i\big), & c \ge w_i. \end{cases} \tag{3-3} V(i,c)=⎩ ⎨ ⎧0,V(i−1,c),max(V(i−1,c), V(i−1,c−wi)+vi),i=0 or c=0,c<wi,c≥wi.(3-3)
其中:
- i∈0,ni\in0,ni∈0,n
- c∈0,Wc\in0,Wc∈0,W
- wiw_iwi 和 viv_ivi 分别表示第 iii 个物品的重量和价值
3.2.3 代码实现
保留完整二维 DP 数组:
python
def knapsack_01(weights, values, W):
"""
weights: List[int], w_i
values: List[int], v_i
W: int, backpack capacity
return: int, maximum total value
"""
n = len(weights)
dp = [[0] * (W + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
w, v = weights[i - 1], values[i - 1]
for c in range(W + 1):
if c < w:
dp[i][c] = dp[i - 1][c]
else:
dp[i][c] = max(
dp[i - 1][c],
dp[i - 1][c - w] + v
)
return dp[n][W]同时输出最优选择的物品集合:
python
def knapsack_01_with_items(weights, values, W):
n = len(weights)
dp = [[0] * (W + 1) for _ in range(n + 1)]
take = [[False] * (W + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
w, v = weights[i - 1], values[i - 1]
for c in range(W + 1):
if c >= w and dp[i - 1][c - w] + v > dp[i - 1][c]:
dp[i][c] = dp[i - 1][c - w] + v
take[i][c] = True
else:
dp[i][c] = dp[i - 1][c]
# recover selected items
selected = []
c = W
for i in range(n, 0, -1):
if take[i][c]:
selected.append(i - 1)
c -= weights[i - 1]
selected.reverse()
return dp[n][W], selected4 DP的理论支撑
4.1 贝尔曼
4.1.1 两种形式的贝尔曼
根据状态演化的视角不同,贝尔曼方程可以分为 Forward Bellman (前向)和 Backward Bellman(后向)。
1. Forward Bellman Equation(前向视角)
定义:从当前时刻的状态出发,预测未来收益的期望(come-to-go)。这是控制理论和强化学习(RL)中最标准的形式。
- 视角:站在"现在",看"未来"。
- 数学逻辑 :V(s)V(s)V(s) 被定义为从 sss 开始到终止状态所能获得的累积奖励。
- 通用方程 :
V(s)=maxa∈AR(s,a)+γ∑s′∈SP(s′∣s,a)V(s′)(4-1) V(s) = \max_{a \in \mathcal{A}} \left R(s, a) + \\gamma \\sum_{s' \\in \\mathcal{S}} P(s'\|s, a) V(s') \\right \tag{4-1} V(s)=a∈AmaxR(s,a)+γs′∈S∑P(s′∣s,a)V(s′)(4-1) - 应用场景 :在线决策、实时规划。例如:机器人当前在 (0,0)(0,0)(0,0),它根据对终点的预期价值来决定下一步往哪走。
2. Backward Bellman Equation(后向视角 / 递推形式)
定义:从当前时刻的状态回溯,累加从起始状态到当前状态已经获得的收益。这在算法竞赛和离散动态规划(DP)中最为常见。
- 视角:站在"现在",看"过去"。
- 数学逻辑 :V(s)V(s)V(s) 被定义为从初始状态开始到达 sss 的最优累积收益(cost-to-come)。
- 通用方程 :
V(s)=maxa~∈A~V(T\~(s,a\~))+R(s,a\~)(4-2) V(s) = \max_{\tilde{a} \in \mathcal{\tilde{A}}} \left V(\\tilde{T}(s, \\tilde{a})) + R(s, \\tilde{a}) \\right \tag{4-2} V(s)=a~∈A~maxV(T\~(s,a\~))+R(s,a\~)(4-2) - 应用场景 :离散问题的查表法。例如:你在计算
dp[i][j]时,你关注的是从左边或上边传过来的最优结果。
3. 核心差异对比
| 特性 | Forward Bellman | Backward Bellman |
|---|---|---|
| 计算逻辑 | 递归(Recursion) | 递推(Recurrence) |
| 起始点 | 由终点向起点推导 | 由起点向终点推导 |
| 状态含义 | 到达终点的剩余最大价值 | 来自起点的累积最大价值 |
| 典型实现 | 记忆化搜索 / 深度优先搜索 | 多重循环(填表法) |
| 算法术语 | 子问题分解 | 状态空间演化 |
4.1.2 再看礼物的最大价值
这个问题本质上就是一个确定性 MDP 上的 Bellman 最优性方程 。下面按前面的符号体系,写成Backward Bellman 方程形式,同时把边界条件自然地嵌进去。
Bellman 最优性方程(确定性情形)建模如下
令状态空间
S=(i,j)∣i∈0,m−1, j∈0,n−1, \mathcal{S}={(i,j)\mid i\in0,m-1,\ j\in0,n-1}, S=(i,j)∣i∈0,m−1, j∈0,n−1,
正序/反序动作空间
A=(1,0),(0,1),A~=(−1,0),(0,−1) \begin{align} \mathcal{A}={(1,0),(0,1)}, \\6pt \mathcal{\tilde{A}}={(-1,0), (0,-1)} \end{align} A=(1,0),(0,1),A~=(−1,0),(0,−1)
即时回报函数
R(s,a~)=R(s)=G(i,j),s=(i,j), s′=T~(s,a~)=(i′,j′). R(s,\tilde{a})=R(s)=G(i,j), \quad s=(i,j),\ s'=\tilde T(s,\tilde a)=(i',j'). R(s,a~)=R(s)=G(i,j),s=(i,j), s′=T~(s,a~)=(i′,j′).
则该问题的 Bellman 方程可写为:
V(i,j)={G(0,0),(i,j)=(0,0),maxa~∈A~,,T~((i,j),a~)∈SR((i,j),a\~)+V(T\~((i,j),a\~)),otherwise.(4-3) V(i,j)= \begin{cases} G(0,0), & (i,j)=(0,0), \\6pt \displaystyle \max_{\tilde a\in\mathcal{\tilde A},,\tilde T((i,j),\tilde a)\in\mathcal{S}} \Big R\\big((i,j),\\tilde a\\big) + V\\big(\\tilde T((i,j),\\tilde a)\\big) \\Big, & \text{otherwise}. \end{cases} \tag{4-3} V(i,j)=⎩ ⎨ ⎧G(0,0),a~∈A~,,T~((i,j),a~)∈SmaxR((i,j),a\~)+V(T\~((i,j),a\~)),(i,j)=(0,0),otherwise.(4-3)
等价的展开形式(更直观)
对本问题,由于状态转移是确定的、且无折扣因子 (γ=1\gamma=1γ=1),上式可直接展开为:
V(i,j)={G(0,0),(i,j)=(0,0),max(G(i,j)+V(i−1,j),G(i,j)+V(i,j−1)),(i,j)≠(0,0).(4-2) V(i,j)= \begin{cases} G(0,0), & (i,j)=(0,0), \\6pt \max\big( G(i,j)+V(i-1,j), G(i,j)+V(i,j-1) \big), & (i,j)\ne(0,0). \end{cases} \tag{4-2} V(i,j)=⎩ ⎨ ⎧G(0,0),max(G(i,j)+V(i−1,j),G(i,j)+V(i,j−1)),(i,j)=(0,0),(i,j)=(0,0).(4-2)
该问题可建模为一个有限状态、确定性、无折扣的 Markov 决策过程,其最优值函数满足 Bellman 最优性方程。
需要注意的是,本问题采用的是 cost-to-come 形式的价值函数定义,因此 Bellman 方程依赖于前序状态(Backward Bellman)。
4.2 DP 的适用范围
1. 重叠子问题 (Overlapping Subproblems) ------ 最直观:为什么需要记忆?
这是理解 DP 必要性的起点。
- 定义:在问题的分解过程中,相同的子问题会反复出现。
- 直观理解 :例如计算斐波那契数列,算 F(5)F(5)F(5) 需要算 F(4)F(4)F(4) 和 F(3)F(3)F(3),算 F(4)F(4)F(4) 又要算 F(3)F(3)F(3)。如果不把 F(3)F(3)F(3) 存起来,电脑就会像复读机一样进行无意义的重复劳动。
- 算法价值 :它决定了 DP 的效率。通过"填表"存储已解决的答案,避免了指数级的搜索爆炸。
2. 最优子结构 (Optimal Substructure) ------ 进阶:为什么可以拆解?
这是建立状态转移方程的逻辑依据。
- 定义:原问题的最优解包含了其子问题的最优解。
- 直观理解 :这是一种"步步最优"的可能性。如果你想拿到全地图最多的礼物,那么当你到达终点前的一步时,你必然已经拿到了到达那个前序位置的最多的礼物。
当子问题不独立时(即一个子问题的决策会限制另一个子问题的选择范围),最优子结构就不复存在。
这也是为什么我们在做 DP 题(如"礼物的最大价值")时,必须确保"向右走"或"向下走"的动作,除了增加价值外,不会对未来的格子产生"封锁"或"资源占用"。 - 数学意义:它保证了局部最优可以推导到全局最优,让我们能用"拆解"的方式把大问题变小。
3. 无后效性 (No After-effect / Markov Property) ------ 最深刻:为什么能叫状态?
这是判定 DP 是否成立的最终底线,也是最抽象的数学性质。
- 定义:一旦某个阶段的状态确定,它之后的过程演变只受当前状态的影响,而与到达该状态的"路径历史"无关。
- 直观理解 :"过往不谏" 。不管你是怎么绕路走到格子 (i,j)(i, j)(i,j) 的,计算下一步时,我们只关心你现在在这个格子里,且手里有多少钱。你过去的"艰辛历程"对未来的决策没有额外影响。
- 建模挑战:如果"过去的选择"确实会影响未来(比如约束规定"不能走重复的路"),那么这个模型就失去了无后效性,必须通过"增加状态维度"来重新封装历史信息。
4.3 DP 的本质
动态规划的本质可以从工程实现、数学建模和图论抽象三个维度来理解:
1. 工程实现:空间换时间
DP 是对暴力搜索的极致优化。通过**"记忆化"**(Memoization)手段,将已经计算过的子问题结果存储在表格中。
- 剪枝效应:由于重复子问题只计算一次,DP 实际上在大规模搜索树中执行了高效的剪枝。
2. 数学建模:确定性 MDP 的求解工具
动态规划是**马尔可夫决策过程(MDP)**在确定性环境下的特例。
- 核心逻辑:它利用贝尔曼最优性方程,将长期的全局最优决策拆解为一系列短期的局部最优决策。只要状态定义满足无后效性,DP 就能通过递推找到系统演化的最优轨迹。
3. 图论抽象:DAG 上的最优路径问题
任何 DP 问题都可以抽象为在**有向无环图(DAG)**中寻找最短或最长路径。
- 节点与边:每个"状态"是图中的节点,"状态转移"是有向边,转移产生的奖励即为边权。
- 拓扑序计算:执行 DP 算法的过程,本质上是对该 DAG 进行拓扑排序并依次松弛(Relaxation)节点的过程。若图中存在强环,则 DP 失效,需转化为通用图算法(如 Dijkstra)。
5 和其他概念对比
5.1 和数列的关系:有"决策"的递推
动态规划与数列(Sequence)有着天然的血缘关系,DP 的状态转移方程本质上可以看作是多阶、非线性的递推数列。
- 数学联系 :斐波那契数列(an=an−1+an−2a_n = a_{n-1} + a_{n-2}an=an−1+an−2)是最简单的单变量 DP。
- 通俗理解 :
- 普通数列 就像是一个死板的规则 。比如:an=an−1+2a_n = a_{n-1} + 2an=an−1+2,你只需要机械地不断加 2 即可。
- DP 则是一个带有"大脑"的规则 。在每一步递推时,它都会根据之前的多个状态做一个**"决策"**。例如:V(i,j)=max(Vleft,Vup)+GcurrV(i, j) = \max(V_{left}, V_{up}) + G_{curr}V(i,j)=max(Vleft,Vup)+Gcurr。
- 差异点:数列通常寻找封闭解(通项公式),而 DP 旨在通过计算机迭代寻找特定状态的数值解。
这是为你整合了"机器人走格子"实例后的 5.2 归档版本。这个例子能够极好地展示排列组合与 DP 在"规则性"与"约束性"之间的分界线。
5.2 和排列组合的关系:不重不漏的计数器
在处理计数类问题时,DP 是对排列组合(Combinatorics)暴力搜索的高效替代。
-
数学联系:DP 的状态转移实际上是加法原理(并集)和乘法原理(分步)在子问题上的系统化应用。
-
典型实例:机器人走格子
- 纯粹网格(组合公式解) :在一个 m×nm \times nm×n 的空网格中,从左上角走到右下角(只能向右或向下),总步数是固定的。这本质上是从总步数中选出几步作为"向下"的动作。此时可以用组合数公式 直接秒杀:
方案数=Cm+n−2m−1 方案数 = C_{m+n-2}^{m-1} 方案数=Cm+n−2m−1 - 带约束网格(DP 解) :一旦场景中出现了障碍物(地雷)或者需要路径权值最大化(礼物) ,公式便因无法处理局部约束而失效。此时 DP 通过每一个格点的状态转移(dpij=dpi−1j+dpij−1 dpij = dpi-1j + dpij-1 dpij=dpi−1j+dpij−1),在递推中自动完成了复杂条件的筛选。
- 纯粹网格(组合公式解) :在一个 m×nm \times nm×n 的空网格中,从左上角走到右下角(只能向右或向下),总步数是固定的。这本质上是从总步数中选出几步作为"向下"的动作。此时可以用组合数公式 直接秒杀:
-
通俗理解:
- 排列组合倾向于利用公式计算"理论可能",它像是在算理想状态下的概率。
- DP 则是**"记账式数数"**。它在每个路口(状态)记下到此为止的走法总数或最大价值。
-
核心优势:DP 通过定义唯一状态,自动解决了排列组合中容易出现的"重复计数"问题。例如在凑零钱时,DP 通过固定的填表顺序,天然避开了"先拿1元再拿2元"与"先拿2元再拿1元"的重复困扰。
5.3 和整数规划的关系:化整为零的拆解
在运筹学中,许多整数规划(Integer Programming)问题可以通过 DP 寻找全局最优解。
-
数学联系:诸如 0/1 背包、切割钢条等问题,既可以写成线性规划的约束方程,也可以写成 DP 的递归式。
-
通俗理解:
- 整数规划 是从全局视角看约束。它像是在解一组复杂的多元不等式方程组。
- DP 则是从小规模开始尝试。先看容量为 1 时的最优解,再看容量为 2 时......这种"由小及大"的试错最终推导出全局最优。
-
差异点:整数规划依赖分支定界等搜索算法;而 DP 依赖最优子结构。当约束条件极其复杂导致状态难以定义时,DP 会遭遇"维数灾难",此时通用规划算法可能更有效。
5.4 DP 和图搜索的关系:有导航的 DAG 遍历
从数学视角看,DP 本质上是在**有向无环图(DAG)**上寻找最短/最长路径的问题。
-
等价转换:将 DP 的每一个"状态"看作图中的"顶点",每一个"转移"看作"有向边",边权为即时奖励。
-
通俗理解:
- 普通图搜索 (BFS/DFS):像是一个拿着探测仪的人,遇到路口就钻。为了防止迷路,必须费力地标记哪些点"已访问"。
- DP :像是在地板上标好数字的导航系统。由于它要求地图必须是单向的(DAG),你永远不会走回头路,只需按顺序更新格子的记录即可。
-
核心优势:
- 松弛操作 (Relaxation):DP 的过程是对节点依次进行松弛,即对比"现有路径"与"经由前序节点的新路径",保留更优者。
- 效率 :DP 利用状态空间的规整性(如网格、线性序列),使用多重循环直接访问内存,比基于队列或栈的通用搜索具有更高的缓存命中率和更低的空间常数。
5.5 和贪婪算法的关系
贪婪算法是在当前时刻决策时选最优的单点(单个状态)结果;DP算法是在当前时刻决策时选最优的子结构。
最经典的是找零钱的例子。
附录
无后效性和最优子结构约束的关系
无后效性(Markov Property)和最优子结构(Optimal Substructure)是两个独立且并行的维度。
一个问题可以满足其中一个,而不满足另一个。只有当两者同时满足(加上重叠子问题),动态规划(DP)的大厦才能建立。
为了看清两者的区别,通过下面这个逻辑矩阵来分析。
1. 逻辑辨析:它们在约束什么?
- 无后效性 约束的是 "状态转移":它要求过去不影响未来。它保证了"我只要站在这里,我的未来就确定了,不管我怎么来的"。
- 最优子结构 约束的是 "目标函数(价值)":它要求全局最优由局部最优构成。它保证了"我拿到的最大价值,一定是由我前一步拿到的最大价值加上现在的奖励组成的"。
2. 只有"无后效性"但没有"最优子结构"的反例
例子:寻找三个数,使它们的平均值最接近 10。
- 无后效性: 满足。当我选到第二个数时,我只需要知道当前两个数的和是多少,不需要知道第一个数具体是多少。系统状态是清晰的。
- 最优子结构: 不满足 。
- 假设前两个数你选了 (10,10)(10, 10)(10,10),它们的均值是 10,这在局部看是"最优"的。
- 但如果第三个数你只能选 303030,那么总均值就跑偏到了 16.616.616.6。
- 如果你局部选个"次优"的 (1,2)(1, 2)(1,2),虽然局部很烂,但如果第三个数是 272727,总均值反而变成了完美的 101010。
- 结论: 局部最优(均值最接近 10)推不出全局最优。
3. 只有"最优子结构"但没有"无后效性"的反例
例子:带有限制的旅行商问题(必须走遍所有城市,且不能走回头路)。
- 最优子结构: 满足。从 AAA 到 DDD 的最长路径,逻辑上应该由 A→CA \to CA→C 的最长路径和 C→DC \to DC→D 的最长路径拼接(假设路径不重叠)。
- 无后效性: 不满足 。
- 当你站在城市 CCC 准备去 DDD 时,你必须检查"我已经去过哪些城市了"。
- "过去"直接限制了"未来"的动作 。如果你过去为了追求局部最长而把 DDD 提前走过了,那你现在就没法去 DDD 了。
- 结论: 路径依赖(Path Dependency)破坏了马尔可夫性。
4. 总结:两者的协作关系
你可以把 DP 想象成一列火车在铁轨上行驶:
- 无后效性 就像是 铁轨的单向性:火车只能往前开,不能因为你昨天在哪个车站吃了顿饭,今天火车的引擎就突然变轨了。它保证了"状态"的纯粹。
- 最优子结构 就像是 货舱的叠加:每过一站,你往车上装最贵的货,到终点时,整车货就是最贵的。它保证了"价值"的贪心有效性。
| 性质 | 针对的对象 | 失败会导致的结果 | 解决办法 |
|---|---|---|---|
| 无后效性 | 决策逻辑/状态转移 | 无法定义状态,状态爆炸 | 增加维度(升维) |
| 最优子结构 | 目标函数/评价标准 | 局部最优导致全局失败 | 放弃 DP,改用暴力或贪心 |
最终结论:
272727,总均值反而变成了完美的 101010。
- 结论: 局部最优(均值最接近 10)推不出全局最优。
3. 只有"最优子结构"但没有"无后效性"的反例
例子:带有限制的旅行商问题(必须走遍所有城市,且不能走回头路)。
- 最优子结构: 满足。从 AAA 到 DDD 的最长路径,逻辑上应该由 A→CA \to CA→C 的最长路径和 C→DC \to DC→D 的最长路径拼接(假设路径不重叠)。
- 无后效性: 不满足 。
- 当你站在城市 CCC 准备去 DDD 时,你必须检查"我已经去过哪些城市了"。
- "过去"直接限制了"未来"的动作 。如果你过去为了追求局部最长而把 DDD 提前走过了,那你现在就没法去 DDD 了。
- 结论: 路径依赖(Path Dependency)破坏了马尔可夫性。
4. 总结:两者的协作关系
你可以把 DP 想象成一列火车在铁轨上行驶:
- 无后效性 就像是 铁轨的单向性:火车只能往前开,不能因为你昨天在哪个车站吃了顿饭,今天火车的引擎就突然变轨了。它保证了"状态"的纯粹。
- 最优子结构 就像是 货舱的叠加:每过一站,你往车上装最贵的货,到终点时,整车货就是最贵的。它保证了"价值"的贪心有效性。
| 性质 | 针对的对象 | 失败会导致的结果 | 解决办法 |
|---|---|---|---|
| 无后效性 | 决策逻辑/状态转移 | 无法定义状态,状态爆炸 | 增加维度(升维) |
| 最优子结构 | 目标函数/评价标准 | 局部最优导致全局失败 | 放弃 DP,改用暴力或贪心 |
最终结论:
符合无后效性并不意味着符合最优子结构。无后效性保证了你能"正确地写出递归式 ",而最优子结构保证了你这个递归式里取 max() 或 min() 是"正确的最优解"。
参考资料
- 清风数学建模。