目录
[深入理解 Tag 与 Field:不只是"索引 vs 数值"](#深入理解 Tag 与 Field:不只是“索引 vs 数值”)
[一、动态 Schema 的真正价值:解决工业场景的核心痛点](#一、动态 Schema 的真正价值:解决工业场景的核心痛点)
[1. MySQL 实现:静态 Schema受限](#1. MySQL 实现:静态 Schema受限)
[2. InfluxDB实现:动态 Schema 完美适配](#2. InfluxDB实现:动态 Schema 完美适配)
[二、实战落地:Java + InfluxDB 动态字段实现](#二、实战落地:Java + InfluxDB 动态字段实现)
[1. 实体类设计:固定 Tag + 动态 FieldMap](#1. 实体类设计:固定 Tag + 动态 FieldMap)
[2. 动态 Field 自动适配数据类型](#2. 动态 Field 自动适配数据类型)
[3. 测试:多厂商数据无缝写入](#3. 测试:多厂商数据无缝写入)
[4. 案例:查询动态数据](#4. 案例:查询动态数据)
[1. 写入端做字段收敛,避免"字段爆炸"](#1. 写入端做字段收敛,避免“字段爆炸”)
[2. 严格控制 Tag 基数](#2. 严格控制 Tag 基数)
[🔍 判断标准:什么时候该用 Tag?](#🔍 判断标准:什么时候该用 Tag?)
[3. 查询性能的平衡:Flux 不要一次查太多动态字段](#3. 查询性能的平衡:Flux 不要一次查太多动态字段)
[4. 时序数据的"时间对齐"陷阱](#4. 时序数据的“时间对齐”陷阱)
[5. 监控与告警](#5. 监控与告警)
[四、总结:动态 Schema 的核心价值](#四、总结:动态 Schema 的核心价值)
在工业物联网、监控告警、可观测性等时序数据场景中,我们总会遇到一个共性痛点:数据结构永远在变。
- 新接入的传感器多了 3 个采集指标
- 不同厂商的设备上报字段完全不统一
- 业务迭代需要临时新增统计维度
如果你用过传统关系型数据库(如 MySQL),一定经历过这样的痛苦:为了新增一个字段,需要提工单、走审批、执行 ALTER TABLE,期间还可能锁表影响线上业务。而 InfluxDB 可以优雅地解决这个问题------它允许你在写入时动态创建新的 Tag 和 Field,不需要提前执行任何 DDL 语句
而InfluxDB可以解决这个问题,正是因为它对 Schema 的约束足够"松弛"------它允许你在写入时动态创建新的 Tag 和 Field,而不需要提前执行**ALTER TABLE**
深入理解 Tag 与 Field:不只是"索引 vs 数值"
很多人对 Tag 和 Field 的理解停留在 "Tag 是索引,Field 是数值" 的表层,这远远不够。要正确使用动态特性,必须先理解它们在 InfluxDB TSM 存储引擎中的本质区别:
| 特性 | Tag(标签) | Field(字段) |
|---|---|---|
| 存储位置 | 倒排索引(内存 + 磁盘) | TSM 列式存储文件(仅磁盘) |
| 数据类型 | 只能是字符串 | 支持整数、浮点数、布尔、字符串 |
| 索引特性 | 全局索引,查询速度极快 | 无索引,全表扫描 |
| 基数影响 | 基数爆炸直接导致内存溢出 | 基数无上限,不影响内存 |
| 动态性 | 完全动态,运行时自动创建 | 完全动态,运行时自动创建 |
用一个生活化的例子来理解:
想象你在管理一个大型仓库的监控系统:
-
Tag 就像仓库的"货架编号"和"区域标识" :数量有限(比如 100 个货架),每个货架编号是唯一的,你需要快速找到某个货架的所有货物。这就像 Tag 用于过滤和分组(如
sensor_id、region)。 -
Field 就像货物本身的"重量"、"体积"、"温度" :这些测量值千变万化,每天新增成千上万条记录,但你很少需要根据"重量=10kg"去反向查找货物。这就像 Field 用于存储实际测量值(如
temperature、humidity)
核心结论
- Tag 是维度,Field 是指标 :Tag 用于过滤和分组(如
sensor_id、region),Field 用于存储实际测量值(如temperature、humidity) - Tag 是稀缺资源,Field 是无限资源:Tag 的数量和基数必须严格控制,Field 可以任意新增
- 两者都是完全动态的:不需要提前定义任何 Schema,写入数据时自动创建对应的 Tag 和 Field
一、动态 Schema 的真正价值:解决工业场景的核心痛点
InfluxDB 的动态 Tag/Field 不是一个 "锦上添花" 的特性,而是工业物联网场景的刚需。我们通过一个真实的项目场景来感受它的威力:
场景:多厂商设备统一接入
我们的平台需要接入来自 5 个不同厂商的 1000 + 台设备:
| 厂商 | 设备类型 | 上报指标 |
|---|---|---|
| 厂商 A | 电表 | current(电流)、temperature(温度)、total_electricity(总电量)、power(功率)、voltage(电压)、status(状态) |
| 厂商 B | 传感设备 | liquid_level(液位)、gas_concentration(气体浓度)、vibration_value(振动值) |
| 厂商 C | 温控设备 | temperature(温度)、humidity(湿度)、co(一氧化碳) |
| 其他厂商 | ... | 各自独立的上报指标,无统一标准 |
1. MySQL 实现:静态 Schema受限
面对这种多变的字段结构,MySQL 只有两个糟糕的选择:
- 分厂商建表:为每个厂商建一张单独的表:维护成本指数级爆炸,跨厂商统计几乎不可能,全局分析完全无法实现;
java
Table1:device_data_a → 6 个字段
Table2:device_data_b → 3 个字段
Table3:device_data_c → 3 个字段
...- 建超大宽表: 建一张大表,包含所有厂商的所有字段:90% 以上都是空值,新增字段必须执行 ALTER TABLE,字段越多全表扫描性能越差,还需停机维护、DBA 审批
java
CREATE TABLE device_data (
device_id VARCHAR(50),
time DATETIME,
current FLOAT, -- 厂商 A 专用
temperature FLOAT, -- 厂商 A、C 都有
total_electricity FLOAT, -- 厂商 A 专用
power FLOAT, -- 厂商 A 专用
voltage FLOAT, -- 厂商 A 专用
status INT, -- 厂商 A 专用
liquid_level FLOAT, -- 厂商 B 专用
gas_concentration FLOAT, -- 厂商 B 专用
vibration_value FLOAT, -- 厂商 B 专用
humidity FLOAT, -- 厂商 C 专用
co FLOAT, -- 厂商 C 专用
-- 厂商 D、E... 继续加字段
);🔴隐性问题:
-
90% 以上的单元格是
NULL(空间浪费) -
新增字段必须执行
ALTER TABLE(需要 DBA 审批、可能锁表) -
字段越多,全表扫描性能越差
本质问题 :关系型数据库的 Schema 是静态绑定的,必须先定义结构再写入数据,业务必须被动适应数据结构。
2. InfluxDB实现:动态 Schema 完美适配
InfluxDB 的存储引擎(TSM)对 Field 是列式独立存储 的------temperature 和 humidity 在磁盘上是不同的数据块。新增 voltage 、power 时,只会在新时间窗口下生成新的列块,完全不影响已有列的数据访问路径
这就带来几个关键收益:
| 对比维度 | MySQL 方案 | InfluxDB 方案 |
|---|---|---|
| 新增指标 | 执行 ALTER TABLE,可能锁表,需要 DBA 审批 | 写入时自动创建,零停机,零审批 |
| 存储效率 | 宽表模式下 90% 空间是 NULL | 列式存储,只存储实际写入的字段 |
| 跨厂商查询 | 需要 UNION 多张表或扫描大量 NULL 列 | 同一张表直接查询,自动过滤 |
| 代码改动 | 每次新增厂商都要修改实体类和 SQL | 代码零改动,只需修改 JSON 数据 |
也就说查询 SELECT temperature 时,引擎只会扫描 temperature 的列块,永远碰不到 voltage 的数据。动态增加字段,查询成本仅在读取那些字段时才发生。不会因为一个 Measurement 下有了 200 个 Field 就写入变慢,未来接入任何新厂商、新指标,代码无需任何修改,极致适配业务变化
而 InfluxDB 可以解决这个问题,因为它把 Schema 定义的权利,从 DBA 手中的 ALTER TABLE 下放到了每一行写入数据里,系统自动适配
二、实战落地:Java + InfluxDB 动态字段实现
围绕下面这个实体,我们能把这个机制看得非常清楚:
1. 实体类设计:固定 Tag + 动态 FieldMap
核心设计思路:固定不变的设备维度用 Tag,多变的设备指标用动态 FieldMap,无需提前定义任何指标字段。
java
@Data
@Measurement(name = "deviceRun")
public class DeviceRunData {
@Column(name = "device_id")
private Integer deviceId;
@Column(name = "device_sn", tag = true)
private String deviceSn;
@Column(name = "project_id", tag = true)
private Long projectId;
@Column(timestamp = true)
private Instant time;
/**
* 动态字段:设备上报什么,就存什么
* 温度、湿度、co、电压、电流、pm2.5... 全部自动映射
*/
private Map<String, Object> fieldMap;
}2. 动态 Field 自动适配数据类型
通过工具类将动态fieldMap转换为 InfluxDB 的 Point,自动识别数值、字符串、布尔类型,无需手动指定字段类型
java
@Autowired
private InfluxDBTemplate influxDBTemplate;
@Override
public void insertPointData(DeviceRunDataDTO dto) {
DeviceRunData runData = ConvertUtil.sourceToTarget(dto, DeviceRunData.class);
runData.setTime(Instant.now());
Point point = this.transDataPoint(runData);
influxDBTemplate.insertPoint(point);
}
public Point transDataPoint(DeviceRunData data) {
Map<String, String> tags = new HashMap<>();
Map<String, Object> fields = new HashMap<>();
if (data.getDeviceSn() != null) {
tags.put("device_sn", data.getDeviceSn());
}
if (data.getProjectId() != null) {
tags.put("project_id", String.valueOf(data.getProjectId()));
}
fields.put("device_id", data.getDeviceId());
Point point = Point.measurement("deviceRun")
.addTags(tags)
.addFields(fields)
.time(data.getTime().toEpochMilli(), WritePrecision.MS);
data.getFieldMap().forEach((key, value) -> {
TypeNormalizerUtil.addField(point, key, value);
});
return point;
}fieldMap 里的每个 key,在数据落盘时自动成为 InfluxDB measurement 中的一个 field。每个 value 的类型,自动决定了这个 field 的类型。没有 ALTER TABLE,没有停机维护,没有 DBA 审批
📢注意:
Tag 和 Field 名称应全部小写,单词间用下划线 _ 分隔,例如 cpu_usage *
InfluxDB 的查询语言(如 Flux 和 InfluxQL)对大小写敏感,驼峰命名可能引发混淆或错误
**insertPointData()**写的比较简单,为了方便实体动态插入,不需要手动塞入Tag|Field的名称与数值,优化上述代码
下面的代码通过反射自动扫描**@Column注解,将标注为tag=true** 的字段自动设为 Tag,其他字段自动设为 Field。核心价值:新增任何字段,只需要在实体类上加注解,代码完全不需要改动
java
public <T> void insertDynamic(T data) {
Map<String, String> tags = new HashMap<>();
Map<String, Object> fields = new HashMap<>();
// 核心:自动扫描所有 @Column(tag=true) 的字段
Class<?> clazz = data.getClass();
Instant time = Instant.now();
// 1. 自动扫描 @Column
for (Field f : clazz.getDeclaredFields()) {
Column column = f.getAnnotation(Column.class);
if (column != null) {
try {
f.setAccessible(true);
Object value = f.get(data);
// 确定字段名:优先 @Column(name),没写用字段名
String key = column.name().isEmpty() ? f.getName() : column.name();
// 自动区分:tag、field、time
if (column.tag()) {
tags.put(key, String.valueOf(value));
} else if (column.timestamp()) {
// 时间戳
time = (Instant) value;
} else {
fields.put(key, value);
}
} catch (Exception ignored) {
}
}
}
try {
String measurement = "";
Measurement annotation = clazz.getAnnotation(Measurement.class);
if (annotation != null && !annotation.name().isEmpty()) {
measurement = annotation.name();
}
// 2. 构建 Point 并写入
Point point = Point.measurement(measurement)
.addTags(tags)
.addFields(fields)
.time(time.toEpochMilli(), WritePrecision.MS);
// 3. 反射拿动态 fieldMap(假设 VO 有 getFieldMap() 方法)
Map<String, Object> fieldMap = null;
Method getFieldMap = clazz.getMethod("getFieldMap");
fieldMap = (Map<String, Object>) getFieldMap.invoke(data);
if (CollUtil.isNotEmpty(fieldMap)) {
//4、写入动态字段
fieldMap.forEach((key, value) -> {
TypeNormalizerUtil.addField(point, key, value);
});
}
writeApiBlocking().writePoint(point);
} catch (Exception e) {
throw new RuntimeException("Failed to insert point", e);
}
}3. 测试:多厂商数据无缝写入
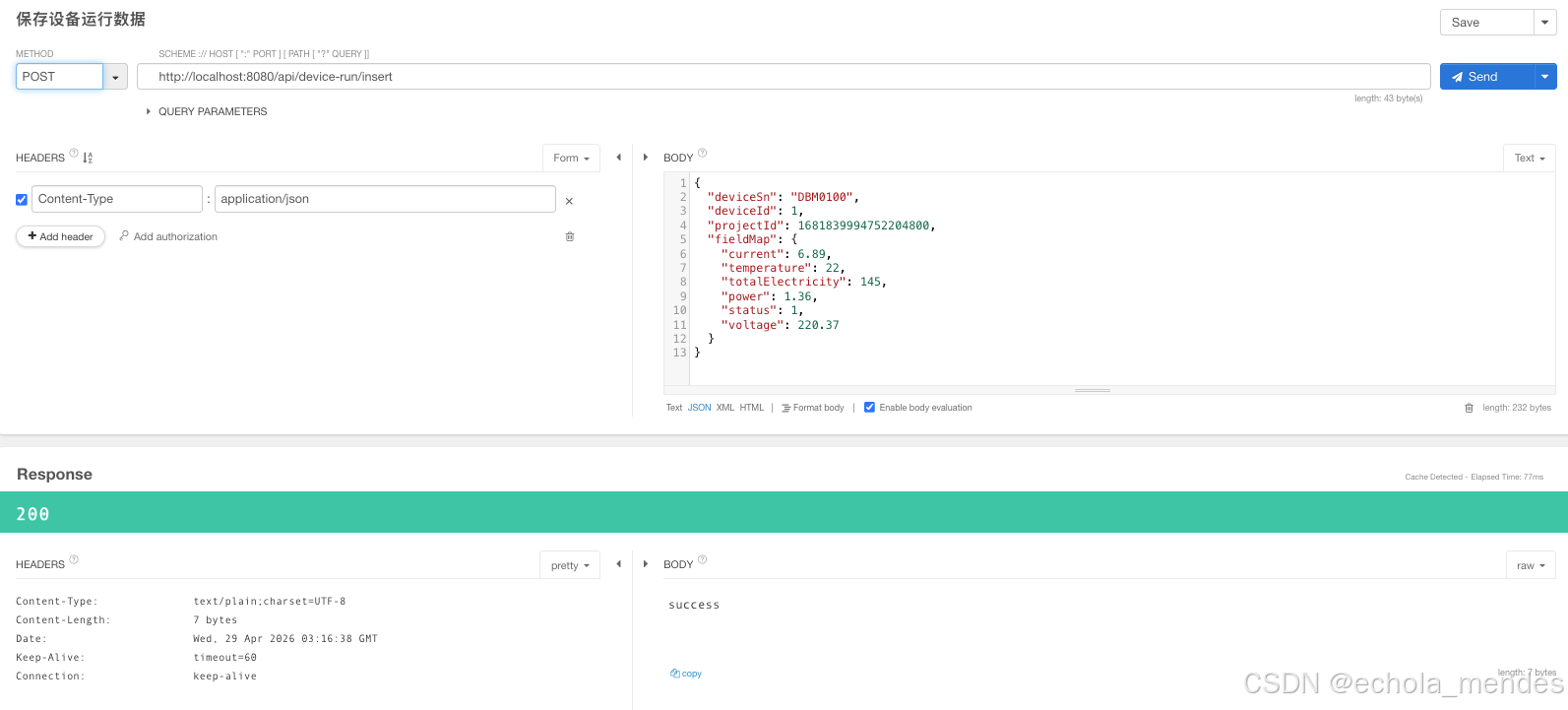
现在将厂商A的电表写入deviceRun中
javascript
{
"deviceSn": "DBM0100",
"deviceId": 1,
"projectId": 1681839994752204800,
"fieldMap": {
"current": 6.89,
"temperature": 22,
"totalElectricity": 145,
"power": 1.36,
"status": 1,
"voltage": 220.37
}
}
{
"deviceSn": "DBM0101",
"deviceId": 2,
"projectId": 1681839994752204800,
"fieldMap": {
"current": 7.12,
"temperature": 23,
"totalElectricity": 148,
"power": 1.42,
"status": 1,
"voltage": 136.45
}
}
{
"deviceSn": "DBM0102",
"deviceId": 3,
"projectId": 1681839994752204800,
"fieldMap": {
"current": 6.55,
"temperature": 21,
"totalElectricity": 142,
"power": 1.29,
"status": 1,
"voltage": 119.86
}
}通过接口插入数据后,数据已经成功写入
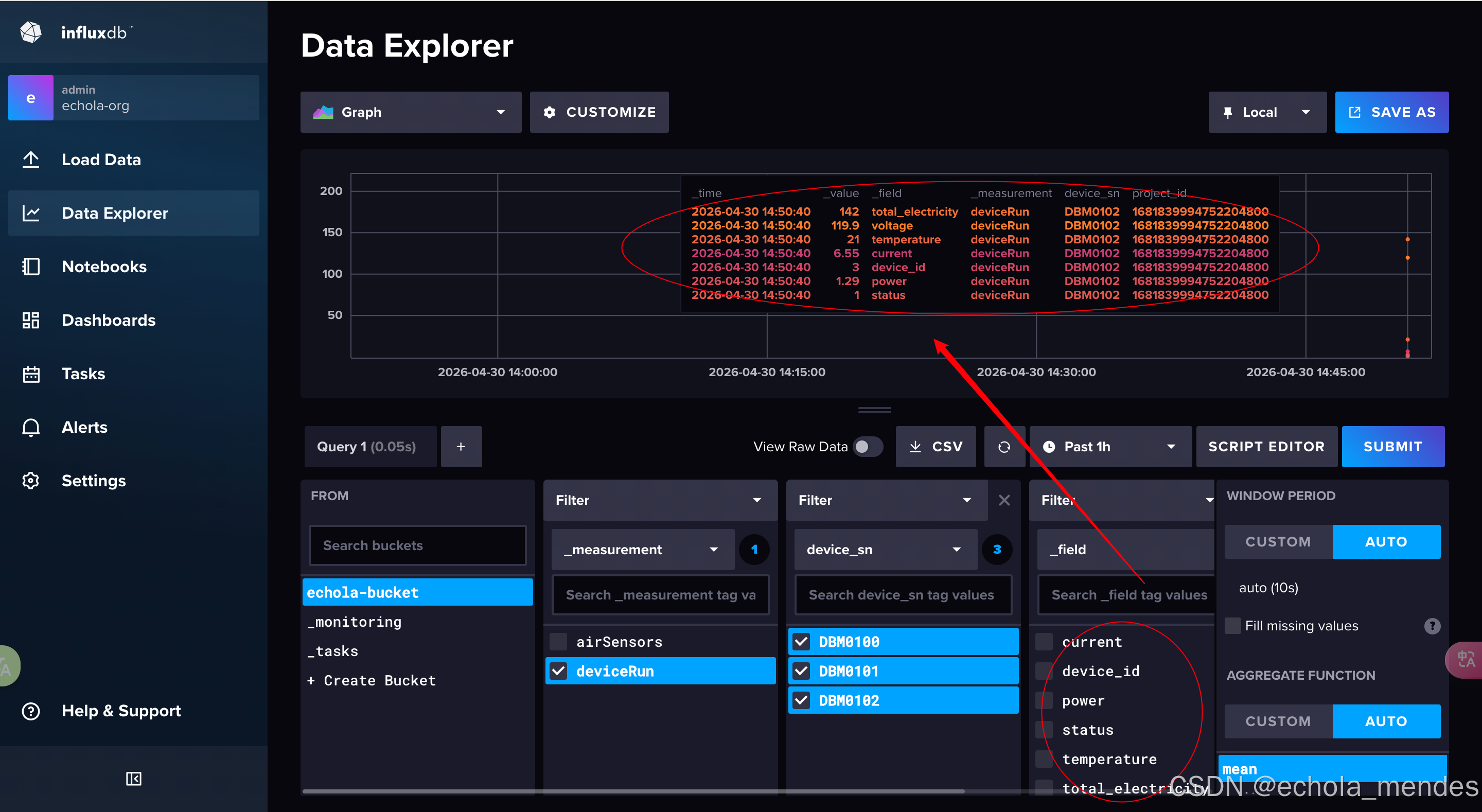
现在写入厂商B的数据
javascript
{
"deviceSn": "SDM001",
"deviceId": 4,
"projectId": 1681839994752204800,
"fieldMap": {
"liquidLevel": 62.5,
"gasConcentration": 18.3,
"vibrationValue": 4.12
}
}
{
"deviceSn": "SDM002",
"deviceId": 5,
"projectId": 1681839994752204800,
"fieldMap": {
"liquidLevel": 48.2,
"gasConcentration": 22.7,
"vibrationValue": 3.56
}
}
{
"deviceSn": "SDM003",
"deviceId": 6,
"projectId": 1681839994752204800,
"fieldMap": {
"liquidLevel": 71.9,
"gasConcentration": 15.6,
"vibrationValue": 5.33
}
}可见数据依然成功插入
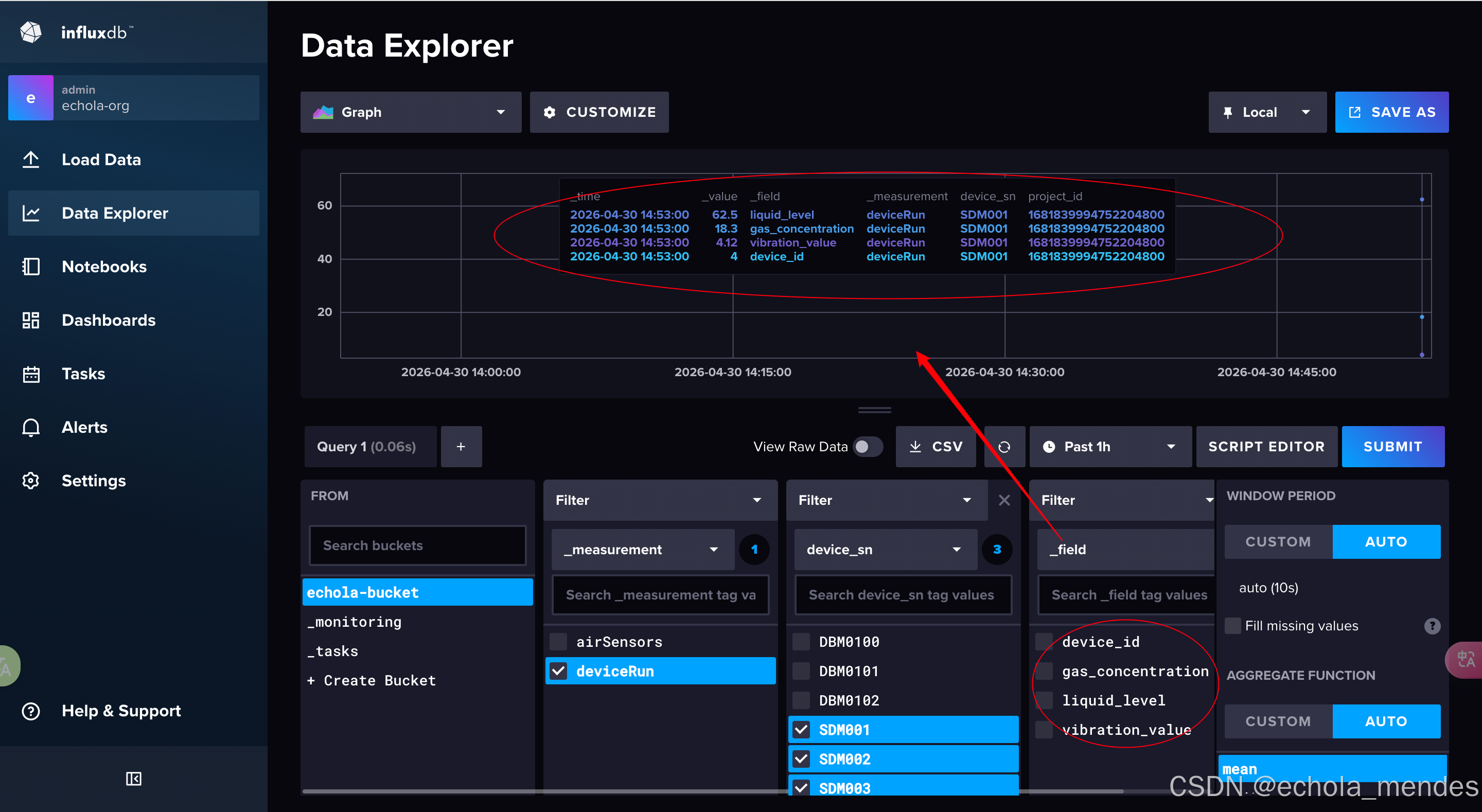
写入结果 :两组完全不同的指标数据,无需修改任何代码、无需调整表结构,全部成功写入deviceRun这一个 Measurement 中。
现在在InfluxDB的怎么样的呢?
将数据通过CSV的是下载下来就更一目了然
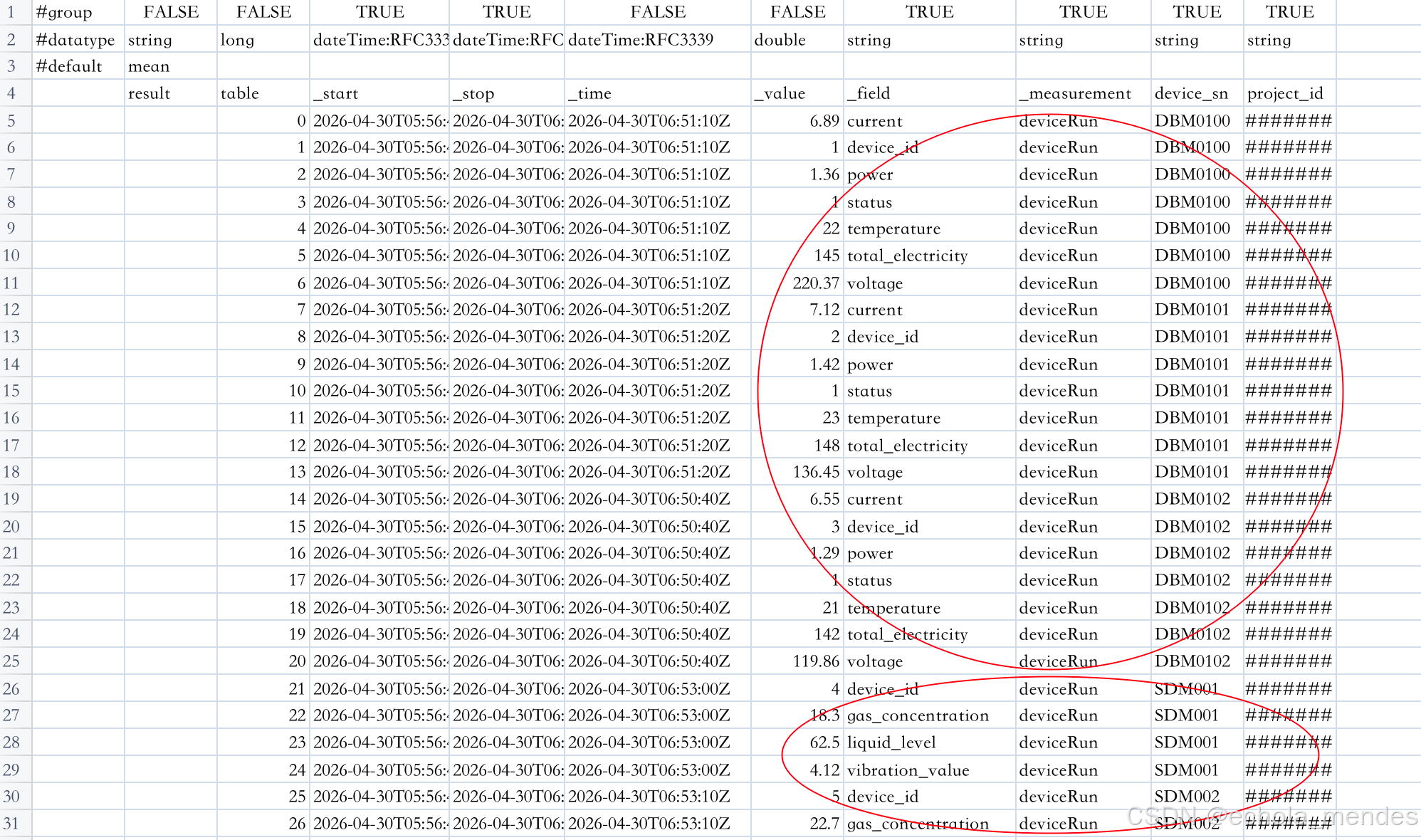
✅ 没有 DDL、没有改表、没有服务重启
✅ 所有设备数据统一存储,无空值冗余;厂商 A 的电表指标、厂商 B 的传感指标自动分列存储;所有数据存在同一个 Measurement 中,跨厂商统计无缝支持
✅ 未来接入任何新厂商,代码都不需要任何变更
这就是动态 Schema 的真正价值:让数据适应业务,而不是让业务适应数据。
4. 案例:查询动态数据
❓查询厂商 A、B 下最近一天设备的所有指标
由于是有动态数据,无法使用之前的接口,为什么呢?
1、influxDB Client 的自动映射 query(flux, clazz) 不支持动态 Map!
java
public <T> List<T> query(String flux, Class<T> clazz) {
return queryApi().query(flux, clazz);
}2、而使用List<FluxTable>可以返回数据
java
List<FluxTable> fluxTables = queryApi().query(flux);FluxTable它是一个通用的数据结构:
java
FluxTable
└── List<FluxRecord>
└── Map<String, Object> values // 所有列名和值,完全动态InfluxDB 返回什么列,FluxRecord 的 values 里就有什么键值对,没有任何映射限制。
所以动态 Field(如 current、liquidLevel、vibrationValue)都能正常出现在结果里
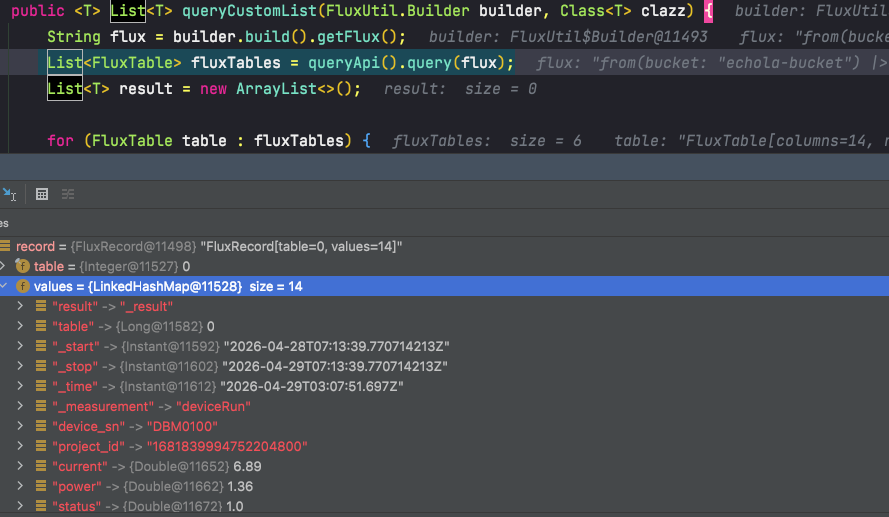
如果是展开所有Field返回到T中,可以使用
java
/**
* 返回DTO,不支持Dynamic字段
* 注意:Flux 必须用 pivot(),把 _field 列展开成真正的字段名
*/
public <T> List<T> queryCustomList(FluxUtil.Builder builder, Class<T> clazz) {
String flux = this.transFlux(builder);
List<FluxTable> fluxTables = queryApi().query(flux);
List<T> result = new ArrayList<>();
for (FluxTable table : fluxTables) {
for (FluxRecord record : table.getRecords()) {
Map<String, Object> values = new HashMap<>(record.getValues());
if (record.getTime() != null) {
values.put("time", Date.from(record.getTime()));
}
//Hutool的toBean()默认就会做下划线转驼峰
T obj = BeanUtil.toBean(values, clazz);
result.add(obj);
}
}
return result;
}或者直接将所有数据放入List<Map>中
java
/**
* 返回Map
*/
public List<Map<String, Object>> queryMap(FluxUtil.Builder builder) {
String flux = this.transFlux(builder);
return queryApi().query(flux).stream()
.flatMap(table -> table.getRecords().stream())
.map(FluxRecord::getValues)
.peek(map -> systemFieldList.forEach(map::remove))
.collect(Collectors.toList());
}但在实际的业务中还是操作POJO计算方便,也并不需要所有的字段参与业务计算,所以也就不需要再实体T中添加太多的字段,这个方法就就不使用了,还是可以没有定义的字段放入Map中,后续需要再进行取值操作,还是通过反射进行数据赋值
自定义注解@DynamicField,标记动态字段
java
/**
* @Author: echola
* @Date: 2026/4/29 18:45
* @Description: 动态Field
*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DynamicField {
}在动态字段上添加注解
java
@Data
public class DeviceRunDataVO {
private String deviceId;
private String deviceSn;
private String projectId;
/**
* 动态字段:设备上报什么,就存什么
* 温度、湿度、co、电压、电流、pm2.5... 全部自动映射
*/
@DynamicField
private Map<String, Object> fieldMap;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date time;
}添加支持动态字段查询的接口
java
/**
* 返回DTO,支持Dynamic字段
*/
public <T> List<T> queryDynamicList(FluxUtil.Builder builder, Class<T> clazz) {
String flux = this.transFlux(builder);
List<FluxTable> fluxTables = queryApi().query(flux);
List<T> result = new ArrayList<>();
//1. 找 @DynamicField 注解的字段
Field fieldMap = null;
for (Field f : clazz.getDeclaredFields()) {
if (f.isAnnotationPresent(DynamicField.class)) {
fieldMap = f;
break;
}
}
// 2. 遍历数据
for (FluxTable table : fluxTables) {
for (FluxRecord record : table.getRecords()) {
Map<String, Object> values = new HashMap<>(record.getValues());
Map<String, Object> dynamicMap = new HashMap<>();
// 3. 只清理系统字段
//systemFieldList.forEach(values::remove);
values.keySet().removeIf(systemFieldList::contains);
// 4. 时间处理
if (record.getTime() != null)
values.put("time", Date.from(record.getTime()));
// 5. Hutool 自动映射(自动下划线转驼峰)
T obj = BeanUtil.toBean(values, clazz);
// 6. 塞入动态字段
if (fieldMap != null) {
for (Map.Entry<String, Object> entry : values.entrySet()) {
String originalKey = entry.getKey();
//转驼峰
String key = TypeNormalizerUtil.toCamelCase(originalKey);
// 检查 obj 里有没有这个字段(Hutool映射后的字段名)
if (BeanUtil.getFieldValue(obj, key) == null) {
dynamicMap.put(key, entry.getValue());
}
}
if (CollUtil.isNotEmpty(dynamicMap)) {
try {
// 开启访问权限(因为 fieldMap 是 private 的)
fieldMap.setAccessible(true);
// 核心:把 dynamicValues 赋值给 obj 的 fieldMap 字段
// 等价于:obj.setFieldMap(dynamicMap);
fieldMap.set(obj, dynamicMap);
// Hutool通过反射设置字段值
//BeanUtil.setFieldValue(obj, fieldMap.getName(), dynamicMap);
} catch (Exception ignored) {
}
}
}
result.add(obj);
}
}
return result;
}查询
java
public List<DeviceRunDataVO> listDeviceData(DeviceRunDataDTO dto) {
FluxUtil.Builder builder = new FluxUtil.Builder().bucket(bucket)
.timeRange(dto.getTimeType())
.measurement(DeviceRunData.class)
.in("device_sn", dto.getDeviceSnList())
.pivot()
.sort();
return influxDBTemplate.queryDynamicList(builder, DeviceRunDataVO.class);
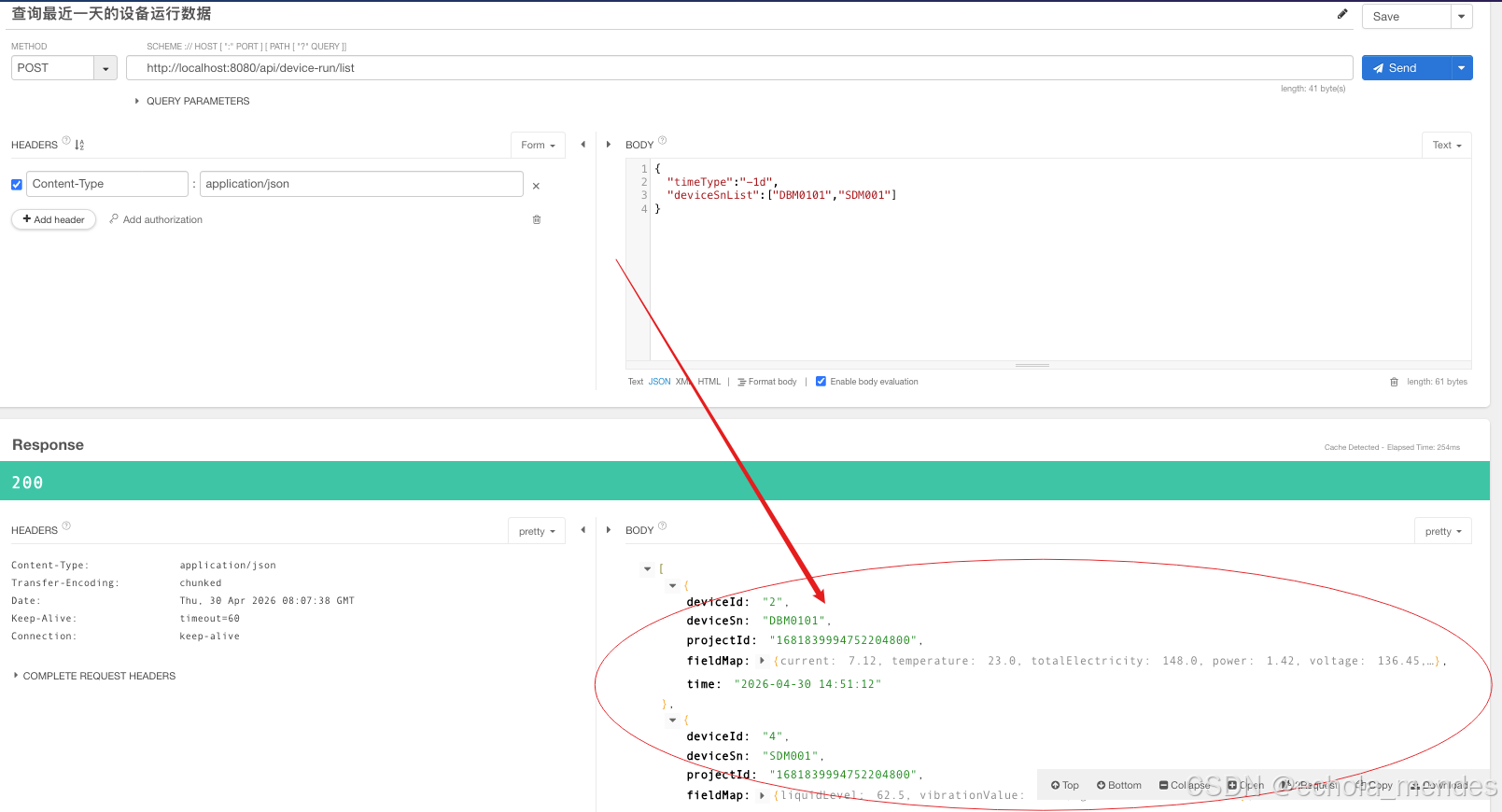
}通过接口成功查询了建议近一天设备的运行数据:
入参:
javascript
{
"timeType":"-1d",
"deviceSnList":["DBM0101","SDM001"]
}
三、生产实践中的边界与权衡
动态 Schema 虽然强大,但并非"银弹",在实际落地中需要关注以下几点:
1. 写入端做字段收敛,避免"字段爆炸"
问题案例: 某物联网平台接入了 10 万台设备,每台设备每次上报都带一个 request_id(每次不同)。半年后,InfluxDB 中积累了 10 亿个不同的 Field key,查询性能急剧下降,甚至出现 OOM
-
虽然 Field 理论无上限,但单 Measurement 下数千个不同 Field 名称会导致查询时元数据开销增大
-
建议在数据接入层对同类设备做字段标准化(如统一
temperature而非混用temp、tem)
**问题案例:**某物联网平台接入了 2000 台同型号的电表。每台电表理论上应该上报相同的指标集(电流、电压、功率、温度、电量)。但由于固件版本差异、配置不同、部分电表升级中途失败,实际上报的字段五花八门:
javascript
// 电表A
{"device_id": "A001", "current": 10.2, "voltage": 220, "power": 2.2, "temp": 45, "energy": 100}
// 电表B
{"device_id": "B001", "flow": 9.8, "elec": 219, "load": 2.1, "heat": 44, "use": 98}
// 电表C
{"device_id": "C001", "amperage": 9.8, "potential": 219, "wattage": 2.1, "thermo": 44, "consumption": 98}三个月后:
2000 台设备,同一个指标------电流,累计产生了 47 个不同的字段名(current、flow、amperage、... 都代表同一个物理量),最终导致:查询任意指标都要加载大量元数据
✅ 正确做法:在数据写入 InfluxDB 之前,增加一层字段映射转换,那么查询一个指标,就只用筛选一个字段
bash
current、flow、amperage --> current2. 严格控制 Tag 基数
-
切勿将
device_id、request_id等超高基数字段设为 Tag -
对百万级以上的设备场景,考虑使用分片策略或改用 Field 存储,配合应用层聚合
问题案例: 某团队将 ip_address(5000 个不同 IP)设为 Tag,查询 SELECT * FROM metrics WHERE ip='10.0.0.1' 确实很快。但当数据量增长到百万级时,InfluxDB 内存飙升至 8GB,服务频繁 OOM。
根本原因: 每个唯一 Tag 值都会在倒排索引中占据内存。Tag 基数 = 唯一 Tag 值的数量。5000 个 IP 看起来不多,但如果还有 user_id(10 万)、device_id(5 万),总索引内存 = 5000 × 10万 × 5万?不,更可怕------每个 Tag 的组合都会产生索引条目!
最佳实践:
-
Tag 基数建议控制在 1 万以内
-
高基数字段(如
ip、user_id、trace_id)应该作为 Field 存储 -
如果确实需要高基数 Tag,考虑使用专业时序数据库(如 M3DB、TDengine)或增加节点规格
权衡说明:
-
用 Tag 查询每秒可处理百万级数据
-
用 Field 查询需要全表扫描,但配合时间范围和低基数 Tag 过滤,依然可控
| 方案 | Series 数量 | 内存占用 | 查询方式 |
|---|---|---|---|
| 高基数设 Tag | 几百万 | 32GB+ OOM | 直接过滤,但内存扛不住 |
| 高基数设 Field | 低基数 Tag 组合(如 300×10=3000) | <2GB | 先粗筛,再应用层过滤 |
🔍 判断标准:什么时候该用 Tag?
| 数据类型 | 基数范围 | 是否适合 Tag | 原因 |
|---|---|---|---|
| 设备类型、厂商、区域 | < 1万 | ✅ 适合 | 低基数,内存友好 |
| 城市、版本号、状态码 | < 10万 | ⚠️ 谨慎 | 需要评估内存 |
| 设备ID、用户ID、订单ID、IP | > 100万 | ❌ 不适合 | 直接导致内存爆炸 |
核心原则:
Tag 用于低基数枚举值(设备类型、区域、厂商),Field 用于高基数标识符(设备ID、用户ID、订单ID)。
记住: Tag 的数量 × 每个 Tag 的基数 = 倒排索引内存。
1万个设备ID作为 Tag,可能只有1万个 Series;但2个 Tag(各1万基数)组合起来,理论 Series = 1亿
**3. 查询性能的平衡:**Flux 不要一次查太多动态字段
-
Tag 查询快但消耗内存,Field 灵活但需扫描
-
高频过滤条件走 Tag,低频、模糊查询走 Field,或借助 InfluxDB 的 Flux 语言做后过滤
问题案例: 某监控系统使用 queryDynamicList() 方法查询过去 30 天数据,一次性返回 60 个动态字段和 10 万条记录。查询耗时 30 秒,应用服务器频繁 GC
根本原因: queryDynamicList() 通过反射构建对象,对于每个动态字段都要做驼峰转换和赋值。字段越多、数据量越大,反射开销越明显
最佳实践:
-
✅ 按需查询:只查询业务真正需要的字段
-
✅ 分页查询:避免一次查询超过 1 万条记录
-
✅ 特定字段查询:如果明确知道需要
current和temperature,直接在 Flux 中指定,不要用pivot()展开所有字段 -
❌ 避免:
SELECT *+ 大时间范围 + 大量动态字段
也就是使用FluxUtils.filterField()
java
// ✅ 推荐:只查询需要的字段
from(bucket:"echola-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "deviceRun")
|> filter(fn: (r) => r._field == "current" or r._field == "temperature")
|> pivot(rowKey:["_time"], columnKey:["_field"], valueColumn:"_value")
// ❌ 不推荐:自动展开所有字段(性能差)
from(bucket:"echola-bucket")
|> range(start: -30d)
|> pivot(rowKey:["_time"], columnKey:["_field"], valueColumn:"_value")4. 时序数据的"时间对齐"陷阱
**问题案例:**某风电场监控系统,风速传感器每10秒上报一次,发电机功率每5分钟上报一次。开发同学直接按原始时间写入
javascript
//风速每10s上送
风速: 2026-04-30 10:00:00, 10.2m/s
风速: 2026-04-30 10:00:10, 10.5m/s
//功率每5min上送
功率: 2026-04-30 10:00:00, 1500kW
功率: 2026-04-30 10:05:00, 1520kW查询"过去1小时风速和功率的关系"时:
-
风速有 360 个点,功率只有 12 个点
-
需要做时间窗口对齐(如按5分钟取平均风速)
-
开发者手动写 Flux 的
aggregateWindow(),容易出错
根本问题: InfluxDB 不做自动时间对齐。不同频率的数据写入后,查询时需要显式指定降采样规则
不同设备上报速度不一样,时间点对不上,没法一起分析,必须强行按同一个时间窗口对齐
正确做法:写入时或查询时做预处理
方案一:写入时统一频率(推荐)
javascript
// 将高频数据按窗口聚合后再写入
public void writeWindSpeed(List<WindSpeed> rawData) {
Map<Long, Double> avgBy5Min = rawData.stream()
.collect(Collectors.groupingBy(
d -> d.getTime().toEpochMilli() / 300000 * 300000, // 按5分钟对齐
Collectors.averagingDouble(WindSpeed::getValue)
));
// 写入对齐后的数据
}方案二:查询时动态对齐
用 Flux 的 aggregateWindow 按 5 分钟求平均,再 join 功率。好处就是原始数据还在
javascript
// 将风速按5分钟降采样,再与功率做 Join
windSpeed = from(bucket:"wind")
|> range(start: -1h)
|> filter(fn: (r) => r._field == "speed")
|> aggregateWindow(every: 5m, fn: mean)
power = from(bucket:"wind")
|> range(start: -1h)
|> filter(fn: (r) => r._field == "power")
join(tables: {w: windSpeed, p: power}, on: ["_time", "device_id"])还有一个问题:❓Time时间应该存 设备事件上送时间 还是 服务器当前时间?
标准答案:
必须存【设备采集的真实业务时间】
-
风速是 10:00:00 测的 → 存 10:00:00
-
温度是 10:00:10 测的 → 存 10:00:10
-
功率是 10:05:00 测的 → 存 10:05:00
❌ 绝对不能存:**Instant.now()**服务器当前时间
为什么?
因为网络延迟、设备离线重发、多设备异步上报 ,服务器收到的时间≠真实采集时间。你存错时间,所有统计、图表、分析全部报废
且 InfluxDB 的 time 字段不是普通 Field,而是存储引擎的核心。
_time是系统级主键、索引、分区依据- 所有底层存储、分片、TTL、
range()、aggregateWindow()、GROUP BY time都强依赖_time
一句话总结:
time存的必须是"事件发生的真实时间",不是"数据入库的时间"。 存错了,InfluxDB 就从一个时序数据库降级成了一个普通的日志存储
| 功能 | 依赖 time 的方式 |
如果存错时间的后果 |
|---|---|---|
| Shard 分区 | 按 time 范围分配数据到不同 Shard |
历史数据可能落到当前 Shard,TTL 失效 |
| TTL 自动清理 | 根据 time 判断数据是否过期 |
该删的不删,不该删的删了 |
range(start, stop) |
基于 time 过滤 |
查不到正确时间范围的数据 |
aggregateWindow(every: 1h) |
按 time 分组聚合 |
数据落入错误的时间窗口 |
| 降采样持续查询 | 依赖 time 对齐窗口 |
统计结果完全错误 |
5. 监控与告警
-
必须监控 Series 数量(
SHOW SERIES CARDINALITY),设置阈值告警 -
设定单 Measurement 的 Field 数量上限,防止异常设备"污染"Schema
在生产环境中,必须对 InfluxDB 的关键指标进行监控:
| 监控项 | 黄色预警(需关注) | 红色预警(立即处理) | 处理方式 |
|---|---|---|---|
| 内存使用率 | >70% | >85% | 检查 Tag 基数,清理高基数 Tag |
| 写入延迟 | >100ms | >500ms | 检查是否有大量小批次写入,改用批量写入 |
| Series 数量 | >100 万 | >500 万 | 检查是否有意外的高基数 Tag 组合 |
| 查询延迟 | >1s | >5s | 优化 Flux 语句,增加时间范围过滤 |
常用监控命令:
javascript
# 查看 Series 数量(关键指标!)
influxd inspect report-db -db-path /var/lib/influxdb/data/my_db
# 查看 Tag 基数分布
influx query 'from(bucket:"echola-bucket") |> range(start: -1d) |> group(columns: ["_tag_key"]) |> count()'四、总结:动态 Schema 的核心价值
InfluxDB 的动态 Schema 特性,彻底颠覆了传统数据库「先定义结构、后写入数据」的模式。它把 Schema 定义的权利从 DBA 的 ALTER TABLE 中解放出来,下放给每一行写入的数据。
核心能力
| 能力 | 传统数据库 | InfluxDB 动态 Schema | 业务价值 |
|---|---|---|---|
| 极致灵活 | 字段变化需要改表、审批、停机 | 新设备、新指标即接即存 | 业务迭代周期从天级缩短到分钟级 |
| 零成本维护 | DDL 需要 DBA 审核,大表加列可能锁表 | 告别 ALTER TABLE,零停机 | 运维成本降低 90% 以上 |
| 统一管理 | 多厂商数据分散在多个表或宽表中 | 异构设备数据统一存储 | 跨厂商统计、全局分析无缝实现 |
适用场景
✅ 工业物联网(设备型号多、上报字段不统一)
✅ 监控告警(Prometheus 的 label 动态变化)
✅ 可观测性(APM 的 span tag 千变万化)
✅ 任何「数据结构无法预定义」的场景
不适用场景
❌ 强事务一致性要求(如金融交易流水)
❌ 复杂关联查询(如多表 JOIN)
❌ 字段总数确定且小于 50 个的小规模场景(此时关系型数据库更简单
这就是时序数据库 InfluxDB 的核心魅力:让数据主动适应业务,而不是让业务被迫适配数据。 在你下一次为 ALTER TABLE 烦恼时,不妨试试动态 Schema 的思路------也许你会发现,原来处理"永远在变"的数据,可以如此优雅,哈哈哈哈......